Command Palette
Search for a command to run...
온라인 튜토리얼 | 기기 기반 TTS를 위한 새로운 기술! NeuTTS-Air, 0.5B 모델 기반 3초 오디오 복제 기술 달성

기존의 고품질 TTS(텍스트 음성 변환) 모델은 오랫동안 몇 가지 핵심적인 과제에 직면해 왔습니다. 컴퓨팅 리소스와 클라우드 서비스에 대한 높은 요구 사항으로 인해 소규모 기업과 개인 개발자가 감당하기 어려운 높은 비용이 발생합니다. 또한, 이러한 모델의 대부분은 학습에 수십 분 또는 심지어 몇 시간 분량의 오디오 데이터를 필요로 합니다. 이러한 구축 및 운영 요건은 모델 사용의 진입 장벽을 높일 뿐만 아니라, 개인정보 보호가 중요한 상황에서 TTS의 적용을 제한합니다.
최신 오픈소스 엔드투엔드 음성 합성 모델인 NeuTTS-Air는 TTS 사용에 따르는 과제에 대한 완전히 새로운 솔루션을 제공합니다.초현실적인 음성 합성 및 실시간 음성 복제를 지원하는 세계 최초의 로컬 실행 TTS 언어 모델로서,0.5B Qwen LLM과 NeuCodec 오디오 코덱을 기반으로 하는 NeuTTS-Air는 엣지 배포와 실시간 음성 복제에서 뛰어난 퓨샷 학습 기능을 보여줄 뿐만 아니라, 내장된 에이전트와 스타일 전송과 같은 새로운 시나리오로 일반화할 수 있으며, 3초 오디오 복제를 지원하고 자연스러운 대화 콘텐츠를 생성합니다.
실험 평가 결과NeuTTS Air는 오픈 소스 모델 중 최첨단(SOTA) 성능을 달성했습니다.특히 초현실적 합성 및 실시간 추론 벤치마크에서 두드러집니다. 사후 학습은 GGML/ONNX 지원과 워터마킹 메커니즘을 도입하여 엣지 사이드 TTS 및 전력 소비 최적화 평가 분야에서 오픈 소스 분야를 선도하며, 일부 시나리오에서는 폐쇄형 소스 모델과 유사한 성능을 보입니다. 더욱 주목할 만한 것은 이 경량 모델입니다.추론은 CPU에서 수행될 수 있습니다.휴대폰, 노트북, Raspberry Pi 등의 기기에 적합합니다.
"CPU에 NeuTTS-Air 음성 복제 모델 배포"에 대한 튜토리얼 링크:
NeuTTS-Air의 출시는 특히 온디바이스 배포 및 실시간 음성 복제 분야에서 효율적이고 지연 시간이 짧으며 사실적인 TTS에 대한 업계의 수요가 급증하는 시기에 이루어졌습니다. NeuTTS-Air는 개발자들이 모바일 및 엣지 디바이스에 고품질 TTS를 배포하는 데 있어 장벽을 낮추어, "초현실적인" 음성이 더 이상 대규모 클라우드 모델의 전유물이 되지 않도록 합니다.
"NeuTTS-Air: 가볍고 효율적인 음성 복제 모델"은 현재 HyperAI 웹사이트(hyper.ai)의 "튜토리얼" 섹션에서 이용 가능합니다.원클릭 배포를 경험해 보세요!
