Command Palette
Search for a command to run...
환경 구성부터 대규모 모델 배포까지 vLLM 실무 튜토리얼 요약, 주요 업데이트 추적을 위한 중국어 문서

대규모 언어 모델(LLM)이 점차 엔지니어링 및 대규모 배포 방향으로 이동함에 따라 추론 효율성, 리소스 활용도, 하드웨어 적응성이 애플리케이션 구현에 영향을 미치는 핵심 문제가 되고 있습니다. 2023년, 캘리포니아 대학교 버클리 캠퍼스의 연구팀은 KV 캐시를 효율적으로 관리하기 위해 PagedAttention 메커니즘을 도입한 vLLM을 오픈 소스화하여 모델 처리량과 응답 속도를 크게 향상시켰고, 오픈 소스 커뮤니티에서 빠르게 인기를 얻었습니다. 현재 vLLM은 GitHub에서 46,000개의 별을 넘어섰으며, 대규모 모델 추론 프레임워크에서 스타 프로젝트가 되었습니다.
2025년 1월 27일vLLM 팀이 v1 알파 버전을 출시했습니다.핵심 아키텍처는 지난 2년간의 개발 작업을 바탕으로 체계적으로 재구성되었습니다.이 업데이트된 버전 v1의 핵심은 실행 아키텍처의 포괄적인 재구성입니다.모델 실행 로직에 집중하기 위해 분리된 EngineCore를 도입하여 다중 프로세스 심층 통합을 채택하고, ZeroMQ를 통해 CPU 작업 병렬화와 다중 프로세스 심층 통합을 실현하며, API 계층과 추론 코어를 명확하게 분리하여 시스템 안정성을 크게 향상시켰습니다.
동시에, 정교한 스케줄링 세분성, 추측적 디코딩 지원, 청크별 사전 채우기 등의 기능을 갖춘 통합 스케줄러가 도입되었습니다.높은 처리량을 유지하면서 지연 시간 제어 기능을 개선합니다.
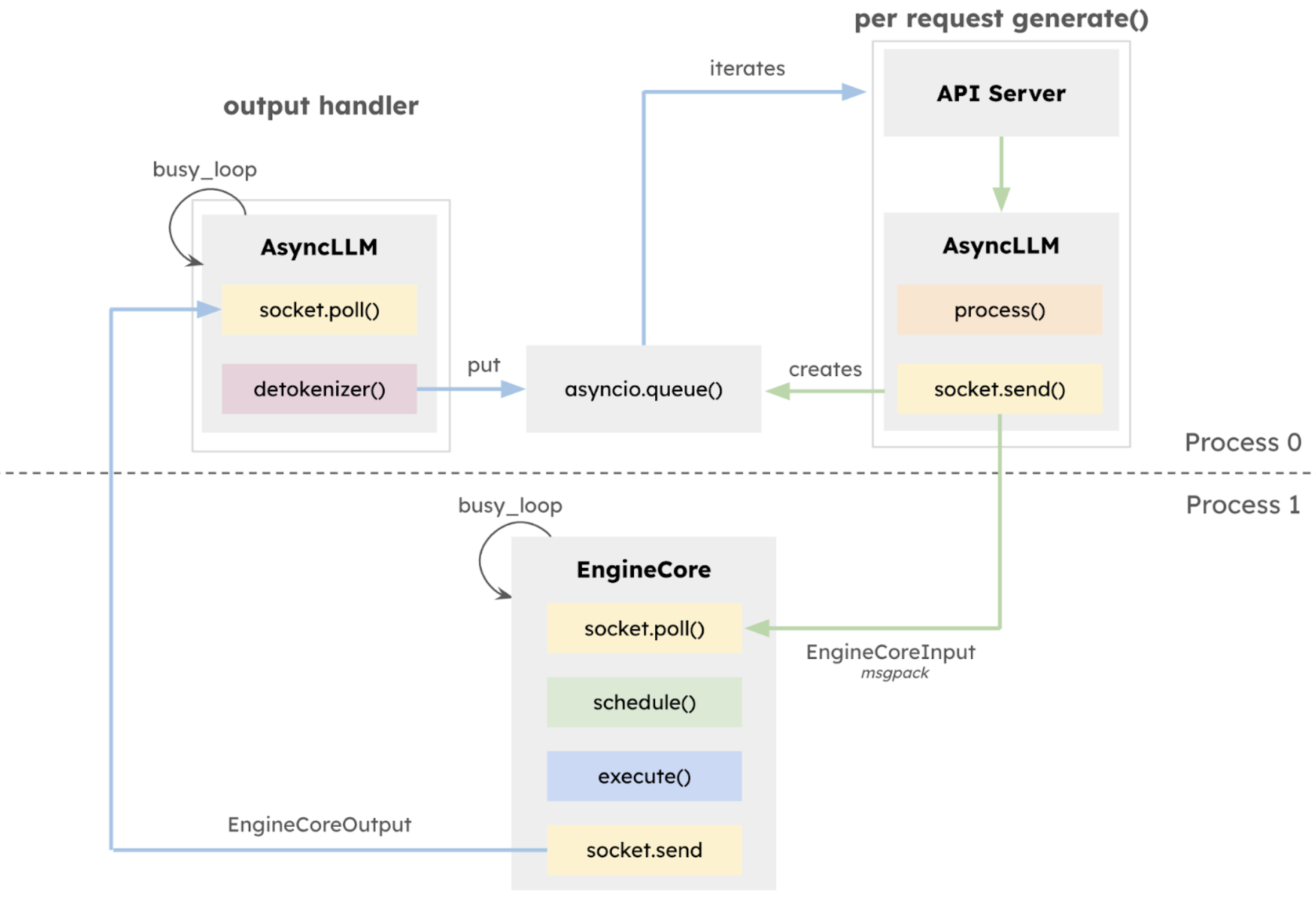
