Command Palette
Search for a command to run...
이 결정은 페이페이 리가 AI 여왕이라는 지위를 확립하는 데 도움이 되었습니다.

가장 고전적인 데이터 세트인 ImageNet은 컴퓨터 비전의 급속한 발전을 이끌었습니다. 그렇다면 이 데이터 세트를 만드는 과정에서 어떤 과제에 직면했을까요? 이는 딥러닝의 발전에 어떤 영향을 미쳤나요? 오늘날 머신 러닝이 매우 인기 있는 상황에서, 머신 러닝은 우리에게 어떤 영감을 줄 수 있을까요?
유명한 컴퓨터 과학자 리페이페이는 여러 차례 이렇게 말했습니다.인공지능은 세상을 바꿀 것이다. 하지만 누가 인공지능을 바꿀 것인가?
리페이페이가 업계에서 중요한 역할을 하고, 그녀가 하는 말 한마디가 업계에 큰 파장을 일으킬 수 있는 이유는 그녀가 많은 중요한 연구 성과를 냈기 때문만은 아니다. 매우 중요한 점은 그녀가 ImageNet 프로젝트의 설립을 주도했다는 점인데, 이 프로젝트는 전체 산업을 진흥하는 데 중요한 역할을 했습니다.
ImageNet: AI 개발을 바꾼 데이터 세트
컴퓨터 비전은 현재 AI 개발에 있어서 가장 좋은 방향 중 하나입니다. ImageNet은 이 분야의 고전적인 데이터 세트입니다. ImageNet이 없었다면 얼굴 인식은 오늘날 사치에 불과했을 것이라고 해도 과언이 아닙니다.
ImageNet은 Fei-Fei Li 등이 소개했습니다. CVPR 2009에서 발표한 논문에서 ImageNet의 수와 품질은 전례가 없습니다.여기에는 22,000개 카테고리를 망라하는 1,500만 개의 주석이 달린 이미지가 포함되어 있으며, 컴퓨터가 세계의 다양성을 인식하도록 가르치는 것을 목표로 합니다..

지난 10년 동안 ImageNet의 소개 논문이 출판되었습니다. 《ImageNet: 대규모 계층적 이미지 데이터베이스》영향은 엄청납니다. Google Scholar에서는 현재 논문이11914회 인용됨.
또 다른 논문에서는 ImageNet 데이터 과제와 객체 인식 분야의 연구 진행 상황을 설명합니다. 《ImageNet 대규모 시각 인식 챌린지》인용 횟수도 놀라울 정도로 늘어났다. 11056회.

ImageNet은 컴퓨터 비전 인식 분야의 벤치마크가 되었으며, 이를 통해 업계는 고품질 데이터 세트 시대로 접어들었습니다. 2010년 이후, Google, Microsoft와 같은 주요 기업과 여러 연구 기관에서 고품질 데이터 세트를 출시하기 시작했습니다.
ImageNet 역시 시간의 시험을 견뎌냈습니다. 2019년 최고 컨퍼런스 CVPR에서지난 10년 동안 컴퓨터 비전 분야에서 가장 광범위한 공헌을 한 공로로 수여됨——롱게-히긴스상은 아무런 걱정 없이 ImageNet을 공개한 논문에 수여되었습니다.
10년 전 그녀는 데이터의 중요성을 예견했습니다.
2009년으로 돌아가 보면, 업계의 주류적 사고방식은 여전히 모델에 관한 것이었고, 이론적이고 수작업으로 코딩된 머신 러닝과 수학적 방법을 사용하여 일반적인 문제를 해결하는 것에 반영되었습니다.
그러나 Fei-Fei Li는 나중에 인터뷰에서 말했듯이 매우 "다른" 일을 했습니다.연구는 장기적이고 영향력이 있어야 합니다. 단순히 현재 트렌드만 보지 마세요. 탄탄하고 영향력 있는 연구를 수행하는 데 전념해야 합니다.

