Command Palette
Search for a command to run...
MIT 팀은 모든 온도에서 작은 분자의 용해도를 예측하기 위해 원래 모델보다 50배 빠른 FASTSOLV 모델을 제안했습니다.

화학 및 재료과학 분야에서 다양한 용매에 대한 유기 고체의 용해도는 핵심 분자 특성으로, 전체 연구 및 산업 사슬에 영향을 미칩니다. 합성 공정의 경우, 용해도를 정밀하게 제어하면 최적의 용매를 선별하고 반응 조건을 최적화할 수 있을 뿐만 아니라, 제품 수율과 순도를 크게 향상시켜 생산 비용을 절감할 수 있습니다. 환경과학에서는 토양 및 수중에서 과불화알킬 물질(PFAS) 및 폴리플루오로알킬 물질(PFAS)과 같은 오염 물질의 이동 및 거동을 분석하는 핵심 매개변수로, 오염 방지 및 제어를 위한 과학적 근거를 제공합니다. 또한 결정화 및 막 분리와 같은 공정에서 용해도는 상 거동과 분리 효율을 결정하는 핵심 변수입니다.
그러나 기존의 실험적 측정 방법은 많은 한계를 가지고 있습니다. 시간과 재료가 많이 소모될 뿐만 아니라 유기 고체 결정 형태나 불순물과 같은 요인에 의해 쉽게 간섭을 받아 데이터 정확도가 떨어집니다. 연구에 따르면 수용해도 logS의 실험실 간 표준 편차는 종종 0.5~0.7 log 단위에 달하며, 극단적인 경우 측정 결과의 차이가 10배를 초과할 수도 있습니다. 경험적 군 첨가법, 양자 화학 모델, 그리고 머신 러닝 방법이 예측에 적용되었지만,그러나 다양성이 부족하거나 정확성과 계산 효율성의 균형을 맞추는 데 어려움이 있는 경우가 많습니다.
이러한 문제점을 해결하기 위해 매사추세츠 공과대학 연구팀은 화학 정보학 도구와 새로운 유기 용해도 데이터베이스인 BigSolDB를 결합했습니다.FASTPROP 및 CHEMPROP 모델 아키텍처를 기반으로 개선됨이 모델은 용질 분자, 용매 분자 및 온도 매개변수를 동시에 입력하고 logS에 대한 회귀 학습을 직접 수행할 수 있습니다.
Vermeire와 같은 기존 SOTA 모델과 비교했을 때 엄격한 용질 외삽 시나리오에서최적화된 모델의 RMSE는 2~3배 감소하였고, 추론 속도는 최대 50배 증가하였습니다.현재 이 팀은 FASTPROP 파생 모델을 FASTSOLV로 명명하고 오픈 소스로 공개하여 관련 과학 연구와 산업 응용 프로그램을 위한 효율적이고 실용적인 도구를 제공하고 있습니다.
관련 연구 결과는 "임의 불확실성의 한계에서의 데이터 기반 유기 용해도 예측"이라는 제목으로 Nature Communication에 게재되었습니다.

서류 주소:
https://www.nature.com/articles/s41467-025-62717-7
공식 계정을 팔로우하고 "유기 용해도"에 답글을 달면 전체 PDF를 받을 수 있습니다.
BigSolDB 기반 데이터셋 구축 및 평가 시스템 설계
이 연구의 핵심 데이터 소스는 BigSolDB로, 다양한 유기 용매와 강수 한계에 가까운 다양한 온도 조건에서 유기 고체의 용해도 데이터를 체계적으로 수집하여 일반적인 예측 모델의 학습을 위한 핵심 지원을 제공합니다.
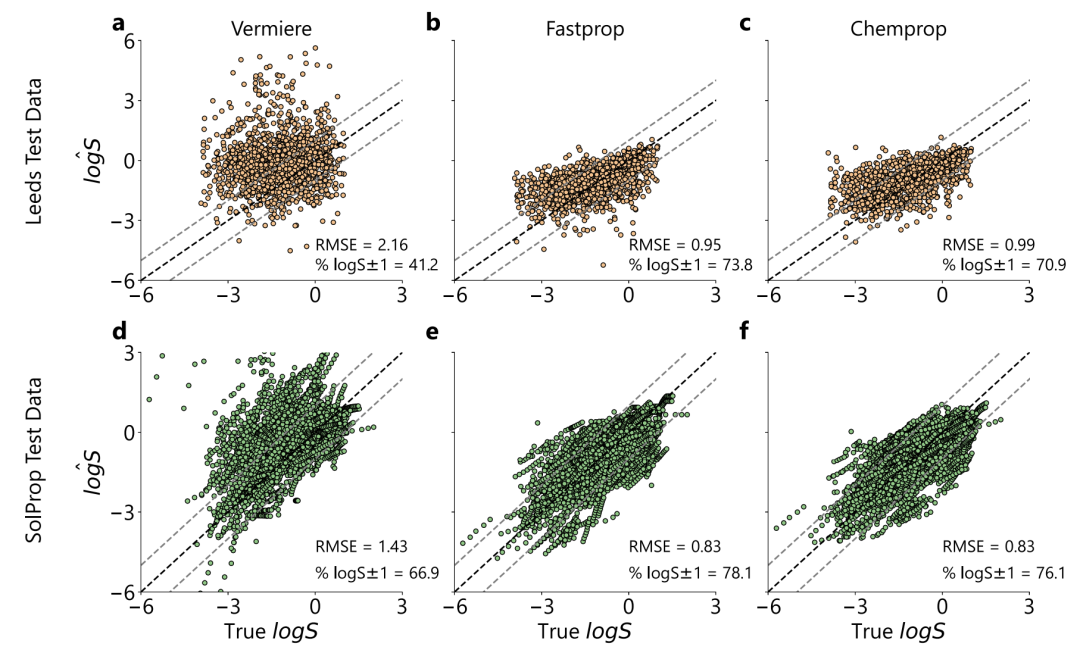
"사전 지식 없이 새로운 용질을 외삽하는" 연구 목표를 달성하기 위해 연구팀은 엄격한 훈련-평가 시스템을 설계했습니다.이 모델은 BigSolDB에서 학습되었고 SolProp과 Leeds라는 두 개의 공개 데이터 세트에서 독립적으로 테스트되었습니다.외삽법의 어려움을 과소평가하지 않기 위해, 아래 그림에서 보듯이 이 연구에서는 먼저 BigSolDB와 겹치는 SolProp의 모든 용질을 제거하고, 보완책으로 더 넓은 화학 공간을 가진 Leeds 데이터 세트를 도입했습니다.
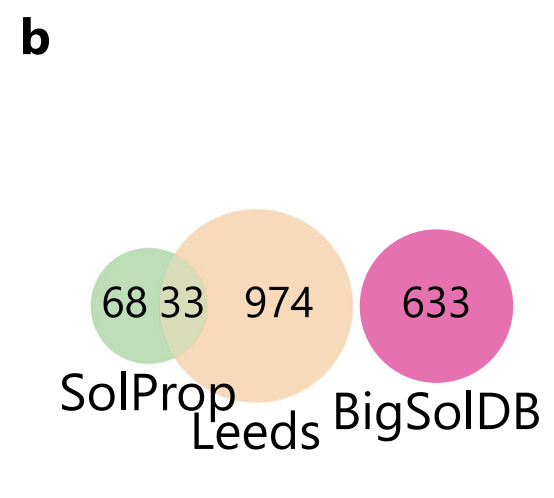
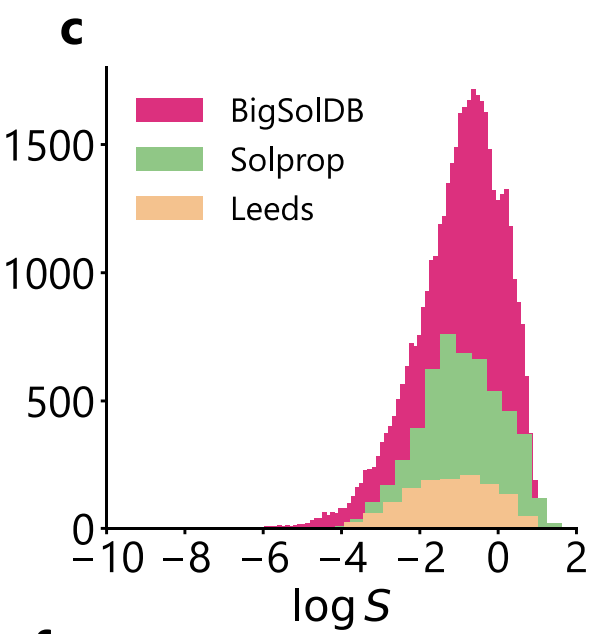
SolProp과 비교했을 때,리즈는 더 높은 용질 다양성을 제공하지만 실온 조건만 포괄합니다.이를 통해 새로운 화학 공간에 대한 모델의 적응성을 검증할 수 있을 뿐만 아니라, "다중 온도 평균화"에서 발생하는 암묵적 노이즈 감소가 부족하여 더 높은 상한 불확실성을 제공합니다. 특히 아래 그림에서 볼 수 있듯이, 세 가지 데이터셋의 logS 분포는 매우 일관성이 있으며, 모두 -1 근처에 집중되어 있고 저용해도 끝부분에서 긴 꼬리를 나타내어 데이터셋 간 성능 비교 시 분포 비교성을 보장합니다.
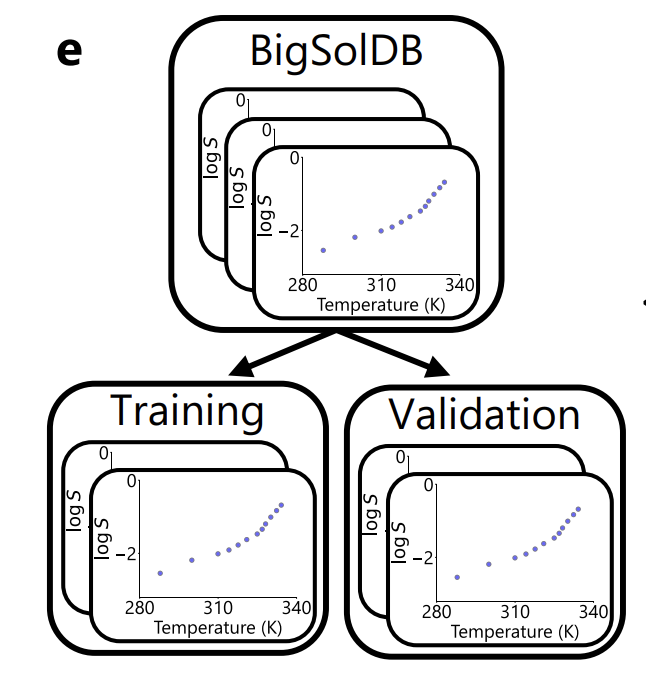
데이터 분할 측면에서 연구자들은 아래 그림과 같이 용질을 단위로 엄격하게 사용합니다. 95%의 용질은 학습에 사용하고 5%는 검증 및 모델 선택에 사용합니다.서로 다른 용매와 온도에서 동일한 용질을 모두 측정한 결과는 동시에 서로 다른 하위 집합에 나타나지 않습니다.이렇게 하면 정보 유출을 효과적으로 방지할 수 있습니다.
또한 이 연구에서는 ASTARTES 툴킷을 사용하여 훈련 데이터에서 검증 세트를 무작위로 "완전한 실험"으로 나누고 최종 평가에서 용질 차원과 실험 차원 모두에서 분할 경계를 다시 검사하여 평가의 독립성과 엄격성을 보장했습니다.
BigSolDB가 주도하는 FASTSOLV 모델 구축
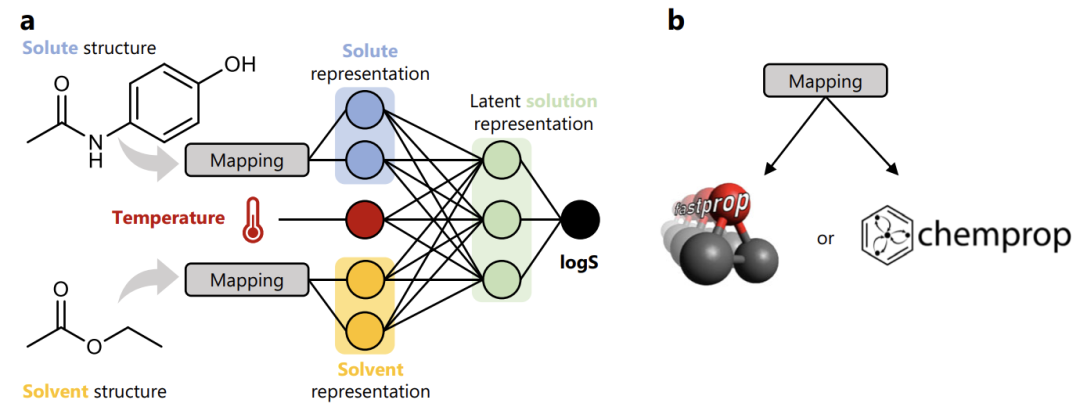
아래 그림에서 볼 수 있듯이, 이 연구에서는 BigSolDB 데이터 세트를 활용하여 FASTPROP과 CHEMPROP의 두 가지 고전적인 모델 아키텍처를 사용자 정의하고 명확한 머신 러닝 모델링 프로세스를 구축했습니다.
첫 번째,용질(예: 파라세타몰)과 용매(예: 에틸 아세테이트)의 분자 구조를 해당 표현 벡터에 매핑합니다.그 다음에,이 두 분자 표현 벡터는 용액 온도 매개변수와 결합되어 완전한 용액 표현을 형성합니다.결정적인,표현은 완전히 연결된 신경망에 입력되었고, logS(용해도의 로그)를 목표로 회귀 훈련이 수행되었습니다.
이러한 변형을 통해 최종적으로 개발된 모델은 다양한 유기 용매와 다양한 온도 시나리오에서 소분자의 용해도를 통합적으로 예측할 수 있게 되었으며, 특정 용매나 온도 범위에 대한 기존 모델의 의존성을 탈피하게 되었습니다.
연구팀은 모델의 견고성과 예측 신뢰성을 더욱 개선하기 위해 단일 모델 출력에 의존하지 않았습니다.대신, FASTPROP 모델은 네 가지 서로 다른 무작위 초기화 조건에서 학습되고, 그런 다음 통합 전략 조합을 통해 최종 FASTSOLV 모델이 얻어집니다.성과 비교 및 사례 검증과 같은 모든 후속 주요 분석은 이 통합 모델을 기반으로 하며, 이를 통해 단일 모델의 무작위 변동 위험을 효과적으로 줄일 수 있습니다.
동시에, 새로운 모델의 성능을 객관적으로 측정하기 위해 본 연구는 현재 널리 알려진 SOTA 모델인 베르메이르(Vermeire) 모델을 비교 벤치마크로 도입했습니다. 이 모델은 네 개의 독립적인 열화학 하위 모델을 통해 학습된 후 열역학적 사이클 조합을 통해 용해도 결과를 출력합니다. 용매 다양성과 온도 의존성을 균형 있게 조절하는 장점이 있습니다. 그러나 본 연구는 테스트에 사용된 SolProp 데이터셋이 자체 학습 세트와 용질 구조가 상당히 중복되는 것을 발견했습니다. 이러한 "데이터 중복"은 외삽된 성능을 과대평가하는 결과를 초래할 수 있습니다. 비교의 공정성과 엄격성을 보장하기 위해 본 연구는 베르메이르 모델의 원래 학습-테스트 설정을 엄격하게 재현하고, 이를 기반으로 제어 실험을 수행하여 성능 차이가 테스트 조건이 아닌 모델 자체에만 기인함을 확인했습니다.
유기 용해도 외삽법을 위한 SOTA를 2~3배의 정확도와 50배의 속도로 업데이트합니다.
본 연구에서는 모델 성능에 대한 다차원 검정 및 검증을 수행했습니다. 보간 시나리오에서 최적화된 FASTPROP 모델은 RMSE=0.22, P₁=94%를 달성했으며, CHEMPROP 모델은 RMSE=0.28, P₁=90%를 달성했습니다.실험 데이터의 노이즈 상한에 도달한 성능이 입증되어 BigSolDB의 가치가 확인되었습니다.
아래 그림과 같이 새로운 용질 외삽 검정에서 Vermeire 모델은 체계적인 과대 추정(RMSE=2.16, P₁=34%)으로 인해 Leeds 데이터셋에서 성능이 저조한 반면, FASTPROP과 CHEMPROP의 RMSE는 각각 0.95와 0.99로 떨어졌고, P₁은 69%를 초과했습니다. SolProp 데이터셋에서도 본 모델의 성능이 더 우수했습니다(RMSE=0.83, P₁=80%).FASTPROP의 추론 속도는 Vermeire 모델의 추론 속도의 약 50배입니다.SHAP 해석 가능성 분석을 지원합니다.
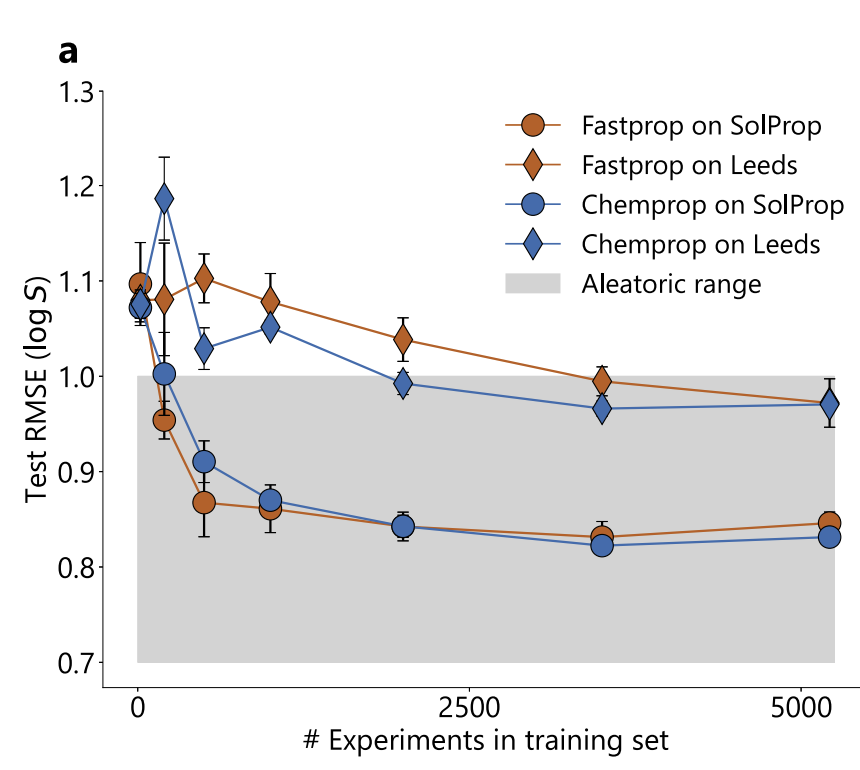
아래 그림은 훈련 데이터 볼륨 실험 결과를 보여줍니다. FASTPROP과 CHEMPROP은 분자 표현 방식이 다르지만, 성능은 유사한 한계에 도달합니다. SolProp 테스트 세트는 안정기에 도달하는 데 약 500회의 실험(약 5,000개의 데이터 포인트)이 필요한 반면, CHEMPROP은 Leeds 테스트 세트에서 약 2,000회의 실험(약 20,000개의 데이터 포인트)이 필요합니다.
BigSolDB에서 동일한 조건 하에 다중 소스 데이터 34개 세트를 추정한 결과, 실험적 무작위 불확실성 한계는 RMSE=0.75 log 단위인 반면, SolProp에서 두 모델의 RMSE는 0.83으로 이 한계에 가깝습니다. MolFormer 및 ChemBERTa-2와 같은 대형 모델과 비교했을 때 두 모델의 성능이 더 우수합니다.이는 성능 병목 현상이 모델의 표현력보다는 실험 데이터에서 발생한다는 것을 증명합니다.
임의의 한계에서 모델 성능의 평균 테스트
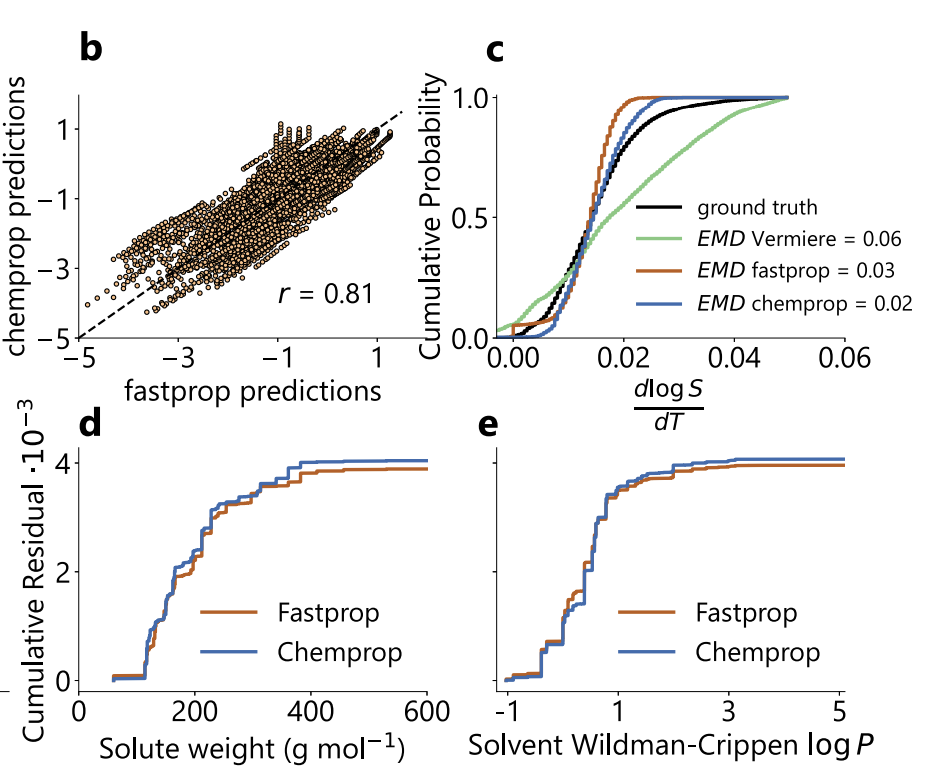
또한, 아래 그림에서 볼 수 있듯이 두 모델은 SolProp 검정 세트에서 높은 상관관계를 보이는 예측값을 보였으며(피어슨 r=0.81), 예측된 온도 기울기 분포 또한 매우 일관성이 높았습니다(EMD=0.03/0.02). 계통 오차는 Vermeire 모델(EMD=0.06)보다 현저히 낮았습니다.
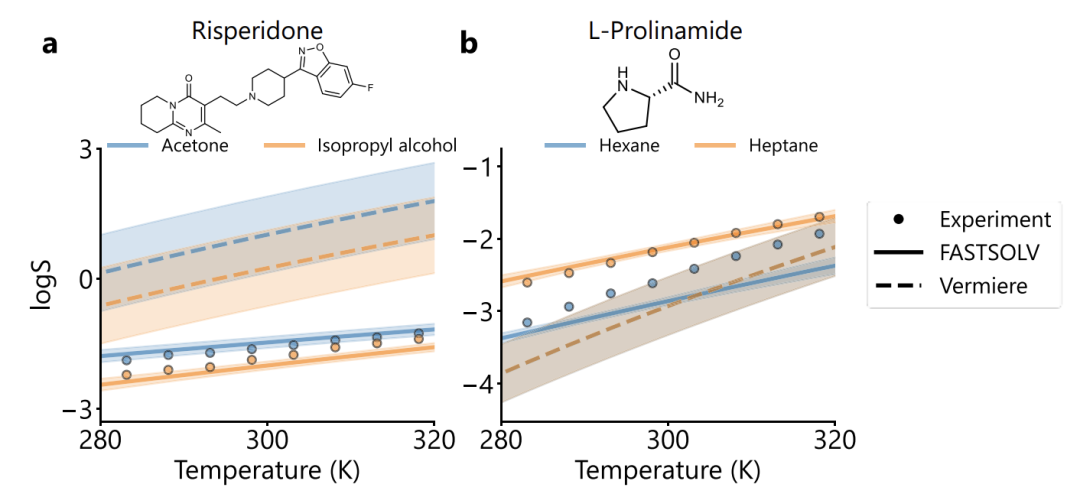
이 연구에서는 또한 아래 그림에서 볼 수 있듯이 일반적인 용질 검증에서 FASTSOLV가 리스페리돈(RMSE=0.16 대 Vermeire 1.64)과 L-프롤린(RMSE=0.25 대 Vermeire 2.33)을 예측하는 데 상당한 이점이 있음을 발견했습니다.용매 용해도의 순서와 온도 의존성을 정확하게 결정할 수 있을 뿐만 아니라, 유사한 구조를 가진 헥산과 헵탄을 구별할 수도 있습니다.실패 모드 분석 결과, 안트라퀴논의 예측 오차가 높았지만, 85개의 안트라퀴논/안트라퀴논 유도체 하위 집합에서 모델의 전체 RMSE는 0.52였으며 용매 용해도는 안정적으로 순위를 매길 수 있었습니다. 이는 분자적 특성 분석이 합리적임을 나타냅니다.
