Command Palette
Search for a command to run...
추론 능력의 도약! GLM-4.1V-Thinking은 인지 지능의 진화를 촉진합니다. 500만 개의 단계별 사고 데이터 예시! MathX-5M은 수학적 추론의 새로운 영역을 열어줍니다.

현재 다중모달 대형 모델은 "지각 지능"에서 "인지 지능"으로 진화하고 있습니다. 기존 연구들은 시각 언어 모델의 추론 능력을 향상시키려는 시도를 해왔지만, 대부분 특정 분야에 국한되어 있습니다. 관련 연구가 진행 중이지만, 아직 보편적인 다중모달 추론 모델은 부족한 실정입니다.
이러한 맥락에서, 지푸 AI와 청화대학교는 일반적인 다중 모드 이해와 추론을 촉진하도록 설계된 시각 언어 모델(VLM)인 GLM-4.1V-Thinking을 공동으로 제안했습니다.핵심 혁신은 "커리큘럼 샘플링을 통한 강화 학습(RLCS)" 전략에 있습니다.10B 매개변수 수준에서 시각 언어 모델의 가장 강력한 성능을 달성할 뿐만 아니라,목록 작업 중 18개에서 Qwen-2.5-VL-72B는 매개변수가 동일하거나 8배 이상 높습니다.또한 멀티모달 모델의 동적 인지 능력을 크게 향상시켜 수동적인 "이미지 인식"에서 능동적인 "사고"로 업그레이드하고, 가벼운 배포의 장점을 유지하면서 추론의 문제점을 해결합니다.
현재 HyperAI 공식 웹사이트에서 "GLM-4.1V-Thinking: 확장 가능한 강화 학습을 통한 다목적 다중 모드 추론" 튜토리얼을 출시했습니다. 와서 체험해 보세요~
GLM-4.1V-Thinking: 확장 가능한 강화 학습을 통한 다재다능한 다중 모드 추론
온라인 사용:https://go.hyper.ai/B3Vzs
7월 7일부터 7월 11일까지 hyper.ai 공식 웹사이트가 업데이트되었습니다.
* 고품질 공개 데이터 세트: 10
* 엄선된 고품질 튜토리얼: 7개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 7월 마감일 상위 컨퍼런스: 4
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
VisDrone은 표적 탐지, 객체 추적, 이미지 분할 등 컴퓨터 비전 작업의 개발 및 평가를 지원하도록 설계된 대규모 드론 시각 표적 탐지 및 추적 벤치마크 데이터셋입니다. 이 데이터셋은 중국 여러 도시의 도시 및 교외 환경에서 드론을 사용하여 수집한 고해상도 이미지와 비디오를 포함하며, 사람, 차량, 건물, 동물 등 6가지 범주로 구성됩니다.
직접 사용:https://go.hyper.ai/hQ5lh

MathX는 사고 능력 향상을 위해 명령어 기반 모델 튜닝 및 기존 모델의 미세 조정을 위해 설계된 수학적 추론 데이터셋입니다. 이 데이터셋은 현재까지 공개된 가장 크고 포괄적인 수학적 추론 데이터 코퍼스로, 엄선된 500만 개의 단계별 사고 데이터 예시를 포함하고 있으며, 각 예시에는 문제 설명, 상세한 추론 과정, 검증된 정답이 포함됩니다.
직접 사용:https://go.hyper.ai/h0eLq
Fruit Classification은 과일 인식 및 분류를 위한 머신러닝 및 딥러닝 모델을 학습하도록 설계된 과일 분류 이미지 데이터셋입니다. 이 데이터셋은 101가지 과일 종을 다루며, 각 종은 학습용 이미지 약 400장, 검증용 이미지 50장, 테스트용 이미지 50장으로 구성되어 있습니다.
직접 사용:https://go.hyper.ai/a8gfG

Dog Breeds Image는 다양한 견종 이미지를 포함하는 견종 이미지 데이터셋으로, 견종 분류 모델의 훈련 및 평가를 지원합니다. 이 데이터셋은 테리어, 하운드, 마스티프, 스패니얼, 비숑 프리제 등 100종 이상의 견종 이미지를 수천 개(17,000개 이상) 포함하고 있으며, 견종 인식 시스템 개발에 도움을 주기 위해 설계되었습니다.
직접 사용:https://go.hyper.ai/DoFA3

Mushroom은 버섯 종 인식 데이터셋입니다. 이 데이터셋은 100종이 넘는 버섯 종의 이미지를 포함합니다. 각 버섯의 색상, 모양, 냄새, 표면 질감 등 물리적 특성을 포함하고 있으며, 각 버섯이 독버섯인지 식용버섯인지에 대한 주석도 포함되어 있습니다. 이러한 이미지는 다양한 성장 단계와 성장 조건에서 버섯의 형태를 보여주므로, 세밀한 분류 작업에 이상적입니다.
직접 사용:https://go.hyper.ai/ws0pi

6. 텍스트-이미지-2M 텍스트-이미지 학습 데이터 세트
Text-to-Image-2M은 텍스트-이미지 모델 미세 조정을 위해 설계된 고품질 텍스트-이미지 쌍 데이터셋입니다. 이 데이터셋은 약 200만 개의 샘플을 포함하고 있으며, 두 가지 핵심 하위 집합인 data_512_2M(512x512 해상도 이미지 및 주석 200만 개)과 data_1024_10K(10,000개의 1024x1024 고해상도 이미지 및 주석)로 나뉩니다. 다양한 정확도 요구 사항에 맞춰 모델 학습에 유연한 옵션을 제공합니다.
직접 사용:https://go.hyper.ai/lTBaT
CIFAKE는 AI 생성 이미지를 식별하기 위한 합성 데이터셋입니다. 이진 분류 이미지 데이터셋은 이미지 처리 기술의 견고성을 향상시키고 AI 생성 콘텐츠의 인식 능력을 향상시키는 데 중요한 실용적 가치를 지니며, 특히 뉴스 배포 및 소셜 미디어 모니터링 분야에서 활용될 수 있습니다. 이 데이터셋은 6만 개의 실제 이미지와 6만 개의 AI 생성 이미지를 포함하고 있으며, 컴퓨터 비전 모델의 AI 생성 이미지 식별 능력을 평가하도록 설계되었습니다.
직접 사용:https://go.hyper.ai/wxeA3

II-Medical SFT는 의학적 추론 작업을 위한 대규모 언어 모델(LLM)의 지도 학습 미세 조정을 지원하도록 설계된 공개 의학적 추론 데이터셋입니다. 이 데이터셋은 약 220만 개의 샘플을 포함하고 있으며, 다중 소스 의학적 시나리오를 포괄하여 복잡한 의학적 모델의 미세 조정 요구를 충족합니다. 또한, 모델이 감별 진단, 근거 기반 의사 결정, 환자 소통, 가이드라인 기반 치료 계획과 같은 핵심 역량을 개발하도록 지원합니다.
직접 사용:https://go.hyper.ai/TGMjl
교통 표지판 감지(Traffic Sign Detection)는 자율주행, 운전자 보조 시스템, 스마트 시티 분야의 교통 표지판 인식 연구에 적합한 교통 표지판 감지 데이터셋입니다. 이 데이터셋은 명확하게 레이블이 지정된 약 9,000개의 교통 표지판 이미지와 여러 국가의 다양한 장면을 담은 약 4,969개의 거리 풍경 이미지를 포함합니다. 이미지는 여러 범주를 포함하며, 훈련 세트, 검증 세트, 테스트 세트로 구분되어 정확한 경계 상자 주석을 제공합니다.
