Command Palette
Search for a command to run...
온라인 튜토리얼 | Deepseek-OCR, 최소한의 시각적 토큰으로 엔드투엔드 모델에서 최첨단 성능 달성

잘 알려진 바와 같이, 대규모 언어 모델이 수천, 수만, 또는 그 이상의 텍스트를 처리할 때 계산량이 급격히 증가하는 경우가 많으며, 심지어 컴퓨팅 파워를 "돈을 태우는" 게임으로 이어질 수도 있습니다. 이는 또한 고밀도 텍스트 정보 시나리오를 처리할 때 LLM의 효율성 한계를 제한합니다.
업계가 연산 효율을 최적화하는 방법을 끊임없이 모색하는 가운데, Deepseek-OCR은 새로운 관점을 제시합니다. 우리가 텍스트를 "보는" 것과 동일한 방식으로 텍스트를 효율적으로 "읽을" 수 있을까요? 이 대담한 가설을 바탕으로 연구진은 문서 텍스트가 포함된 단일 이미지가 동일한 숫자 텍스트보다 훨씬 적은 기호를 사용하여 풍부한 정보를 표현할 수 있다는 것을 발견했습니다. 즉, 텍스트 정보를 이미지 형태로 대형 모델에 제공하여 이해하고 기억하도록 하면 전반적인 효율성을 효과적으로 향상시킬 수 있습니다. 이는 더 이상 단순한 이미지 처리가 아닙니다.그 대신, 텍스트 정보를 위한 효과적인 압축 매체로 시각적 방식을 사용하는 영리한 "광학 압축"을 통해 기존 텍스트 표현 방식보다 훨씬 높은 압축률을 달성합니다.
구체적으로, DeepSeek-OCR은 DeepEncoder와 DeepSeek3B-MoE-A570M의 두 가지 구성 요소로 구성됩니다. 인코더(DeepEncoder)는 이미지 특징 추출, 단어 분할, 시각적 표현 압축을 담당하고, 디코더(DeepSeek3B-MoE-A570M)는 이미지 태그와 프롬프트를 기반으로 원하는 결과를 생성하는 데 사용됩니다.핵심 엔진인 DeepEncoder는 높은 압축률을 달성하는 동시에 고화질 입력에서 낮은 활성화 상태를 유지하도록 설계되어 시각적 토큰의 수가 최적화되고 관리가 용이해집니다.실험 결과, 텍스트 토큰 수가 시각적 토큰 수의 10배 미만일 때(즉, 압축률 < 10배), 모델은 971 TP3T의 디코딩(OCR) 정확도를 달성할 수 있는 것으로 나타났습니다. 압축률이 20배일 때에도 OCR 정확도는 약 601 TP3T로 유지되었습니다.
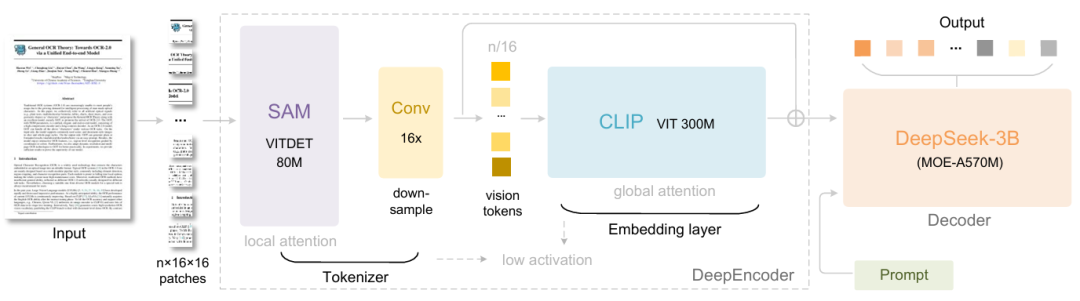
DeepSeek-OCR의 출시는 OCR 작업의 진전일 뿐만 아니라, 장문맥 압축 및 LLM에서의 메모리 망각 메커니즘 탐색과 같은 최첨단 연구 분야에서 엄청난 잠재력을 보여줍니다.
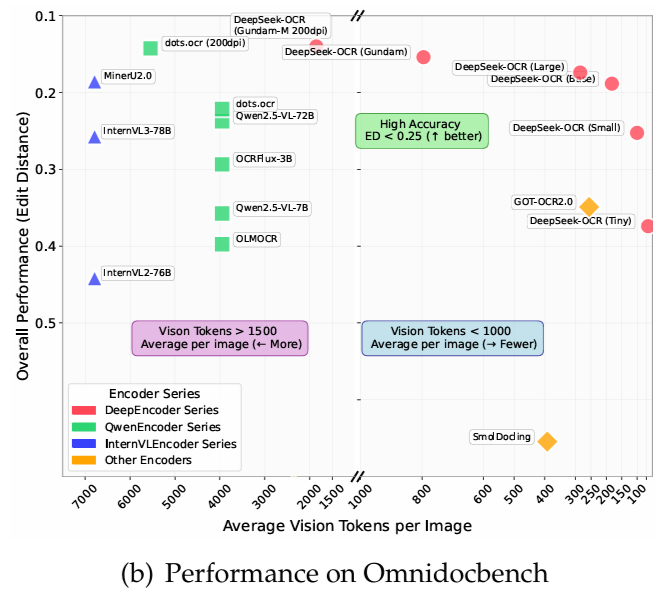
OmniDocBench에서단 100개의 시각적 토큰을 사용하여 GOT-OCR2.0(페이지당 256개의 토큰)을 능가합니다.또한, 800개 미만의 시각적 토큰을 사용할 때 MinerU2.0(페이지당 평균 6,000개 이상의 토큰)보다 우수한 성능을 보입니다. 운영 환경에서 DeepSeek-OCR은 단일 A100-40G를 사용하여 하루에 20만 페이지 이상의 LLM/VLM 학습 데이터를 생성할 수 있습니다.
"DeepSeek-OCR: 시각적 압축으로 기존 문자 인식을 대체하다"를 HyperAI 웹사이트(hyper.ai)의 "튜토리얼" 섹션에서 지금 바로 만나보세요. 