Command Palette
Search for a command to run...
86,000개의 단백질 구조 데이터를 기반으로 양자역학 계산과 결합된 머신러닝 방법을 사용하여 69개의 새로운 질소-산소-황 결합을 발견했습니다.

세포 "공장"에서 질소-산소-황(NOS) 결합은 환경의 산화환원 변화에 따라 효소 활동을 조절할 수 있는 가역적인 "스마트 스위치"와 같습니다. 2021년, 독일 괴팅겐 게오르크-아우구스트 대학교 연구팀은 임균의 트랜스알돌라제를 연구하여 라이신과 시스테인 사이의 NOS 결합을 발견했습니다.이 연구는 단일 병원균과 효소 연구의 범위를 넘어서서 학제간 단백질 과학, 약물 설계, 생명공학을 위한 중요한 기반을 마련했습니다.
그러나 단백질 구조 데이터가 폭발적으로 증가하고 과학계에서 단백질 구조의 화학 결합에 대한 연구가 계속되면서 새로운 문제도 생겨났습니다.간과된 다른 NOS 결합이나 화학적 상호작용이 있나요?
위의 고려 사항을 바탕으로,조지 오거스트 대학의 소피아 바지와 샤라레 사야드는 혁신적인 계산 생물학 알고리즘인 SimplifiedBondfinder를 개발했습니다.이는 단백질 공유 결합 탐구에 있어서 새로운 장을 열었습니다.연구팀은 머신 러닝과 양자역학 계산을 통합하여 고해상도 X선 결정학 데이터베이스를 구축하고 86,000개 이상의 고해상도 X선 단백질 구조를 체계적으로 분석했습니다.69개의 새로운 NOS 결합이 발견되었을 뿐만 아니라, 이전에는 관찰되지 않았던 아르기닌(Arg)-시스테인과 글리신(Gly)-시스테인 사이에 형성되는 새로운 NOS 결합도 발견되었습니다.
이 혁명적인 발견은 단백질 화학의 범위를 넓혔고, 약물 설계와 단백질 공학에서 표적 조절이 가능해졌습니다.이 연구는 NOS 결합에 초점을 맞추었지만, 이 접근 방식은 다양한 다른 화학 결합과 공유 결합 변형을 연구하는 데 유연하게 적용될 수 있습니다.구조적으로 분해 가능한 번역 후 변형(PTM)이 포함됩니다.
해당 연구 결과는 "단백질 구조의 체계적 재평가를 통한 아르기닌-시스테인 및 글리신-시스테인 NOS 연결 밝혀내기"라는 제목으로 Communications Chemistry에 게재되었습니다.
연구 하이라이트:
* NOS 결합은 리신(Lys)과 시스테인 사이에만 존재한다는 기존의 과학적 통념을 깨고, 아르기닌-시스테인, 글리신-시스테인 NOS 결합의 새로운 산화환원 조절 메커니즘을 혁신적인 방법으로 최초로 규명했다.
* 제안된 방법은 기계 학습, 양자 역학 계산 및 고해상도 X-선 결정학 데이터를 통합하여 이 연구 분야에서 체계적인 화학 결합 발견 알고리즘이 부족하다는 과제를 해결하고 기존 실험의 한계를 벗어나 후속 연구를 위한 안정적이고 사용하기 쉬운 도구를 제공합니다.
* 머신러닝 및 인공지능 기술을 통해 이러한 연구의 비용은 크게 절감되고 연구 효율성은 향상되었으며, 단백질 기능 해독 및 새로운 단백질 상호작용 식별에 있어 머신러닝 기반 기술의 모범 사례가 되었습니다.

