옥스퍼드 대학 등은 746만 명의 성인 건강 데이터를 심층 분석해 혈액 지표를 기반으로 15가지 유형의 암을 조기에 예측하는 조기 검진 알고리즘을 개발했다.

영국에서는 암 생존율이 오랫동안 심각한 어려움에 직면해 왔으며, 임상적 결과는 선진국 중 가장 낮은 수준입니다. 이런 상황의 이면에는 많은 수의 암 환자가 진단을 받을 당시 이미 질병의 중간 단계나 말기에 있었고, 치료를 위한 최적의 시기를 놓쳤다는 객관적인 현실이 있습니다. 2011년 영국 국민건강보험(NHS)은 암 전략을 발표했는데, 여기에는 75% 암을 치료 가능한 단계(1기 또는 2기)에서 진단한다는 목표가 명확히 명시되어 있으며, 진단 과정을 최적화하여 현재 상황을 개선하는 것이 목적이었습니다. 이 전략은 1차 진료를 획기적인 전환점으로 삼고, 예측 알고리즘을 통해 조기 진단의 효과를 높이고, 암 진단 및 치료 모델의 혁신 방향을 제시합니다.
이러한 맥락에서 대규모 1차 의료 전자 건강 데이터베이스를 기반으로 개발된 QCancer 점수 모델과 같은 암 예측 알고리즘이 등장했습니다.개인이 진단받지 않은 암에 걸릴 절대 확률은 나이, 성별, 빈곤 상태, 흡연, 음주, 가족력, 증상 등 여러 요소를 통합하여 평가합니다.국가 임상 지침에서는 암에 대한 양성 예측 값이 특정 임계값(예: 3%)을 초과할 경우 임상의가 추가 검사나 의뢰를 고려할 것을 권고하고 있습니다. 이러한 알고리즘은 환자가 의사를 방문할 때 실시간으로 암 위험을 평가하기 위해 1차 진료 임상 컴퓨터 시스템에 통합되어 임상적 의사 결정을 위한 데이터 지원을 제공합니다.
2020년 현재, 영국에서 암의 절반 이상이 1기 또는 2기에서 진단되었는데, 이는 2028년까지 75%라는 목표와는 여전히 상당한 격차입니다. 최근 몇 년 동안 혈액 검사 기술의 발전으로 이러한 병목 현상을 극복할 수 있는 새로운 방향이 마련되었습니다.많은 연구에 따르면 헤모글로빈, 백혈구 수, 혈소판 수 등 혈액 지표의 비정상적인 변화가 임상 증상보다 몇 년 일찍 나타날 수 있다고 합니다.이는 암에 대한 조기 경보 바이오마커로서의 잠재력을 시사하며, 연구자들은 혈액 검사 데이터를 예측 모델에 통합하여 알고리즘이 무증상 또는 비정형적인 증상을 보이는 암을 식별하는 능력을 향상시키는 방안을 모색하고 있습니다.
이를 바탕으로 런던 퀸 메리 대학교와 옥스퍼드 대학교 연구팀은 영국 성인 746만 명의 익명 전자 건강 기록을 기반으로 두 가지 새로운 암 예측 알고리즘을 개발하기 위해 협력했습니다.기본 알고리즘은 전통적인 임상적 요인과 증상 변수를 통합하고, 고급 알고리즘은 완전 혈구수 및 간 기능 검사와 같은 혈액 지표를 추가로 통합합니다.
이 연구에서는 암의 전반적인 확률을 예측할 뿐만 아니라 남성 및 여성 그룹을 별도로 모델링하기 위해 다항 로지스틱 회귀 모델을 사용했습니다.이를 통해 간암과 구강암을 포함한 15가지 암 유형에 대한 개인별 위험 평가가 처음으로 가능해졌습니다.500만 건의 독립적인 검증에서 새로운 알고리즘은 기존 모델보다 뛰어난 판별력, 보정 및 민감도를 보여 임상적 의사 결정 프로세스를 최적화하고 조기 암 진단을 촉진하기 위한 과학적 근거를 제공했습니다. 또한 연구팀은 이 방법이 현재 진단되지 않은 간암의 확률을 추정하기 위해 1차 진료에서 사용되는 최초의 알고리즘이라고 제안했습니다.