클릭 한 번으로 바로 설치하고 체험해 보세요!
* 튜토리얼 링크:
* 관련 논문 보기:
https://hyper.ai/papers/DeepSeek_OCR
데모 실행
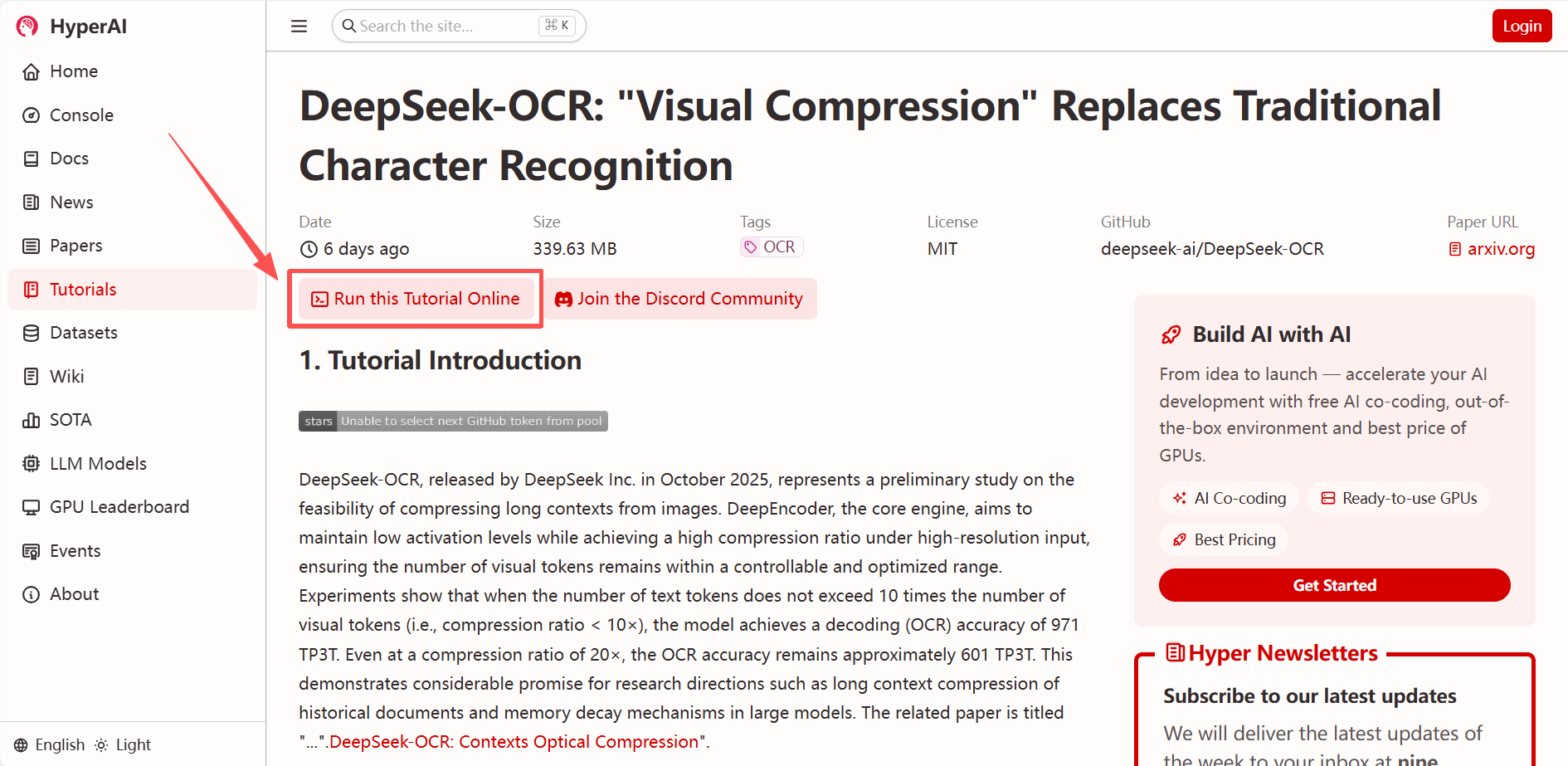
1. hyper.ai 홈페이지에 접속한 후, "DeepSeek-OCR: 기존 문자 인식 대신 시각적 압축"을 선택하거나, "튜토리얼" 페이지로 이동하여 "이 튜토리얼을 온라인으로 실행"을 선택하세요.
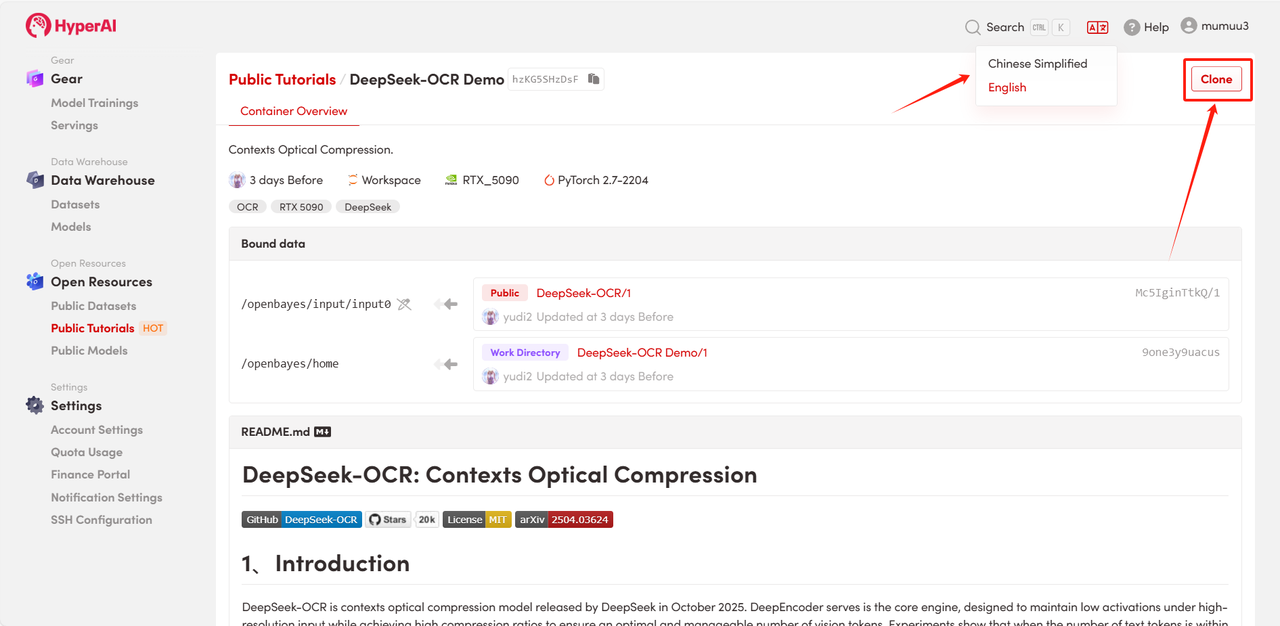