2006년에 페이페이 리는 일리노이 대학교 어바나-샴페인 캠퍼스에서 컴퓨터 과학 교수로 재직했습니다. 그녀는 커뮤니티 전체가 더 나은 알고리즘 사양 전략을 연구하고 있지만, 데이터의 역할을 과소평가하고 있다는 것을 발견했습니다.
그녀는 침착하게 분석해보니 그렇게 하는 데에는 다음과 같은 단점이 있다는 것을 알게 되었습니다.사용된 데이터가 연구 목적으로 생산된 것으로 현실 세계를 반영할 수 없다면, 아무리 최고의 알고리즘이라도 의미가 없습니다.
이로 인해 그녀는 데이터 작업을 하기로 결심했습니다.
10년 전만 해도 컴퓨터는 특징을 포착한 다음 결과를 제공하는 방식으로 물체를 인식했습니다. 하지만 이 방법에는 많은 단점이 있습니다. 예를 들어, 컴퓨터로 추상화된 모델은 여러 자세와 각도에서 동일한 물체를 표현할 때 종종 실수를 합니다.
가장 큰 문제는 훈련 데이터가 단일하다는 것입니다. 컴퓨터에 한 가지 유형의 사진만 입력하면 컴퓨터는 "고정관념"에 사로잡힌 인지를 갖도록 훈련되고, 약간의 변화가 생기면 인식하지 못하게 됩니다.
페이페이 리는 이 문제가 컴퓨터 비전의 가장 큰 병목 현상이 될 것이라는 사실을 예리하게 발견했습니다.
ImagNet의 탄생: 일련의 우여곡절
이 문제를 해결하기 위해 페이페이리의 사고가 사람들에게 돌아왔습니다. 그녀의 이해에 따르면,3살짜리 아이는 눈으로 많은 사물을 보고, 많은 이미지를 수집했기 때문에 사물을 인식하고 구별할 수 있습니다.
대량의 라벨이 붙은 이미지가 컴퓨터에 '공급'되면 AI가 이미지를 인식하는 법을 배울 수도 있습니다. 이러한 아이디어에 따라 발전한다면 핵심은 데이터에 있는데, 그렇다면 포괄적인 시스템을 어떻게 구축할 수 있을까?
이때, 워드넷 이 프로젝트는 페이페이 리의 비전에서 나타났습니다.
이는 어휘 분류를 기반으로 구축된 영어 아키텍처입니다. 각 단어는 다른 단어와의 관계에 따라 표시됩니다. 이 프로젝트 전체는 세계의 수많은 사물을 나타내는 단어를 다룹니다.
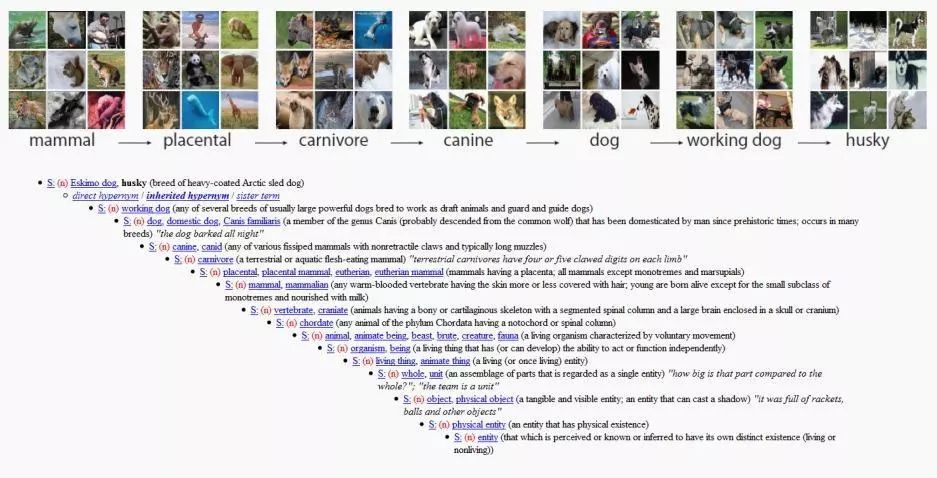
페이페이 리는 2006년에 WordNet 연구자인 크리스티안 펠바움 교수를 만난 뒤 답을 얻었습니다. 그녀는 WordNet의 접근 방식을 모방하여 각 단어에 대한 예시 그림을 제공하는 대규모 데이터 세트를 구축하고 싶었습니다.
그 다음 해, 프린스턴 대학에서 일하는 동안 Fei-Fei Li는 이미지넷 프로젝트를 시작하고, 이 거대한 작업을 완료하기 위해 팀을 구성하기 시작했습니다. 그들의 목표는 다음과 같습니다.완전하고 거대한 이미지 시스템을 구축할 만큼 충분한 주석이 달린 이미지를 수집합니다.
