Command Palette
Search for a command to run...
오디오 미학 평가의 새로운 패러다임! Audiobox-Aesthetics는 4차원 오디오 정량화의 선구자이며, 670만 건의 소송을 처리했습니다! Caselaw는 법률 참고를 위한 규정 준수 청사진을 제시합니다.

기존의 오디오 평가는 대개 수동 청취에 의존하며, 주관적인 편향으로 인해 평가 기준을 통일하기 어렵습니다. 기존의 평가 방법과 도구는 특정 평가 결과를 제공할 수 있지만, 대부분은 전반적인 오디오 품질에만 초점을 맞추고 있으며, 지역적인 세부 사항에 대한 집중적인 분석이 부족합니다.
이를 위해,Meta AI는 오디오 품질 평가 도구인 Audiobox-Aesthetics를 출시했습니다.음성, 음악, 주변 소리에 대한 다차원 자동 분석을 실현합니다.제작 품질, 제작 복잡성, 콘텐츠 즐거움, 콘텐츠 유용성이라는 4가지 핵심 측면을 통해 오디오 품질을 종합적으로 평가합니다.이 솔루션은 수동 청취와 기존 도구의 근본적인 단점을 보완할 뿐만 아니라 오디오 제작자, 엔지니어, 연구자에게 전문가 수준의 정량적 분석을 제공하고 오디오 최적화를 위한 정확한 지침을 제공합니다.
현재 HyperAI 공식 홈페이지에서 "AudioBox-Aesthetics 오디오 미학 평가 데모"를 출시했습니다. 지금 바로 체험해보세요~
온라인 사용:https://go.hyper.ai/FNpIQ
7월 21일부터 7월 25일까지 hyper.ai 공식 웹사이트가 업데이트됩니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 8개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 8월 마감일 상위 컨퍼런스: 9
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. 의료정보 약물정보 데이터셋
의료 정보 데이터셋(MID 데이터셋)은 현재 가장 크고 대표적인 약물 정보 데이터셋입니다. 이 데이터셋은 44가지 치료 범주에 걸쳐 19만 2천 개 이상의 약물을 포괄하는 데이터를 포함하고 있으며, 정확하고 권위 있는 약물 정보를 제공하고, 약물 분류 및 치료 라벨을 지원하며, 임상시험 관리의 예측 및 효율성을 향상시키는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/qmGCW
2. Nemotron-Math-HumanReasoning 수학적 추론 데이터 세트
Nemotron-Math-HumanReasoning은 NVIDIA에서 출시한 수학적 추론 데이터셋으로, DeepSeek-R1과 같은 모델의 확장된 추론 스타일을 시뮬레이션하는 것을 목표로 합니다. 이 데이터셋은 OpenMathReasoning 데이터셋에서 가져온 50개의 수학 문제, 200개의 수기 답안, 그리고 QwQ-32B-Preview에서 생성된 50개의 추가 답안으로 구성되어 있습니다.
직접 사용:https://go.hyper.ai/udrjz
3. Updesh 인도어 합성 텍스트 데이터 세트
Updesh는 Microsoft에서 공개한 인도어 합성 텍스트 데이터셋으로, 인도어에 대한 대규모 언어 모델(LLM)의 사후 학습을 촉진하는 것을 목표로 합니다. 이 데이터셋은 아삼어와 벵골어 등의 언어를 포함하는 680만 개의 추론 데이터와 210만 개의 생성 데이터를 포함합니다.
직접 사용:https://go.hyper.ai/wMWci
4. QMOF150 양자화학 데이터 세트
QMOF150은 메타(Meta)와 케임브리지 대학교가 양자 물질 발견을 가속화하기 위해 발표한 양자 화학 데이터셋입니다. 이 데이터셋에는 약 14,000개의 금속 유기 골격체(MOF)와 배위 고분자가 포함되어 있습니다. 여기에는 DFT(분자량 푸리에 변환)를 이용한 구조 완화 후 실험적으로 특성화된 MOF의 계산된 특성이 포함되어 있으며, 여기에는 최적화된 기하 구조, 에너지, 밴드갭, 전하 밀도, 상태 밀도, 부분 전하, 스핀 밀도, 결합 차수 등이 포함되지만 이에 국한되지는 않습니다.
직접 사용:https://go.hyper.ai/2rxVD
5. 안전 조끼 감지 안전 조끼 감지 데이터 세트
Safety Vests Detection은 새로운 객체 감지 아키텍처(YOLOv8, Faster-RCNN, SSD 등)의 벤치마킹, 관련 개인 보호 장비(PPE) 감지 작업(헬멧, 장갑, 고글)의 전이 학습, 그리고 엣지에 배치된 안전 모니터의 프로토타입 개발을 위해 설계된 안전 조끼 감지 데이터셋입니다. 이 데이터셋은 안전 조끼 착용자를 자동으로 식별 및 감지하고 작업장 안전을 개선하는 모델을 개발하고 학습하는 데 도움을 줍니다. 이 데이터셋에는 3,897장의 고화질 사진, 경계 상자 주석, 이미지 컨텍스트가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/q0aEL

6. Open-Omega-Atom-1.5M 수학 및 과학적 추론 데이터 세트
Open-Omega-Atom-1.5M은 수학 및 과학 분야의 추론 능력 향상을 위해 설계된 수학적 및 과학적 추론 데이터셋입니다. 이 데이터셋은 약 150만 개의 데이터를 포함하고 있으며, 수학, 과학 및 코드 응용 프로그램을 위해 설계되었으며, 수학적 데이터가 데이터셋 구성에 중요한 역할을 합니다.