2. 페이지가 리디렉션된 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
참고: 페이지 오른쪽 상단에서 언어를 변경할 수 있습니다. 현재 중국어와 영어로만 제공됩니다. 이 튜토리얼에서는 영어로 된 단계를 안내합니다.
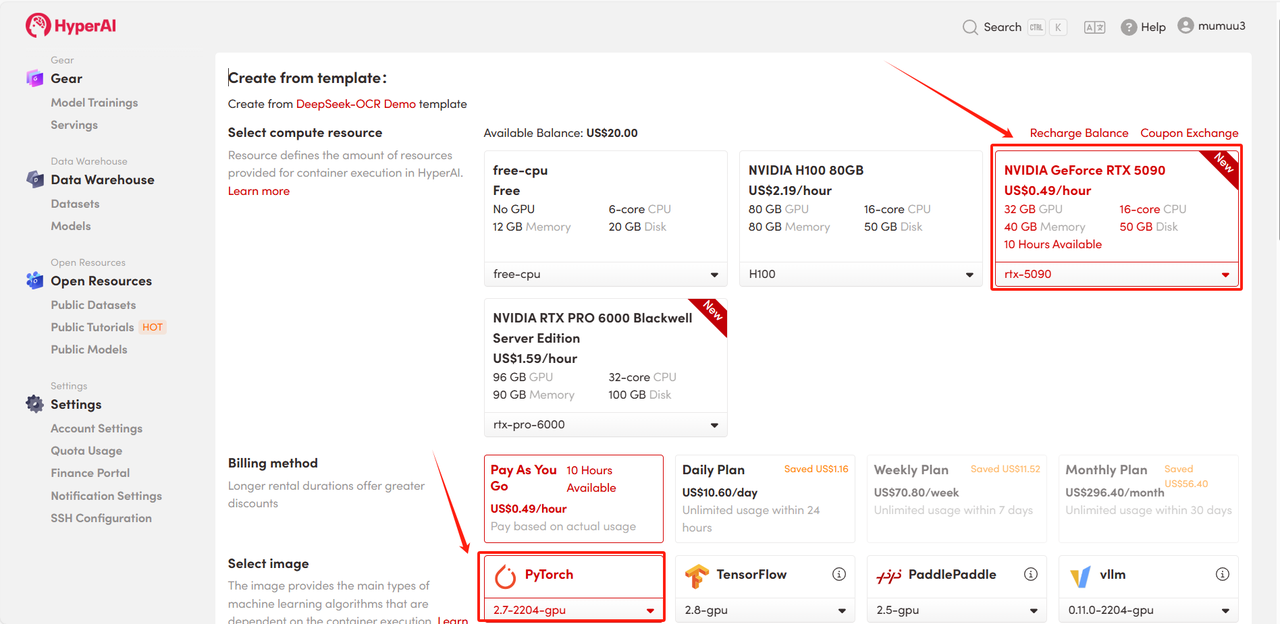
3. "NVIDIA GeForce RTX 5090" 및 "PyTorch" 이미지를 선택하고 필요에 따라 "Pay As You Go" 또는 "Daily Plan/Weekly Plan/Monthly Plan"을 선택한 다음 "Continue job execution"을 클릭합니다.
