Command Palette
Search for a command to run...
타일 수준 기본 요소는 자동 추론 메커니즘과 통합되어 있습니다. TileAI 커뮤니티의 창시자는 TileLang의 핵심 기술과 장점을 심층적으로 분석합니다.

7월 5일, 제7회 Meet AI Compiler Technology Salon이 베이징에서 성황리에 마무리되었습니다. 업계 전문가들은 최신 개발 사례와 실무 및 구현 경험을 공유했으며, 대학 연구진은 혁신 기술의 구현 경로와 장점을 자세히 설명했습니다.
안에,TileAI 커뮤니티 창립자인 레이 왕 박사는 "현대 AI 워크로드에서의 프로그래밍 가능성과 성능의 연결"이라는 제목으로 연설했습니다.혁신적인 연산자 프로그래밍 언어 TileLang을 이해하기 쉬운 방식으로 소개하고, 핵심적인 설계 개념과 기술적 장점을 공유합니다.
TileLang은 AI 커널 프로그래밍의 효율성을 향상시키고, 스케줄링 공간(스레드 바인딩, 레이아웃, 텐서화, 파이프라인 포함)을 데이터 흐름에서 분리하여 사용자 정의 가능한 애노테이션과 프리미티브 집합으로 캡슐화하는 것을 목표로 합니다. 이러한 접근 방식을 통해 사용자는 커널 데이터 흐름 자체에 집중하고, 대부분의 다른 최적화 작업은 컴파일러에 맡길 수 있습니다.
평가 결과는 다음과 같습니다.TileLang은 여러 주요 커널에서 업계 최고의 성능을 달성합니다.이는 현대 AI 시스템 개발에 필요한 성능과 유연성을 제공할 수 있는 통합된 블록-스레드 프로그래밍 패러다임과 투명한 스케줄링 기능을 완벽하게 보여줍니다.
HyperAI는 원래 의도를 훼손하지 않고 연설 내용을 편집하고 요약했습니다. 다음은 연설 전문입니다.
위챗 공개 계정 "HyperAI Super Neuro"를 팔로우하고 키워드 "0705 AI Compiler"에 답글을 달면 공인 강사의 발표 PPT를 받으실 수 있습니다.
왜 "새로운 DSL"이 필요한가요?
이 공유에서는 주로 저희 팀이 2025년 1월에 GitHub에 오픈 소스로 공개한 AI 워크로드를 위한 새로운 DSL TileLang을 소개합니다.
우선, 왜 새로운 DSL이 필요한지부터 말씀드리고 싶습니다.
개인적인 관점에서, Microsoft 인턴십 기간 동안 혼합 정밀도 컴퓨팅을 연구하는 BitBLAS라는 프로젝트에 참여했습니다. 당시 이 프로젝트는 주로 TVM/Tensor IR 기반이었으며, 최종적으로 매우 좋은 실험 결과를 얻었습니다. 하지만 유지 관리의 어려움 등 여러 문제점이 있었습니다. 행렬 계층의 혼합 정밀도 계산과 같은 각 연산자에 대해 500줄의 Schedule Primitives를 작성했습니다. 비록 우아하게 작성되었지만,하지만 이 스케줄링 코드를 이해할 수 있는 사람은 저뿐이고, 이를 유지 관리하거나 확장해줄 사람을 찾는 것도 어렵습니다.
게다가 스케줄 IR을 기반으로 새로운 요구 사항이나 최적화를 설명하는 데 어려움이 있었습니다. 예를 들어, 커널 작업을 할 때 프로그램 최적화를 위해 플래시 어텐션, 선형 어텐션 등 세 가지 스케줄 프리미티브를 작성했습니다. 이러한 연산자는 스케줄 기반으로 설명하기가 어려웠습니다. 따라서 당시 프로젝트가 계속 확장된다면 TIR을 사용하는 것이 효과적이지 않을 수 있으며, 다른 해결책이 필요하다고 생각했습니다.
그러면 트리톤은 왜 안 될까?
트리톤도 시도해봤는데,하지만 고성능 커널을 사용자 지정하는 데 어려움이 있었습니다.예를 들어, 역양자화 연산자를 작성할 때 각 스레드의 동작을 제어해야 할 수 있습니다. 고성능 커널에서 각 스레드의 역양자화를 구현하는 방법은 여전히 매우 까다롭습니다.
두 번째는 버퍼를 적절한 메모리 범위에 캐시하는 방법입니다.예를 들어, 일부 GPU에서는 역양자화를 위해 데이터를 레지스터에 캐시한 후 공유 메모리에 쓰는 것이 더 좋지만, 다른 GPU에서는 데이터를 공유 메모리에 직접 다시 쓰는 것이 더 좋습니다. 하지만 Triton에서는 이를 제어하기가 어렵습니다.
마침내,트리톤의 지수는 좀 복잡한 것 같아요.예를 들어, 타일을 로컬에 캐시해야 하는 경우 아래 그림의 왼쪽에 표시된 코드를 작성해야 하지만 Tensor IR에서는 오른쪽에 표시된 것처럼 서브스크립트를 사용하여 인덱싱할 수 있는데, 제 생각에는 매우 좋습니다.
이를 바탕으로 기존 DSL로는 내 요구 사항을 충족할 수 없다는 것을 알게 되었고, 더 많은 백엔드와 사용자 정의 연산자를 지원하고 더 나은 성능을 달성하는 혁신적인 DSL을 만들고자 했습니다.더 나은 성능을 달성하려면 타일링, 파이프라인 등 다양한 디자인 공간을 최적화하는 것이 필요합니다.이러한 목적을 위해 우리는 TileLang 프로젝트를 제안했습니다.
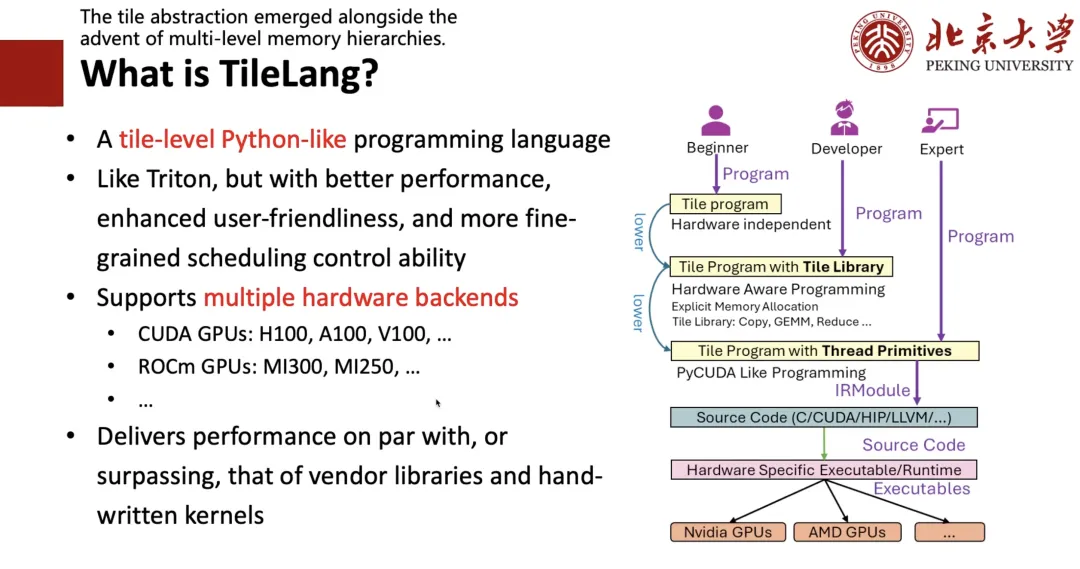
TileLang이란 무엇인가요?