하지만 그 과제는 너무 방대해서 처음에는 대학생을 고용하여 온라인 이미지를 찾고, 필터링하고, 라벨을 지정하여 데이터 세트에 추가하려고 했습니다.
하지만 리페이페이는 곧 이런 방식으로 이미지를 수집하는 것이 너무 느리다는 것을 깨달았습니다. 대략적인 추정에 따르면, 어떤 사람이 멈추지 않고, 먹지도 마시지도 않고 계속해서 표시를 한다면 수십 년이 걸릴 것입니다.
우연히, 페이페이리는 또 다른 전환점을 발견했습니다. 그들은 소개를 통해 알게 되었습니다.Amazon Mechanical Turk는 온라인 크라우드소싱 방식입니다.이 플랫폼을 이용하면 고용주는 온라인으로 많은 사람을 고용해 간단한 채점을 완료할 수 있습니다.
결국 Amazon의 크라우드소싱 서비스를 활용함으로써,167개국 49,000명이 2년 반 동안이 거대한 프로젝트를 완료할 시간이 왔습니다.
지원 부족, 자금 부족, 인력 부족 등 여러 어려움에 직면했음에도 불구하고 ImageNet은 끈기로 탄생했습니다.
ImageNet은 새로운 것이어서 처음에는 심각하게 받아들여지지 않았습니다. 2009년 CVPR 컨퍼런스에서 ImageNet 논문은 연구 포스터로만 사용되어 눈에 띄지 않는 곳에 게시되었습니다.
이런 상황은 ImageNet에서 파생된 챌린지 대회에서 완전히 역전되었습니다.
ILSVRC 경연대회: ImageNet을 성공으로 이끄세요
ImageNet이 출시된 지 1년 후, Fei-Fei Li와 다른 사람들의 노력 덕분에 ImageNet 대규모 시각 인식 챌린지(ILSVRC)가 시작되었습니다..
ILSVRC는 ImageNet 대회로도 알려져 있으며, 2010년부터 매년 개최되고 있습니다. 이 대회에서 참가자들은 ImageNet 데이터 세트를 벤치마크로 사용하여 대규모 객체 감지 및 이미지 분류 분야의 성과를 평가합니다.
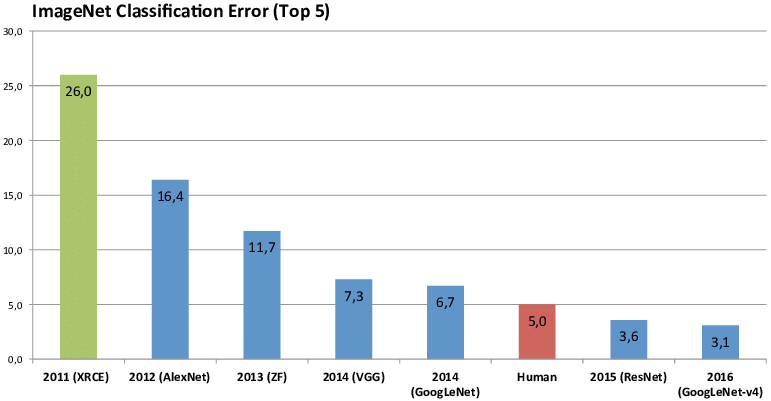
곧 이 행사는 알고리즘 경연대회의 올림픽이 되었습니다. 주요 기관들은 이를 자체 알고리즘의 장단점을 테스트하기 위한 훈련장으로 활용했습니다. 갑자기 다양한 혁신과 성과가 나타났습니다.
하지만 ImageNet 대회의 가장 큰 장점은 신경망과 딥러닝의 발전을 촉진했다는 점입니다.
힌튼은 그의 팀을 이끌고 2012년 ImageNet 대회에 참가했습니다. 그해 힌튼 팀이 사용한 딥러닝 방식은 이미지 인식 경쟁에서 다른 모든 방식보다 훨씬 앞서 있었습니다. 그들이 제출한 딥 컨볼루션 신경망 구조 모델 Alexnet은 2위보다 41% 높은 10.8 %로 성능을 향상시켰습니다.

