Command Palette
Search for a command to run...
CVPR 2025에 선정된 하얼빈 공업대학 팀은 기가픽셀 병리학 전체 슬라이스 이미지를 빠르게 처리하기 위한 계층적 증류 다중 인스턴스 학습 프레임워크 HDML을 제안했습니다.

병리학적 이미지에는 풍부한 표현형 정보가 포함되어 있으며, 병리학적 이미지를 기반으로 한 병리학적 진단은 암 진단의 "골드 스탠다드"로 널리 알려져 있습니다. 그 중 Whole Slide Image(WSI)는 전체 슬라이드 디지털 스캐닝 기술을 사용하여 병리 조직 슬라이스를 최대 10억 픽셀의 디지털 이미지로 변환하는 고해상도 디지털 병리 이미지입니다. 고해상도, 파노라마 디스플레이, 대용량 데이터라는 특징을 가지고 있습니다. 이는 현재 의학 진단 및 의학 연구의 주류를 이루는 방법입니다.
다중 인스턴스 학습(MIL)은 WSI를 분석하는 주요 방법 중 하나이며 종양 감지, 조직 미세환경 정량화, 생존 예측과 같은 작업에서 좋은 성과를 거두었습니다. 하지만 WSI는 엄청난 양의 정보를 담고 있기 때문에 MIL을 이용한 추론은 비용이 많이 든다는 과제에 직면하게 됩니다. 첫 번째는 데이터 전처리 문제입니다. WSI 자르기 및 기능 추출 과정은 매우 시간이 많이 걸립니다. 두 번째는 중복 패치 문제입니다. WSI는 일반적으로 중복 패치를 포함하고 있으며, 이는 가방 수준 분류에 가장 적게 기여합니다. 위의 문제를 해결하는 가장 간단한 방법은 주의 점수를 통해 관련 없는 예를 제거하는 것입니다. 그러나 기존 MIL 알고리즘은 주의 점수를 계산하기 전에 모든 잘린 블록의 특징을 추출해야 하며, 이는 의심할 여지 없이 "닭과 달걀" 문제를 야기합니다.
위의 분석을 바탕으로 중국 하얼빈 공업대학의 장쥔쥔 교수, 장쿠이 부교수, 하얼빈 공업대학(선전)의 장융빙 교수 등은 추론 시간을 단축할 수 있는 혁신적인 솔루션을 시연했습니다. 이 팀은 관련 없는 패치를 빠르게 식별하여 빠르고 정확한 분류를 달성하는 것을 목표로 하는 계층적 증류 다중 인스턴스 학습 프레임워크(HDMIL)를 제안했습니다. 실험 결과에 따르면, 기존의 고급 방법과 비교했을 때 HDMIL은 3개의 공개 데이터 세트에 대한 추론 시간을 28.6%만큼 단축했습니다.
관련 결과는 "계층적 증류 다중 인스턴스 학습을 통한 빠르고 정확한 기가픽셀 병리학적 이미지 분류"라는 제목으로 출판되었으며 CVPR 2025에 선정되었습니다.
연구 하이라이트:
* 제안된 방법은 추론 과정을 가속화하는 동시에 분류 성능을 향상시켜 기존 방법에서는 달성할 수 없는 속도와 성능 간의 균형을 이루며 다중 인스턴스 분류에 대한 미래 연구에 영감을 제공합니다.
*이 방법은 체비셰프 다항식을 기반으로 한 콜모고로프-아놀드 분류기를 처음으로 시연하고 이를 디지털 병리학에 적용하여 분류 성능을 크게 향상시켰습니다.
* 제안된 방법은 다수의 실험을 통해 검증되었으며, 3개의 공개 데이터셋에 대해 신뢰할 수 있고 효과적인 검증 결과를 얻었습니다.

서류 주소:
https://arxiv.org/abs/2502.21130
데이터 세트: 3개의 주요 공개 데이터 세트가 효과를 검증합니다.
실험의 효과를 보장하기 위해 연구진은 세 가지 공개 데이터 세트에서 제안된 방법의 효과를 평가했습니다.
