Command Palette
Search for a command to run...
최첨단 문서 파싱 플랫폼! MinerU의 새로운 버전은 2단계 "대략적 분석(Coarse-to-fine)" 파싱 전략을 혁신적으로 개선했습니다. S2S 도메인 벤치마크가 처음 공개되었습니다! Tencent의 최신 벤치마크 데이터 세트는 음성 모델 성능을 평가합니다.

디지털화의 물결 속에서 모든 계층에서 엄청난 양의 비정형 문서 데이터가 축적되고 있습니다. 특히 학술 논문, 보고서, 양식 등이 PDF 형식으로 많이 축적되고 있습니다.이러한 문서를 기계가 읽을 수 있는 구조화된 데이터로 효율적이고 정확하게 변환하는 것은 자동화된 정보 추출, 문서 관리 및 지능형 분석을 달성하기 위한 중요한 전제 조건이며, 데이터의 가치를 끌어내는 핵심 단계이기도 합니다.
지속적으로 증가하는 OCR 수요에 따라OpenDataLab과 상하이 AI 랩이 공동으로 시각 언어 모델 MinerU2.5-2509-1.2B를 출시했습니다.PDF와 같은 복잡한 형식의 문서를 구조화된 기계 판독 가능 데이터(예: Markdown, JSON 등)로 변환하는 데 중점을 두고 있으며, 고정밀도와 고효율의 문서 구문 분석 작업을 위해 설계되었습니다.이 모델의 새로운 버전은 "대략적인 것에서 정교한 것"의 2단계 전략을 통해 효율적인 구문 분석을 달성합니다.첫 번째 단계에서는 효율적인 레이아웃 분석을 사용하여 구조적 요소를 식별하고 문서 프레임워크를 개략적으로 설명합니다. 두 번째 단계에서는 원래 해상도에서 잘린 영역 내에서 정밀한 인식을 수행하여 텍스트, 수식, 표와 같은 세부 정보가 복원되었는지 확인합니다.
MinerU2.5-2509-1.2B는 글로벌 레이아웃 분석을 로컬 콘텐츠 인식에서 분리하여 강력한 문서 구문 분석 기능을 보여줍니다.다양한 인식 작업에서 일반 및 수직 필드 모델보다 우수한 성능을 보입니다.동시에, 계산 오버헤드 측면에서도 상당한 이점을 보여줍니다. 기술적으로 우수한 모델일 뿐만 아니라, 데이터 분석, 정보 검색, 코퍼스 구축과 같은 하위 사용자 요구 사항을 강력하게 지원하여 기술적 효율성을 효과적으로 향상시키는 도구입니다.
HyperAI 공식 웹사이트에서 "MinerU2.5-2509-1.2B: 문서 파싱 데모"가 출시되었습니다. 직접 사용해 보세요!
온라인 사용:https://go.hyper.ai/emEKs
10월 13일부터 10월 17일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 11개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 10월 마감일 상위 컨퍼런스: 1
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. FDAbench-Full 이기종 데이터 분석 벤치마크 데이터 세트
FDAbench-Full은 난양기술대학교, 싱가포르 국립대학교, Huawei Technologies Co., Ltd.가 공동으로 출시한 데이터 에이전트를 위한 최초의 이기종 데이터 분석 작업 벤치마크입니다. 이 벤치마크의 목적은 데이터베이스 쿼리 생성, SQL 이해, 재무 데이터 분석 측면에서 모델의 역량을 평가하는 것입니다.
직접 사용:https://go.hyper.ai/AUjv5
2. PubMedVision 의료 다중 모드 평가 데이터 세트
PubMedVision은 다양한 의료 영상 기법과 해부학적 영역을 포괄하는 의료 다중모달 역량을 평가하는 데이터셋입니다. 의료 시각-텍스트 이해 과제에서 다중모달 대용량 언어 모델(MLLM)에 대한 표준화된 테스트 리소스를 제공하여 의료 분야에서 시각 지식 융합 및 추론 성능을 평가하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/qdvVe
3. Verse-Bench 오디오-비주얼 조인트 생성 평가 데이터 세트
Verse-Bench는 StepFun이 홍콩과학기술대학교, 홍콩과학기술대학교(광저우) 및 기타 기관들과 협력하여 발표한 오디오 및 비디오 공동 생성을 평가하기 위한 벤치마크 데이터셋입니다. 이 데이터셋은 생성 모델이 비디오를 생성할 뿐만 아니라 오디오 콘텐츠(주변 소리 및 음성 포함)와 엄격한 시간적 정렬을 유지할 수 있도록 지원합니다.
