Command Palette
Search for a command to run...
최고의 오픈소스 플레이어들이 모였습니다! QwQ-32B는 다양한 게임플레이 모드를 제공하고, OpenManus는 저렴한 비용으로 AI 에이전트를 개발합니다! vLLM v1은 효율적인 모델 추론을 가능하게 합니다.

인공지능 분야에서 끊임없이 획기적인 발전이 이루어지는 가운데, Qwen 팀의 최신 모델인 320억 개의 매개변수를 갖춘 QwQ-32B는 업계에서 오픈 소스 대규모 모델에 대한 이해를 다시 한번 새롭게 했습니다. 이 모델은 코드 생성 및 다중 라운드 대화와 같은 작업에서 뛰어난 성능을 입증했으며, 추론 능력은 DeepSeek-R1의 순수 버전과 비슷합니다.
요전,대규모 모델에 대한 추론을 가속화하기 위해 특별히 설계된 vLLM 핵심 아키텍처가 대규모 업데이트를 거쳤습니다.실행 루프, 통합 스케줄러, 오버헤드 없는 접두사 캐시를 최적화함으로써 처리량과 지연 시간에서 최대 1.7배의 성능 향상을 달성하여 QwQ-32B를 듀얼 카드 A6000 그래픽 카드에 효율적으로 배포할 수 있습니다.
AI 에이전트 분야에서 OpenManus는 출시 이후 점점 더 주목을 받고 있습니다. "Manus 대안"으로 알려진 이 오픈 소스 프로젝트는기술 재생산을 통해 폐쇄된 생태계에 대한 외부의 의심에 대응할 뿐만 아니라, 모듈형 설계와 툴체인 통합을 통해 개발자에게 저렴한 비용으로 지능형 엔티티를 구축할 수 있는 "마스터 키"를 제공합니다.
현재 HyperAI는 "vLLM을 사용하여 QwQ-32B 배포"와 "OpenManus + QwQ-32B를 사용하여 AI 에이전트 구현"이라는 두 가지 튜토리얼을 출시했습니다. 와서 드셔보세요~
vLLM을 사용하여 QwQ-32B 배포
온라인 사용:https://go.hyper.ai/8nPfC
OpenManus + QwQ-32B는 AI Agent를 구현합니다.
온라인 사용:https://go.hyper.ai/GIX1H
3월 10일부터 3월 15일까지 hyper.ai 공식 웹사이트가 빠르게 업데이트되었습니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 4개
* 커뮤니티 기사 선정: 6개 기사
* 인기 백과사전 항목: 5개
* 3월 마감일 상위 컨퍼런스: 4
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
Big-Math는 언어 모델에 강화 학습(RL)을 적용하기 위해 설계된 대규모 고품질 수학 데이터 세트입니다. 이 데이터 세트에는 각각 검증 가능한 답이 있는 25만 개 이상의 고품질 수학 문제가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/qtlbQ
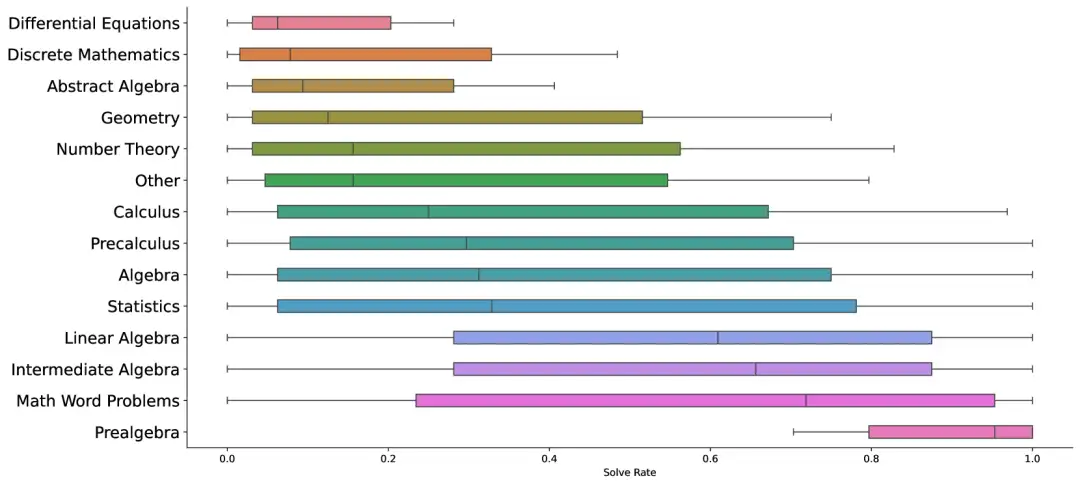
JMED 데이터 세트는 실제 의료 데이터 분포를 기반으로 한 새로운 데이터 세트입니다. 이 데이터 세트는 JD Health Internet Hospital에서 이루어진 익명의 의사-환자 대화에서 파생되었으며, 표준화된 진단 워크플로를 따르는 상담 내용을 유지하기 위해 필터링되었습니다.