왜 "타일"인가?
첫째, 타일(Tile)이라는 개념이 매우 중요하다는 것을 알게 되었습니다. 하드웨어에 캐시, 레지스터, 공유 메모리라는 개념이 있다면, 고성능 프로그램을 작성할 때 블록, 즉 타일을 고려해야 합니다. 둘째, 모두가 파이썬 프로그램을 작성하는 경향이 있기 때문에, 트리톤(Triton)처럼 작성하기 쉽고 성능도 더 나은 파이썬 유사 프로그래밍 언어를 설계하고 싶었습니다.
이를 위해 우리는 다음 그림의 오른쪽에 표시된 프레임워크를 설계했습니다.당신이 전문가라면,즉, CUDA나 하드웨어에 대한 지식이 있다면 저수준 코드를 직접 작성할 수 있습니다.당신이 개발자라면,즉, 트리톤을 작성할 수 있고 타일과 레지스터와 같은 개념을 이해할 수 있다면 트리톤을 작성하는 것과 마찬가지로 타일 수준의 프로그램을 작성할 수 있습니다.하드웨어에 대해 아무것도 모르고 알고리즘만 아는 초보자라면,그런 다음 TRL을 쓰는 것과 같은 고수준 표현식을 작성한 다음 Auto Schedule을 사용하여 이를 해당 코드로 낮출 수 있습니다.
아래 그림과 같이, 왼쪽의 Dequant Schedule은 제가 TIR을 사용하여 작성한 것이며, 오른쪽의 TileLang 형태로도 완벽하게 동일하게 작성하여 레벨 1과 레벨 2의 공존을 실현했습니다.

다음으로 TileLang의 디자인에서 고려해야 할 사항은 무엇인지 소개해드리겠습니다.
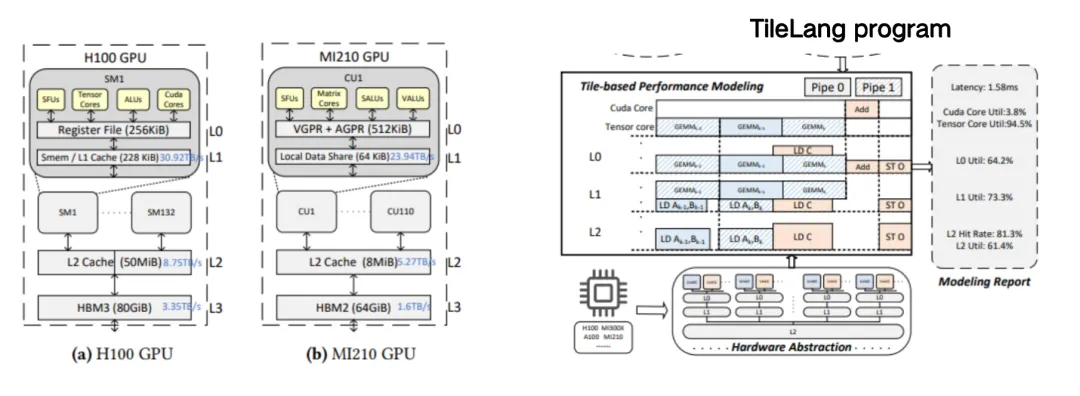
아래 그림의 왼쪽은 DeepSeek MLA의 TileLang 구현으로, 약 50줄의 코드로 구성되어 있습니다. 이 커널에서 사용자는 GPU 커널(커널 함수)을 시작할 때 병렬 컴퓨팅 작업을 수행하기 위해 몇 개의 블록(스레드 블록)을 지정해야 하는지, 각 블록에 몇 개의 스레드를 할당해야 하는지 등 많은 것을 관리해야 합니다. 이를 타일 구성(Tile Configuration)이라고 하며, 아래 각 코드는 컨텍스트를 갖습니다. 사용자는 버퍼의 메모리 범위를 제어하고, 공유 메모리 또는 레지스터의 레이아웃을 결정하고, 파이프라인 등에도 주의를 기울여야 합니다. 이러한 모든 작업을 수행하기 위해서는 컴파일러가 사용자의 관리를 지원해야 합니다.

