Command Palette
Search for a command to run...
"보조자"에서 "사용자"로, Microsoft UserLM-8B는 실제 인간 대화를 시뮬레이션하여 LLM 최적화의 새로운 흐름을 주도합니다. 가벼운 성능을 위해 설계된 Extract-0은 소모수 모델이 정확한 정보 추출을 달성할 수 있도록 지원합니다.

대규모 언어 모델(LLM)의 급속한 발전으로, 사용자의 명확한 요구를 충족시키기 위해 세부적이고 체계적인 응답을 제공하는 "도우미" 역할을 하는 강력한 모델이 등장했습니다.존재하다실제 대화 상황에서 사용자들은 자신의 의도를 한 번에 완전히 표현하기보다는 여러 차례의 대화를 통해 점진적으로 정보를 드러내는 경우가 많습니다. 또한 이들의 언어 스타일은 일반적으로 단편화, 개인화, 그리고 즉각적인 적응이라는 특징을 보입니다.반면, 기존의 "어시스턴트" 모델은 사용자를 시뮬레이션하는 데 그다지 능숙하지 않습니다. 더욱이, LLM 어시스턴트가 좋을수록 "사용자" 모방이 더욱 왜곡됩니다. 이러한 한계는 현재 LLM 평가 시스템의 핵심적인 문제점을 드러냅니다. 인간 대화를 정확하게 시뮬레이션할 수 있는 고품질 "사용자" 페르소나가 부족하기 때문에 기존 평가 환경은 종종 지나치게 이상화되어 실제 애플리케이션의 복잡한 맥락에 비해 크게 뒤떨어집니다.
이러한 맥락에서Microsoft는 최신 사용자 언어 모델 UserLM-8B를 출시했습니다.일반적으로 보조자 역할을 하는 일반적인 LLM과 달리, WildChat 대화 코퍼스를 기반으로 학습된 이 모델은 대화에서 "사용자" 역할을 시뮬레이션하여 여러 차례의 대화에 참여하고 대규모 모델의 성능을 평가하는 데 유용한 도구로 활용할 수 있습니다. UserLM을 사용하여 프로그래밍 및 수학 대화를 시뮬레이션할 때 GPT-4o의 점수는 74.61 TP3T에서 57.41 TP3T로 떨어졌습니다. 이는 더 현실적인 시뮬레이션 환경일수록 "보조자"가 사용자 표현의 미묘한 차이에 반응하는 데 어려움을 겪어 성능 저하로 이어질 수 있음을 보여줍니다.
UserLM-8B의 출시는 대규모 모델을 평가하는 데 더욱 현실적이고 견고한 테스트 환경을 제공합니다. 사용자 대화를 시뮬레이션함으로써 최첨단 어시스턴트 모델조차도 성능이 크게 저하될 수 있으며, 이를 통해 연구자와 개발자는 실제 상호작용에서 모델의 취약점을 더욱 정확하게 파악할 수 있습니다.이를 통해 LLM 역량 평가가 단일하고 정적인 벤치마크 테스트와 점수 비교를 넘어 점차 현실에 가까운 "실전 훈련"을 강조하게 됩니다.LLM이 사용자의 진정한 의도를 더 잘 이해하고 인간 사용자 경험을 지속적으로 최적화하도록 하세요.
"UserLM-8b: 사용자 대화 시뮬레이션 모델"이 HyperAI 공식 웹사이트에 공개되었습니다. 지금 바로 체험해 보세요!
온라인 사용:https://go.hyper.ai/EHcdQ
10월 20일부터 10월 24일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 8개
* 엄선된 고품질 튜토리얼: 7개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 10월 마감일 상위 컨퍼런스: 1
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. CP2K_Benchmark 성능 벤치마크 데이터 세트
CP2K 벤치마크 데이터셋은 고성능 컴퓨팅(HPC) 환경을 위해 특별히 설계된 성능 테스트 및 검증 입력 데이터셋입니다. 오픈소스 First Principles 시뮬레이션 소프트웨어인 CP2K에서 파생된 이 데이터셋은 다양한 하드웨어 플랫폼, 병렬화 전략(MPI/OpenMP), 그리고 컴파일 최적화 설정에서 양자 화학 및 분자 동역학 계산의 성능을 평가하는 데 사용됩니다.
직접 사용:https://go.hyper.ai/BGnLb
2. Smilei_Benchmark 플라즈마 동역학 시뮬레이션 벤치마크 데이터 세트
Smilei는 Simulation of Matter Irradiated by Light at Extreme Intensities의 약자로, 레이저-플라즈마 상호작용, 입자 가속, 강장 QED, 우주 물리학과 같은 분야에서 고정밀, 고성능, 확장 가능한 플라즈마 동역학 시뮬레이션 플랫폼을 제공하도록 설계된 오픈 소스의 사용하기 쉬운 전자기 입자-셀(PIC) 코드입니다.
직접 사용:https://go.hyper.ai/6VCxB
3. Gatk_benchmark 게놈 분석 예제 데이터 세트
GATK(Genome Analysis Toolkit)는 MIT와 하버드 대학교의 합작 투자 기관인 브로드 연구소(Broad Institute)에서 개발한 오픈소스 생물정보학 툴킷입니다. 이 프로젝트는 고처리량 시퀀싱(NGS) 데이터에 대한 표준화된 분석 파이프라인을 제공하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/0VAuf
4. LAMMPS-Bench 분자 동역학 벤치마크 데이터 세트
LAMMPS 벤치 데이터셋은 다양한 하드웨어 및 구성에서 LAMMPS(분자 동역학 시뮬레이션 소프트웨어)의 성능을 테스트하고 비교하는 데 사용됩니다. 이 데이터셋은 과학적 실험 데이터가 아니라, 계산 성능(속도, 확장성, 효율성)을 평가하는 데 사용됩니다. 특정 아키텍처, 역장 파일, 입력 스크립트, 초기 원자 좌표 등이 포함되어 있습니다. LAMMPS는 이러한 데이터셋을 `bench/` 폴더에 제공합니다.