직접 사용:https://go.hyper.ai/mvau0

4. MMMC 교육용 비디오 생성 벤치마크 데이터 세트
MMMC는 싱가포르 국립대학교 쇼랩에서 발표한 교육용 비디오 생성을 위한 대규모 다학제 교육용 비디오 생성 벤치마크 데이터셋입니다. 교육용 인공지능 모델을 위한 고품질 학습 및 평가 리소스를 제공하고, 구조화된 코드와 교육 콘텐츠를 기반으로 전문적인 교육용 비디오를 자동 생성하는 연구를 지원하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/AELav
5. T2I-CoReBench 다중 모달 이미지 생성 벤치마크 데이터 세트
T2I-CoReBench는 중국과학기술대학교, 콰이쇼우테크놀로지(Kuaishou Technology)의 클링(Kling) 팀, 그리고 홍콩대학교가 제안한 텍스트 기반 이미지 생성 모델에 대한 포괄적인 평가 벤치마크입니다. 이미지 생성 모델의 조합 능력과 추론 능력을 동시에 측정하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/SLyED
6. WildSpeech-Bench 음성 이해 및 생성 벤치마크 데이터 세트
WildSpeech-Bench는 텐센트가 SpeechLLM의 음성 대 음성(Speech-to-Speech) 기능을 평가하기 위해 발표한 최초의 벤치마크입니다. 이 벤치마크는 실제 음성 상호작용 시나리오에서 모델이 완전한 음성 입력-음성 출력(S2S)을 이해하고 생성하는 능력을 측정하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/Cy63e
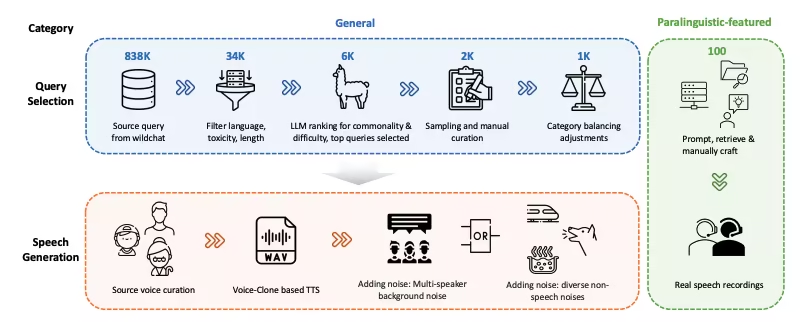
7. OmniRetarget 글로벌 로봇 모션 리매핑 데이터 세트
OmniRetarget은 아마존이 MIT, 캘리포니아 대학교 버클리 및 기타 기관들과 협력하여 공개한 휴머노이드 로봇의 전신 동작 리매핑을 위한 고품질 궤적 데이터셋입니다. 이 데이터셋에는 G1 휴머노이드 로봇이 물체 및 복잡한 지형과 상호작용할 때의 동작 궤적이 포함되어 있으며, 로봇이 물체를 운반하는 상황, 지형 위를 걷는 상황, 그리고 물체와 지형이 혼합된 상호작용의 세 가지 시나리오를 다룹니다.
직접 사용:https://go.hyper.ai/xfZY4

8. Paper2Video 페이퍼 비디오 벤치마크 데이터
Paper2Video는 싱가포르 국립대학교에서 발표한 최초의 논문 및 비디오 쌍 벤치마크 데이터셋입니다. 학술 논문에서 슬라이드, 자막, 오디오, 발표자 사진 등 프레젠테이션 비디오를 자동 생성하는 작업에 대한 표준 벤치마크 및 평가 리소스를 제공하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/NeRuV
9. FoMER 벤치 다중모달 평가 데이터 세트
FoMER Bench는 세 가지 로봇 유형과 여러 로봇 모드를 포괄하는 FoMER(Foundational Model Embodied Reasoning) 벤치마크로, 복잡한 구체화된 의사 결정 시나리오에서 LMM의 추론 능력을 평가하도록 설계되었습니다.
직접 사용:https://go.hyper.ai/Tiy5w
10. OCRBench-v2 텍스트 인식 벤치마크 데이터 세트
OCRBench-v2는 화중과학기술대학교가 남중국이공대학교, 바이트댄스 및 기타 기관들과 협력하여 발표한 다중 모드 대규모 광학 문자 인식(OCR) 벤치마크입니다. 이 벤치마크는 다양한 텍스트 관련 작업에서 대규모 다중 모드 모델(LMM)의 OCR 성능을 평가하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/hhGFR
선택된 공개 튜토리얼
이번 주에는 고품질 공개 튜토리얼을 4가지 범주로 요약했습니다.
* OCR 튜토리얼: 2
* AI4S 튜토리얼: 2
* 대형 모델 튜토리얼 : 1
* 멀티모달 튜토리얼: 6
OCR 튜토리얼
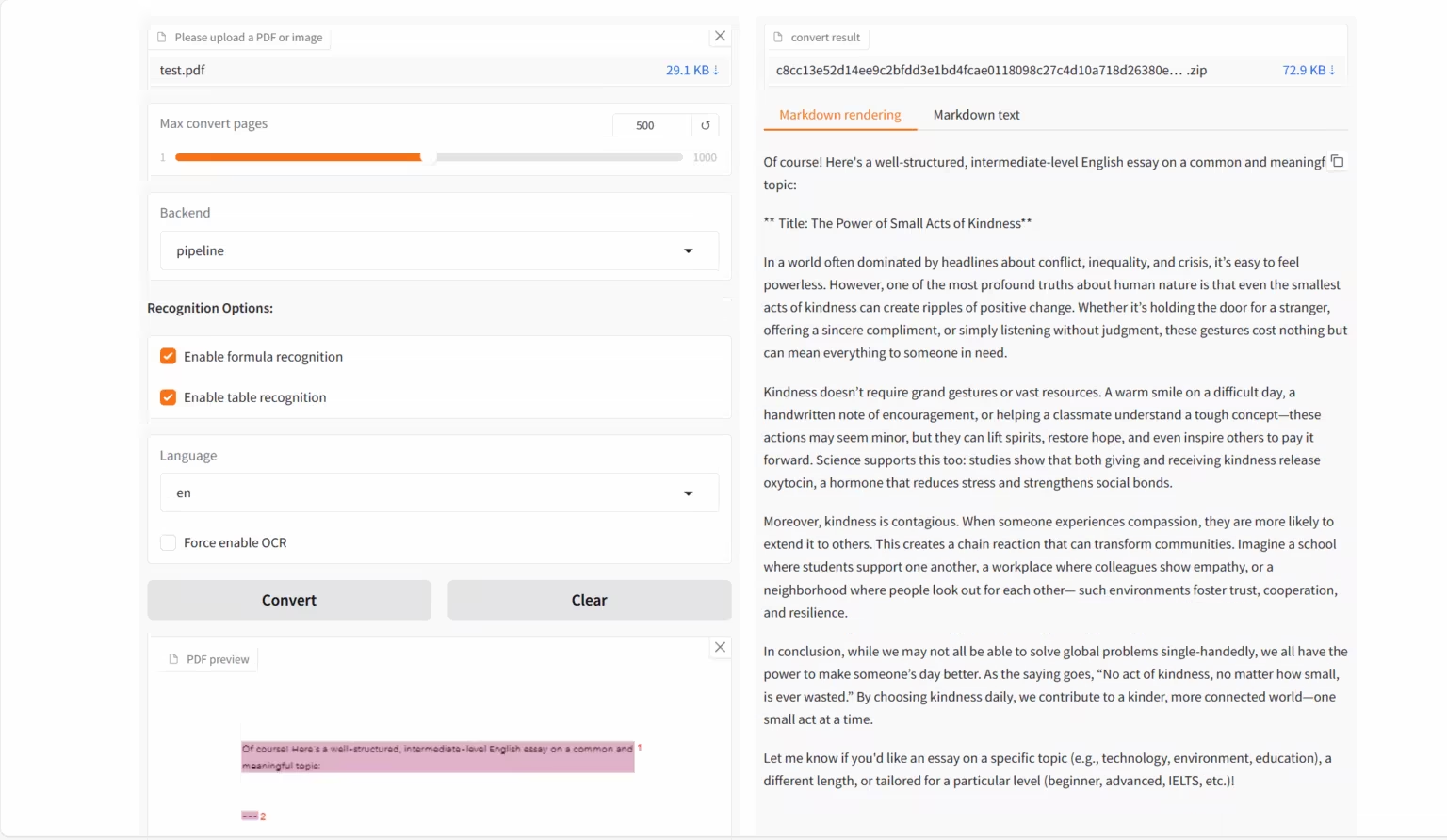
1. MinerU2.5-2509-1.2B: 문서 구문 분석 데모
MinerU 2.5-2509-1.2B는 OpenDataLab과 Shanghai AI Lab에서 개발한 시각 언어 모델로, 고정밀도의 효율적인 문서 파싱을 위해 특별히 설계되었습니다. MinerU 시리즈의 최신 버전으로, PDF와 같은 복잡한 문서 형식을 구조화되고 기계가 읽을 수 있는 데이터(예: 마크다운 및 JSON)로 변환하는 데 중점을 두고 있습니다.
온라인으로 실행:https://go.hyper.ai/emEKs
2. Dolphin 멀티모달 문서 이미지 파싱
Dolphin은 ByteDance 팀이 개발한 다중 모드 문서 파싱 모델입니다. 이 모델은 두 단계 접근 방식을 사용합니다. 먼저 구조를 분석하고 그 후 콘텐츠를 파싱합니다. 첫 번째 단계에서는 일련의 문서 레이아웃 요소를 생성하고, 두 번째 단계에서는 이러한 요소를 앵커로 사용하여 콘텐츠를 병렬로 파싱합니다. Dolphin은 다양한 문서 파싱 작업에서 GPT-4.1 및 Mistral-OCR과 같은 모델을 능가하는 탁월한 성능을 보여주었습니다.
온라인 실행: https://go.hyper.ai/lLT6X

AI4S 튜토리얼
1. BindCraft: 단백질 결합제 설계
마틴 파세사가 개발한 오픈소스 원클릭 단백질 결합제 설계 파이프라인인 BindCraft는 10~100%의 실험 성공률을 자랑합니다. 이 파이프라인은 AlphaFold2 사전 훈련된 가중치를 직접 활용하여 나노몰 친화도의 새로운 결합제를 실리코(in silico) 방식으로 생성하므로, 고처리량 스크리닝, 실험 반복, 심지어 알려진 결합 부위의 필요성도 없습니다.
온라인으로 실행:https://go.hyper.ai/eSoHk
2. Ml-simplefold: 가벼운 단백질 접힘 예측 AI 모델
Ml-simplefold는 Apple에서 출시한 단백질 접힘 예측을 위한 경량 AI 모델입니다. 플로우 매칭 기술을 기반으로 하는 이 모델은 다중 서열 정렬(MSA)과 같은 복잡한 모듈을 우회하고 무작위 노이즈로부터 단백질의 3차원 구조를 직접 생성하여 계산 비용을 크게 절감합니다.
온라인 실행: https://go.hyper.ai/Y0Us9
대형 모델 튜토리얼
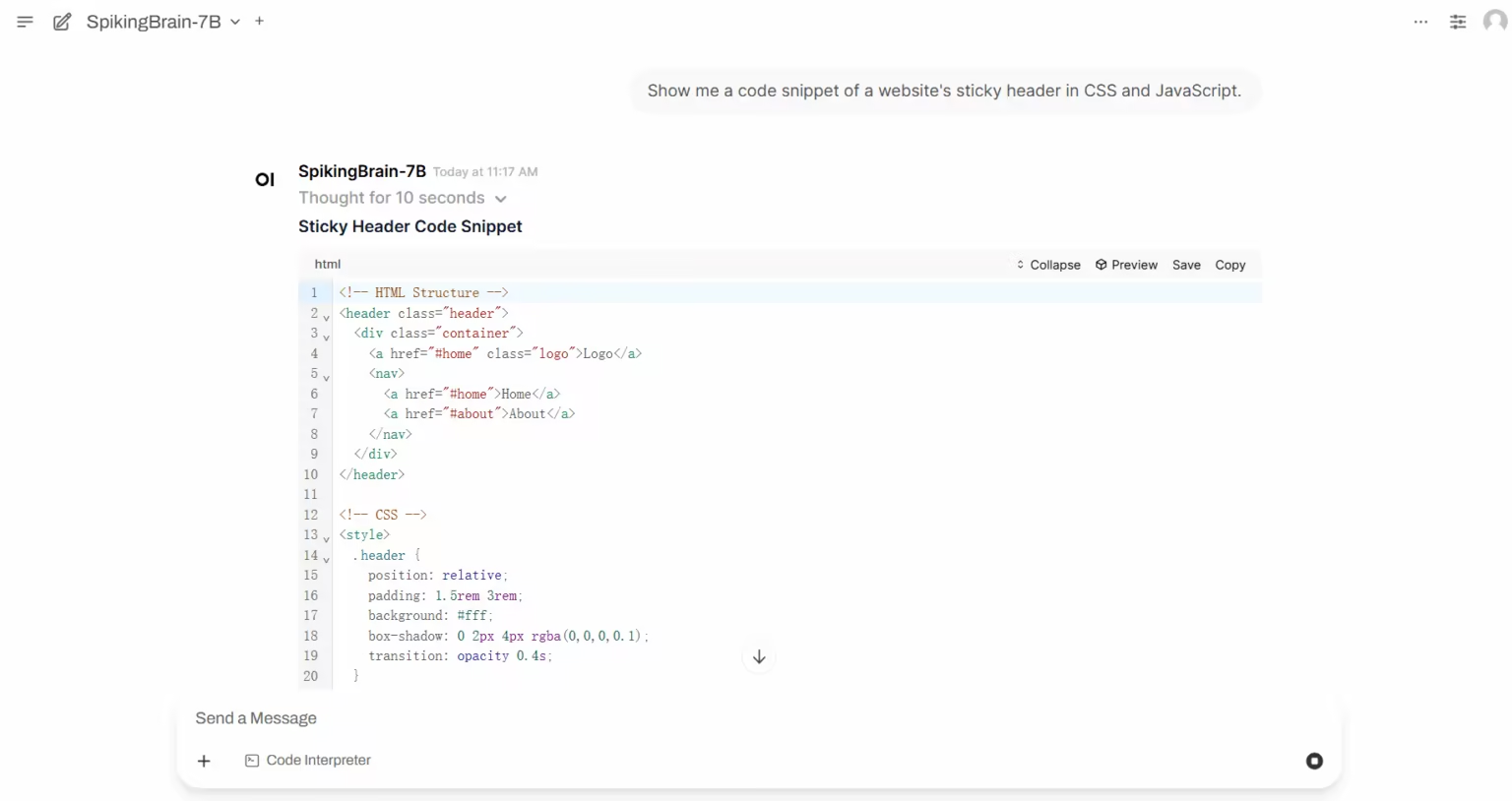
1. SpikingBrain-1.0: 내재적 복잡성을 기반으로 한 대규모 뇌 유사 스파이크 모델
SpikingBrain-1.0은 중국과학원 자동화연구소가 국가뇌인지 및 뇌유사지능중점실험실, Muxi Integrated Circuit Co., Ltd. 및 기타 기관들과 협력하여 개발한 대규모의 국내 개발 제어 가능 뇌 기반 스파이킹 모델입니다. 뇌 메커니즘에서 영감을 받은 이 모델은 하이브리드 고효율 주의 메커니즘, MoE 모듈, 그리고 스파이크 코딩을 아키텍처에 통합했으며, 오픈 소스 모델 생태계와 호환되는 범용 변환 파이프라인을 지원합니다.
온라인으로 실행:https://go.hyper.ai/i3zHC
멀티모달 튜토리얼
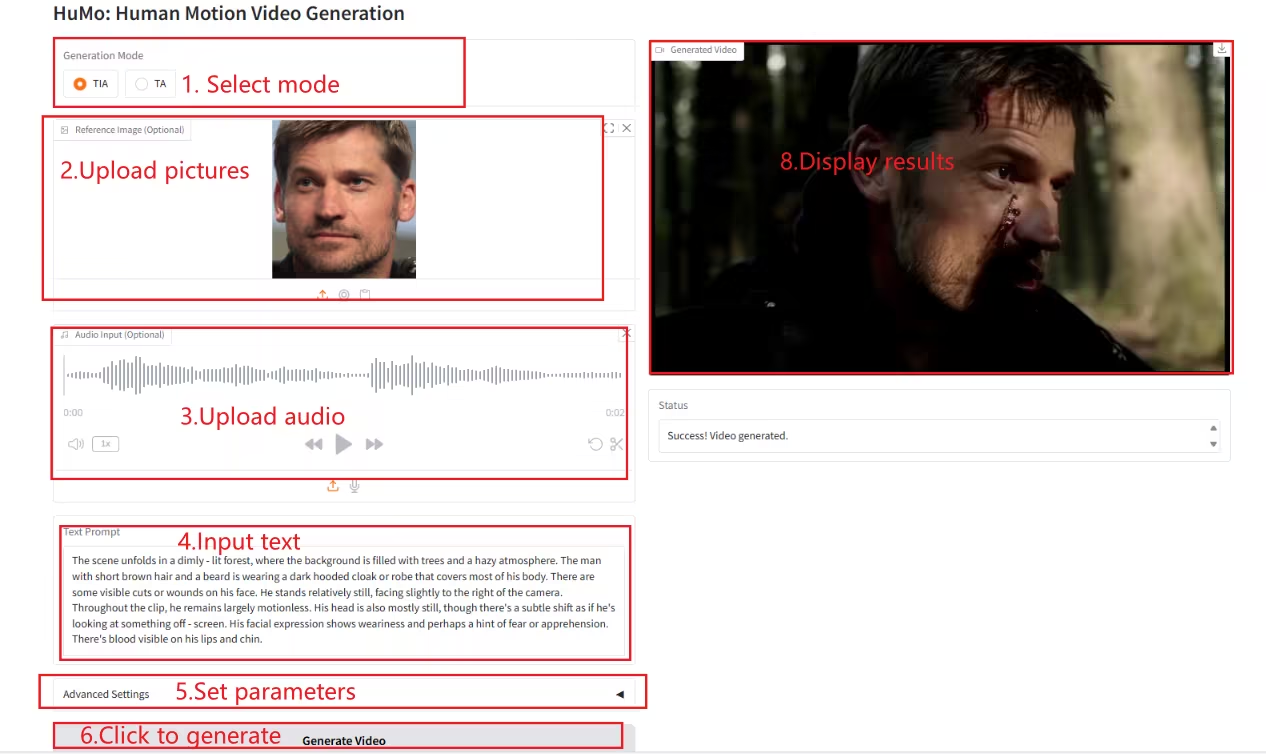
1. HuMo-1.7B: 다중 모달 비디오 생성 프레임워크
HuMo는 칭화대학교와 바이트댄스(ByteDance)의 지능형 영상 제작 연구소(Intelligent Creation Lab)가 개발한 멀티모달 영상 생성 프레임워크입니다. 인간 중심 영상 생성에 중점을 두고 있으며, 텍스트, 이미지, 오디오 등 다양한 모달 입력을 통해 고품질의 상세하고 제어 가능한 인간형 영상을 생성할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/Xe4dM
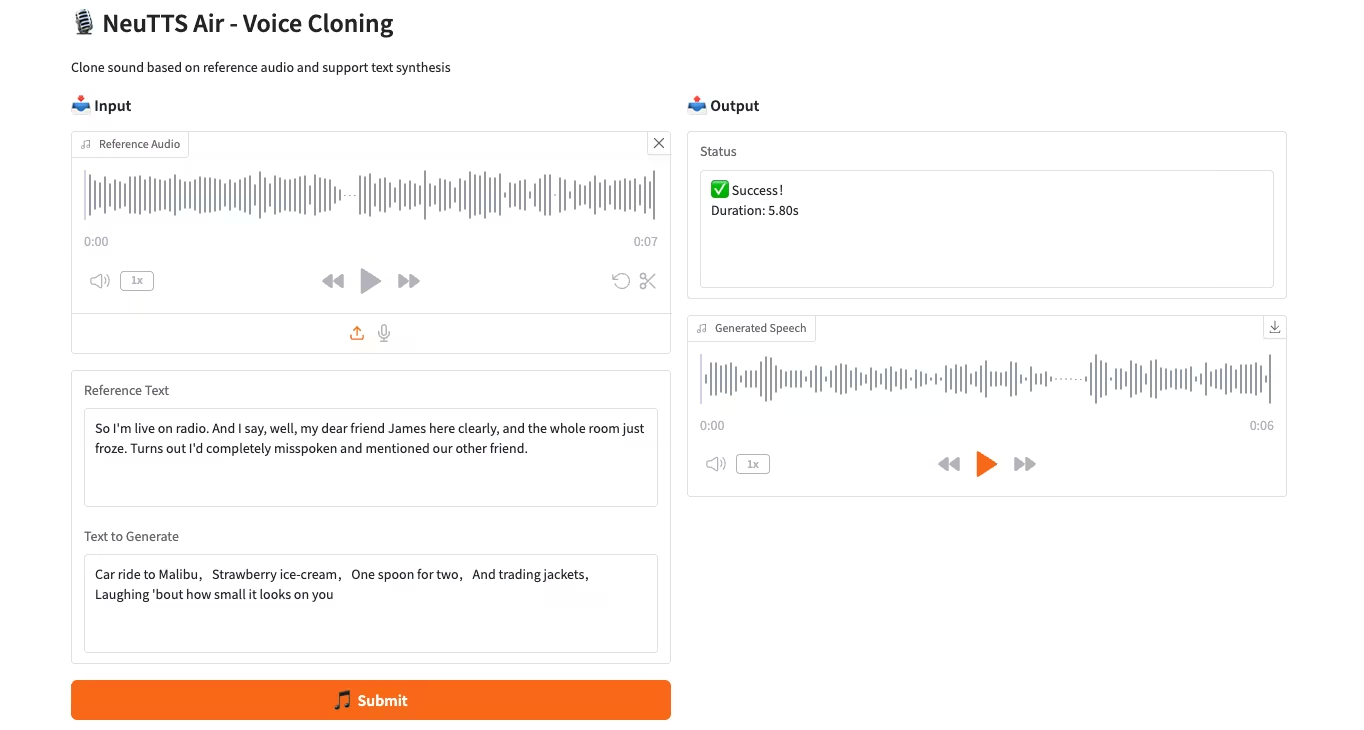
2. NeuTTS-Air: 가볍고 효율적인 음성 복제 모델
NeuTTS-Air는 Neuphonic에서 출시한 종단간 텍스트-음성 변환(TTS) 모델입니다. 0.5B Qwen LLM 백본과 NeuCodec 오디오 코덱을 기반으로, 온디바이스 배포 및 즉각적인 음성 복제에서 퓨샷 학습(Few-Shot Learning) 성능을 보여줍니다. 시스템 평가 결과, NeuTTS Air는 특히 초현실적 합성 및 실시간 추론 벤치마크에서 오픈소스 모델 중 최고 수준의 성능을 달성하는 것으로 나타났습니다.