관련 연구 결과는 "암 조기 진단 개선을 위한 예측 알고리즘의 개발 및 외부 검증"이라는 제목으로 국제적으로 유명한 학술지인 Nature Communications에 게재되었습니다.

서류 주소:
오픈소스 프로젝트인 "awesome-ai4s"는 100개가 넘는 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
이중 데이터베이스 및 다중 코호트 연구: 표본 크기가 100만 개를 초과하여 모든 방향으로 데이터 지원 구축
이 연구의 데이터는 두 개의 전자 의무 기록 데이터베이스인 QResearch(버전 48)와 Clinical Practice Research Datalink(CPRD Gold)에서 얻었습니다.전자는 EMIS 시스템을 기반으로 하며 영국을 포괄하는 반면, 후자는 Vision 시스템을 기반으로 하며 북아일랜드, 스코틀랜드, 웨일즈의 진료소 데이터를 포함하여 지리적으로 독립적인 외부 검증 코호트를 형성하여 데이터 다양성과 대표성을 보장합니다.
연구 대상 인구 측면에서 볼 때, 아래 그림과 같이 영국의 QResearch 클리닉 데이터는 129,715건의 신규 암 사례를 포함하는 7,464,507명의 개발 코호트, 44,984건의 신규 암 사례를 포함하는 2,637,184명의 검증 코호트, 32,328건의 신규 암 사례를 포함하는 2,736,726명의 CPRD 검증 코호트로 무작위로 나뉘었습니다.
3개 코호트의 표본 크기는 모두 100만 명을 넘어섰으며, 18~84세를 대상으로 했습니다.여기에는 젊은 세대에 흔한 혈액암, 유방암, 중년 및 노년층에게 흔한 암 유형이 포함됩니다. 기간은 2015년 1월 1일부터 2023년 3월 31일까지이며, 후속 조사 기간은 2년입니다. 등록 당시 암 진단을 받지 않은 환자에 초점을 맞추고, 등록 전 12개월 이내에 "위험 신호 증상"이 있었던 환자를 제외하여 새로운 암 데이터의 정확성을 보장합니다. 이 데이터는 연령, 성별, 빈곤 상태, 흡연, 음주, 가족력, 증상, 혈액 검사(전혈구수, 간 기능 검사) 등의 차원을 포괄합니다. 자체 보고된 인종, 흡연, 음주, BMI 데이터의 완전성이 약간 더 높은 영국 코호트를 제외하고, 각 코호트의 기본 특성은 일반적으로 일관적이었으며, 이는 모델 개발을 위한 균형 잡힌 데이터 기반을 제공했습니다.
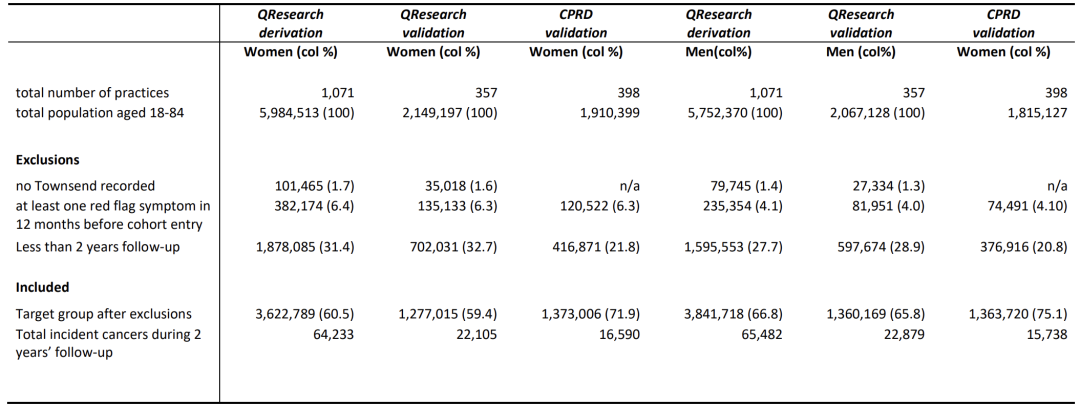
이 연구는 일반의, 병원, 사망률, 암 등록부라는 4가지 주요 데이터 소스를 기반으로 합니다. QCancer에 이미 포함된 13가지 유형의 암(폐암, 대장암 등)에 새롭게 추가된 간암, 구강인두암 등 총 15가지 유형을 식별합니다.CPRD 코호트는 데이터 제한으로 인해 일반의가 기록한 진단에만 기반을 두었고, 이로 인해 계층적 검증 시스템이 필요했습니다. 이러한 데이터는 표본 크기가 크고, 지리적 영역이 넓으며, 기간이 길고, 예측 요소가 다양하며, 임상적으로 관련성이 강하다는 특징이 있습니다. 예측 모델을 구축하기 위한 코호트를 개발하고, 다양한 지역과 시스템(특히 CPRD 외부 코호트)의 검증 코호트를 사용하여 모델의 보편성과 신뢰성을 평가함으로써, 실제 임상 시나리오에서 알고리즘의 효과성과 안정성을 보장하고 암 조기 진단을 위한 데이터 지원을 제공할 수 있습니다.
암 예측 모델 개발: 다항 로지스틱 회귀 모델링 및 다차원 검증
모델 개발 과정에서 이 연구는 기존 알고리즘과 문헌을 기반으로 인구 통계적 특성, 흡연 및 음주 습관, 암 가족력, 동반 질환, 증상 및 혈액 검사 결과를 포함한 후보 예측 변수를 선별했습니다. 증상은 "위험 신호 증상(강력한 암 연관성, 임상 지침에 따라 긴급 의뢰의 근거)"과 비특이적 증상으로 세분되었으며, 혈액 검사에는 잠재적 신호를 포착하기 위해 지난 2년간의 코호트 기록이 포함되었습니다.
모델의 과학성과 정확성을 보장하기 위해,연구진은 모델링에서 다항 로지스틱 회귀 분석을 사용하여 각 암 유형의 예측 변수 계수를 추정하고 남성과 여성에 대한 모델을 적용했습니다.음주, 흡연 상태 및 혈액 지표의 누락된 값은 연쇄 방정식 다중 대입법(남성과 여성 각각 5회 대입 + 루빈 규칙 병합)을 통해 채웠고, 이진 변수는 일반의 진단 기록에 따라 이분형 범주로 코딩했습니다. 모형을 적합할 때 유의수준이 ≤ 0.01인 변수는 그대로 유지하고, 위험비가 0.80~1.20이고 유의수준이 없는 계수는 0으로 설정했습니다. 통계적 유의성에만 근거한 자동 변수 선택을 피하고 임상적 관련성을 보장하기 위해 P값과 효과 크기를 결합하여 간결한 모델을 구성했습니다.
분수 다항식은 연속 변수 간의 비선형 관계를 모델링하고 예측 변수와 연령 간의 상호 작용을 테스트하는 데 사용되었습니다. 연구진은 모델의 낙관성을 평가할 때 휴리스틱 수축 계수를 사용하여 모델의 낙관성을 평가했으며 두 모델 모두 수축 값이 >0.99로 과적합이 없음을 확인했습니다. 마지막으로, 모델 A(임상적 요인 + 증상)와 모델 B(모델 A + 혈액 검사 결과)가 도출되었습니다. 후자는 새로운 암 관련 신호를 추가하여 예측 정확도를 높이는 것을 목표로 합니다.