직접 사용:https://go.hyper.ai/L4gye
5. PromptCoT-2.0-SFT-4.8M 감독 미세 조정 프롬프트 SFT 데이터 세트
PromptCoT-2.0-SFT-4.8M은 대규모 언어 모델에 대한 고품질 추론 프롬프트를 제공하도록 설계된 대규모 합성 프롬프트 데이터셋으로, 미세 조정 또는 자가 학습을 위해 사용됩니다. 이 데이터셋은 추론 추적을 포함한 약 480만 개의 완전 합성 프롬프트를 포함하고 있으며, 수학 및 프로그래밍이라는 두 가지 주요 추론 영역을 포괄합니다.
직접 사용:https://go.hyper.ai/f188j
6. Extract-0 문서정보 추출 데이터
Extract-0는 문서 정보 추출 작업을 위해 특별히 설계된 고품질 학습 및 평가 데이터셋입니다. 복잡한 추출 작업에서 소규모 매개변수 모델의 성능 최적화 연구를 지원하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/z9BQO
7. EmoBench-M 감정 인식 벤치마크 데이터 세트
EmoBench-M은 선전대학교, 광밍연구소, 마카오대학교 및 기타 기관에서 다중모달 대규모 언어 모델(MLLM)의 감정 이해 능력을 평가하기 위해 제안한 벤치마크 데이터셋입니다. 이 데이터셋은 동적 및 다중모달 상호작용 시나리오에서 기존의 단일모달 또는 정적 감정 데이터셋의 부족한 부분을 메우고, 실제 환경에서 인간의 감정 표현 및 인식의 복잡성에 더욱 근접하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/WafXo
8. GeoReasoning-10K 기하학적 다중 모드 추론 데이터 세트
GeoReasoning-10K는 기하학을 위한 다중 모드 추론 데이터셋으로, 기하학에서 시각적 양식과 언어적 양식 간의 간극을 메우도록 설계되었습니다. 이 데이터셋은 상세한 기하학적 추론 주석이 포함된 10,000개의 기하학적 이미지-텍스트 쌍을 포함합니다. 각 쌍은 기하학적 구조, 의미적 표현 및 시각적 표현 측면에서 일관성을 유지하여 매우 정확한 교차 모드 의미 정렬을 제공합니다.
직접 사용:https://go.hyper.ai/7qisY

선택된 공개 튜토리얼
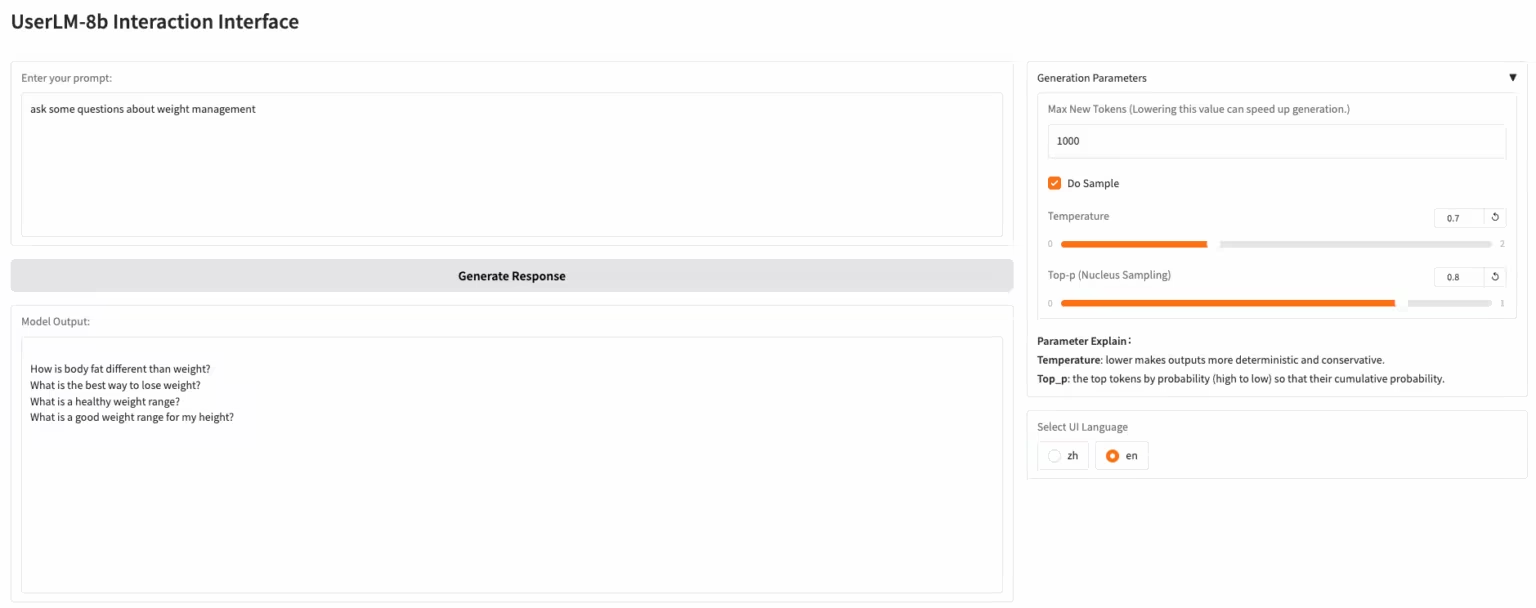
1. UserLM-8b: 사용자 대화 시뮬레이션 모델
UserLM-8b는 마이크로소프트에서 출시한 사용자 행동 시뮬레이션 모델입니다. 대화에서 "어시스턴트" 역할을 하는 일반적인 LLM과 달리, UserLM-8b는 WildChat 대화 코퍼스를 기반으로 학습된 대화에서 "사용자" 역할을 시뮬레이션하며, 대규모 어시스턴트의 역량을 평가하는 데 사용할 수 있습니다. 이 모델은 일반적인 대규모 어시스턴트가 아니므로 더욱 현실적인 대화를 시뮬레이션하거나 문제를 해결할 수는 없지만, 더욱 강력한 어시스턴트를 개발하는 데 도움이 될 수 있습니다.