온라인으로 실행:https://go.hyper.ai/7ONYq
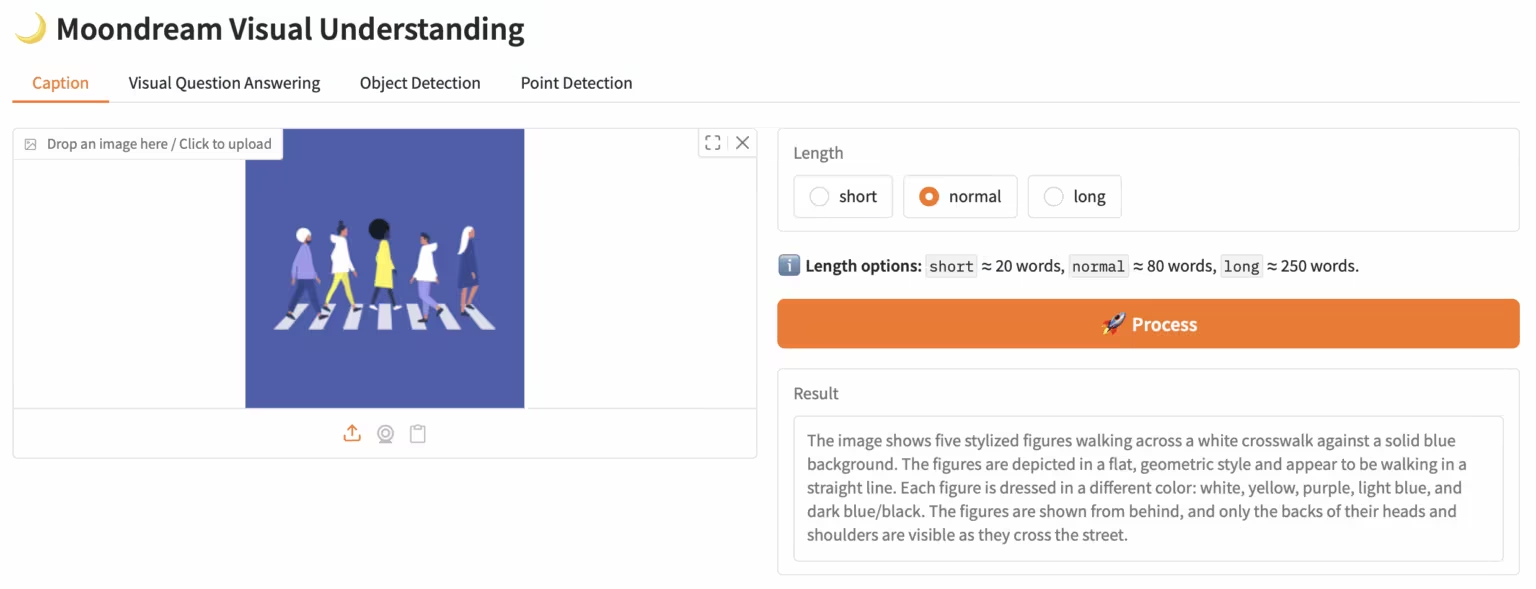
3. Moondream3-preview: 모듈형 시각 언어 이해 모델
Moondream 팀이 제안한 하이브리드 전문가 아키텍처 기반의 시각 언어 모델인 Moondream3는 90억 개의 매개변수(그중 20억 개는 활성화 매개변수)를 자랑합니다. 이 모델은 최첨단 시각 추론 기능을 제공하고, 최대 32KB의 컨텍스트 길이를 지원하며, 고해상도 이미지도 효율적으로 처리할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/eKGcP
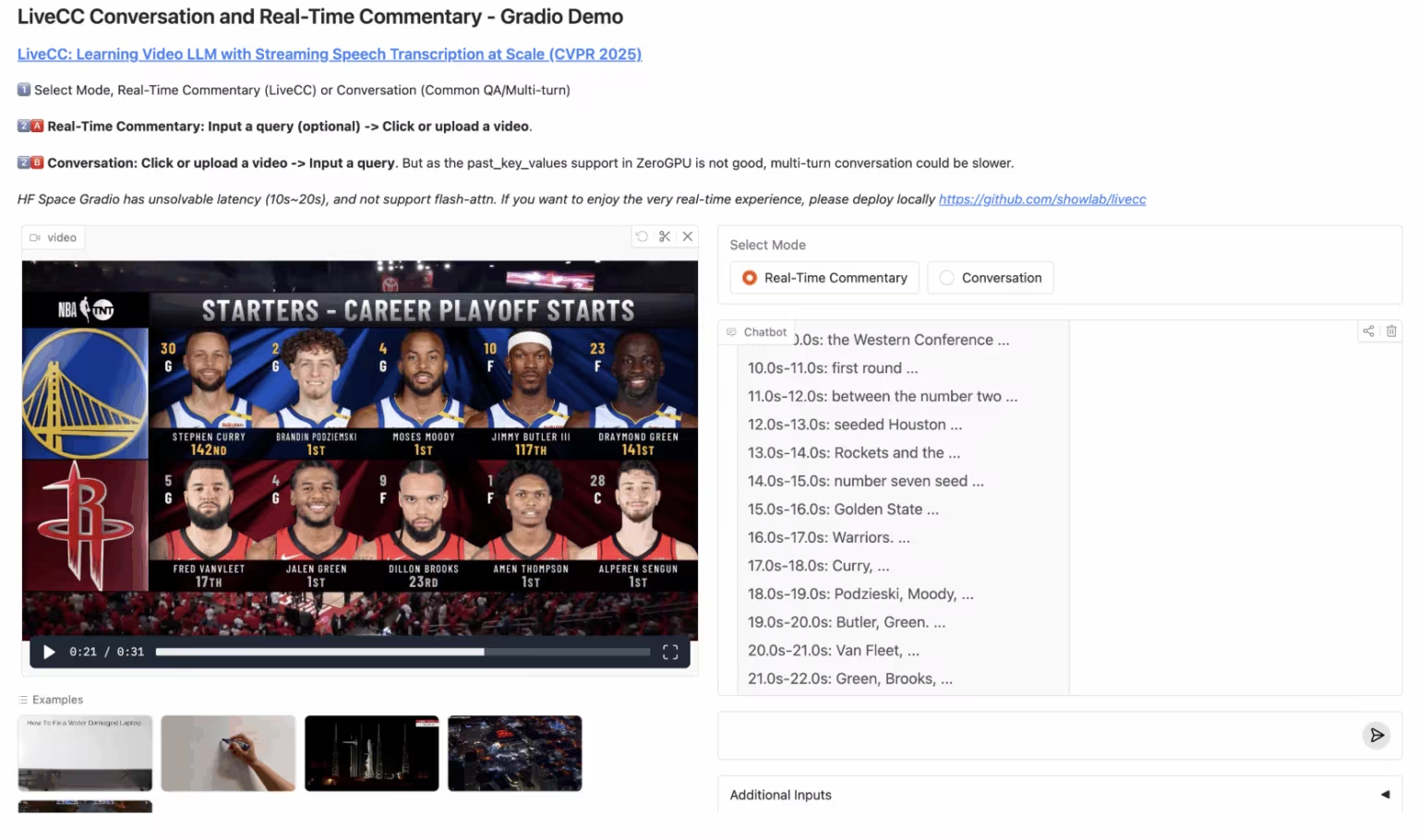
4. LiveCC: 실시간 영상 해설 대형 모델
LiveCC는 대규모 스트리밍 음성 전사에 중점을 둔 비디오 언어 모델 프로젝트입니다. 이 프로젝트는 혁신적인 비디오 자동 음성 인식(ASR) 스트리밍 방식을 통해 실시간 해설 기능을 갖춘 최초의 비디오 언어 모델을 학습하는 것을 목표로 합니다. 스트리밍 및 오프라인 벤치마크 모두에서 최첨단 기술을 달성했습니다.