모델 평가는 두 개의 독립적인 검증 코호트에서 수행되었습니다. AUROC를 계산하여 판별력을 평가하는 것 외에도,연구진은 전반적인 분류 성능을 측정하기 위해 다중 범주 판별 지수(PDI, 남성의 경우 12개 범주, 여성의 경우 14개 범주, 암이 없는 범주 포함)를 도입했습니다(PDI가 1에 가까울수록 판별력이 더 정확함).예측된 확률과 실제 값 사이의 일관성은 검정 곡선, 기울기, 절편을 통해 테스트되었습니다. 조기 암에 대한 특별 분석은 1기/2기를 초기 정의로 사용하여 2015년부터 2020년까지의 사례에 초점을 맞추고, 지리적 지역, 인종, 연령대 등의 하위 그룹을 계층화하고 평가하여 다양한 인구에서 모델의 보편성을 검증합니다.
암 예측 모델 적용: 간암과 구강암을 최초로 포함하였으며, 혈액 지표와 암 위험도 간의 관계를 분석하였다.
모델 적용 및 실험 검증 단계에서,본 연구에서는 새로운 예측모형의 변수 연관성, 변별력, 교정효과, 임상적 가치에 대한 다차원적 검증을 실시하였다.기존 QCancer 알고리즘과 비교하여 새로운 모델은 간경변, B형 간염, C형 간염(간암 관련), AIDS(혈액암 및 신장암 관련)의 4가지 새로운 질환을 추가하고, 폐암/혈액암 가족력과의 연관성을 보완하며, 가려움증, 멍, 복부 덩어리와 같은 7가지 교차암 증상을 추가합니다.
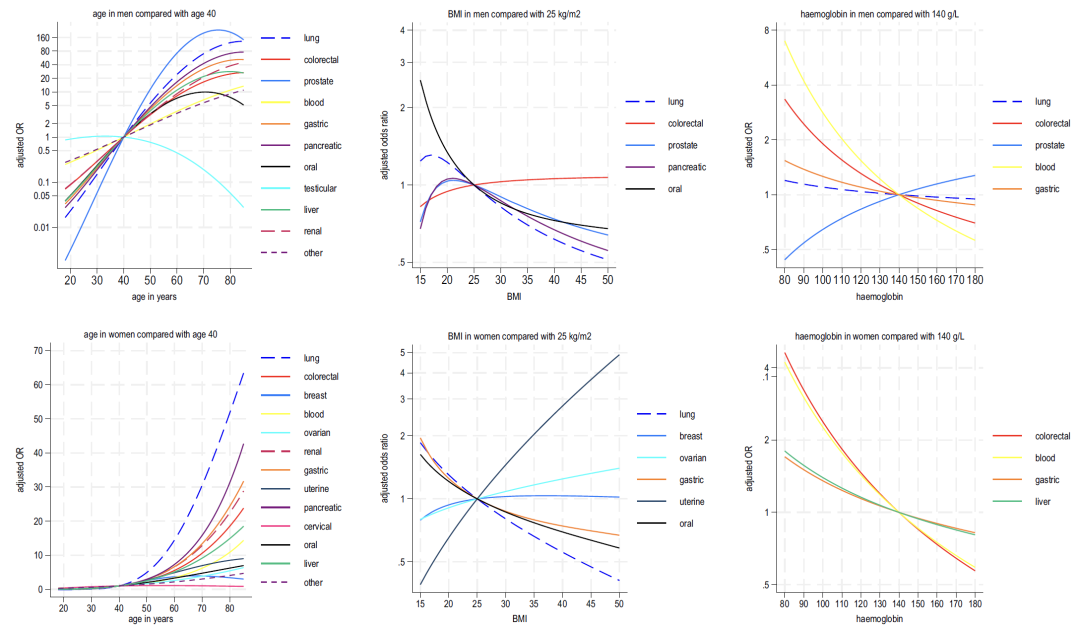
연령과 증상 간의 상호작용에는 성별 차이가 있었습니다.대부분 암의 위험은 남성의 경우 젊은 나이에 더 크지만, 여성의 경우는 그 반대입니다.연령과 BMI를 분석한 결과, 고환암과 자궁경부암을 제외한 모든 유형의 암 위험이 연령에 따라 증가하는 것으로 나타났습니다. 낮은 BMI는 여러 암 유형과 양의 상관관계를 보였으며, 여성의 자궁암과 난소암 위험은 BMI가 높을수록 증가했습니다.
