Command Palette
Search for a command to run...
OmniGen2 다중 모드 추론 × 자가 교정 듀얼 엔진으로 이미지 생성의 새로운 패러다임을 선도합니다. 95만 개의 분류 라벨! TreeOfLife-200M은 종 인지의 새로운 차원을 열어줍니다.

최근 몇 년 동안 생성 AI 기술은 이미지 분야에서 상당한 발전을 이루었습니다. Stable Diffusion 시리즈와 DALL-E3와 같은 모델은 확산 모델을 통해 고품질 텍스트-이미지 생성을 달성했습니다. 그러나 이러한 모델은 일반적인 시각 생성 모델에 필요한 포괄적인 지각 이해 및 생성 기능이 부족합니다. OmniGen은 확산 모델 아키텍처를 기반으로 다양한 생성 작업에 대한 통합 솔루션을 제공하기 위해 탄생했습니다. 멀티태스크 처리 기능을 갖추고 있으며 추가 플러그인 없이도 고품질 이미지를 생성할 수 있습니다. 하지만 이 모델이 멀티모달 디커플링과 데이터 다양성 측면에서 여전히 한계가 있다는 것은 부인할 수 없습니다.
이러한 어려움을 극복하고 시스템의 유연성과 표현력을 더욱 향상시키기 위해 OmniGen2는 큰 혁신을 이루었습니다.텍스트와 이미지 모달리티에 대해 두 개의 독립적인 디코딩 경로가 있습니다.비공유 매개변수와 별도의 이미지 태거를 사용합니다. 이러한 설계를 통해 OmniGen2는 변이 자동 인코더 입력을 재구성하지 않고도 기존 다중 모드 이해 모델을 기반으로 구축할 수 있으므로 원본 텍스트 생성 기능을 그대로 유지할 수 있습니다.
현재 HyperAI 공식 홈페이지에서 "OmniGen2: 고급 멀티모달 생성 탐색" 튜토리얼이 공개되었습니다. 지금 바로 체험해보세요~
OmniGen2: 고급 멀티모달 생성 탐색
온라인 사용:https://go.hyper.ai/fKbUP
6월 30일부터 7월 4일까지 hyper.ai 공식 웹사이트가 업데이트됩니다.
* 고품질 공개 데이터 세트: 10
* 엄선된 고품질 튜토리얼: 7개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 7월 마감일 상위 컨퍼런스: 4
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. ShareGPT-4o-Image 이미지 생성 데이터 세트
ShareGPT-4o-Image는 GPT-4o 수준의 이미지 생성 기능을 오픈소스 멀티모달 모델로 마이그레이션하는 것을 목표로 하는 대규모 고품질 이미지 생성 데이터셋입니다. 이 데이터셋의 모든 이미지는 GPT-4o의 이미지 생성 함수를 통해 생성되었으며, GPT-4o에서 생성된 총 92,256개의 이미지 생성 샘플을 포함하고 있습니다.
직접 사용:https://go.hyper.ai/5G48Y

2. MAD-Cars 다중 시점 자동차 비디오 데이터 세트
MAD-Cars는 기존 공개 멀티뷰 자동차 데이터셋의 범위를 크게 확장하는 대규모 멀티뷰 자동차 비디오 데이터셋입니다. 이 데이터셋은 약 7만 개의 자동차 비디오 인스턴스를 포함하고 있으며, 인스턴스당 평균 85개의 프레임을 제공합니다. 대부분의 자동차 인스턴스는 1920×1080 해상도를 가지며, 다양한 차종, 색상, 그리고 3가지 조명 조건을 포함하여 약 150개 브랜드의 자동차를 포함합니다.
직접 사용:https://go.hyper.ai/xuB9I
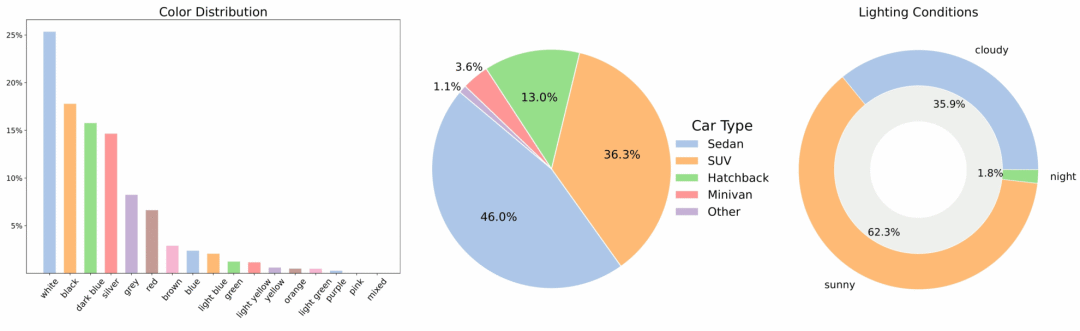
3. 식물 및 작물 작물 이미지 데이터 세트
식물 및 작물 데이터셋은 농업 AI 분야를 위한 포괄적인 작물 이미지 데이터셋으로, 전 세계적으로 널리 재배되는 139종의 작물을 포함하는 10만 개의 표준화된 이미지를 포함하고 있습니다. 이 데이터셋은 묘목부터 개화 및 결실까지 작물의 여러 생장 단계를 포괄하며, 이미지 콘텐츠는 잎, 줄기, 열매와 같은 다양한 구조적 부분을 포괄하고 풍부한 표현 정보를 제공합니다. 모든 이미지는 모델 학습 시 크기 차이의 영향을 줄이기 위해 224x224 픽셀로 통합되었습니다.
직접 사용:https://go.hyper.ai/PLVJp

4. 다중모달 교과서-6.5M 다중모달 교과서 데이터 세트
Multimodal-Textbook-6.5M은 멀티모달 사전 학습을 강화하고 모델의 인터레이스된 시각 및 텍스트 입력 처리 능력을 확장하는 것을 목표로 합니다. 이 데이터셋은 교육용 비디오에서 추출한 650만 개의 이미지와 8억 개의 텍스트 데이터를 포함합니다. 모든 이미지와 텍스트는 수학, 물리, 화학 등 6개 기본 과목을 다루는 온라인 교육용 비디오에서 추출됩니다.
직접 사용:https://go.hyper.ai/q8Iin
5. IndicVault 인도 질문-답변 쌍 데이터 세트
Indic Vault는 챗봇 및 음성 비서 튜닝에 적합한 인도 일상 언어 질의응답 데이터셋입니다. 이 데이터셋은 2025년 인도 전역에서 사용되는 현대 일상 언어로 작성된 질의응답 쌍을 포함하고 있으며, 일상 대화에서 사용되는 실제 구어체 표현을 포착하여 20가지 핵심 범주를 포괄합니다.
직접 사용:https://go.hyper.ai/JhEUR
6. DREAM-1K 비디오 설명 벤치마크 데이터 세트
이 데이터 세트는 5가지 범주에 속하는 다양한 복잡성의 주석이 달린 1,000개의 비디오 클립으로 구성되어 있으며, 각 클립에는 단일 프레임으로는 정확하게 식별할 수 없는 동적 이벤트가 최소 하나 이상 포함되어 있습니다. 각 비디오에는 모든 이벤트, 동작 및 동작을 포괄하는 세부적인 수동 주석이 제공됩니다.
직접 사용:https://go.hyper.ai/AgOm0
7. 뇌 MRI 뇌종양 검출 분석 데이터 세트
뇌 MRI는 다양한 환자의 고품질 다중 시퀀스 뇌 MRI 스캔 데이터를 포함합니다. 이 스캔 데이터에는 T1 강조 영상, T2 강조 영상, FLAIR 영상, 그리고 확산 강조 영상 시퀀스가 포함됩니다. 이 데이터세트는 다양한 유형의 뇌종양을 포함하며, 건강한 대조군과 비교 분석되므로 모든 고급 머신러닝 모델 및 임상 연구 응용 분야의 개발 및 검증에 적합합니다.
직접 사용:https://go.hyper.ai/oZWNu
8. AceReason-1.1-SFT 수학 코드 추론 데이터 세트
이 데이터셋은 수학 및 코드 추론 모델 AceReason-Nemotron-1.1-7B의 SFT 학습 데이터로 사용됩니다. 이 데이터셋의 모든 답변은 DeepSeek-R1을 통해 생성되었습니다. AceReason-1.1-SFT 데이터셋은 2,668,741개의 수학 샘플과 1,301,591개의 코드 샘플을 포함하고 있으며, 여러 데이터 소스의 데이터를 포함합니다. 데이터셋은 정제되었으며, 수학 및 코딩 벤치마크의 테스트 샘플과 9-gram이 겹치는 샘플은 필터링되었습니다.
직접 사용:https://go.hyper.ai/WGl1k
9. TreeOfLife-200M 생물학적 시각 데이터 세트
TreeOfLife-200M은 생물학적 컴퓨터 비전 모델을 위한 가장 크고 다양한 공개 머신러닝 지원 데이터셋입니다. 이 데이터셋은 약 2억 1,400만 개의 이미지를 포함하고 있으며, 95만 2,000개 종 범주를 포괄하고 있으며, 4개 핵심 생물다양성 데이터 제공업체의 이미지와 메타데이터를 통합합니다.
직접 사용:https://go.hyper.ai/UKC0H
10. VL-Health 의료 추론 생성 데이터 세트
VL-Health는 의료 다중모달 이해 및 생성을 위한 최초의 포괄적인 데이터셋입니다. 이 데이터셋은 765,000개의 이해 작업 샘플과 783,000개의 생성 작업 샘플을 통합하여 11가지 의료 모달리티와 다양한 질병 시나리오를 포괄합니다.
직접 사용:https://go.hyper.ai/GvKlu
선택된 공개 튜토리얼
이번 주에는 3가지 유형의 고품질 공개 튜토리얼을 모아봤습니다.
*이미지 생성 및 편집 튜토리얼: 3
*3D 생성 튜토리얼: 2
* 오디오 생성 튜토리얼: 2
이미지 생성 및 편집 튜토리얼
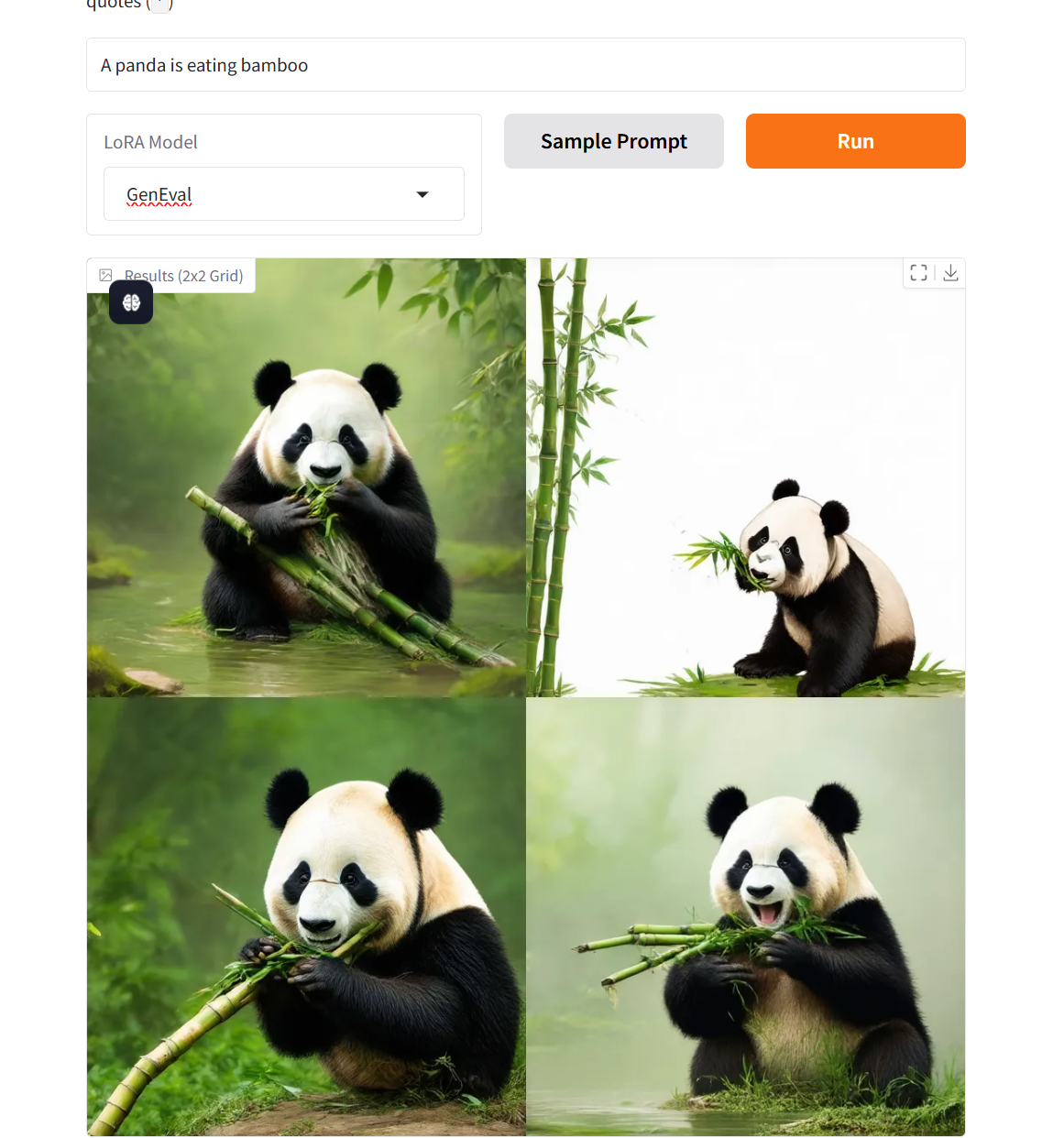
1. OmniGen2: 고급 멀티모달 생성 탐색
OmniGen2는 텍스트-이미지 생성, 이미지 편집, 컨텍스트 생성을 포함한 다중 생성 작업을 위한 통합 솔루션을 제공하는 것을 목표로 합니다. 비공유 매개변수와 별도의 이미지 토크나이저를 통해 OmniGen2는 VAE 입력을 재조정하지 않고도 기존 다중모달 이해 모델을 기반으로 구축할 수 있으며, 원본 텍스트 생성 기능을 그대로 유지합니다.
온라인으로 실행:https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev: 텍스트 기반 원클릭 이미지 편집
FLUX.1 Kontext의 이미지 편집은 광범위한 의미에서 이미지 편집으로, 로컬 이미지 편집(나머지 요소에 영향을 주지 않고 이미지의 특정 요소를 집중적으로 수정하는 것)을 지원할 뿐만 아니라 캐릭터 일관성(여러 장면과 환경에서 일관성을 유지하기 위해 참조 캐릭터나 객체와 같은 이미지의 고유한 요소를 유지하는 것)도 달성합니다.
온라인으로 실행:https://go.hyper.ai/PqRGn

3. Flow-GRPO 흐름 매칭 텍스트 그래프 모델 데모
이 모델은 온라인 강화 학습 프레임워크와 흐름 매칭 이론을 통합하는 데 앞장섰으며, GenEval 2025 벤치마크 테스트에서 획기적인 진전을 이루었습니다. SD 3.5 Medium 모델의 결합 생성 정확도는 벤치마크 값인 63%에서 95%로 뛰어올랐고, 생성 품질 평가 지수는 처음으로 GPT-4o를 넘어섰습니다.
온라인으로 실행:https://go.hyper.ai/v7xkq
3D 생성 튜토리얼
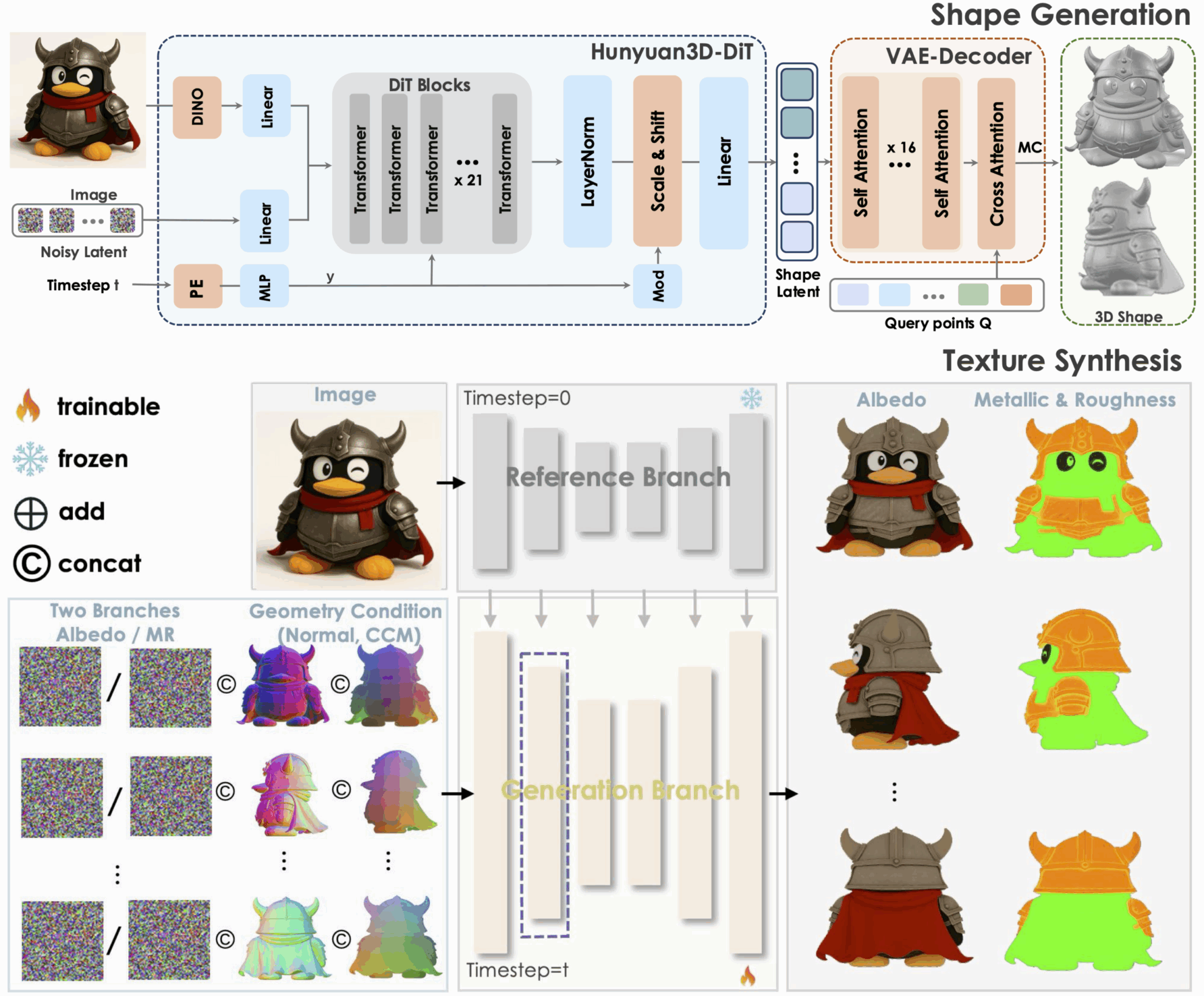
1. Hunyuan3D-2.1: 물리적 렌더링 텍스처를 지원하는 3D 생성 모델
Tencent Hunyuan3D-2.1은 산업용 오픈소스 3D 생성 모델이자 확장 가능한 3D 자산 생성 시스템입니다. 완전 오픈소스 프레임워크와 물리 기반 렌더링 텍스처 합성이라는 두 가지 핵심 혁신을 통해 최첨단 3D 생성 기술 개발을 촉진합니다. 동시에 데이터 처리, 학습 및 추론 코드 등을 완전히 개방하여 학술 연구를 위한 재현 가능한 기반을 제공하고 산업 구현을 위한 반복 개발 비용을 절감합니다.
온라인으로 실행:https://go.hyper.ai/0H91Z
2. Direct3D‑S2: 고해상도 3D 렌더링을 위한 프레임워크
Direct3D‑S2는 확산 변환기의 계산 효율을 크게 향상시키고 희소 볼륨 표현과 혁신적인 공간 희소 어텐션 메커니즘을 기반으로 학습 비용을 크게 절감하는 고해상도 3D 생성 프레임워크입니다. 이 프레임워크는 생성 품질과 효율성 면에서 기존 방식을 능가하며, 고해상도 3D 콘텐츠 제작을 위한 강력한 기술 지원을 제공합니다.
온라인으로 실행:https://go.hyper.ai/67LQM

오디오 생성 튜토리얼
1. PlayDiffusion: 오픈 소스 오디오 로컬 편집 모델
PlayDiffusion은 오디오를 개별 토큰 시퀀스로 인코딩하고, 수정이 필요한 부분을 마스크 처리하고, 확산 모델을 사용하여 업데이트된 텍스트를 바탕으로 마스크 처리된 영역의 노이즈를 제거하여 고품질 오디오 편집을 구현합니다. 맥락을 완벽하게 보존하고, 음성의 일관성과 자연스러움을 보장하며, 효율적인 텍스트-음성 합성을 지원하여 높은 시간적 일관성과 확장성을 제공합니다.
온라인으로 실행:https://go.hyper.ai/WTlI4
2. OuteTTS: 음성 생성 엔진
OuteTTS는 오픈 소스 텍스트-음성 합성 프로젝트입니다. 이 프로젝트의 핵심 혁신은 기존 TTS 시스템의 복잡한 어댑터나 외부 모듈에 의존하지 않고 순수 언어 모델링 방식을 사용하여 고품질 음성을 생성하는 것입니다. 주요 기능으로는 텍스트-음성 합성 및 음성 복제가 있습니다.
온라인으로 실행:https://go.hyper.ai/eQVHL
💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

이번 주 논문 추천
1. GLM-4.1V-Thinking: 확장 가능한 강화 학습을 통한 다재다능한 다중 모드 추론을 향해
본 논문에서는 일반적인 다중 모드 이해 및 추론 능력을 향상시키도록 설계된 시각 언어 모델(VLM)인 GLM-4.1V-Thinking을 제시합니다. 강화 학습과 커리큘럼 샘플링을 결합하여 모델의 잠재력을 최대한 활용하는 방법을 제안합니다. 이를 통해 STEM 문제 해결, 비디오 이해, 콘텐츠 인식, 프로그래밍, 상호 참조 해결, GUI 기반 에이전트, 장문 문서 이해 등 다양한 과제에서 종합적인 역량을 확보할 수 있습니다. GLM-4.1V-9B-Thinking은 동일한 크기의 오픈 소스 모델 중 최고 수준의 성능을 달성하며, 장문 문서 이해 및 STEM 추론과 같은 까다로운 과제에서도 GPT-4o와 같은 폐쇄형 소스 모델과 동등하거나 더 나은 성능을 보여줍니다.
논문 링크:https://go.hyper.ai/5UuYG
2. Ovis-U1 기술 보고서
본 논문에서는 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집을 통합하는 30억 개의 매개변수를 가진 통합 모델인 Ovis-U1을 소개합니다. Ovis 제품군을 기반으로 구축된 Ovis-U1은 확산 시각 디코더와 양방향 태그 정제기를 결합하여 이미지 생성 작업에서 GPT-4o와 같은 주요 모델과 견줄 만합니다. Ovis-U1은 OpenCompass 멀티모달 학술 벤치마크에서 69.6점을 기록하여 Ristretto-3B 및 SAIL-VL-1.5-2B와 같은 최신 모델을 능가합니다.
논문 링크:https://go.hyper.ai/7Q8JV
3. BlenderFusion: 3D 기반 시각적 편집 및 생성적 합성
본 논문에서는 객체, 카메라, 배경을 재조합하여 새로운 장면을 합성하는 생성적 시각 합성 프레임워크인 BlenderFusion을 제안합니다. 이 프레임워크는 레이어-편집-합성 파이프라인을 따릅니다. 즉, 시각 입력을 분할하여 편집 가능한 3D 엔티티로 변환하고, Blender의 3D 기반 컨트롤을 사용하여 편집한 후, 생성적 합성기를 사용하여 일관된 장면으로 융합합니다. 실험 결과, BlenderFusion은 복잡한 합성 장면 편집 작업에서 기존 방식보다 훨씬 뛰어난 성능을 보였습니다.
논문 링크:https://go.hyper.ai/YoirX
4. SciArena: 과학 문헌 과제의 기초 모델을 위한 개방형 평가 플랫폼
본 논문에서는 과학 문헌 과제에서 기반 모델을 평가하는 개방형 협업 플랫폼인 SciArena를 소개합니다. 기존의 과학 문헌 이해 및 종합 벤치마크와 달리, SciArena는 연구 커뮤니티와 직접 소통하며, Chatbot Arena와 유사한 평가 방식을 채택하여 커뮤니티 투표를 통해 모델을 비교합니다. 현재 이 플랫폼은 23개의 오픈 소스 및 자체 개발 기반 모델을 지원하고 있으며, 여러 과학 분야의 신뢰할 수 있는 연구자들로부터 13,000개 이상의 투표를 수집했습니다.
논문 링크:https://go.hyper.ai/oPbpP
5. SPIRAL: 제로섬 게임에서의 자기 플레이는 다중 에이전트 다중 턴 강화 학습을 통해 추론을 장려합니다.
본 논문에서는 모델이 지속적으로 개선되는 자기 자신과 여러 라운드의 제로섬 게임을 통해 학습하는 자가 플레이 프레임워크인 SPIRAL을 소개하며, 이를 통해 인간의 감독이 필요 없게 됩니다. 대규모 자가 플레이 학습을 가능하게 하기 위해, 연구진은 완전 온라인, 여러 라운드, 여러 에이전트 강화 학습 시스템을 구현하고, 다중 에이전트 학습을 안정화하기 위해 역할 조건부 이점 추정을 제안했습니다. SPIRAL을 이용한 제로섬 게임에 대한 자가 플레이 학습은 광범위하게 전이 가능한 추론 능력을 생성할 수 있습니다.
논문 링크:https://go.hyper.ai/n7J4m
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 메타물질 설계의 혁신! Meta AI와 다른 연구진은 위상 생성 및 성능 예측과 같은 작업의 통합 모델링을 최초로 구현하는 UNIMATE를 제안했습니다.