서류 주소:
https://www.nature.com/articles/s42004-025-01535-w
더 많은 AI 프런티어 논문:
https://go.hyper.ai/UuE1o
데이터 세트: 여러 계층의 제한을 통해 신뢰할 수 있는 데이터 세트 추출
SimplifiedBondfinder가 수집한 데이터는 세 개의 서로 다른 단백질 데이터베이스에서 나왔습니다.PDB, PDB-REDO, 그리고 BDB가 그것입니다. 수집된 데이터는 신뢰할 수 있고 사용 가능한 데이터 세트를 걸러내기 위해 다양한 제약 조건을 거칩니다. 그중 PDB-REDO 데이터베이스(2024년 1월 기준)는 PDB의 정적 구조를 개선하고 최적화하여 현대 결정학 표준에 더욱 부합하도록 합니다. 기존 PDB 항목과 비교했을 때 정확도와 신뢰성이 더 높습니다. 아래 그림 왼쪽에서 볼 수 있듯이,
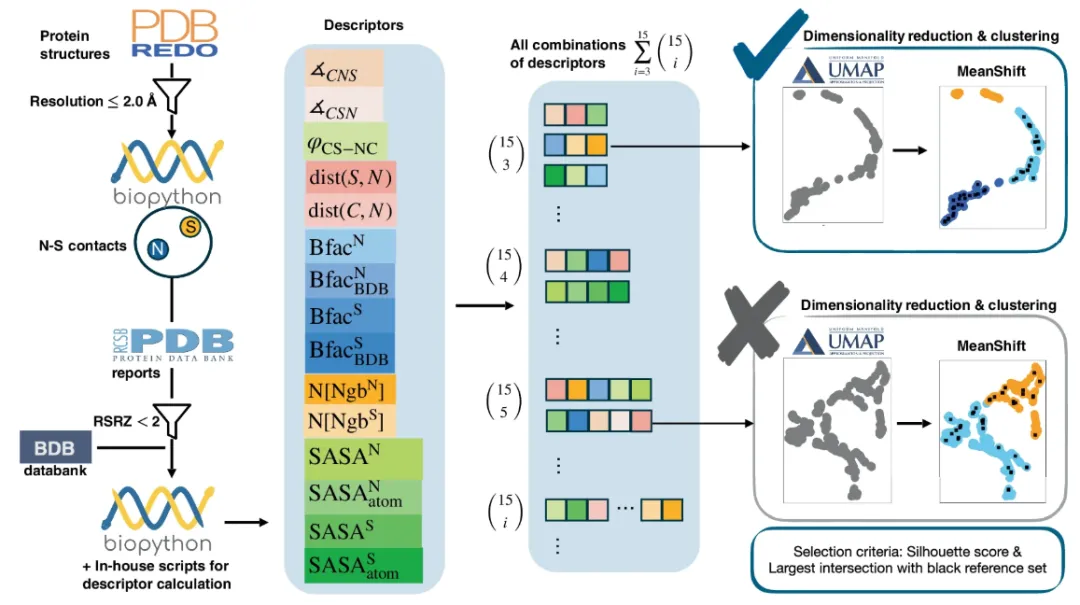
구체적으로 연구팀은 여러 개의 상호 연관된 기능을 사용하여 처음에 170,251개의 단백질 데이터가 들어 있는 데이터베이스에서 자동 데이터 세트를 생성했습니다.먼저 Biopython(v 1.79)을 사용하여 구조 분석(MMCIFParser 및 PDBParse 사용)을 수행하고 기타 원자 및 잔류물 특성을 계산했습니다. 연구팀은 X선으로 결정된 구조만 분석한 후, 170,127개 단백질의 데이터를 최적화했습니다.
이후 연구팀은 예측 정확도를 더욱 높이기 위해 ≤ 2 Å의 분해능으로 단백질 구조를 추가로 스크리닝하였고, 최종적으로 실험 분석을 위해 86,491개의 구조를 얻었습니다.
특정 화학 결합을 연구하기 위한 데이터 세트를 구성하려면연구팀은 구성 원자 유형, 잔류물 이름, 원자 간 거리, 점유율 등을 기반으로 기준을 확립했습니다.표준 잔류물에서 황(S)과 질소(N) 원자가 관여하는 NOS 연결의 경우, 연구팀은 SN의 원자간 거리, 즉 dist(S, N)를 라이신과 시스테인 사이의 원자가 상호작용에 대한 임계치에 해당하는 ≤ 3.2 Å로 제한하고, 위치 불확실성이 높은 원자를 배제하기 위해 점유 임계값을 > 0.8로 설정했습니다. 이 기준을 사용하여 본 연구에서는 25,462개의 NS 접촉을 확인했습니다.
연구팀은 목표 원자량이 정확하게 표현되도록 임계값을 <2.0으로 설정한 실제 공간 R 값 Z 점수(RSRZ)를 추가로 적용하여 실제 공간의 데이터와 신뢰할 수 있는 일치를 식별할 수 있도록 했습니다.데이터 세트는 23,129개의 NS 연락처로 더욱 축소되었습니다.이를 통해 실험 대상은 주로 시스테인의 두 가지 유형의 상호 작용, 즉 시스테인의 황 원자와 글리신의 골격 질소 사이의 상호 작용, 그리고 시스테인의 황 원자와 아르기닌 및 리신의 측쇄 질소 사이의 상호 작용에 집중할 수 있었습니다.
다음,연구팀은 Biopython의 NeighborSearch 모듈을 사용하여 구조적 매개변수를 추출하고, 각 데이터 세트의 각 샘플에 대해 15개의 서로 다른 설명자를 수집했습니다.여기에는 각도(∡CSN, ∡CNS), 비틀림 각도(φCS-NC), 기타 거리(dist(C, N), dist(S, N)) 및 Bio.PDB.SASA를 사용하여 추가로 계산된 대상 원자와 해당 잔류물의 용매 접근 가능 표면적(SASA) 값이 포함됩니다.
연구팀은 분석에서 목표 원자 이동도 매개변수를 확보하기 위해 실험에 원자 B-인자(Bfac)를 포함시켰습니다. 이 값들은 RCSB PDB와 일관된 B-인자를 포함하는 PDB 파일 데이터베이스(BDB) 두 데이터베이스에서 추출되었습니다.
이 연구의 구체적인 요구 사항에 따라 실험에서는 단 15개의 설명자만 선택되었다는 점을 언급할 가치가 있습니다.하지만 연구팀은 제안된 알고리즘은 처리할 수 있는 설명자의 수에 엄격한 제한이 없다고 밝혔다.이 시스템은 설계상 임의의 수의 설명자를 수용할 수 있으므로 도메인별 지식을 통합하거나 새로운 실험적 접근 방식에 적응할 수 있습니다.
모델 아키텍처: 머신 러닝과 양자 역학 컴퓨팅 통합
위 부분은 제안된 방법의 핵심 단계 중 첫 번째 단계로, 특정 화학 결합에 대한 목표 데이터 세트를 구성하고 엄격한 기준을 적용하는 것입니다.이 섹션에서는 제안된 방법의 두 번째 핵심 단계에 초점을 맞춥니다. 즉, 머신 러닝 기술을 사용하여 이러한 고차원 데이터를 탐색하는 것입니다.효과적인 구조적 설명자를 식별하고 공유 결합 형성을 위한 잠재적인 위치를 예측합니다.
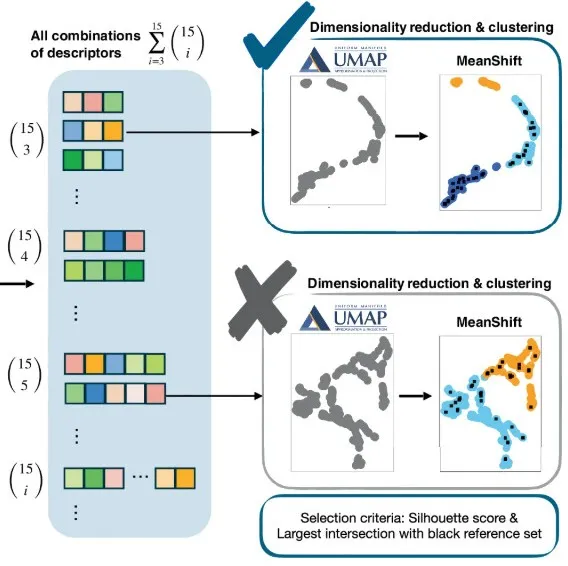
위의 그림과 같이.먼저 연구팀은 최대 임베딩 차원이 3인 비지도 균일 매니폴드 근사 및 투영(UMAP) 차원 축소 기법을 적용했습니다.그런 다음 모든 가능한 설명자 집합에 대해 평균 이동 클러스터링을 수행합니다.
안에,UMAP은 고차원 데이터의 본질적인 위상적, 기하학적 속성을 최적으로 보존하여 저차원 임베딩에서도 필수적인 구조적 특징이 보존되도록 보장합니다.이는 의미 있는 다운스트림 분석을 용이하게 합니다. UMAP에서 임베딩 차원 선택은 데이터셋과 원래 고차원 다양체의 위상 및 기하학적 특성에 따라 달라집니다. 실제 적용에서는 2차원 또는 3차원 임베딩이 직관적인 시각화와 클러스터링 품질 평가를 가능하게 하므로 해석 가능성이 가장 높습니다.
본 연구에서는 3개의 임베딩 차원이 잘 분리되고 의미 있는 클러스터를 제공했으며, 이는 선택의 정당성을 뒷받침합니다. 화학 결합 분석 및 클러스터링 결과는 이 차원 축소 방법이 본 실험에 사용된 데이터셋에 최적임을 보여줍니다. 필요 이상으로 임베딩 차원을 높게 선택하면 원래의 인기 있는 특징을 보존할 수 있지만, 해석성은 향상되지 않고 계산 비용이 증가합니다. 반대로, 차원을 최적 수준 이하로 줄이면 많은 정보 손실과 클러스터 분리 불량이 발생할 수 있습니다.
그 다음에,연구팀은 모든 3차원 임베딩 좌표의 실루엣 점수를 얻어 각 조합의 클러스터링 품질을 평가했습니다.알고리즘은 각 클러스터 내에서 클러스터, 실루엣 계수, 그리고 참조-표적 연결성을 출력합니다. 각 후보는 단백질 내 모든 표적 원자를 구별하기 위해 표적 원자의 이름, 해당 잔류물 이름, 잔류물 번호, 사슬, 그리고 PDB ID로 식별됩니다.
연구팀은 최종적이고 최소의 특징 공간을 찾기 위해 실루엣 계수 값, 각 특징 공간에서 생성된 클러스터 수, 이러한 클러스터에서 참조-대상 연결의 분포를 포함한 여러 기준을 사용했습니다.
구체적으로,연구팀은 실루엣 계수 ≥ 0.5를 갖는 두 개 또는 세 개의 뚜렷한 클러스터로 데이터를 효과적으로 분할할 수 있는 특징 공간을 식별하는 것을 목표로 했습니다.이상적으로 클러스터 중 하나에 참조 대상 연결이 전혀 없는 경우를 "불가능 클러스터"라고 합니다. 실제로 이 클러스터의 최소 참조 샘플 수는 허용 가능합니다. 참조 대상 연결의 전부 또는 대부분을 포함하는 나머지 클러스터를 "가능 클러스터"라고 합니다.
목표 화학 결합을 포함하는 가능한 후보 클러스터와 불가능한 후보 클러스터를 도입함으로써,연구팀은 새로운 화학 결합을 형성할 가능성이 있는 표적 원자 쌍과 그러한 결합을 형성할 가능성이 낮은 표적 원자 쌍을 구별하기 위해 최적화된 특징 공간을 식별할 수 있었습니다.이러한 경우를 확실하게 구분할 수 있는 기술자 집합이 확인되면 추가 기술자를 포함할 필요가 없습니다. 이러한 접근 방식은 계산 효율성과 해석 가능성 모두에서 장점이 있으며, 단백질 구조 내 새로운 화학 결합 형성을 식별하는 방법의 예측 정확도를 크게 향상시킬 수 있습니다.
본 연구에서 제안하는 방법은 머신러닝뿐만 아니라 양자역학적 계산도 통합한다.연구진은 Lys-NOS-Cys, Gly-NOS-Cys, ARG-NηOS-Cys, 그리고 ARG-NεOS-Cys 복합체에서 NOS 결합 후보 물질들에 대한 기하 최적화를 수행했습니다. 기하 최적화는 Gaussian16 – A.03(Gaussian 16, revision C.01) 소프트웨어 패키지를 사용하여 B3LYP-D3 (BJ)/def2-TZVPD 이론 수준에서 물 속에서 수행되었습니다. 최적화된 구조를 위해 황 원자와 질소 원자 사이의 거리(dist(S, N))와 각도(∡CSN, ∡CNS, ∡NOS)를 포함한 여러 기하 매개변수를 실험적으로 계산했습니다.