직접 사용:https://go.hyper.ai/FjZsa
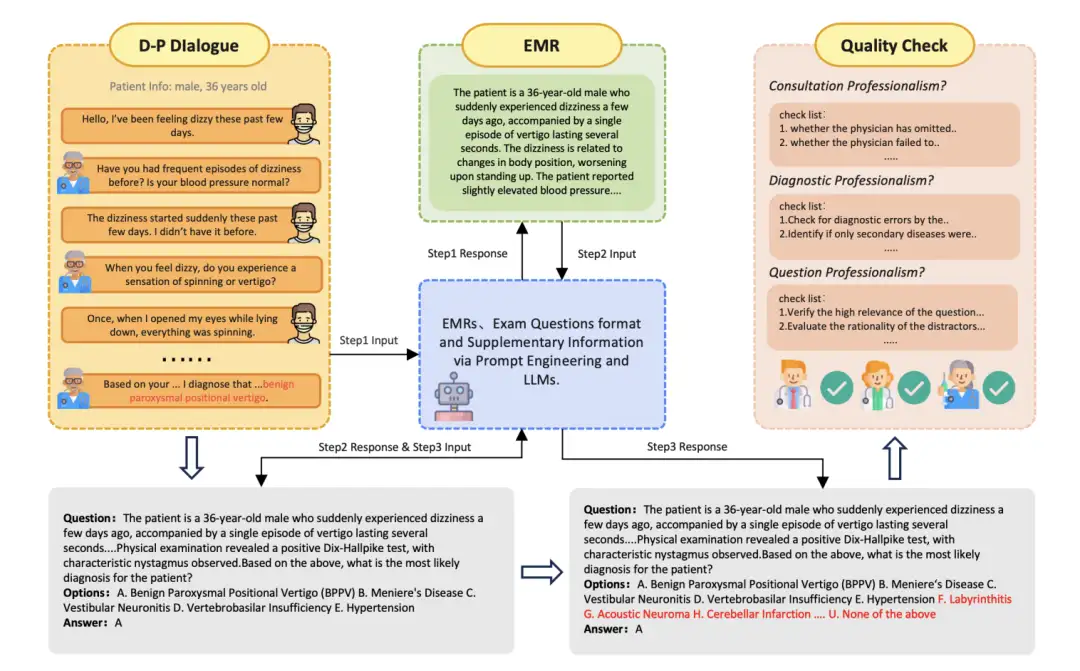
3. R1-Onevision 다중 모드 추론 데이터 세트
R1-Onevision 데이터 세트는 모델에 고급 다중 모드 추론 기능을 부여하도록 설계되었습니다. 자연 경관, 과학, 수학 문제, OCR 기반 콘텐츠, 복잡한 다이어그램 등 다양한 분야에서 풍부하고 맥락을 인식하는 추론 작업을 통해 시각적 이해와 텍스트 이해 간의 격차를 메웁니다.
직접 사용:https://go.hyper.ai/jLbSI
4. NaturalReasoning 자연 추론 데이터 세트
NaturalReasoning 데이터 세트는 STEM 분야(예: 물리학, 컴퓨터 과학), 경제학, 사회 과학 등 여러 분야를 포괄하는 280만 개의 까다로운 질문을 포함하는 대규모 고품질 추론 데이터 세트입니다. 이 데이터 세트는 추가적인 인간 주석 없이 사전 훈련된 코퍼스와 대규모 언어 모델(LLM)을 활용하여 다양하고 까다로운 추론 질문과 해당 참조 답변을 생성하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/Mb6Cd
5. AI-CUDA-Engineer-Archive 커널 컬렉션 데이터 세트
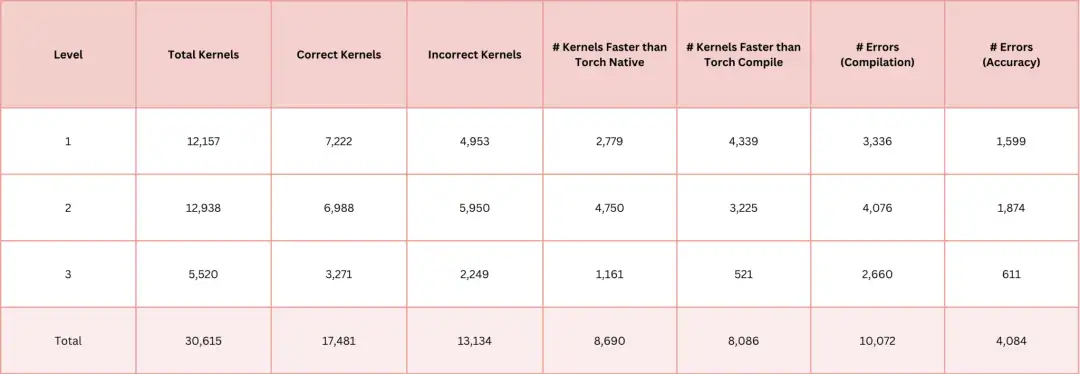
AI-CUDA-Engineer-Archive 데이터 세트는 AI가 생성한 CUDA 커널 컬렉션으로, 오픈 소스 모델의 후속 학습과 더 나은 CUDA 기능 모듈의 개발을 용이하게 하는 것을 목표로 합니다. 데이터 세트에는 30,000개가 넘는 CUDA 커널이 포함되어 있으며, 이는 모두 AI 기반 CUDA 엔지니어가 생성했습니다. 이 중 17,000개 이상의 커널이 정확한 것으로 검증되었으며, 약 50% 커널은 PyTorch의 네이티브 런타임보다 성능이 뛰어납니다.
직접 사용:https://go.hyper.ai/3lPrI
QM9 데이터 세트는 널리 사용되는 양자 화학 데이터 세트로, 약 134,000개의 유기 소분자에 대한 양자 화학 계산 결과를 포함하고 있습니다. 이러한 분자는 탄소, 수소, 질소, 산소, 불소 원소로 구성되어 있으며 분자량이 900달톤을 넘지 않습니다.
직접 사용:https://go.hyper.ai/PZdz7
GEOM-Drugs 데이터 세트는 430,000개의 분자를 포함하는 대규모 3D 분자 구조 데이터 세트이며, 각 분자는 평균 44개의 원자를 가지고 있습니다. 데이터 처리 후, 각 분자는 최대 181개의 원자를 포함할 수 있습니다. 실험에서 연구진은 각 분자의 가장 낮은 에너지 형태를 30개 수집하고 각 기준 방법을 사용하여 이들 분자의 구성 원자의 3차원 위치와 유형을 생성하도록 요청했습니다.
직접 사용:https://go.hyper.ai/5B3U8
데이터 세트에는 풍수, 사주 등에 대한 207개의 질문이 포함되어 있으며, 각 질문에는 고유한 답변이 있습니다.
직접 사용:https://go.hyper.ai/31k1P
9. SuperGPQA 과목 영역 평가 벤치마크 데이터 세트
SuperGPQA는 고급 질문 답변 시스템의 성능을 평가하기 위한 벤치마크 데이터 세트입니다. 자연어 처리와 머신러닝 평가 분야에 초점을 맞추고 있으며, 복잡한 학제간 질문을 통해 모델의 추론 능력과 지식 수준을 테스트하는 것을 목표로 합니다. 이 데이터 세트는 생물학, 물리학, 화학 및 기타 과학 분야를 포함하여 다양한 질문 유형이 포함된 285개의 대학원 수준 과목 영역을 다룹니다.
직접 사용:https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 대규모 PDF 문서 데이터 세트
olmOCR-mix-0225는 광학 문자 인식(OCR) 모델을 훈련하고 최적화하도록 설계된 대규모 고품질 PDF 문서 데이터 세트입니다. 이 데이터 세트에는 학술 논문, 법률 문서, 매뉴얼 등 다양한 유형을 망라하는 약 25만 페이지의 PDF 콘텐츠가 포함되어 있습니다. 이 데이터 세트는 텍스트 콘텐츠를 포함할 뿐만 아니라, 각 페이지에서 중요한 요소(예: 텍스트 블록 및 이미지)의 좌표 정보도 추출합니다. 이 정보는 모델 프롬프트에 동적으로 주입되어 모델의 환각 현상을 크게 줄여줍니다.
직접 사용:https://go.hyper.ai/dXNkk
선택된 공개 튜토리얼
QwQ-32B는 Qwen 시리즈의 추론 모델입니다. 기존의 명령어 튜닝 모델과 비교했을 때, QwQ는 사고 및 추론 능력을 갖추고 있으며, 특히 어려운 문제를 다루는 다운스트림 작업에서 상당한 성능 향상을 이룰 수 있습니다. DeepSeek-R1 및 o1-mini와 같은 고급 추론 모델과 비슷합니다.
이 프로젝트의 관련 모델과 종속성이 배포되었습니다. 컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
온라인으로 실행:https://go.hyper.ai/Q8HmJ

vLLM은 대규모 언어 모델의 효율적인 배포를 위해 설계된 오픈 소스 추론 프레임워크입니다. 이 기술의 핵심은 메모리 관리와 컴퓨팅 효율성을 최적화함으로써 모델 추론에 필요한 하드웨어 임계값을 크게 낮추는 것입니다. 이 튜토리얼에서는 vLLM을 사용하여 QwQ-32B 모델을 배포하여 배포 비용을 더욱 줄이고 더욱 상호 작용적인 시나리오의 요구 사항을 충족합니다.
이 프로젝트의 관련 모델과 종속성이 배포되었습니다. 컨테이너를 시작한 후 API 주소를 클릭하여 웹 인터페이스로 들어갑니다.
온라인으로 실행:https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32B는 Al Agent를 구현합니다.
OpenManus는 MetaGPT 팀이 시작한 오픈 소스 프로젝트입니다. 이 솔루션은 Manus의 핵심 기능을 재현하고 초대 코드 없이도 로컬에 배포할 수 있는 지능형 에이전트 솔루션을 사용자에게 제공하는 것을 목표로 합니다.
공식 웹사이트로 가서 컨테이너를 복제하고 시작한 후, 작업 공간에 들어가 해당 명령을 입력하여 모델을 경험해보세요.
온라인으로 실행:https://go.hyper.ai/GIX1H
4. Step-Audio-TTS-3B 프로덕션 레벨 방언 음성 생성 모델
Step-Audio는 음성 이해와 생성 제어를 통합한 업계 최초의 제품 수준의 오픈 소스 실시간 음성 대화 시스템입니다. Stepfun-AI 팀에서 2025년에 오픈 소스로 공개했습니다. 다국어 생성(중국어, 영어, 일본어 등), 음성 감정(행복, 슬픔 등), 방언(광둥어, 쓰촨 방언 등)을 지원합니다. 말하기 속도와 리듬 스타일을 제어할 수 있으며, RAP과 콧노래 등을 지원합니다.
공식 웹사이트로 가서 컨테이너를 복제하고 시작한 후, API 주소를 직접 복사하면 다기능 음성 합성을 수행할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/WiyVK
커뮤니티 기사
1. 정확도는 97%에 도달합니다. 호주 팀의 새로운 업적은 두개골 CT를 통해 성별을 식별하는 딥러닝을 기반으로 하며 인간 법의학자를 능가합니다.