직접 사용:https://go.hyper.ai/ctAbA
7. AF-Chat 오디오 대화 텍스트 데이터세트
AF-Chat은 NVIDIA에서 대화 생성 모델의 학습 및 평가를 위해 공개한 오디오 대화 텍스트 데이터셋입니다. 이 데이터셋은 약 75,000개의 멀티턴, 멀티오디오 대화(평균 4.6개 세그먼트, 6.2개 라운드, 범위 2~8개 세그먼트, 2~10개 라운드)를 포함하고 있으며, 음성, 주변 소리, 음악을 포함합니다.
직접 사용:https://go.hyper.ai/mx6G0
8. rStar Coder 경쟁 수준 코딩 문제 데이터 세트
rStar Coder는 Microsoft에서 출시한 대규모 경쟁 수준 코딩 문제 데이터셋으로, 특히 경쟁 수준 코딩 문제를 처리할 때 대규모 언어 모델의 코드 추론 능력을 향상시키는 것을 목표로 합니다. 이 데이터셋은 418,000개의 경쟁 수준 프로그래밍 문제, 580,000개의 장문 추론 솔루션, 그리고 다양한 난이도의 테스트 케이스를 포함합니다. 각 솔루션은 다양한 난이도의 시뮬레이션 테스트 케이스를 통해 검증되었습니다.
직접 사용:https://go.hyper.ai/uJXHe
9. 판례법 법률 문헌 데이터 세트
