Command Palette
Search for a command to run...
270M 경량 모델! Gemma-3-270M-IT는 가벼운 장문 텍스트 상호작용에 중점을 두고 있으며, 크로스 플랫폼 GUI 에이전트를 위한 최고의 선택입니다! AgentNet은 200개 이상의 웹사이트를 지원합니다.

대규모 모델 매개변수의 규모가 계속 증가함에 따라, AI 사용에 대한 사용자들의 요구는 점차 다양해지고 있습니다. 한편으로는 복잡한 작업을 처리할 수 있는 고성능 모델이 필요하고, 다른 한편으로는 저사양 컴퓨팅 환경에서 가볍고 실용적인 대화 경험을 원합니다. 장문의 텍스트 대화와 일상적인 작업 시나리오에서,기존의 대형 모델은 높은 컴퓨팅 파워 지원이 필요할 뿐만 아니라 응답 지연, 컨텍스트 손실 또는 불일치 생성 문제가 발생하기 쉽기 때문에 "사용하기 쉽고, 사용하기 쉬우며, 잘 실행되는" 경량 모델을 긴급하게 해결해야 할 문제점으로 만들었습니다.
이를 바탕으로 구글은 경량형 명령어 미세조정 모델 Gemma-3-270M-IT를 출시했습니다.매개변수는 2억 7천만 개에 불과하지만, 단일 카드 1GB 비디오 메모리 환경에서 원활하게 실행될 수 있어 로컬 배포에 대한 한계를 크게 낮춥니다.또한 32K 토큰 컨텍스트 윈도우를 지원하여 장문의 텍스트 대화와 문서 처리가 가능합니다. 일상적인 질의응답 세션과 간단한 작업을 위한 특화된 미세 조정을 통해 Gemma-3-270M-IT는 가볍고 효율적인 작동을 유지하는 동시에 대화형 상호작용의 실용성을 균형 있게 유지합니다.
Gemma-3-270M-IT는 또 다른 개발 경로를 보여줍니다. "더 크고 더 강력함"의 추세 외에도,가볍고 긴 컨텍스트 지원을 통해 엣지 배포와 포괄적인 애플리케이션에 대한 새로운 가능성을 제공합니다.
HyperAI Hyperneuron 공식 웹사이트에서 "vLLM + Open WebUI 배포 gemma-3-270m-it" 기능이 출시되었습니다. 지금 바로 사용해 보세요!
온라인 사용:https://go.hyper.ai/kBjw3
8월 25일부터 8월 29일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 12
* 고품질 튜토리얼 선택: 4개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 6개 기사
* 인기 백과사전 항목: 5개
* 9월 마감일 상위 컨퍼런스: 5개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. Nemotron-Post-Training-Dataset-v2 훈련 후 데이터 세트
Nemotron-Post-Training-Dataset-v2는 NVIDIA의 기존 사후 학습 코퍼스를 확장한 것입니다. 이 데이터셋은 SFT(과학, 기술, 공학, 수학) 및 RL(강화학습) 데이터를 5개 대상 언어(스페인어, 프랑스어, 독일어, 이탈리아어, 일본어)로 확장하여 수학, 코딩, STEM(과학, 기술, 공학, 수학) 및 대화와 같은 시나리오를 포괄합니다.
직접 사용: https://go.hyper.ai/lSIjR
2. Nemotron-CC-v2 사전 학습 데이터 세트
Nemotron-CC-v2는 2024년부터 2025년까지의 8개의 Common Crawl 스냅샷을 원본 영어 웹페이지 코퍼스에 추가하고, 글로벌 중복 제거 및 영어 필터링을 수행합니다. 또한 Qwen3-30B-A3B를 사용하여 웹페이지 콘텐츠를 합성하고 재구성하며, 다양한 질문과 답변을 추가하고 15개 언어로 번역하여 다국어 논리적 추론 및 일반 지식 사전 훈련을 강화합니다.
직접 사용: https://go.hyper.ai/xRtbR
3.Nemotron-사전 훈련-데이터셋-샘플 샘플링 데이터셋
Nemotron-Pretraining-Dataset-sample에는 전체 SFT 및 사전 학습 코퍼스의 다양한 구성 요소에서 선택한 10개의 대표적인 하위 집합이 포함되어 있으며, 검토 및 빠른 실험에 적합한 고품질 질의 응답 데이터, 수학 중심 추출물, 코드 메타데이터 및 SFT 스타일 지침 데이터가 포함됩니다.
