Command Palette
Search for a command to run...
온라인 튜토리얼 | NVIDIA, 소형 모델 출시: 작고 컴팩트한 Nemotron-Nano-9B-v2는 Qwen3보다 6배 빠릅니다.

대규모 언어 모델이 처음 도입되었을 때, 언젠가 스마트워치에 들어갈 만큼 작아질 거라고 상상해 보셨나요? 오늘날 이러한 환상은 점차 현실이 되고 있습니다. 스마트워치와 같은 기기는 클라우드에서 모델에 접속하여 음성 대화와 지능형 비서를 활용할 수 있게 되었습니다. 하지만 앞으로의 과제는 단순히 소형 기기에 모델을 배포하는 것뿐만 아니라, 모델의 추론 능력과 효율성을 유지하면서도 경량성을 유지하는 것입니다.
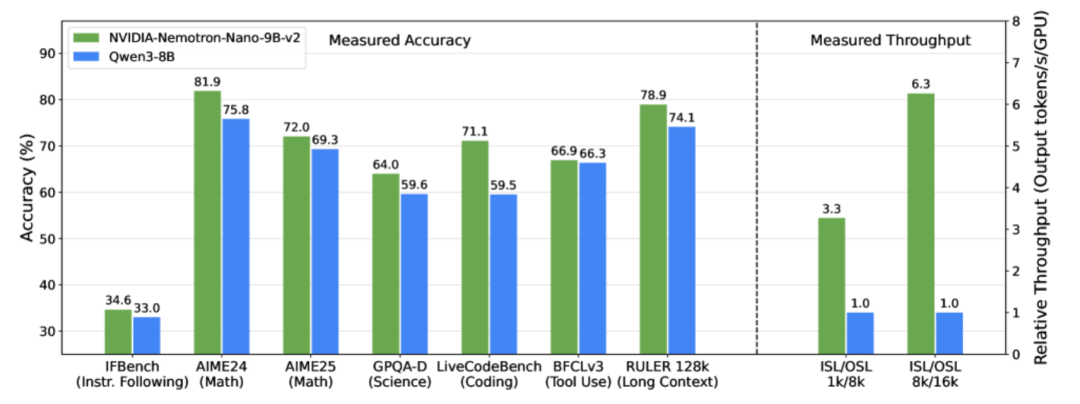
이를 해결하기 위해 NVIDIA 팀은 2025년 8월 19일에 경량의 대규모 언어 모델 NVIDIA-Nemotron-Nano-9B-v2를 출시했습니다. Nemotron 시리즈의 하이브리드 아키텍처 최적화 버전으로,이 모델은 Mamba의 효율적인 긴 시퀀스 처리 기능과 Transformer의 강력한 의미 모델링 기능을 혁신적으로 결합하여 대부분의 자기 주의 계층을 Mamba-2 상태 공간 계층으로 대체함으로써 긴 추론 궤적을 처리할 때 모델을 더 빠르게 만듭니다.90억 개의 매개변수만으로 128K의 초장문맥을 지원합니다. 복합 추론 벤치마크에서 동급 최고의 오픈소스 모델인 Qwen3-8B와 동등하거나 그 이상의 정확도를 달성했으며, 처리량은 후자보다 최대 6배 향상되어 경량 배포 및 대규모 언어 모델의 장문 텍스트 이해 분야에서 획기적인 진전을 이루었습니다.
다시 말해, Nemotron-Nano-9B-v2는 단순히 "소형 장치 속의 모델" 그 이상을 나타냅니다.대신, 강력한 추론 능력을 진정으로 가볍고 대중이 접근하기 쉽게 만드는 것을 목표로 합니다.아마도 미래에는 대규모 언어 모델이 언제 어디서나 "작고 정확한" 형태로 사람들에게 지능형 서비스를 제공할 수 있을 것입니다.
모델 기능을 종합적으로 향상시키기 위해 다국어 사후 훈련 데이터 세트를 출시합니다.
연구팀은 단순히 작은 모델을 구축하는 대신, 12B 매개변수를 가진 기준 모델인 Nemotron-Nano-12B-v2-Base를 기반으로 대량의 큐레이팅된 합성 데이터로 사전 학습을 진행했습니다. 또한 추론 능력을 향상시키기 위해 여러 영역을 포괄하는 SFT(Synthetic Transformation) 방식의 데이터도 추가했습니다.
이후 팀은 SFT(지도 미세 조정), IFeval RL(지시 후 평가), DPO(직접 선호도 최적화), RLHF(인간 피드백 강화 학습)를 포함한 다단계 사후 학습을 수행하여 수학, 코드, 도구 호출, 장문 대화 측면에서 모델의 정확도와 견고성을 높였습니다.관련 사후 훈련 데이터 세트가 업데이트되어 "Nemotron-Post-Training-Dataset-v2"로 출시되었습니다.수학, 코딩, STEM(과학, 기술, 공학, 수학) 및 대화와 같은 시나리오를 포함하여 SFT 및 RL 데이터를 5개 대상 언어(스페인어, 프랑스어, 독일어, 이탈리아어, 일본어)로 확장하여 모델의 추론 및 명령 수행 기능을 개선합니다.
데이터 세트 주소:
연구팀은 미니트론(Minitron) 압축 및 증류 전략을 기반으로 경량 신경망 구조 탐색(neural architecture search) 방법을 사용하여 모델 구성 요소(각 계층 및 피드포워드 신경망 등)의 중요도를 평가한 후 이를 가지치기(prune)했습니다. 증류 및 재학습을 통해 연구팀은 원래 모델의 성능을 가지치기된 모델로 개선했습니다. 최종적으로 12바이트 모델을 9바이트 Nemotron-Nano-9B-v2로 압축하여 추론 정확도를 유지하면서 리소스 사용량을 크게 줄였습니다.
HyperAI Hyperneuron 웹사이트(hyper.ai)의 "튜토리얼" 섹션에서 "vLLM + Open WebUI를 사용한 NVIDIA-Nemotron-Nano-9B-v2 배포"를 지금 바로 확인해 보세요. "작지만 정확한" 이 대규모 언어 모델을 통해 소통하는 경험을 직접 경험해 보세요!
튜토리얼 링크:
데모 실행
1. 브라우저에 hyper.ai URL을 입력합니다. 홈페이지에 접속한 후 "튜토리얼" 페이지를 클릭하고, "vLLM + Open WebUI to Deploy NVIDIA-Nemotron-Nano-9B-v2"를 선택한 후 "이 튜토리얼을 온라인으로 실행"을 클릭합니다.
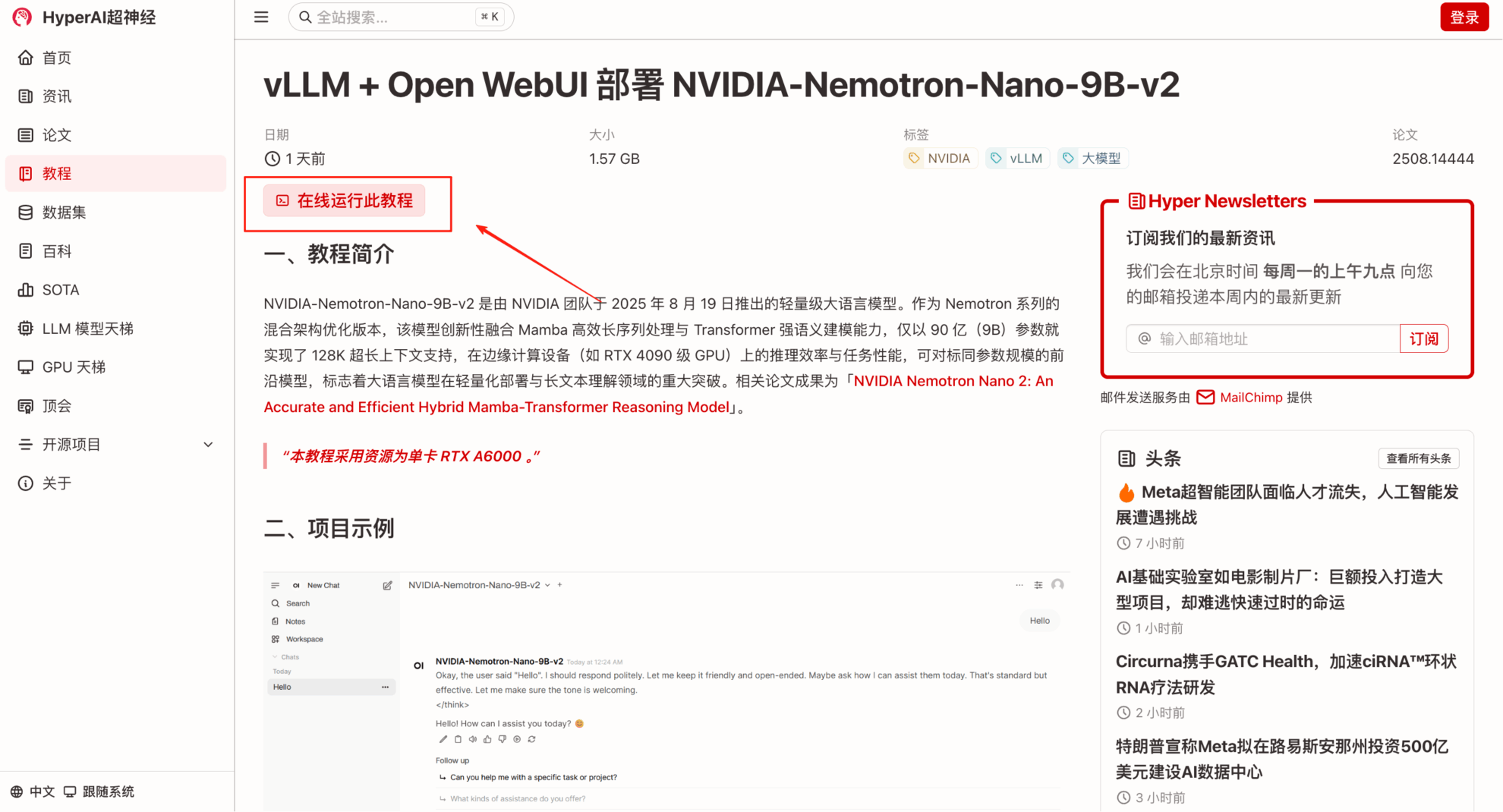
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
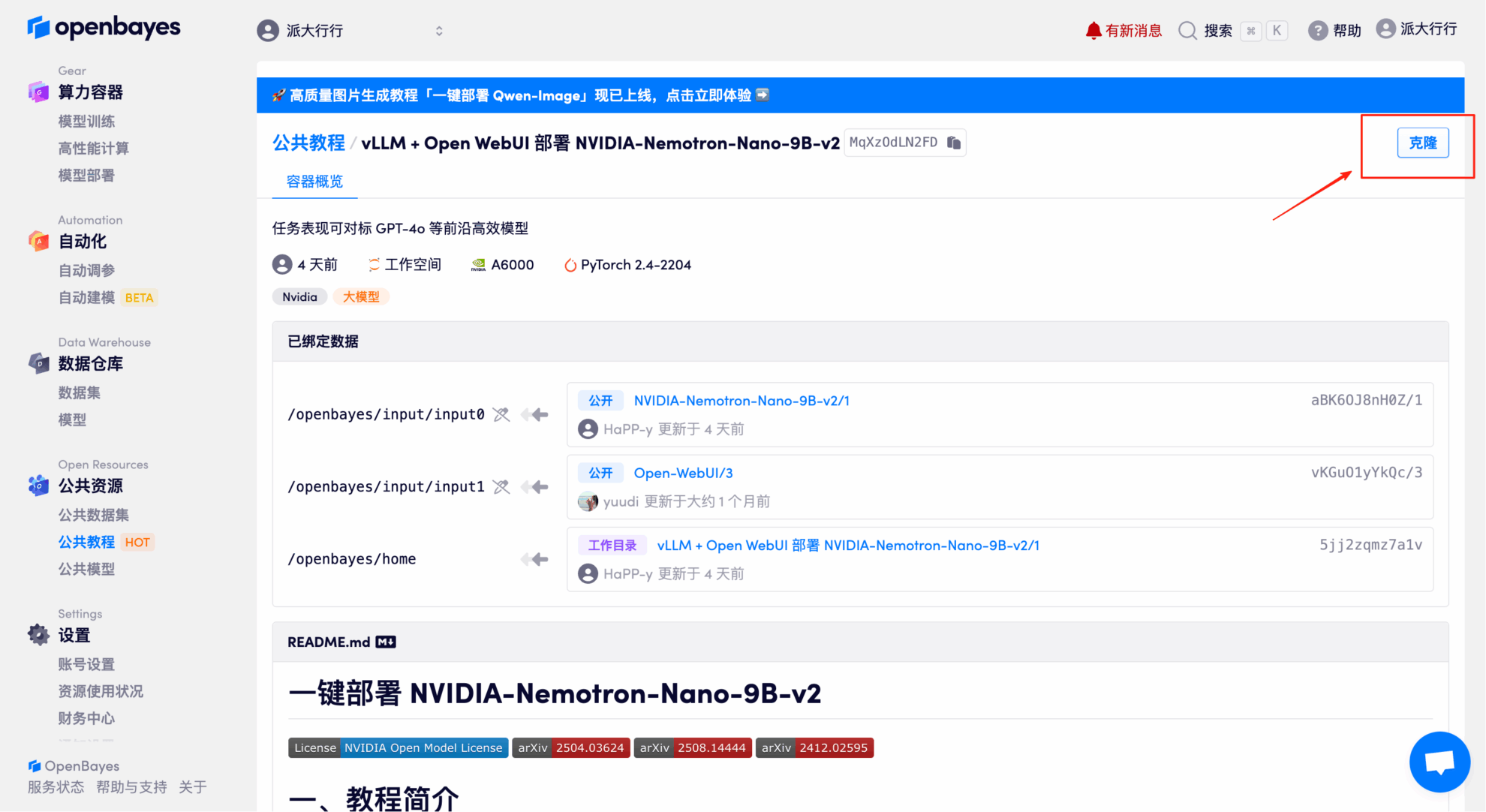
3. NVIDIA RTX A6000 48GB 및 PyTorch 이미지를 선택하고 "계속"을 클릭하세요. OpenBayes 플랫폼은 사용량 기반 요금제 또는 일일/주간/월간 요금제 등 네 가지 결제 옵션을 제공합니다. 신규 사용자는 아래 초대 링크를 통해 등록하시면 RTX 4090 4시간과 CPU 5시간 무료 이용권을 받으실 수 있습니다!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_NR0n
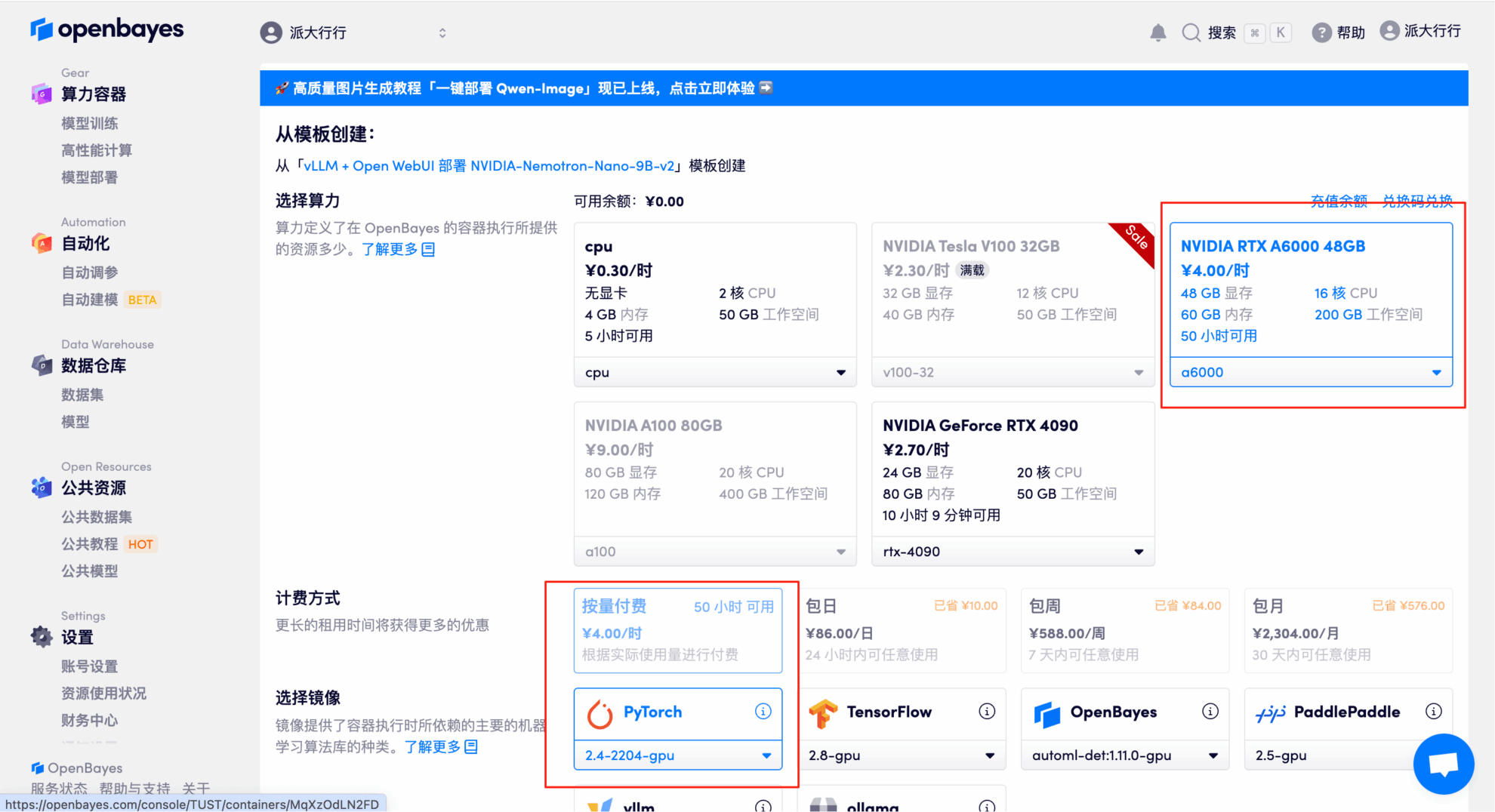
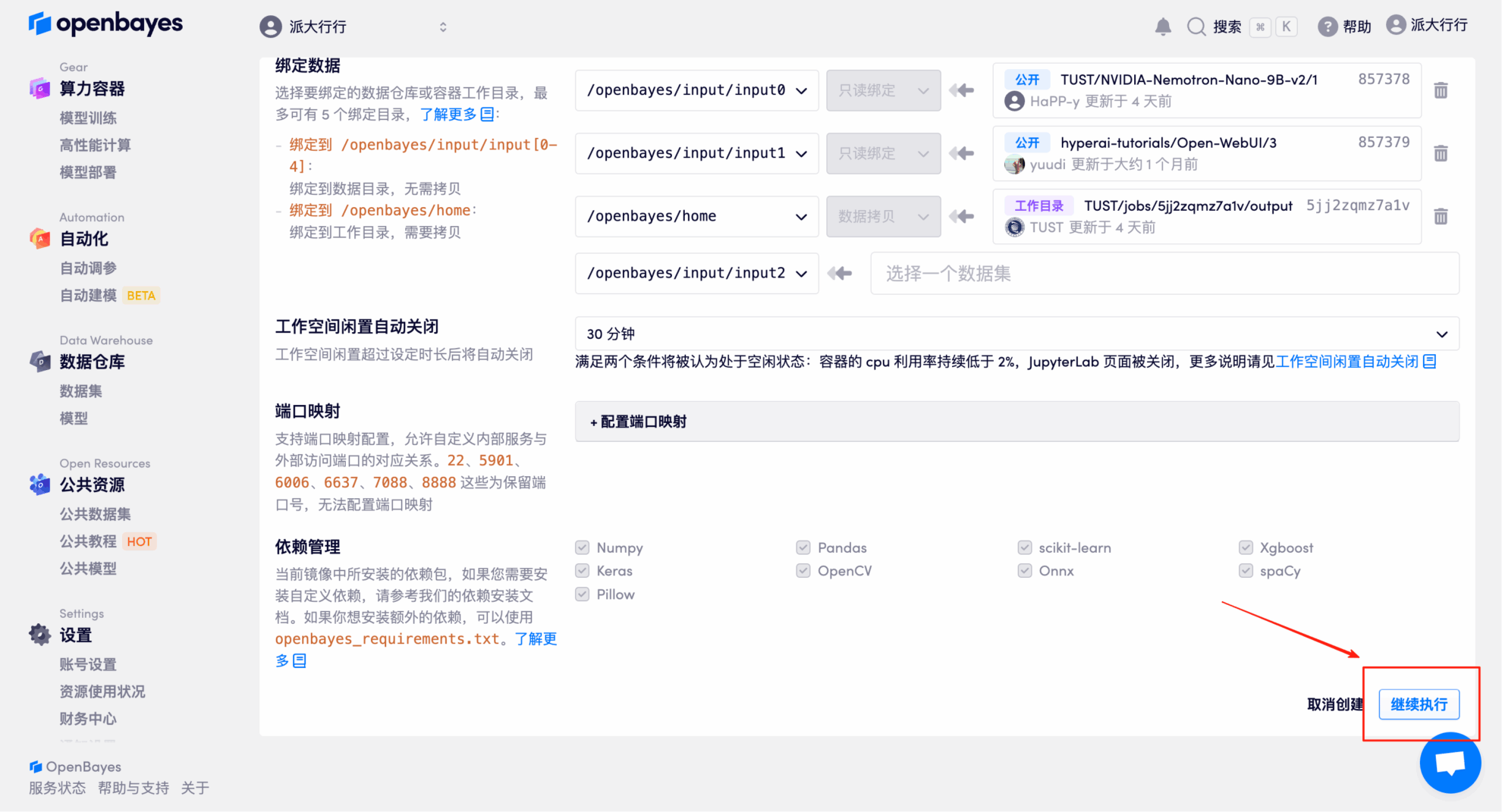
4. 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 프로세스는 약 3분 정도 소요됩니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆의 화살표를 클릭하여 데모 페이지로 이동하세요. API 주소를 사용하려면 실명 인증을 완료해야 합니다.
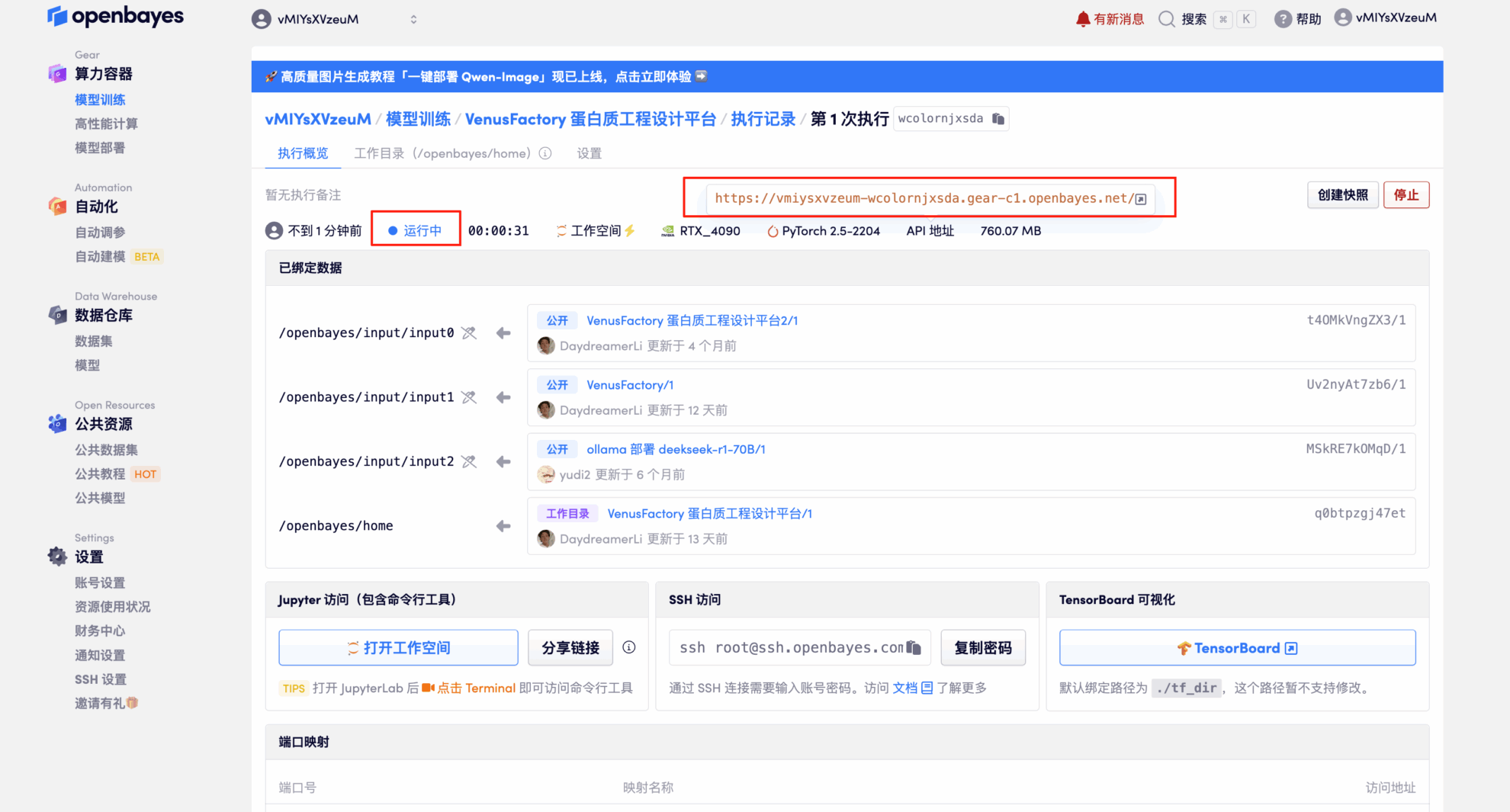
효과 시연
데모 실행 페이지에 들어간 후 대화 상자에 Prompt를 입력하고 실행을 클릭합니다.
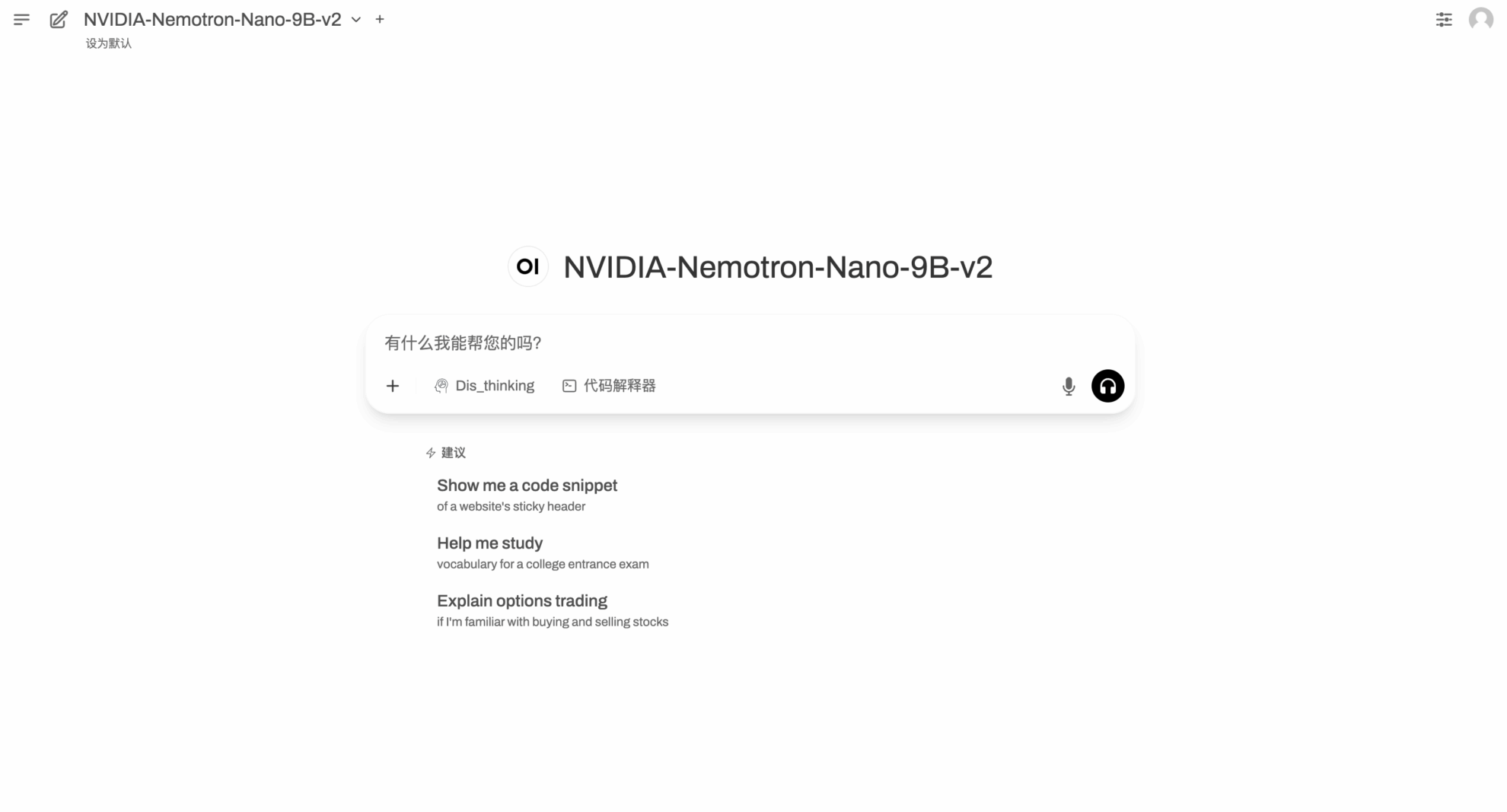
가을이 시작되면서 날씨가 점점 시원해집니다. Nemotron-Nano-9B-v2가 초가을을 따뜻하게 보내는 몇 가지 팁을 알려드리겠습니다.



위는 HyperAI가 이번에 추천하는 튜토리얼입니다. 누구나 와서 체험해 보세요!
튜토리얼 링크:
2023년부터 2024년까지 AI4S 분야의 고품질 논문과 심층 해석 기사를 클릭 한 번으로 받아보세요⬇️