요약하자면,FASTSOLV는 Vermeire 모델과 비교했을 때 RMSE를 2~3배 줄이고 추론 속도를 최대 50배까지 높입니다.이 방법은 해석 가능성과 엔지니어링 잠재력을 결합하여 엄격한 외삽법 설정에서 최첨단 성능을 나타냅니다. 또한 이 연구는 추가 학습 데이터를 추가하더라도 성능 한계를 극복하지 못하며, 향후 연구는 고정밀 유기 용매 데이터셋 구축에 집중할 것이라고 지적합니다.
"데이터셋 + AI", 분자 특성 예측 분야에서 세계적 혁신을 주도
오늘날 화학, 의학, 재료 과학 분야에서 혁신이 활발하게 일어나는 가운데, "대규모 데이터 세트 + 고급 머신 러닝 모델"을 중심으로 한 분자 특성 예측 기술은 시간이 많이 소요되는 실험, 높은 연구개발 비용, 어려운 성능 예측 등 업계의 문제점을 해결하는 핵심 도구가 되고 있습니다.
학계에서는 전 세계 연구팀이 FASTSOLV와 BigSolDB의 획기적인 성과에 대응하여 일련의 혁신적인 용해도 예측 연구를 시작하고 있습니다. 예를 들어, 영국 리즈 대학교의 연구진은 인공지능과 물리화학적 메커니즘을 결합한 인과적 구조 속성 관계 모델을 제안했습니다.유기 용매와 수계에서의 용해도 예측은 실험 오차만큼 정확합니다.또한 뛰어난 해석성을 가지고 있어 용해도 모델링 분야에서 중요한 이정표로 여겨진다.
한편, 매사추세츠 공과대학교(MIT) 연구팀은 그래프 신경망 Chemprop을 이용하여 항생제 개발에 상당한 진전을 이루었습니다. 39,312개 화합물의 항생제 활성과 인체 세포독성 프로파일을 분석하고, 그래프 신경망 앙상블을 사용하여 1,207만 6,365개 화합물의 항생제 활성과 세포독성을 예측하여 새로운 항생제를 개발했습니다. 초기 화합물 패널을 스크리닝하고 메티실린 감수성 균주인 S. aureus RN4220에 대한 성장 억제 활성을 평가함으로써,512개의 활성 화합물이 얻어졌습니다.그래프 신경망은 이진 분류 예측을 수행하도록 훈련됩니다.
제약 산업에서도 주목할 만한 혁신이 나타나고 있습니다. 제약 산업은 오랫동안 고처리량, 저비용 용해도 평가 기술에 집중해 왔습니다. 예를 들어, AspenTech의 Aspen Solubility Modeler 도구는 몇 가지 용매에서 측정된 데이터를 기반으로 수백 가지 용매 조합의 용해도를 예측할 수 있습니다. 이 도구는 GSK와 AstraZeneca와 같은 주요 기업의 결정 스크리닝 및 공정 개발 효율성과 의사 결정 신뢰성을 크게 향상시킵니다.
또한, 일부 기업들은 소재 연구개발 분야에서도 유사한 데이터 기반 모델을 활용하고 있습니다. 방대한 분자 구조 및 성능 데이터를 분석하여 신소재의 특성을 예측하고, 연구개발 주기를 단축하며, 연구 개발 비용을 절감하고 있습니다. 화학 산업에서는 다양한 용매 및 온도 조건에서 화학 반응의 영향을 예측하는 모델을 활용하여 생산 공정을 최적화하고 생산 효율과 제품 품질을 향상시키고 있습니다. 이는 모두 학계 연구의 모델과 데이터 개념을 실제 생산 혁신에 적용하는 기업들의 사례입니다.
참조 링크:
2.https://www.manufacturingchemist.com/news/article_page/Solubility_modelling/57726
2023년부터 2024년까지 AI4S 분야의 고품질 논문과 심층 해석 기사를 클릭 한 번으로 받아보세요⬇️