* Camelyon16 데이터셋은 유방암 림프절 전이 검출에 사용되었으며, 훈련 세트와 검증 세트의 비율은 공식 훈련 세트에 따라 9:1로 나뉘고, 공식 테스트 세트는 모든 폴드에 대한 테스트에 사용되었습니다.
*폐암 분류에는 TCGA-NSCLC 데이터 세트가 사용되었습니다. 데이터 세트는 8:1:1의 비율로 훈련 세트, 검증 세트, 테스트 세트로 나뉘었습니다.
* TCGA-BRCA 데이터셋을 유방암 하위 유형 분류에 사용할 경우 학습 세트, 검증 세트, 테스트 세트의 비율도 8:1:1입니다.
모든 WSI가 CLAM에서 개발한 도구를 사용하여 전처리되었고, 실험은 10겹 몬테카를로 교차 검증을 따랐다는 점이 주목할 만합니다.
모델 아키텍처: 2단계 아키텍처는 학습과 추론을 포함하며 혁신적으로 Kolmogorov-Arnold 분류기를 도입합니다.
연구소가 제안한 HDMIL 프레임워크는 훈련과 추론이라는 두 부분으로 구성됩니다. 이 프레임워크에는 두 가지 핵심 구성 요소가 있습니다. 하나는 고해상도 WSI를 분류하고 가방 수준 분류와 관련이 없는 인스턴스를 식별하도록 설계된 동적 다중 인스턴스 네트워크(DMIN)입니다. 다른 하나는 저해상도 WSI에 특별히 맞춰진 네트워크인 LIPN(Lightweight Instance Prescreening Network)입니다.
연구자들은 훈련에 앞서 먼저 병리학적 WSI에 대한 표준 절차에 따라 입력 데이터를 사전 처리했습니다. 데이터 세트는 슬라이드 레이블이 있는 S WSI 피라미드로 구성되며, 각 Xᵢ에는 고해상도(20배)와 저해상도(1.25배) WSI 쌍이 포함되어 있으며, 각각 Xᵢ,ₕᵣ 및 Xᵢ,ₗᵣ로 표시됩니다.
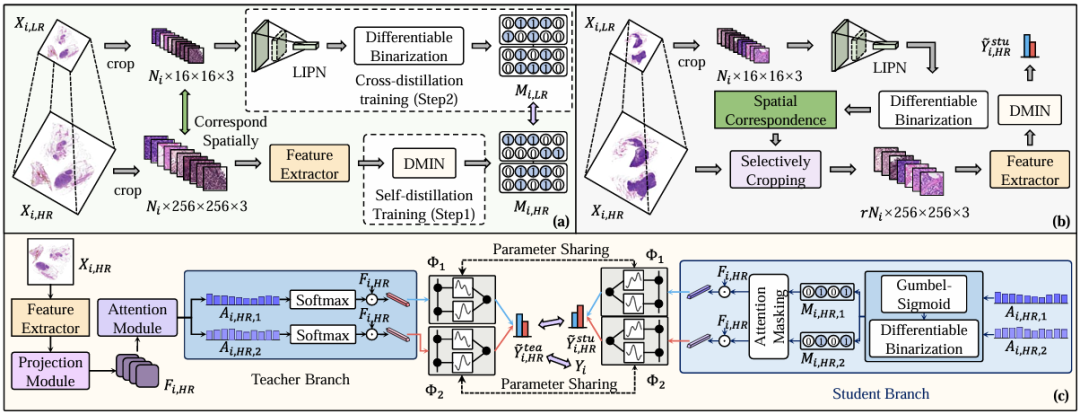
구체적으로, 그림 a는 다음 그림에서 볼 수 있듯이 훈련 단계를 보여줍니다. 연구진은 먼저 고해상도 WSI(Xᵢ,ₕᵣ)를 사용하여 DMIN을 훈련하기 위해 자체 증류 훈련 전략을 채택하여 가방 수준 분류를 수행하고 관련 없는 영역을 표시할 수 있었습니다. DMIN은 WSI에서 관련 없는 영역을 성공적으로 식별했지만 추론 속도는 향상되지 않았습니다. DIMN은 기능 추출기에서 생성된 모든 패치의 기능을 사용하여 어떤 인스턴스를 제거해야 할지 결정해야 하며, 패치별 기능 추출은 실제로 WSI 추론 속도의 병목 현상을 해소하는 핵심입니다.
