Command Palette
Search for a command to run...
TCR 서열의 세밀한 특성 분석 달성! 딥러닝 프레임워크 DeepTCR은 5만 명의 폐암 환자 데이터를 기반으로 면역학 연구 방법을 확장합니다! 폐암 위험(Lung Cancer Risk)은 폐암 위험 요인에 대한 자세한 정보를 제공합니다.

T 세포 수용체 시퀀싱(TCR-Seq)은 차세대 시퀀싱(NGS) 기술의 중요한 응용 분야로, 연구자들이 적응 면역 반응의 다양성을 체계적으로 분석할 수 있도록 지원합니다. T 세포 수용체 시퀀싱 데이터 분석에는 모티프 검색이나 서열 정렬과 같은 기존 방법들이 성과를 거두었지만, 점차 한계점에 부딪히고 있습니다.신체에서 낮은 빈도의 항원 특이적 T 세포 반응을 식별할 때, 그 신호는 많은 수의 비특이적 T 세포 배경에 의해 압도되는 경우가 많습니다.이는 기존 방법이 노이즈에서 신호를 식별하는 데 직면하는 어려움을 반영합니다.
TCR 시퀀스에 대한 더욱 정교한 특성화에 대한 수요가 계속해서 증가함에 따라 연구자들은 합성곱 신경망(CNN)으로 대표되는 딥 러닝 기술에 주목하고 있습니다.DeepTCR은 딥러닝 기반 면역 수용체 시퀀싱 분석 프레임워크로 등장했습니다.이 프레임워크는 TCR 시퀀싱 면역 레퍼토리 데이터에서 CDR3 시퀀스, V/D/J 유전자 사용 및 MHC 분자 유형 특성을 학습하고 매우 복잡한 TCR 시퀀싱 데이터를 모델링하기 위한 공동 표현을 구성할 수 있습니다.
DeepTCR은 TCR 시퀀스 분석에 딥러닝 프레임워크를 체계적으로 적용하여 면역학 연구의 분석 방법을 확장할 뿐만 아니라, 다양한 분야에서 딥러닝 기술이 폭넓게 적용 가능하다는 것을 더욱 입증했습니다.
HyperAI 공식 웹사이트에 "DeepTCR: 딥러닝을 활용한 TCR-펩타이드 친화도 예측"이 출시되었습니다. 지금 바로 체험해 보세요!
온라인 사용:https://go.hyper.ai/gKmgi
9월 8일부터 9월 12일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 10
* 엄선된 고품질 튜토리얼: 2개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 9월 마감일 상위 컨퍼런스: 5개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. 새로운 식물 질병 식물 질병 이미지 데이터 세트
New Plant Diseases는 식물 질병 식별 및 잎 분류 연구를 위한 이미지 데이터셋입니다. 건강한 잎과 다양한 질병 유형을 포괄합니다. 특히 작물 건강 모니터링, 질병 식별, 정밀 농업 모델 및 학술 연구 분야에서 머신러닝 및 딥러닝 모델 개발 및 평가에 널리 적합하며, 중요한 벤치마크 가치를 지닙니다.
직접 사용: https://go.hyper.ai/RKYtW

2. 인텔 이미지 분류 자연 장면 이미지 분류 데이터 세트
인텔 이미지 분류(Intel Image Classification)는 인텔에서 공개한 이미지 분류 데이터셋으로, 자연경관과 인공경관 이미지를 분류하는 데 사용됩니다. 이 데이터셋에는 건물과 숲을 포함한 6가지 범주에 걸쳐 약 25,000개의 컬러 이미지가 포함되어 있습니다.
직접 사용: https://go.hyper.ai/qgbeX

3. LongPage 소설 추론 데이터 세트
LongPage는 복잡한 추론 기능을 갖춘 완전한 소설을 작성하도록 인공지능 모델을 훈련하기 위한 최초의 포괄적인 데이터셋입니다. 강화 학습 훈련 프로세스에 대한 콜드 스타트 지도 학습 미세 조정을 지원하며, 계층적 추론 기능을 갖춘 대규모 언어 모델을 훈련하고 장문 글쓰기의 일관성과 계획을 개선하는 데 적합합니다.
직접 사용: https://go.hyper.ai/odoKA
4. 폐암 위험 데이터 세트
폐암 위험(Lung Cancer Risk)은 폐암 위험 예측 및 건강 요인 분석을 위한 테이블 형식 데이터셋입니다. 다차원 특성을 통해 흡연 습관, 생활 습관, 그리고 폐암 위험 간의 연관성을 탐구하는 것을 목표로 합니다. 폐암 위험 모델링, 의료 머신러닝 연구, 건강 예측 시스템 개발 및 교육 실험에 적합합니다. 특히 분류 모델링 및 위험 평가 시나리오에서 유용합니다.
직접 사용:https://go.hyper.ai/YGFzG
5. IFEval-Inverse 역방향 명령어 평가 데이터 세트
IFEval-Inverse는 ByteDance Seed가 난징대학교, 칭화대학교 및 기타 기관들과 협력하여 공개한 대규모 언어 모델을 위한 적대적 명령어 평가 데이터셋입니다. 이 데이터셋은 역방향 또는 비정상 명령어에 직면했을 때 모델이 학습 관성을 깨고 진정한 명령어 준수를 달성할 수 있는지 검증하는 것을 목표로 합니다.
직접 사용: https://go.hyper.ai/IcTqj
6. FinReflectKG 금융 지식 그래프 데이터 세트
FinReflectKG는 금융 분야를 위한 대규모 지식 그래프 데이터셋입니다. 기업 규제 문서에서 구조화된 의미 관계를 추출하고 금융 분야의 지식 그래프 연구 발전을 촉진하는 것을 목표로 합니다. 개체 인식, 관계 추출, 지식 그래프 구축, 시계열 분석, 대규모 언어 모델 기반 정보 추출 평가 및 금융 분야의 다운스트림 금융 지능형 애플리케이션 개발에 적합합니다.
직접 사용: https://go.hyper.ai/EB5em
7. WenetSpeech Yue 광둥어 코퍼스 데이터 세트
WenetSpeech Yue는 광둥어 음성 인식(ASR) 및 텍스트 음성 합성(TTS)을 위한 대규모 다차원 주석 음성 코퍼스입니다. WenetSpeech Yue는 광둥어 분야의 부족한 자원을 메우고 고품질 광둥어 모델의 학습 및 평가를 촉진하는 것을 목표로 합니다.
직접 접속: https://go.hyper.ai/cICOv
8. UCIT 연속 교육 튜닝 데이터 세트
UCIT는 대규모 멀티모달 언어 모델의 지속적인 명령어 튜닝을 위한 벤치마크 데이터셋입니다. 이 데이터셋의 각 샘플은 작업 설명(프롬프트/명령)과 그에 상응하는 정확한 실행 기대값(실제 응답)으로 구성되며, 이는 제로샷 조건에서 모델의 성능을 측정하는 데 사용됩니다.
직접 사용: https://go.hyper.ai/TZPwY
9. LoongBench 다중 도메인 추론 벤치마크 데이터 세트
LoongBench는 LLM에 다중 도메인의 검증 가능한 학습 및 평가 리소스를 제공하도록 설계된 다중 도메인 추론 평가 데이터셋입니다. 이 데이터셋은 고급 수학 및 고급 물리학을 포함한 12개의 추론 중심 영역을 포괄하는 8,729개의 자연어 질문을 포함합니다.
직접 사용: https://go.hyper.ai/AcFOZ
10. CA‑1 인간 선호도 정렬 데이터 세트
CA-1은 AI 모델의 기본 행동에 대한 인간의 가치 판단과 선호도에 초점을 맞춥니다. 이는 모델에서 생성된 콘텐츠와 주석자 평가를 결합한 인간 피드백 행동 데이터셋입니다. 집단 편향 차이 연구, 모델 행동 규범 설정, 그리고 가치 기반 보상 메커니즘 개발에 적합합니다.
직접 사용: https://go.hyper.ai/mXznO
선택된 공개 튜토리얼
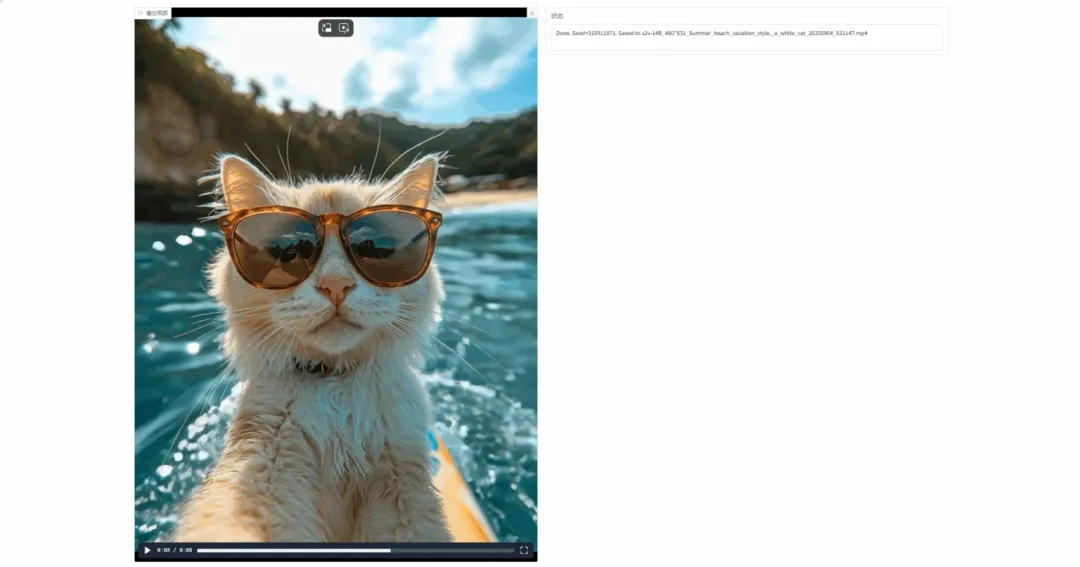
1. Wan2.2-S2V-14B: 필름급 오디오 기반 비디오 생성
Wan2.2-S2V-14B는 Alibaba Tongyi Wanxiang 팀이 개발한 오픈 소스 오디오 기반 비디오 생성 모델입니다. 단 하나의 정지 이미지와 오디오만 사용하여 최대 몇 분 길이의 영화급 디지털 휴먼 비디오를 생성할 수 있으며, 다양한 이미지 유형과 크기를 지원합니다. 이 모델은 여러 혁신적인 기술을 통합하여 복잡한 장면에 대한 오디오 기반 비디오 생성을 가능하게 하며, 긴 비디오 생성과 다중 해상도 학습 및 추론을 지원합니다.
온라인 실행: https://go.hyper.ai/TlSai
2. DeepTCR: TCR-펩타이드 친화도 예측을 위한 딥러닝
DeepTCR은 TCR 시퀀싱 면역 레퍼토리 데이터로부터 친화도를 예측하고, TCR CDR3 서열, V/D/J 유전자 사용 또는 MHC 분자 유형 특성을 추출 및 학습하며, TCR을 공동으로 표현하여 매우 복잡한 TCR 시퀀싱 데이터를 모델링할 수 있는 딥러닝 기반 면역 수용체 시퀀싱 분석 프레임워크입니다. 배경 잡음을 고려한 단일 세포 RNA-Seq 및 T 세포 배양 기반 분석에서 항원 특이적 TCR을 추출할 수 있습니다.
온라인 실행: https://go.hyper.ai/gKmgi
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. 공유는 배려입니다: 집단적 RL 경험 공유를 통한 효율적인 LM 사후 훈련
본 논문은 완전히 분산화된 비동기 강화 학습 사후 학습 알고리즘인 Swarm sAmpling Policy Optimization(SAPO)을 제안합니다. SAPO는 이기종 컴퓨팅 노드로 구성된 분산형 네트워크를 위해 설계되었습니다. 각 노드는 다른 노드와 궤적을 "공유"하면서 자체 정책 모델을 자율적으로 관리합니다. 이 알고리즘은 지연 시간, 모델 동질성 또는 하드웨어 구성에 대한 명시적인 가정에 의존하지 않으며, 노드는 필요에 따라 독립적으로 작동할 수 있습니다.
논문 링크: https://go.hyper.ai/MWeWF
2. 언어 모델이 환각을 겪는 이유
본 논문은 언어 모델이 환각을 경험하는 근본적인 이유는 학습 및 평가 메커니즘이 불확실성을 인정하기보다는 추측에 가치를 부여하는 경향이 있기 때문이라고 주장합니다. 또한 현대 학습 과정에서 환각의 통계적 원인을 분석합니다. 대규모 모델이 불확실한 응답에 대해 부과하는 체계적인 페널티는 환각을 평가하기 위한 추가적인 지표를 도입하기보다는, 현재 주류이지만 편향된 벤치마크 채점 방식을 수정해야 함을 시사합니다.
논문 링크: https://go.hyper.ai/eXoOR
3. 개방형 생성을 위한 역공학적 추론
본 논문은 추론의 구성 방식을 근본적으로 바꾸는 새로운 패러다임인 역공학 추론(REER)을 제안합니다. 시행착오나 모방을 통해 상향식으로 추론 과정을 구축하는 기존 방식과 달리, REER은 "역" 전략을 채택합니다. 알려진 고품질 솔루션에서 시작하여, 이러한 솔루션을 생성할 수 있는 잠재적인 단계별 심층 추론 경로를 계산적으로 발견합니다.
논문 링크: https://go.hyper.ai/xFygJ
4. Parallel-R1: 강화 학습을 통한 병렬적 사고로의 전환
본 논문은 병렬적 사고 행동을 가능하게 하는 복잡한 현실 세계 추론 과제를 위한 최초의 강화 학습(RL) 프레임워크인 Parallel-R1을 제시합니다. 이 프레임워크는 점진적인 커리큘럼 설계를 통해 강화 학습에서 병렬적 사고를 훈련하는 데 있어 콜드 스타트 문제를 명확하게 해결합니다.
논문 링크: https://go.hyper.ai/s2OlH
5. WebExplorer: 장기 웹 에이전트 교육을 위한 탐색 및 진화
본 논문은 신중하게 구축된 고품질 데이터셋을 활용하여, 강화 학습과 결합된 지도 학습 미세 조정을 통해 최첨단 웹 프록시 모델인 WebExplorer-8B를 성공적으로 학습시켰습니다. 이 모델은 최대 128KB의 컨텍스트 길이를 지원하고 최대 100개의 도구 호출을 실행할 수 있어 장기 문제 해결이 가능합니다. 여러 정보 검색 벤치마크에서 WebExplorer-8B는 유사한 크기의 모델들 중에서 최고 수준의 성능을 달성했습니다.
논문 링크: https://go.hyper.ai/NusbG
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 홍콩 중국 대학과 다른 연구진은 유전자 발현 데이터와 세포 형태 이미지를 연관시켜 전사체 유도 확산 모델을 개발하여 표현형 약물 개발을 가속화했습니다.