온라인으로 실행:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part: 구성 요소 기반 3D 생성 모델
텐센트 훈위안 팀이 개발한 3D 생성 모델인 훈위안3D-파트는 P3-SAM과 X-Part로 구성되어 있습니다. 50개 이상의 구성 요소를 자동으로 생성할 수 있도록 고정밀 제어 가능한 구성 요소 기반 3D 모델 생성의 선구자입니다. 게임 모델링 및 3D 프린팅과 같은 분야에서 폭넓게 활용되고 있으며, 게임별 스크롤 로직을 구현하기 위해 자동차 모델을 차체와 바퀴로 분리하거나 단계별 3D 프린팅을 구현하는 데 활용됩니다.
온라인으로 실행:https://go.hyper.ai/1w1Jq

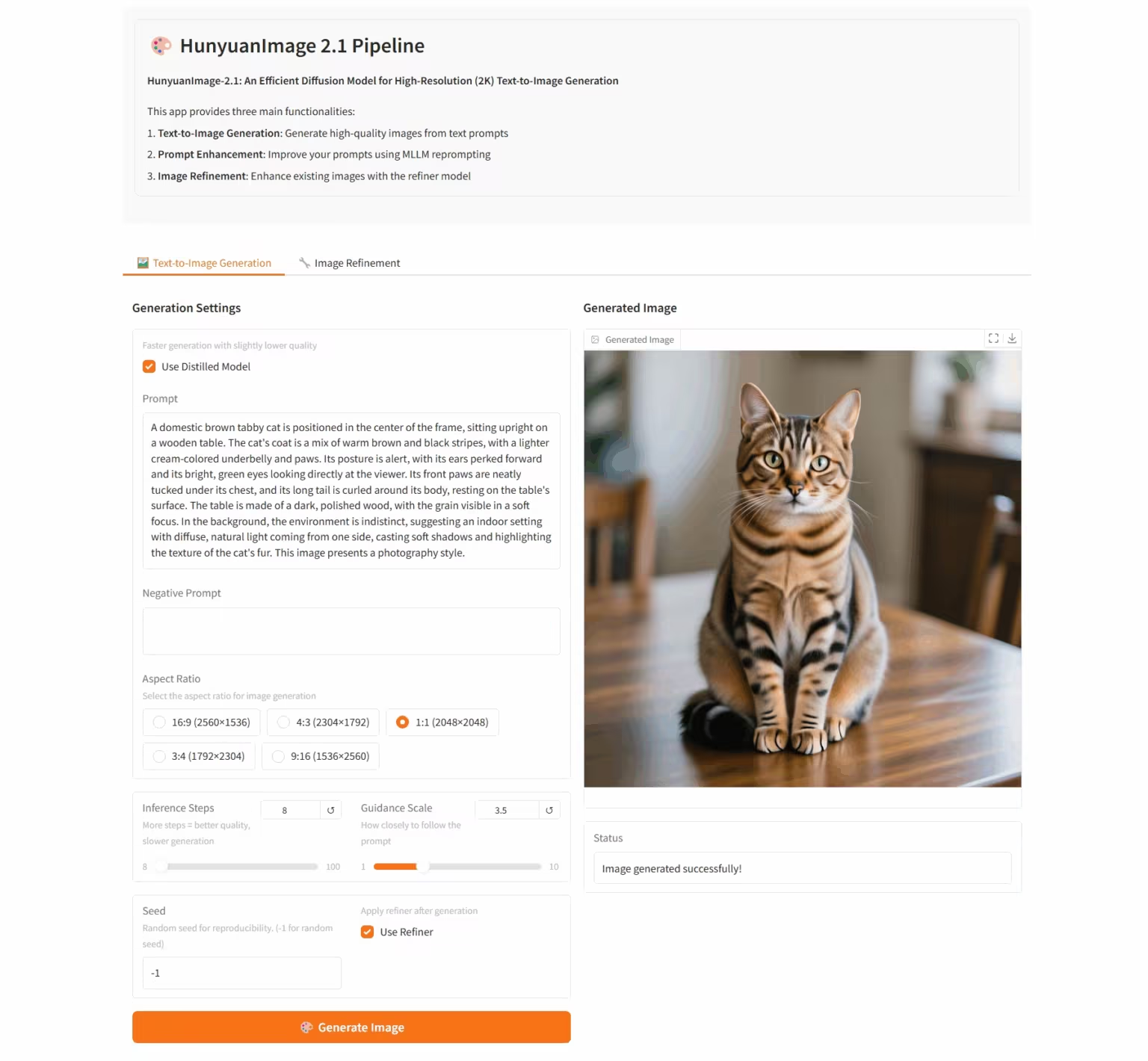
6. HunyuanImage-2.1: 고해상도(2K) Wensheng 이미지에 대한 확산 모델
HunyuanImage-2.1은 텐센트 Hunyuan 팀이 개발한 오픈소스 텍스트 기반 이미지 모델입니다. 네이티브 2K 해상도를 지원하고 강력한 복합 의미 이해 기능을 갖추고 있어 장면 세부 정보, 캐릭터 표현 및 동작을 정확하게 생성할 수 있습니다. 이 모델은 중국어와 영어 입력을 모두 지원하며, 만화나 액션 피규어 등 다양한 스타일의 이미지를 생성할 수 있으며, 이미지 내 텍스트와 세부 정보에 대한 강력한 제어 기능을 유지합니다.
온라인으로 실행:https://go.hyper.ai/i96yp
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. QeRL: 효율성을 넘어 - LLM을 위한 양자화 강화 학습
본 논문에서는 대규모 언어 모델을 위한 양자화 강화 학습 프레임워크인 QeRL을 제안합니다. NVFP4 양자화와 저랭크 적응(LoRA)을 결합한 이 모델은 메모리 오버헤드를 크게 줄이면서 강화 학습 샘플링 단계를 가속화합니다. QeRL은 단일 H100 80GB GPU에서 320억 개의 매개변수(32B)를 갖는 대규모 강화 학습 모델을 학습하는 동시에 전반적인 학습 속도를 향상시킬 수 있는 최초의 프레임워크입니다.