제안된 클러스터링 방법을 통해 예측된 NOS 공유 결합의 존재를 검증하기 위해,연구팀은 phenix.refine(버전 1.20.1-4487-000)을 사용하여 대표적인 단백질 구조 4개를 다시 최적화했습니다.phenix.molprobity를 사용하여 기하학적 품질, 충돌 점수, 그리고 입체적 상호작용을 평가하여 고해상도 결정학 데이터와의 일관성을 확보하기 위한 포괄적인 구조 검증을 수행했습니다. phenix.table1을 사용하여 정밀화 통계, 모델 품질 지표, 그리고 입체화학적 편차를 요약한 전체 검증 보고서를 생성했습니다. 이러한 검증 단계를 통해 NOS 접합의 구조적 무결성과 전자 밀도 맵과의 적합성을 확인했습니다.
실험 결과: Arg-NOS-Cys 및 Gly-NOS-Cys 결합은 합리적인 공유 결합입니다.
연구팀은 제안된 방법의 효과를 입증하기 위해 여러 실험을 수행하여 기술자 선택, 다중 기술자 공간의 생화학적 중요성, 클러스터 분석, 구조 및 열역학적 검증을 위한 머신 러닝 기법 사용을 탐구했습니다.
머신 러닝을 사용하여 설명자 선택
연구팀은 먼저 Lys-NOS-Cys 연결이 존재할 가능성이 높은 데이터에 이를 적용했습니다.이 데이터 세트에는 527개의 라이신-시스테인 쌍이 포함되어 있으며 실험적으로 검증된 NOS 결합도 포함되어 있습니다.주요 설명자는 질소 원자의 B-인자(Bfac(BDB)(N))와 리신(Ngbᴺ)과 시스테인(Ngbˢ)의 Cα 원자 반경 4Å 내에 있는 인접 잔류물의 수인 것으로 실험적으로 확인되었습니다.
연구팀은 아래 그림에서 볼 수 있듯이 잠재적인 Gly-NOS-Cys 연결을 탐색하기 위해 313개의 글리신-시스테인 쌍의 데이터 세트로 분석을 더욱 확장했습니다.
여기서 주요 설명자 세트에는 황 함유 잔류물의 B-인자(BfacBDBS), 황-질소 거리(dist(S,N)), 탄소-황-질소 각도(∡CSN)가 포함됩니다.
아르기닌과 시스테인 잔기 사이의 NOS 결합 형성을 예측하기 위한 주요 기술자의 관점에서,아르기닌 측쇄에는 Nη와 Nε라는 두 가지 유형의 질소 원자가 있는데, 이들은 기하학적 특성과 화학적 성질이 다릅니다.따라서 우리는 Nη(Arg-NηOS-Cys)와 Nε(Arg-Nε-Cys) 데이터 세트를 개별적으로 분석했습니다.
Arg-NηOS-Cys의 경우, 선택된 설명자는 질소 잔류물(SASAᴺ), ∡CSN 및 황(Ngbˢ)과 질소(Ngbᴺ)에 인접한 잔류물의 용매 접근 가능 표면적에 해당합니다. 마찬가지로 240개 Arg-NεOS-Cys 쌍의 데이터 세트의 경우 주요 설명자로는 BfacBDBS, SASAˢ, 질소 원자의 용매 접근 가능 표면적, ∡CSN 및 ∡CNS가 포함됩니다.