홍콩 중국대학교, 모하메드 빈 자이드 인공지능대학교 및 기타 기관의 연구진은 확장 가능한 전사체 유도 확산 모델인 MorphDiff를 제안했습니다. 이 모델은 세포 형태가 교란에 반응하는 것을 높은 정확도로 시뮬레이션하도록 특별히 설계되었습니다. 잠재 확산 모델(LDM) 아키텍처를 기반으로 하는 이 모델은 L1000 유전자 발현 프로파일을 노이즈 제거 학습을 위한 조건부 입력으로 사용합니다.
전체 보고서 보기: https://go.hyper.ai/f7WeP
2. 중국석유대학 연구팀은 "블라인드 스크리닝"에서 "정밀 위치 결정"까지 PPI 계면 개질제 예측에 있어 기존 방법을 능가하는 AlphaPPIMI를 출시했습니다.
중국석유대학교와 연세대학교의 공동 연구팀은 여러 첨단 기술을 통합하여 AlphaPPIMI라는 새로운 프레임워크를 개발했습니다. 대규모 사전 학습된 모델과 적응형 학습 메커니즘을 결합한 이 도구는 PPI 계면을 특이적으로 표적으로 하는 조절 인자를 발견하는 핵심 과제를 해결하여 향후 PPI 표적 약물 개발에 강력한 기반을 제공합니다.
전체 보고서 보기: https://go.hyper.ai/4tp0M
3. Apple Intelligence가 완벽하게 구현되었으며 핵심 제품 AI 기능이 업그레이드되었습니다: 실시간 번역/시각 지능/고혈압 모니터링
9월 10일 베이징 시간 오전 1시, Apple의 2025년 가을 컨퍼런스는 전적으로 AI에 초점을 맞춰 iPhone 17, Apple Watch Series 11, AirPods Pro 3 등 세 가지 핵심 제품에 대한 AI 업그레이드를 발표했습니다. Apple Intelligence는 작년 컨셉트 쇼케이스에서 실시간 번역, 건강 모니터링, 시각 지능 등의 시나리오를 포괄하는 본격적인 구현으로 발전했습니다. 차세대 A19 및 M19 Pro 칩은 Apple 컴퓨팅 성능의 초석 역할을 합니다.
전체 보고서 보기: https://go.hyper.ai/IimjS
우한대학교와 난양이공대학교 연구팀은 대화, 기억, 처리의 세 가지 요소로 구성된 헬스케어 에이전트를 공동으로 개발했습니다. 이 에이전트는 환자의 의료 목적을 파악하고 의료 윤리 및 안전 문제를 자동으로 감지할 수 있습니다.
전체 보고서 보기: https://go.hyper.ai/AdG2j
5. 애플 인수설부터 ASML의 대주주 되기 위한 13억 달러 투자까지, 미스트랄 AI의 기술·사업 비밀 파헤쳐
9월 초, 애플이 프랑스 스타트업 미스트랄 AI(Mistral AI) 인수에 관심을 보였다는 보도가 나왔습니다. 반도체 대기업 ASML도 뒤이어 13억 유로를 투자하며 시리즈 C 투자 라운드에서 선두를 달렸습니다. 현재 미스트랄 AI의 기업 가치는 140억 달러로 치솟으며 유럽 AI 분야를 선도하는 기업으로 자리매김했습니다.
전체 보고서 보기: https://go.hyper.ai/zsQBu
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
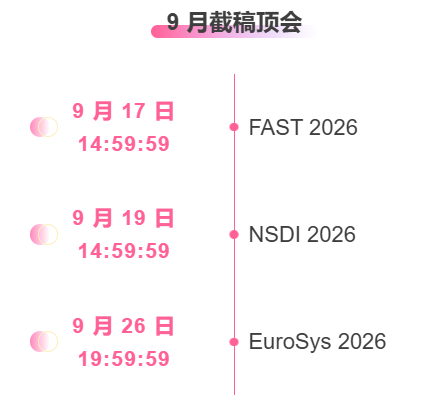
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1800개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 600개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 200개 이상의 AI4Science 논문 사례 해석
* 600개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.