튜토리얼 링크:
데모 실행
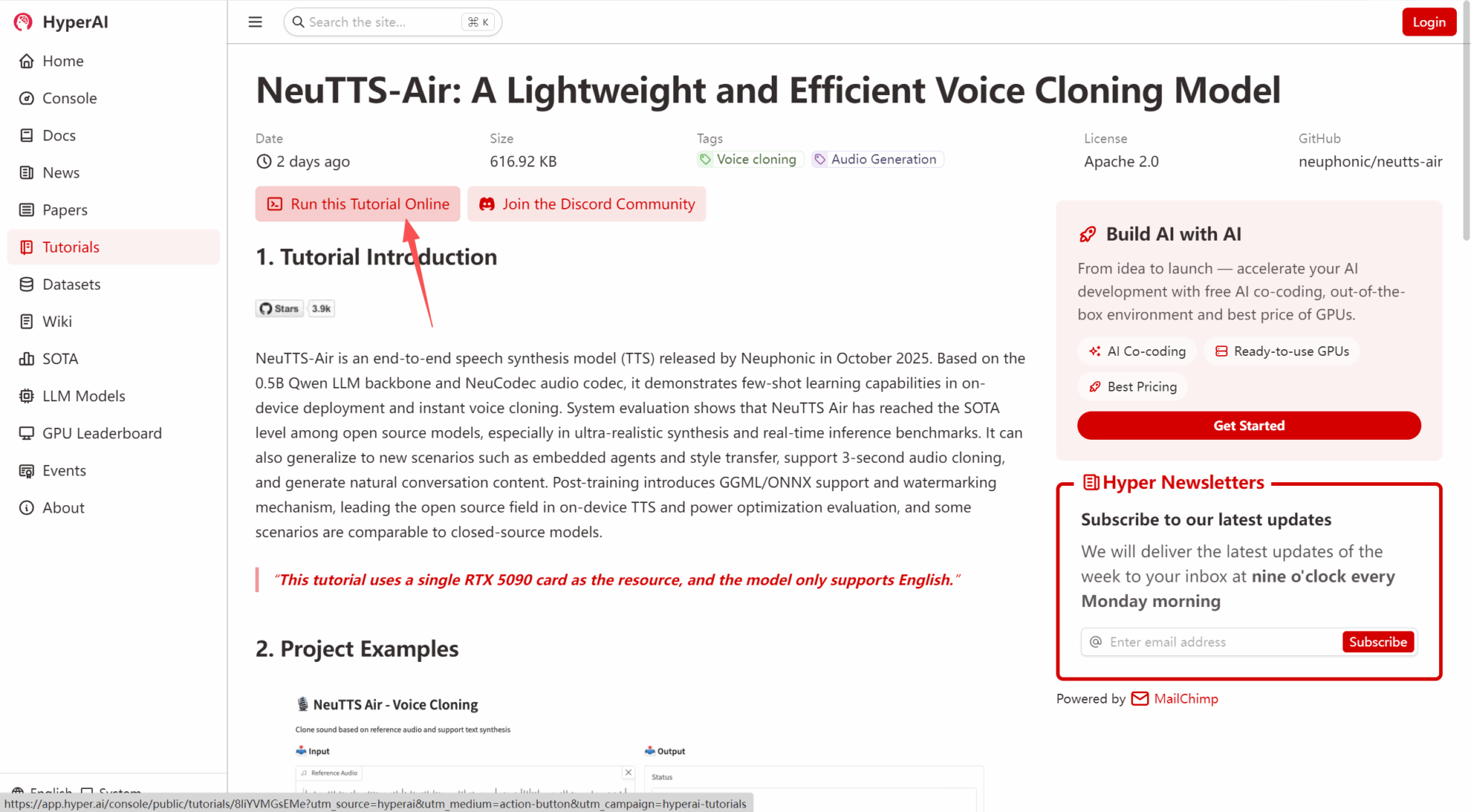
1. hyper.ai 홈페이지에 접속한 후, "튜토리얼" 페이지를 선택하거나 "더 많은 튜토리얼 보기"를 클릭하고, "NeuTTS-Air: 가볍고 효율적인 음성 복제 모델"을 선택한 후, "이 튜토리얼을 온라인으로 실행"을 클릭하세요.