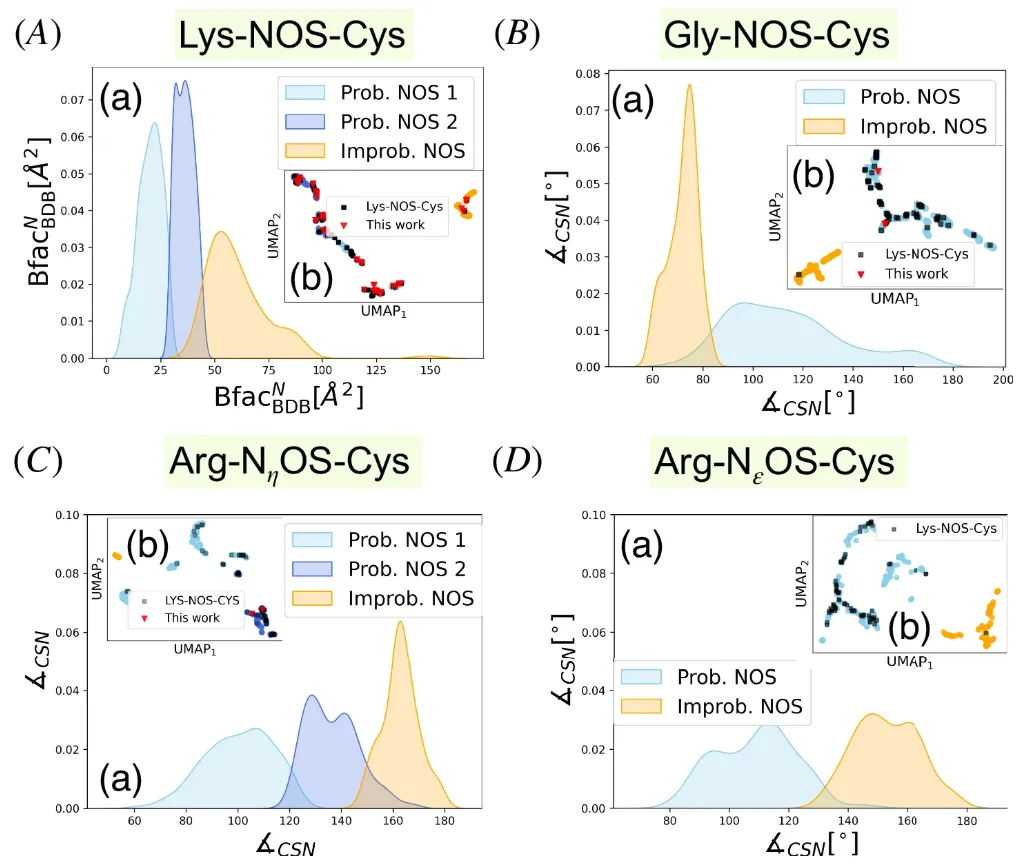
이러한 연구 결과는 UMAP 차원 축소 시각화를 통해 명확한 클러스터 분리가 이루어졌음을 보여줍니다.아래 그림에서 하늘색과 감청색은 NOS 결합 후보군을, 주황색은 "불가능한 클러스터링"을, 검은색 사각형은 참조 데이터 세트를 나타냅니다. NOS 결합을 형성할 수 있는 샘플의 분포가 참조 표준점의 분포와 상당히 겹치는 것을 명확하게 알 수 있습니다.
다차원 설명자 공간의 생화학적 중요성
연구팀은 알고리즘을 통해 최소한의 설명자 집합을 결정함으로써 NOS와 비 NOS 결합을 구별하는 데 중요한 주요 설명자의 생화학적 관련성을 탐구했습니다.
B-인자를 예로 들면, 각 클러스터에서 B-인자는 서로 다른 분포 패턴을 보입니다. 위 A(a)에서 볼 수 있듯이, "가능한 클러스터링"과 "불가능한 클러스터링"에 대한 B-인자의 모드는 서로 다릅니다.B-인자는 원자 또는 영역의 유연성과 관련이 있으며, 활성 부위 잔류물은 일반적으로 B-인자가 낮아 효소 활성과 관련이 있음을 나타냅니다.하지만 연구팀은 낮은 B-인자가 NOS 결합을 나타낼 수 있지만, 다른 질소-황 상호작용을 반영할 수도 있다고 지적했습니다.
서로 다른 아미노산 잔기로 형성된 NOS 결합의 설명자 특성과 관련하여, BfacBDBᴺ는 Lys-NOS-Cys에서 두 클러스터를 구별하는 주요 요인입니다. Gly-NOS-Cys 연결의 경우, ∠CSN은 가능한 NOS 연결 클러스터를 구별하는 주요 설명자이며, 대부분의 가능한 샘플에서 ∠CSN >80°이고 최적화된 Gly-NOS-Cys 복합체의 ∠CSN 값은 약 94°입니다. ∠CSN은 여전히 Arg-NεOS-Cys 연결의 가능한 NOS 연결과 불가능한 NOS 연결을 구별하는 주요 결정 요소입니다.
클러스터 분석
이번 평가에서 연구팀은 65개의 Lys-NOS-Cys 결합, 2개의 Gly-NOS-Cys 결합(아래 그림 a 및 b), 2개의 Arg-NηOS-Cys 결합(아래 그림 c 및 d)을 감지했습니다.
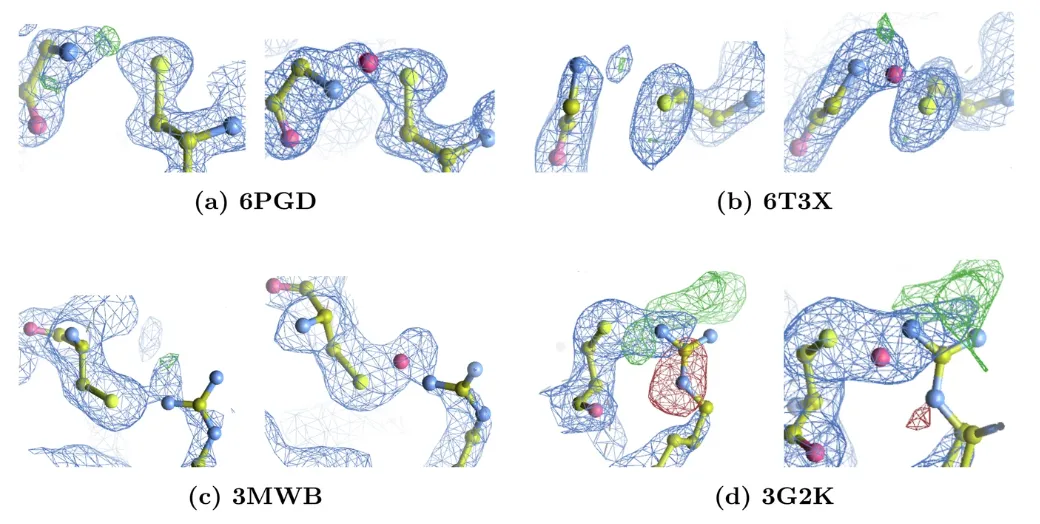
연구팀은 명시적 모델링과 재정의를 통해NOS 결합을 도입한 후, Rwork/Rfree 값은 평균 0.5%만큼 향상되었고, 설명할 수 없는 전자 밀도 피크가 상당히 감소했습니다.3G2K의 경우, 원래 구조에서 아르기닌 측쇄 주변에 음의 전자 밀도 피크가 존재하며, 이는 아르기닌 구조 재분배 후 현저히 감소합니다. 또한, 두 모델 모두 아르기닌 측쇄 근처에 양의 차이 피크가 존재합니다. 진폭이 크고 DMSO가 존재하기 때문에, 이는 현재 모델에서 모델링되지 않은 용매 분자를 나타낼 수 있습니다.
구조 및 열역학적 검증
연구팀은 Arg-NOS-Cys와 Gly-NOS-Cys 사이의 연관성을 더욱 확실히 하기 위해 양자역학적 기하 최적화와 4가지 대표적인 단백질 복합체(6PGD, 6T3X, 3MWB, 3G2K)에 대한 열역학적 평가를 결합하여 생체 내에서 발생할 수 있는 화학적 변동성을 체계적으로 설명했습니다.
구조 검증 측면에서, NOS 결합 최적화 모델에서 SN 거리는 2.61~2.70Å 범위에 있으며, 이는 원래 PDB-REDO 구조의 2.63~2.89Å 간격과 매우 가깝습니다.브리징 산소 원자를 제거한 시뮬레이션 결과, SN 분리가 3.36-4.26Å로 상당히 증가했습니다. 이는 실험적으로 관찰된 더 짧은 SN 거리가 중간 산소 원자의 존재와 일치한다는 것을 나타냅니다.
열역학적 평가 측면에서 연구팀은 다양한 양성자화 상태에서 깁스 자유 에너지(ΔG)를 계산하여 모든 NOS 결합 형성 과정이 음수임을 보여주었습니다.이는 시뮬레이션된 상태에서 수소 하나를 산소로 치환하여 NOS 결합을 형성하는 것이 열역학적으로 가능함을 시사합니다. 그러나 ΔG의 크기는 양성자화 상태와 아르기닌 및 글리신 유래 복합체 간에 유의미한 차이를 보입니다. 두 시스템 모두에서 중성 글리신 또는 아르기닌이 양전하 상태보다 선호됩니다. 글리신 기반 복합체는 약간 더 높은 ΔG 값을 나타냅니다. 이러한 값은 여전히 열역학적으로 유리한 결합을 의미하지만, 해당 아르기닌 복합체보다 체계적으로 발열량이 적습니다.
이러한 구조적 결과를 종합하면 일관된 증거가 제공됩니다.Arg-NOS-Cys와 Gly-NOS-Cys 결합은 단순한 비결합 접촉이 아니라 적절한 공유 결합이라는 것이 밝혀졌습니다.동시에 양자역학적으로 최적화된 기하학과 결정계의 결정학적 데이터, 그리고 형성의 음의 자유 에너지 사이의 일치는 이러한 연결이 관련 단백질 환경에서 구조적, 에너지적으로 가능하다는 것을 강력하게 시사합니다.
머신러닝, 단백질의 미시세계에 새로운 장을 열다
논문에서 언급했듯이, 머신러닝과 인공지능 기술의 급속한 발전은 생화학 분야의 복잡한 문제 해결에 있어 기존의 생화학적 방법보다 우수함을 입증했습니다. 낮은 컴퓨팅 비용과 높은 효율성 덕분에 과학 연구계는 "생산 방법"에 큰 혁명을 일으켰으며, 머신러닝 기반 기술이 단백질 기능을 해석하고 새로운 단백질 상호작용을 규명하는 데 더 큰 잠재력을 발휘하도록 촉진했습니다.
우연히도 캘리포니아 공과대학(California Institute of Technology)의 케빈 K. 양(Kevin K. Yang) 외 연구진은 Nat. Methods에 "단백질 공학을 위한 머신러닝 기반 지향 진화(Machine learning-guided direct evolution for protein engineering)"라는 제목의 논문을 게재했습니다.지시적 진화와 머신 러닝을 이용한 지시적 진화를 비교함으로써 머신 러닝의 우수성을 설명합니다.동시에 이 글에서는 효소 촉매 효율, 시토크롬 P450 열 안정성 최적화 등의 실제 사례를 나열하고, 선형 회귀, 가우시안 과정, 베이지안 최적화 등 다양한 머신 러닝 방법을 언급합니다.이는 머신 러닝이 단백질 공학을 위한 "데이터 기반의 지능형 탐색"을 제공할 수 있음을 보여줍니다.서열-기능 관계를 모델링함으로써 지향성 진화의 효율성과 성공률을 크게 향상시킬 수 있습니다.
서류 주소:
https://arxiv.org/pdf/1811.10775
또한, 이탈리아 볼로냐 대학의 리타 카사디오 등이 발표한 "단백질-단백질 상호작용 예측을 위한 머신 러닝 솔루션"이라는 제목의 논문에서도 단백질 연구에서 머신 러닝을 탐색한 내용이 자세히 설명되어 있습니다.단백질-단백질 분자 상호작용(PPI)에 대한 비지도 학습과 지도 학습을 포함한 머신 러닝 방법의 적용을 소개합니다.데이터 품질, 표현, 학습 알고리즘, 검증 절차의 핵심 문제가 강조됩니다.
서류 주소:
https://wires.onlinelibrary.wiley.com/doi/full/10.1002/wcms.1618
일반적으로 단백질의 미시적 세계에 숨겨진 생명 관련 코드는 여전히 많이 있으며, 머신 러닝을 주요 수단으로 하는 체계적인 데이터 기반 방법은 의심할 여지 없이 단백질의 미시적 세계의 문을 여는 열쇠와 같으며, 과학 연구 커뮤니티가 단백질의 기능과 안정성에 대한 보다 심층적인 연구와 탐구를 수행하도록 영감을 주어 인간의 생명 인식의 한계를 끊임없이 깨뜨립니다.