직접 사용: https://go.hyper.ai/xzwY5
4. Nemotron-Pretraining-Code-v1 코드 데이터 세트
Nemotron-Pretraining-Code-v1은 GitHub에 구축된 대규모 큐레이션 코드 데이터셋입니다. 이 데이터셋은 다단계 중복 제거, 라이선스 적용, 휴리스틱 품질 검사를 거쳐 필터링되었으며, LLM에서 생성된 11개 프로그래밍 언어로 작성된 코드 질의응답 쌍을 포함하고 있습니다.
직접 사용: https://go.hyper.ai/DRWAw
5. Nemotron-Pretraining-SFT-v1 지도 미세 조정 데이터 세트
Nemotron-Pretraining-SFT-v1은 STEM, 학문적, 논리적 추론 및 다국어 시나리오를 위해 설계되었습니다. 고품질 수학 및 과학 자료를 기반으로 생성되었으며, 대학원 수준의 학술 텍스트와 사전 훈련된 SFT 데이터를 결합하여 복잡한 객관식 및 분석 문제(완전한 답/생각 포함)를 구성합니다. 이 문제는 수학, 코딩, 일반 상식 및 논리적 추론을 포함한 다양한 과제를 다룹니다.
직접 사용: https://go.hyper.ai/g568w
6. Nemotron-CC-Math 수학 사전 학습 데이터 세트
Nemotron-CC-Math는 수학에 중점을 둔 고품질의 대규모 사전 학습된 데이터셋입니다. 1,330억 개의 토큰을 포함하는 이 데이터셋은 방정식과 코드의 구조를 보존하는 동시에 수학적 내용을 편집 가능한 LaTeX 형식으로 통합합니다. 웹 규모에서 다양한 수학적 형식(롱테일 형식 포함)을 안정적으로 지원하는 최초의 데이터셋입니다.
직접 사용: https://go.hyper.ai/aEGc4
7. Echo-4o-Image 합성 이미지 생성 데이터 세트
GPT-4o에서 생성된 Echo-4o-Image 데이터셋은 세 가지 작업 유형에 걸쳐 약 179,000개의 예시를 포함합니다. 복잡한 명령 실행(약 68,000개), 초현실적 판타지 생성(약 38,000개), 그리고 다중 참조 이미지 생성(약 73,000개)입니다. 각 예시는 1024×1024 해상도의 2×2 이미지 그리드로 구성되며, 이미지 경로, 피처(속성/주체), 그리고 생성된 프롬프트에 대한 구조화된 정보를 포함합니다.
직접 사용: https://go.hyper.ai/uLJEh

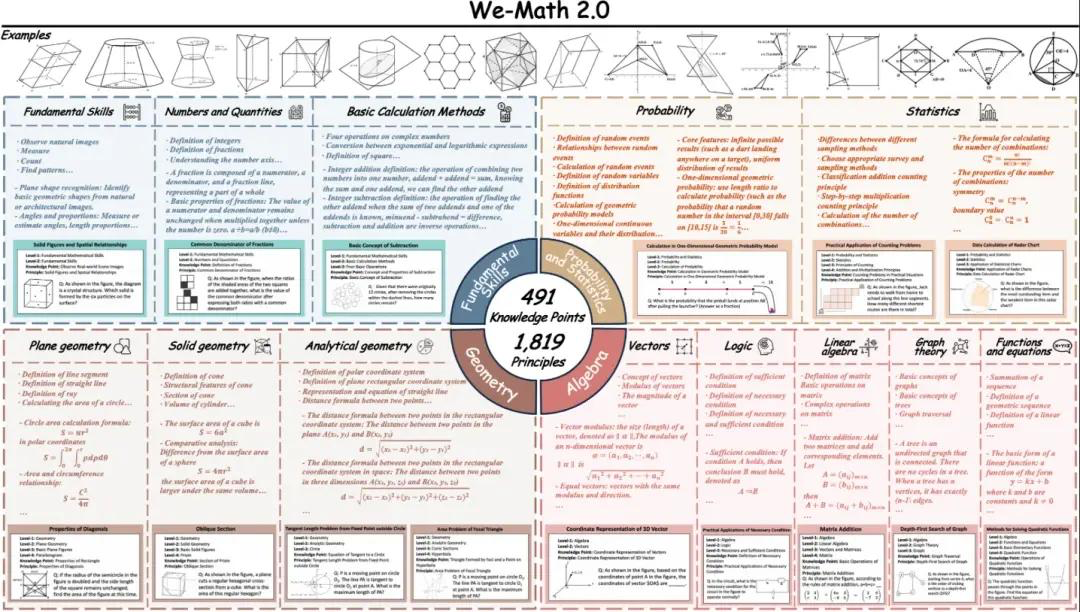
8. We-Math2.0-표준 시각적 수학적 추론 벤치마크 데이터 세트
We-Math2.0-Standard는 1,819개의 정확하게 정의된 원리를 중심으로 통합 라벨링 공간을 구축합니다. 각 문제에는 해당 원리가 명확하게 라벨링되고 엄격하게 큐레이션되어 전반적으로 광범위하고 균형 잡힌 내용을 제공하며, 특히 이전에는 제대로 표현되지 않았던 수학 하위 분야와 문제 유형을 강화합니다. 이 데이터셋은 문제당 여러 그림과 그림당 여러 질문을 포함하는 이중 확장 설계를 사용합니다.
