Command Palette
Search for a command to run...
확산 모델 × 음악 생성, DiffRhythm은 단 몇 분 만에 노래 제작을 완료합니다! MiniMind 데이터 세트는 배포 장벽이 낮은 대규모 언어 모델을 활성화하기 위해 오픈 소스로 제공됩니다.

음악 생성 분야는 최근 몇 년 동안 상당한 진전을 이루었지만, 기존 모델은 실제 적용에 있어 여전히 많은 한계가 있습니다. 대부분의 모델은 보컬이나 반주 트랙만 독립적으로 생성할 수 있어 일관성 없는 음악적 경험을 제공합니다. 이러한 과제를 해결하기 위해, 노스웨스턴 폴리테크닉 대학의 오디오 음성 및 언어 처리 연구실과 홍콩 중국 대학은 공동으로 DiffRhythm이라는 모델을 개발했습니다.
확산기술을 기반으로 한 최초의 오픈소스 완전곡 생성 모델로서DiffRhythm은 높은 수준의 음악 생성 및 이해도를 유지할 뿐만 아니라 간결하고 효과적인 모델, 아키텍처 및 데이터 처리 파이프라인을 통해 확장성도 보장합니다. 사용자 경험 측면에서 비자기회귀 구조는 빠른 생성 속도를 보장합니다.단 1분 만에 완벽한 음악을 만들어 보세요.
현재 HyperAI는 "DiffRhythm: 1분 안에 완전한 음악 데모 생성" 튜토리얼을 출시했습니다. 와서 드셔보세요~
온라인 사용:https://go.hyper.ai/sHdPu
3월 17일부터 3월 21일까지 hyper.ai 공식 웹사이트가 업데이트되었습니다.
* 고품질 공개 데이터 세트: 10
* 엄선된 고품질 튜토리얼: 2개
* 커뮤니티 기사 선정: 6개 기사
* 인기 백과사전 항목: 5개
* 3월 마감일 상위 컨퍼런스: 1
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
이 데이터 세트는 현재 가장 큰 완전 합성 오픈 소스 데이터 세트로, 코딩 작업에 대한 검증 가능한 솔루션과 테스트를 제공합니다. 여기에는 다양한 분야(알고리즘에서 소프트웨어 패키지별 지식까지)와 난이도(기본 코딩 연습에서 인터뷰 및 경쟁적 프로그래밍 과제까지)를 포괄하는 12개의 서로 다른 하위 집합이 포함되어 있으며, 지도 미세 조정(SFT) 및 RL 조정을 위해 설계되었습니다.
직접 사용:https://go.hyper.ai/CfZCm
이 데이터 세트에는 2.7k개의 이미지가 포함되어 있으며 주로 도로의 움푹 패인 곳, 균열, 열린 맨홀을 감지하는 데 사용됩니다.
직접 사용:https://go.hyper.ai/XPJNQ

이는 51개의 인간 시연 데이터 샘플을 포함하는 작은 데이터 세트로, 데이터와 형식을 이해하고, 코드를 실행하여 훈련 과정을 경험하는 데 유용합니다. 연구 배경은 복잡한 장면에서도 능숙한 파악의 성공률을 높여야 한다는 필요성에서 비롯되었으며, 특히 물체, 조명, 배경의 전례 없는 조합에서 90% 이상의 성공률을 달성해야 한다는 필요성에서 비롯되었습니다.
직접 사용:https://go.hyper.ai/pJ44Y

4. IllusionAnimals 시각적 환상 VQA 데이터 세트
IllusionAnimals 데이터 세트는 2,000개의 샘플을 포함하는 51개의 데이터 세트입니다. 이 데이터 세트에는 10개의 동물 카테고리와 1개의 비착시 카테고리가 포함되어 있으며, 이미지 해상도는 512×512픽셀입니다. 이는 다중 모드 모델이 동물 기반 시각적 환상을 식별하고 설명하는 능력을 평가하는 데 사용됩니다.
