4달 전
비지도 단일 카메라 깊이와 자아 운동 학습에 구조와 의미를 활용한 방법
Casser, Vincent ; Pirk, Soeren ; Mahjourian, Reza ; Angelova, Anelia
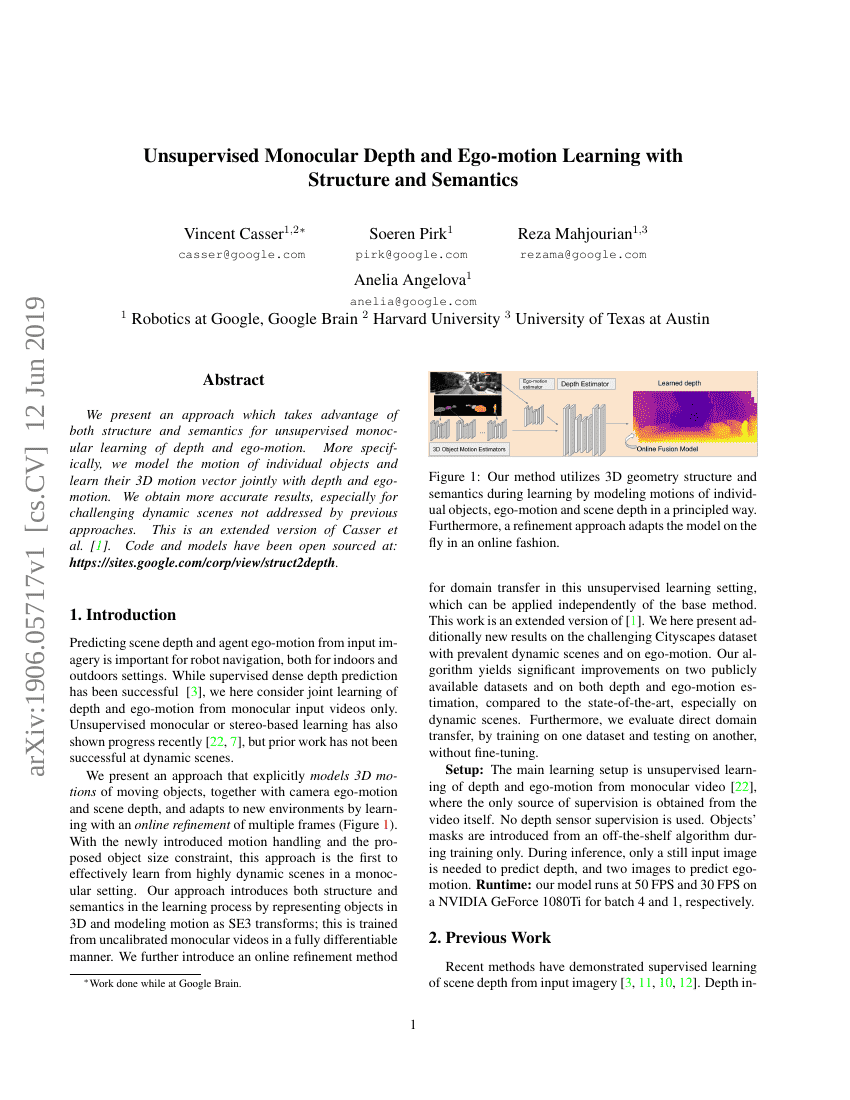
초록
우리는 구조와 의미를 모두 활용하여 감독되지 않은 단일 카메라 깊이 및 자기 운동 학습을 위한 접근 방식을 제시합니다. 보다 구체적으로, 개별 객체의 운동을 모델링하고 그들의 3차원 운동 벡터를 깊이와 자기 운동과 함께 공동으로 학습합니다. 이로 인해 특히 이전 접근 방식에서 다루지 않았던 도전적인 동적 장면에 대해 더 정확한 결과를 얻을 수 있습니다. 이는 Casser 등 [AAAI'19]의 확장된 버전입니다. 코드와 모델은 https://sites.google.com/corp/view/struct2depth에서 오픈 소스로 제공되고 있습니다.