Command Palette
Search for a command to run...
주가 하락이 멈추지 않았습니다. 황런쉰, 블랙웰 울트라와 베라 루빈 출시 시기 공개, 추론 능력에 초점 맞춰

최근 몇 년 동안 NVIDIA는 클라우드 컴퓨팅에서 암호화폐, 메타버스에서 인공지능에 이르기까지 글로벌 기술 분야의 거의 모든 주요 트렌드에 참여해 왔습니다. 특히 인공지능의 새로운 물결 속에서, 심오한 기술 축적을 바탕으로 엔비디아는 약 95%의 데이터센터 GPU 시장 점유율을 확고히 장악하며, AI 칩 분야의 절대적인 선두주자로 자리매김했습니다.
그러나 올해 초,딥시크 추론 모델의 등장은 대중에게 분명한 신호를 보냈습니다. 과거 데이터와 컴퓨팅 파워를 축적하는 데 의존했던 "기적을 이루기 위한 위대한 노력" 모델은 점차 효과가 없게 되었다는 것입니다. 이로 인해 AI 컴퓨팅 성능에 대한 시장의 기대가 흔들렸고, 엔비디아를 포함한 많은 기술 대기업의 주가가 급격히 하락했습니다. 엔비디아의 주가는 그 이후 회복되었지만, 업계에서 차지하는 지배력은 한때만큼 깨지지 않았습니다. 엔비디아는 회사의 강점을 증명하기 위해 GPU를 전면적으로 업그레이드하고 업데이트해야 할 것입니다.
3월 19일 베이징 시간 오전 1시에 개최된 GTC 2025 컨퍼런스에서 황런쉰은 엔비디아 칩에 대한 최신 소식을 전했습니다.블랙웰 AI 칩 아키텍처의 업그레이드 버전인 블랙웰 울트라가 올해 하반기에 출시될 예정이다. NVIDIA GB300 NVL72와 NVIDIA HGX™ B300 NVL16은 모델 추론 기능을 포괄적으로 향상시킵니다. NVIDIA의 차세대 GPU 아키텍처인 Vera Rubin은 내년에 출시될 예정입니다.
NVIDIA Blackwell Ultra, AI 추론 가속화
황런쉰은 작년 GTC 컨퍼런스에서 차세대 AI 칩 아키텍처인 블랙웰을 발표했습니다. 홉 따는 기계 NVIDIA GeForce GPU의 후속 제품인 Blackwell 아키텍처는 2,080억 개의 트랜지스터를 갖추고 있으며 생성적 AI 작업, 대규모 교육 및 추론 워크로드를 가속화하는 데 중점을 두고 있습니다. 황런쉰은 자신의 연설에서 이것이 지금까지 가장 강력한 AI 칩 시리즈라고 자랑스럽게 선언했습니다.

오늘 생방송에서 황런쉰이 다시 블랙웰을 언급했습니다.그는 "블랙웰의 장점은 더 빠르고, 더 크고, 트랜지스터가 더 많고, 컴퓨팅 성능이 더 강력하다는 것입니다."라고 말했습니다. 또한, 이 아키텍처가 채택한 NVL 72 아키텍처 + FP4 컴퓨팅 정밀도 모델은 블랙웰의 성능을 더욱 향상시켜, 더 적은 에너지 소비로 동일한 컴퓨팅 작업을 완료할 수 있다는 것을 의미합니다.