직접 사용:https://go.hyper.ai/Ebl40

5. m-WildVision 다국어 다중 모달 대규모 모델 평가 데이터 세트
이 데이터 세트에는 23개 언어로 된 500개의 까다로운 사용자 쿼리 예시가 포함되어 있으며, 각 예시는 WildVision-Arena 플랫폼에서 파생되었습니다. 데이터 세트의 구조에는 질문 ID, 언어 유형, 지침 텍스트, 이미지 데이터가 포함되어 있으며, 다양한 언어에서 모델의 일반화와 견고성을 평가하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/Im6mN

6. MiniMind 대규모 모델 학습 및 미세 조정 데이터 세트
MiniMind는 대규모 언어 모델(LLM) 사용에 대한 임계값을 낮추고 개별 사용자가 일반 장치에서 빠르게 학습하고 추론할 수 있도록 하는 것을 목표로 하는 오픈 소스 경량 대규모 언어 모델 프로젝트입니다.
직접 사용:https://go.hyper.ai/gCz2y
7. Seaclear 해양 쓰레기 탐지 및 분할 데이터 세트
이 데이터 세트에는 객체 감지 및 인스턴스 분할 작업을 위해 주석이 달린 8,610개의 해양 쓰레기 이미지가 포함되어 있으며, 쓰레기뿐만 아니라 관찰된 동물, 식물, 로봇 부품을 포함한 40개의 객체 범주를 다룹니다. 주석은 COCO 형식(.json) 파일로 제공되며, 이미지는 폴더로 정리되어 각 폴더는 고유한 사이트-카메라 쌍에 할당됩니다. 모든 이미지의 해상도는 1920×1080입니다.
직접 사용:https://go.hyper.ai/JFofd
8. 텍스트 및 오디오 캡차 텍스트 및 오디오 캡차 데이터 세트
이 데이터 세트에는 10만 개의 CAPTCHA 샘플이 포함되어 있으며, 각 샘플에는 해당 영숫자 문자열이 레이블되어 있어 OCR 모델, 음성 인식, AI 기반 CAPTCHA 솔버를 학습하는 데 이상적입니다.
직접 사용:https://go.hyper.ai/vFmTJ
이 데이터 세트에는 플라스틱, 종이 및 판지, 유리/금속, 유기물, 폐기물, 섬유, 전자제품(전자 폐기물) 등 다양한 유형의 폐기물을 분류하고 감지하는 데 필요한 이미지와 YOLO 형식 주석이 포함되어 있습니다.
직접 사용:https://go.hyper.ai/NwEF7
10. 화성 표면 이미지(큐리오시티 로버) 화성 표면 이미지 데이터 세트
이 데이터 세트는 화성 과학 연구소(MSL)의 3가지 장비(오른쪽 눈 마스트캠, 왼쪽 눈 마스트캠, MAHLI)를 통해 수집한 6,691개의 이미지로 구성되어 있으며, 24개 범주를 포괄합니다. 이러한 이미지는 각 원시 데이터 제품의 "탐색" 버전이며 전체 해상도가 아니며 이미지당 약 256×256픽셀입니다.
직접 사용:https://go.hyper.ai/B1T0l
선택된 공개 튜토리얼
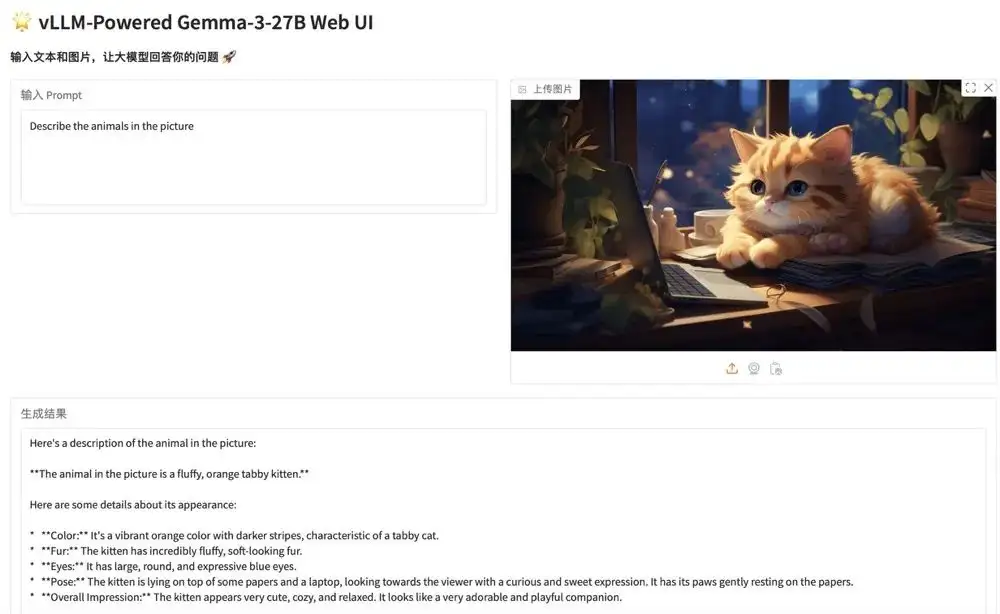
1. vLLM을 사용하여 Gemma-3-27B-IT 배포
Gemma 시리즈는 Google이 오픈 소스로 공개한 대규모 모델 시리즈로, Gemini 모델과 동일한 연구와 기술을 기반으로 구축되었습니다. Gemma 3는 텍스트와 이미지 입력을 처리하고 텍스트 출력을 생성할 수 있는 대규모 멀티모달 모델입니다. 이 모델은 질의응답, 요약, 추론을 포함한 다양한 텍스트 생성 및 이미지 이해 작업에 적합합니다. 비교적 작은 크기 덕분에 노트북, 데스크톱, 클라우드 인프라 등 리소스가 제한된 환경에 배포하는 데 적합합니다.