이러한 목적을 위해 최적화 공간을 두 가지 범주로 나눕니다.하나는 추론입니다.즉, 컴파일러는 사용자가 더 나은 솔루션을 도출하도록 직접 도와줍니다.하나는 추천입니다,즉, 추천을 통해 계획을 선택하는 것입니다.
모든 최적화 공간을 고려한 후,원래 500개가 넘는 코드 블록으로 구성되었던 고성능 FlashMLA 구현을 95%의 성능은 유지하면서 단 50줄의 TileLang 코드로 압축했습니다.
다음으로, TileLang을 맨 아래부터 소개해드리겠습니다.
아래 그림에서 볼 수 있듯이 TIR에 익숙한 학생이라면 이것이 TIR 표현식임을 알 수 있을 것입니다. 그러면 TIR을 기반으로 PyCUDA 프로그래밍을 할 수 있습니다. 예를 들어, 두 개의 Python 부정 루프를 작성하면 TIR Codegen을 통해 CUDA 표현식으로 생성할 수 있습니다.
벡터화와 같은 스레드 기본 요소를 사용하면 CUDA 벡터화를 구현하고, 나아가 스레드 바인딩을 구현할 수 있습니다. 위의 프로그램들은 모두 TIR이 원래 가지고 있던 프로그램들이며, 사용자는 CUDA를 사용하는 것처럼 프로그램을 작성할 수 있지만, Python으로 작성하는 것은 여전히 더 복잡합니다.
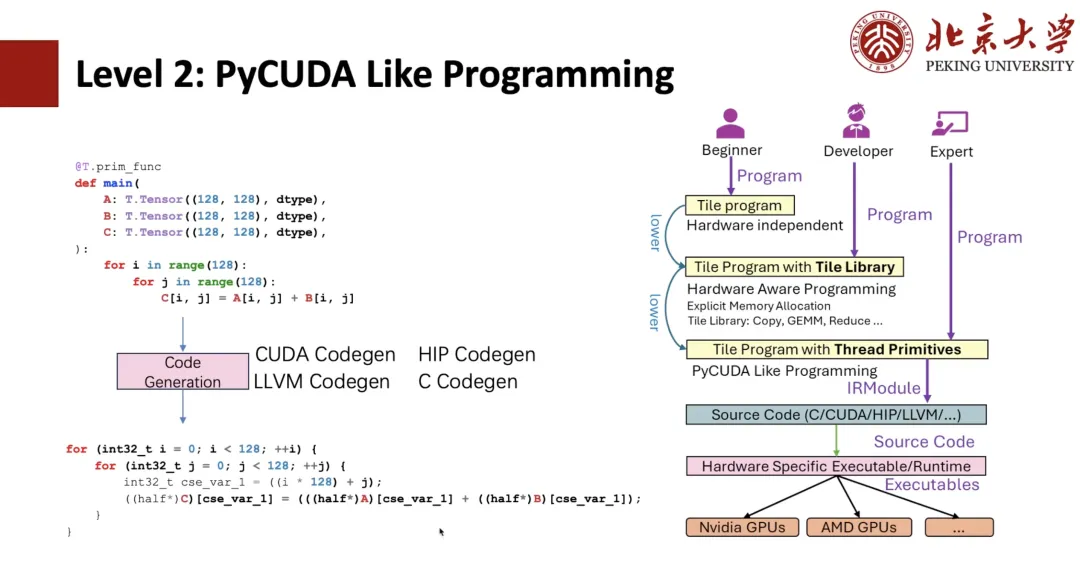
사용자의 작업을 보다 쉽게 하기 위해,레벨 1 타일 라이브러리의 쓰기 방법이 제안되었습니다.예를 들어, 128개의 스레드가 있는 커널 컨텍스트를 제공하고 Copy를 "T.Parallel"로 래핑합니다. 컴파일러의 추론 후, 방금 보여준 고성능 형태를 추론하고 최종적으로 codegen을 CUDA 코드로 변환합니다. 더 "우아하게" 작성하려면 "T.copy"를 직접 작성하고 Copy를 "T.Parallel" 표현식으로 직접 확장할 수 있습니다.
T.Parallel은 복사뿐만 아니라 복잡한 계산도 구현하고, 벡터화 및 스레드 바인딩을 자동으로 구현할 수 있습니다. 현재 복사 외에도 Reduce, Fill, Clear 등과 같은 타일 라이브러리를 제공합니다. 타일 라이브러리를 기반으로 Triton과 같은 유용한 연산자를 작성할 수 있습니다.
그래서,"T.Parallel"을 지원하는 핵심 개념은 메모리 레이아웃입니다.
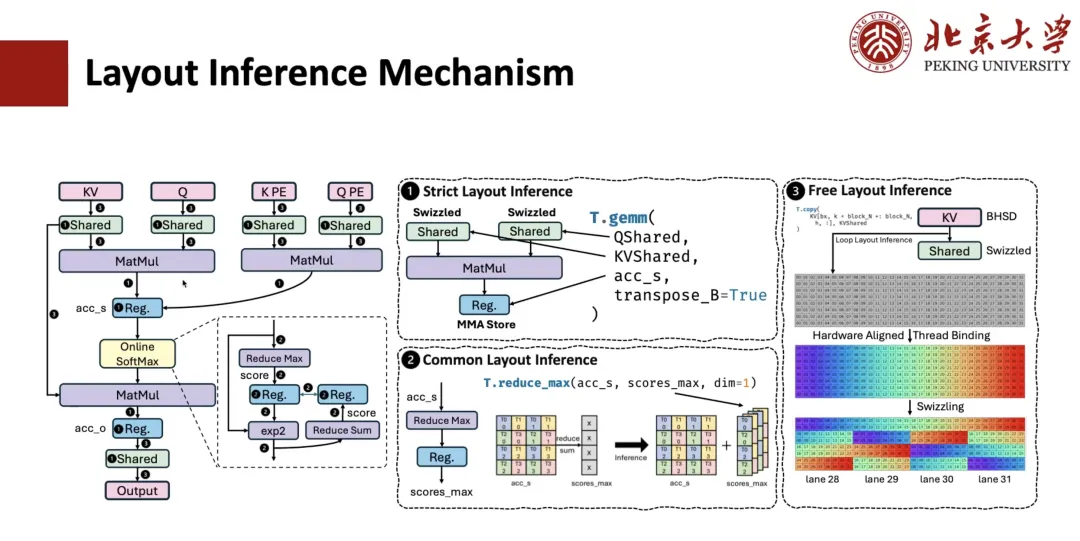
TileLang에서는 A[i, k]와 같은 고수준 인터페이스를 사용하여 다차원 배열의 인덱싱을 지원합니다. 이 고수준 인덱스는 일련의 소프트웨어 및 하드웨어 추상화 계층을 통해 최종적으로 물리적 메모리 주소로 변환됩니다. 이 인덱스 변환 과정을 모델링하기 위해,우리는 데이터가 메모리에서 어떻게 구성되고 매핑되는지 설명하기 위해 레이아웃을 도입했습니다.
MLA 계산을 위한 레이아웃 도출은 어떻게 구현됩니까? 일반적으로 이 과정은 3단계로 구성됩니다.
첫 번째 단계는 엄격한 레이아웃 추론입니다.예를 들어, 행렬 곱셈과 같은 연산자는 데이터 레이아웃에 강한 제약을 받으며 지정된 레이아웃을 따라야 하므로, 연결된 레지스터의 레이아웃도 결정됩니다. 공유 메모리가 관련되어 있고 이 연산자가 스필 연산을 수행해야 한다는 것을 알고 있는 경우, 해당 메모리 레이아웃도 결정됩니다.
두 번째 단계는 공통 레이아웃 추론입니다.예를 들어, 이전 단계에서 결정된 레이아웃에 연결된 표현식의 경우, 해당 레이아웃도 결정되어야 합니다. 예를 들어, accum_s에서 scope_max로의 reduce 연산이 있고, QMS의 레이아웃이 행렬 계층을 통해 지정된 경우, 이를 기반으로 scope_max의 레이아웃을 추론할 수 있습니다. 이러한 일반적인 추론을 통해 대부분의 중간 표현식의 레이아웃을 결정할 수 있습니다.
세 번째 단계는 자유 레이아웃 추론입니다.즉, 남은 자유 레이아웃이 추론됩니다. 이 레이아웃은 크게 제약되지 않으므로, 일반적으로 하드웨어에 맞춰진 몇 가지 레이아웃 추론 전략을 채택하여 액세스 모드와 메모리 범위를 기반으로 최적의 레이아웃 솔루션을 추론합니다.
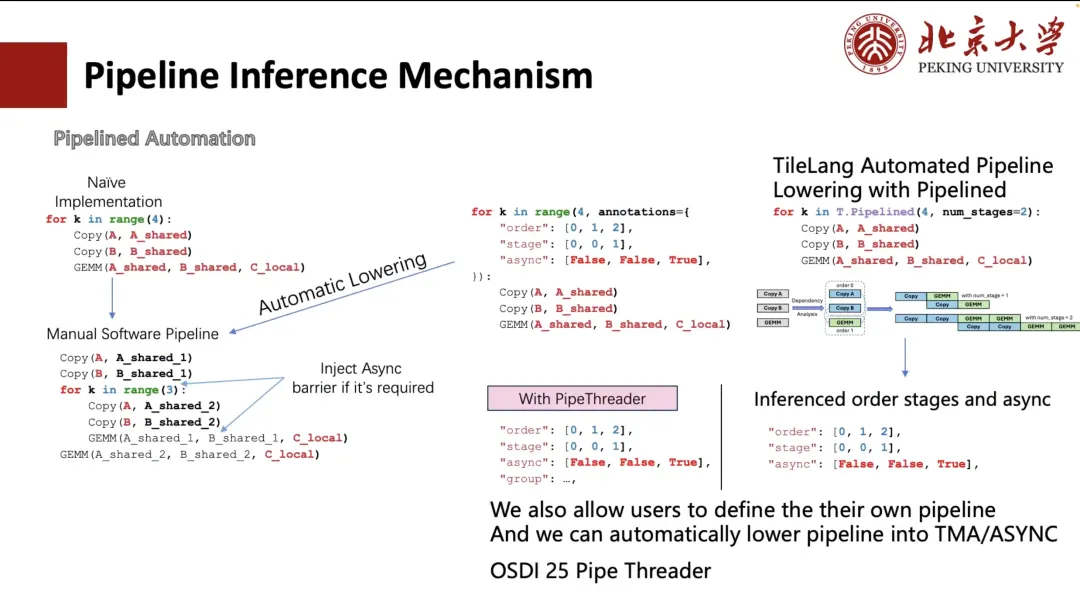
다음은 파이프라인이 파생을 수행하는 방법을 설명합니다.
일반적으로 파이프라인을 수동으로 확장할 수 있지만, 이러한 작성 방식은 번거롭고 사용자 친화적이지 않습니다. 따라서 TVM은 주석을 통해 프로세스를 단순화하는 방안을 모색했습니다. 사용자는 루프의 실행 순서와 스케줄링 단계만 지정하면 됩니다.TVM은 루프를 수동으로 푸는 것과 동일한 구조로 자동 변환할 수 있습니다(아래 그림의 왼쪽 하단 모서리에 표시된 대로).
하지만 사용자에게는 여전히 복잡하고 번거롭습니다. 따라서 TileLang에서는 이 값을 "num_stage"로 줄였습니다. 사용자는 "num_stage" 값만 지정하면 시스템이 자동으로 계산 및 스케줄링의 종속성을 분석하여 그에 따라 분배합니다. 실제로 GPU 또는 대부분의 다른 장치에서는 Copy와 GEMM만이 진정한 비동기 실행을 구현할 수 있으며, 특히 Copy 연산은 ASYNC 또는 TMA와 같은 메커니즘을 통해 비동기 전송을 지원할 수 있습니다.
그러므로,스케줄링에서는 복사 작업을 별도의 단계로 분리합니다.전체 파이프라인에 적합한 단계 분할을 자동으로 도출합니다. 물론, 사용자는 왼쪽 그림에 표시된 두 가지 사용자 지정 방식처럼 스케줄링 방식을 수동으로 지정할 수도 있습니다.
또한, 하드웨어 기능(예: A100 및 H100의 TMA 모듈)을 기반으로 하는 자동 레이아웃 추론 및 스케줄링 최적화도 지원합니다. 이 작업의 일부는 올해 OSDI 25에서 발표될 Pipe Threader 프로젝트에서 비롯되었습니다.
다음으로, 지시의 추론에 대해 알려드리겠습니다.
행렬 곱셈을 예로 들면, "T.GEMM"에 호출할 수 있는 하드웨어 명령어가 많습니다. 예를 들어, INT8 정밀도에서는 DP4A 명령어를 사용하거나 TensorCore 기반 INT8 구현을 사용할 수 있습니다. 각 명령어 자체가 여러 형태를 지원하므로, 이러한 구현 중에서 최적의 타일 구성을 선택하는 것이 핵심입니다.
이를 위해 TileLang은 두 가지 사용 방법을 제공합니다.
첫 번째는 TileLang을 사용하면 사용자가 PTX를 호출하여 ASM을 작성할 수 있다는 것입니다.하지만 이 방법의 단점은 조합 공간이 매우 크다는 것입니다. 모든 PTX와 호환되려면 많은 코드를 작성해야 하고 레이아웃도 관리해야 합니다. 하지만 이 방법은 매우 무료이며, 저는 개인적으로 이 방법을 매우 좋아합니다.
하지만 우리는 지금은 두 번째 방법을 사용하고 있습니다.즉, "T.GEMM" 뒤에 CUTE/CK-TILE과 같은 타일 라이브러리가 옵니다.행렬 곱셈에 일반적으로 사용되는 타일 수준 라이브러리 인터페이스를 제공하지만, 템플릿 확장으로 인해 컴파일 시간이 매우 오래 걸린다는 단점이 있습니다. RTX 4090에서 Flash Attention을 컴파일하는 데 10초가 걸릴 수 있으며, 그중 90% 이상이 템플릿 확장에 사용됩니다. 또 다른 문제는 Python 프런트엔드와 매우 분리되어 있다는 것입니다.
그래서 우리는 생각합니다.타일 라이브러리는 우리가 앞으로 집중할 방향입니다.즉, Tile의 기본 구문을 통해 "T.GEMM" 및 "T.GEMMSP"와 같은 다양한 Tile 수준 라이브러리가 지원됩니다.
미래의 직업 전망
마지막으로 저희 팀의 향후 작업 중 일부를 소개하고 싶습니다.