온라인으로 실행:https://go.hyper.ai/EHcdQ
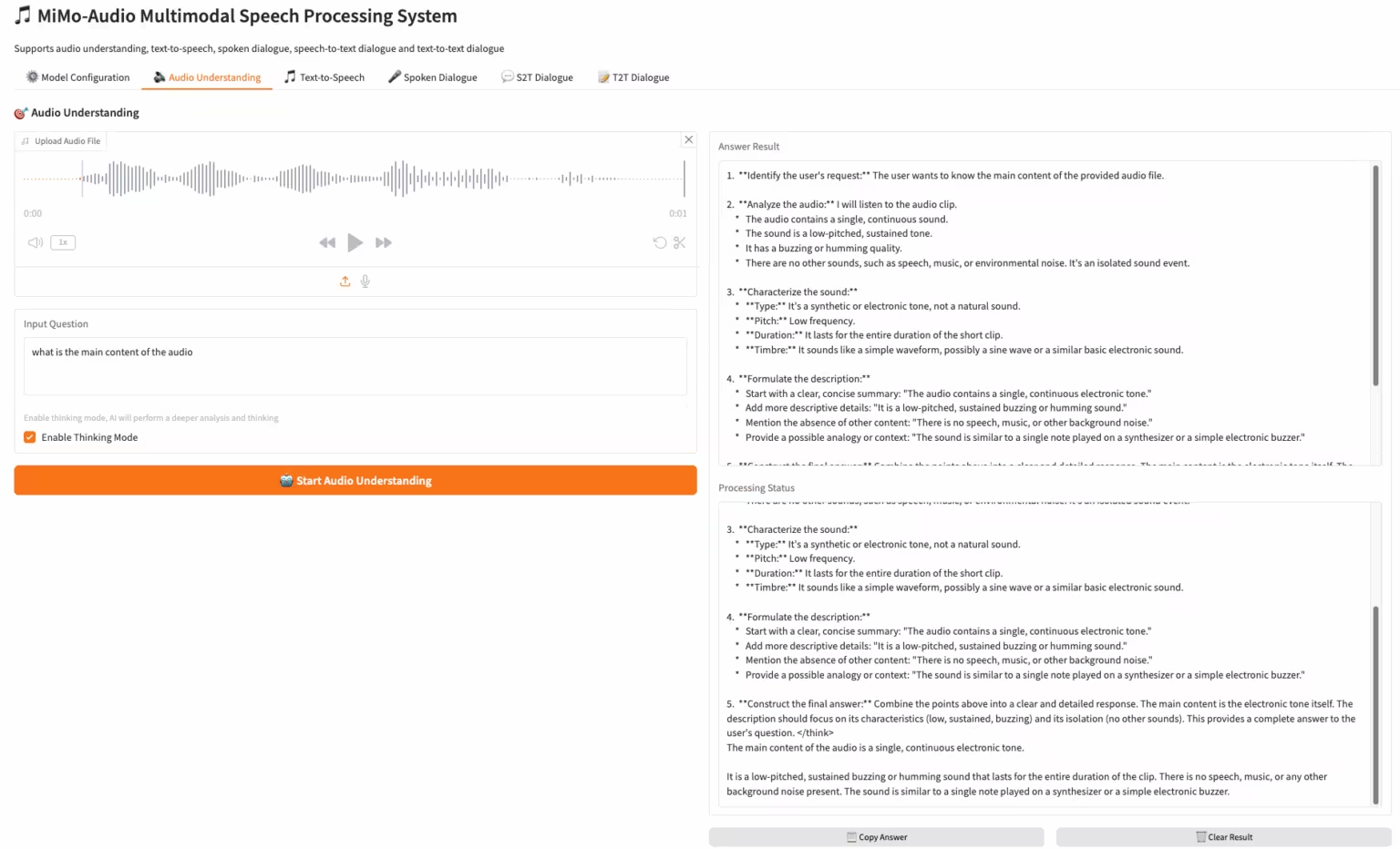
2. MiMo-Audio-7B-Instruct: Xiaomi의 오픈소스 엔드투엔드 음성 모델
MiMo-Audio는 샤오미에서 출시한 엔드투엔드 음성 모델입니다. 사전 학습 데이터는 1억 시간 이상으로 확장되었으며, 연구원들은 다양한 오디오 작업에서 퓨샷 학습(Few-Shot Learning) 성능을 입증했습니다. 연구팀은 이러한 성능을 체계적으로 평가한 결과, MiMo-Audio-7B-Base가 오픈소스 모델의 음성 지능 및 오디오 이해 벤치마크 모두에서 최고 성능(SOTA)을 달성했음을 확인했습니다.