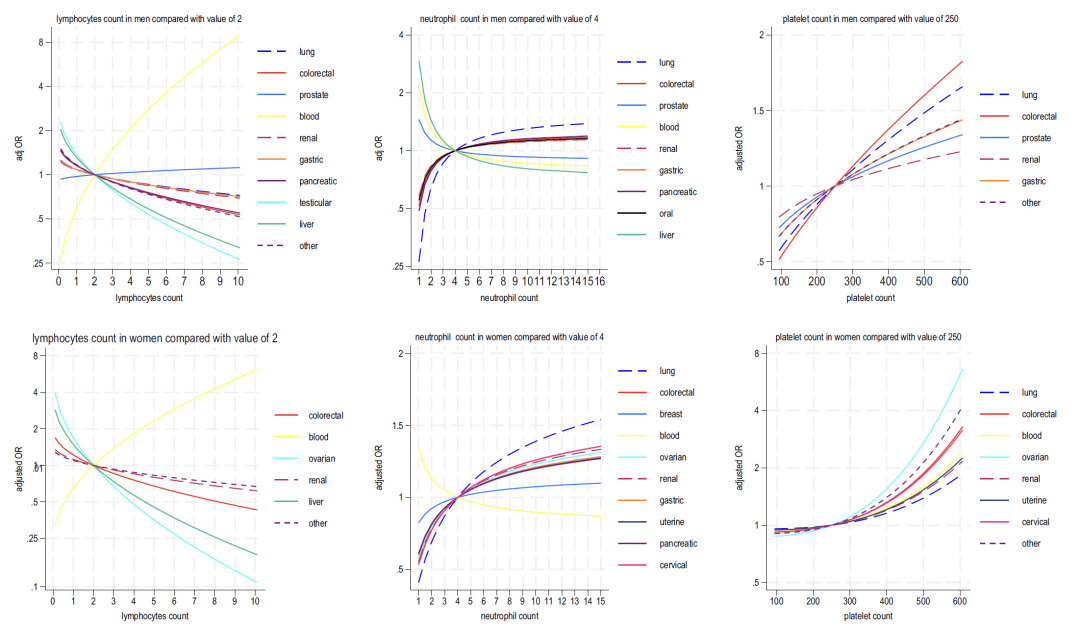
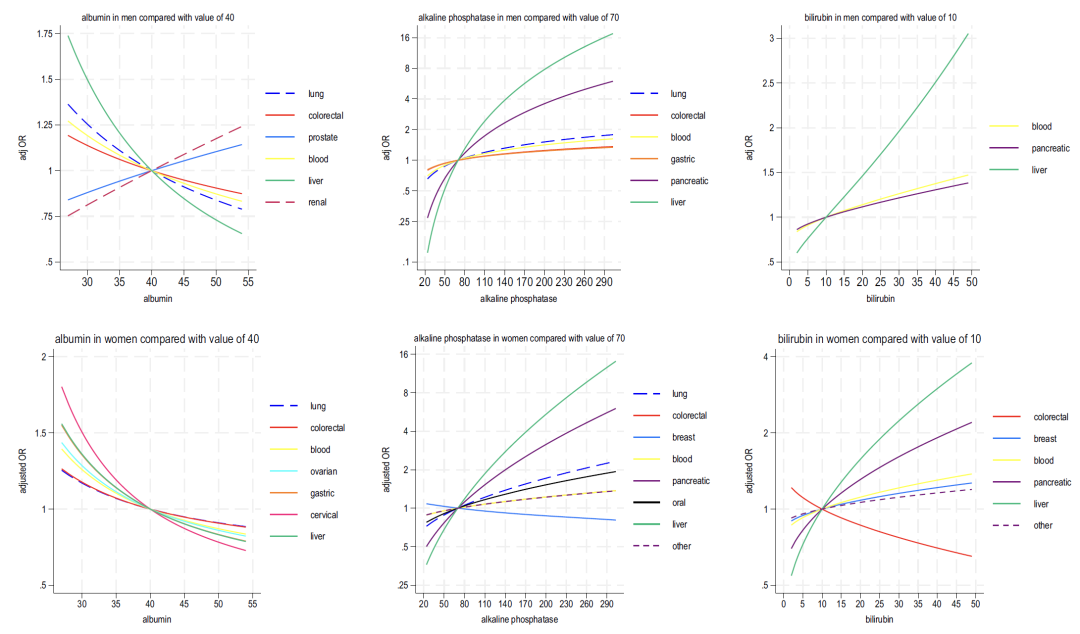
아래 그림 2-4에서 볼 수 있듯이, 모델 B에 포함된 혈액 지표를 분석한 결과 다음과 같은 사실이 나타났습니다.