또한,vLLM v1은 획기적인 무단계 스케줄링 설계를 채택했습니다.사용자 입력 및 모델 출력 토큰 처리가 최적화되었고, 스케줄링 로직이 간소화되었습니다. 스케줄러는 청크 사전 채우기 및 접두사 캐싱을 지원할 뿐만 아니라 추측 디코딩도 수행하여 추론 효율성을 효과적으로 개선할 수 있습니다.
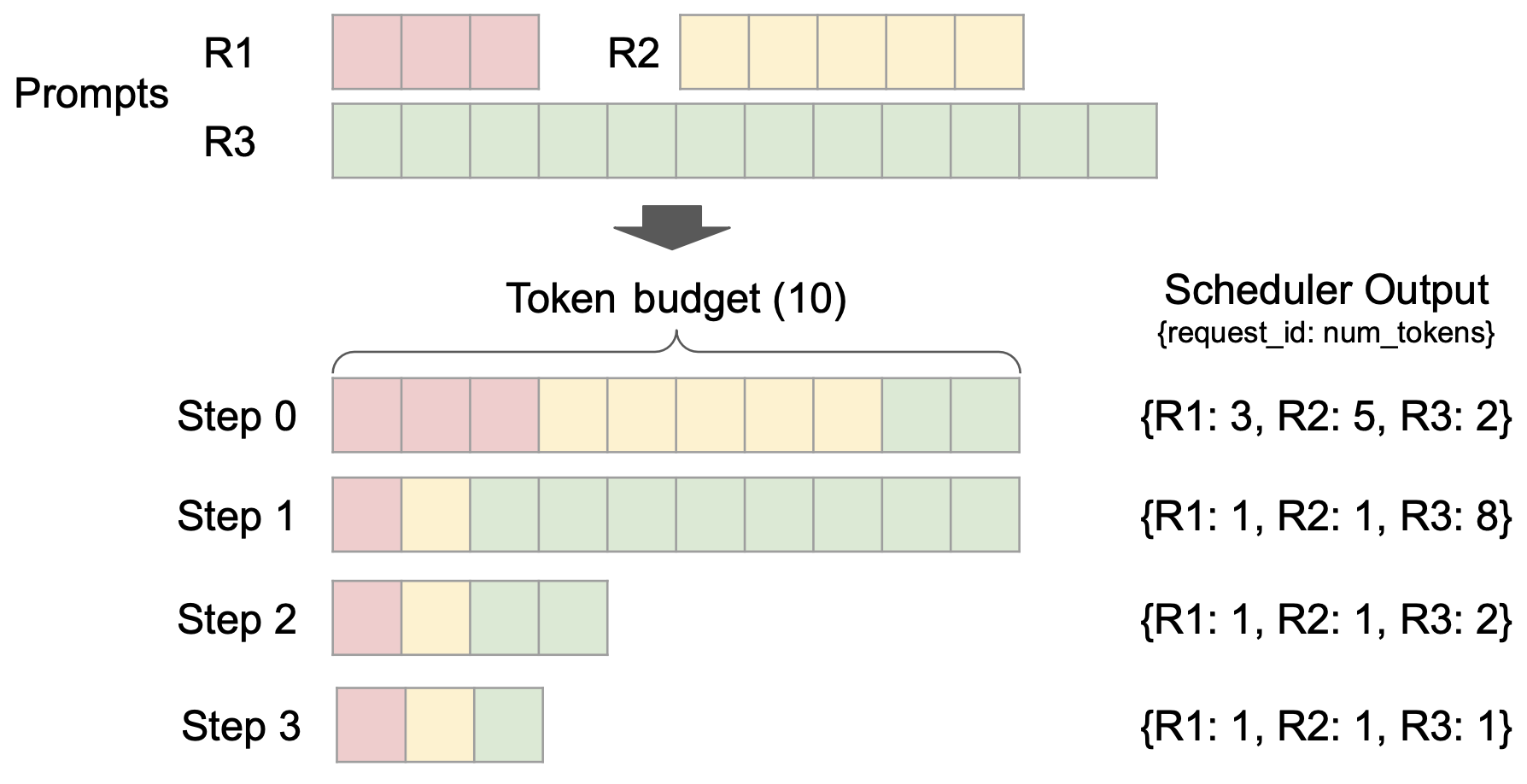
캐시 메커니즘의 최적화도 또 다른 하이라이트입니다. vLLM v1은 오버헤드가 없는 접두사 캐싱을 구현합니다.캐시 적중률이 매우 낮은 긴 텍스트 추론 시나리오에서도 반복 계산을 효과적으로 피하고 추론의 일관성과 효율성을 개선할 수 있습니다.
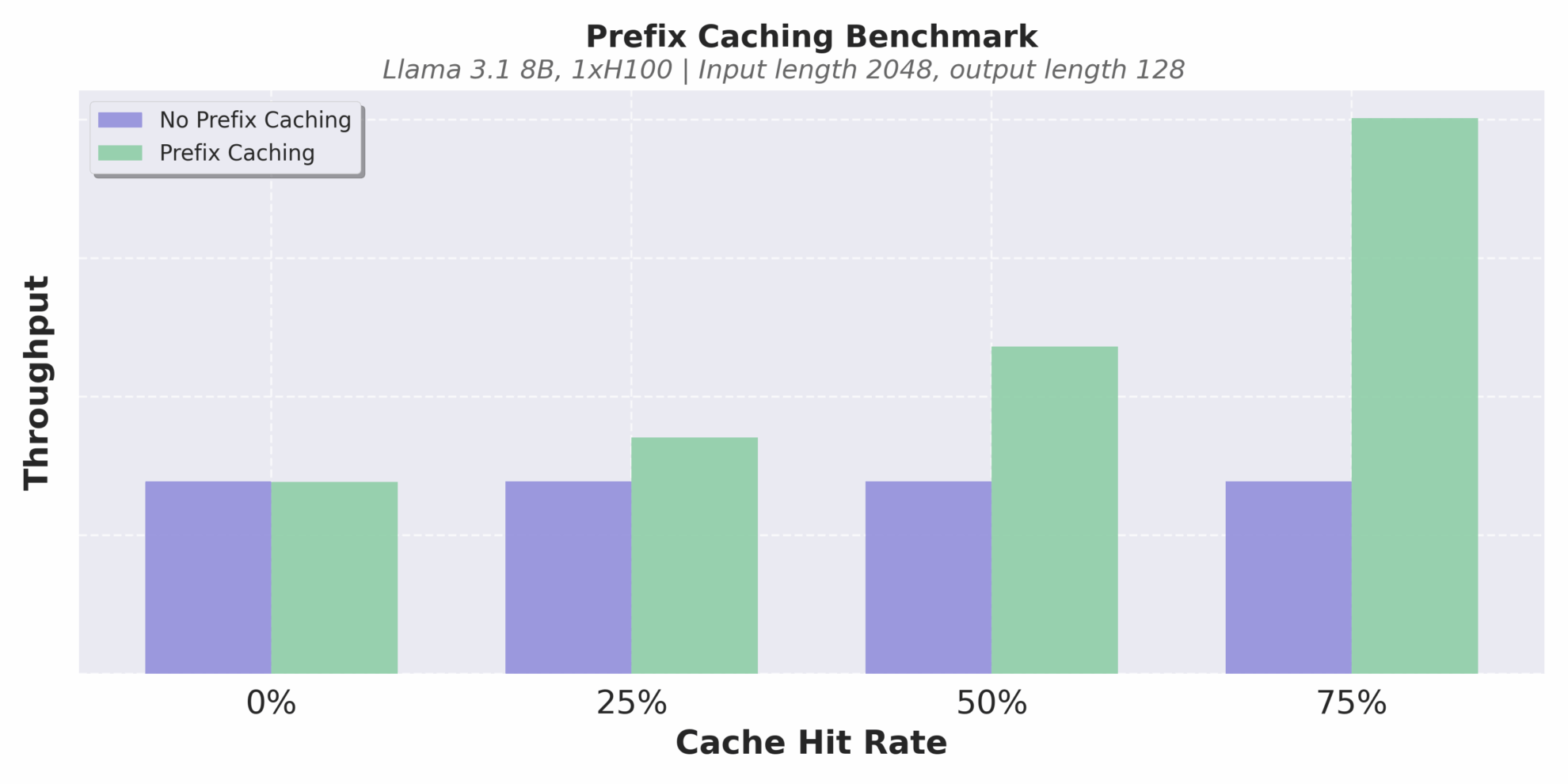
다양한 캐시 적중률에서의 처리량
아래 그림에서 볼 수 있듯이, vLLM v1의 처리량은 v0에 비해 최대 1.7배 증가하였고, 특히 QPS가 높은 경우 성능 향상이 더욱 두드러졌습니다. 알파 버전인 vLLM v1은 아직 활발하게 개발 중이며 안정성과 호환성 문제가 있을 수 있지만 아키텍처 발전 방향은 고성능, 높은 유지 관리성, 높은 모듈성을 명확히 지향하고 있어 후속 팀이 새로운 기능을 신속하게 개발할 수 있는 견고한 기반을 마련해 줍니다.
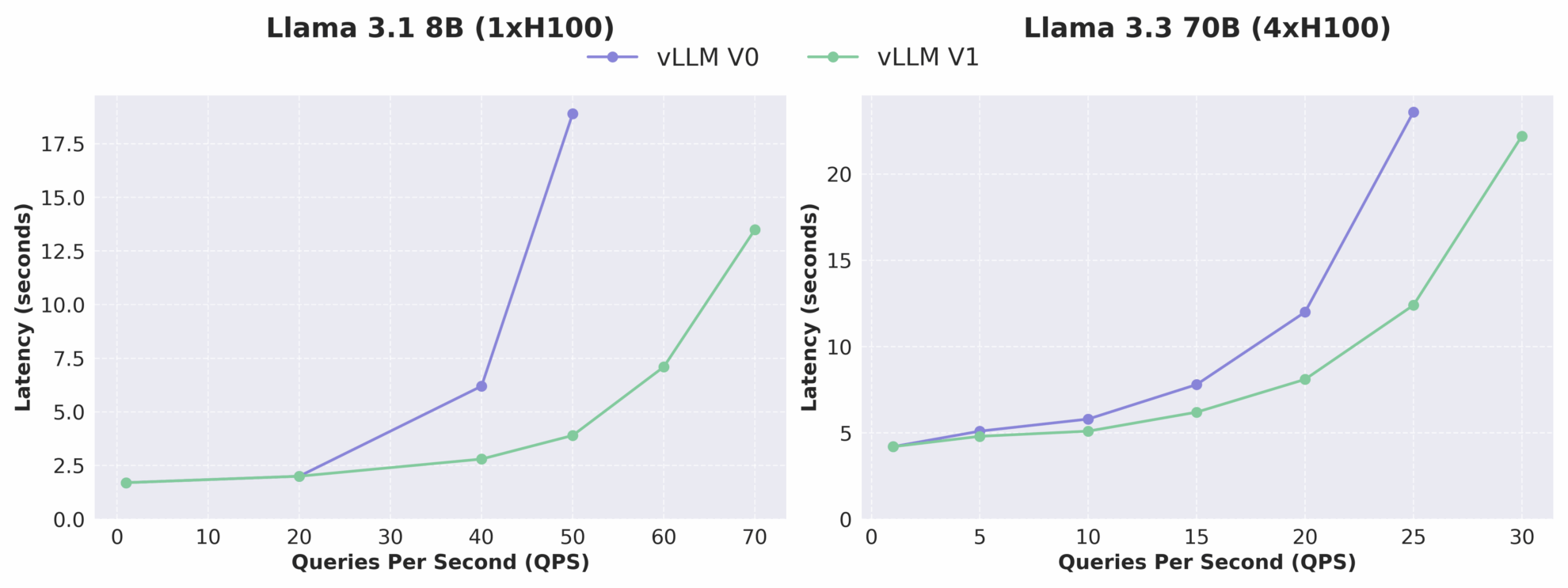
vLLM V0와 V1의 지연시간-QPS 관계 비교
지난달에도 vLLM 팀은 모델 호환성과 추론 안정성을 개선하는 데 중점을 두고 사소한 버전 업데이트를 수행했습니다. 업데이트된 vLLM v0.8.5 버전은 Qwen3 및 Qwen3MoE 모델에 대한 첫날 지원을 도입하고, 융합된 FP8_W8A8 MoE 커널 구성을 추가하고, 다중 모드 시나리오에서 중요한 버그를 수정하고, 프로덕션 환경에서의 성능 견고성을 더욱 향상시킵니다.