Caselaw는 토론토 대학교에서 발행한 법률 문헌 데이터세트로, Caselaw Access Project와 Court Listener에서 수집한 670만 건의 판례를 포함하고 있습니다. Caselaw Access Project와 Court Listener는 하버드 법학 도서관, 미국 의회 법학 도서관, 대법원 데이터베이스 등 퍼블릭 도메인에 속하는 문서들을 포함하여 다양한 출처에서 법률 데이터를 수집합니다.
직접 사용:https://go.hyper.ai/a1bET
10. APM 단백질 생성 데이터 세트
APM은 후난대학교, 중국과학원, 그리고 ByteDance Seed Team이 2025년에 공개한 단백질 생성 데이터셋입니다. 단일 사슬 단백질 데이터셋과 다중 사슬 단백질 데이터셋으로 구성되어 있습니다.
직접 사용:https://go.hyper.ai/p4qgN
선택된 공개 튜토리얼
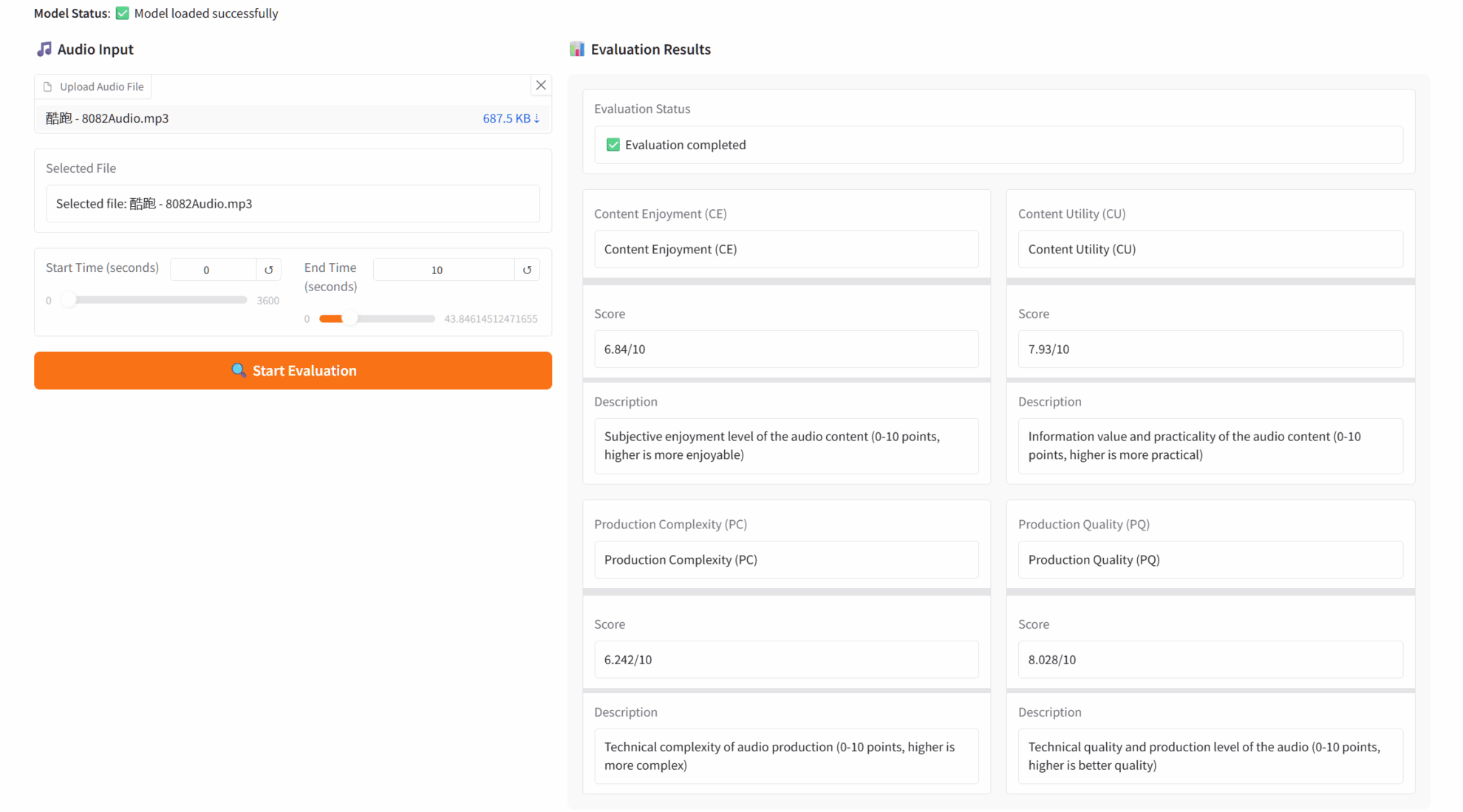
1. AudioBox-Aesthetics 오디오 미학 평가 데모
오디오박스-에스테틱스는 메타 AI에서 출시한 오디오 품질 평가 도구입니다. 딥러닝 기술을 기반으로 음성, 음악, 주변 소리에 대한 다차원 자동 분석을 구현하고, 4가지 핵심 차원을 통해 오디오 품질을 종합적으로 평가하며, 오디오 제작자, 엔지니어, 연구자에게 전문가 수준의 정량적 분석 결과를 제공합니다.
온라인으로 실행:https://go.hyper.ai/FNpIQ
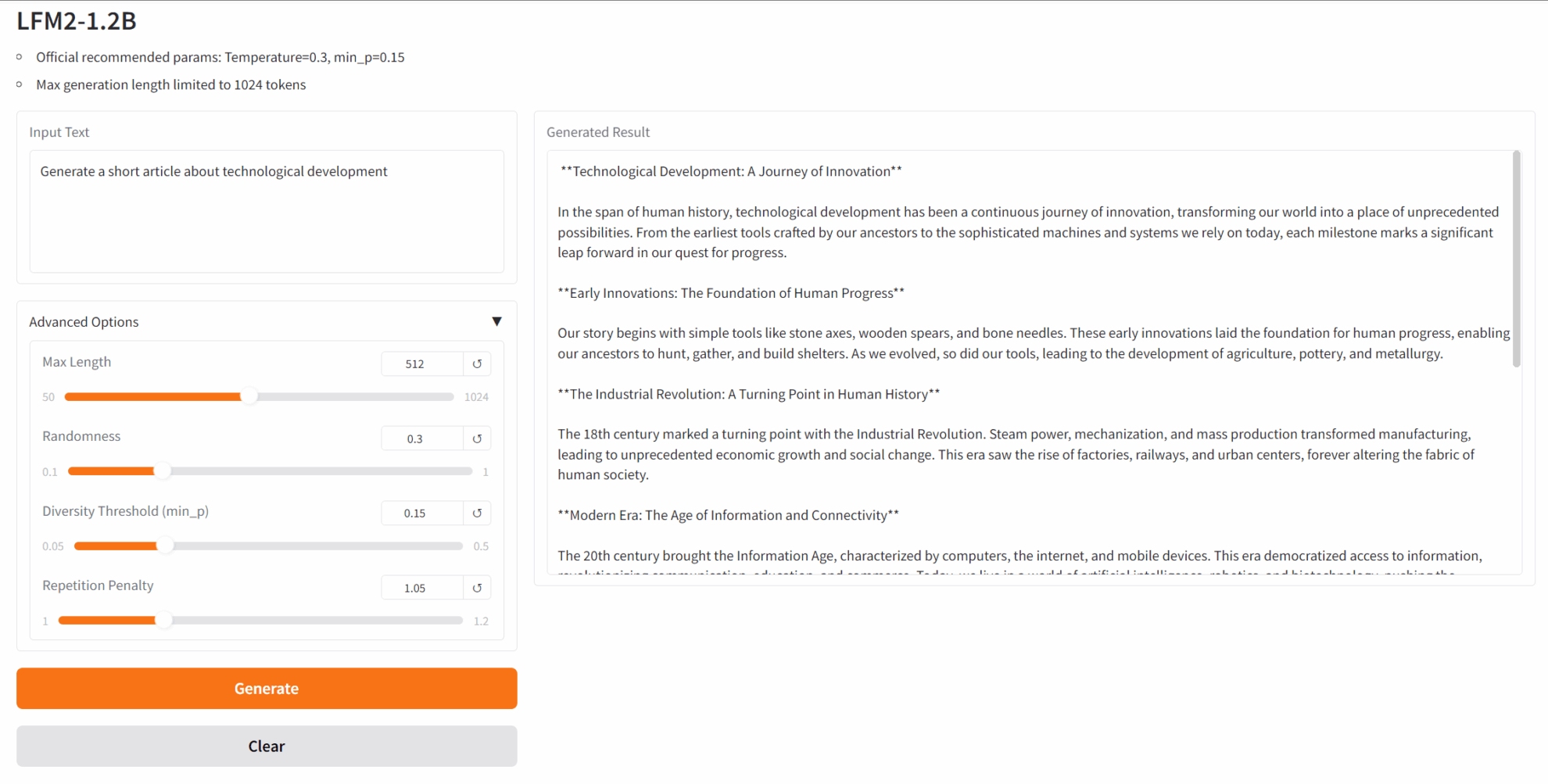
2. LFM2-1.2B: 효율적인 에지 배포 텍스트 생성 모델
LFM2-1.2B는 Liquid AI가 출시한 Liquid Foundation 모델(LFM)의 2세대입니다. 하이브리드 아키텍처를 기반으로 하는 생성 AI 모델입니다. 업계에서 가장 빠른 온디바이스 생성 AI 경험을 제공하는 것을 목표로 하며, 저지연 온디바이스 언어 모델 워크로드를 위해 설계되었습니다.
온라인으로 실행:https://go.hyper.ai/fEtm9
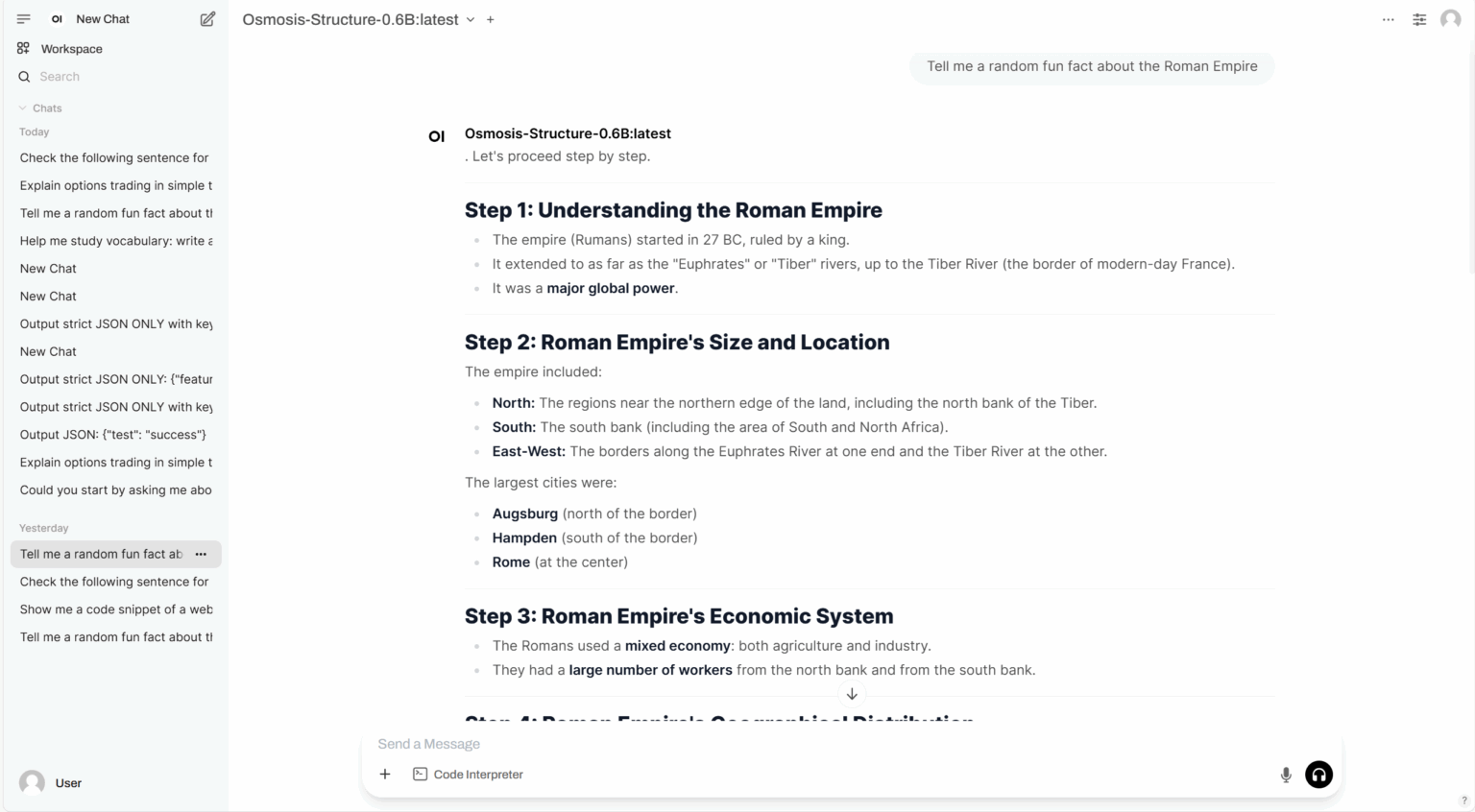
3. Osmosis-Structure-0.6B: 구조화된 출력을 제공하는 소규모 언어 모델
Osmosis-Structure-0.6B는 Osmosis에서 출시한 특수 소규모 언어 모델(SLM)로, 구조화된 출력 생성 작업을 완료하도록 설계되었습니다. 매개변수 크기가 0.6B에 불과함에도 불구하고, 이 모델은 지원되는 프레임워크와 함께 사용할 경우 구조화된 정보 추출에서 탁월한 성능을 보여줍니다.
온라인으로 실행:https://go.hyper.ai/ayrhc
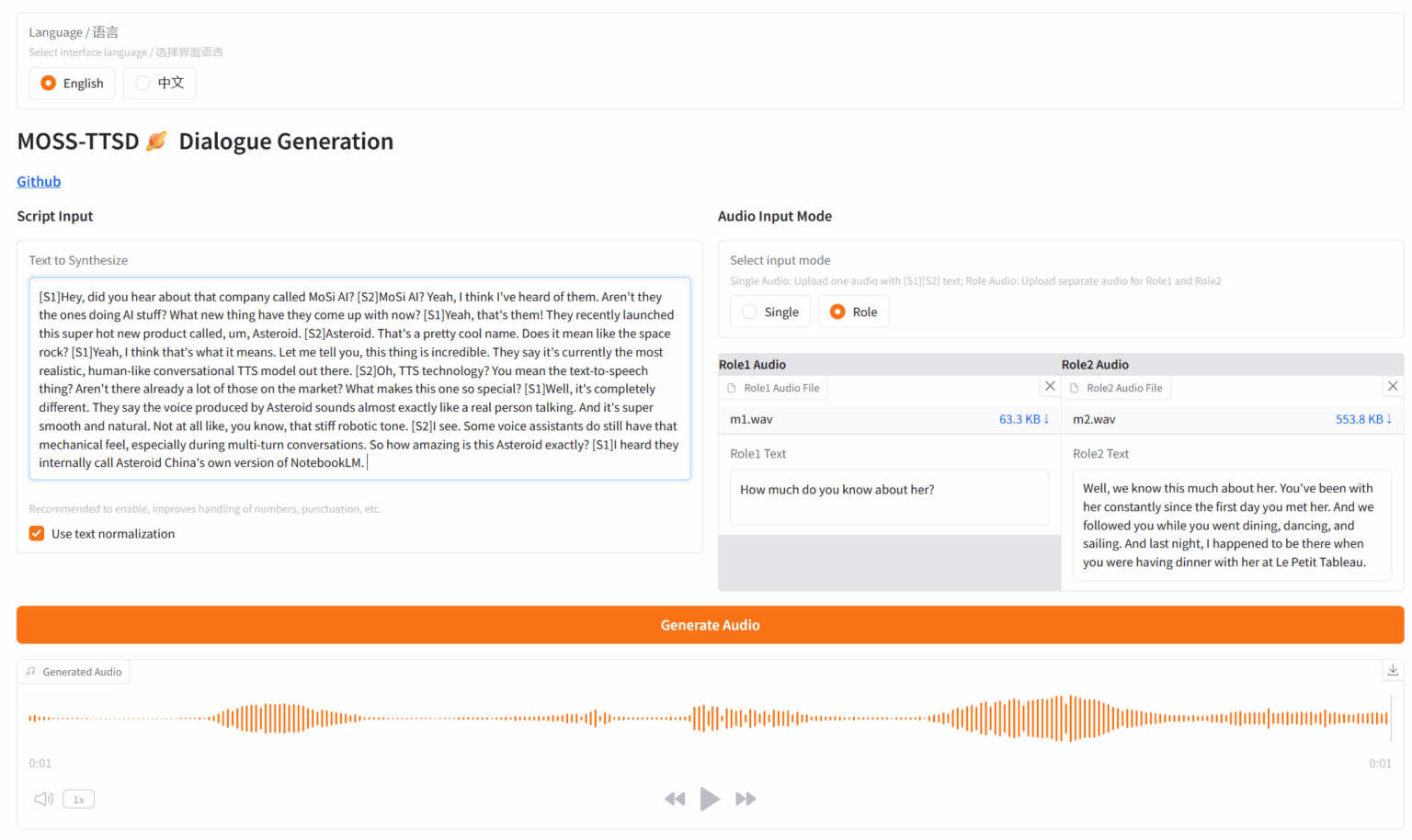
4. MOSS: 텍스트-음성 대화 생성
MOSS-TTSD는 OpenMOSS 팀에서 출시한 오픈 소스 이중 언어 음성 대화 합성 모델로, 중국어와 영어를 지원합니다. 두 화자 간의 대화 스크립트를 자연스럽고 표현력이 풍부한 대화 음성으로 변환할 수 있습니다. MOSS-TTSD는 음성 복제 및 장문 단일 세그먼트 음성 생성을 지원하여 AI 팟캐스트 제작에 이상적입니다.
온라인으로 실행:https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb: 아이소메트릭 3D 스타일 아이콘 생성
아이소메트릭-스큐모픽-3D-bnb는 멀티모달아트 그룹에서 출시한 LoRA 모델로, 스큐어모픽 디자인의 미학과 스타일리시한 특징을 모두 갖춘 3D 아이소메트릭 아이콘 제작에 중점을 두고 있습니다. 이 모델은 실제 사물과 건축 랜드마크를 처리할 때 뛰어난 성능을 발휘하며, 이를 쉽게 알아볼 수 있는 아이콘 스타일의 일러스트레이션으로 변환할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/3BnDy

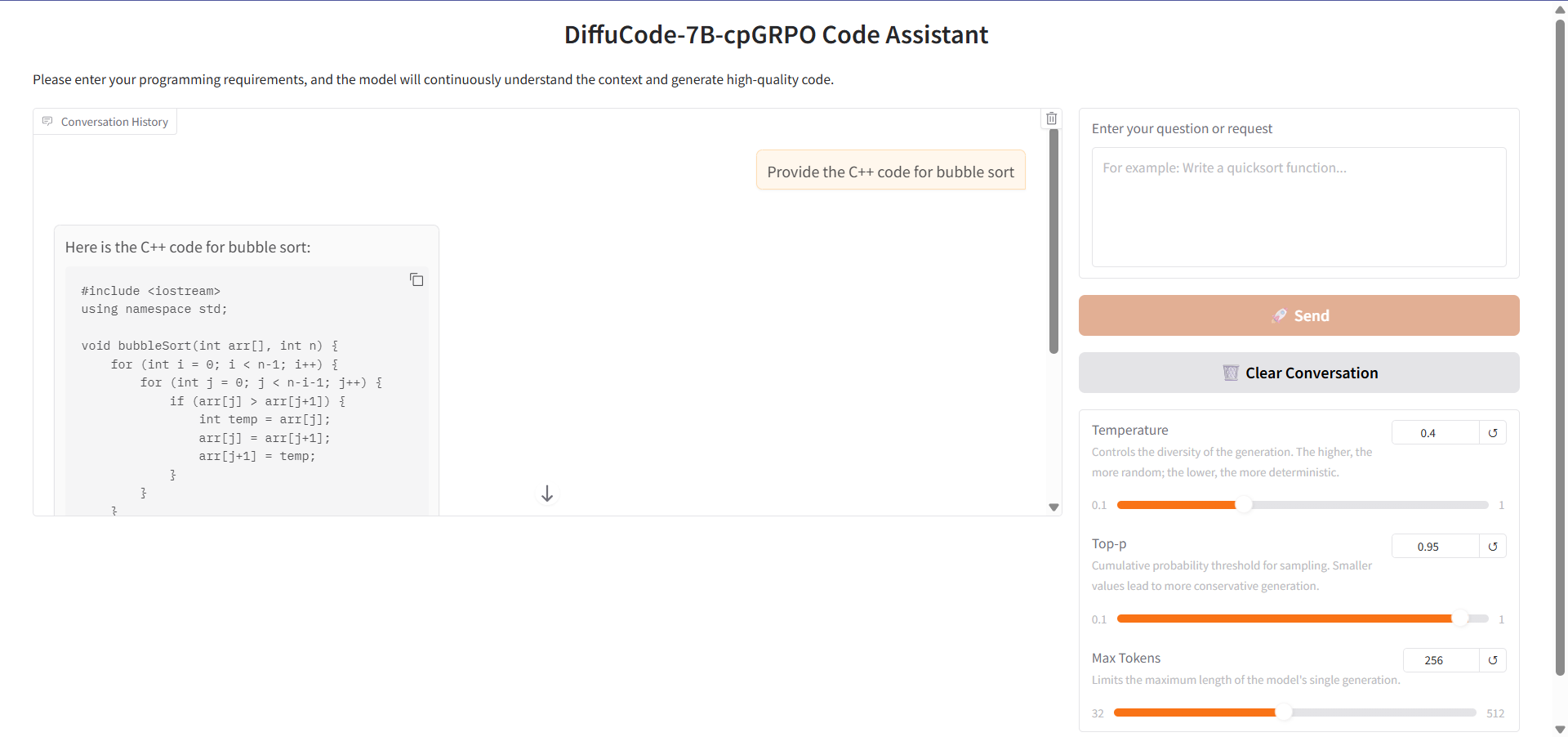
6. DiffuCode-7B-cpGRPO: 마스크 확산 기술 기반 코드 생성 모델
DiffuCoder-7B-cpGRPO는 Apple 팀에서 제안한 마스크 확산 기반 코드 생성 모델(dLLM)입니다. 이 모델은 기존의 좌우 자기회귀 생성 방식 대신, 반복적인 노이즈 감소를 통해 코드를 생성하고 편집하는 것을 목표로 합니다.