이 프로젝트의 관련 모델과 종속성이 배포되었습니다. 컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
온라인으로 실행:https://go.hyper.ai/JxVbA
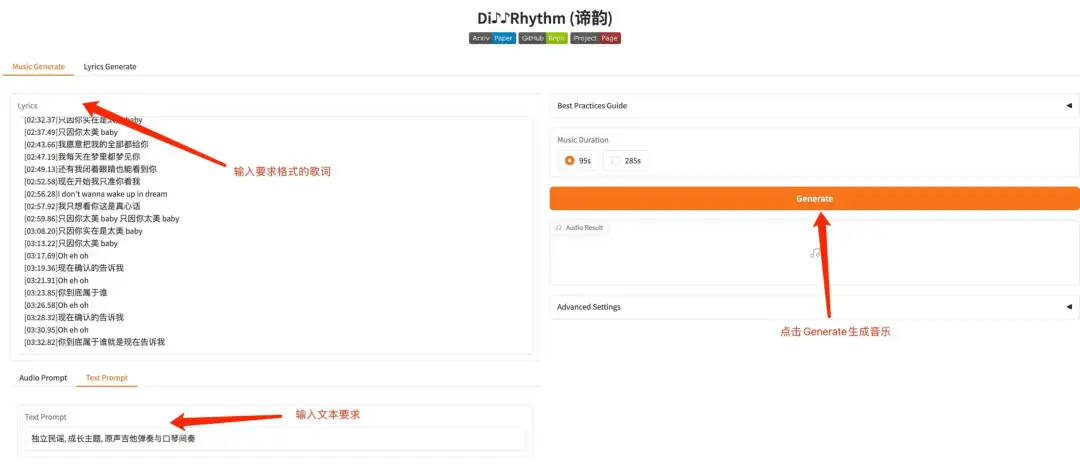
2. DiffRhythm: 1분 안에 완전한 음악 데모를 생성합니다.
DiffRhythm은 전체 노래를 작곡할 수 있는 최초의 확산 기반 노래 생성 모델입니다. 짧은 시간 안에 보컬과 반주를 포함해 최대 4분 45초 길이의 완전한 노래를 생성할 수 있습니다. 사용자는 가사와 스타일 힌트만 제공하면 DiffRhythm이 가사에 맞는 멜로디와 반주를 자동으로 생성해 다국어 입력을 지원합니다.
이 프로젝트의 관련 모델과 종속성이 배포되었습니다. 컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
온라인으로 실행:https://go.hyper.ai/sHdPu
커뮤니티 기사
1. 컴퓨팅 효율성이 3000배 증가했습니다! 라오산 연구실 등은 수치해양예측보다 우수한 성능을 보이는 대규모 지능형 해양환경예측 모델인 '웬하이(Wenhai)'를 제안했다.