온라인으로 실행:https://go.hyper.ai/3DWbb
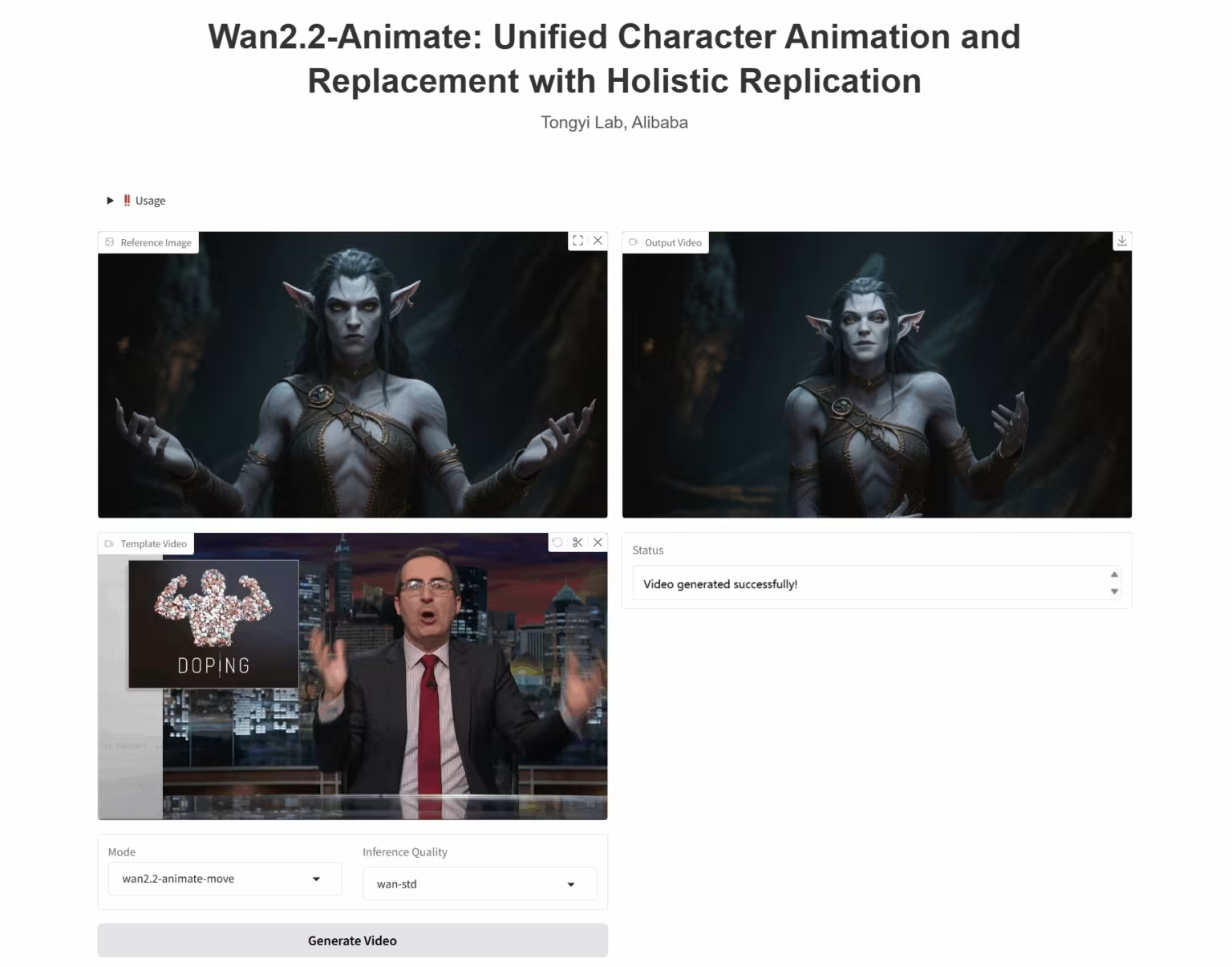
3. Wan2.2-Animate-14B: 개방형 고급 대규모 비디오 생성 모델
Wan2.2-Animate-14B는 Alibaba Tongyi Wanxiang 팀이 개발한 오픈소스 모션 생성 모델입니다. 이 모델은 모션 모방 모드와 롤플레잉 모드를 모두 지원합니다. 연기자 영상을 기반으로 얼굴 표정과 움직임을 정확하게 재현하여 매우 사실적인 캐릭터 애니메이션 영상을 생성할 수 있습니다.
온라인 실행: https://go.hyper.ai/UbtSO
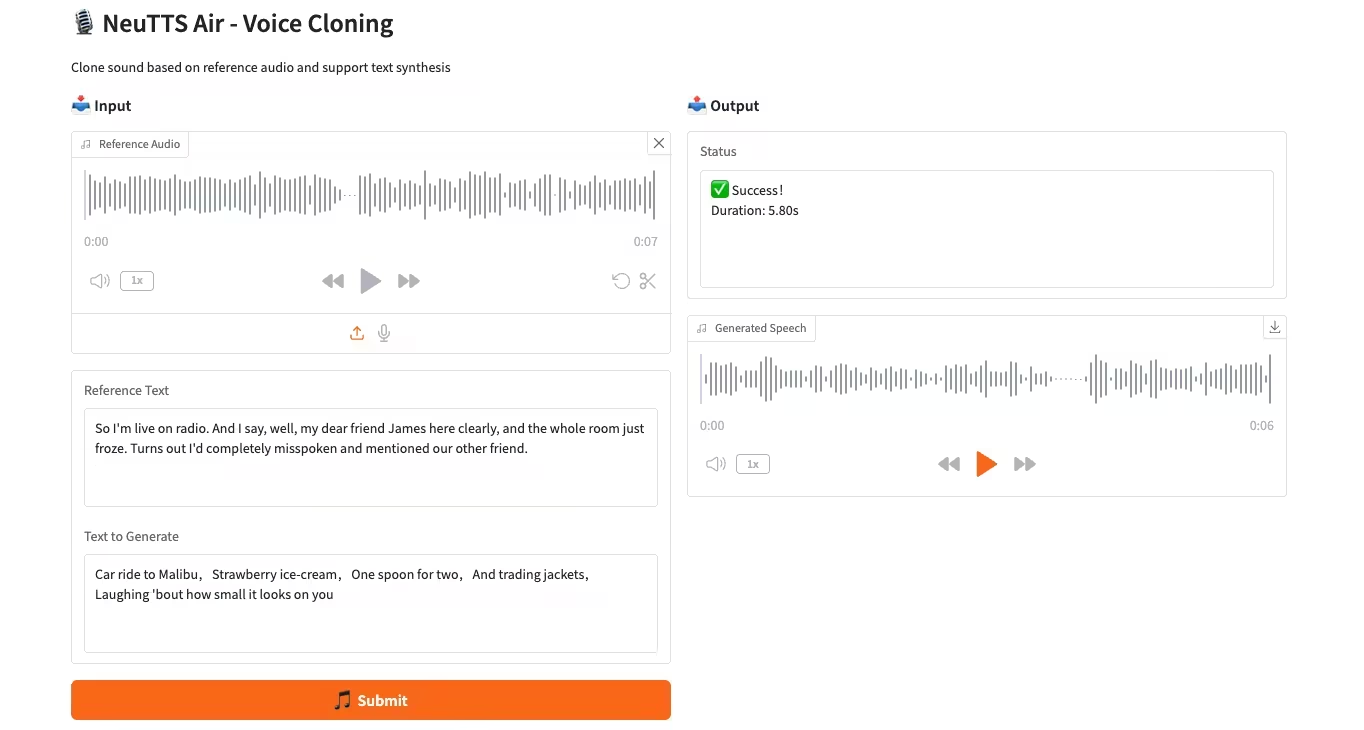
4. NeuTTS-Air 음성 복제 모델의 CPU 배치
NeuTTS-Air는 Neuphonic에서 출시한 종단간 텍스트-음성 변환(TTS) 모델입니다. 