직접 사용: https://go.hyper.ai/VlqK1
9. AgentNet 데스크톱 작업 작업 데이터 세트
AgentNet은 크로스 플랫폼 GUI 조작 에이전트와 시각-언어-행동 모델을 지원하고 평가하도록 설계된 최초의 대규모 데스크톱 컴퓨터 사용 에이전트 궤적 데이터셋입니다. 이 데이터셋에는 Windows, macOS, Ubuntu에서 수동으로 주석이 추가된 22.6K개의 컴퓨터 사용 작업 궤적과 200개 이상의 애플리케이션 및 웹사이트가 포함되어 있습니다. 시나리오는 사무, 업무, 일상 생활, 시스템 사용의 네 가지 범주로 분류됩니다.
직접 사용: https://go.hyper.ai/3DGDs
10. WideSearch 정보 수집 벤치마크 데이터 세트
WideSearch는 광역 정보 수집을 위해 특별히 설계된 최초의 벤치마크 데이터셋입니다. 이 벤치마크는 실제 사용자 질의에서 엄선하고 직접 정리한 200개의 고품질 질문(영어 100개, 중국어 100개)으로 구성되어 있습니다. 이 질문들은 15개 이상의 다양한 도메인에서 수집되었습니다.
직접 사용: https://go.hyper.ai/36kKj
11. MCD 멀티모달 코드 생성 데이터 세트
MCD는 명령어 기반 형식으로 구성된 약 598,000개의 고품질 예시/쌍을 제공합니다. 다양한 입력 방식(텍스트, 이미지, 코드)과 출력 방식(코드, 답변, 설명)을 지원하여 다중 방식 코드 이해 및 생성 작업에 적합합니다. 데이터에는 향상된 HTML 코드, 차트, 질문과 답변, 알고리즘이 포함됩니다.
직접 사용: https://go.hyper.ai/yMPeD
12. 라마-네모트론-훈련 후 데이터 세트 훈련 후 데이터 세트
Llama-Nemotron 학습 후 데이터셋은 학습 후 단계(예: SFT 및 RL)에서 Llama-Nemotron 계열 모델의 수학, 코딩, 일반 추론 및 지시 수행 능력을 향상시키도록 설계된 대규모 학습 후 데이터셋입니다. 이 데이터셋은 지도 학습 미세 조정 단계와 강화 학습 단계의 데이터를 결합합니다.
직접 사용: https://go.hyper.ai/Vk0Pk
선택된 공개 튜토리얼
1. Microsoft VibeVoice-1.5B, TTS 기술을 새롭게 정의하다경계
VibeVoice-1.5B는 팟캐스트와 같이 표현력이 풍부하고 장문의 다중 화자 대화 오디오를 생성하는 새로운 텍스트 음성 변환(TTS) 모델입니다. VibeVoice는 높은 충실도를 유지하면서 긴 오디오 시퀀스를 효율적으로 처리하고 최대 4명의 화자가 참여하는 최대 90분 분량의 음성 합성을 지원합니다.