따라서 연구진은 DMIN을 동결시키고 그 결과로 생성된 마스크를 사용해 LIPN을 추출했습니다. 위에서 언급했듯이 LIPN은 저해상도 WSI에 맞춰 제작된 가벼운 인스턴스 사전 검토 네트워크입니다. 저해상도 WSI(Xᵢ,ₗᵣ)를 사용하여 교차 증류를 통해 학습되었으며 저해상도 WSI에서 관련 없는 영역을 빠르게 식별하여 고해상도 WSI에서 관련 없는 패치를 간접적으로 나타낼 수 있습니다.
구체적인 구현 측면에서 연구진은 ImageNet에서 사전 학습된 모델인 널리 사용되는 ResNet-50을 특징 추출기로 채택하고, 사전 스크리닝 네트워크 LIPN에는 MobileNetV4의 경량 변형을 사용했습니다. 위의 단계를 거쳐 연구진은 매우 낮은 계산 비용으로 각 지역의 이진 중요도(중요도 또는 비중요도) 판단을 달성했습니다.
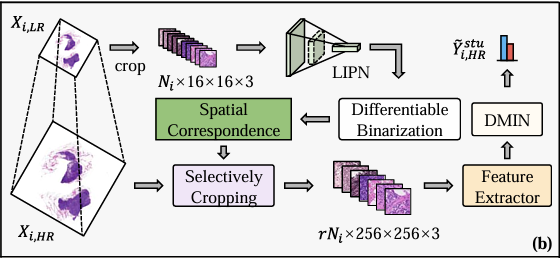
그림 c는 아래와 같이 고해상도 WSI(Xᵢ,ₕᵣ)에 대한 DMIN의 자체 증류 훈련을 보여줍니다. DMIN은 Projection 모듈, Attention 모듈, Teacher 분기, Student 분기, CKA 분류기를 포함한 5개의 모듈로 구성되어 있음을 알 수 있습니다.

구체적으로, 고해상도 WSI(Xᵢ,ₕᵣ)에서 추출된 모든 패치는 먼저 사전 학습된 기능 추출기에 입력되어 예제 수준 기능 세트 Iᵢ,ₕᵣ를 생성합니다. 그런 다음 이 기능 세트는 차원 축소를 위해 투영 모듈에 입력되어 새로운 기능 세트 Fᵢ,ₕᵣ를 얻습니다. 그런 다음 이 기능 세트는 비정규화된 주의 점수를 계산하기 위해 주의 모듈에 입력됩니다.
교사 분기에서는 축소된 Fᵢ,ₕᵣ에 각 클래스의 주의 행렬을 사용하여 선형적으로 가중치를 부여하여 최종 분류에 대한 백 수준 표현을 생성합니다. 학생 브랜치에서는 주의 점수가 큰 일부 예제만 사용하여 가방 수준 표현을 계산하고, 연구자들은 또한 가방 수준 표현이 모든 인스턴스를 사용하여 교사 브랜치에서 얻은 표현과 최대한 일관성이 있도록 제약 조건을 부과합니다. 이 방법을 통해, 가방 수준 분류에 더 중요한 인스턴스에 더 많은 주의를 기울이고 관련 없는 인스턴스를 걸러내는 주의 모듈이 구현됩니다. 동시에 최적화 과정에서는 Gumbel 트릭을 채택하여 주의 점수가 높은 인스턴스를 선택적으로 사용하여 종단 간 학습을 수행함으로써 미분 불가능한 문제가 발생하는 것을 방지합니다.