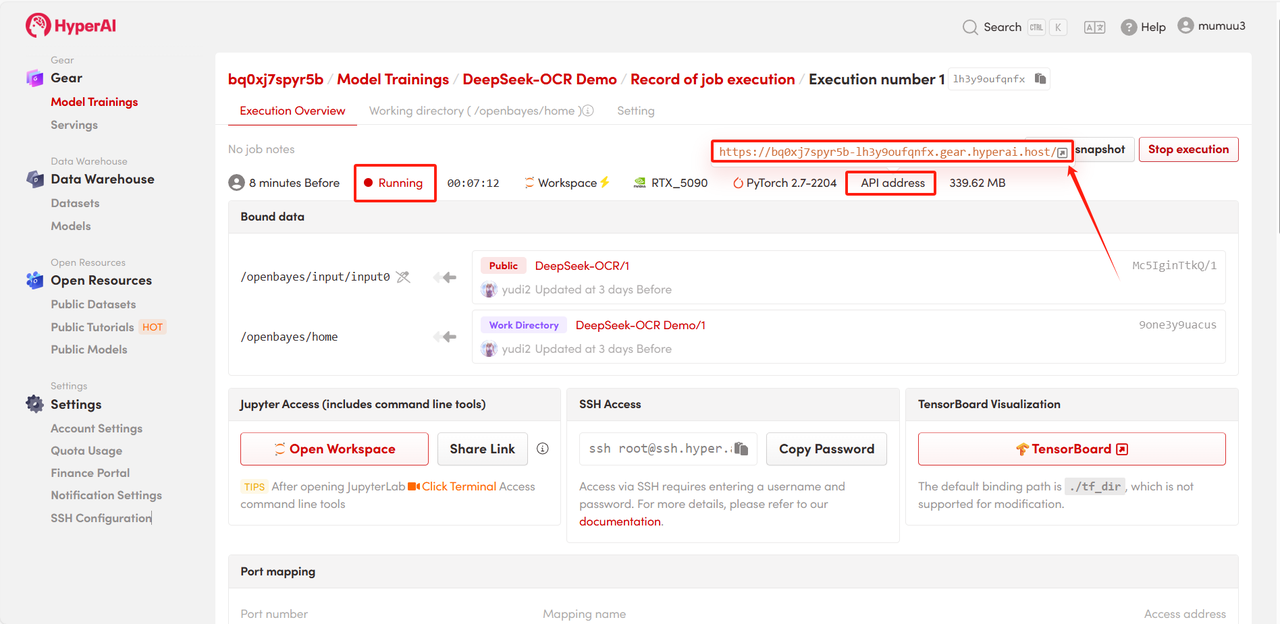
4. 리소스 할당을 기다리세요. 첫 번째 복제에는 약 3분이 소요됩니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆의 이동 화살표를 클릭하여 데모 페이지로 이동하세요.
효과 시연
데모 실행 페이지에 들어간 후, 구문 분석할 문서 이미지를 업로드하고 "텍스트 추출"을 클릭하여 구문 분석을 시작합니다.