0.5B Qwen LLM 백본과 NeuCodec 오디오 코덱을 기반으로 하는 이 모델은 온디바이스 배포 및 즉각적인 음성 복제에서 퓨샷 학습(fue-shot learning) 성능을 보여줍니다. 시스템 평가 결과, NeuTTS Air는 특히 초현실적 합성 및 실시간 추론 벤치마크에서 오픈소스 모델 중 최고 수준의 성능을 달성하는 것으로 나타났습니다.
온라인으로 실행:https://go.hyper.ai/KMMG1
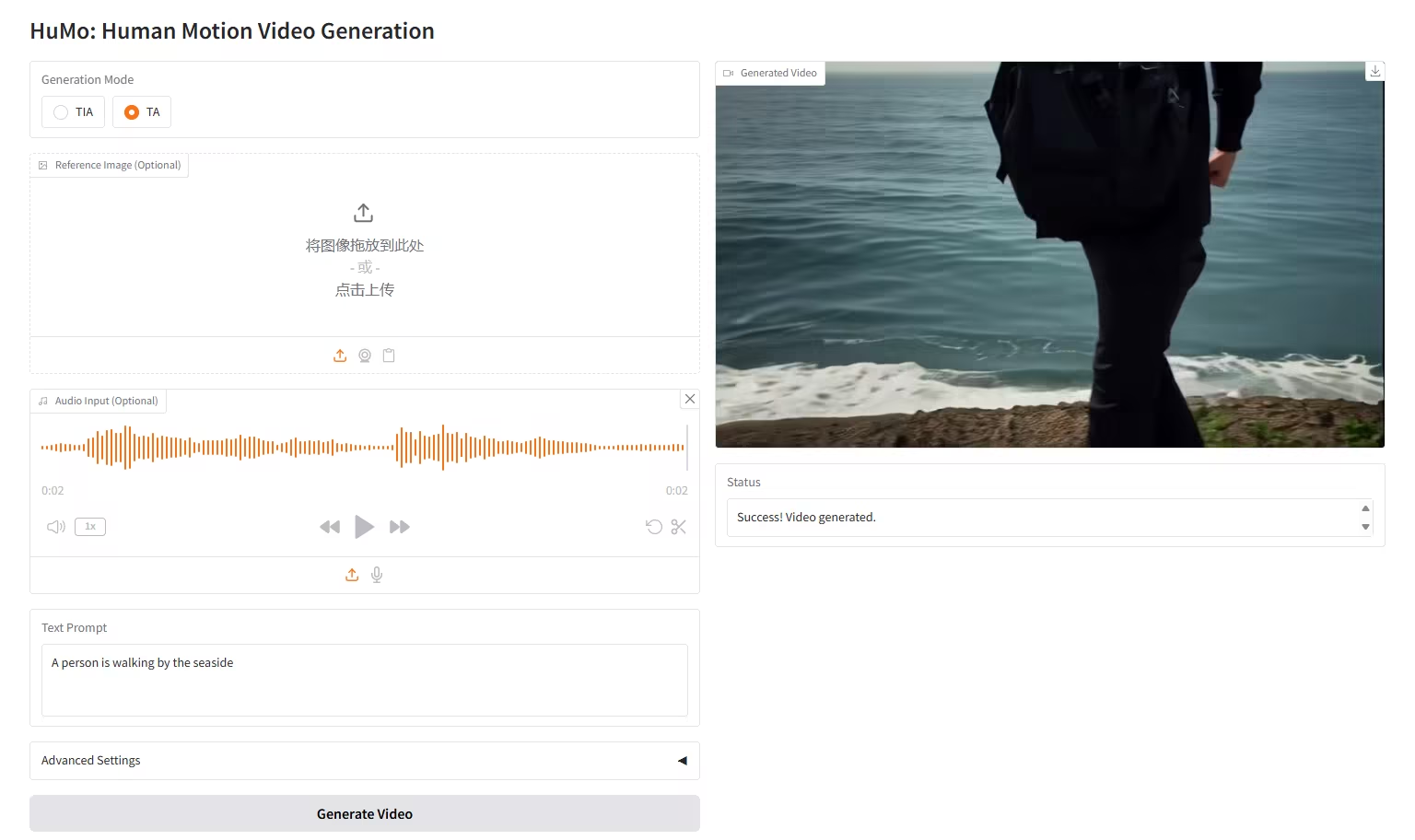
5. HuMo-1.7B: 다중 모달 비디오 생성 프레임워크
HuMo는 칭화대학교와 바이트댄스(ByteDance)의 지능형 창작 랩(Intelligent Creation Lab)이 개발한 멀티모달 비디오 생성 프레임워크로, 인간 중심 비디오 생성에 중점을 두고 있습니다. 텍스트, 이미지, 오디오를 포함한 멀티모달 입력으로부터 고품질의 상세하고 제어 가능한 인간형 비디오를 생성합니다. 이 모델은 강력한 텍스트 큐 추적, 일관된 피사체 보존, 그리고 오디오 기반 모션 동기화를 지원합니다.