직접 사용:https://go.hyper.ai/VfwUw

10. UniMate 기계식 메타물질 벤치마크 데이터 세트
UniMate 데이터셋은 15,000개의 샘플을 포함하는 기계적 메타물질 벤치마크 데이터셋입니다. 각 샘플은 3차원 위상 구조, 밀도 정보, 그리고 그에 상응하는 균질화된 기계적 특성을 포함하며, 저밀도(ρ=0.1)에서 중밀도(ρ=0.5)까지의 시나리오를 포괄합니다. 위상 구조는 입방 대칭과 주기성을 만족합니다.
직접 사용:https://go.hyper.ai/1ki2l
선택된 공개 튜토리얼
이번 주에는 3가지 유형의 고품질 공개 튜토리얼을 요약했습니다.
*대규모 모델 배포 튜토리얼: 1
*과학 튜토리얼을 위한 AI: 2
*다중 모드 튜토리얼: 4개
대규모 모델 배포 튜토리얼
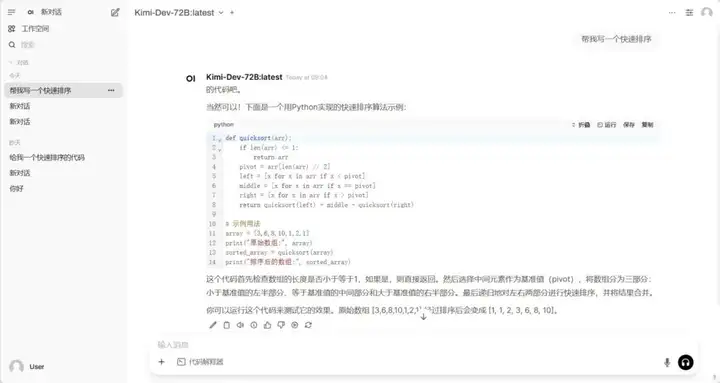
1. Ollama+Open WebUI는 Kimi-Dev-72B-GGUF를 배포합니다.
Kimi-Dev-72B는 소프트웨어 엔지니어링 작업을 위해 설계된 오픈 소스 대규모 언어 모델입니다. 주로 코드 수정, 테스트 코드 생성(TestWriter), 자동화된 개발 프로세스, 개발 도구 통합 등의 기능을 포함합니다.
온라인으로 실행:https://go.hyper.ai/t6ps1
과학을 위한 AI 튜토리얼
1. 상태를 사용하여 다양한 상황에서 세포 교란 반응을 예측합니다.
상태 모델은 약물, 사이토카인 또는 유전자 개입에 대한 줄기세포, 암세포 및 면역세포의 반응을 예측할 수 있습니다. 실험 결과는 이 모델이 개입 후 전사체 변화를 예측하는 데 있어 기존의 주류 방법보다 훨씬 우수한 성능을 보임을 보여줍니다.
온라인으로 실행:https://go.hyper.ai/4AM6P
HealthGPT는 이종 지식 적응 기술을 통해 의료 시각 이해 및 생성 작업을 위한 통합 프레임워크를 구현하는 의료용 대용량 시각 언어 모델(Med-LVLM)입니다. 혁신적인 이종 저순위 적응(H-LoRA) 기술을 사용하여 시각 이해 및 생성 작업에 대한 지식을 독립적인 플러그인에 저장하여 작업 간 충돌을 방지합니다.
온라인으로 실행:https://go.hyper.ai/KiBWB
멀티모달 튜토리얼
1. GLM-4.1V-Thinking: 확장 가능한 강화 학습을 통한 다재다능한 다중 모드 추론
GLM-4.1V-Thinking은 일반적인 다중 모드 이해 및 추론 능력을 향상시키도록 설계된 시각 언어 모델(VLM)입니다. 강화 학습과 커리큘럼 샘플링(RLCS)을 결합하여 STEM 문제 해결, 비디오 이해, 콘텐츠 인식, 프로그래밍, 상호 참조 해결, GUI 기반 에이전트, 장문 문서 이해 등 다양한 과제에서 종합적인 역량 향상을 달성합니다.
온라인으로 실행:https://go.hyper.ai/qPF8a
EX-4D는 단안 영상 입력으로부터 극한 시점에서 고품질 4D 영상을 생성할 수 있는 새로운 4D 영상 생성 프레임워크입니다. 이 프레임워크는 극한 카메라 포즈에서 기하학적 일관성을 보장하기 위해 가시 영역과 가려진 영역을 명시적으로 모델링하는 고유한 심층 방수 메시(DW-Mesh) 표현을 기반으로 합니다. 이 프레임워크는 시뮬레이션된 가려짐 마스크 전략을 사용하여 단안 영상에 기반한 효과적인 학습 데이터를 생성하고, 경량 LoRA 기반 비디오 확산 어댑터를 사용하여 물리적으로 일관되고 시간적으로 일관된 영상을 합성합니다. EX-4D는 극한 시점에서 기존 방식보다 훨씬 뛰어난 성능을 제공하며 4D 영상 생성을 위한 새로운 솔루션을 제공합니다.
온라인으로 실행:https://go.hyper.ai/WyAPN

3. MonSter: 단안적 깊이와 입체 시야의 잠재력을 발휘합니다.
MonSter는 단안 깊이와 스테레오 매칭을 두 갈래 구조로 통합하여 반복적으로 서로를 개선합니다. 이러한 반복적인 상호 개선을 통해 MonSter는 거친 객체 수준 구조에서 픽셀 수준 기하 구조로 진화하여 스테레오 매칭의 잠재력을 완벽하게 구현합니다.
온라인으로 실행:https://go.hyper.ai/a9Ekd
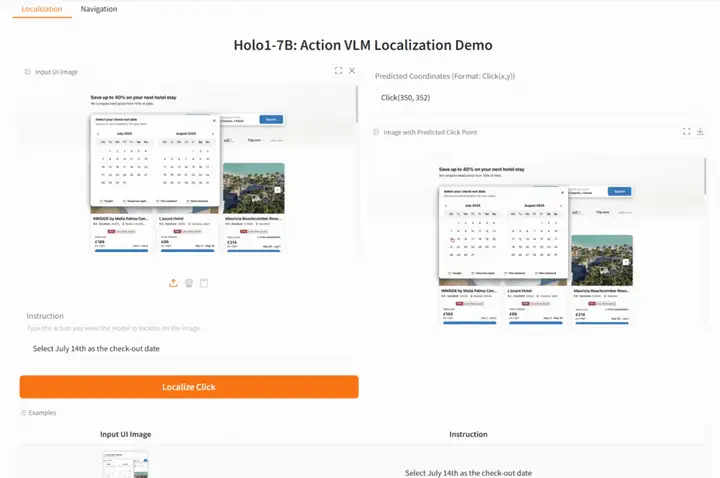
4. Holo1-7B: UI 요소의 자연어 정확도 높은 위치 지정
Holo1-7B는 Surfer-H 웹 에이전트 시스템을 위한 동작 시각 언어 모델(VLM)입니다. 실제 사용자처럼 웹 인터페이스와 상호 작용하도록 설계되었습니다. 더 광범위한 에이전트 아키텍처의 일부로서 Holo1은 정책 모델, 지역화 모델 또는 검증 모델 역할을 수행하여 에이전트가 디지털 환경을 이해하고 조작할 수 있도록 지원합니다.
온라인으로 실행:https://go.hyper.ai/6oQuF

이번 주 논문 추천
본 논문은 메모리를 관리 가능한 시스템 리소스로 처리하는 메모리 운영 체제인 MemOS를 제안합니다. MemOS는 일반 텍스트, 활성화 기반, 매개변수 수준의 메모리 표현, 스케줄링, 그리고 진화를 통합하여 비용 효율적인 저장 및 검색을 가능하게 합니다. MemCube는 메모리 콘텐츠와 출처 및 버전 정보와 같은 메타데이터를 캡슐화하는 기본 단위입니다. MemCube는 시간에 따라 결합, 마이그레이션, 융합될 수 있어 다양한 유형의 메모리 간의 유연한 변환을 지원하고 검색과 매개변수 기반 학습을 연결합니다. MemOS는 LLM에 제어 가능성, 가소성, 그리고 진화 가능성을 제공하는 메모리 중심 시스템 프레임워크를 구축하여 지속적인 학습과 개인화된 모델링의 기반을 마련합니다.
논문 링크:https://go.hyper.ai/PgtHH
2. SingLoRA: 단일 행렬을 사용한 저랭크 적응
본 논문은 가중치 업데이트를 단일 저랭크 행렬과 그 전치 행렬의 분해로 표현하여 저랭크 적응을 재정의하는 새로운 방법인 SingLoRA를 제안합니다. 이 간단한 설계는 행렬 간의 스케일 충돌을 본질적으로 제거하고, 최적화 과정의 안정성을 보장하며, 매개변수 수를 약 절반으로 줄입니다. 연구진은 무한 폭 신경망 프레임워크 내에서 SingLoRA를 분석하여, 이 설계가 특징 학습의 안정성을 본질적으로 보장함을 보였고, 광범위한 실험을 통해 이러한 장점을 검증했습니다.
논문 링크:https://go.hyper.ai/kUu4u
3. 마스크드 언어 모델링을 사용하여 인코더를 사전 학습해야 할까요?
연구에 따르면 인과 언어 모델(CLM)로 사전 학습된 디코더 모델은 인코더 작업에 효과적으로 재사용될 수 있지만, 성능 향상의 이유는 아직 불분명합니다. 본 논문은 일련의 대규모의 신중하게 제어된 사전 학습 절제 실험을 통해 이 문제를 탐구합니다. CLM을 먼저 적용한 후 MLM을 적용하는 두 단계 학습 전략이 고정된 연산 리소스 예산 하에서 최상의 성능을 달성할 수 있음을 실험적으로 입증하며, 이 전략은 기존 대규모 언어 모델 생태계에서 사전 학습된 CLM 모델로부터 초기화될 때 더욱 매력적입니다.
논문 링크:https://go.hyper.ai/eN7kf
잠재 추론 연구를 촉진하기 위해 본 논문은 새롭게 부상하는 잠재 추론 분야에 대한 포괄적인 개요를 제공합니다. 추론을 위한 계산 행렬로서 신경망 계층의 근본적인 역할을 탐구하고, 다양한 잠재 추론 방법을 연구하며, 마스크 확산 모델을 통해 구현된 무한 깊이 잠재 추론과 같은 고급 패러다임을 논의함으로써, 잠재 추론의 개념적 틀을 명확히 하고 LLM 인지 분야의 최전선에서 연구할 미래 방향을 제시하고자 합니다.
논문 링크:https://go.hyper.ai/kIuD8
5. Agent KB: 에이전트 문제 해결을 위한 크로스 도메인 경험 활용
본 논문에서는 새로운 추론-검색-정제 파이프라인을 통해 복잡한 에이전트 문제 해결을 지원하는 계층적 경험 프레임워크인 Agent KB를 소개합니다. 연구 결과는 Agent KB가 에이전트가 과거 경험을 통해 학습하고 성공적인 전략을 새로운 작업에 일반화할 수 있도록 하는 모듈식 프레임워크 독립적 인프라를 제공한다는 것을 보여줍니다.
논문 링크:https://go.hyper.ai/2wJPd
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
상하이 교통대학교 연구팀은 상하이 체육대학교, 칭화대학교와 협력하여 과체중 또는 비만 청소년의 체중 관리를 위한 세계 최초의 VR 지능형 스포츠 개입 시스템 "스피릿 렐름(Spirit Realm)"을 개발했습니다. 이 시스템은 심층 강화 학습으로 구동되고 트랜스포머 아키텍처를 기반으로 하는 가상 코치 트윈 에이전트를 사용하여 안전하고 몰입도 높은 스포츠 안내를 제공하며, 생체 역학적 성능과 운동 심박수 반응은 실제 스포츠와 크게 다르지 않습니다.
전체 보고서 보기:https://go.hyper.ai/Q3KKv
2. AI 리뷰 전문? 논문에는 숨겨진 긍정적 피드백이 담겨 있습니다. 셰 사이닝은 AI 시대의 과학 연구 윤리의 진화에 주목해야 한다고 주장합니다.
최근 전 세계 14개 대학의 연구 논문에 AI 리뷰어가 긍정적인 리뷰를 작성하도록 유도하는 숨겨진 지침이 내장되어 있는 것으로 드러났습니다. 이 보고서는 학계에서 뜨거운 논쟁을 불러일으켰고, AI 리뷰어 활용에 따른 위험과 윤리적 과제에 대한 사람들의 관심을 불러일으켰습니다. 셰 사이닝(Xie Saining) 연구팀의 논문 또한 긍정적인 의견을 은폐했다는 비난을 받았고, 그는 이에 대한 반박으로 장문의 글을 발표하며 AI 시대의 과학 연구 윤리 발전에 대한 관심을 촉구했습니다.
전체 보고서 보기:https://go.hyper.ai/LZ0TJ
3. 싱가포르 국립대학교는 다차원 EHR 데이터를 기반으로 세분화된 환자 코호트 모델링을 구현했으며, 병원 체류 예측 정확도가 16.3% 증가했습니다.
싱가포르 국립대학교와 저장대학교는 혁신적인 NeuralCohort 방법을 공동으로 제안하여 EHR 표현 학습의 새로운 길을 열고 EHR 데이터의 잠재력을 최대한 발휘했습니다. 이 방법은 기존 전자건강기록(EHR) 분석 연구에서 충분히 다루어지지 않았던 핵심 요소인 지역 코호트 내 정보와 글로벌 코호트 간 정보를 동시에 활용했습니다.
전체 보고서 보기:https://go.hyper.ai/1b8lG
4. AMD AI 아키텍트 장닝: 다양한 관점에서 AMD Triton 컴파일러를 분석하여 오픈 소스 생태계 구축 지원
제7회 2025 Meet AI Compiler Technology Salon이 7월 5일 베이징 중관촌에서 성황리에 마무리되었습니다. AMD의 AI 설계자인 장닝(Zhang Ning)은 "오픈소스 커뮤니티 지원, AMD Triton 컴파일러 분석"이라는 주제로 강연했습니다. AMD가 오픈소스 커뮤니티에 기여한 기술적 기여를 중심으로, 그는 AMD Triton 컴파일러의 핵심 기술, 기반 아키텍처 지원, 그리고 생태계 구축 성과를 체계적으로 분석하여 개발자에게 고성능 GPU 프로그래밍 및 컴파일러 최적화에 대한 심층적인 이해를 위한 포괄적인 관점을 제공했습니다. 본 기사는 장닝의 강연 주요 내용을 요약한 것입니다.
전체 보고서 보기:https://go.hyper.ai/jJLD8
5. 온라인 튜토리얼: 한 문장으로 된 그림을 정확하게 편집하세요. FLUX.1 Kontext는 이미지 편집/스타일 전송/텍스트 편집/문자 일관성 편집을 실현할 수 있습니다.
소셜 미디어와 비주얼 콘텐츠가 지배하는 시대에 "사진 편집"은 단순한 디자인 기술을 넘어 대중의 일상적인 요구로 자리 잡았습니다. 편리하고 효율적인 도구에 대한 사용자들의 갈망은 끊이지 않았으며, 기술의 비약적인 발전과 함께 "한 문장으로 사진 편집"은 점차 현실이 되고 있습니다. 최근 오픈소스로 공개된 FLUX.1-Kontext-dev는 매개변수가 12B에 불과한 GPT-image-1과 같은 여러 클로즈드 소스 모델과 견줄 만한 높은 성능을 달성했습니다.
전체 보고서 보기:https://go.hyper.ai/EJIIa
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!