Command Palette
Search for a command to run...
학교로 돌아가지 마세요. 선생님들의 방법이 더욱 교묘해졌습니다.

Super Neuro에서
오늘은 국제 교사의 날입니다. 제 친구들은 선생님들을 위한 축복으로 넘쳐났습니다. 모두가 선생님들에게 경의를 표하고 캠퍼스를 그리워합니다. 하지만 오늘날 중학생들의 "절박한" 생활 환경을 알았다면, 어떻게 생각하실지 궁금합니다.
최근 항저우 11중학교에서는 학생들의 표정과 움직임을 포착하기 위해 교실에 여러 대의 카메라를 설치하는 스마트 아이 시스템을 시범적으로 도입했습니다. 얼굴 인식 기술을 활용하여 학생들의 6가지 수업 행동 유형과 7가지 수업 표현 유형을 수집합니다.

큰 반향을 일으킨 교육 시스템의 이름은 '스마트 교실 행동 관리 시스템', 줄여서 '스마트 아이'입니다.
학생들의 모습을 정확하게 포착할 수 있다고 합니다.읽고, 일어서고, 손을 들고, 테이블에 누워서 듣고, 쓰세요그리고 학생들의 얼굴 표정과 결합된 다른 6가지 행동을 분석합니다.중립, 행복, 슬픔, 분노, 두려움, 혐오감, 놀라움 7가지 감정.
똑똑한 눈 - 반에서 가장 이야기하기를 좋아하는 학생
시스템은 이러한 정보를 간단히 처리한 후, 학생들의 말을 주의 깊게 듣는 경우 A, 누워서 잠을 자는 경우 B, 질문에 답하는 경우 C와 같은 일련의 코드를 생성하고 이를 사용하여 학생의 상태를 판단합니다. 수업 시간에 주의 깊게 듣는 것과 같은 좋은 상태는 점수를 얻고, 수업 시간에 잠을 자는 것과 같은 나쁜 상태는 점수를 잃습니다.
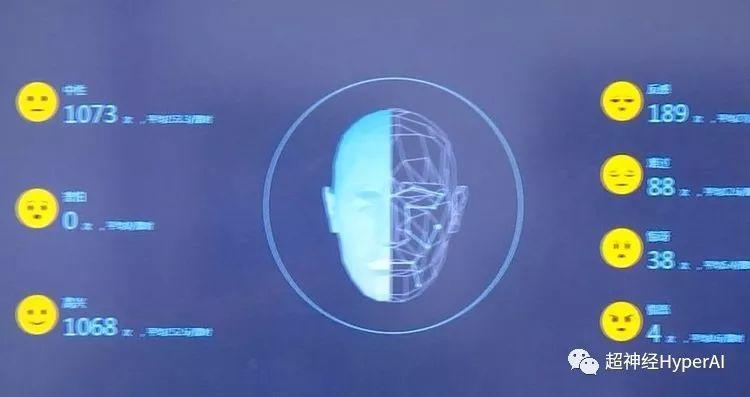
이러한 데이터는 수업이 끝난 후 교사에게 직접 전달되어, 교사가 수업 효과와 학생들의 반응을 파악하는 데 도움이 됩니다.
교사는 이를 활용해 자신의 교육 방법을 최적화할 수 있고, 학교는 이를 활용해 교사의 교육 품질을 평가할 수 있습니다. 하지만 카메라가 있기 때문에 학생들이 약간 불편함을 느끼는 것은 당연한 일이며, 이는 이해할 만한 일입니다.
국민들이 우려하는 개인정보보호 및 데이터 유출 문제에 대해서는, 이 시스템에서 생성되는 데이터 정보는 오직 교사와 학교 선배들만 볼 수 있고, 다른 교사나 외부인은 볼 권리가 없다고 합니다.

