Command Palette
Search for a command to run...
AMD AI 아키텍트 장닝: 다양한 관점에서 AMD Triton 컴파일러를 분석하여 오픈 소스 생태계 구축 지원

7월 5일, HyperAI가 주최하는 제7회 Meet AI Compiler Technology Salon이 예정대로 개최되었습니다. 한여름의 뜨거운 열기에도 불구하고 관객들의 열기는 여전히 뜨거웠습니다. 행사장은 사람들로 가득 찼고, 많은 사람들이 모든 발표 세션을 듣기 위해 일어섰습니다. AMD, Muxi Integrated Circuits, ByteDance, 그리고 베이징대학교의 여러 강사들이 차례로 무대에 올라 기초적인 컴파일부터 실제 구현까지 심도 있는 업계 통찰력과 트렌드 분석을 선보였으며, 실질적인 정보로 가득했습니다!
위챗 공개 계정 "HyperAI Super Neuro"를 팔로우하고 키워드 "0705 AI Compiler"에 답글을 달면 공인 강사의 발표 PPT를 받으실 수 있습니다.




고성능 GPU 커널 개발을 간소화하도록 설계된 프로그래밍 언어인 Triton은 복잡한 병렬 컴퓨팅 프로그래밍을 간소화하여 LLM 추론 및 학습 프레임워크의 핵심 도구로 자리매김했습니다. Triton의 핵심 장점은 개발 효율성과 하드웨어 성능의 균형을 맞추는 것입니다. 기본 하드웨어 세부 정보 노출을 방지하고 컴파일러 최적화를 통해 GPU 컴퓨팅 성능을 최대한 활용할 수 있습니다. 이러한 기능 덕분에 오픈 소스 커뮤니티에서 빠르게 인기를 얻었습니다.
GPU 분야를 선도하는 기업으로서 AMD는 Triton 언어 지원에 앞장서고 관련 코드를 오픈 소스 커뮤니티에 제공하여 Triton 생태계의 벤더 간 호환성을 증진해 왔습니다. 이러한 움직임은 고성능 컴퓨팅 분야에서 AMD의 기술적 영향력을 강화할 뿐만 아니라, 특히 대규모 모델 학습 및 추론 시나리오에서 오픈 소스 협업 모델을 통해 전 세계 개발자에게 더욱 유연한 GPU 프로그래밍 옵션을 제공하여 컴퓨팅 성능 최적화를 위한 새로운 길을 제시합니다.
AMD의 AI 아키텍트인 장닝은 "오픈 소스 커뮤니티 지원, AMD Triton 컴파일러 분석"이라는 제목의 연설에서 AMD Triton 컴파일러의 핵심 기술, 기반 아키텍처 지원, 생태 구축 성과를 체계적으로 해석했으며, 오픈 소스 커뮤니티에 대한 회사의 기술적 기여에 초점을 맞췄습니다.개발자에게 고성능 GPU 프로그래밍과 컴파일러 최적화를 깊이 이해할 수 있는 포괄적인 관점을 제공합니다.
HyperAI는 장닝 교수의 연설을 원문의 의도를 훼손하지 않고 편집 및 요약했습니다. 다음은 연설 전문입니다.
Triton: 효율적인 프로그래밍, 실시간 컴파일, 유연한 반복
Triton은 OpenAI가 제안한 오픈 소스 프로그래밍 언어이자 컴파일러로, 고성능 GPU 커널 개발을 단순화하기 위해 고안되었습니다.주류 LLM 추론 훈련 프레임워크에서 널리 사용됩니다. 핵심 기능은 다음과 같습니다.
* 효율적인 프로그래밍은 커널 개발을 단순화하여 개발자가 복잡한 GPU 기반 아키텍처를 깊이 이해하지 않고도 효율적으로 GPU 코드를 작성할 수 있도록 해줍니다.
* 실시간 컴파일은 적시 컴파일을 지원하여 다양한 하드웨어 및 작업 요구 사항에 맞게 GPU 코드를 동적으로 생성하고 최적화할 수 있습니다.
* 블록 프로그램과 스칼라 스레드를 기반으로 하는 유연한 반복 공간 구조는 반복 공간의 유연성을 향상시키고, 희소 작업 처리를 용이하게 하며, 데이터 지역성을 최적화합니다.
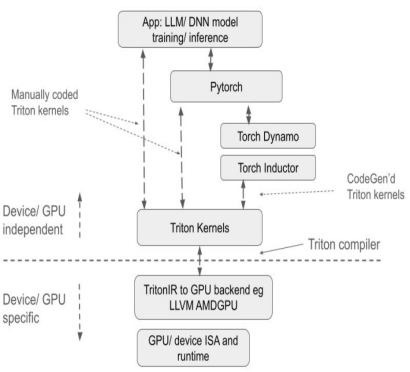
기존 솔루션과 비교했을 때 Triton은 상당한 장점을 가지고 있습니다.
첫 번째,오픈 소스 프로젝트인 Triton은 Python 기반 프로그래밍 환경을 제공합니다. 사용자는 기본 GPU 아키텍처의 세부 사항에 신경 쓰지 않고 Python Triton 코드를 개발하여 GPU 커널을 구현할 수 있습니다. 이는 AMD HIP와 같은 다른 GPU 프로그래밍 방식에 비해 개발 난이도를 크게 낮추고 제품 개발 효율성을 크게 향상시킵니다. Triton 컴파일러는 GPU 아키텍처 특성에 기반한 다양한 최적화 전략을 사용하여 Python 코드를 최적화된 GPU 어셈블리 코드로 변환하고, 상위 텐서 연산을 기본 GPU 명령어로 자동 컴파일하며, GPU에서 코드의 효율적인 작동을 보장합니다.
둘째,Triton은 하드웨어 간 호환성이 뛰어납니다. 이론적으로 동일한 코드 세트를 NVIDIA, AMD GPU, 그리고 Triton을 지원하는 국내 GPU 등 다양한 하드웨어에서 실행할 수 있습니다. 성능과 유연성 측면에서 PyTorch와 같은 플랫폼보다 더 뛰어난 성능과 최적화 유연성을 제공하며, CUDA에 비해 기본 GPU 연산 세부 정보를 숨길 수 있어 개발자가 알고리즘 구현에 더욱 집중할 수 있도록 합니다.
PyTorch API와 비교했을 때, 이 API는 컴퓨팅 연산의 구체적인 구현에 더욱 중점을 두어 개발자가 스레드 블록 분할 방법을 유연하게 정의하고, 블록/타일 단위의 데이터 읽기 및 쓰기를 수행하고, 하드웨어 관련 컴퓨팅 기본 요소를 실행할 수 있도록 지원합니다. 특히 연산자 융합 및 매개변수 튜닝과 같은 성능 최적화 전략 개발에 적합합니다.
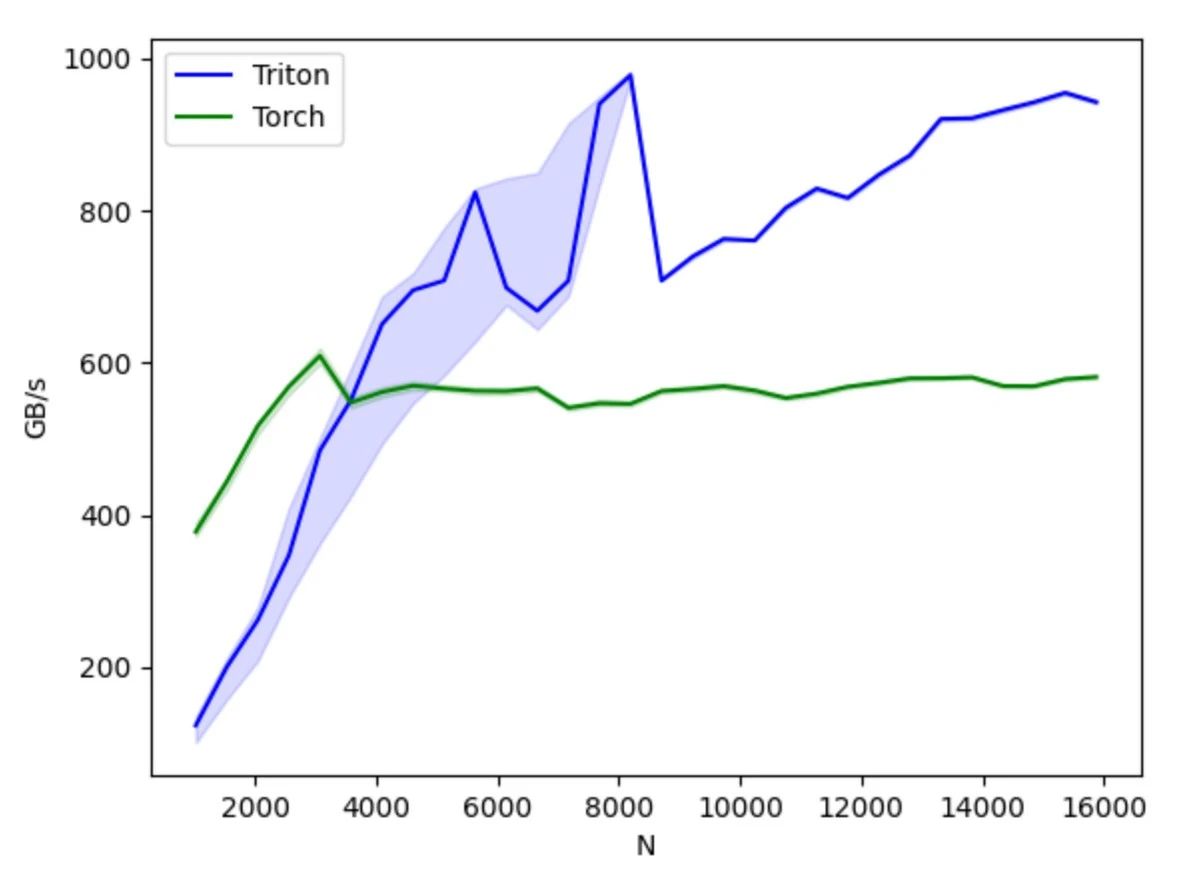
CUDA와 달리 Triton은 스레드 수준의 작업 제어를 숨기고 컴파일러가 공유 스토리지, 스레드 병렬 처리, 병합된 메모리 액세스, 텐서 레이아웃과 같은 세부 사항을 자동으로 처리하도록 합니다. 이를 통해 병렬 프로그래밍 모델의 난이도를 낮추는 동시에 GPU 코드 개발 효율성을 향상시켜 개발 효율성과 프로그램 성능 간의 균형을 효과적으로 달성합니다. 개발자는 기본 하드웨어 세부 사항이나 프로그래밍 최적화 기법에 대해 크게 신경 쓰지 않고 알고리즘의 설계 및 구현에 집중할 수 있습니다. 간단한 병렬 프로그래밍 원리만 이해한다면 더 나은 성능의 GPU 코드를 빠르게 개발할 수 있습니다.