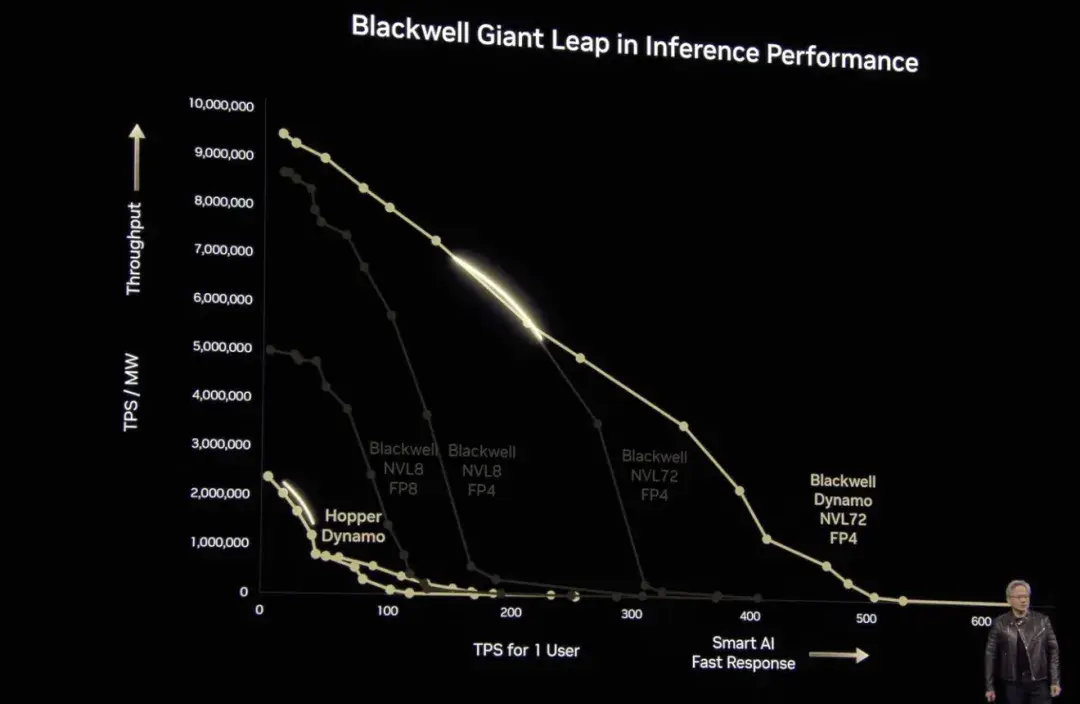
DeepSeek이 등장한 이후 인공지능 시장의 초점이 점차 '훈련'에서 '추론'으로 옮겨갔다는 점도 언급할 가치가 있습니다. 이 컨퍼런스에서 황런쉰은 블랙웰의 컴퓨팅 성능이 호퍼보다 40배 더 우수하다는 것을 증명하기 위해 추론 모델 사례를 구체적으로 인용했습니다. "전에도 말했지만, 블랙웰이 대량으로 출하하기 시작하면 호퍼를 출시하기도 어려울 거예요." 물론, 황런쉰은 블랙웰이 생산에 전액 투자되었으며, 엔비디아 블랙웰 AI 공장은 올해 하반기에 다시 업그레이드될 것이라고 언급했습니다.그리고 Blackwell Ultra로 원활하게 전환하세요.

Blackwell Ultra에는 NVIDIA GB300 NVL72 랙 스케일 솔루션이 포함됩니다. 엔비디아 HGX B300 NVL16 체계.
첫째, NVIDIA GB300 NVL72는 72개의 NVIDIA Blackwell Ultra GPU와 36개의 Arm 기반 NVIDIA를 탑재한 완전 액체 냉각 랙 장착 디자인을 사용합니다. 그레이스™ CPU 테스트 시간의 확장 추론에 최적화된 단일 플랫폼으로 통합합니다. 이전 세대인 NVIDIA GB200 NVL72와 비교했을 때 GB300 NVL72는 AI 성능이 1.5배 뛰어나고, 여러 솔루션을 탐색하고, 복잡한 작업을 여러 단계로 나누어 더 높은 품질의 응답을 생성할 수 있습니다.
둘째, NVIDIA HGX B300 NVL16은 AI 추론과 같은 복잡한 작업을 효율적으로 처리하는 데 획기적인 기술을 제공합니다. Hopper와 비교했을 때 대규모 언어 모델의 추론 속도는 11배, 컴퓨팅 성능은 7배, 메모리 용량은 4배 증가합니다.
요약하자면, Blackwell Ultra는 훈련 및 테스트 시 확장된 추론을 강화하여 가속화된 AI 추론, AI 에이전트, Physical AI와 같은 애플리케이션에 대한 강력한 지원을 제공합니다.