(위의 빨간색 원은 얼굴인식 장치이고, 아래 빨간색 원은 정보를 수집하는 카메라입니다)
하드웨어 부분은 회전식 카메라와 얼굴 인식 장치로 구성되어 있습니다. 각 교실에는 약 3대가 있으며, 30초마다 스캔합니다.
모든 카메라는 행동 정보를 수집하는 데에만 사용되며 감시나 녹화 목적으로는 사용되지 않습니다. 개인정보 보호나 데이터 유출 문제는 발생하지 않습니다.
11중학교는 올해 모든 교실에 이 시스템을 설치할 계획인데, 이를 통해 수업 중 학생들의 감정을 모니터링할 뿐만 아니라 얼굴 인식을 통해 출석도 기록하게 됩니다. 하지만 이 시스템은 아직 초기 단계에 있으며 감정 인식의 정확도를 높이기 위해서는 더 많은 데이터를 학습해야 합니다.
앞으로는 학교 내 모든 카드 결제를 얼굴 스캔으로 대체해, 전국 최초로 카드가 필요 없는 캠퍼스를 만들 계획입니다. 이게 바로 옆집에 사는 알리바바의 잭마에게서 영감을 받은 건지 궁금하네요.
교실 모니터링은 좋은 일일 수 있습니다
항저우 11중학교는 캠퍼스에 첨단 기술을 도입하는 첫 번째 학교가 되어야 하지만, 수업의 질을 향상시키는 데 사용되는 감정 인식을 실시간 모니터링 도구로 사용하지 않기를 바랍니다. 결국, 캠퍼스가 공공장소라 할지라도 모든 학생은 일정한 범위 내에서 개인의 사생활을 보호받아야 합니다.
결국, 스마트아이 시스템이 주목을 받고 논의되는 이유는 모든 사람이 학생들이 감시받고 있다고 느끼기 때문입니다. 하지만 반대로 생각해 보세요. 휘얀은 데이터가 저장되거나 공개되지 않는다고 주장하는데, 이는 실제로 전통적인 의미에서 교사의 눈과 유사합니다.
그러므로 가장 중요한 것은 "이용자 계약"입니다. 현재 학교에서 명확히 해야 할 것은 휘얀 영상 콘텐츠의 사용 및 권한 범위입니다.
감정 인식의 기술적 구현
기계가 인간의 감정을 인식할 수 있다는 것은 현실이 되었지만, 방대한 학습 데이터와 모델 구축의 복잡성으로 인해 많은 연구자들이 어려움을 겪고 있습니다.
이제 5개의 거대 기업이 가벼운 감정 인식 모델을 내놓았는데, 이 모델은 훈련 세트의 분류를 자동으로 완료할 수 있을 뿐만 아니라 모델 구축 프로세스를 간소화하여 감정 인식 모델을 만드는 데 필요한 한계를 크게 낮춰줍니다.
감정 인식은 이미지 및 얼굴 인식과 같은 기술을 기반으로 하며, 사람의 신체적 행동(얼굴 표정 인식, 음성, 자세 등)을 분석하여 인간의 감정 상태를 파악합니다.

인간의 얼굴 감정의 다양성
감정 인식을 위한 신경망은 의료 및 고객 분석 등의 분야에서 널리 사용되고 있지만, 대부분의 감정 인식 모델은 여전히 인간의 감정을 깊이 이해하지 못하고 있으며, 이러한 모델을 구축하는 데는 많은 비용이 들고 개발도 어렵습니다.
가벼운 감정 인식 모델을 살펴보겠습니다.
이 문제를 해결하기 위해 프랑스의 Orange Labs와 Caen Normandy 대학(UNICAEN)의 5명의 엔지니어가 공동으로 논문을 발표했습니다. "시청각적 감정 학습에 대한 오컴의 면도날 관점".
그들은 논문에서 오디오-비주얼 감정 인식(즉, 오디오와 비디오를 활용한 감정 인식)을 기반으로 한 가벼운 딥 신경망 모델을 제안했습니다. 이 모델은 학습이 쉽고, 학습 세트를 자동으로 분류할 수 있으며, 정확도가 높고, 학습 세트가 작아도 좋은 성능을 낼 수 있다고 합니다.
본 논문에서 제안하는 모델은 다음과 같다.오컴의 면도날AFEW 데이터 세트를 기반으로 학습되었습니다. 오디오와 비디오는 여러 처리 계층(특징 추출, 분석 등에 사용)을 통해 동시에 전처리 및 특징 분석을 거치고, 최종적으로 두 가지를 결합하여 감정 인식 결과를 출력합니다.
AFEW는 "실제 상황에서의 행동적 표정"을 뜻합니다. 감정 인식 모델 학습과 EmotiW 시리즈의 감정 인식 챌린지를 위한 테스트 데이터를 제공하는 표현 인식 데이터 모음입니다.
모든 데이터는 영화와 TV 드라마에서 편집된 얼굴 표정이 담긴 비디오 클립에서 나온 것입니다. 여기에는 "행복, 놀람, 혐오, 분노, 두려움, 슬픔"의 6가지 기본 표정과 중립적 표정이 포함됩니다.
AFEW에서 모델이 훈련 데이터를 더 잘 인식하도록 하기 위해 5명의 R&D 인력이 모델에 몇 가지 혁신을 도입했습니다.
1) 전이 학습과 저차원 공간 임베딩을 통해 특징 차원을 줄이고 모델 분석 프로세스를 단순화합니다.
2) 훈련 세트의 크기를 줄이기 위해 각 프레임에 점수를 매겨 샘플링합니다.
3) 간단한 프레임 선택 메커니즘을 사용하여 이미지 시퀀스에 가중치를 부여합니다.
4) 예측 단계에서는 다양한 형태의 기능 융합이 수행됩니다. 즉, 비디오와 오디오를 별도로 처리한 후 융합합니다.
이러한 일련의 혁신은 데이터 세트의 특성을 나타내는 매개변수의 수를 크게 줄이고, 모델 학습 과정을 간소화하며, 감정 인식의 정확도를 향상시킵니다. 2018년 감정 인식 경연 대회 EmotiW(Emotion Recognition In The Wild Challenge)에서 이 모델은 60.64%의 인식 정확도를 달성하여 4위를 차지했습니다.
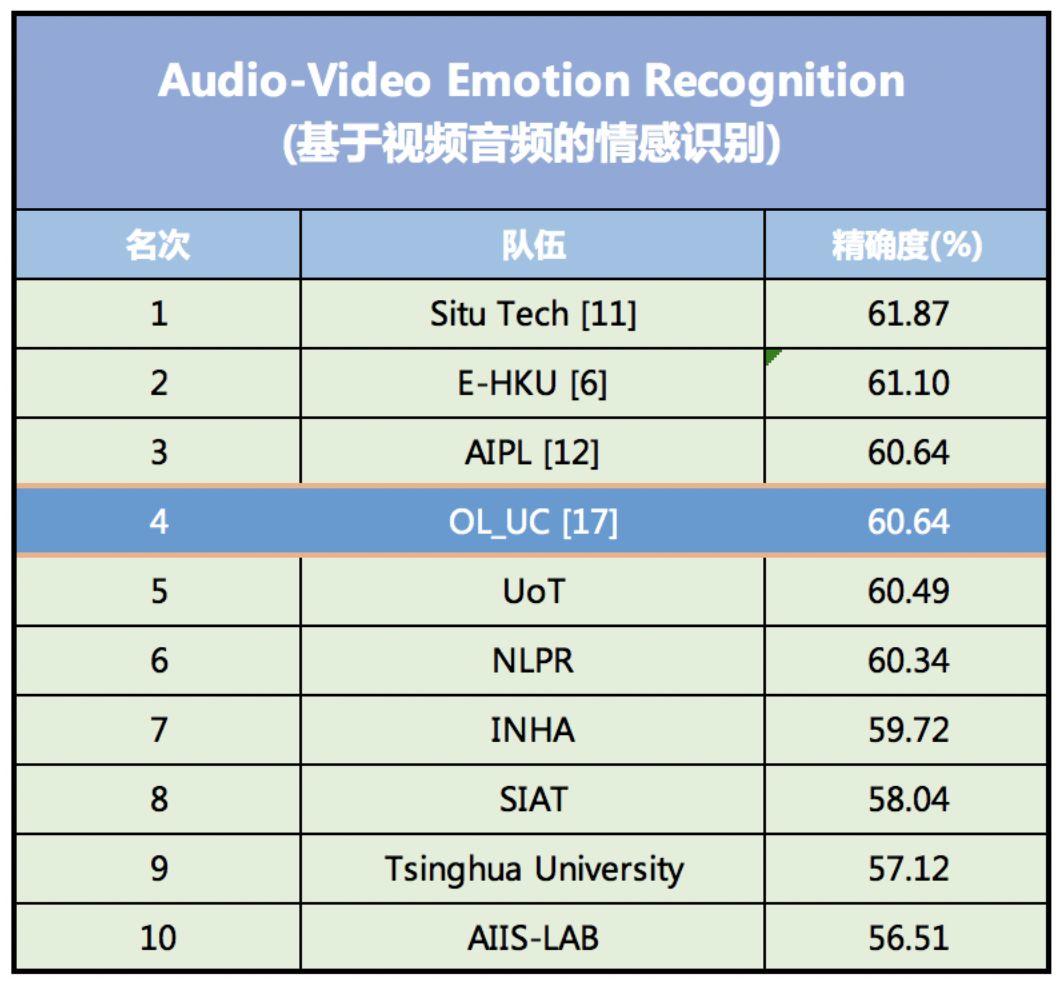
이 모델은 2018년 EmotiW 시청각 감정 인식 모델 정확도 순위에서 4위를 차지했습니다.
국내 AI 금융기술 기업 SEEK TRUTH가 개발한 감정인식모델이 1위를 차지했으며, 정확도는 61.87%입니다. 2위를 차지한 모델은 미국 캘리포니아의 AI 스타트업 DeepAI가 개발한 것으로, 정확도는 61.10%입니다.
모델은 자동으로 훈련 세트에 레이블을 추가할 수 있습니다.
다른 감정 인식 모델과 비교했을 때, 이 모델의 가장 큰 장점은 구축과 훈련이 쉽다는 것입니다. 이를 통해 컴퓨터가 신체 언어를 포함한 인간의 미세 표정을 더 쉽게 인식할 수 있습니다.
현재 대부분의 감정 인식 모델은 영화와 TV 드라마 속 캐릭터의 얼굴 표정을 통해 훈련됩니다. 첫째, 취득비용이 저렴하고, 둘째, 표현력이 풍부합니다.

하지만 이러한 데이터를 훈련 세트에 입력하면 분류되지 않습니다(즉, 각 비디오에 감정 레이블이 추가됩니다). 따라서 훈련 전에 수동으로 또는 다른 방법을 통해 분류해야 하는데, 이는 운영이 어렵고 훈련 세트가 왜곡되기 쉽습니다.
프레데릭 쥐리(Frédéric Jurie) 등이 개발한 시청각 감정 인식 모델은 모델에서 사용할 수 있는 심층 신경망을 통해 훈련 세트의 표정을 자동으로 분류할 수 있습니다.
이런 방식으로 모델 학습의 어려움은 줄어들고 인식 정확도는 향상됩니다.
또한 이 모델은 가벼운 신경망 모델도 좋은 결과를 얻을 수 있고, 훈련하기도 쉽다는 것을 보여주는데, 이는 오늘날 점점 더 복잡해지는 신경망 모델과 극명한 대조를 이룹니다.
앞으로는 비디오가 아닌 형식의 데이터를 더 잘 통합하고 분류가 적거나 전혀 없는 데이터를 인식하는 방법을 추가로 연구할 것입니다.