온라인 작업:https://go.hyper.ai/Ofjb1
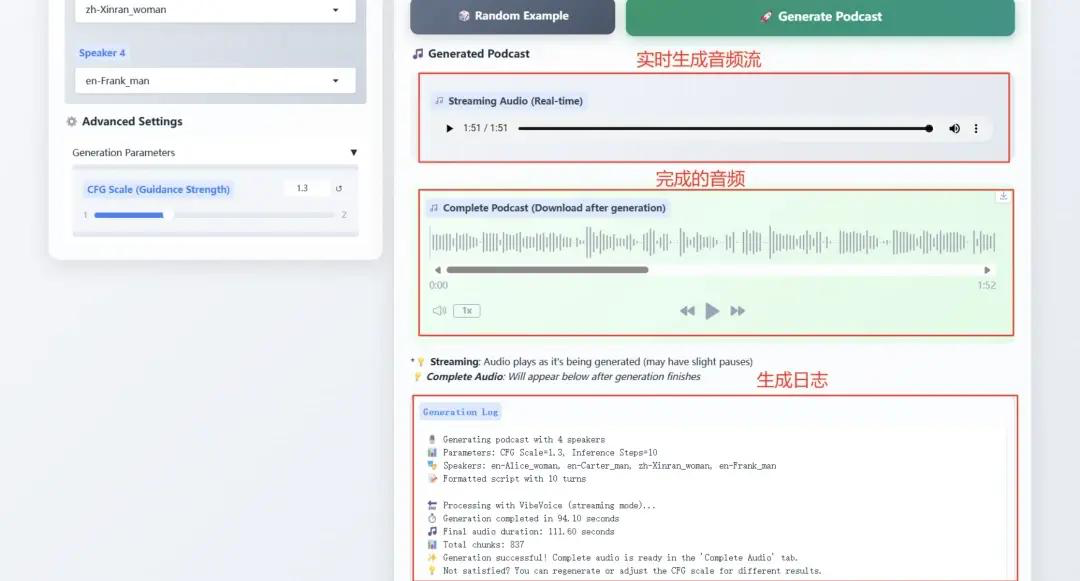
2. vLLM + Open WebUI로 NVIDIA-Nemotron-Nano-9B-v2 배포
NVIDIA-Nemotron-Nano-9B-v2는 Mamba의 효율적인 장시퀀스 처리와 Transformer의 강력한 시맨틱 모델링 기능을 혁신적으로 결합하여 단 90억(9B) 개의 매개변수만으로 128K 초장문 컨텍스트를 지원합니다. RTX 4090급 GPU와 같은 엣지 컴퓨팅 디바이스에서의 추론 효율성과 작업 성능은 동일한 매개변수 규모를 가진 최첨단 모델과 유사합니다.
온라인 실행: https://go.hyper.ai/cVzPp
3. vLLM + 개방형 WebUI 배포 gemma-3-270m-it
gemma-3-270m-it은 효율적인 대화형 상호작용과 가벼운 배포에 중점을 두고 2억 7천만 개의 매개변수로 구축되었습니다. 이 가볍고 효율적인 모델은 단일 그래픽 카드에 1GB 이상의 그래픽 메모리만 필요하므로 엣지 기기 및 리소스가 부족한 상황에 적합합니다. 이 모델은 여러 차례의 대화를 지원하며, 일상적인 Q&A 및 간단한 작업 지시에 맞춰 특별히 미세 조정되었습니다. 텍스트 생성 및 이해에 중점을 두고 있으며, 3만 2천 개의 토큰으로 구성된 컨텍스트 윈도우를 지원하여 긴 텍스트 대화도 처리할 수 있습니다.
온라인 실행: https://go.hyper.ai/kBjw3

4. vLLM+Open WebUI 배포 Seed-OSS-36B-Instruct
Seed-OSS-36B-Instruct는 학습에 12조(12테라바이트)의 토큰을 사용했으며, 여러 주류 오픈소스 벤치마크에서 탁월한 성능을 달성했습니다. 가장 대표적인 특징 중 하나는 최대 512,000 토큰의 컨텍스트 길이를 지원하는 네이티브 롱 컨텍스트 기능입니다. 이를 통해 성능 저하 없이 매우 긴 문서와 추론 체인을 처리할 수 있습니다. 이 길이는 OpenAI의 최신 GPT-5 모델군의 두 배이며, 약 1,600페이지 분량의 텍스트에 해당합니다.