마지막으로, MIL 분류기의 성능을 향상시키기 위해 연구진은 분류기에서 고정된 활성화 함수를 사용하는 대신 콜모고로프-아놀드 네트워크를 사용하여 비선형 활성화 함수를 학습하는 것을 제안했습니다. 그리고 하이브리드 손실 함수를 설계함으로써 연구자들은 DMIN에 대한 세 가지 훈련 목표를 달성했습니다. 첫 번째는 교사 분기가 Xᵢ,ₕᵣ를 올바르게 분류할 수 있다는 것입니다. 두 번째는 학생 분기에서 일부 인스턴스를 사용한 분류 결과가 교사 분기에서 모든 인스턴스를 사용한 분류 결과와 일치할 수 있다는 것입니다. 세 번째는 선택된 인스턴스의 비율을 제어할 수 있어야 한다는 것입니다.
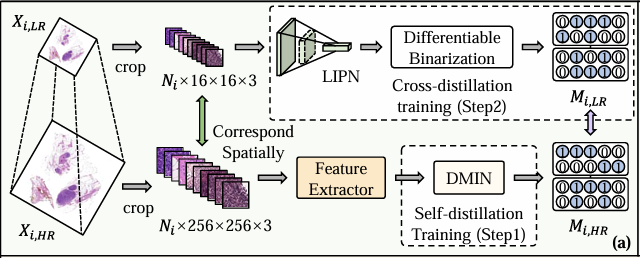
그림 b는 아래와 같이 추론 단계를 보여줍니다. 구체적인 프로세스는 세 단계로 나눌 수 있습니다. 첫 번째 단계는 총 Nᵢ인 저해상도 WSI(Xᵢ,ₗᵣ)의 모든 패치를 자르는 것입니다. 두 번째 단계는 이러한 패치를 LIPN에 입력하여 분류 관련 영역을 식별하고 Mᵢ,ₗᵣ을 생성하는 것입니다. 세 번째 단계는 Mᵢ,ₗᵣ을 기반으로 Xᵢ,ₕᵣ의 해당 패치를 선택적으로 잘라낸 다음 나머지 패치를 피처 추출기와 DMIN에 입력하고 마지막으로 교차 범주 학생 분기를 통해 별도로 계산하여 최종 분류 결과를 생성하는 것입니다.
연구 결과: "단순화된" HDMIL은 여전히 기존의 고급 방법보다 성능이 우수합니다.
연구진은 Camelyon16, TCGA-NSCLC, TCGA-BRCA의 세 가지 데이터 세트를 기반으로 Max-pooling, Mean-Pooling, ABMIL, CLAMSB, CLAMMB, DSMIL, TransMIL, DTFDAFS, DTFDMAS, S4MIL, MambaMIL을 포함한 11가지 MIL 방법과 HDMIL의 분류 성능을 비교했습니다.
연구원들이 HDMIL†과 HDMIL 등 다양한 HDMIL 구성을 테스트했다는 점은 언급할 가치가 있습니다. 전자는 LIPN을 통한 사전 검토 없이 DMIN만 추론에 사용된다는 것을 의미합니다. 구체적인 결과는 아래 그림과 같습니다.