온라인으로 실행:https://go.hyper.ai/tnyQU
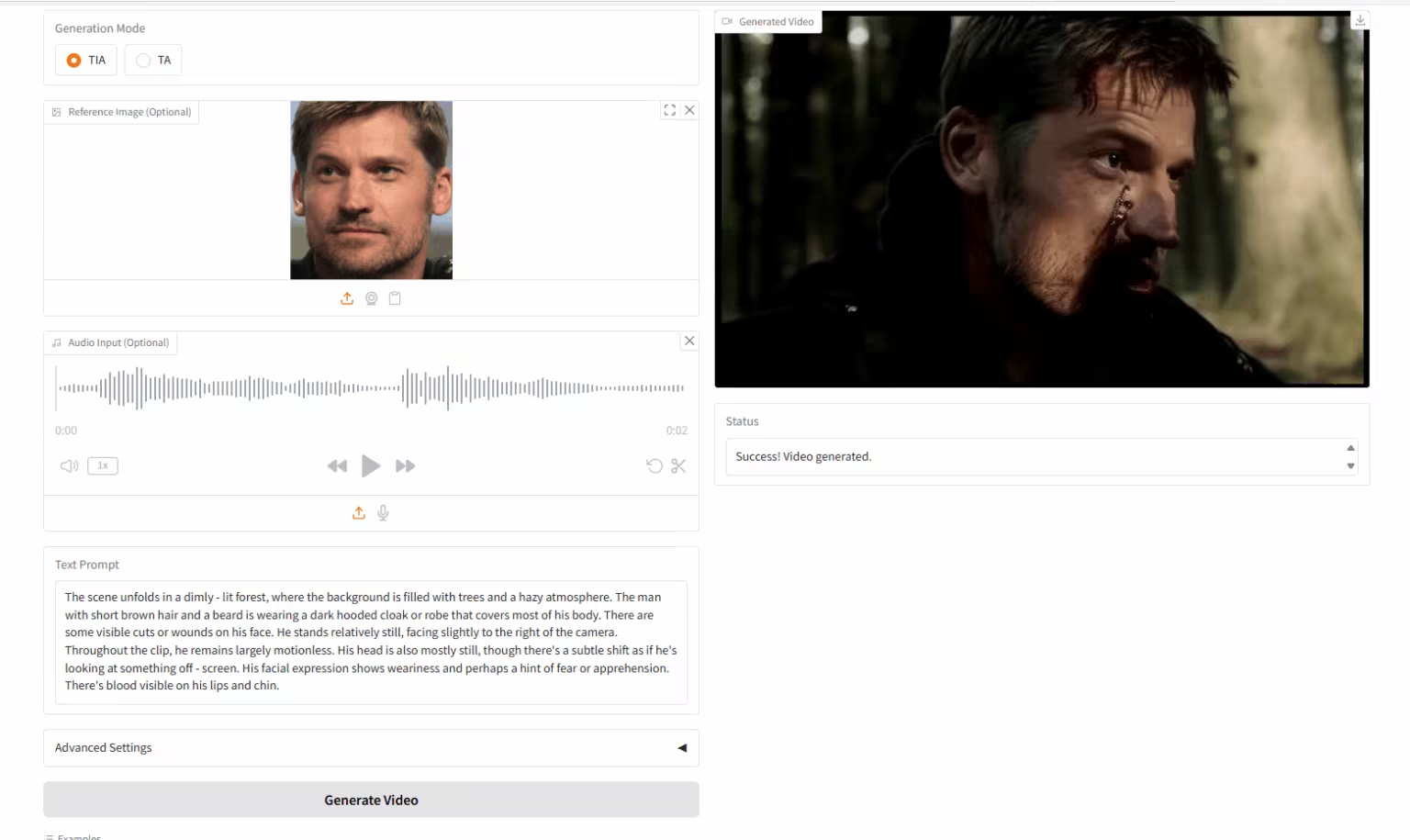
6. HuMo-17B: 삼중 협력 창조
HuMo는 칭화대학교와 바이트댄스 인텔리전트 크리에이션 랩에서 개발한 멀티모달 비디오 생성 프레임워크입니다. 텍스트-이미지(텍스트-이미지 기반 VideoGen), 텍스트-오디오(텍스트-오디오 기반 VideoGen), 그리고 텍스트-이미지-오디오(텍스트-이미지-오디오 기반 VideoGen)를 기반으로 비디오를 생성할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/liAti
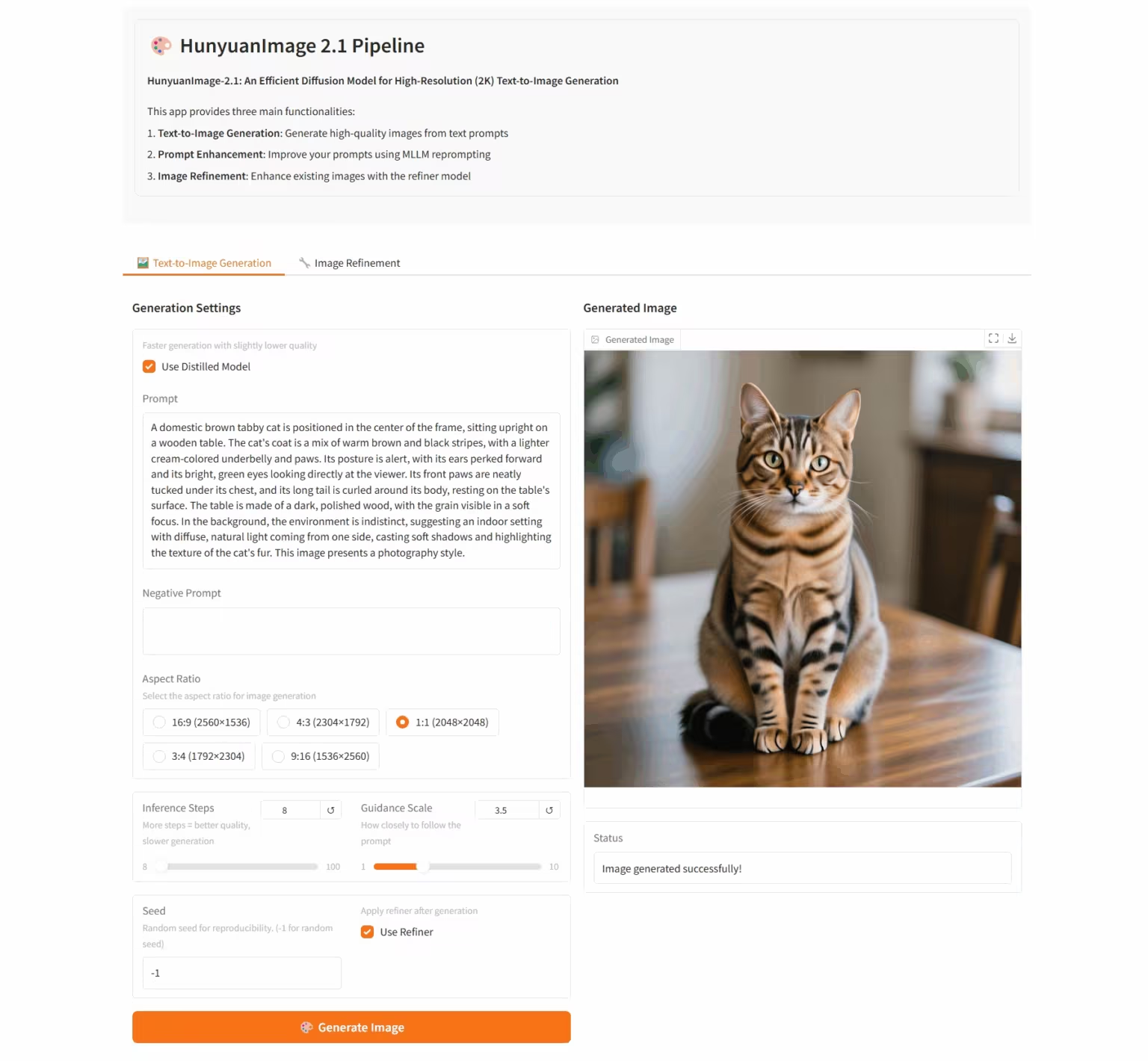
7. HunyuanImage-2.1: 고해상도(2K) Wensheng 이미지에 대한 확산 모델
HunyuanImage-2.1은 텐센트 Hunyuan 팀이 개발한 오픈소스 텍스트 기반 이미지 모델입니다. 네이티브 2K 해상도를 지원하고 강력한 복합 의미 이해 기능을 갖추고 있어 장면 세부 정보, 캐릭터 표현 및 동작을 정확하게 생성할 수 있습니다. 이 모델은 중국어와 영어 입력을 모두 지원하며, 만화나 액션 피규어 등 다양한 스타일의 이미지를 생성할 수 있으며, 이미지 내 텍스트와 세부 정보에 대한 강력한 제어 기능을 유지합니다.
온라인으로 실행:https://go.hyper.ai/hpWNA
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. LLM 추론을 위한 내부 확률과 자기 일관성 연결에 대한 이론적 연구