이와 관련하여 황런쉰은 다음과 같이 말했습니다. "AI 기술은 비약적인 발전을 이루었으며, 추론 및 AI 에이전트를 위한 컴퓨팅 성능에 대한 수요가 크게 증가했습니다. 이를 위해 저희는 사전 훈련, 사후 훈련, 추론 작업을 효율적으로 수행할 수 있는 다기능 플랫폼인 Blackwell Ultra를 설계했습니다."
엔비디아의 차세대 GPU 아키텍처 베라 루빈
엔비디아는 1998년부터 자사 아키텍처에 과학자의 이름을 붙여왔으며 이번에도 예외는 아닙니다.엔비디아의 차세대 GPU 아키텍처인 베라 루빈은 암흑 물질을 발견한 미국의 천문학자 베라 루빈의 이름을 따서 명명되었습니다.

베라 루빈은 처음으로 자체 개발한 CPU와 GPU 아키텍처를 심층적으로 통합했습니다.이는 NVIDIA가 AI 컴퓨팅 아키텍처에서 또 다른 획기적인 성과를 거두었으며, AI 컴퓨팅 성능의 경계를 더욱 확장하는 데 기여했습니다.
황런쉰은 "기본적으로 섀시를 제외한 모든 것이 새것입니다."라고 말했습니다. NVIDIA 최초의 완전 독립적으로 설계된 CPU 아키텍처인 Vera는 맞춤형 Arm 코어를 기반으로 구축되었습니다. 전력 소모량이 50와트에 불과한 작은 CPU이지만, 메모리 용량이 더 크고 대역폭도 더 높습니다. NVIDIA의 공식 데이터에 따르면 Vera의 컴퓨팅 성능은 Grace Blackwell에 비해 2배나 향상되었습니다. 또한 AI 부하에 대해서도 심층적으로 최적화되어 있습니다. 명령어 세트를 최적화함으로써 통신 지연 시간이 크게 줄어들어 데이터 처리가 더욱 효율적이고 원활해지며, AI 학습 및 추론에 대한 강력한 지원이 제공됩니다.
동시에, 새로운 Rubin GPU는 AI 컴퓨팅에 또 다른 도약을 가져옵니다. Vera를 사용하면 Rubin 추론 컴퓨팅은 기존 Blackwell GPU 성능의 2배 이상인 50페타플롭을 달성할 수 있습니다. 또한 Rubin은 최대 288GB의 고속 메모리를 지원하여 AI 학습 및 추론이 엄청난 양의 데이터를 효율적으로 처리할 수 있도록 보장합니다.
황런쉰은 또한 Vera Rubin NVL144가 내년 하반기에 출시될 것이라고 밝혔습니다.엔비디아는 2027년 하반기에 NVL576 기술을 사용하고 250만 개의 구성 요소로 구성된 Vera Rubin Ultra를 출시할 것으로 예상합니다. 각 랙의 최대 전력은 600킬로와트입니다. 부동 소수점 연산 수는 14배 증가해 15엑사플롭에 달하며 극도의 확장성을 달성합니다.

