Command Palette
Search for a command to run...
온라인 튜토리얼: TTS 모델 SOTA 새로 고침, OpenAudio S1은 200만 시간의 오디오 데이터를 기반으로 훈련되어 감정과 음성 세부 사항을 심층적으로 이해합니다.

최근 몇 년 동안 TTS(텍스트 음성 변환) 모델은 연쇄 음성 합성에서 통계적 매개변수 합성, 그리고 신경망 TTS(Neural TTS)로 이어지는 반복적인 발전을 거쳤습니다. 기술적인 측면에서는 엔드 투 엔드 및 모듈 융합 추세를 보였으며, 응용 수준에서는 다국어 지원, 높은 자연스러움, 그리고 풍부한 감정 변화를 제공하는 향상된 효과를 보여주었습니다.
TTS 모델은 가상 음성 비서, 디지털 인간, AI 더빙, 지능형 고객 서비스 등 다양한 분야에서 널리 활용되고 있으며, 업계에서는 실시간 피드백에 대한 수요가 점차 증가하고 있습니다.그 다음에는 추론 속도와 모델 매개변수 간의 균형이 필요합니다.후자는 어느 정도 TTS 모델의 배포 비용과 적용 시나리오를 제한합니다.
이를 고려하여,Fish Audio는 새로운 오픈 소스 TTS 모델인 OpenAudio S1을 출시했습니다.OpenAudio-S1과 OpenAudio-S1-mini 두 가지 버전이 포함되어 있습니다. 공식 문서에 따르면, OpenAudio S1은 200만 시간 이상의 대규모 오디오 데이터셋을 학습했습니다. 연구팀은 모델 매개변수를 40억 개로 확장하고 자체 개발한 보상 모델링 메커니즘을 도입했습니다. 동시에, GRPO(인간 피드백 기반 강화 학습) 학습 방식인 RLHF(강화 학습)도 적용했습니다.
이를 바탕으로 OpenAudio S1은 다른 대부분 모델이 의미론적 모델만을 사용할 때 발생하는 정보 손실로 인한 아티팩트와 잘못된 어휘를 성공적으로 제거하여 오디오 품질, 감정 표현, 화자 유사성 측면에서 기존 모델을 크게 앞지르고 있습니다.단 10~30초 분량의 음성 샘플 입력으로 고품질 TTS 출력을 생성할 수 있습니다.현재 HuggingFace TTS-Arena-V2 인간의 주관적 평가 순위에서 1위를 차지했으며, Seed-TTS Eval에서 약 0.4%의 낮은 CER(문자 오류율)과 약 0.8%의 WER(단어 오류율)을 달성했습니다.
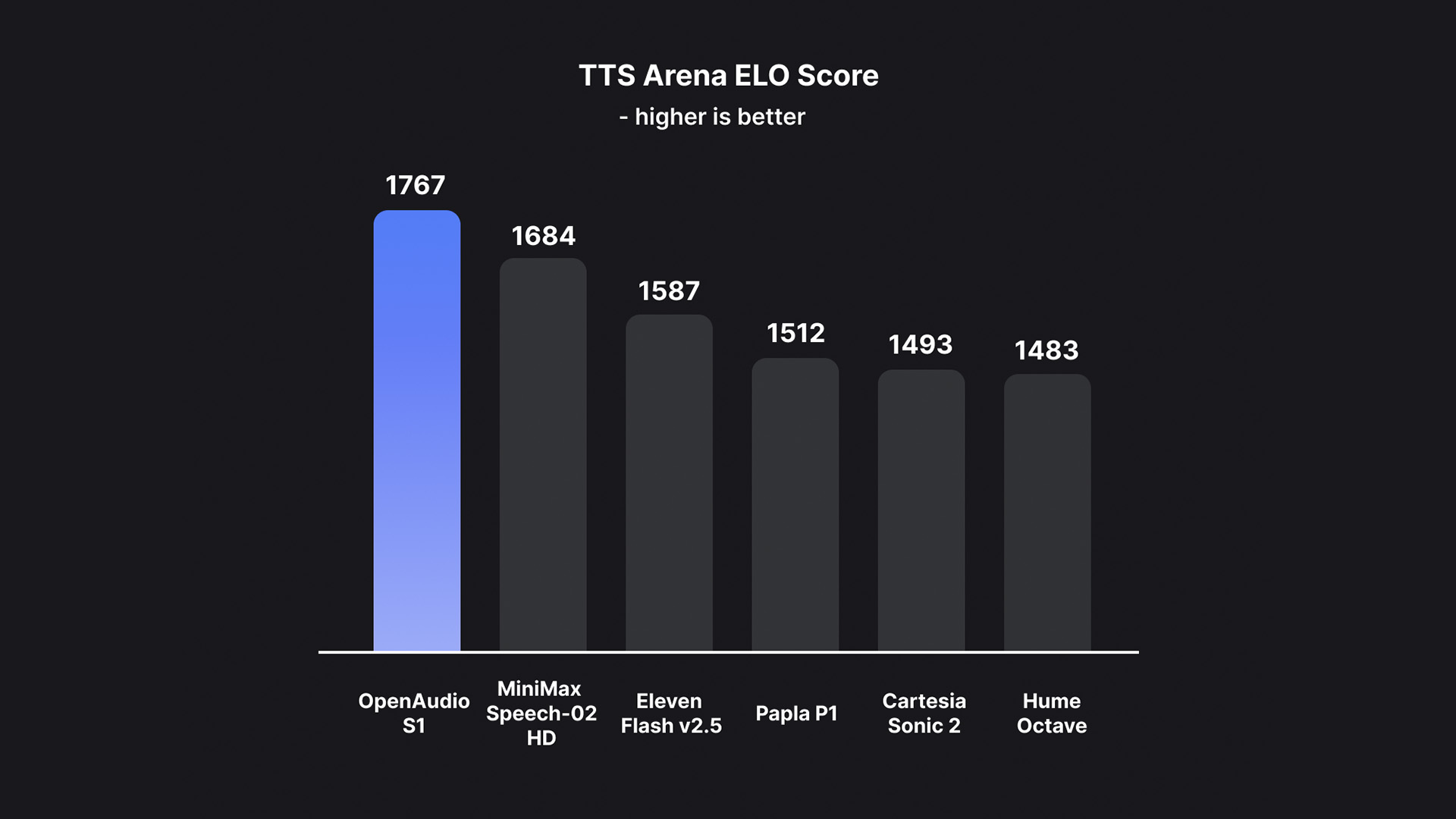
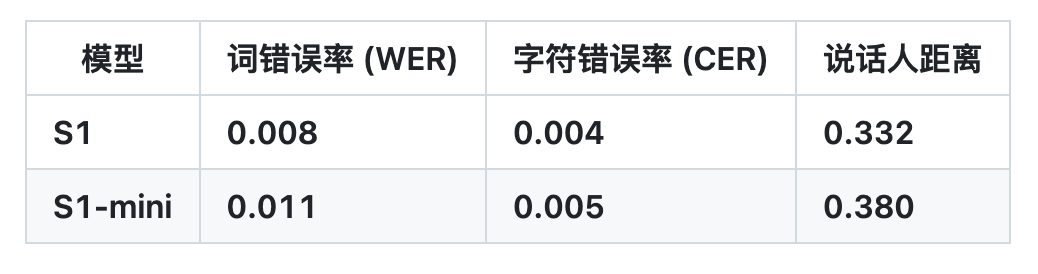
팀에 따르면,OpenAudio S1을 정말 독특하게 만드는 것은 인간의 감정과 말의 세부 사항을 깊이 이해하고 표현할 수 있는 능력입니다.합성 음성의 정밀한 제어를 위한 풍부한 태그 세트를 지원합니다. TTS 모델이 지시를 따르도록 훈련하기 위해, 연구팀은 감정, 억양, 화자 정보 등이 포함된 오디오에 자막을 생성할 수 있는 음성-텍스트 변환 모델(곧 출시 예정)도 구축했습니다. OpenAudio S1을 훈련하기 위해 이 모델을 기반으로 10만 시간 이상의 오디오에 무작위로 주석을 달았습니다.
이러한 이유로 OpenAudio S1은 음성 합성을 향상시키기 위해 다양한 감정, 억양 및 특수 마커를 지원합니다. 분노, 놀람, 행복과 같은 기본 감정 외에도 경멸, 비꼬는 말, 망설임과 같은 고급 감정도 지원합니다. 억양 측면에서는 속삭임, 비명, 흐느낌 등을 지원합니다. 언어 측면에서는 현재 영어, 중국어, 일본어가 지원됩니다.
더욱 언급할 가치가 있는 것은 성능과 배포 비용 간의 균형 측면에서이 팀은 이것이 100만 바이트당 15달러에 불과한 최초의 SOTA 모델이라고 주장합니다($15/100만 바이트, 시간당 약 0.8달러).
OpenAudio S1의 강력한 성능을 모든 분들이 더욱 빠르게 경험하실 수 있도록,HyperAI 공식 웹사이트(hyper.ai)의 튜토리얼 섹션에서 "OpenAudio-s1-mini: 효율적인 텍스트-음성 생성 도구"가 출시되었습니다.
튜토리얼 링크:https://go.hyper.ai/rVvkS
신규 가입 사용자를 위해 RTX 4090 리소스 무료 사용 혜택도 준비했습니다. 아래 초대 코드를 사용하여 가입하시면 고품질 TTS 모델을 무료로 체험하실 수 있습니다.
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_NR0n
데모 실행
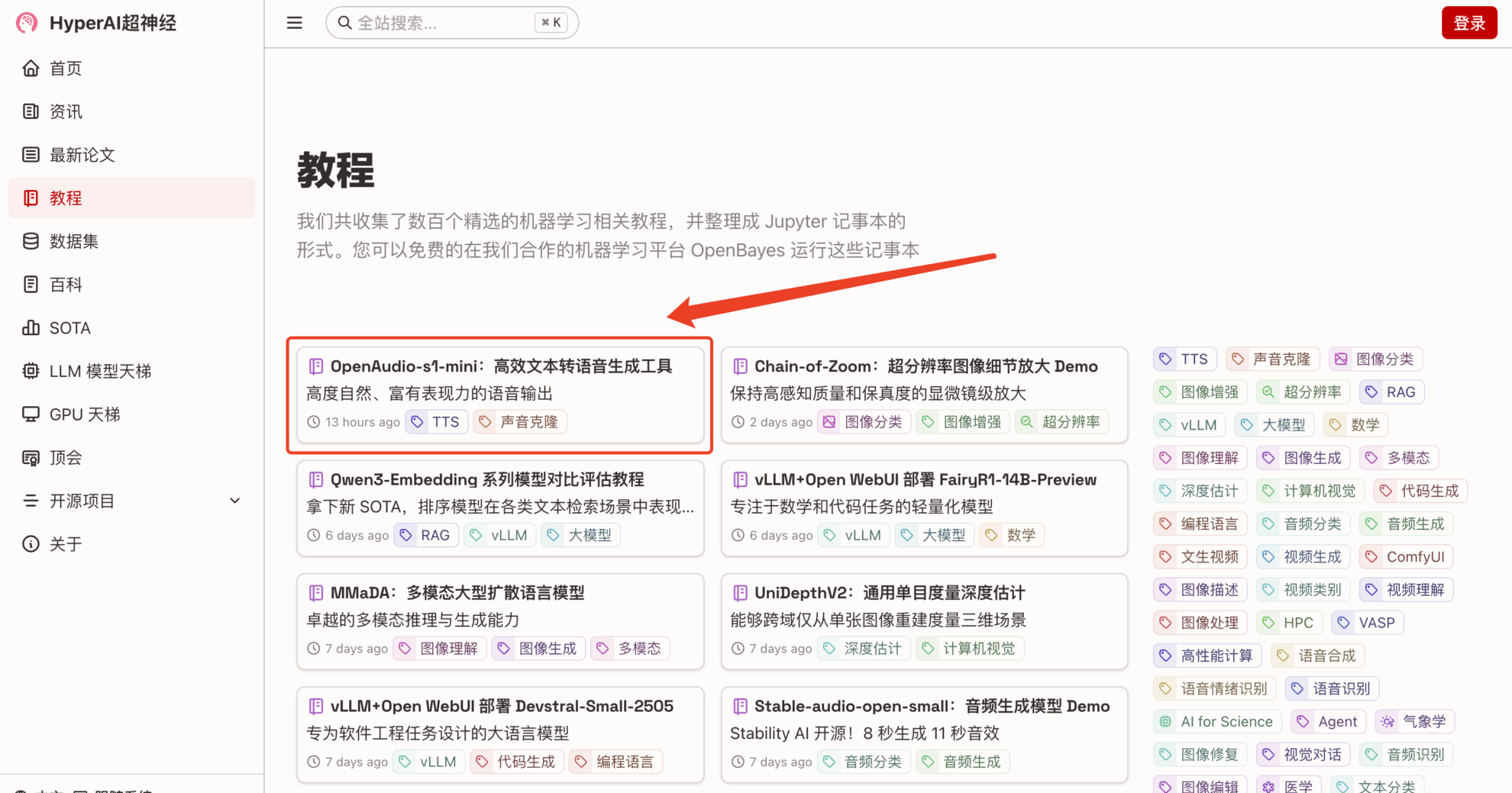
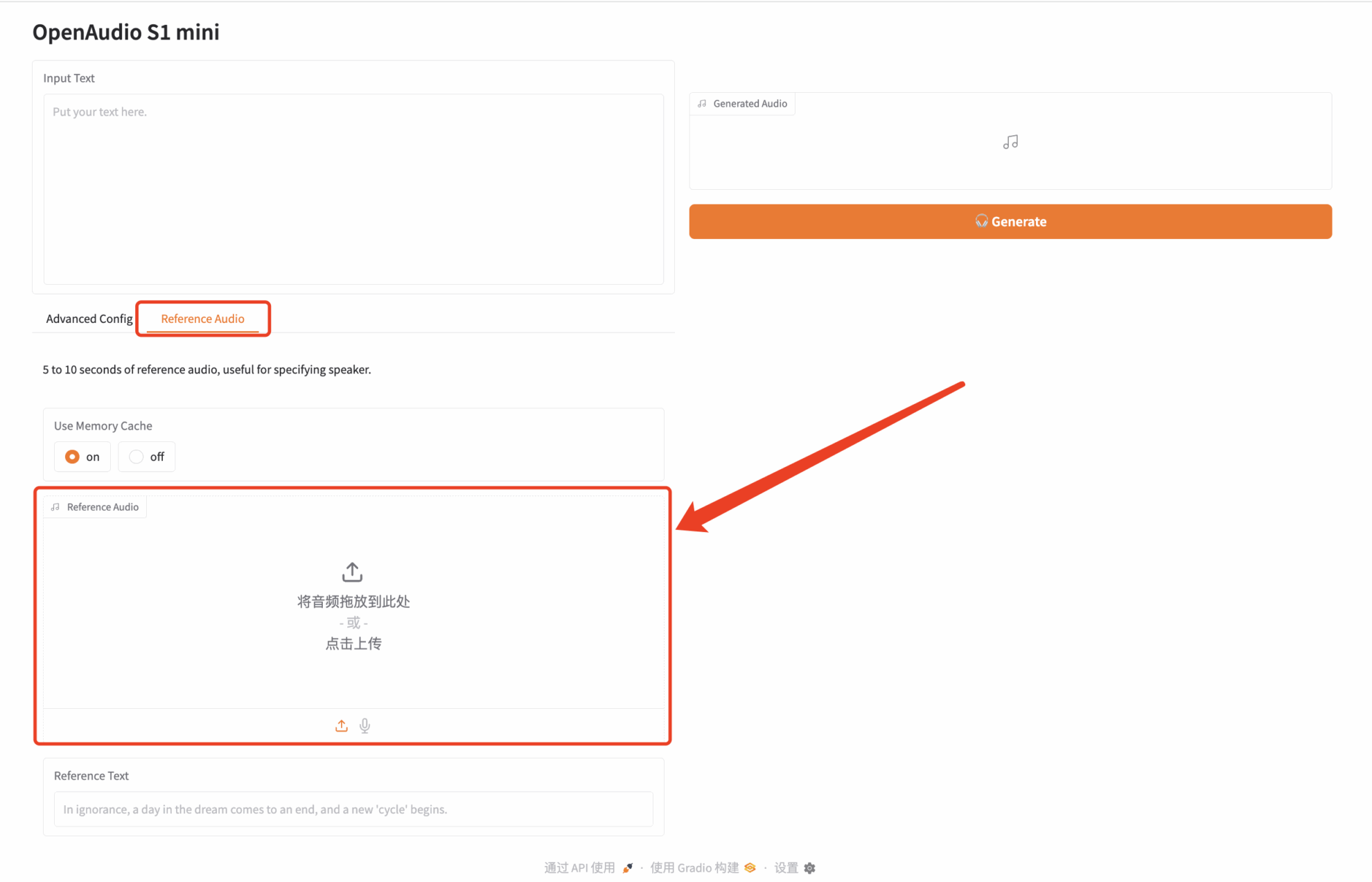
1. hyper.ai 홈페이지에 접속한 후, "튜토리얼" 페이지를 선택하고 "OpenAudio-s1-mini: 효율적인 텍스트 음성 변환 생성 도구"를 선택한 후, "이 튜토리얼을 온라인으로 실행"을 클릭하세요.
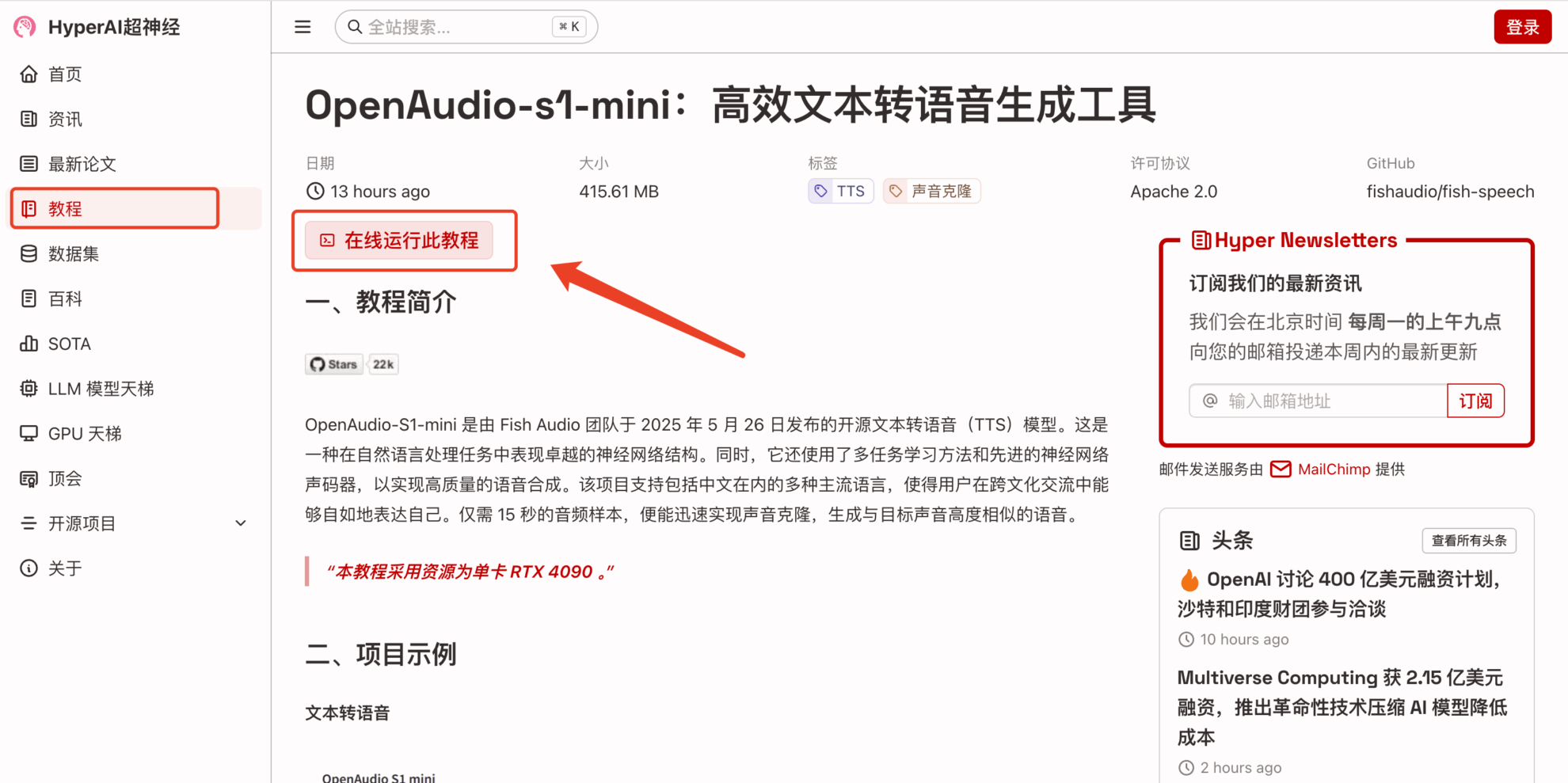
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
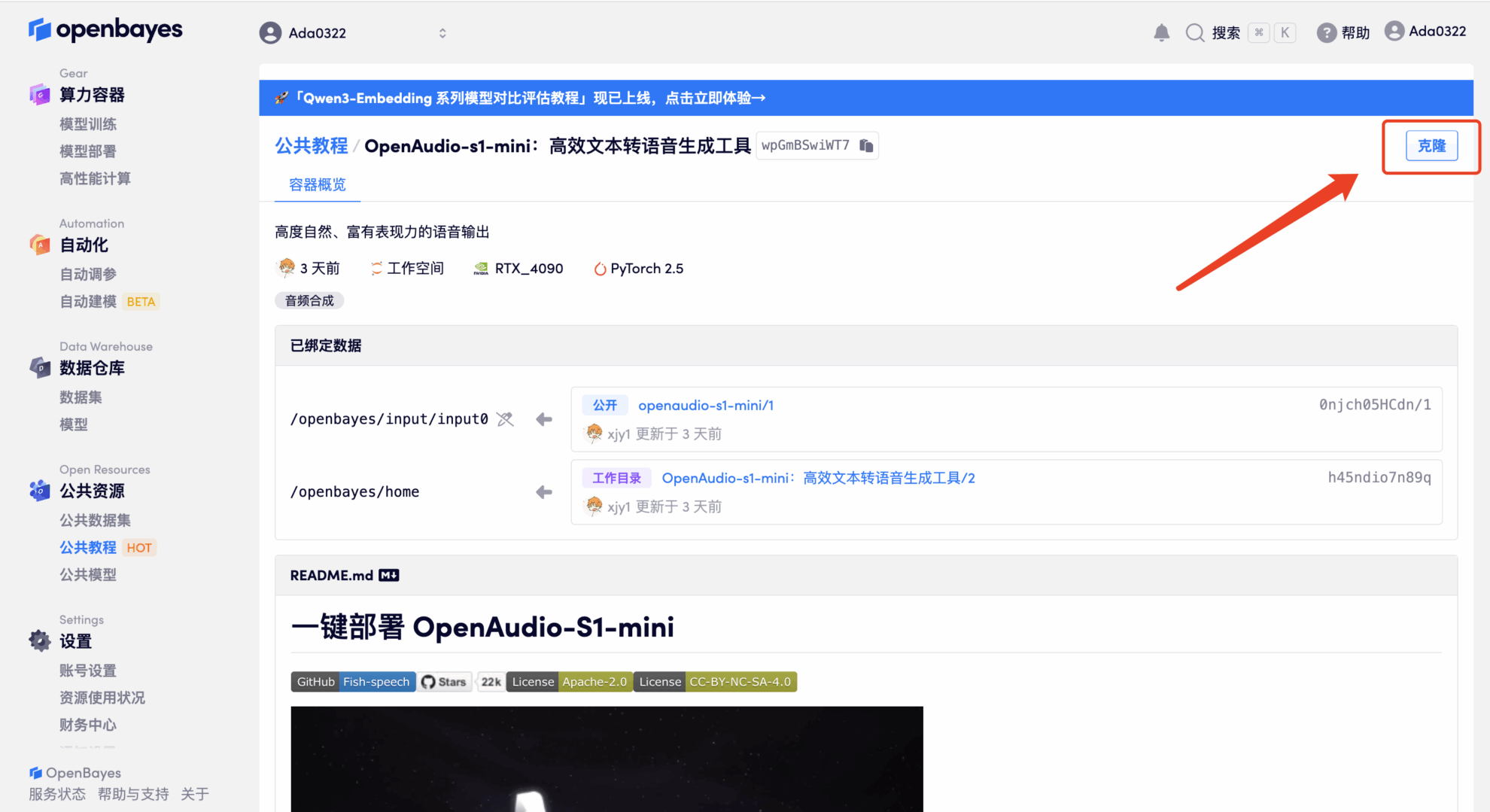
3. "NVIDIA RTX 4090" 및 "PyTorch" 이미지를 선택하세요. OpenBayes 플랫폼은 4가지 결제 방식을 제공합니다. 필요에 따라 "종량제" 또는 "일/주/월" 결제를 선택할 수 있습니다. "계속"을 클릭하세요. 신규 사용자는 아래 초대 링크를 통해 등록하시면 RTX 4090 4시간 + CPU 무료 사용 시간 5시간을 받으실 수 있습니다!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_NR0n
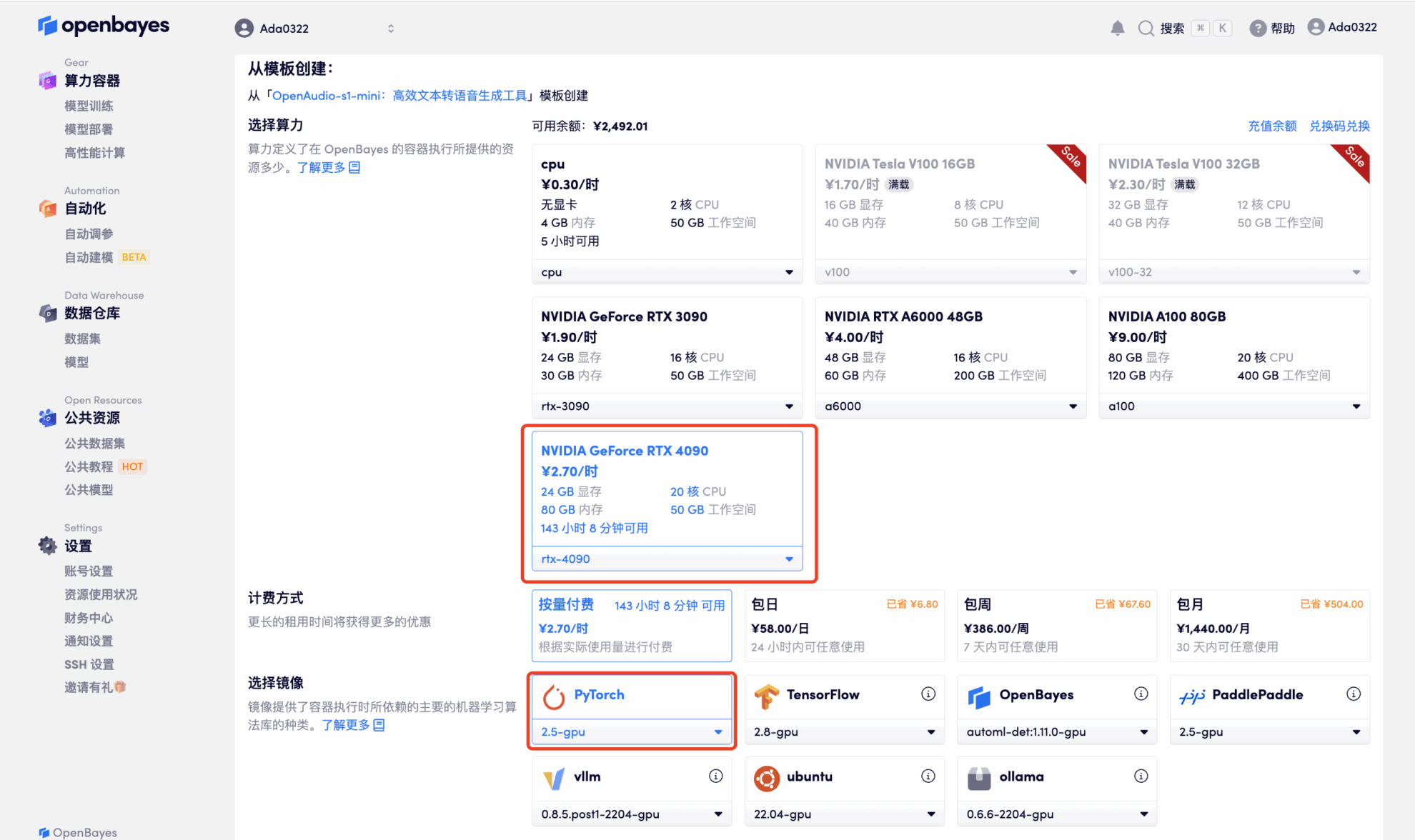
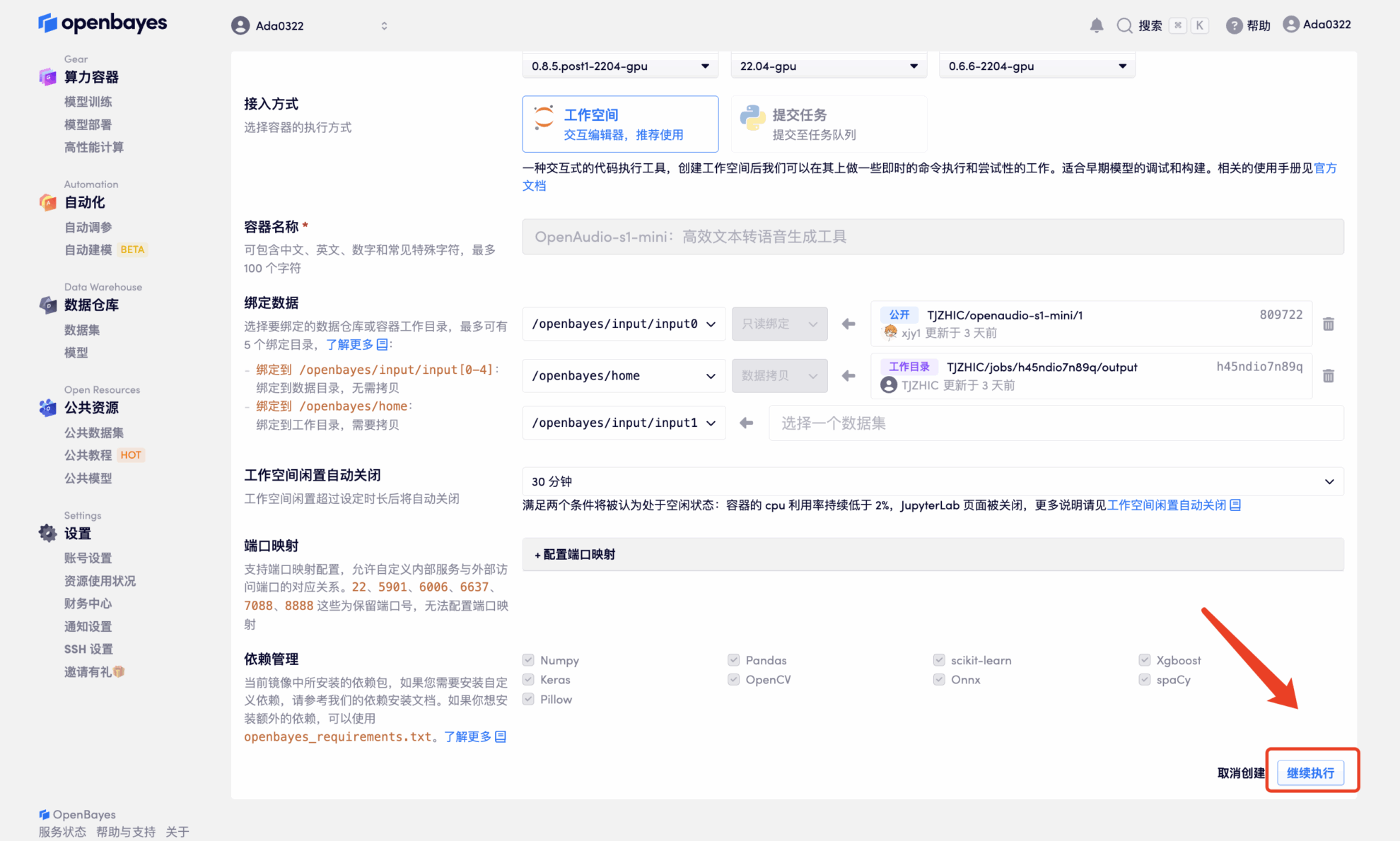
4. 리소스가 할당될 때까지 기다리세요. 첫 번째 클로닝 과정은 약 2분이 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다. 모델이 크기 때문에 WebUI 인터페이스를 표시하는 데 약 3분이 걸리며, 그렇지 않으면 "잘못된 게이트웨이"가 표시됩니다. API 주소 접근 기능을 이용하기 위해서는 이용자가 실명인증을 완료해야 합니다.
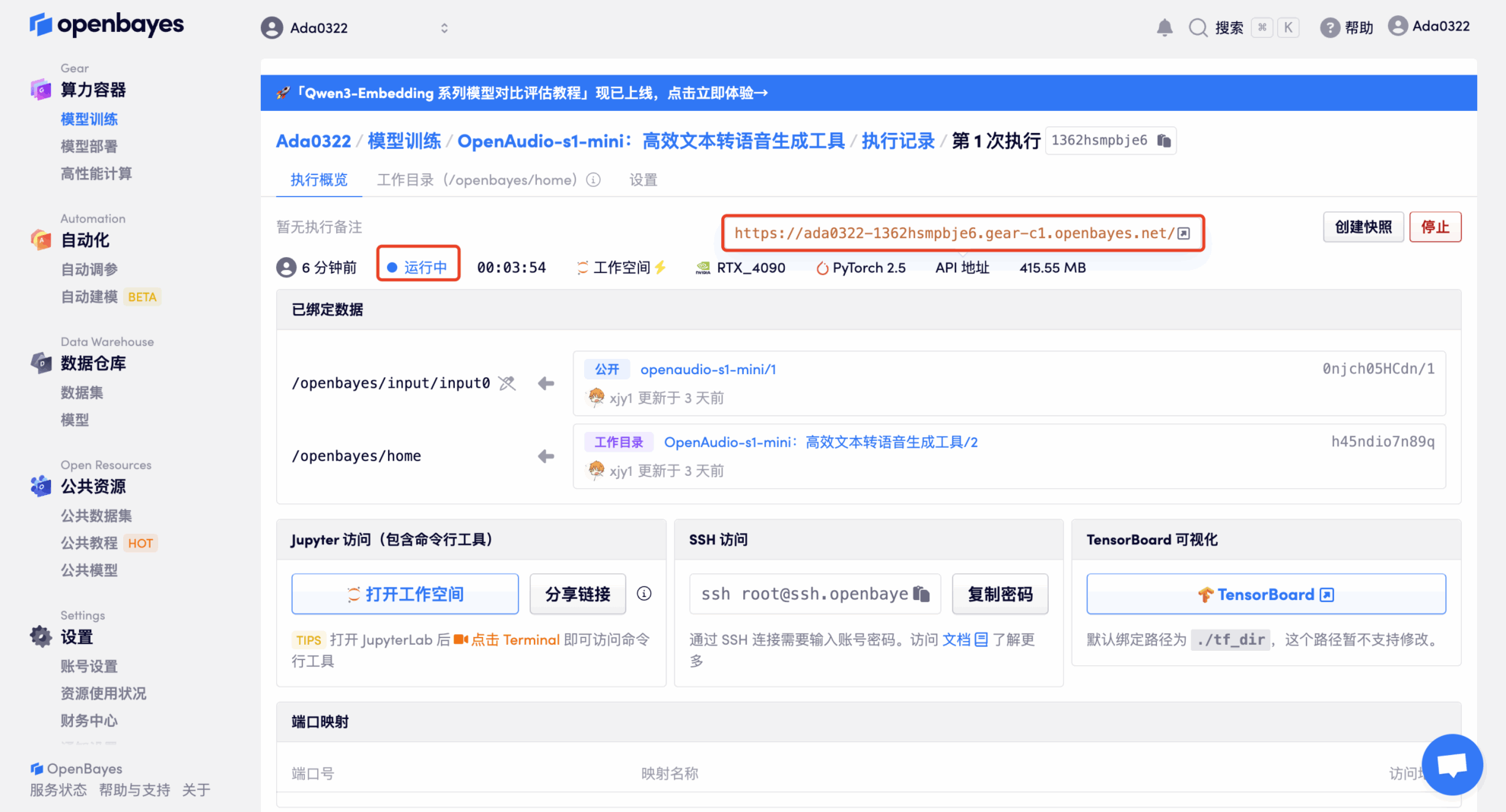
효과 시연
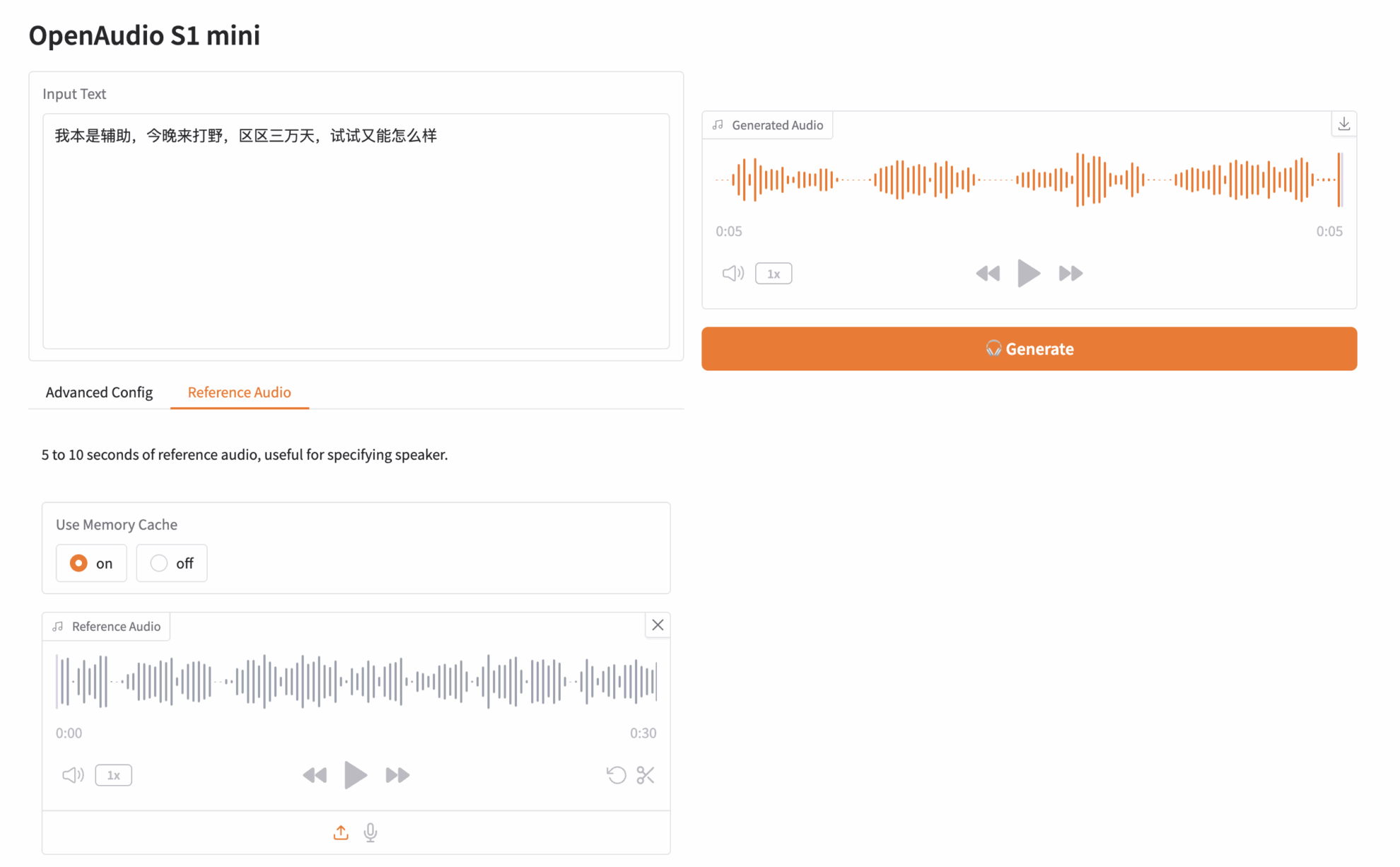
"API 주소"를 클릭하여 모델을 체험해 보세요. 원신에 등장하는 캐릭터 "파이몬"의 오디오 클립을 업로드했습니다. 입력 텍스트는 다음과 같습니다.
원래 서포터였는데, 오늘 밤은 정글을 하러 왔어. 3만 일밖에 안 됐는데, 한번 해 보는 게 뭐가 문제야?
그런 다음 오른쪽의 생성을 클릭하여 오디오를 생성합니다.
위는 HyperAI가 이번에 추천하는 튜토리얼입니다. 온라인에서 체험해 보세요.