온라인으로 실행:https://go.hyper.ai/CMfWm
7. LAMMPS: 단결정 알루미늄을 예로 들어 재료의 단축 인장 시뮬레이션
LAMMPS(Large-scale Atomic/Molecular Massively Parallel Simulator)는 재료 모델링에 중점을 둔 고전적인 분자 동역학 시뮬레이션 코드입니다. 이 튜토리얼에서는 재료의 격자 상수를 변경하여 재료에 단축 변형을 가하는 상황을 시뮬레이션하고, 재료의 변형률-응력 곡선을 계산하여 그래프로 표시합니다.
온라인으로 실행:https://go.hyper.ai/LAqAs
8. Voxtral-Mini-3B-2507 음성 이해 모델 데모
Voxtral은 Mistral AI가 출시한 고급 오디오 모델입니다. 탁월한 음성 전사 및 심층 이해 기능을 기반으로 음성을 자연스러운 인간-컴퓨터 상호작용 방식으로 발전시킵니다. 이 모델은 다국어, 장문 텍스트 컨텍스트 처리, 내장된 질의응답 및 요약 기능을 지원하며, 백엔드 함수 호출을 직접 트리거할 수 있습니다. Voxtral의 성능은 여러 벤치마크에서 기존 오픈 소스 모델 및 독점 API를 능가하는 동시에, 비용이 저렴하고 다양한 시나리오에서 널리 사용되어 음성 상호작용의 대중화에 기여합니다.
온라인으로 실행:https://go.hyper.ai/PpjOs
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. GUI-G^2: GUI 접지를 위한 가우시안 보상 모델링
인간의 클릭 행동이 대상 요소를 중심으로 자연스럽게 가우시안 분포를 이룬다는 사실에서 영감을 받아, 본 논문에서는 GUI 요소를 인터페이스에서 연속 가우시안 분포로 모델링하는 원리 기반 보상 프레임워크인 GUI 가우시안 지역화 보상(GUI-G^2)을 소개합니다. 연구 분석 결과, 연속 모델링은 인터페이스 변경에 대한 강건성과 보이지 않는 레이아웃에 대한 일반화 능력을 향상시켜 GUI 상호작용 작업에서 공간 추론의 새로운 패러다임을 제시합니다.
논문 링크:https://go.hyper.ai/wLUhD
2. MiroMind-M1: 컨텍스트 인식 다단계 정책 최적화를 통한 수학적 추론의 오픈 소스 발전
대규모 언어 모델은 최근 유창한 텍스트 생성에서 여러 도메인에 걸친 고급 추론으로 발전하여 추론 언어 모델(RLM)의 탄생을 가져왔습니다. RLM 개발의 투명성을 높이기 위해 연구자들은 Qwen-2.5 프레임워크를 기반으로 구축된 완전 오픈 소스 RLM 세트인 MiroMind-M1 시리즈를 출시했습니다. 이 시리즈는 기존 오픈 소스 RLM과 동등하거나 그 이상의 성능을 제공합니다.
논문 링크:https://go.hyper.ai/EGWPq
3. 맥락의 한계를 넘어서: 장기적 추론을 위한 잠재의식의 실마리
대규모 언어 모델(LLM)의 문맥 길이 제한은 추론의 정확성과 효율성을 저해합니다. 이러한 한계를 극복하기 위해 본 논문에서는 재귀 및 분해 문제 해결을 위한 LLM 계열인 스레드 추론 모델(TIM)을 제안합니다. 또한, 문맥 제한을 넘어 장기적 구조적 추론을 가능하게 하는 추론 런타임 환경인 TIMRUN을 제안합니다.
논문 링크:https://go.hyper.ai/18j9w
4. 보이지 않는 끈: RLVR이 그 기원에서 벗어날 수 없는 이유
본 연구는 이론적 및 실증적 분석을 통해 RLVR의 잠재적 한계에 대한 새로운 통찰력을 제공하며, 추론의 경계를 확장하는 데 있어 RLVR의 잠재적 한계를 드러냅니다. 이러한 보이지 않는 제약을 극복하기 위해서는 명시적 탐색 메커니즘이나 해결 공간의 과소 표현된 영역에 확률적 질량을 도입하는 하이브리드 전략과 같은 향후 알고리즘 혁신이 필요할 수 있습니다.