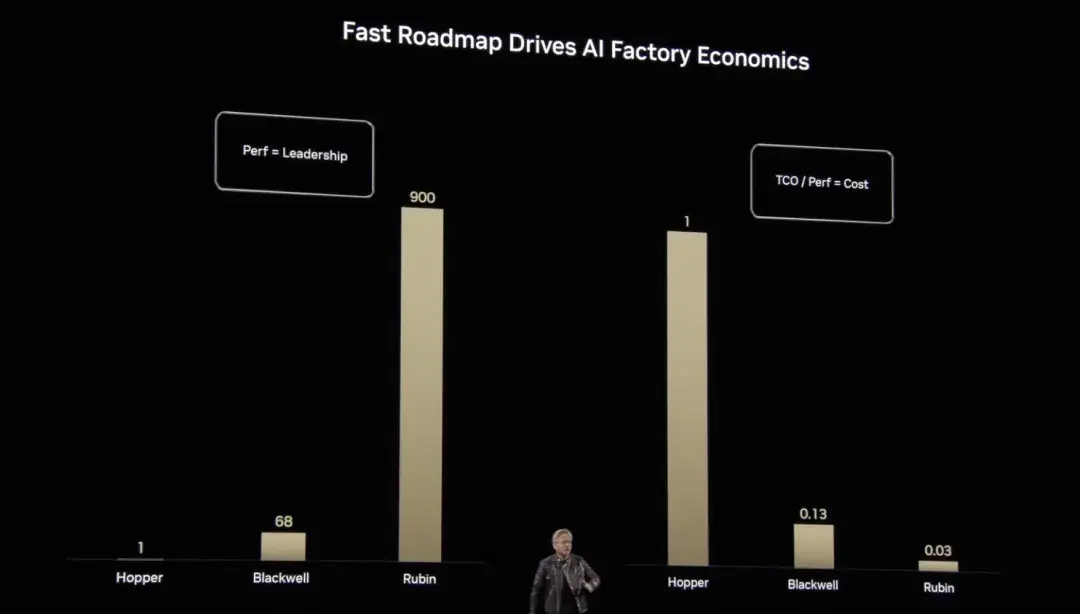
그레이스 호퍼에서 블랙웰을 거쳐 이제는 루빈에 이르기까지 황런쉰은 컴퓨팅 성능과 비용 최적화 분야에서 NVIDIA의 엄청난 발전을 보여주었습니다.벤치마크 컴퓨팅 파워와 비교했을 때, 호퍼의 수직 확장 부동 소수점 연산은 벤치마크의 1배이고, 블랙웰은 68배, 루빈은 900배로 뛰어올라 기하급수적 성장을 이루었습니다. 이러한 획기적인 발전은 AI 컴퓨팅의 단위 비용을 크게 줄일 뿐만 아니라, 보다 복잡하고 대규모의 AI 모델을 훈련하고 추론하는 과정을 효율적이고 실현 가능하게 만들어줍니다.
엔비디아, AI 팩토리 구축 위한 풀 프로세스 서비스 제공 예정
최근 몇 년 동안 AI 분야의 초점은 대규모 모델 학습에서 추론 모델의 광범위한 적용으로 점차 바뀌고 있습니다. 추론은 AI 경제의 급속한 성장을 이끄는 핵심 동력이 되었습니다. 이러한 변화는 기술 환경을 변화시킬 뿐만 아니라 컴퓨팅 인프라에 대한 새로운 요구 사항도 제기합니다. 기존의 데이터 센터는 새로운 AI 시대에 맞춰 설계되지 않았습니다. AI 추론 및 배포를 효율적으로 촉진하기 위해 AI 팩토리(AI 공장)이 생겨났습니다.
AI 팩토리는 데이터를 저장하고 처리할 뿐만 아니라, 대규모로 "지능을 생산"하여 원시 데이터를 실시간 통찰력으로 변환합니다. 엔비디아는 "AI 팩토리 구축에 특화된 기업에 투자하면 미래 시장을 선도할 수 있을 것"이라고 밝혔습니다.
이러한 변화를 지원하기 위해 NVIDIA는 풀스택 AI 팩토리의 구성 요소를 만들고 파트너에게 다음과 같은 핵심 구성 요소를 제공합니다. 고성능 컴퓨팅 칩, 고급 네트워크 기술, 인프라 관리 및 워크로드 오케스트레이션, 가장 큰 AI 추론 생태계, 스토리지 및 데이터 플랫폼, 설계 및 최적화 청사진, 참조 아키텍처, 유연한 배포 방법.

컴퓨팅 능력이 AI 팩토리의 핵심이라는 점에는 의심의 여지가 없습니다. Hopper부터 Blackwell 아키텍처까지, NVIDIA는 세계에서 가장 강력한 가속 컴퓨팅을 제공합니다. AI 팩토리는 Blackwell Ultra 기반 GB300 NVL72 랙 레벨 솔루션을 통해 최대 50배 높은 AI 추론 출력을 달성하고 복잡한 작업 처리에 대한 전례 없는 성능 지원을 제공할 수 있습니다.