첫 번째는 Tile Sight로, 대규모 언어 모델에서 대규모 복잡한 커널(예: FlashAttention 및 FlashMLA)의 성능 최적화를 가속화하도록 특별히 설계되었습니다.이는 GPU, CPU, 가속기 등 여러 백엔드에 대한 효율적인 타일 구성(타일링 전략이나 스케줄링 힌트)을 생성하고 평가하는 것을 목표로 하는 가벼운 자동 튜닝 프레임워크로, 개발자가 우수한 성능을 갖춘 스케줄링 전략을 빠르게 찾고 수동 튜닝 시간을 줄이는 데 도움을 줍니다.
위의 사용자 정의 모델을 기반으로 사용자는 MLA와 같은 어려운 커널을 더 쉽게 작성할 수 있습니다. 사용자 정의 모델은 사용자가 각 캐시를 해당 공유 캐시에 배치하도록 안내할 수 있습니다.
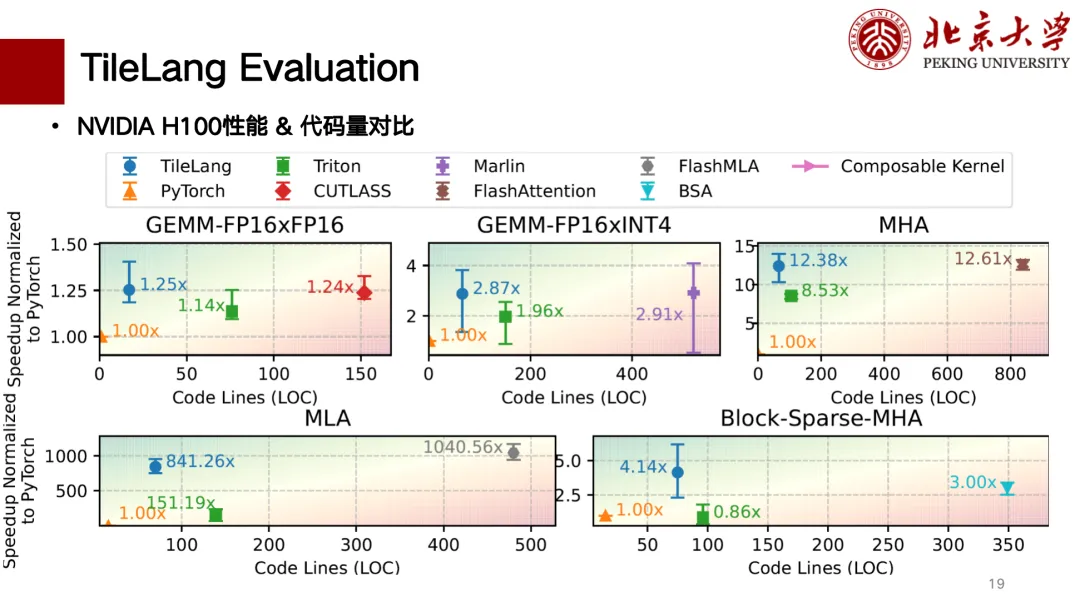
아래는 TileLang의 부분적인 성능 평가입니다. H 카드와 A 카드에 대한 지원을 주로 완료했습니다. 아래 그림은 코드 줄 수와 성능 간의 상관관계 비교 차트입니다. 성능은 왼쪽 상단으로 갈수록 더 좋습니다. 특히 행렬 곱셈의 경우, TileLang은 CUTLASS와 유사한 성능을 달성할 수 있습니다. 또한 MLA, Flash Attention, Block Sparse 등의 연산자도 CUTLASS와 유사한 성능을 달성할 수 있으며, 코드 줄 수도 비교적 적고 작성하기도 비교적 "깔끔"합니다.
TileLang 생태계에서는 이미 일부 사용자가 사용하고 있습니다. 예를 들어, Microsoft의 저정밀도 대형 모델 BitNet의 핵심 양자화 연산자는 TileLang을 기반으로 개발되었으며, Microsoft의 BitBLAS 또한 완전히 TileLang을 기반으로 합니다. 국내 칩 지원 측면에서는 Suanneng TPU와 Ascend NPU도 일부 지원했습니다.