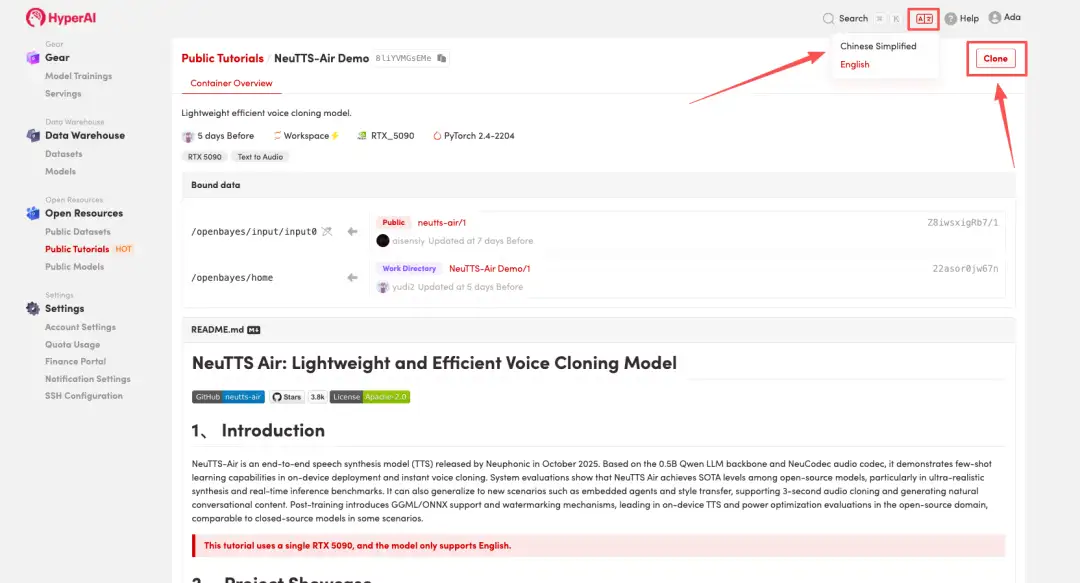
2. 페이지가 리디렉션된 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
참고: 페이지 오른쪽 상단에서 언어를 변경할 수 있습니다. 현재 중국어와 영어로만 제공됩니다. 이 튜토리얼에서는 영어로 된 단계를 안내합니다.
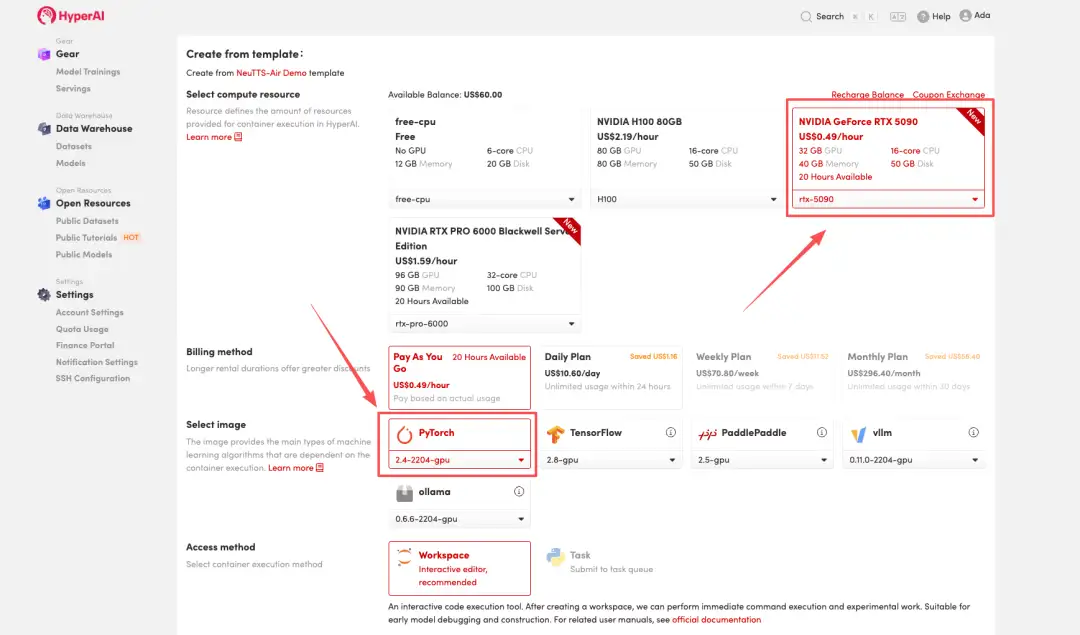
3. "NVIDIA GeForce RTX 5090" 및 "PyTorch" 이미지를 선택하고 필요에 따라 "Pay As You Go" 또는 "Daily Plan/Weekly Plan/Monthly Plan"을 선택한 다음 "Continue job execution"을 클릭합니다.

