Command Palette
Search for a command to run...
메이투안의 오픈소스 비디오 생성 모델인 LongCat-Video는 텍스트 기반 비디오 생성, 이미지 기반 비디오 생성, 비디오 연속 기능을 결합하여 최고 수준의 오픈소스 및 폐쇄소스 모델과 경쟁합니다.

월드 모델은 복잡한 현실 환경을 이해하고, 시뮬레이션하고, 예측하는 것을 목표로 하며, 현실 세계에서 인공지능을 효과적으로 적용하는 데 중요한 기반이 됩니다. 이러한 프레임워크 내에서 비디오 생성 모델은 생성 과정을 통해 기하학적, 의미적, 물리적 요소를 포함한 다양한 지식 형태를 점진적으로 압축하고 학습합니다.따라서 이는 세계 모델을 구축하는 핵심 경로로 간주되며, 궁극적으로 실제 물리적 세계의 역학에 대한 효과적인 시뮬레이션과 예측을 달성할 것으로 기대됩니다.영상 생성 분야에서는 효율적인 긴 영상 생성 기능을 확보하는 것이 특히 중요합니다.
이를 바탕으로,메이투안은 최신 비디오 생성 모델인 LongCat-Video를 오픈 소스로 공개했습니다. 이 모델은 텍스트-비디오, 이미지-비디오, 비디오 연속 등 통합 아키텍처를 통해 다양한 비디오 생성 작업을 처리하는 것을 목표로 합니다.연구팀은 일반적인 비디오 생성 작업에서 탁월한 성능을 보이는 LongCat-Video를 진정한 "세계 모델"을 구축하는 데 한 걸음 더 다가간 견고한 도구로 여겼습니다.
LongCat-Video의 주요 기능은 다음과 같습니다.
* 다양한 작업을 위한 통합 아키텍처. LongCat-Video는 텍스트 기반 비디오, 이미지 기반 비디오, 비디오 연속 작업을 단일 비디오 생성 프레임워크로 통합하여 조건 프레임 수를 기준으로 이를 구분합니다.
* 긴 영상 생성 기능. LongCat-Video는 비디오 연속 작업을 기반으로 사전 학습되어 몇 분 길이의 비디오를 생성할 수 있으며, 생성 과정에서 색상 왜곡이나 기타 형태의 이미지 품질 저하를 효과적으로 방지합니다.
* 효율적인 추론. LongCat-Video는 "대략적으로 정밀하게" 전략을 채택하여 단 몇 분 만에 720p, 30fps 비디오를 생성하여 비디오 생성 정확도와 효율성을 효과적으로 개선합니다.
* 다중 보상 강화 학습 프레임워크(RLHF)의 강력한 성능. LongCat-Video는 GRPO(그룹 상대 정책 최적화)를 채택하여 여러 보상을 사용하여 모델 성능을 더욱 향상시키고, 주요 오픈 소스 비디오 생성 모델 및 최신 상용 솔루션과 비교할 수 있는 성능을 달성합니다.
내부 벤치마크 성능 평가에 따르면, LongCat-Video는 텍스처 비디오 작업에서 좋은 성능을 보입니다.시각적 품질과 동작 품질 모두에서 매우 뛰어난 성능을 보이며, 최상위 모델인 Wan2.2와 거의 동등한 점수를 받았습니다.이 모델은 텍스트 정렬과 전반적인 품질 측면에서도 견고한 결과를 달성하여 사용자에게 여러 측면에서 일관되고 고품질의 경험을 제공했습니다.
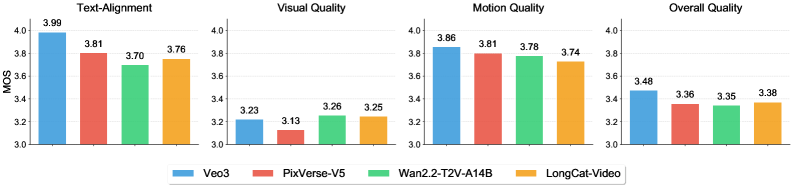
이미지-비디오 변환 작업에서 LongCat-Video는 시각적 품질 면에서 두드러지며, Wan2.2와 같은 다른 모델들보다 우수한 성능을 보이고 고품질 이미지 생성에 있어 상당한 이점을 보여줍니다. 그러나 이미지 정렬 및 전반적인 품질과 같은 영역에서는 여전히 개선의 여지가 있습니다.

최근 Cloudflare에서 서비스 중단이 발생하여 X, ChatGPT, Canva 등 다양한 인터넷 애플리케이션의 연결에 문제가 발생했습니다. LongCat-Video에서 서비스 중단 시 어떻게 대응했는지 살펴보겠습니다. 👇
현재 HyperAI 웹사이트의 "튜토리얼" 섹션에서 "롱캣-비디오: 메이투안의 오픈소스 AI 비디오 생성 모델"을 확인하실 수 있습니다. 아래 링크를 클릭하시면 원클릭 배포 튜토리얼을 경험하실 수 있습니다. ⬇️
튜토리얼 링크:
데모 실행
1. hyper.ai 홈페이지에 접속한 후, "LongCat-Video: Meituan의 오픈소스 AI 비디오 생성 모델"을 선택하거나, "튜토리얼" 페이지로 이동하여 선택한 후 "이 튜토리얼을 온라인으로 실행"을 클릭하세요.


2. 페이지가 리디렉션된 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
참고: 페이지 오른쪽 상단에서 언어를 변경할 수 있습니다. 현재 중국어와 영어로만 제공됩니다. 이 튜토리얼에서는 영어로 된 단계를 안내합니다.

3. "NVIDIA RTX PRO 6000 Blackwell" 및 "PyTorch" 이미지를 선택하고 필요에 따라 "Pay As You Go" 또는 "Daily Plan/Weekly Plan/Monthly Plan"을 선택한 다음 "Continue job execution"을 클릭합니다.


4. 리소스 할당을 기다리세요. 첫 번째 복제에는 약 3분이 소요됩니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆의 이동 화살표를 클릭하여 데모 페이지로 이동하세요.

효과 시연
데모 인터페이스에 접속하면 이미지-비디오 변환, 텍스트-비디오 변환, 긴 비디오 변환, 비디오 연속 변환 등 네 가지 예시 중에서 선택하여 테스트할 수 있습니다. 이 글에서는 이미지-비디오 변환을 예시로 선택했습니다.
샘플 이미지를 업로드한 후 "프롬프트"를 입력하세요. "고급 옵션"에서는 부정 프롬프트, 해상도, 생성 과정의 무작위성 시작점 등 매개변수를 추가로 설정하여 더욱 이상적인 생성 효과를 얻을 수 있습니다.


최근 Cloudflare에서 서비스 중단이 발생하여 X, ChatGPT, Canva 등 다양한 인터넷 애플리케이션의 연결에 장애가 발생했습니다. LongCat-Video에서 서비스 중단에 대한 사용자들의 반응을 시뮬레이션한 영상을 확인해 보세요. 👇
위는 HyperAI가 이번에 추천하는 튜토리얼입니다. 누구나 와서 체험해 보세요!
튜토리얼 링크: