Command Palette
Search for a command to run...
비용이 대폭 절감됩니다! Distill-Any-Depth는 고정밀 깊이 추정을 달성하며, CVPR 2025에 선정되었습니다! Real-IADD는 산업 감지 분야의 새로운 지평을 엽니다.

단안 측정 깊이 추정은 단일 RGB 이미지로부터 절대 깊이를 예측하는 컴퓨터 비전 기술입니다. 이 기술은 자율주행, 증강 현실, 로봇 공학, 3D 장면 이해 등 다양한 분야에서 폭넓게 활용됩니다.
제로샷 단안 깊이 추정(MDE)은 깊이 분포를 통합하고 대규모 미레이블 데이터를 활용하여 일반화 성능을 크게 향상시킵니다. 그러나 기존 방법은 모든 깊이 값을 균일하게 처리하기 때문에 의사 레이블의 노이즈가 증폭되고 증류 효과가 감소할 수 있습니다. 이를 바탕으로 저장 이공대학교를 비롯한 여러 대학에서 Distill-Any-Depth를 출시했습니다.
Distill-Any-Depth는 증류 알고리즘을 통해 여러 오픈 소스 모델의 장점을 통합하고, 레이블이 지정되지 않은 소량의 데이터만으로 고정밀 깊이 추정을 달성합니다.수백만 개의 주석이 필요한 기존 방법과 비교했을 때, 이 프로젝트에서는 레이블이 지정되지 않은 이미지가 20,000개만 필요하여 데이터 주석 비용이 크게 줄었습니다.
현재 HyperAI에서 "Distill-Any-Depth: Monocular Depth Estimator" 튜토리얼을 출시했습니다. 지금 바로 체험해 보세요~
Distill-Any-Depth: 단안경 깊이 추정기
온라인 사용:https://go.hyper.ai/DNSf5
6월 16일부터 6월 20일까지 hyper.ai 공식 웹사이트가 업데이트됩니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼: 14개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
* 7월 마감일 상위 컨퍼런스: 5개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
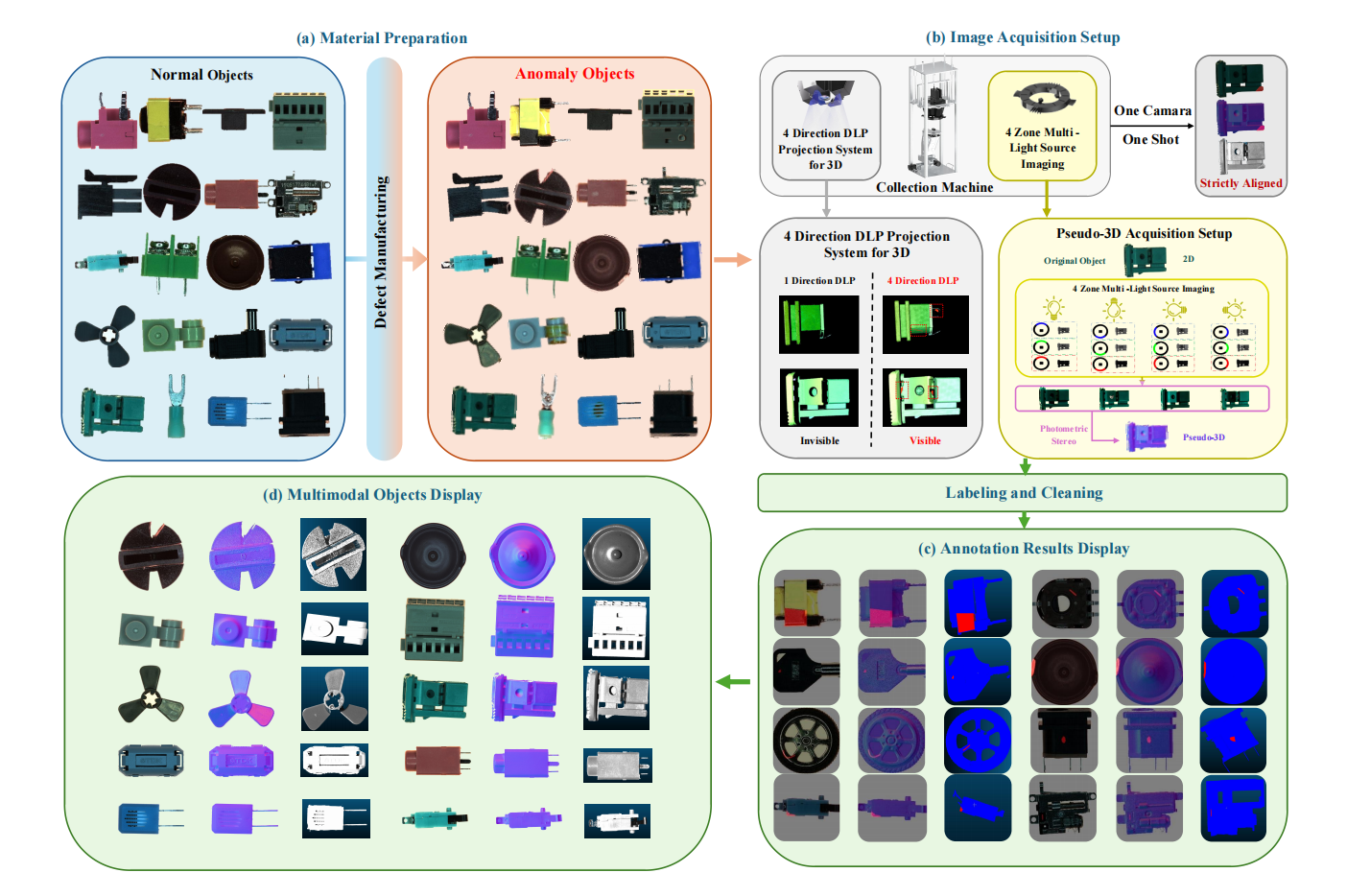
1. 실제 IAD D³ 산업 이상 탐지 데이터 세트
Real-IAD D³는 고정밀 멀티모달 데이터 세트이며, 관련 논문이 최고의 컴퓨터 비전 컨퍼런스인 CVPR 2025에 포함되었습니다. 이 데이터 세트에는 20개의 산업 제품 범주, 69개의 결함 유형, 총 8,450개의 샘플이 포함되어 있으며, 이 중 5,000개가 정상 샘플이고 3,450개가 비정상 샘플입니다.
직접 사용:https://go.hyper.ai/i4T8m
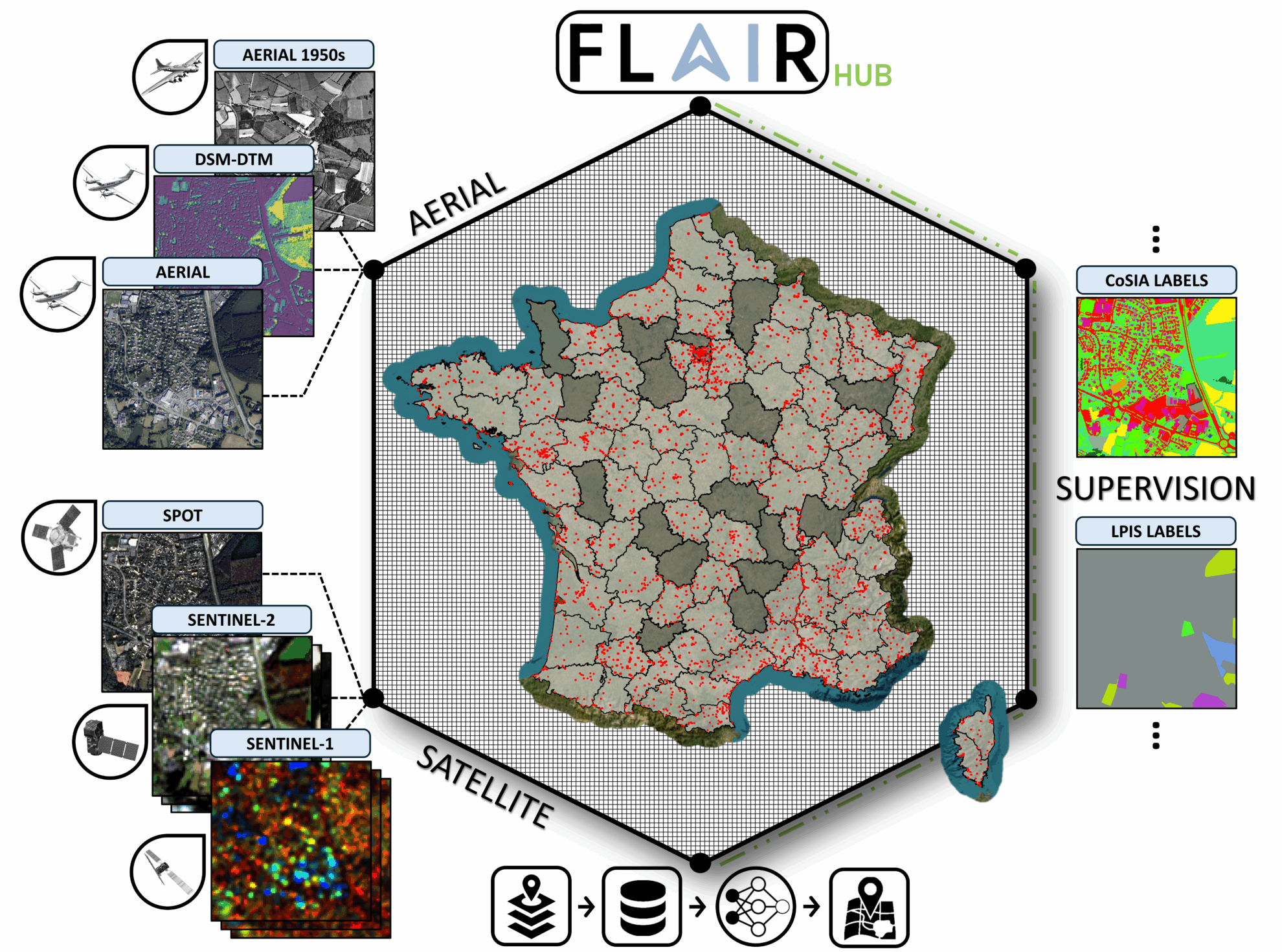
2. FLAIR HUB 다중 센서 프랑스 토지 데이터 세트
FLAIR-HUB는 19개 토지 피복 등급과 23개 작물 범주를 포함하여 프랑스의 다양한 생태 기후와 풍경 2,500km2 이상을 포괄하며, 630억 개의 수동 주석이 달린 픽셀을 포함하고 있으며, 보완적인 데이터 소스를 통합합니다.
직접 사용:https://go.hyper.ai/4VvCI
3. MathFusionQA 수학적 추론 데이터 세트
MathFusionQA는 다단계 추론 및 수학 문제 해결에 중점을 둡니다. 이 데이터 세트에는 산술 연산, 대수 방정식, 기하 응용, 논리적 추론 등 다양한 유형의 문제를 다루는 59,000개의 고품질 수학 질의응답 샘플이 포함되어 있습니다. 일상적인 응용, 학업 훈련 등 다양한 문제를 다루는 풍부한 문제 시나리오를 통해 대규모 언어 모델(LLM)의 수학 문제 해결 능력 향상을 목표로 합니다.
직접 사용:https://go.hyper.ai/uGR9C
4. 기관 도서 1.0 도서 데이터 세트
Institutional Books는 254개 언어로 출판된 983,004권의 퍼블릭 도메인 도서로 구성되어 있으며, 주로 19세기와 20세기에 출판되었습니다. 이 데이터세트는 2,420억 개의 토큰과 3억 8,600만 페이지의 텍스트를 포함하고 있으며, 원본 및 후처리된 OCR 내보내기 형식으로 제공됩니다.
직접 사용:https://go.hyper.ai/ZsSI7
5. ReasonMed 의학적 추론 데이터 세트
ReasonMed는 최대 규모의 오픈소스 의료 추론 데이터셋으로, 의료 질의응답 및 텍스트 생성 등의 작업을 위한 모델을 학습하고 평가하도록 설계되었습니다. 이 데이터셋에는 임상 지식, 해부학, 유전학 등 다양한 분야를 아우르는 37만 개의 고품질 질의응답 예시가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/DwGmH
6. Miriad-5.8M 의학 질문 답변 데이터 세트
이 데이터 세트에는 기초 과학부터 임상 실무까지 모든 측면을 포괄하는 582만 개의 의학 질의응답 쌍이 포함되어 있습니다. MIRIAD는 RAG, 의료 검색, 환각 감지, 지시 조정 등 다양한 후속 작업을 지원하기 위해 체계적이고 고품질의 질의응답 쌍을 제공합니다.
직접 사용:https://go.hyper.ai/Xw8Ph
7. Common Corpus 대규모 오픈 텍스트 데이터 세트
이 데이터 세트는 현재 가장 큰 오픈 라이선스 텍스트 데이터 세트로, 2조 개의 토큰을 포함하고 있으며, 책, 과학 문헌, 코드, 법률 문서 등 다양한 분야의 콘텐츠를 포괄합니다. 주요 언어는 영어와 프랑스어이며, 100억 개가 넘는 토큰을 포함하는 8개 언어(독일어/스페인어/이탈리아어 등)와 10억 개가 넘는 토큰을 포함하는 33개 언어도 포함되어 있습니다.
직접 사용:https://go.hyper.ai/PnbfK
8. HLE 인간 질문 추론 벤치마크 데이터 세트
HLE는 인간 지식의 경계를 포괄하는 최고의 폐쇄형 평가 시스템 구축을 목표로 합니다. 이 데이터셋에는 수학, 인문학, 자연과학 등 수십 가지 학문 분야를 아우르는 2,500개의 문항이 포함되어 있으며, 객관식 문제와 자동 채점에 적합한 단답형 문제도 포함되어 있습니다.
직접 사용:https://go.hyper.ai/Lq7mE
9. MedCaseReasoning 의료 사례 추론 데이터 세트
MedCaseReasoning은 내과, 신경과, 감염성 질환, 심장학과 등 다양한 분야를 아우르는 13,000건의 사례를 포함하고 있습니다. 이 데이터셋은 질병 진단, 감별 분석, 치료 결정과 같은 핵심 업무를 포함하여 다전문 임상 사례의 전체 진단 및 치료 과정을 통합하여 의료용 대규모 언어 모델의 추론 능력 평가를 위한 표준화된 리소스를 제공하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/4vqwo
10. FineHARD 이미지-텍스트 정렬 데이터 세트
FineHARD는 오픈 소스 고품질 이미지-텍스트 정렬 데이터셋입니다. 이 데이터셋은 1,200만 개의 이미지와 그에 상응하는 장문 및 간략한 설명 텍스트를 포함하고 있으며, 4,000만 개의 경계 상자를 포함하는 확장성과 정밀성이 특징입니다.
직접 사용:https://go.hyper.ai/L2TOZ
선택된 공개 튜토리얼
이번 주에는 고품질 공개 튜토리얼을 4가지 범주로 요약했습니다.
*대규모 모델 배포 튜토리얼: 5
*멀티모달 처리 튜토리얼: 4
*3D 재구성 튜토리얼: 3
*OCR 인식 튜토리얼: 2
대규모 모델 배포지도 시간
1. vLLM+Open WebUI 배포 KernelLLM-8B
KernelLLM은 PyTorch 모듈을 효율적인 Triton 커널 코드로 자동 변환하여 고성능 GPU 프로그래밍 프로세스를 간소화하고 가속화하는 것을 목표로 합니다. 이 모델은 Llama 3.1 Instruct 아키텍처를 기반으로 하며, 80억 개의 매개변수를 포함하고 효율적인 Triton 커널 구현을 생성하는 데 중점을 둡니다.
온라인으로 실행:https://go.hyper.ai/DfoWo
2. vLLM+Open WebUI 배포 MiniCPM4-8B
MiniCPM 4.0은 희소 구조, 양자화 압축, 효율적인 추론 프레임워크 등의 기술을 통해 낮은 컴퓨팅 비용으로 고성능 추론을 구현합니다. 특히 장문 텍스트 처리, 개인정보 보호가 중요한 시나리오, 그리고 엣지 컴퓨팅 장치 구축에 적합합니다. 긴 시퀀스를 처리할 때 이 모델은 Qwen3-8B보다 훨씬 빠른 처리 속도를 보여줍니다.
온라인으로 실행:https://go.hyper.ai/kcANp
3. vLLM+Open WebUI 배포 FairyR1-14B-미리보기
FairyR1-14B-Preview는 수학 및 코딩 작업에 중점을 둡니다. 이 모델은 DeepSeek-R1-Distill-Qwen-32B 기반 모델을 기반으로 하며, 미세 조정 및 모델 병합 기술을 결합하여 구축되었습니다.
온라인으로 실행:https://go.hyper.ai/8jwGm
4. Qwen3-Embedding 시리즈 모델 비교 평가 튜토리얼
Qwen3 임베딩 제품군은 텍스트 검색, 코드 검색, 텍스트 분류, 텍스트 클러스터링, 이중 텍스트 마이닝을 포함한 다양한 텍스트 임베딩 및 순위 지정 작업에서 상당한 발전을 나타냅니다.
이 튜토리얼을 통해 임베디드 모델과 재정렬 모델의 핵심 개념을 체계적으로 이해하고, 실제 시나리오에서 이를 선택하고 적용하는 방법을 배울 수 있습니다.
온라인으로 실행:https://go.hyper.ai/YtMdH
5. vLLM+Open WebUI 배포 Devstral-Small-2505
Devstral은 코드 베이스 탐색, 여러 파일 편집, 소프트웨어 엔지니어링 에이전트 구동을 위한 도구 활용에 탁월합니다. 이 모델은 SWE-bench에서 좋은 성능을 보이며 벤치마크에서 1위를 차지한 오픈소스 모델이 되었습니다.
온라인으로 실행:https://go.hyper.ai/mnGzy
멀티모달 처리 튜토리얼
1. VideoLLaMA3-7B의 원클릭 배포
VideoLLaMA3는 이미지 및 비디오 이해 작업에 중점을 둔 오픈 소스 멀티모달 기본 모델입니다. 비전 중심 아키텍처 설계와 고품질 데이터 엔지니어링을 통해 비디오 이해의 정확도와 효율성을 크게 향상시킵니다.
이 튜토리얼에서는 단일 RTX 4090 컴퓨팅 리소스를 사용하고 VideoLLaMA3-7B-Image 모델을 배포하여 비디오 이해와 이미지 이해의 두 가지 예를 제공합니다.
온라인으로 실행:https://go.hyper.ai/t2z4d
2. Step1X-Edit: 이미지 편집 도구
Step1X-Edit은 정밀한 의미 분석, 아이덴티티 일관성 유지, 그리고 고정밀 영역 단위 제어라는 세 가지 핵심 기능을 제공합니다. 텍스트 교체, 스타일 변환, 소재 변형, 문자 보정 등 11가지 유형의 고빈도 이미지 편집 작업을 지원합니다.
온라인으로 실행:https://go.hyper.ai/MdDTI

3. Chain-of-Zoom: 초고해상도 이미지 디테일 확대 데모
체인 오브 줌(Chain-of-Zoom)은 최신 단일 이미지 초고해상도(SISR) 모델이 해당 범위를 크게 초과하는 확대/축소를 시도할 때 실패하는 문제를 해결하는 체인 줌(COZ) 프레임워크입니다. COZ 프레임워크에 캡슐화된 표준 4배 확산 초고해상도(SR) 모델은 높은 지각 품질과 충실도를 유지하면서 256배 이상의 확대/축소를 달성할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/7Lixx

4. Sa2VA: 이미지와 비디오에 대한 고밀도 지각적 이해를 향하여
Sa2VA는 이미지와 비디오에 대한 고밀도 지각 이해를 위한 최초의 통합 모델입니다. 특정 모달리티와 작업에 제한되는 기존의 다중 모달 대규모 언어 모델과 달리, Sa2VA는 최소한의 단일 미세 조정만으로 참조 분할 및 대화를 포함한 광범위한 이미지 및 비디오 작업을 지원합니다.
온라인으로 실행:https://go.hyper.ai/tj2bX
3D 재구성 튜토리얼
1. Distill-Any-Depth: 단안경 깊이 추정기
이 프로젝트는 증류 알고리즘을 통해 여러 오픈 소스 모델의 장점을 통합하여, 레이블이 지정되지 않은 소량의 데이터만으로 고정밀 깊이 추정을 달성하고, 현재의 SOTA(최신 기술) 성능을 새롭게 구현합니다.
온라인으로 실행:https://go.hyper.ai/DNSf5

2. VGGT: 일반 3D 비전 모델
VGGT는 하나, 몇 개, 또는 수백 개의 뷰에서 외부 및 내부 카메라 매개변수, 포인트 맵, 깊이 맵, 3D 포인트 궤적을 포함한 장면의 모든 주요 3D 속성을 몇 초 만에 직접 추론하는 피드포워드 신경망입니다. 또한 간단하고 효율적이어서 1초 이내에 재구성을 완료하며, 시각적 기하 최적화 기법을 사용한 후처리가 필요한 다른 방법들보다 성능이 뛰어납니다.
온라인으로 실행:https://go.hyper.ai/e8xzG
3. UniDepthV2: 범용 단안경 측정 깊이 추정
UniDepthV2는 단일 이미지만으로 여러 도메인에 걸쳐 메트릭 3D 장면을 재구성할 수 있습니다. 기존 MMDE 패러다임과 달리, UniDepthV2는 추론 시점에 추가 정보 없이 입력 이미지로부터 메트릭 3D 점을 직접 예측하여 일반적이고 유연한 MMDE 솔루션을 구현하고자 노력합니다.
온라인으로 실행:https://go.hyper.ai/JdgZC
OCR 인식 튜토리얼
1. MonkeyOCR: 구조-인식-관계 삼중 패러다임 기반 문서 분석
MonkeyOCR은 비정형 문서 콘텐츠를 정형화된 정보로 효율적으로 변환하는 기능을 제공합니다. 이 모델은 학술 논문, 교과서, 신문 등 다양한 문서 유형을 지원하고 여러 언어에 적용 가능하여 문서 디지털화 및 자동화 처리를 강력하게 지원합니다.
온라인으로 실행:https://go.hyper.ai/s9GE2
2. Nanonets-OCR-s: 문서 정보 추출 및 벤치마킹 도구
Nanonets-OCR은 수학 공식, 이미지, 서명, 워터마크, 체크박스, 표 등 문서의 다양한 요소를 인식하고 이를 구조화된 마크다운 형식으로 정리할 수 있습니다. 이러한 기능은 학술 논문, 법률 문서 또는 비즈니스 보고서와 같은 복잡한 문서 처리에 매우 유용합니다.
이 튜토리얼에서는 RTX 4090 카드 하나를 리소스로 사용합니다. 이 튜토리얼에는 문서에서 정보와 이미지를 추출하는 기능과 PDF를 마크다운으로 변환하는 기능 두 가지가 포함되어 있습니다.
온라인으로 실행:https://go.hyper.ai/1uPym
💡Stable Diffusion 튜토리얼 교환 그룹도 개설했습니다. Neural Star(WeChat ID: Hyperai01)를 추가하고 [SD 튜토리얼]을 댓글로 남겨주세요. 다양한 기술적인 문제에 대해 논의하고 응용 결과를 공유하는 그룹에 참여하실 수 있습니다.
이번 주 논문 추천
1.FocalAD: 엔드투엔드 자율주행을 위한 로컬 모션 플래닝
본 논문은 중요한 지역 이웃에 초점을 맞추고 지역 동작 표현을 향상시켜 계획을 최적화하는 새로운 엔드투엔드 자율주행 프레임워크인 FocalAD를 제안합니다. 구체적으로 FocalAD는 자율-지역-에이전트 상호작용 모듈(ELAI)과 초점-지역-에이전트 손실 모듈(FLA Loss)의 두 가지 핵심 모듈을 포함합니다.
논문 링크:https://go.hyper.ai/vjBZy
2. Biomni: 범용 생물의학 AI 에이전트
Biomni는 다양한 생물의학 하위 분야에 걸쳐 광범위한 연구 과제를 자율적으로 수행하도록 설계된 범용 생물의학 AI 비서입니다. 생물의학 활동 공간을 체계적으로 매핑하기 위해 Biomni는 활동 탐색 에이전트를 활용하여 25개 생물의학 분야에 걸쳐 수만 건의 논문에서 핵심 도구, 데이터베이스 및 프로토콜을 마이닝하여 최초의 통합 에이전트 환경을 구축합니다.
논문 링크:https://go.hyper.ai/zTFzy
3.SeerAttention-R: 장기 추론을 위한 희소 주의 적응
본 논문에서는 추론 모델의 장시간 디코딩을 위해 설계된 희소 어텐션 프레임워크인 SeerAttention-R을 소개합니다. 이 프레임워크는 SeerAttention을 확장하고, 자가 증류 게이팅 메커니즘을 통해 어텐션 희소성을 학습하는 설계를 유지하는 동시에, 자기 회귀 디코딩에 적합하도록 쿼리 풀링을 제거합니다. 가벼운 삽입 게이팅 메커니즘을 통해 SeerAttention-R은 유연하며, 기존 매개변수를 수정하지 않고도 기존 사전 학습된 모델에 쉽게 통합할 수 있습니다.
논문 링크:https://go.hyper.ai/8XHpf
4.확산 모델을 사용한 텍스트 인식 이미지 복원
본 논문에서는 다중 작업 확산 프레임워크인 TeReDiff를 제안합니다. TeReDiff는 확산 모델의 내부 기능을 텍스트 검출 모듈에 통합하여 두 구성 요소 모두 공동 학습의 이점을 누릴 수 있도록 합니다. 이를 통해 후속 노이즈 제거 단계에서 단서로 사용할 수 있는 풍부한 텍스트 표현을 추출할 수 있습니다.
논문 링크:https://go.hyper.ai/3YDSf
5.전기 응답의 통합 미분 학습
본 논문은 일반화 퍼텐셜 함수와 인가된 외부 필드 간의 정확한 미분 관계로부터 응답 특성을 도출하는 등변 머신 러닝 프레임워크를 구현합니다. 이 방법은 전기장에 대한 응답에 초점을 맞춰, 정확한 물리적 제약 조건, 대칭성 및 보존 법칙을 모두 적용하는 통합 모델에서 전기 엔탈피, 힘, 분극, 보른 전하 및 분극률을 예측합니다.
논문 링크:https://go.hyper.ai/AO8dM
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 석영에서 강유전체까지, 하버드 대학은 재료의 대규모 전기장 시뮬레이션을 가속화하기 위한 등가 머신 러닝 프레임워크를 제안했습니다.
하버드 대학교와 보쉬의 공동 연구팀은 혁신적인 해결책을 제시하고 전기적 반응을 위한 통합 미분 가능 학습 프레임워크를 개발했습니다. 이 프레임워크는 단일 머신 러닝 모델에서 일반화된 위치 에너지와 외부 자극에 대한 반응 함수를 동시에 학습할 수 있어, 기존 독립 모델의 고유한 단점을 극복하고 결정, 무질서 및 액체 물질의 유전 및 강유전성 특성에 대한 고정밀 연구를 위한 새로운 길을 열었습니다.
전체 보고서 보기:https://go.hyper.ai/d3cAc
HyperAI는 7월 5일 베이징 중관촌에서 제7회 Meet AI Compiler Technology Salon을 개최합니다. 이 행사에서는 AMD, Muxi Integrated Circuit, ByteDance, 베이징 대학의 고위 전문가 4명을 초대하여 저수준 컴파일부터 상위 수준 애플리케이션까지 다양한 관점에서 AI 컴파일러의 최첨단 기술을 살펴보았습니다.
전체 보고서 보기:https://go.hyper.ai/elNCA
3. 다양한 소스의 식물 전사체 데이터를 통합하여 산둥이공대학 등은 최대 96%의 종간 lncRNA 예측 정확도를 갖는 PlantLncBoost 모델을 구축했습니다.
산둥 이공대학은 베이징 임업대학, 광둥 농업 과학 아카데미, 브라질 상파울루 대학, 영국의 로잘린드 프랭클린 의과대학, 스웨덴 우메오 대학의 연구팀과 함께 PlantLncBoost 모델을 공동으로 구축하여 식물 lncRNA 식별의 일반화 문제에 대한 체계적인 솔루션을 제공했습니다.
전체 보고서 보기:https://go.hyper.ai/M88RZ
4. MIT 연구팀은 대형 모델을 활용해 시멘트 클링커 대체 소재 25종을 선별했으며, 이는 온실가스 배출량을 12억 톤 줄이는 것과 맞먹는 수준이다.
MIT의 재료과학 및 공학과는 여러 부서로 구성된 팀과 협력하여 대규모 언어 모델(LLM)과 다중 헤드 신경망 아키텍처를 기반으로 하는 새로운 데이터 기반 접근 방식을 개발하여 시멘트 대체 재료의 반응성을 대규모로 예측하고 검토했습니다.
전체 보고서 보기:https://go.hyper.ai/rtvf4
더 많은 사용자에게 학계 인공지능 분야의 최신 동향을 알리기 위해 HyperAI 공식 웹사이트(hyper.ai)에서 "최신 논문" 섹션을 출시했습니다. 이 섹션에서는 머신 러닝, 계산 언어, 컴퓨터 비전 및 패턴 인식, 인간-컴퓨터 상호 작용 등 다양한 분야를 포괄하는 최첨단 AI 연구 논문을 매일 업데이트합니다.
전체 보고서 보기: https://go.hyper.ai/ttAl7
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
정상회담 7월 마감일
7월 2일 7:59:59 VLDB 2026
7월 11일 7:59:59 포플 2026
7월 15일 7:59:59 소다 2026
7월 18일 7:59:59 시그모드 2026
7월 19일 7:59:59 ICSE 2026
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!