본 논문은 이론적 통찰을 통합하고 퍼플렉시티 일관성과 추론 가지치기라는 두 가지 핵심 요소로 구성된 하이브리드 접근법인 RPC(Perplexity-Consistency and Reasoning Pruning)를 제안합니다. 이론적 분석과 7개의 벤치마크 데이터셋에 대한 실증 결과는 RPC가 추론 오류를 줄이는 데 상당한 잠재력을 가지고 있음을 보여줍니다. 특히, RPC는 자기 일관성과 유사한 추론 성능을 달성하는 동시에 신뢰도와 샘플링 비용을 50%만큼 크게 향상시킵니다.
논문 링크:https://go.hyper.ai/V3reH
2. 모든 주의가 중요합니다: 장기 맥락 추론을 위한 효율적인 하이브리드 아키텍처
본 기술 보고서는 Ring-mini-linear-2.0과 Ring-flash-linear-2.0을 포함한 일련의 Ring-linear 모델을 제안합니다. 두 모델 모두 선형 어텐션과 소프트맥스 어텐션을 효과적으로 통합하는 하이브리드 아키텍처를 채택하여, 긴 맥락 추론 시나리오에서 I/O 오버헤드와 계산 부담을 크게 줄입니다.
논문 링크:https://go.hyper.ai/xLhP3
3. BAPO: 적응적 클리핑을 통한 균형 잡힌 정책 최적화를 통해 LLM을 위한 비정책 강화 학습 안정화
본 논문에서는 적응적 클리핑을 이용한 균형 정책 최적화(BAPO)라는 간단하고 효율적인 방법을 제안합니다. 이 방법은 클리핑 경계를 동적으로 조정하고, 긍정적 기여와 부정적 기여를 적응적으로 재균형화하며, 정책 엔트로피를 효과적으로 유지하고, RL 최적화의 안정성을 크게 향상시킵니다.