4. 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 프로세스는 약 3분 정도 소요됩니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆의 화살표를 클릭하여 데모 페이지로 이동하세요. API 주소를 사용하려면 실명 인증을 완료해야 합니다.
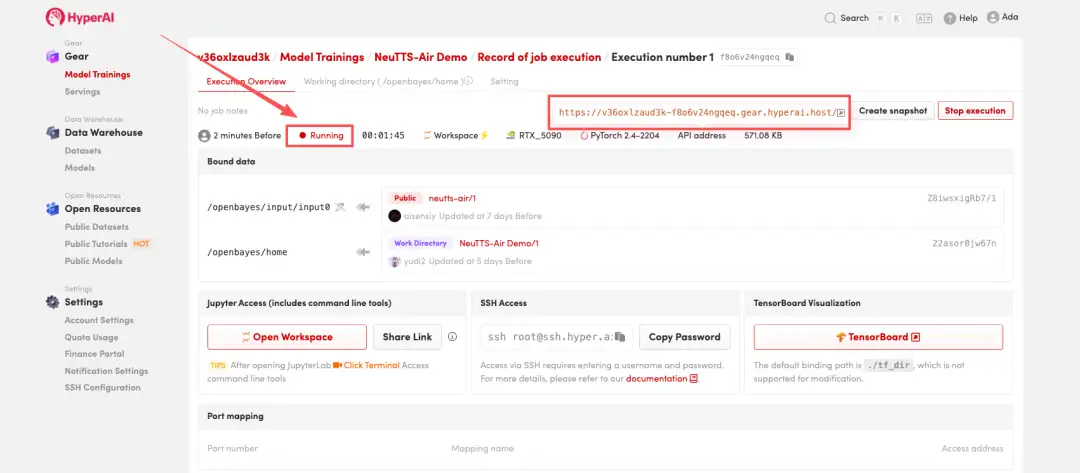
효과 시연
데모 실행 페이지에 들어간 후, "참조 오디오"에 참조 오디오를 업로드하고, "참조 텍스트" 텍스트 상자에 참조 텍스트를 입력하고, 복제 후 원하는 오디오 텍스트 내용을 "생성할 텍스트"에 입력하고, "제출"을 클릭한 후 복제된 오디오를 받을 때까지 잠시 기다리세요.
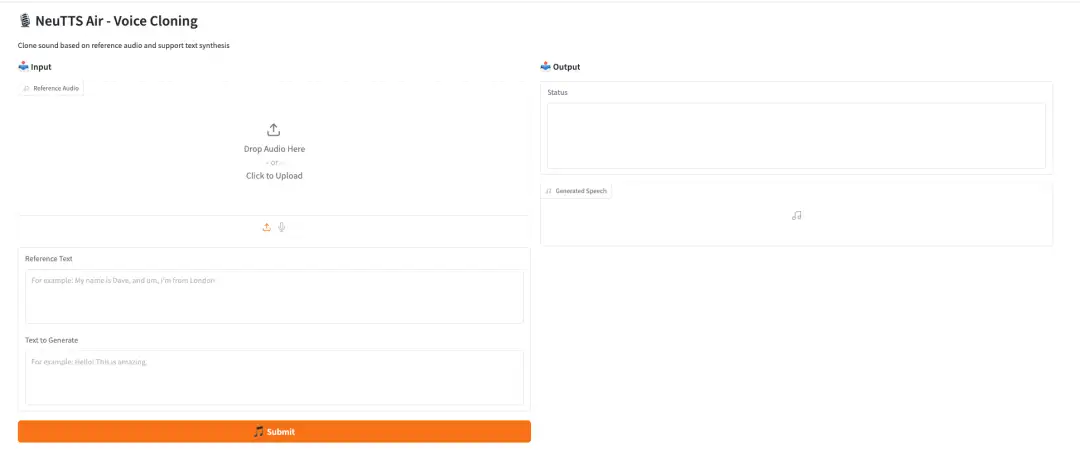
위는 HyperAI가 이번에 추천하는 튜토리얼입니다. 누구나 와서 체험해 보세요!
튜토리얼 링크: