Command Palette
Search for a command to run...
1천만 시간 분량의 음성 데이터! Higgs Audio V2 음성 모델이 감정 표현 능력을 향상시키고, MathCaptcha10k가 인증 코드 인식 기술을 개선합니다.

"텍스트를 위한 대규모 언어 모델 학습에 1천만 시간 분량의 음성 데이터를 추가하면 어떻게 될까요?" 이러한 생각을 바탕으로,리무와 그의 팀인 보손 AI는 연구 끝에 대규모 음성 모델인 "히그스 오디오 V2"를 공식 출시했습니다.
기존 TTS(텍스트 음성 변환) 시스템은 기계적인 음성 출력을 사용하는 경우가 많아 감정적 적응성과 자연스러운 리듬감이 부족합니다. 여러 캐릭터가 등장하는 대화는 수동 분할이 필요하며, 모델만으로는 음색과 캐릭터를 일치시키기 어렵습니다. 반면, Higgs Audio V2는 기존 TTS에서는 보기 드문 혁신적인 기능들을 도입했습니다.이 기능에는 내레이션 중 자동 리듬 적응, 여러 화자 대화 생성 기능, 제로 샘플 음성 복제 및 멜로디 허밍, 음성과 배경 음악을 동시에 생성하는 기능이 포함되어 있어 오디오 AI 기능의 큰 도약을 나타냅니다.
EmergentTTS-Eval에서는 다음 사항을 언급할 가치가 있습니다.이 모델은 감정 및 질문 카테고리에서 각각 gpt-4o-mini-tts보다 75.7%, 55.7% 더 우수한 성과를 보였습니다.이는 "감정적 상호작용"이 오디오 분야의 모델에 있어 핵심 단계가 되었다는 것을 보여줍니다.
현재 HyperAI 공식 웹사이트에 "Higgs Audio V2: 음성 생성의 표현력을 재정의하다"가 출시되었습니다. 지금 바로 체험해 보세요!
온라인 사용:https://go.hyper.ai/Ty0CM
8월 4일부터 8월 8일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 10
* 엄선된 고품질 튜토리얼: 7개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 8월 마감일 상위 컨퍼런스: 2
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. STRIDE-QA-Mini 자율주행 질의응답 데이터세트
STRIDE-QA-Mini는 자율주행을 위한 질의응답 데이터셋으로, 자율주행 시나리오에서 시각 언어 모델(VLM)의 시공간적 추론 능력을 연구하도록 설계되었습니다. 이 데이터셋은 103,220개의 질의응답 쌍과 5,539개의 이미지 샘플을 포함하고 있습니다. 이 데이터는 도쿄에서 수집된 실제 블랙박스 영상에서 추출되었습니다.
직접 사용:https://go.hyper.ai/9DVTI
2. MathCaptcha10k 산술 검증 코드 이미지 데이터 세트
MathCaptcha10K는 CAPTCHA 인식 알고리즘을 테스트하고 학습하도록 설계된 산술 CAPTCHA 이미지 데이터셋으로, 특히 배경이 산만하고 텍스트가 왜곡된 CAPTCHA를 처리할 때 유용합니다. 이 데이터셋은 레이블이 지정된 10,000개의 예시와 레이블이 지정되지 않은 11,766개의 예시를 포함합니다. 레이블이 지정된 각 예시에는 CAPTCHA 이미지, 이미지에 포함된 정확한 문자, 그리고 정수형 답변이 포함됩니다.
직접 사용:https://go.hyper.ai/QERJt

3. CoSyn-400K 다중 모드 합성 질의응답 데이터세트
CoSyn-400K는 펜실베이니아 대학교와 앨런 인공지능 연구소가 공동으로 공개한 멀티모달 합성 질의응답 데이터셋입니다. 멀티모달 모델 학습을 위한 고품질의 확장 가능한 합성 데이터 리소스를 제공하는 것을 목표로 합니다. 이 데이터셋은 40만 개 이상의 이미지-텍스트 질의응답 쌍을 포함하고 있어 시각적 답변 작업을 지원합니다.
직접 사용:https://go.hyper.ai/aNjiz
4. NonverbalTTS 비언어적 오디오 생성 데이터 세트
NonverbalTTS는 VK Lab과 Yandex가 공동으로 개발한 비언어적 오디오 생성 데이터셋입니다. 표현력이 풍부한 텍스트-오디오(TTS) 연구를 촉진하고 감정과 비언어적 소리가 포함된 자연스러운 음성을 생성하는 모델을 지원하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/0Gz9V
5. GPT 이미지 편집-1.5M 이미지 생성 데이터 세트
GPT Image Edit-1.5M은 캘리포니아 대학교 산타크루즈 캠퍼스와 에든버러 대학교에서 발표한 이미지 생성 데이터셋입니다. 이미지 편집 모델의 학습 및 평가를 위한 포괄적인 멀티모달 데이터 리소스를 제공하는 것을 목표로 합니다. 이 데이터셋은 150만 개 이상의 고품질 트리플릿(명령어, 원본 이미지, 편집된 이미지)을 포함합니다.
직접 사용:https://go.hyper.ai/ohpmD

6. UniRef50 단백질 서열 데이터 세트
UniRef50 단백질 서열 데이터세트는 UniProt 지식베이스에서 파생되었으며, UniParc 서열에서 반복적 클러스터링을 통해 추출되었습니다. 이러한 반복적 과정을 통해 UniRef50의 대표 서열은 고품질, 비중복성, 다양성을 보장하여 단백질 언어 모델에 필요한 단백질 서열 공간의 광범위한 커버리지를 제공합니다.
직접 사용:https://go.hyper.ai/EcUF5
7. 차이 인식 공정성 차이 인식 벤치마크 데이터 세트
차이 인식 공정성(Difference-Aware Fairness)은 스탠퍼드 대학교에서 발표한 차이 인식 벤치마크 데이터셋입니다. 이 데이터셋은 차이 인식 및 맥락 인식 분야에서 모델의 성능을 측정하는 것을 목표로 합니다. 관련 논문은 ACL 2025에 게재되었으며, 최우수 논문상을 수상했습니다.
직접 사용:https://go.hyper.ai/wwBos
8. T-Wix 러시아 SFT 데이터 세트
T-Wix는 499,598개의 러시아어 샘플을 포함하는 SFT 데이터 세트로, 알고리즘 및 수학 문제 해결부터 대화, 논리적 사고, 추론 패턴까지 모델의 역량을 강화하도록 설계되었습니다.
직접 사용:https://go.hyper.ai/p0sgT
9. WebInstruct 검증된 다중 도메인 추론 데이터 세트
WebInstruct-verified는 워털루 대학교와 벡터 연구소가 공동으로 발표한 다중 영역 추론 데이터셋입니다. 이 데이터셋은 LLM 학생들의 수학 강점을 유지하면서 다양한 영역에 걸친 추론 능력을 향상시키는 것을 목표로 합니다. 이 데이터셋은 객관식 문제 및 수치 표현 데이터셋을 포함한 다양한 답안 형식에 걸쳐 약 23만 개의 추론 문제를 포함하고 있으며, 각 영역별로 균형 있게 분포되어 있습니다.
직접 사용:https://go.hyper.ai/oCgsZ
10. Finance-Instruct-500k 재무 추론 데이터 세트
Finance-Instruct-500k는 금융 업무, 추론 및 멀티턴 대화를 위한 고급 언어 모델을 학습하도록 설계된 금융 추론 데이터셋입니다. 이 데이터셋은 금융 질의응답, 추론, 감정 분석, 주제 분류, 다국어 개체명 인식, 대화형 AI를 포함하는 50만 개 이상의 금융 분야 고품질 레코드를 포함하고 있습니다.
직접 사용:https://go.hyper.ai/03UVH
선택된 공개 튜토리얼
1. Higgs Audio V2: 음성 생성의 표현력을 재정의하다
Higgs Audio V2는 Boson AI의 Li Mu와 그의 팀이 개발한 대규모 음성 모델입니다. Seed-TTS Eval 및 Emotional Speech Dataset(ESD)을 포함한 기존 TTS 벤치마크에서 최첨단 성능을 달성합니다. 이 모델은 내레이션 중 자동 운율 적응 및 여러 언어로 자연스러운 다중 화자 대화의 제로샷 생성 등 이전 시스템에서는 보기 드문 기능을 보여줍니다.
온라인으로 실행:https://go.hyper.ai/BqZJD
2. Ovis-U1-3B: 다중 모드 이해 및 생성 모델
Ovis-U1-3B는 알리바바 그룹의 Ovis 팀이 출시한 멀티모달 통합 모델입니다. 이 모델은 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집이라는 세 가지 핵심 기능을 통합합니다. 고급 아키텍처와 협업 통합 학습을 활용하여 고충실도 이미지 합성과 효율적인 텍스트-비주얼 상호작용을 지원합니다.
온라인으로 실행:https://go.hyper.ai/oSA7p

3. Neta Lumina: 고품질 2D 스타일 이미지 생성 모델
네타 루미나(Neta Lumina)는 네타.아트(Neta.art)에서 출시한 고품질 애니메이션 스타일 이미지 생성 모델입니다. 상하이 인공지능 연구소의 알파-VLLM 팀이 개발한 오픈소스 프로젝트인 루미나-이미지-2.0을 기반으로 하는 이 모델은 방대한 양의 고품질 애니메이션 스타일 이미지와 다국어 레이블 데이터를 활용하여 강력한 수요 이해 및 해석 기능을 제공합니다.
온라인으로 실행:https://go.hyper.ai/nxCwD

4. Qwen-Image: 고급 텍스트 렌더링 기능을 갖춘 이미지 모델
Qwen-Image는 Alibaba Tongyi Qianwen 팀이 개발한 고품질 이미지 생성 및 편집을 위한 대규모 모델입니다. 이 모델은 텍스트 렌더링 분야에서 획기적인 발전을 이루어, 중국어와 영어 모두에서 여러 줄로 구성된 단락 단위의 고품질 출력을 지원하고, 복잡한 장면과 밀리미터 단위의 세부 묘사를 정확하게 재현합니다.
온라인으로 실행:https://go.hyper.ai/8s00s

5. MediCLIP: CLIP을 이용한 소규모 의료 영상에서의 이상 탐지
베이징대학교에서 발표한 MediCLIP은 매우 적은 수의 정상 의료 이미지만으로도 최첨단 이상 탐지 성능을 달성하는 효율적인 단 몇 번의 촬영으로 구성된 의료 이미지 이상 탐지 방법입니다. 이 모델은 학습 가능한 큐, 어댑터, 그리고 현실적인 의료 이미지 이상 탐지 합성 작업을 통합합니다.
온라인으로 실행:https://go.hyper.ai/3BnDy
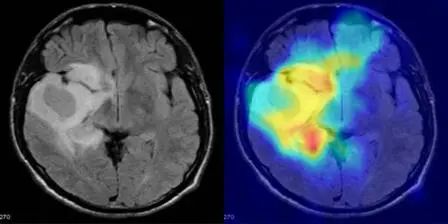
6. 아이네이아스 모델: 고대 로마 비문 복원 데모
아이네이아스는 구글 딥마인드가 여러 대학과 협력하여 개발한 다중 모드 생성 신경망입니다. 라틴어 및 고대 그리스어 비문의 텍스트 복원, 지리적 속성, 그리고 연대기적 속성에 사용됩니다. 이 모델의 출시는 디지털 금석학의 새로운 시대를 열었습니다. 고대 텍스트 복원, 지리적/연대기적 속성, 그리고 역사 연구 지원 분야에서 이 모델의 잠재력은 엄청나며, 과학적 발견과 학제간 응용을 가속화할 것으로 기대됩니다.
온라인으로 실행:https://go.hyper.ai/8ROfT

7. Qwen3-Coder-30B-A3B-Instruct의 원클릭 배포
Qwen3-Coder-30B-A3B-Instruct는 알리바바의 Tongyi Wanxiang Lab에서 개발한 대규모 언어 모델입니다. 프록시 코딩, 프록시 브라우저 사용 및 기타 기본 코딩 작업을 위한 개방형 모델에서 뛰어난 성능을 보여주며, 여러 프로그래밍 언어로 작성된 코딩 작업을 효율적으로 처리할 수 있습니다. 강력한 상황 이해 및 논리적 추론 기능을 통해 복잡한 프로젝트 개발 및 코드 최적화에 탁월한 선택입니다.
온라인으로 실행:https://go.hyper.ai/vYf3s
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. Qwen-Image 기술 보고서
Qwen 제품군의 기반 이미지 생성 모델인 Qwen-Image는 복잡한 텍스트 렌더링과 정밀한 이미지 편집 분야에서 상당한 진전을 이루었습니다. 복잡한 텍스트 렌더링으로 인한 어려움을 해결하기 위해 연구진은 대규모 데이터 수집, 필터링, 주석, 합성 및 밸런싱을 아우르는 포괄적인 데이터 처리 파이프라인을 설계했습니다. 이 모델은 여러 벤치마크에서 최첨단 성능을 달성하여 이미지 생성 및 편집 작업에서 강력한 역량을 충분히 입증했습니다.
논문 링크:https://go.hyper.ai/HWjVM
2. 시드 확산: 고속 추론을 갖춘 대규모 확산 언어 모델
본 논문은 매우 빠른 추론 속도를 자랑하는 이산 상태 확산 메커니즘에 기반한 대규모 언어 모델인 Seed Diffusion Preview를 제안합니다. 이산 확산 모델은 비순차적이고 병렬적인 생성 메커니즘을 통해 추론 효율을 크게 향상시키고 기존 토큰 단위 디코딩과 관련된 고유 지연 시간을 효과적으로 완화합니다.
논문 링크:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: 심층 연구 에이전트 및 에이전트 기반 모델 훈련을 위한 프레임워크
일반 AI 에이전트는 차세대 인공지능의 초석 프레임워크로 점점 더 주목받고 있으며, 복잡한 추론, 네트워크 상호작용, 프로그래밍, 그리고 자율적인 연구를 가능하게 합니다. 본 연구에서 연구진은 고급 AI 에이전트의 개발 및 평가를 민주화하기 위해 설계된 완전 오픈 소스이며 대부분 무료로 제공되는 다중 모듈 지능형 에이전트 프레임워크인 Cognitive Kernel-Pro를 제안합니다.
논문 링크:https://go.hyper.ai/65j3v
4. 고정 그 이상: 확산형 대규모 언어 모델을 위한 가변 길이 잡음 제거
본 논문에서 연구진은 DLLM의 동적이고 적응적인 길이 확장을 가능하게 하는 새로운 학습 없는 노이즈 제거 전략인 DAEDAL을 제안합니다. 다양한 DLLM에 대한 광범위한 실험을 통해 DAEDAL이 정밀하게 조정된 고정 길이 기준 모델의 성능과 동일하거나, 경우에 따라 이를 능가하는 동시에 계산 효율을 크게 향상시키고 더 높은 유효 토큰 비율을 달성함을 보여줍니다.
논문 링크:https://go.hyper.ai/p7WxK
5. Skywork UniPic: 시각적 이해 및 생성을 위한 통합 자기회귀 모델링
본 논문에서는 15억 개의 매개변수를 가진 자기회귀 모델인 Skywork UniPic을 제시합니다. Skywork UniPic은 작업별 어댑터나 모듈 간 커넥터에 의존하지 않고 단일 아키텍처 내에서 이미지 이해, 텍스트-이미지 생성, 이미지 편집을 통합합니다. Skywork UniPic은 과도한 리소스 비용 없이 고충실도 멀티모달 융합을 달성할 수 있음을 보여줌으로써, 배포 가능한 고충실도 멀티모달 AI를 위한 실질적인 패러다임을 제시합니다.
논문 링크:https://go.hyper.ai/FiVaf
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. Nature 저널에 게재된 이 폐수 역학 평가는 유전자 시퀀싱과 머신 러닝을 기반으로 하며, 최대 4주 일찍 바이러스를 감지할 수 있습니다.