논문 링크:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: 자율 데이터 과학을 위한 에이전트 기반 대규모 언어 모델
본 논문은 자율 데이터 과학을 위해 특별히 설계된 최초의 대규모 언어 모델인 DeepAnalyze-8B를 제시합니다. 이 모델은 데이터 소스에서 분석가급 심층 연구 보고서 작성에 이르는 전 과정을 자동화합니다. 실험 결과는 80억 개의 매개변수만 사용하여 이 모델이 최첨단 독점 대규모 언어 모델을 기반으로 구축된 기존 워크플로 에이전트보다 우수한 성능을 발휘함을 보여줍니다.
논문 링크:https://go.hyper.ai/UTdwP
5. OmniVinci: 옴니모달 이해를 위한 아키텍처 및 데이터 강화 LLM
본 논문은 강력하고 오픈 소스 기반의 옴니모달 대규모 언어 모델(LLM)을 구축하는 것을 목표로 하는 OmniVinci 프로젝트를 제안합니다. 연구진은 모델 아키텍처 설계 및 데이터 구축 전략에 대한 심층 연구를 수행하고, 데이터 구축 및 합성 프로세스를 설계 및 구현하여 2,400만 개의 단일모달 및 옴니모달 대화 데이터셋을 생성했습니다.
논문 링크:https://go.hyper.ai/c3yQW
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. NVIDIA는 NeurIPS 2025에 선정되어 장기 예측 문제를 해결하기 위한 ERDM 모델을 제안했으며, 중장기 예측은 EDM 벤치마크를 계속 선도하고 있습니다.
NVIDIA와 캘리포니아 대학교 샌디에이고 캠퍼스의 연구팀은 EDM(Elucidated Diffusion Model) 프레임워크를 기반으로 시퀀스 모델링의 요구 사항을 충족하기 위해 노이즈 스케줄링, 노이즈 제거 네트워크 매개변수화, 전처리 절차, 손실 가중치 전략 및 샘플링 알고리즘을 체계적으로 개선하고 향상된 시퀀스 확산 모델(ERDM)을 구축했습니다.
전체 보고서 보기:https://go.hyper.ai/QZBBl
2. 튜토리얼 포함 | MIT 등은 단백질 복합체의 지능적 설계를 달성하기 위해 AF2를 직접 호출하는 BindCraft를 출시했습니다.
스위스 로잔 연방 공과대학(EPFL)과 매사추세츠 공과대학(MIT) 연구팀은 단백질 결합제를 처음부터 설계하기 위한 오픈 소스 자동화 프로세스인 BindCraft를 제안했습니다. 핵심 아이디어는 환각 결합제 서열을 AlphaFold2 가중치를 통해 역전파하고 오차 기울기를 계산하는 것입니다.
전체 보고서 보기:https://go.hyper.ai/LqNeb
3. 2년 만에 노벨상 3관왕: 알파벳의 장기 과학 연구 축적, AI+양자 컴퓨팅이 이끄는 기술력과 야심
2025년 노벨상 발표와 함께 구글 모회사 알파벳 소속 과학자들이 다시 한번 노벨상을 수상했습니다. 2년 연속 노벨상을 수상한 거대 기술 기업으로서, "2년 만에 3개의 상과 5명의 수상자"라는 업적은 결코 우연이 아닙니다. 2024년 AI 기술 부문 화학상과 물리학상 수상부터, 이번에는 물리학상을 수상한 양자 연구 혁신에 이르기까지, 10년 넘게 야심 찬 기획과 연구 전략을 통해 구글은 강력한 과학 연구 역량을 키워왔습니다.
전체 보고서 보기:https://go.hyper.ai/mY9Z3
MIT는 물리적 사전 확률을 기반으로 한 생성적 AI 모델을 구축하여 단일 스펙트럼 모달 입력만으로 최대 99%의 실험적 상관관계를 갖는 교차 모달 스펙트럼 생성을 달성했습니다.
MIT 연구팀은 물리적 사전 확률에 기반한 생성 AI 모델인 SpectroGen을 제안했습니다. 단일 스펙트럼 모달리티만 입력으로 사용하여 실험 결과와 99%의 상관관계를 갖는 교차 모달 스펙트럼을 생성할 수 있습니다. 이 모델은 두 가지 주요 혁신을 도입했습니다. 첫째, 스펙트럼 데이터를 수학적 분포 곡선으로 표현하고, 둘째, 물리적 사전 확률에 기반한 변분 자동 인코더 생성 알고리즘을 구축합니다.
전체 보고서 보기:https://go.hyper.ai/OsYY2
5. Google 팀은 Earth AI에 협력하여 3가지 핵심 데이터 포인트에 집중하고 공간 추론 기능을 64%까지 개선했습니다.
구글의 여러 팀이 지리공간 인공지능 모델이자 지능형 추론 시스템인 "Earth AI"를 공동 개발했습니다. 이 시스템은 상호 운용 가능한 GeoAI 모델군을 구축하고 맞춤형 추론 에이전트를 통해 다중 모드 데이터의 협업 분석을 지원합니다. 영상, 인구, 환경이라는 세 가지 핵심 데이터 유형에 중점을 둔 이 시스템은 Gemini 기반 에이전트를 사용하여 이 세 가지 모델을 연결합니다. 이 시스템은 단일 지점 모델의 한계를 뛰어넘어 비전문가 사용자도 교차 도메인 실시간 분석을 수행하고 지구 시스템 연구를 실행 가능한 글로벌 통찰력으로 발전시킬 수 있도록 지원합니다.
전체 보고서 보기:https://go.hyper.ai/djq48
인기 백과사전 기사
1. 달-이
2. 하이퍼네트워크
3. 파레토 전선
4. 양방향 장단기 메모리(Bi-LSTM)
5. 상호 순위 융합
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
10월 컨퍼런스 마감일

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1800개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 600개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 200개 이상의 AI4Science 논문 사례 해석
* 600개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.