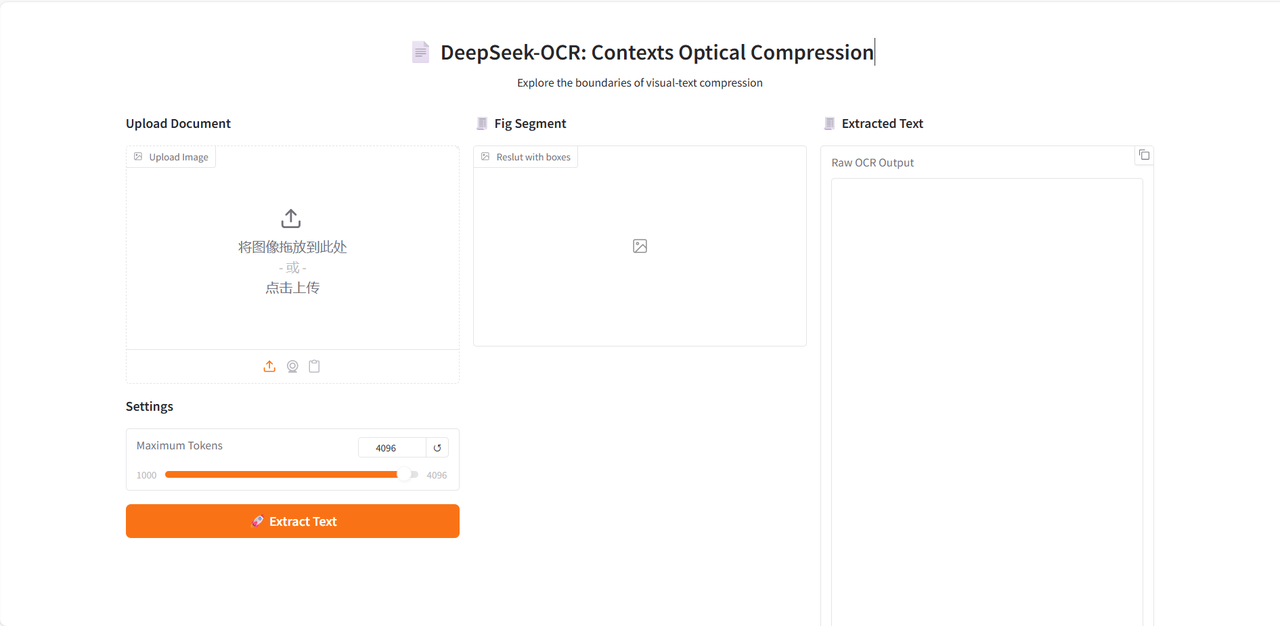
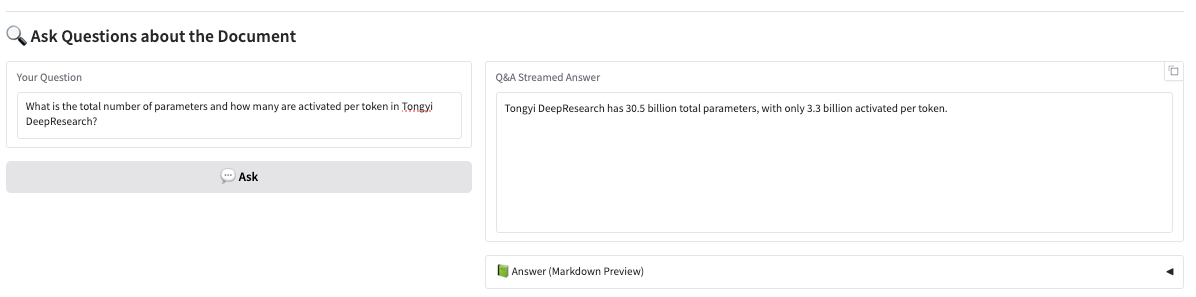
이 모델은 먼저 이미지의 텍스트나 차트 모듈을 나눈 다음, 텍스트를 마크다운 형식으로 출력합니다.

위는 HyperAI가 이번에 추천하는 튜토리얼입니다. 누구나 와서 체험해 보세요!
* 튜토리얼 링크: