Command Palette
Search for a command to run...
ACL 25 최우수 논문! 스탠퍼드 대학교, 차이 인식 공정성 구축을 위한 차이 인식 벤치마크 데이터셋 공개; 자가 강제 기법으로 1초 미만의 지연 시간으로 실시간 스트리밍 비디오 생성 달성

AI 모델은 종종 기존의 "동등한 대우"를 공정성과 동일시합니다.법적 맥락과 손해 평가 시나리오에서 공정성을 달성하기 위해 "차별 없는 대우" 원칙을 기계적으로 적용하는 것은 보편적인 해결책이 아닙니다.공정성 차원이 하나만 있어도 쉽게 편향된 결과가 나올 수 있으므로 집단 간 차이를 고려해야 합니다.따라서 "차별 없는 공정성"에서 "인지된 차이에 기반한 공정성"으로 패러다임을 점진적으로 전환하기 위해 대규모 모델을 홍보하는 것이 점점 더 중요해지고 있습니다.
이를 바탕으로,스탠포드 대학은 차이 인식과 맥락 인식 측면에서 모델의 성능을 측정하는 것을 목표로 하는 Difference Aware Fairness 벤치마크 데이터 세트를 공개했습니다.관련 연구 결과는 ACL의 25개 우수 논문으로 선정되었습니다. 이 데이터셋은 법률, 전문 분야, 문화 분야를 포함한 다양한 실제 상황을 포괄하는 기술적 과제와 규범적 과제의 두 가지 유형으로 나뉜 8개의 벤치마크를 포함합니다. 각 벤치마크는 2,000개의 질문으로 구성되어 있으며, 그중 1,000개는 서로 다른 집단 간의 차이를 구분하는 질문을 포함하여 총 16,000개의 질문이 있습니다. 이 벤치마크의 발표는 대규모 모델의 공정성 측면을 개선하여 기술 발전과 사회적 가치 간의 격차를 해소하는 데 중요한 보완책을 제공하고, AI 생태계가 더욱 다양하고 정확한 방향으로 심층적으로 발전하는 데 크게 기여할 것입니다.
Difference Aware Fairness Benchmark Dataset이 HyperAI 공식 웹사이트에서 제공됩니다. 지금 바로 다운로드하여 사용해 보세요!
온라인 사용:https://go.hyper.ai/XOx97
7월 28일부터 8월 1일까지 hyper.ai 공식 웹사이트 업데이트에 대한 간략한 개요를 소개합니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 5개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 8월 마감일 상위 컨퍼런스: 9
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
B3DB는 캐나다 맥마스터 대학교에서 발표한 대규모 생물학적 벤치마크 데이터셋입니다. 소분자 혈액-뇌 장벽 투과성 모델링에 대한 벤치마크를 제공하는 것을 목표로 합니다. 이 데이터셋은 50개의 출판된 자료를 바탕으로 작성되었으며, 이러한 분자들의 물리화학적 특성의 일부를 제공합니다. 일부 분자에 대해서는 수치형 logBB 값이 제공되며, 전체 데이터셋은 수치형 데이터와 범주형 데이터를 모두 포함합니다.
직접 사용:https://go.hyper.ai/0mPpP
Anime은 애니메이션 데이터 세트입니다. http://MyAnimeList.net 이 데이터베이스는 데이터 과학자, 머신러닝 엔지니어, 그리고 애니메이션 애호가들에게 풍부하고 명확하며 쉽게 접근할 수 있는 리소스를 제공하는 것을 목표로 합니다. 이 데이터 세트는 28,000개 이상의 독특한 애니메이션 작품에 대한 정보를 포함하고 있어 애니메이션 업계의 트렌드에 대한 통찰력을 제공합니다.
직접 사용:https://go.hyper.ai/MxrqC
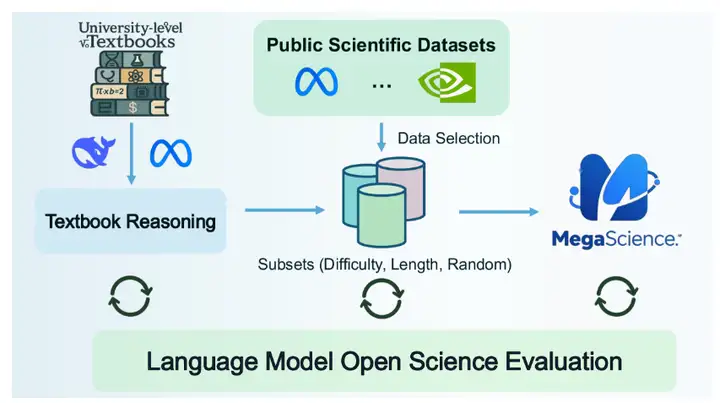
메가사이언스(MegaScience)는 상하이 교통대학교에서 공개한 과학적 추론 데이터셋입니다. 이 데이터셋은 125만 개의 인스턴스를 포함하고 있으며, 특히 과학 연구 분야의 문헌 검색, 정보 추출, 자동 요약, 인용 분석 등의 작업에서 자연어 처리(NLP) 및 머신러닝 모델을 지원하도록 설계되었습니다.
직접 사용:https://go.hyper.ai/694qh
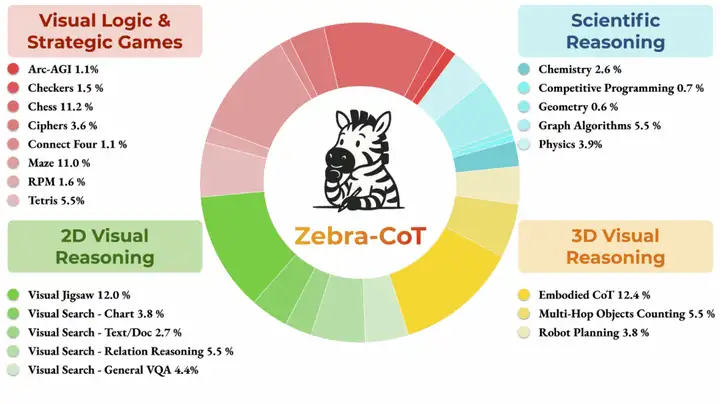
4. Zebra-CoT 텍스트-이미지 추론 데이터 세트
Zebra-CoT는 컬럼비아 대학교, 메릴랜드 대학교, 서던캘리포니아 대학교, 뉴욕 대학교가 공동으로 발표한 시각 언어 추론 데이터셋입니다. 이 데이터셋은 모델이 이미지와 텍스트 간의 논리적 관계를 더 잘 이해하도록 돕는 것을 목표로 합니다. 시각적 질의응답 및 이미지 설명 생성과 같은 분야에서 널리 사용되어 추론 능력과 정확도 향상에 기여합니다. 이 데이터셋은 과학적 추론, 2D 시각 추론, 3D 시각 추론, 시각 논리 및 전략 게임의 네 가지 주요 범주를 포괄하는 182,384개의 샘플을 포함합니다.
직접 사용:https://go.hyper.ai/y2a1e
PolyMath는 알리바바와 상하이 교통대학교가 공동으로 개발한 수학적 추론 데이터셋입니다. 폴리매스 연구 활성화를 목표로 합니다. 이 데이터셋은 500개의 고품질 수학적 추론 문제를 포함하고 있으며, 각 언어 레벨별로 125개의 문제가 있습니다.
직접 사용:https://go.hyper.ai/yRVfY
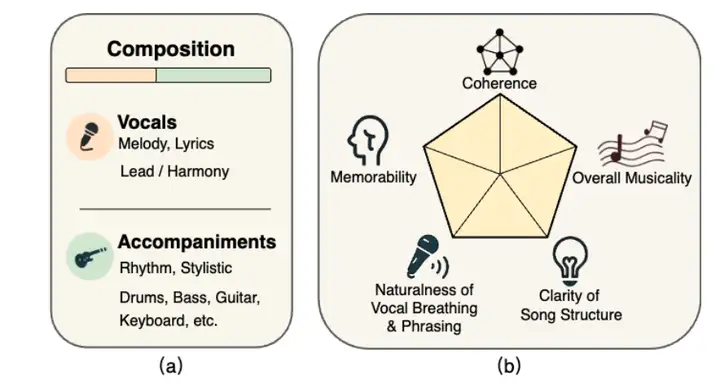
SongEval은 상하이 음악원, 노스웨스턴 폴리테크닉 대학교, 서리 대학교, 홍콩 과학기술대학교가 공동으로 발표한 음악 평가 데이터셋입니다. 이 데이터셋은 완전한 곡에 대한 미적 평가를 수행하는 것을 목표로 합니다. 이 데이터셋은 보컬과 악기 연주를 포함한 2,399곡 이상의 곡을 포함하고 있으며, 16명의 전문 평가자가 다섯 가지 지각적 차원(전반적 일관성, 기억성, 자연스러운 보컬 호흡과 프레이징, 곡 구조의 명확성, 그리고 전반적인 음악성)에 대해 주석을 달았습니다. 이 데이터셋은 중국어 및 영어 노래와 9개 주요 장르를 포함하여 약 140시간 분량의 고품질 오디오를 포함하고 있습니다.
직접 사용:https://go.hyper.ai/ohp0k
7. Vchitect T2V 비디오 생성 데이터 세트
Vchitect T2V는 상하이 인공지능 연구소에서 공개한 비디오 생성 데이터셋입니다. 모델의 텍스트와 시각적 콘텐츠 간 변환 능력을 향상시켜 연구자와 개발자가 이미지 생성, 의미 이해, 그리고 크로스 모달 작업에서 진전을 이루는 데 도움을 주는 것을 목표로 합니다. 이 데이터셋에는 1,400만 개의 고품질 비디오가 포함되어 있으며, 각 비디오에는 상세한 텍스트 캡션이 포함되어 있습니다.
직접 사용:https://go.hyper.ai/vLs9z
LED는 현재까지 기계 판독이 가능한 라틴어 명문 데이터 세트 중 가장 큰 규모로, 176,861개의 명문으로 구성되어 있습니다. 그러나 이 명문의 대부분은 부분적으로 손상되어 있으며, 사용 가능한 이미지를 생성하는 것은 5% 명문뿐입니다. 이 데이터는 가장 포괄적인 라틴어 명문 데이터베이스 세 곳, 즉 로마 명문 데이터베이스(EDR), 하이델베르크 명문 데이터베이스(EDH), 그리고 클라우스-슬라비 데이터베이스에서 제공됩니다.
직접 사용:https://go.hyper.ai/O8noU
AutoCaption 데이터셋은 Tjunlp Labs에서 공개한 비디오 자막 벤치마크 데이터셋입니다. 이 데이터셋은 비디오 자막 생성을 위한 다중 모드 대규모 언어 모델 분야의 연구를 촉진하는 것을 목표로 합니다. 이 데이터셋은 두 개의 하위 집합으로 구성되어 있으며, 총 11,184개의 샘플을 포함합니다.
직접 사용:https://go.hyper.ai/pgOCw
10. ArtVIP Machine 대화형 이미지 데이터 세트
ArtVIP는 베이징 휴머노이드 로봇 혁신 센터에서 공개한 머신 인터랙티브 이미지 데이터세트입니다. 이 데이터세트는 26개 카테고리에 걸쳐 206개의 관절형 객체를 포함하고 있습니다. 정밀한 기하학적 메시와 고해상도 텍스처를 통해 시각적 사실성을 보장하고, 정밀하게 조정된 동적 매개변수를 통해 물리적 충실도를 구현하며, 자산 내에 모듈식 인터랙티브 동작을 내장하는 최초의 데이터세트로, 픽셀 수준의 어포던스 주석 기능을 지원합니다.
직접 사용:https://go.hyper.ai/vGYek

선택된 공개 튜토리얼
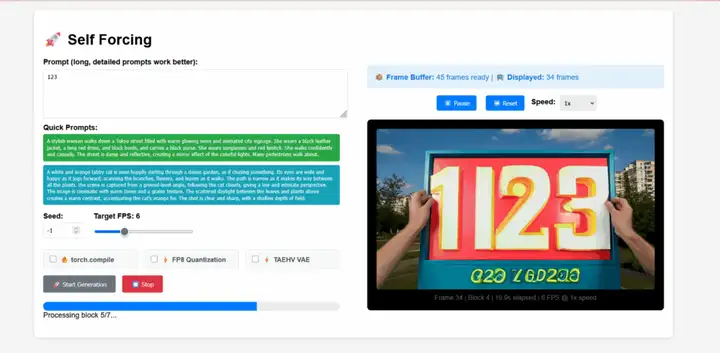
자가강제(Self-Forcing)는 Xun Huang 연구팀이 제안한 자기회귀 비디오 확산 모델을 위한 새로운 학습 패러다임입니다. 이는 실제 맥락에서 학습된 모델이 추론 과정에서 자체적으로 불완전한 출력을 기반으로 시퀀스를 생성해야 하는, 오랫동안 지속되어 온 노출 편향 문제를 해결합니다. 이 모델은 단일 GPU에서 1초 미만의 지연 시간으로 실시간 스트리밍 비디오를 생성하는 동시에, 현저히 느리고 비인과적 확산 모델의 생성 품질과 동등하거나 심지어 더 나은 성능을 달성합니다.
온라인으로 실행:https://go.hyper.ai/j19Hx
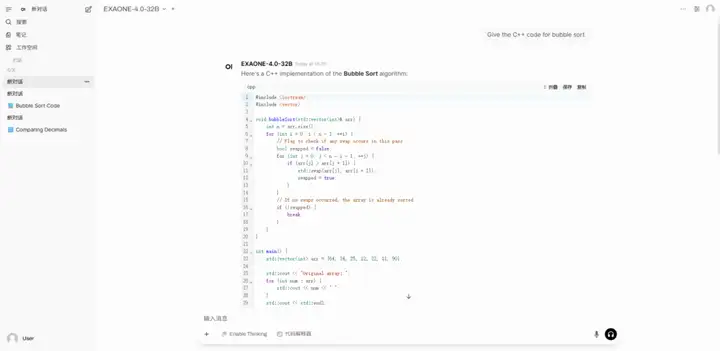
2. vLLM + Open WebUI를 사용하여 EXAONE-4.0-32B 배포
EXAONE-4.0은 LG AI Research가 한국에서 출시한 차세대 하이브리드 추론 AI 모델입니다. 또한, 국내 최초의 하이브리드 추론 AI 모델이기도 합니다. 이 모델은 일반적인 자연어 처리 능력과 EXAONE Deep에서 검증된 고급 추론 능력을 결합하여 수학, 과학, 프로그래밍과 같은 까다로운 분야에서 획기적인 발전을 이루었습니다.
온라인으로 실행:https://go.hyper.ai/7XiZM
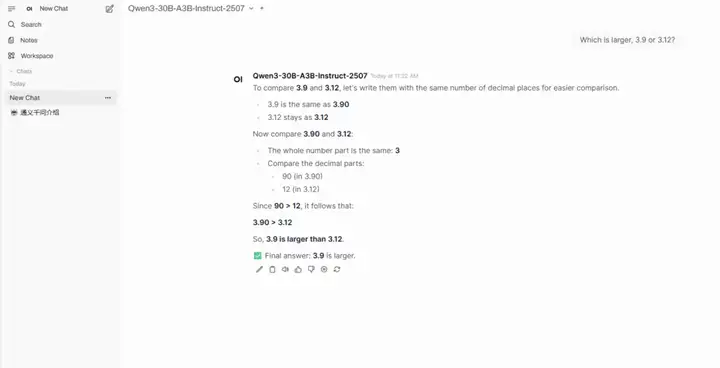
3. Qwen3-30B-A3B-Instruct-2507의 원클릭 배포
Qwen3-30B-A3B-Instruct-2507은 알리바바의 통이완샹 연구실에서 개발한 대규모 언어 모델입니다. 이 모델은 Qwen3-30B-A3B의 비사고 모드의 업데이트된 버전입니다. 30억(3B) 개의 매개변수만 활성화했음에도 불구하고 구글 제미니 2.5-플래시(비사고 모드) 및 OpenAI의 GPT-4o에 필적하는 놀라운 성능을 보인다는 점이 가장 큰 특징입니다. 이는 모델 효율성과 성능 최적화 측면에서 획기적인 진전을 의미합니다.
온라인으로 실행:https://go.hyper.ai/hr1o6
4. Wan2.2: 개방형 고급 대규모 비디오 생성 모델
Wan-2.2는 알리바바의 통이완샹 랩(Tongyi Wanxiang Lab)에서 개발한 오픈소스 고급 AI 비디오 생성 모델입니다. 이 모델은 전문가 혼합(MoE) 아키텍처를 도입하여 생성 품질과 연산 효율성을 효과적으로 향상시킵니다. 또한 조명, 색상, 구도 및 기타 미적 효과를 정밀하게 제어할 수 있는 영화적 미적 제어 시스템을 선도합니다.
온라인으로 실행:https://go.hyper.ai/AG6CE
5. PE3R: 효율적인 인식 및 3D 재구성을 위한 프레임워크
PE3R(Perception-Efficient 3D Reconstruction)은 싱가포르 국립대학교(NUS) XML 랩에서 발표한 혁신적인 오픈소스 3D 재구성 프레임워크입니다. 다중 모드 인식 기술을 통합하여 효율적이고 지능적인 장면 모델링을 구현합니다. 여러 최첨단 컴퓨터 비전 연구 결과를 기반으로 개발된 이 프레임워크는 2D 이미지만으로 3D 장면을 빠르게 재구성합니다. RTX 3090 그래픽 카드에서 단일 장면 재구성 시간은 평균 2.3분으로, 기존 방식 대비 65% 이상 향상되었습니다.
온라인으로 실행:https://go.hyper.ai/3BnDy

이번 주 논문 추천
실제 추론 시나리오에서 대규모 언어 모델(LLM)은 과제 해결을 지원하는 외부 도구의 이점을 활용하는 경우가 많습니다. 그러나 기존 강화 학습 알고리즘은 모델 고유의 장거리 추론 능력과 다중 라운드 도구 상호작용의 능숙도 간의 균형을 맞추는 데 어려움을 겪습니다. 이러한 간극을 메우기 위해 본 논문에서는 다중 라운드 LLM 기반 에이전트를 학습하도록 특별히 설계된 새로운 에이전트 강화 학습 알고리즘인 에이전트 강화 정책 최적화(ARPO)를 제안합니다. 이 알고리즘은 기존 방법보다 도구 사용 예산이 절반으로 줄어들어 성능 향상을 달성하며, LLM 기반 에이전트를 실시간 동적 환경에 맞춰 조정할 수 있는 확장 가능한 솔루션을 제공합니다.
논문 링크:https://go.hyper.ai/lPyT2
2. HunyuanWorld 1.0: 단어나 픽셀로 몰입적이고 탐색 가능하며 상호 작용이 가능한 3D 세계 생성
텍스트나 이미지로부터 몰입적이고 인터랙티브한 3D 세계를 생성하는 것은 컴퓨터 비전 및 그래픽 분야에서 여전히 근본적인 과제로 남아 있습니다. 기존의 세계 생성 방법은 3D 일관성 부족 및 낮은 렌더링 효율성과 같은 한계를 가지고 있습니다. 이러한 문제를 해결하기 위해 본 논문에서는 텍스트와 이미지로부터 몰입적이고 탐색 가능하며 인터랙티브한 3D 장면을 생성하는 혁신적인 프레임워크인 HunyuanWorld 1.0을 제안합니다.
논문 링크:https://go.hyper.ai/aMbdz
3. ScreenCoder: 모듈형 멀티모달 에이전트를 통한 프런트엔드 자동화를 위한 시각적-코드 생성 향상
대규모 언어 모델(LLM)을 이용한 텍스트-코드 생성 기술의 최근 발전에도 불구하고, 기존 방법들은 자연어 단서에만 의존하여 레이아웃의 공간 구조와 시각적 디자인 의도를 효과적으로 포착하는 데 어려움을 겪고 있습니다. 반면, 실제 UI 개발은 본질적으로 다중 모드이며 시각적 스케치나 프로토타입으로 시작하는 경우가 많습니다. 이러한 간극을 메우기 위해 본 논문에서는 로컬라이제이션, 계획, 생성이라는 세 가지 해석 가능한 단계를 통해 UI-코드 생성을 지원하는 모듈형 다중 에이전트 프레임워크인 ScreenCoder를 제안합니다.
논문 링크:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: 실제 단편 영상의 구조화된 이해
현재의 대규모 멀티모달 모델은 효과적인 비디오 검색 및 추천, 그리고 새로운 비디오 애플리케이션의 기반이 되는 시간적으로 구조화되고 상세하며 심층적인 비디오 이해 능력이 부족합니다. 본 연구는 원시 비디오 입력부터 시각, 오디오, 텍스트 신호를 종단 간(end-to-end) 처리하여 구조화된 이해를 달성하는 멀티모달 모델인 ARC-Hunyuan-Video를 제안합니다. 이 모델은 다분할 타임스탬프 비디오 설명 및 요약, 개방형 비디오 질의응답, 시간적 비디오 위치 추정, 그리고 비디오 추론 기능을 제공합니다.
논문 링크:https://go.hyper.ai/ogYbH
복잡하고 긴 연구 보고서를 생성하기 위해 일반적인 테스트 시간 스케일링 알고리즘을 사용할 때, 성능에 병목 현상이 발생하는 경우가 많습니다. 인간 연구 과정의 반복적인 특성에서 영감을 받아 본 논문에서는 테스트 시간 확산 심층 연구자(TTD-DR)를 제안합니다. TTD-DR은 연구 방향을 제시하는 진화하는 기반 역할을 하는 예비 초안(업데이트 가능한 프레임워크)으로 프로세스를 시작합니다. 이러한 초안 중심 설계는 반복적인 검색 과정에서 정보 손실을 줄이는 동시에 보고서 작성 과정을 더욱 시의적절하고 일관성 있게 만들어 줍니다.
논문 링크:https://go.hyper.ai/D4gUK
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
베이징대학교의 시 복신(Shi Boxin)이 이끄는 팀은 OpenBayes 베이지안 컴퓨팅과 협력하여 텍스트 기반 파노라마 비디오 생성 프레임워크인 PanoWan을 출시했습니다. 간결하고 효율적인 모듈형 아키텍처를 갖춘 이 접근법은 사전 훈련된 텍스트-비디오 모델의 생성 사전 확률을 파노라마 영역으로 원활하게 전환합니다.
전체 보고서 보기:https://go.hyper.ai/9UWXl
2. 가치 평가 정확도 99% 이상! YOLOv11 기반 지능형 도자기 분류 프레임워크는 시각적 모델링과 경제 분석을 통합하여 문화재 분류 및 가치 평가를 수행합니다.
말레이시아 푸트라 대학교(UPM)와 뉴사우스웨일스 대학교(UNSW) 시드니 캠퍼스 연구팀은 YOLOv11 모델을 기반으로 도자기 유물의 자동 분류 및 시장 가치 추정을 위한 지능형 프레임워크를 공동 개발했습니다. 최적화된 YOLOv11 모델은 장식 패턴, 형태, 장인 정신 등 도자기의 주요 속성을 식별하고, 추출된 시각적 특징과 다중 소스 경매 데이터를 기반으로 시장 가격을 예측할 수 있습니다. 이는 지능형 도자기 진위 확인 및 디지털 유물 큐레이션을 위한 확장 가능한 솔루션을 제공합니다.
전체 보고서 보기:https://go.hyper.ai/XcuLz
3. 펜실베이니아 대학은 동물 독에서 386개의 새로운 항균 펩타이드를 식별하여 잠재적인 항생제 후보를 선별하는 딥 러닝 모델인 APEX를 개발했습니다.
미국 펜실베이니아 대학교 연구팀은 4개의 주요 독 데이터베이스를 통합하여 글로벌 독 데이터베이스를 구축하고, 독 프로테옴에서 잠재적인 항균 후보 물질을 체계적으로 발굴하는 데 특화된 APEX라는 시퀀스-투-기능 딥러닝 모델을 적용했습니다. 최종적으로 항균 잠재력을 가지면서도 기존 AMP와 서열 유사성이 낮은 386개의 후보 펩타이드를 선별했습니다.
전체 보고서 보기:https://go.hyper.ai/u067l
4. NVIDIA/UC Berkeley 등은 1분 안에 15일 예보를 완료하고 단일 카드 초고속 추론을 지원하는 머신 러닝 날씨 예보 시스템 FCN3를 제안했습니다.
엔비디아, 로렌스 버클리 국립연구소, 캘리포니아 대학교 버클리, 캘리포니아 공과대학(California Institute of Technology)의 공동 연구팀은 구형 신호 처리와 은닉 마르코프 집합 프레임워크를 결합한 확률론적 머신러닝 기상 예보 시스템인 FourCastNet 3(FCN3)을 출시했습니다. 이 시스템은 단일 엔비디아 H100 GPU에서 60초 만에 15일 예보를 생성할 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/JQh25
5. 온라인 튜토리얼 | 세계 최초의 MoE 영상 생성 모델! Alibaba Wan2.2 오픈 소스, 소비자용 그래픽 카드에서 영화 같은 AI 영상 제작 가능
알리바바의 통이완샹 랩(Tongyi Wanxiang Lab)은 최근 고급 AI 영상 생성 모델인 Wan2.2를 오픈소스로 공개했습니다. MoE(Mixture of Experts) 아키텍처를 도입한 이 모델은 영상 생성 품질과 연산 효율을 효과적으로 향상시켜 NVIDIA RTX 4090과 같은 소비자용 그래픽 카드에서 효율적인 작동을 가능하게 합니다. 또한, 조명, 색상, 구도 및 기타 미적 효과를 정밀하게 제어할 수 있는 영화적 미적 제어 시스템을 선도했습니다.
전체 보고서 보기:https://go.hyper.ai/RgFmY
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!