버지니아 공대와 메타 AI 연구팀은 혁신적인 모델 아키텍처를 통해 현재 AI 메타물질 설계의 주요 병목 현상을 해결하는 UNIMATE라는 통합 모델을 제안했습니다. 또한, 메타물질 설계의 세 가지 핵심 요소인 3차원 위상 구조, 밀도 조건, 기계적 특성에 대한 통합 모델링 및 협업 처리를 최초로 구현했습니다.
전체 보고서 보기:https://go.hyper.ai/1x8iJ
저장대학교는 중국 전자과학기술대학교 및 기타 기관의 팀들과 협력하여 HealthGPT 모델을 제안했습니다. 혁신적인 이기종 지식 적응 프레임워크를 통해 의료 다중 모드 이해 및 생성을 통합하는 최초의 대규모 시각 언어 모델을 성공적으로 구축하여 의료 AI 개발의 새로운 길을 열었습니다. 관련 연구 결과는 ICML 2025에 선정되었습니다.
전체 보고서 보기:https://go.hyper.ai/F7W6a
3. 단백질 구조 예측/기능 주석/상호작용 식별/주문형 설계, 중국 해양 대학 장수강 팀은 단백질 지능 컴퓨팅의 핵심 과제를 직접 해결합니다.
중국해양대학교 컴퓨터공학과 장수강 부교수는 "단백질 지능형 컴퓨팅 시스템의 구축 및 응용"이라는 제목의 강연에서 지능형 컴퓨팅 기술이 가져온 혁신적인 발전에 대해 체계적으로 설명했습니다. 특히 단백질 연구 분야의 기존 과제와 기능 주석, 상호작용 식별, 설계 최적화 분야에서 연구팀이 달성한 성과를 중점적으로 다뤘습니다. 본 논문은 장수강 부교수의 강연 내용을 요약한 것입니다.
전체 보고서 보기:https://go.hyper.ai/rTgSi
4. ICML 2025 | 뮌헨 공과대학교 및 기타 연구진은 SD3 기반 위성 이미지 생성 방법을 개발하여 현재 가장 큰 원격 감지 데이터 세트를 구축했습니다.
독일 뮌헨 공과대학교와 스위스 취리히 대학교 연구팀은 지리적 기후 단서를 기반으로 하는 Stable Diffusion 3(SD3)을 사용하여 위성 이미지를 생성하는 새로운 방법을 제안하고, 현재까지 가장 크고 포괄적인 원격 탐사 데이터셋인 EcoMapper를 개발했습니다. 이 데이터셋은 Sentinel-2를 통해 전 세계 104,424개 지점에서 수집된 290만 개 이상의 RGB 위성 이미지 데이터를 포함하고 있으며, 15가지 토지 피복 유형과 해당 기후 기록을 포함하고 있습니다. 이를 통해 정밀하게 조정된 SD3 모델을 사용하는 두 가지 위성 이미지 생성 방법의 기반을 마련했습니다.
전체 보고서 보기:https://go.hyper.ai/1zpeD
5. CASP가 중단될 수도 있습니다! NIH의 자금 지원 중단으로 단백질 구조 예측 경진대회의 미래가 불투명해졌습니다.
과학 전문지 사이언스는 국립보건원(NIH)의 CASP에 대한 자금 지원이 이미 소진되었으며, 프로젝트 자금을 관리하는 캘리포니아대학교 데이비스 캠퍼스(UC 데이비스)가 긴급 지원을 제공했지만, 이 역시 8월 8일에 소진되어 CASP가 중단 위기에 직면했다고 단독 보도했습니다.
전체 보고서 보기:https://go.hyper.ai/3kTMU
인기 백과사전 기사
1. 칸
2. 시그모이드 함수
3. 인간-기계 루프 HITL
4. 검색 향상으로 RAG 생성
5. 보강재 미세 조정
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
정상회담 7월 마감일
7월 11일 7:59:59 포플 2026
7월 15일 7:59:59 소다 2026
7월 18일 7:59:59 시그모드 2026
7월 19일 7:59:59 ICSE 2026
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!