이것의 개념은 무엇입니까? 당시 1%의 성능 향상은 '주요 기여'로 여겨졌고, 10년 이상 잠복해 있던 방법인 신경망이 실제로 10퍼센트 포인트를 넘어서면서 순식간에 대지진이 일어났습니다.

이전에는 이렇게 큰 규모의 데이터로 딥 신경망을 훈련시킨 적이 없었습니다. AlexNet에 이어, ImagNet의 도움으로 딥 신경망의 뛰어난 성능이 완전히 입증되었습니다.
2년 후, ImageNet 챌린지에 참여한 모든 팀은 딥러닝을 활용했습니다.
경쟁은 끝났지만 연구는 계속됩니다
8년 후인 2017년에 ImagNet Challenge는 목표를 달성했습니다. 컴퓨터의 인식 오류율이 사람보다 낮았습니다. 성숙한 이미지 식별은 더 이상 도전이 되지 않았고, 새로운 여정은 이미지 이해를 지향했기 때문에 경쟁은 성공적으로 마무리되었습니다.
ImageNet과 Challenge의 주도로컴퓨터의 사물 분류 정확도는 71.8%에서 97.3%로 증가했습니다.인간의 수준을 훨씬 뛰어넘었습니다.
ImageNet을 구축하는 과정을 돌이켜보면, 당시에는 주류가 되는 과제는 아니었습니다. 그러나 이러한 "역추세" 연구는 페이페이 리 등의 끈질긴 노력으로 인해 결국 AI의 역사적 진보를 촉진했습니다. 동시에, 페이페이 리(Fei-Fei Li)는 ImageNet 덕분에 컴퓨터 비전 분야에 가장 큰 족적을 남겼습니다.
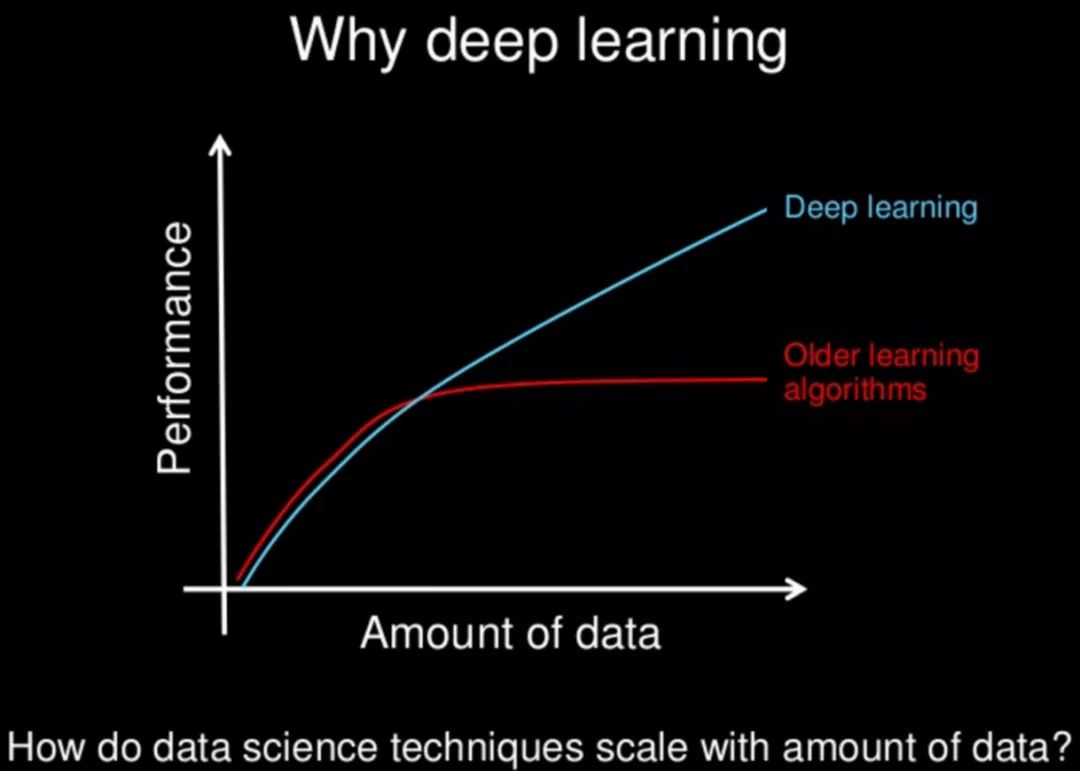
데이터를 머신 러닝의 "로켓 연료"에 비유한다면, ImageNet은 의심할 여지 없이 첫 번째이자 가장 중요한 연료통입니다.
Fei-Fei Li의 팀이 말했듯이,"가장 인기 있는 일을 할 필요는 없지만, 자신이 믿는 일을 하고, 그것이 영향을 미칠 수 있는 일을 해야 합니다."

참고문헌:
3. CVPR 2019에 9,000명의 참석자가 모였습니다. 최우수 논문 발표; ImageNet, 10년 만에 영예
-- 위에--