vLLM을 보다 효율적으로 시작할 수 있도록 돕기 위해 편집자는 기본 설치부터 추론 배포까지 전체 프로세스를 다루는 일련의 실용적인 튜토리얼과 모델 사례를 편집했습니다.모든 사람이 빠르게 시작하고 심층적으로 이해할 수 있도록 도와주세요. 관심 있는 친구 여러분, 와서 경험해 보세요!
더 많은 vLLM 중국어 문서와 튜토리얼은 다음에서 찾을 수 있습니다.
기본 튜토리얼
1 . vLLM 시작하기 튜토리얼: 초보자를 위한 단계별 가이드
* 온라인 실행:https://go.hyper.ai/Jy22B
이 튜토리얼에서는 vLLM을 구성하고 실행하는 방법을 단계별로 보여주고, vLLM 설치, 모델 추론, vLLM 서버 시작 및 요청 방법에 대한 완전한 시작 가이드를 제공합니다.
2 . vLLM을 사용하여 Qwen2.5에 대해 추론하기
* 온라인 실행:https://go.hyper.ai/SwVEa
이 튜토리얼에서는 모델 로딩, 데이터 준비, 추론 프로세스 최적화, 결과 추출 및 평가를 포함하여 3B 매개변수를 사용하는 대규모 언어 모델에서 추론 작업을 수행하는 방법을 자세히 보여줍니다.
3 . vLLM을 사용하여 대형 모델 로드 , 퓨샷 학습 수행
* 온라인 실행:https://go.hyper.ai/OmVjM
이 튜토리얼에서는 vLLM을 사용하여 Qwen2.5-3B-Instruct-AWQ 모델을 로드하여 몇 번의 학습을 진행합니다. 유사한 질문을 얻어 대화를 구축하기 위한 훈련 데이터를 검색하는 방법, 모델을 사용하여 다양한 출력을 생성하는 방법, 오해를 추론하는 방법, 통합 순위를 위한 관련 방법을 결합하는 방법 등을 자세히 설명하여 데이터 준비부터 결과 제출까지 완전한 프로세스를 달성합니다.
4 . LangChain과 vLLM 결합 , 지도 시간
* 온라인 실행:https://go.hyper.ai/Y1EbK
이 튜토리얼은 LangChain을 vLLM과 함께 사용하는 데 중점을 두고, 기본 설정에서 고급 기능 애플리케이션까지 광범위한 내용을 다루며 스마트 LLM 애플리케이션 개발을 단순화하고 가속화하는 것을 목표로 합니다.
대규모 모델 배포
1 . vLLM을 사용하여 Qwen3-30B-A3B 배포
* 발급 기관:알리바바 퀸 팀
* 온라인 실행:https://go.hyper.ai/6Ttdh
Qwen3-235B-A22B는 코드, 수학, 일반 기능 등의 벤치마크 테스트에서 DeepSeek-R1, o1, o3-mini, Grok-3, Gemini-2.5-Pro와 비슷한 성능을 보였습니다. Qwen3-30B-A3B의 활성화된 매개변수 수는 QwQ-32B의 10%에 불과하지만 성능은 더 우수하다는 점이 언급할 가치가 있습니다. Qwen3-4B와 같은 작은 모델조차도 Qwen2.5-72B-Instruct의 성능에 필적할 수 있습니다.
2 . vLLM을 사용하여 GLM-4-32B 배포
* 발급 기관:Zhipu AI, 칭화대학교
* 온라인 실행:https://go.hyper.ai/HJqqO
GLM-4-32B-0414는 코드 엔지니어링, 아티팩트 생성, 함수 호출, 검색 기반 질의응답 및 보고서 생성 분야에서 좋은 성과를 거두었습니다. 특히 코드 생성이나 특정 질의응답 작업과 같은 여러 벤치마크에서 GLM-4-32B-Base-0414는 GPT-4o 및 DeepSeek-V3-0324(671B)와 같은 대형 모델과 비슷한 성능을 달성합니다.
3 . vLLM을 사용한 배포 , DeepCoder-14B-미리보기
* 발급 기관:Agentica 팀, Together AI
* 온라인 실행:https://go.hyper.ai/sYwfO
이 모델은 DeepSeek-R1-Distilled-Qwen-14B를 기반으로 하며 분포 강화 학습(RL)을 통해 미세 조정되었습니다. 140억 개의 매개변수를 가지고 있으며 LiveCodeBench v5 테스트에서 60.6%의 Pass@1 정확도를 달성했습니다. 이는 OpenAI의 o3-mini와 비슷합니다.
4 . vLLM을 사용한 배포 , 젬마-3-27B-IT
* 발급 기관:메타GPT 팀
* 온라인 실행:https://go.hyper.ai/0rZ7j
Gemma 3는 텍스트와 이미지 입력을 처리하고 텍스트 출력을 생성할 수 있는 대규모 멀티모달 모델입니다. 사전 훈련된 변형과 지침에 맞춰 조정된 변형 모두 다양한 텍스트 생성 및 이미지 이해 작업(질문에 대한 답변, 요약, 추론 포함)에 대한 개방형 가중치를 제공합니다. 비교적 작은 크기 덕분에 리소스가 제한된 환경에서도 배포가 가능합니다. 이 튜토리얼에서는 모델 추론을 위한 데모로 gemma-3-27b-it을 사용합니다.
더 많은 응용 프로그램
1 .오픈매너스 + QwQ-32B , AI 에이전트 구현
* 발급 기관:메타GPT 팀
* 온라인 실행:https://go.hyper.ai/RqNME
OpenManus는 MetaGPT 팀이 2025년 3월에 출시한 오픈 소스 프로젝트입니다. 이 프로젝트는 Manus의 핵심 기능을 복제하고 초대 코드 없이도 로컬에 배포할 수 있는 지능형 에이전트 솔루션을 사용자에게 제공하는 것을 목표로 합니다. QwQ는 Qwen 급수의 추론 모델입니다. 기존의 명령어 튜닝 모델과 비교했을 때, QwQ는 사고 및 추론 능력을 갖추고 있으며, 특히 어려운 문제를 다루는 다운스트림 작업에서 상당한 성능 향상을 이룰 수 있습니다. 이 튜토리얼은 QwQ-32B 모델과 gpt-4o를 기반으로 OpenManus에 대한 추론 서비스를 제공합니다.
2 .RolmOCR 크로스 시나리오 초고속 OCR , 새로운 오픈소스 식별 벤치마크
* 발급 기관:리덕토 AI
* 온라인 실행:https://go.hyper.ai/U3HRH
RolmOCR은 Qwen2.5-VL-7B 시각 언어 모델을 기반으로 개발된 오픈 소스 OCR 도구입니다. 이 도구는 olmOCR과 같은 유사 도구보다 성능이 뛰어나며 이미지와 PDF에서 텍스트를 빠르고 메모리 사용량 없이 추출할 수 있습니다. RolmOCR은 PDF 메타데이터에 의존하지 않아 프로세스가 간소화되고 손으로 쓴 메모와 학술 논문 등 다양한 문서 유형을 지원합니다.
위 내용은 편집자가 작성한 vLLM 관련 튜토리얼입니다. 관심이 있으시다면, 직접 와서 경험해 보세요!
국내 사용자들이 vLLM을 더 잘 이해하고 적용할 수 있도록 돕기 위해,HyperAI 커뮤니티 자원봉사자들은 협력하여 최초의 vLLM 중국어 문서를 완성했으며, 이 문서는 현재 hyper.ai에서 모두 이용할 수 있습니다.이 콘텐츠는 모델 원칙, 배포 튜토리얼, 버전 해석 등을 다루며, 중국 개발자에게 체계적인 학습 경로와 실용적인 리소스를 제공합니다.
더 많은 vLLM 중국어 문서와 튜토리얼은 다음에서 찾을 수 있습니다.https://vllm.hyper.ai