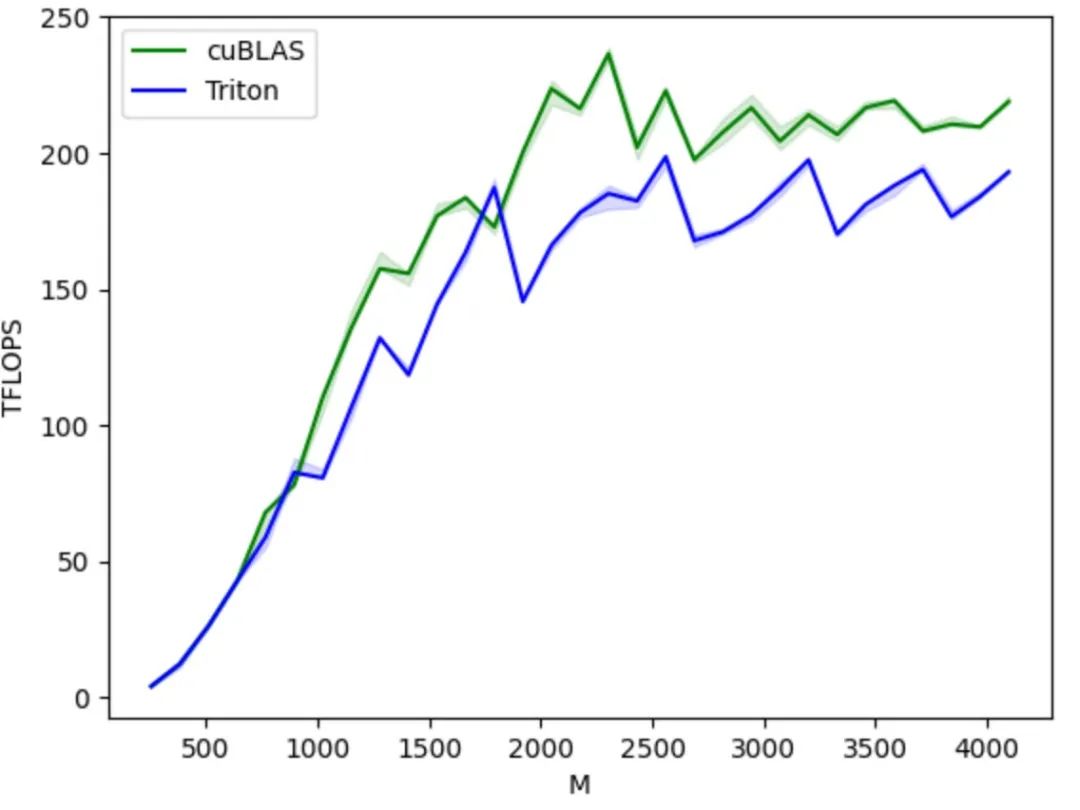
생태학적 관점에서 볼 때, Triton은 Python 언어 환경을 기반으로 PyTorch에서 정의한 텐서 데이터 타입을 사용하며, PyTorch 생태계에 완벽하게 통합될 수 있습니다. 폐쇄형 CUDA와 달리, Triton의 오픈 소스 코드와 개방형 생태계는 AI 칩 제조업체가 자사 칩에 Triton을 포팅하고 오픈 소스 커뮤니티를 활용하여 툴 체인을 개선하는 것을 더욱 용이하게 만들어 Triton 생태계의 건전한 발전을 촉진합니다.
AMD Triton 컴파일러 프로세스
Triton 컴파일러는 다음 그림에서 볼 수 있듯이 프런트엔드 모듈, 최적화 모듈, 백엔드 머신 코드 생성 모듈의 세 가지 핵심 모듈로 구성됩니다.
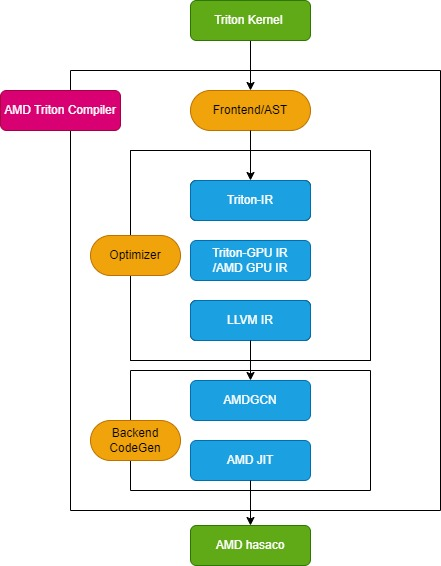
프런트엔드 모듈
프런트엔드 모듈은 Python Triton 커널 함수의 추상 구문 트리(AST)를 탐색하여 Triton 중간 표현(Triton-IR)을 생성하고, 해당 커널 함수는 Triton-IR로 변환됩니다.예를 들어, @triton.jit 데코레이터로 표시된 add_kernel 커널 함수는 이 모듈에서 해당 IR로 변환됩니다. JIT 데코레이터 진입 함수는 먼저 TRITON_INTERPRET 환경 변수의 값을 확인합니다. 이 변수가 True이면 InterpretedFunction이 호출되어 Triton 커널을 해석 모드로 실행합니다. False이면 JITFunction이 호출되어 실제 장치에서 Triton 커널을 컴파일하고 실행합니다.
커널 컴파일의 시작점은 Triton 컴파일 함수로, 대상 장치 및 컴파일 옵션 정보와 함께 호출됩니다. 이 프로세스는 커널 캐시 관리자를 생성하고, 컴파일 파이프라인을 시작하고, 커널 메타데이터를 채웁니다. 또한 AMD 플랫폼용 TritonAMDGPUDialect와 같은 백엔드 전용 언어와 LLVM-IR 컴파일을 처리하는 백엔드 전용 LLVM 모듈을 로드합니다. 모든 준비가 완료되면 ast_to_ttir 함수가 호출되어 커널용 Triton-IR 파일을 생성합니다.
최적화 모듈
최적화 모듈은 Triton-IR 최적화, Triton-GPU IR 최적화, LLVM-IR 최적화의 3가지 핵심 부분으로 나뉩니다.
* Triton-IR 최적화
AMD 플랫폼에서 Triton-IR 최적화 파이프라인은 make_ttir 함수로 정의됩니다. 이 단계에서 최적화는 하드웨어에 독립적이며, 인라이닝, 공통 부분 표현식 제거, 정규화, 데드 코드 제거, 루프 불변 코드 동작, 루프 풀기 등을 포함합니다.
* Triton-GPU IR 최적화
AMD 플랫폼에서는 GPU 성능 향상을 위해 make_ttgir 함수를 통해 Triton-IR 최적화 프로세스를 정의합니다. AMD GPU의 특성과 최적화 경험을 바탕으로 다음 그림과 같이 특정 최적화 프로세스를 개발했습니다.
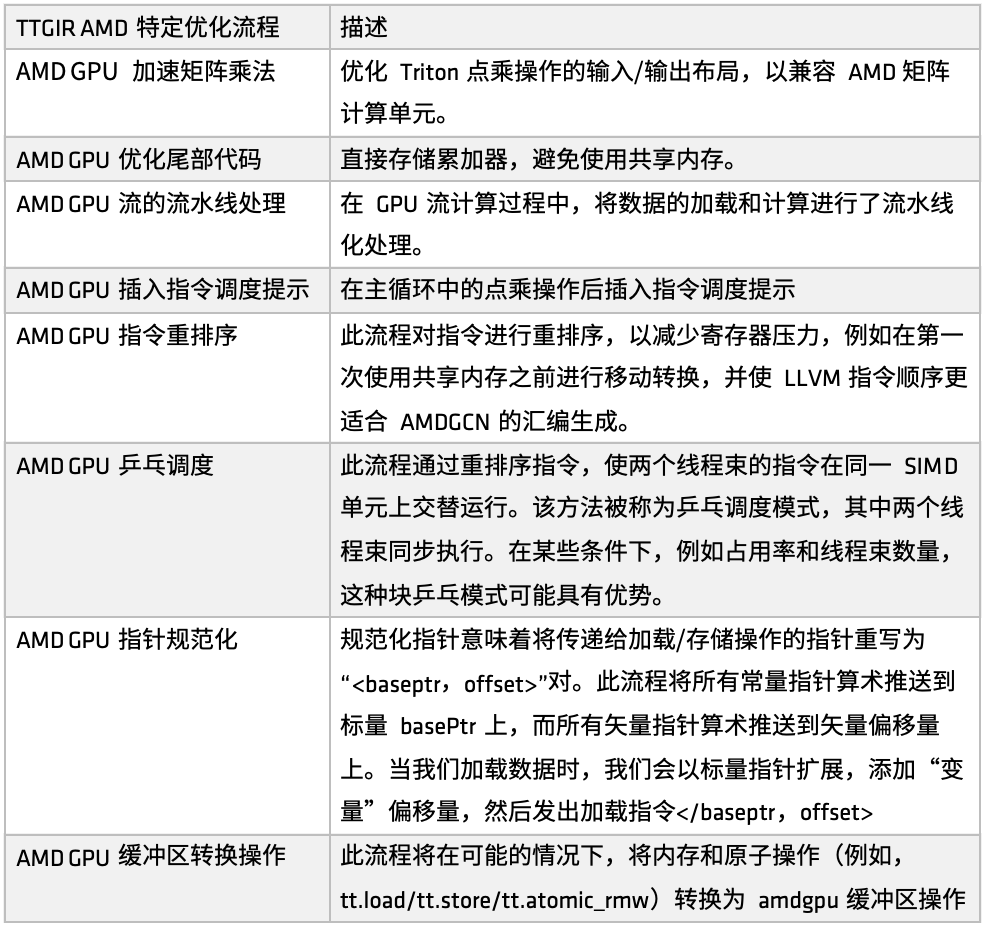
첫째, AMD GPU를 위한 가속 행렬 곱셈,이 최적화는 Triton의 점 곱셈 연산 입출력 레이아웃에 중점을 두어 AMD의 행렬 컴퓨팅 유닛(예: Matrix)과의 호환성을 높였습니다. 이 최적화는 전체 구현에서 비교적 큰 부분을 차지하는 CDNA 아키텍처에 대한 많은 매칭 처리를 포함합니다. AMD 플랫폼에서 Triton이 생성하는 코드를 심층적으로 최적화하려면 이 구현 부분에 집중하는 것이 좋습니다.
둘째, 꼬리 가공 단계에서최적화 전략은 어큐뮬레이터를 직접 저장하여 공유 메모리 사용을 피하고, 공유 메모리의 액세스 압력을 줄이고, 전반적인 효율성을 개선하는 것입니다.
다음으로, GPU 스트림 컴퓨팅 과정에서 로딩 및 컴퓨팅의 파이프라인 처리가 소개되었습니다.즉, 이전 작업이 실행되는 동안 해당 메모리가 호출되어 데이터를 로드하고 계산하는 병렬 실행 모드를 형성합니다. 이 메커니즘은 많은 사용자 시나리오에서 좋은 결과를 얻었습니다. 파이프라인 최적화를 기반으로, 컴퓨팅 장치 또는 원격 작업 완료 후 명령어 흐름을 안내하는 명령어 스케줄링 힌트가 도입되어 명령어 수준에서의 응답 효율이 향상됩니다.
이후 AMD는 다양한 목적에 맞게 여러 세트의 명령어 재정렬을 구현했습니다.여기에는 레지스터 압력 완화, 중복 리소스 할당 및 해제 방지, 부하와 계산 프로세스 간의 연결 최적화 등이 포함됩니다. 재정렬의 한 부분은 파이프라인 메커니즘과 긴밀하게 통합되어 있으며, 다른 부분은 AMDGCN 어셈블리의 생성 규칙에 더 잘 부합하도록 LLVM IR의 명령어 순서를 조정하는 데 중점을 둡니다.
지시사항 재정렬 및 일정 힌트 외에도,또한, 우리는 또 다른 스케줄링 최적화 전략인 핑퐁 스케줄링을 도입했습니다.순환 스케줄링 메커니즘을 통해 두 개의 스레드 워프가 동일한 SIMD 장치에서 번갈아 실행되어 유휴 상태와 대기를 방지하고, 이를 통해 컴퓨팅 리소스 활용도를 향상시킵니다.
또한 AMD는 포인터 정규화와 버퍼 작업 변환을 최적화했습니다.이러한 최적화의 주요 목표는 특정 비즈니스 애플리케이션에 대한 명령어를 효과적으로 매핑하고 더 효율적인 원자 명령어 실행을 달성하는 것입니다.
이러한 최적화 과정은 먼저 Triton-IR을 Triton-GPU IR로 변환합니다. 이 과정에서 레이아웃 정보가 IR에 내장됩니다. 텐서가 #blocked 레이아웃 형태로 표현된 다음 그림을 예로 들어 보겠습니다.

다른 Triton 행렬 곱셈 예제를 시도해 보면, 위의 최적화 흐름은 성능을 향상시키기 위해 공유 메모리 액세스를 도입합니다. 이는 행렬 곱셈에 대한 일반적인 최적화 솔루션이며, AMD MFMA 가속기용으로 설계된 amd_mfma 레이아웃을 사용합니다.
마침내,실험 검증에서는 더 복잡한 행렬 곱셈 행렬 계층을 예로 들었습니다. GPR(General Purpose Register) 매핑을 확인하는 과정에서 MFMA, 전치, 공유 메모리 호출 등 다수의 하드웨어 관련 명령어를 삽입했습니다. 뱅크 충돌 감소, 스위즐 연산 적용, 명령어 재정렬 및 파이프라인 처리 전략의 결합을 통해 이러한 모든 최적화가 Triton IR 변환 프로세스에 자동으로 추가되어 더욱 강력한 하드웨어 적응성과 성능 향상을 달성할 것입니다.

* LLVM-IR 최적화
AMD 플랫폼에서 최적화 프로세스는 make_llir 함수에 의해 정의됩니다. 이 함수는 IR 수준 최적화와 AMD GPU LLVM 컴파일러 구성의 두 부분으로 구성됩니다. IR 수준 최적화의 경우, AMD GPU별 최적화 프로세스에는 다음 그림과 같이 LDS/공유 메모리 관련 최적화와 LLVM-IR 수준의 일반 최적화가 포함됩니다.
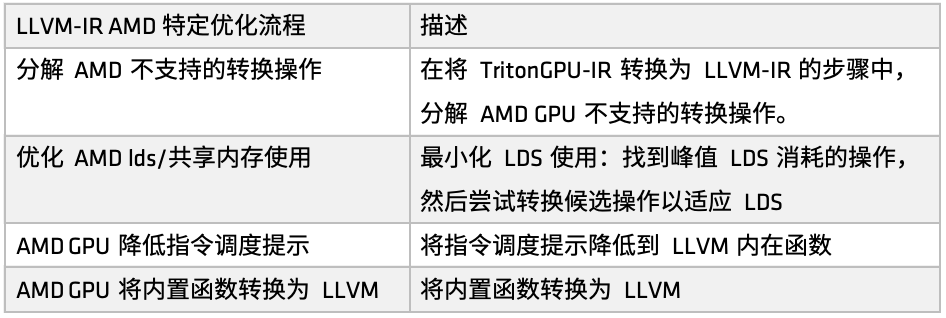
첫 번째,AMD가 지원하지 않는 일부 변환 연산을 분해합니다. 예를 들어, Triton GPU IR을 LLVM-IR로 변환할 때 현재 지원되지 않는 변환 경로가 발견되면, 전체 변환 프로세스가 원활하게 완료될 수 있도록 이러한 연산을 보다 기본적인 하위 연산으로 분해합니다.
AMD GPU LLVM 컴파일러를 구성할 때 먼저 LLVM 대상 라이브러리와 컨텍스트를 초기화하고, LLVM 모듈에서 컴파일 매개변수를 설정한 다음, AMD GPU HIP 커널에 대한 호출 규칙을 설정하고 amdgpu-flat-work-group-size, amdgpu-waves-per-eu, denormal-fp-math-f32와 같은 일부 LLVM-IR 속성을 구성하고, 마지막으로 LLVM 최적화를 실행하고 최적화 수준을 OPTIMIZE_O3으로 설정합니다.
속성 구성 참조 문서:
https://llvm.org/docs/AMDGPUUsage.html
백엔드 머신 코드 생성 모듈
백엔드 머신 코드 생성 모듈은 주로 중간 코드를 하드웨어에서 실행 가능한 바이너리 파일로 변환하는 역할을 합니다. 이 단계는 크게 AMDGCN 어셈블리 코드 생성과 최종 AMD hsaco ELF 파일 빌드의 두 단계로 나뉩니다.
먼저, make_amdgcn 단계에서 translateLLVMIRToASM 함수를 호출하여 AMD 어셈블리 코드를 생성합니다. 이 과정을 통해 중간 코드에서 대상 아키텍처 명령어 집합으로의 매핑이 완료되어 후속 바이너리 생성의 기반이 마련됩니다. 이후, 컴파일러는 make_hsaco 단계에서 assemble_amdgcn 함수와 ROCm 링크 모듈을 사용하여 AMD hsaco ELF(Executable and Linkable Format) 바이너리 파일을 생성합니다. 이 파일은 AMD GPU에서 직접 실행할 수 있는 최종 바이너리이며, 완전한 장치 측 명령어와 메타데이터를 포함합니다.
이 두 단계를 거쳐 컴파일러는 고수준 중간 표현을 저수준 GPU 실행 코드로 효율적으로 변환하여 프로그램이 AMD Instinct 시리즈와 같은 GPU에서 원활하게 실행되고 기본 하드웨어의 성능을 최대한 활용할 수 있도록 보장합니다.
AMD GPU 개발자 클라우드
AMD는 공식적으로 자사의 고성능 GPU 클라우드 플랫폼인 AMD Developer Cloud를 글로벌 개발자와 오픈 소스 커뮤니티에 공개했습니다.이 솔루션의 목표는 모든 개발자가 세계적 수준의 컴퓨팅 리소스에 방해받지 않고 액세스하고, AMD Instinct MI 시리즈 GPU 리소스에 편리하게 액세스하여 AI 및 고성능 컴퓨팅 작업을 신속하게 시작할 수 있도록 하는 것입니다.
AMD Developer Cloud에서 개발자는 필요에 따라 컴퓨팅 리소스를 유연하게 선택할 수 있습니다.
* 소형: 1 MI 시리즈 GPU(192GB VRAM)
* 대형: 8개의 MI 시리즈 GPU(1536GB VRAM)
이 플랫폼은 구성 임계값을 최소화하여 사용자가 복잡한 설치 없이 클라우드 기반 Jupyter Notebook을 즉시 시작할 수 있도록 지원합니다. 구성은 GitHub 계정이나 이메일 주소만으로 간편하게 완료할 수 있습니다. 또한, AMD Developer Cloud는 기본 제공되는 주요 AI 소프트웨어 프레임워크가 포함된 사전 구성된 Docker 컨테이너를 제공하여 환경 설정 시간을 최소화하는 동시에 높은 수준의 유연성을 유지하여 개발자가 특정 프로젝트 요구에 맞게 코드를 맞춤 설정할 수 있도록 지원합니다.
개발자 여러분, AMD Developer Cloud를 직접 체험하고 코드를 실행하여 아이디어를 검증해 보세요. 이 플랫폼은 혁신과 구현을 가속화하는 데 필요한 안정적이고 강력하며 유연한 컴퓨팅 성능을 제공합니다.
AMD 개발자 클라우드 링크:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
PPT 받기:위챗 공개 계정 "HyperAI Super Neuro"를 팔로우하고 키워드 "0705 AI Compiler"에 답글을 달면 공인 강사의 발표 PPT를 받으실 수 있습니다.