우리신(吳立新) 학자 팀은 물리 해양학과 AI를 심층적으로 통합하고, 해양 역학 이론을 사용하여 신경망 아키텍처를 구동하며, 실제 해양의 상태를 더 잘 반영하고 컴퓨팅 시간과 에너지 소비를 크게 절감하기 위해 대규모 글로벌 고해상도 해양 환경 지능형 예측 모델 "원하이(Wenhai)"를 구축했습니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/s7YMj
2. ICLR 2025에 선정되었습니다! 케임브리지 대학에서 제안한 셀코멘 모델은 공간 전사체 분석에서 인과 추론의 식별 가능성을 처음으로 달성했습니다.
케임브리지 대학의 연구팀은 셀코멘(Celcomen)이라는 가상 조직 모델을 제안했습니다. 이 모델은 환경이 개별 세포에 미치는 영향을 추정할 수 있을 뿐만 아니라, 개별 세포가 주변 환경과 전체 조직에 미치는 영향을 추론할 수도 있습니다. 연구진은 자체 일관성 있는 합성 데이터와 실제 데이터 실험을 통해 인과 관계 학습과 풀이 과정에서 셀코멘 모델의 식별 가능성을 검증했으며, 실제 데이터와 자체 시뮬레이션된 공간 전사체 데이터에서 유전자-유전자 상호작용을 풀고 복구하는 능력도 검증했습니다. 관련 결과는 ICLR 2025에 선정되었습니다. 본 논문은 해당 연구에 대한 자세한 해석과 공유를 담고 있습니다.
전체 보고서 보기:https://go.hyper.ai/ylKOr
3. HUST/상하이 AI 연구실/상하이 교통대학교 연구 선구자들이 공유하는 심도 있는 내용: 최신 성과, 주요 학회에 논문을 제출하는 경험, 학제 간 협업의 과제...
제7회 Meet AI4S 라이브 방송에서 HyperAI는 화중과학기술대학교의 황홍 부교수, 상하이 AI 연구실의 저우동잔 박사, 상하이 교통대학교 연구소의 저우빙신 박사를 초대하여 세 명의 학자와 사회과학, 물리화학, 생명과학 및 기타 분야에서 AI의 최첨단 개발에 대해 논의했습니다. 또한 그들은 연구 방향을 선택하는 것에 대한 통찰력과 주요 AI 컨퍼런스에 논문을 제출하는 경험을 공유했습니다. 이 글은 세 선생님의 말씀을 요약한 것입니다.
전체 보고서 보기:https://go.hyper.ai/klU6m
4. GTC 2025: 젠슨 황은 칩 그 이상의 것을 공개했습니다. 30분 만에 물리적 AI 분야에서 여러 가지 새로운 성과를 공개했습니다. 모두 오픈 소스입니다.
엔비디아 CEO 젠슨 황은 매년 열리는 글로벌 AI 행사인 GTC 2025 컨퍼런스에서 기조연설을 하며 최첨단 AI 분야의 최신 개발 동향에 초점을 맞췄습니다. 이 행사에서는 블랙웰의 차세대 핵급 AI 칩이 선보였을 뿐만 아니라, Physical AI 데이터 세트, GR00T N1 모델, Newton 물리 엔진, Cosmos 세계 모델을 비롯한 일련의 새로운 성과도 공개되었습니다. 본 글은 황인쉰의 연설 내용과 새로운 성과를 요약한 것입니다.
전체 보고서 보기:https://go.hyper.ai/Q6wdO
NVIDIA는 MIT 등과 협력하여 새로운 유형의 대규모 흐름 단백질 백본 생성기인 Proteina를 개발했습니다. Proteina는 RFdiffusion 모델보다 매개변수 수가 5배 더 많고, 학습 데이터를 2,100만 개의 합성 단백질 구조로 확장했습니다. 이 기술은 새로운 단백질 백본 설계에서 SOTA 성능을 달성했으며, 최대 800개 잔기라는 전례 없는 길이의 다양하고 설계 가능한 단백질을 생성했습니다. 해당 연구 결과는 ICLR 2025 Oral에 선정되었습니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/w7jlU
상하이 교통대학은 다수의 명문 교육기관과 협력하여 권위 있는 평가 시스템을 구축하고 ChatGPT, DeepSeek 등 국내외 주류 LLM 10개에 대한 체계적인 시험을 실시했습니다. 이는 AI 지원 1차 진료 의사 교육에 대한 최초의 실제 증거를 제공하고 AI 기반 1차 진료에 대한 핵심 지원을 제공합니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/DH8hf
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1700개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 500개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 200개 이상의 AI4Science 논문 사례 해석
* 600개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.