네바다대학교 라스베이거스 캠퍼스 연구팀은 비지도 학습(unsupervised machine learning) 프로세스 설계를 기반으로 하는 ICA-Var라는 다변량 분석 방법을 제안했습니다. 이 방법은 독립 성분 분석을 통해 폐수 데이터에서 공변량 및 시간에 따라 진화하는 돌연변이 패턴을 추출하여 변이를 더 빠르고 정확하게 탐지합니다.
전체 보고서 보기:https://go.hyper.ai/z1vVo
2. 온라인 튜토리얼 | Qwen3-Coder-Flash는 Claude4와 유사한 에이전트 기능을 탑재하여 최신 오픈 소스 AI 프로그래밍을 새롭게 선보입니다.
Qwen 팀은 프록시 코딩, 프록시 브라우저 사용 및 기타 기본 코딩 작업에서 오픈소스 모델 중 탁월한 성능을 보이는 Qwen3-Coder-Flash를 오픈소스로 공개했습니다. 여러 프로그래밍 언어로 코딩 작업을 효율적으로 처리할 수 있습니다. 동시에 강력한 컨텍스트 이해 및 논리적 추론 기능을 통해 복잡한 프로젝트 개발 및 코드 최적화에도 뛰어난 성능을 발휘합니다.
전체 보고서 보기:https://go.hyper.ai/FmOep
3. 데이비드 베이커 연구팀은 Science에 약물로 치료할 수 없는 표적을 특별히 표적으로 삼아 무질서한 영역 결합 단백질을 설계하는 새로운 방법을 제안했습니다.
자연적으로 무질서한 단백질을 표적으로 삼는 문제를 해결하기 위해 데이비드 베이커와 그의 연구팀은 로고스(Logos)라는 단백질 설계 전략을 제안했습니다. 로고스는 단백질이 다양한 확장된 형태로 자연적으로 무질서한 영역에 결합하고, 곁사슬이 상보적인 결합 포켓에 삽입되도록 하는 것입니다. 이 연구는 RFdiffusion 모델을 활용하여 포켓을 재구성하고 이를 광범위한 서열로 일반화함으로써, 설계된 결합 단백질-표적 펩타이드 템플릿을 기반으로 무질서한 단백질 영역을 보편적으로 인식할 수 있도록 합니다.
전체 보고서 보기:https://go.hyper.ai/F0lti
칭화대학교 지능산업연구소의 저우 하오 연구팀이 상하이 인공지능연구소와 협력하여 베이지안 흐름 네트워크를 기반으로 한 단백질 기초 모델 AMix-1을 제안했습니다. 연구진은 사전 학습 스케일링 법칙, 창발적 능력, 맥락 내 학습, 그리고 테스트 시점 스케일링이라는 체계적인 방법론을 사용하여 단백질 기초 모델을 구축하고, 대규모 언어 모델의 성공적인 패러다임을 단백질 설계에 도입했습니다. 이 모델의 효율성과 다재다능함은 테스트 시점 스케일링과 실제 실험을 통해 검증되었습니다.
전체 보고서 보기:https://go.hyper.ai/X9iMe
5. GPT-5 출시, 샘 알트먼: 프로그래밍, 글쓰기, 건강 분야의 주요 업그레이드를 통해 박사 학위를 소지한 전문가와 대화하는 것과 같습니다.
OpenAI는 ChatGPT의 가장 일반적인 세 가지 사용 사례인 글쓰기, 프로그래밍, 건강 관리에서 성능을 더욱 향상시킨 GPT-5를 공식 출시했습니다. GPT-5는 대부분의 질문에 답하는 지능적이고 효율적인 모델(GPT-5-main), 더 복잡한 문제를 위한 심층 추론 모델(GPT-5-thinking), 그리고 대화 유형, 질문의 복잡성, 필요한 도구, 그리고 사용자의 명시적 의도를 기반으로 사용할 모델을 신속하게 결정하는 실시간 라우터로 구성된 통합 시스템입니다.
전체 보고서 보기:https://go.hyper.ai/gFHQg
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.https://go.hyper.ai/wiki
정상회담 8월 마감
8월 21일 11:59:59 아스플로스 2026
8월 27일 7:59:59 USENIX 보안 심포지엄 2025
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!