* 헤모글로빈: 이 지표의 감소는 남성의 경우 폐암 및 대장암, 여성의 경우 대장암 및 간암과 관련이 있습니다.
* 림프구: 대부분의 암과는 음의 상관관계를 보이며, 혈액암과는 강한 양의 상관관계를 보입니다.
* 호중구: 여성의 경우 이 지표의 증가는 암(가장 중요한 암)과 널리 연관되어 있는 반면, 남성의 경우 "양방향 연관(높은 값은 6가지 유형의 암과 연관되고 낮은 값은 간암 및 전립선암과 연관됨)"을 보입니다.
* 혈소판: 혈소판 수치 증가는 남성과 여성 모두에서 다양한 암과 양의 상관관계를 보입니다(남성의 경우 대장암, 여성의 경우 난소암이 가장 강함). 또한 호중구 증가와 림프구 감소와 상승적으로 연관되어 있습니다.
* 간 기능: 알부민 감소와 알칼리성 인산가수분해효소 증가는 일반적으로 암 위험을 나타내며, 빌리루빈 증가는 간암 및 혈액암과 밀접한 관련이 있습니다.
판별력 평가에서는 아래 그림과 같이 모델 B의 c 통계량(혈액검사 포함)이 모델 A보다 전반적으로 더 우수함을 알 수 있다. 남성(0.876)의 전반적인 판별 효율성은 여성(0.844)보다 높습니다. 15개 암의 c값은 대부분 >0.8이며, 여성의 경우 구강암(0.747)과 자궁경부암(0.694)만이 약간 낮았습니다. 다중범주 판별 지수(PDI)는 모델 B가 남성과 여성을 구별하는 능력(남성 0.323, 여성 0.266) 면에서 모델 A보다 우수한 것으로 나타났으며, 고환암(남성 PDI 0.641)과 자궁암(여성 PDI 0.439)에 대한 분류 성능이 뛰어났습니다. 하위 그룹 분석 결과모델의 성능은 인종, 연령, 지역에 따라 안정적이었고, 희귀 암의 경우 사건 수가 적어 약간의 변동이 있었습니다.
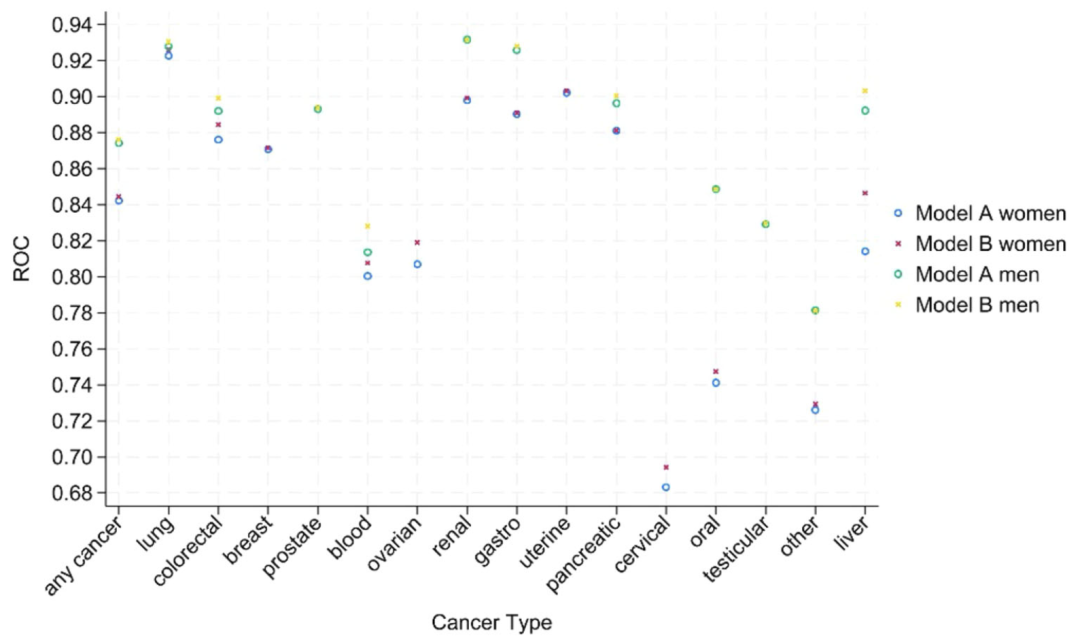
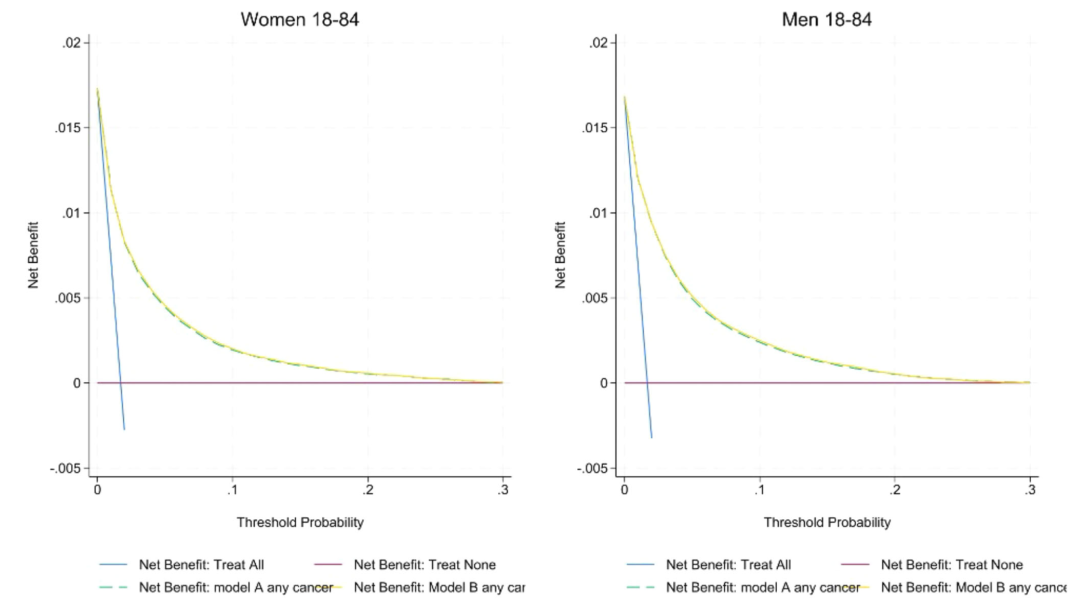
교정 능력 측면에서는 아래 그림과 같이 영국 코호트에서 모델 A/B의 교정 기울기는 1에 가깝고(여성은 1.00, 남성은 0.99), 절편은 0에 접근합니다. 그러나 외부 CPRD 코호트에 속한 남성과 여성의 암 발생 확률은 다소 과대평가되는 경향이 있습니다. 결정 곡선은 모델 B의 순이익이 모델 A 및 QCancer보다 높은 것을 보여줍니다. 특히 추천 임계값인 3%에서 그렇습니다. 모델 A/B의 남성 암에 대한 민감도(82.6%)는 QCancer(78.1%)보다 높고, 여성 암에 대한 민감도는 66.0%에서 77% 이상으로 증가하며, 1/2기 조기 암을 식별하는 능력은 모든 단계(여성의 경우 75%, 남성의 경우 81%)와 비슷합니다. 재분류 분석 결과QCancer와 비교했을 때, 모델 A는 노인을 고위험군으로, 젊은 사람을 저위험군으로 분류하여 임상 자원 배분의 정확도를 최적화합니다.
글로벌 암 예측 알고리즘과 조기 진단: 대학 연구와 기업 혁신의 학제간 발전
암 예측 알고리즘과 조기 진단 분야에서 전 세계 대학의 과학 연구팀과 기술 회사는 학제간 혁신을 통해 이론 연구를 임상 응용으로 신속하게 전환하는 것을 추진하고 있습니다.
예를 들어, 베이징 대학의 Dong Bin과 Shen Lin 팀이 개발한 MuMo 모델은HER2 양성 위암 환자의 영상, 병리학 및 임상 데이터를 통합하여 개별화된 치료에 대한 정확한 예측을 제공합니다.중국과학원 컴퓨터 네트워크 정보센터는 트랜스포머 아키텍처를 사용하여 "동팡" 슈퍼컴퓨터 시스템을 기반으로 SuRe-Transformer 모델을 구축했습니다.21%로 유방암 병리 이미지의 HRD 예측 정확도를 향상시킵니다.청화대학교의 리샤오 연구 그룹은 약한 지도 학습 프레임워크인 HistoCell을 사용했습니다.병리학적 이미지에서 세포의 공간 연관 네트워크에 대한 비지도 추론을 달성합니다.종양 미세환경 연구를 위한 새로운 도구를 제공합니다.
하버드 의대와 스탠포드 대학이 개발한 CHIEF 모델은94%의 정확도로 19가지 암을 진단합니다.또한 병리학적 이미지를 기반으로 환자 생존율을 예측할 수도 있습니다. 케임브리지 대학에서 개발한 ResNetRS50 딥러닝 모델은 혈액 데이터를 분석하여 혈액암을 예측하는데, 기존 모델보다 정확도, 속도가 높고 오류율이 낮습니다.
비즈니스 분야의 혁신은 기술 구현과 임상 실무의 통합에 더욱 중점을 둡니다. Microsoft의 AI for Health 플랫폼은 유전체와 전자 건강 기록을 통합하여 유방암 위험이 높은 사람의 경우 89%의 예측 정확도로 개인별 암 위험 지도를 구축합니다. Google DeepMind의 AlphaScan 시스템은 폐암 조기 발견에서 96%의 정확도를 보였습니다. AI 의료기술 기업 InferRead의 폐 영상 AI 솔루션은 딥러닝 기반 폐 결절 검출 시스템으로, 임상 CT에 적용되어 진단 효율성을 크게 향상시켰습니다.
전반적으로, 암 예측 알고리즘과 조기 진단 분야는 단일 암 검진에서 여러 암에 대한 전체 암 조기 검진으로 진화하고 있습니다. 미국에서 Grail의 Galleri 검사는 50가지 유형의 암을 검진하고 혈액 메틸화 분석을 통해 원발 병변을 찾아내고, 중국 회사 Xunyuan Biotechnology의 PanSeer® 기술은 5가지 흔한 암에 대한 조기 검진을 효과적으로 달성합니다. 인공지능과 빅데이터의 심층적 융합을 통해 암 예측 알고리즘이 1차 의료에 대중화되어 진단 및 치료 모델이 '경험적 의학'에서 '정밀 데이터 의학'으로 전환되고 '조기 발견 및 조기 개입'을 실현하는 기반이 마련될 것으로 기대됩니다.
참조 링크:
1.https://bda.pku.edu.cn/info/1003/2824.htm
2.https://www.cas.cn/syky/202505/t20250522_5069507.shtml
3.https://mp.weixin.qq.com/s/s1JyOTPChdoMipmTzBBqvw
4.https://mp.weixin.qq.com/s/4fhMJ25xVAThAFTdmZyt9w