온라인 실행: https://go.hyper.ai/aKw9w

💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. Pass@1 이후: 변형 문제 합성을 통한 자체 플레이로 RLVR 유지
본 논문은 대규모 언어 모델에 대한 검증 가능한 보상 강화 학습을 개선하기 위해 자가 재생 변분 문제에 대한 합성 전략을 제안합니다. 기존 RLVR은 Pass@1의 성능을 향상시키지만, 엔트로피 붕괴로 인해 생성 다양성이 감소하여 Pass@k의 성능이 제한됩니다. SvS는 정답을 기반으로 동등한 변분 문제를 합성함으로써 엔트로피 붕괴를 완화하고 학습 다양성을 유지합니다.
논문 링크: https://go.hyper.ai/IU71P
2. 메멘토: LLM 미세 조정 없이 LLM 에이전트 미세 조정
본 논문은 적응형 대규모 언어 모델 에이전트를 위한 새로운 학습 패러다임을 제안하며, 이를 통해 기반 LLM의 미세 조정이 필요 없게 됩니다. 기존 방법들은 종종 두 가지 한계를 안고 있습니다. 첫째, 너무 경직적이거나 둘째, 계산 비용이 많이 든다는 것입니다. 연구팀은 메모리 기반 온라인 강화 학습을 통해 저비용 연속 적응을 달성합니다. 연구팀은 이 과정을 메모리 강화 마르코프 결정 과정(M-MDP)으로 공식화하고, 행동 결정을 유도하는 신경망적 사례 선택 전략을 도입합니다.
논문 링크: https://go.hyper.ai/sl9Yj
3. TreePO: 휴리스틱 트리 기반 모델링을 통해 정책 최적화와 효율성 및 추론 효율성 간의 격차 해소
본 논문은 시퀀스 생성을 트리 형태의 탐색 과정으로 처리하는 자가 유도형 롤아웃 알고리즘인 TreePO를 제안합니다. TreePO는 동적 트리 샘플링 전략과 고정 길이 세그먼트 디코딩으로 구성되며, 지역적 불확실성을 활용하여 추가 분기를 생성합니다. TreePO는 공통 접두사에 대한 연산 오버헤드를 분할하고 가치가 낮은 경로를 조기에 제거함으로써 탐색 다양성을 유지하거나 향상시키면서 각 업데이트의 연산 부담을 효과적으로 줄입니다.
논문 링크: https://go.hyper.ai/J8tKk
4. VibeVoice 기술 보고서
본 논문은 넥스트 토큰 확산(next-token diffusion)을 기반으로 긴 다중 화자 음성을 생성하는 새로운 음성 합성 모델인 VibeVoice를 제안합니다. VibeVoice의 연속 음성 토크나이저는 Encodec 대비 80배 향상된 압축률을 달성하여 음질을 유지하면서 긴 시퀀스 처리 효율을 크게 향상시킵니다. 이 모델은 64k 환경에서 최대 4명의 화자가 참여하는 최대 90분 분량의 대화 음성을 합성하여, 실제 소통 분위기를 생생하게 재현하고 기존 오픈 소스 및 상용 모델을 능가합니다.
논문 링크: https://go.hyper.ai/pokVi
5. CMPhysBench: 응집 물질 물리학에서 대규모 언어 모델을 평가하기 위한 벤치마크
본 논문은 응집물질물리학에서 대규모 언어 모델의 성능을 평가하는 새로운 벤치마크인 CMPhysBench를 제시합니다. CMPhysBench는 자기, 초전도, 강상관계와 같은 응집물질물리학의 대표적인 하위 분야와 기본 이론적 틀을 포괄하는 520개 이상의 신중하게 선별된 대학원 수준의 문제로 구성되어 있습니다.
논문 링크: https://go.hyper.ai/uo8de
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 구조/서열/기능 간의 관계에 기반한 단백질 언어 모델 분류 재정의: 리밍천 박사가 단백질 언어 모델을 자세히 설명합니다.
상하이 교통대학교가 주최한 제3회 "생체공학을 위한 AI 여름학교"에서 상하이 교통대학교 자연과학연구소 홍량 연구팀의 박사후 연구원인 리밍천은 "단백질과 유전체 기본 모델"이라는 주제로 단백질과 유전체 기본 모델의 최신 연구 진행 상황과 기술적 혁신을 모든 사람과 공유했습니다.
전체 보고서 보기: https://go.hyper.ai/Ynjdj
2. MIT 팀은 모든 온도에서 작은 분자의 용해도를 예측하기 위해 원래 모델보다 50배 빠른 FASTSOLV 모델을 제안했습니다.
MIT 연구팀은 화학정보학 도구와 새로운 유기 용해도 데이터베이스인 BigSolDB를 결합하여 FASTPROP 및 CHEMPROP 모델 아키텍처를 개선하여 모델이 용질 및 용매 분자와 온도 매개변수를 동시에 입력하여 logS에 대한 직접 회귀 학습을 수행할 수 있도록 했습니다. 엄격한 용질 외삽 시나리오에서 최적화된 모델은 Vermeire 등이 개발한 최첨단 모델에 비해 RMSE가 2~3배 감소하고 추론 속도가 50배 향상되었습니다.
전체 보고서 보기: https://go.hyper.ai/cj9RX
3. 3,499달러의 가격으로 판매되는 Nvidia의 Jetson Thor는 로봇과 물리적 세계 간의 실시간 지능형 상호 작용을 가능하게 합니다.
엔비디아는 3,499달러부터 시작하는 Jetson AGX Thor 개발 키트의 공식 출시를 발표했습니다. Thor T5000 양산 모듈은 현재 기업 고객을 대상으로 판매 중입니다. "로봇의 두뇌"로 불리는 Jetson AGX Thor는 제조, 물류, 운송, 의료, 농업, 소매 등 다양한 산업에서 수백만 대의 로봇에 동력을 제공하는 것을 목표로 합니다.
전체 보고서 보기: https://go.hyper.ai/1XLXn
4. 다중 모드 모델은 새로운 소재와 산업 응용 분야의 매칭을 가속화하여 완전한 결정 구조가 없어도 소재의 특성을 예측할 수 있습니다.
캐나다 토론토 대학교 화학공학 및 응용화학과 연구팀은 MOF 합성 후 얻은 정보(PXRD와 합성에 사용된 화학물질)를 활용하는 다중 모드 머신러닝 기법을 제안했습니다. 이 기법을 통해 기존 보고된 응용 분야와는 다른 분야에서 잠재력을 가진 MOF를 발굴할 수 있었습니다. 이 연구는 MOF 합성과 응용 분야 간의 연관성을 더욱 강화합니다.
전체 보고서 보기: https://go.hyper.ai/cqX1t
5. 과학 데이터의 가용성을 개선하기 위해 중국과학원 장정더 연구팀은 지능형 에이전트를 기반으로 한 AI 지원 데이터 처리 및 제공 솔루션을 제안했습니다.
2025CCF 국가 고성능 컴퓨팅 학술대회에서 고에너지물리학연구소 컴퓨팅센터 AI4S 책임자인 장정더 연구원은 대규모 시설의 과학 데이터 현황과 데이터 주석 및 제공에 지능형 에이전트와 다중 에이전트 프레임워크를 적용하는 것을 바탕으로 데이터에 대한 효율적이고 고품질의 AI 준비 구축 계획을 체계적으로 설명했습니다.
전체 보고서 보기: https://go.hyper.ai/u7F9L
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.https://go.hyper.ai/wiki
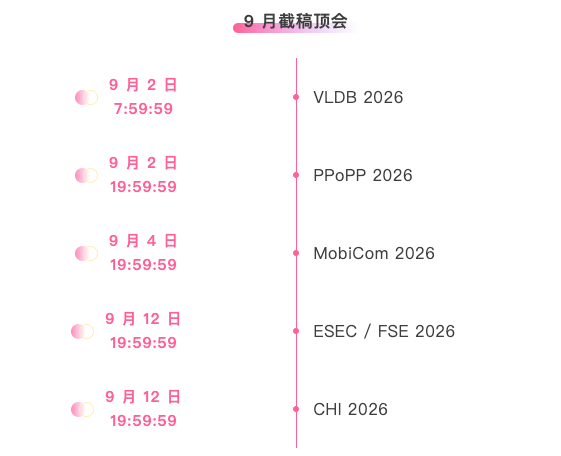
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!