논문 링크: https://go.hyper.ai/catLh
2. 표현 자동 인코더를 갖춘 확산 변환기
본 논문에서는 VAE를 사전 훈련된 표현 인코더(예: DINO, SigLIP, MAE)와 사전 훈련된 디코더를 결합하여 표현 오토인코더(RAE)라고 불리는 새로운 아키텍처를 구축하는 방법을 살펴봅니다. 이러한 모델은 고품질 재구성을 달성할 뿐만 아니라, 의미적으로 풍부한 잠재 공간을 보유하고 확장 가능한 트랜스포머 기반 아키텍처 설계를 지원합니다.
논문 링크: https://go.hyper.ai/fqVs4
3. D2E: 구현된 AI로의 전송을 위한 데스크톱 데이터의 비전-액션 사전 학습 확장
본 논문은 D2E(Desktop to Embodied AI) 프레임워크를 제안하며, 데스크톱 상호작용이 로봇 구현 AI 작업을 위한 효과적인 사전 훈련 기반으로 활용될 수 있음을 보여줍니다. 특정 도메인이나 데이터로 제한되었던 기존 접근 방식과 달리, D2E는 확장 가능한 데스크톱 데이터 수집부터 구현 도메인 검증 및 마이그레이션까지 완전한 기술 체인을 구축합니다.
논문 링크: https://go.hyper.ai/aNbE4
4. 카메라로 생각하기: 카메라 중심 이해 및 생성을 위한 통합 멀티모달 모델
본 논문에서는 카메라 차원을 따라 공간적 인식을 확장하고, 언어 회귀를 확산 기반 생성 기술과 융합하고, 임의의 관점에서 장면을 구문 분석하고 생성할 수 있는 통합된 카메라 중심의 다중 모드 모델인 퍼핀을 제안합니다.
논문 링크: https://go.hyper.ai/9JBvw
5. DITING: 웹 소설 번역 벤치마킹을 위한 다중 에이전트 평가 프레임워크
본 논문은 온라인 소설 번역을 위한 최초의 종합 평가 프레임워크인 DITING을 제안합니다. DITING은 관용어 번역, 어휘 모호성 처리, 용어 현지화, 시제 일관성, 대명사 무분별 해결, 문화적 안전성의 여섯 가지 측면에서 번역의 서사적 일관성과 문화적 충실성을 체계적으로 평가하며, 전문가가 주석을 단 18,000개 이상의 중국어-영어 문장 쌍을 기반으로 합니다.
논문 링크:https://go.hyper.ai/KRUmn
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 홍콩과학기술대학교 등은 751개 매개변수를 단순화하면서도 최첨단 성능을 달성한 증분형 기상예보 모델 VA-MoE를 제안했습니다.
홍콩과학기술대학교와 저장대학교 연구팀은 가변 적응 전문가 혼합(VA-MoE) 모델을 개발했습니다. 이 모델은 단계적 학습과 변수 인덱스 임베딩을 사용하여 다양한 전문가 모듈이 특정 기상 변수에 집중하도록 안내합니다. 새로운 변수나 관측소가 추가되면 모델을 완전히 재학습하지 않고도 확장할 수 있어 정확도를 유지하면서도 계산 오버헤드를 크게 줄일 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/nPWPN
2. NeurIPS 2025 | 화중과학기술대학교 등에서 OCRBench v2를 출시했습니다. Gemini는 중국 랭킹에서 1위를 차지했지만 합격점만 받았습니다.
화중과학기술대학의 바이샹 팀은 남중국이공대학, 애들레이드 대학, 바이트댄스와 협력하여 차세대 OCR 평가 벤치마크인 OCRBench v2를 출시했습니다. 이 벤치마크는 2023년부터 2025년까지 전 세계의 58개 주류 멀티모달 모델을 중국어와 영어로 평가했습니다.
전체 보고서 보기:https://go.hyper.ai/AL1ZJ
3. 토론토 대학과 다른 연구자들은 NeurIPS 2025에 선정되어 특정 세포의 유전자 발현을 "표적적으로 제어"하기 위해 Ctrl-DNA 프레임워크를 제안했습니다.
토론토 대학의 한 팀은 창핑 연구실과 협력하여 Ctrl-DNA라는 제한적 강화 학습 프레임워크를 개발했습니다. 이 프레임워크는 표적 세포에서 CRE의 조절 활동을 극대화하는 동시에 비표적 세포에서의 활동을 엄격하게 제한할 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/eVORr
4. AI가 플라즈마 폭주를 예측합니다. MIT를 비롯한 연구진은 머신러닝을 활용하여 적은 표본 크기로 플라즈마 역학을 고정밀도로 예측합니다.
MIT가 이끄는 연구팀은 과학적 머신러닝을 사용하여 물리 법칙과 실험 데이터를 지능적으로 융합했습니다. 그들은 최소한의 데이터만으로 토카막 구성 변수(TCV) 램프 다운 과정에서 플라즈마 동역학과 잠재적 불안정성을 예측할 수 있는 신경 상태 공간 모델을 개발했습니다.
전체 보고서 보기:https://go.hyper.ai/HQgZx
5. MOF 구조, 36년 만에 노벨상 수상: AI가 화학을 이해하면 금속-유기 구조체는 생성적 연구 시대로 접어들게 됩니다.
2025년 10월 8일, 키타가와 스스무, 리처드 롭슨, 오마르 야기가 금속-유기 골격체(MOF) 분야에 기여한 공로로 노벨 화학상을 수상했습니다. 지난 30년 동안 MOF 분야는 구조 설계에서 산업화로 발전하며 계산화학의 기반을 마련했습니다. 오늘날 인공지능은 생성 모델과 확산 알고리즘을 통해 MOF 연구를 혁신하며 화학 설계의 새로운 시대를 열고 있습니다.
전체 보고서 보기:https://go.hyper.ai/U5XgN
인기 백과사전 기사
1. 달-이
2. 하이퍼네트워크
3. 파레토 전선
4. 양방향 장단기 메모리(Bi-LSTM)
5. 상호 순위 융합
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
10월 컨퍼런스 마감일

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1800개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 600개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 200개 이상의 AI4Science 논문 사례 해석
* 600개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.