논문 링크:https://go.hyper.ai/kkRo2
5. 가면 뒤에 숨은 악마: 확산 LLM의 새로운 안전 취약성
확산 기반 대규모 언어 모델(dLLM)은 최근 자기회귀 대규모 언어 모델에 대한 강력한 대안으로 부상하여 병렬 디코딩 및 양방향 모델링을 통해 더 빠른 추론 속도와 향상된 상호작용성을 제공합니다. 그러나 기존의 정렬 메커니즘은 마스킹된 입력을 이용한 상황 인식 적대적 신속 공격으로부터 dLLM을 보호하지 못하여 새로운 취약점을 노출시킵니다. 이를 위해 본 논문에서는 dLLM의 고유한 보안 취약점을 체계적으로 연구하고 구축하는 최초의 탈옥 공격 프레임워크인 DIJA를 제안하며, 이러한 새로운 언어 모델에 대한 보안 정렬 메커니즘을 재고해야 할 시급성을 강조합니다.
논문 링크:https://go.hyper.ai/dyDhr
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
ByteDance의 시드 연구 과학자인 정 사이즈(Zheng Size)는 기조 연설 "트리톤 분산형: 고성능 통신을 위한 네이티브 파이썬 프로그래밍"에서 대규모 모델 학습에서 트리톤 분산형의 통신 효율성 혁신, 크로스 플랫폼 적응성, 파이썬 프로그래밍을 통한 통신과 컴퓨팅의 긴밀한 통합을 달성하는 방법을 자세히 분석했습니다.
전체 보고서 보기:https://go.hyper.ai/L2rfl
2. 데이터 노이즈 제거/생물학적 신호 강화/드롭아웃 완화, 딥러닝 모델 SUICA는 공간 전사체 슬라이스의 모든 위치에서 유전자 발현 예측을 달성합니다.
도쿄대학교 정인창 교수 연구팀과 맥길대학교 딩 준 교수 연구팀이 공동으로 공간 전사체 데이터 모델링 방법인 SUICA를 제안했습니다. SUICA는 암묵적 신경 표현과 그래프 오토인코더를 기반으로 하는 딥러닝 모델입니다. 연구 결과는 SUICA로 처리된 공간 전사체 데이터가 더 높은 품질, 더 낮은 노이즈, 그리고 더 강력한 생물학적 신호를 가질 수 있음을 보여줍니다. 관련 연구 결과는 ICML 2025에 선정되었습니다.
전체 보고서 보기:https://go.hyper.ai/5esoL
3. 타일 수준 기본 요소와 자동 추론 메커니즘이 통합되었습니다. TileAI 커뮤니티 창립자는 TileLang의 핵심 기술과 장점을 심층적으로 분석합니다.
TileAI 커뮤니티 창립자인 왕레이 박사는 "현대 AI 워크로드에서의 프로그래밍 가능성과 성능의 연결"이라는 제목의 연설을 했습니다. 이 연설에서 그는 혁신적인 연산자 프로그래밍 언어인 TileLang을 이해하기 쉬운 방식으로 소개하고 핵심 설계 개념과 기술적 장점을 공유했습니다.
전체 보고서 보기:https://go.hyper.ai/AkeOJ
4. 단백질 생성/폴딩/역폴딩 지원. HUST/USTC/Byte는 모든 원자 설계 및 기능 최적화를 달성하기 위해 APM 모델을 제안했습니다.
후난대학교는 중국과학원 및 ByteDance Seed 팀과 협력하여 새로운 전원자 단백질 생성 모델인 APM(All-Atom Protein Generative Model)을 제안했습니다. 이 모델은 원자 수준의 정보를 통합하고, 유사 서열 연결에 의존하지 않고 다중 사슬 단백질의 생성, 접힘, 그리고 역접힘을 지원합니다. 항체 설계 및 펩타이드 결합 설계와 같은 후속 작업에서 기존 SOTA를 능가하는 성능을 달성할 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/fJvpi
5. Google DeepMind는 176,000개 이상의 비문 데이터를 기반으로 고대 로마 비문의 임의 길이 복원을 처음으로 달성한 Aeneas를 출시했습니다.
구글 딥마인드의 연구진은 노팅엄 대학, 워릭 대학 및 기타 대학과 협력하여 세계 최고의 학술지인 네이처에 "생성적 신경망을 이용한 고대 텍스트의 맥락화"라는 제목의 연구 논문을 게재하여 아이네이아스가 고대 로마 비문을 임의 길이로 복원한 최초의 사례라고 발표했습니다.
전체 보고서 보기:https://b23.moe/cYtSI
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
정상회담 8월 마감
8월 1일 7:59:59 인포콤 2026
8월 1일 7:59:59 KDD 2026
8월 2일 7:59:59 HPCA 2026
8월 2일 7:59:59 유비콤프 2025
8월 2일 11:59:59 VLDB 2026
8월 2일 19:59:59 AAAI 2026
8월 7일 7:59:59 NDSS 2026
8월 21일 11:59:59 아스플로스 2026
8월 27일 7:59:59 USENIX 보안 심포지엄 2025
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!