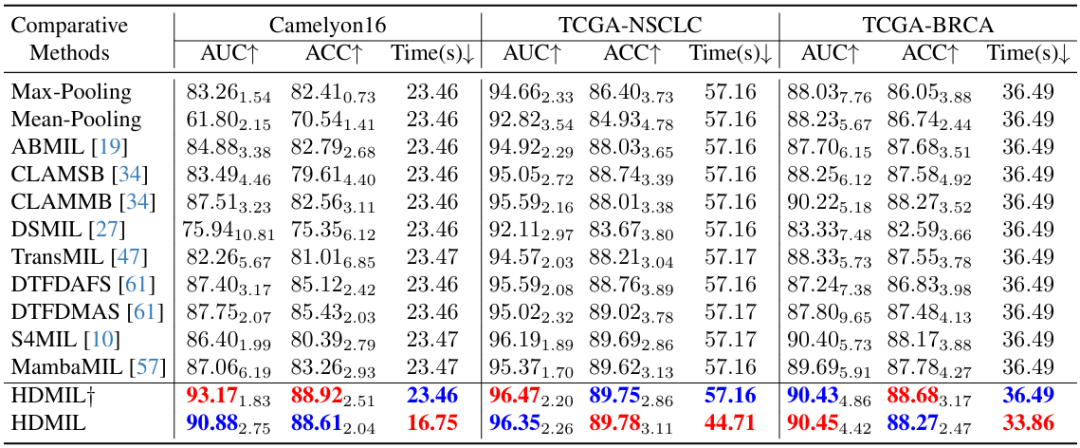
HDMIL†과 HDMIL 모두 기존 방법보다 3가지 데이터 세트에서 지속적으로 더 나은 테스트 결과를 보이는 것을 알 수 있습니다. 예를 들어, Camelyon16 데이터 세트에서 HDMIL은 90.88%의 AUC와 88.61%의 정확도를 달성했는데, 이는 각각 이전의 가장 좋은 방법보다 3.13%와 3.18% 더 높은 수치입니다.
동시에 데이터 세트가 충분히 클 경우 HDML은 분류 성능에 영향을 주지 않고 속도를 향상시킵니다. 예를 들어, TCGA-NSCLC와 TCGA-BRCA의 경우 두 연구 모두 약 1,000개의 WSI를 포함하고 있지만, HDML†과 HDML 간의 테스트 성능 격차는 크지 않아 HDML이 추론 속도와 분류 성능 간에 우수한 균형을 이루고 있음을 보여줍니다.
또한 HDMIL†은 기존의 다른 방식과 처리 시간이 비슷한데, HDMIL은 다른 방식과 동일한 수의 고해상도 패치를 처리해야 하기 때문에 모든 방식보다 성능이 훨씬 뛰어납니다. HDMIL은 LIPN을 통해 데이터 처리에 소요되는 시간을 줄여, 3가지 데이터 세트에 대해 다른 방법에 비해 추론에 소요되는 시간을 크게 줄여 각각 28.6%, 21.8%, 7.2%의 속도 증가를 달성했습니다.
연구진은 각 구성 요소의 영향을 분석하기 위해 아래 그림과 같이 HDML의 각 모듈이 분류 결과에 미치는 영향을 더욱 자세히 보여주기 위해 절제 실험을 수행했습니다. 연구 결과에 따르면 기존의 선형 계층 기반 분류기를 제안된 CKA 분류기로 대체하고 DMIN 학습에 자가 증류를 통합하면 분류 성능이 크게 향상됩니다.

전반적으로 HDMIL 제안은 의심할 여지 없이 새로운 아이디어이자 시도입니다. 이 아이디어의 실현 가능성은 수많은 실험을 통해 입증되었습니다. 이는 MIL 방법을 사용하여 병리학적 이미지, 특히 WSI를 분석하는 새로운 방법을 제공하고 디지털 병리학의 활발한 발전을 가속화합니다.
AI로 디지털 병리학이 발전합니다
최근 몇 년 동안 디지털 병리학의 활발한 발전으로 의학과 생물학 분야에서 새로운 진전이 이루어졌으며, 특히 인류의 가장 큰 적 중 하나인 암과의 싸움에서 중요한 역할을 했습니다. HDMIL 제안이 하얼빈 공업대학 팀이 이 분야에서 시도한 첫 번째 시도는 아니라는 점은 언급할 가치가 있습니다.
작년 CVPR 2024에는 "약한 감독 학습을 통해 지원되는 조직학적 이미지를 위한 가상 면역조직화학 염색"이라는 제목의 연구가 포함되었습니다. 이 논문에서는 가상 면역조직화학(IHC) 염색을 위한 confusion-GAN이라는 약한 지도 학습 방법을 언급했는데, 이는 H&E 이미지를 IHC 이미지로 변환하여 IHC 염색에서 기존 방법의 번거롭고 비용이 많이 드는 문제를 해결할 수 있습니다.

논문 주소: https://openaccess.thecvf.com/content/CVPR2024/papers/Li_Virtual_Immunohistochemistry_Staining_for_Histological_Images_Assisted_by_Weakly-supervised_Learning_CVPR_2024_paper.pdf
본 논문은 위에 언급된 연구진과 동일한 저자들 외에도 장쥔쥔 교수와 장융빙 교수가 공동으로 집필하였으며, 이를 통해 하얼빈 공업대학이 이 분야에서 깊이 있는 연구와 축적을 하고 있음을 더욱 확인할 수 있었습니다.
물론, 이 논문의 두 책임저자인 장쥔쥔 교수와 장융빙 교수도 특별히 언급할 가치가 있습니다. 장쥔쥔 교수는 현재 하얼빈 공업대학 컴퓨터과학부의 종신 교수이자 박사 과정 지도교수이며, 인공지능부의 부학장, 지능형 인터페이스 및 인간-컴퓨터 상호작용 연구 센터의 부소장을 맡고 있습니다. 그는 국가 청소년 인재 프로그램에 선발되었으며, 하얼빈 공업 대학의 "젊은 과학자 스튜디오"의 학술 리더이기도 합니다. 그의 연구 방향에는 이미지 처리, 컴퓨터 비전, 딥 러닝(연구는 대형 모델과 이미지 처리, 다중 모드 자율 무인 시스템, 생성 인공 지능 등에 초점을 맞춥니다) 및 기타 분야가 포함됩니다.
장용빙 교수는 현재 하얼빈 공업대학 컴퓨터 과학부의 교수이자 박사 학위 지도교수입니다. 그의 주요 연구 분야로는 컴퓨터 비전, 생체의학 영상 처리, 컴퓨터 이미징 등이 있습니다. 장용빙 교수는 또한 다양한 직책을 맡고 있습니다. 그는 중국컴퓨터학회, 중국인공지능학회, IEEE, SPIE, OSA 등 국내외 유명 협회의 회원입니다. 그는 세계 유수의 인공지능 학회에서 100편 이상의 논문을 발표했으며, 50건 이상의 발명 특허를 취득했습니다. 현재 장용빙 교수의 주요 연구는 생명의학과 의료 건강 분야에서 인공지능과 컴퓨터 비전의 응용 분야를 탐구하는 것입니다.
하얼빈 공업대학 외에도 점점 더 많은 대학과 연구실에서 디지털 병리학 분야에 주목하고 있으며, 이에 대한 노력을 기울이고 있습니다. 예를 들어, 네덜란드 에인트호번 공과대학의 한 팀은 "디지털 병리학을 위한 공간 인식 다중 인스턴스 학습 프레임워크"라는 제목의 연구를 발표했는데, 여기서 글로벌 ABMIL(GABMIL)이라는 모델을 제안했습니다. 이 모델은 기존 ABMIL 모델을 개선한 버전입니다. 공간 정보 혼합 모듈을 통해 공간 정보를 임베딩 벡터에 통합한 다음 ABMIL 네트워크를 사용하여 슬라이스 레이블을 예측함으로써 병리학적 진단의 핵심 요소인 영상 블록 간의 공간적 상호 작용 정보를 종종 무시하는 기존 MIL 방법을 피할 수 있습니다.
논문 주소: https://arxiv.org/abs/2504.17379
간단히 말해, 인공지능과 전통의학의 통합은 돌이킬 수 없으며, 누구나 그 혜택을 누릴 수 있습니다. 인공지능과 의학의 교차 통합을 응용할 수 있는 기회를 제공하는 것은 과학의 최전선에 헌신하는 이러한 "탐험가"들이라는 사실은 부인할 수 없습니다. 물론, 장기간에 걸쳐 심도 있는 연구를 통해 하얼빈 공업대학 팀이 이곳에 뿌리를 내리고, 이를 통해 전체 분야의 발전을 가속화할 것이라는 믿음이 생겼습니다.