서부호주 대학과 다른 기관의 팀은 딥 러닝을 기반으로 한 자동화 프레임워크를 사용할 것을 제안했습니다. 이 연구에서는 인도네시아의 한 병원에서 촬영한 두개골 CT 스캔 200개를 사용하여 딥 러닝 기반 네트워크 구성 3가지를 훈련하고 테스트했습니다. 가장 정확한 딥러닝 프레임워크는 판단을 위해 성별과 두개골 특징을 결합할 수 있었으며, 분류 정확도는 97%로, 인간 관찰자의 82%보다 상당히 높았습니다. 본 논문은 논문에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/0rfjM
2. 1.7K 선전 주택 가격을 예로 들면, 저장대학교 GIS 연구실은 주의 메커니즘을 사용하여 지리적 맥락 특징을 마이닝하고 공간 비정상 회귀의 정확도를 향상시킵니다.
저장성 GIS 핵심 실험실의 연구원들은 주의 메커니즘을 기반으로 한 딥러닝 모델 CatGWR을 제안했습니다. 이 모델은 샘플 간의 공간적 거리와 맥락적 유사성을 결합하여 공간적 비정상성을 보다 정확하게 추정하는 주의 메커니즘을 도입합니다. 이는 특히 복잡한 지리적 현상을 다룰 때 공간 모델링에 대한 새로운 관점을 제공하며, 공간적 이질성과 맥락적 효과를 더 잘 포착할 수 있습니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/irDAo
3. 수학/코드/과학/퍼즐을 포괄하는 고품질 추론 데이터 세트가 요약되어 DeepSeek의 강력한 추론 기능을 재현하는 데 도움이 됩니다.
HyperAI는 수학, 코드, 과학, 퍼즐 등 다양한 분야를 포괄하는 가장 인기 있는 추론 데이터 세트를 신중하게 정리했습니다. 대규모 모델의 추론 기능을 크게 개선하고자 하는 실무자와 연구자에게 이러한 데이터 세트는 의심할 여지 없이 훌륭한 시작점이 될 것입니다. 이 문서는 데이터세트 다운로드 주소입니다.
전체 보고서 보기:https://go.hyper.ai/XGIi8
4. ICLR 2025에 선정되었습니다! 저장대학교의 션춘화 등은 볼츠만 정렬 기술을 제안했고, 단백질 결합 자유에너지 예측이 SOTA에 도달했습니다.
저장대학과 다른 연구진은 볼츠만 정렬이라는 기술을 제안했는데, 이는 사전 훈련된 역 폴딩 모델에서 얻은 지식을 결합 자유 에너지 예측으로 전환하는 것입니다. 이 방법은 뛰어난 성능을 보였으며 인공지능 분야 최고 국제 학술대회인 ICLR 2025에 포함되었습니다. 본 논문은 논문에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/MsUDj
NVIDIA는 MIT 등과 협력하여 새로운 유형의 대규모 흐름 단백질 백본 생성기인 Proteina를 개발했습니다. Proteina는 RFdiffusion 모델보다 매개변수 수가 5배 더 많고, 학습 데이터를 2,100만 개의 합성 단백질 구조로 확장했습니다. 이 기술은 새로운 단백질 백본 설계에서 SOTA 성능을 달성했으며, 최대 800개 잔기라는 전례 없는 길이의 다양하고 설계 가능한 단백질을 생성했습니다. 해당 연구 결과는 ICLR 2025 Oral에 선정되었습니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/n4fWv
레이쥔, 저우홍이, 류칭펑 등 업계 리더들은 시대의 흐름을 따라가며 신에너지 자동차, 대형 모델 환각, AI 의료, AI 얼굴 바꾸기, AI 교육 등 핵심 분야에서 적극적으로 제안과 의견을 제시했습니다. 자세한 내용은 아래를 참조하세요.
전체 보고서 보기:https://go.hyper.ai/EazuY
인기 백과사전 기사
1. 달-이
2. 상호 정렬 융합 RRF
3. 파레토 전선
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 대조 학습
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
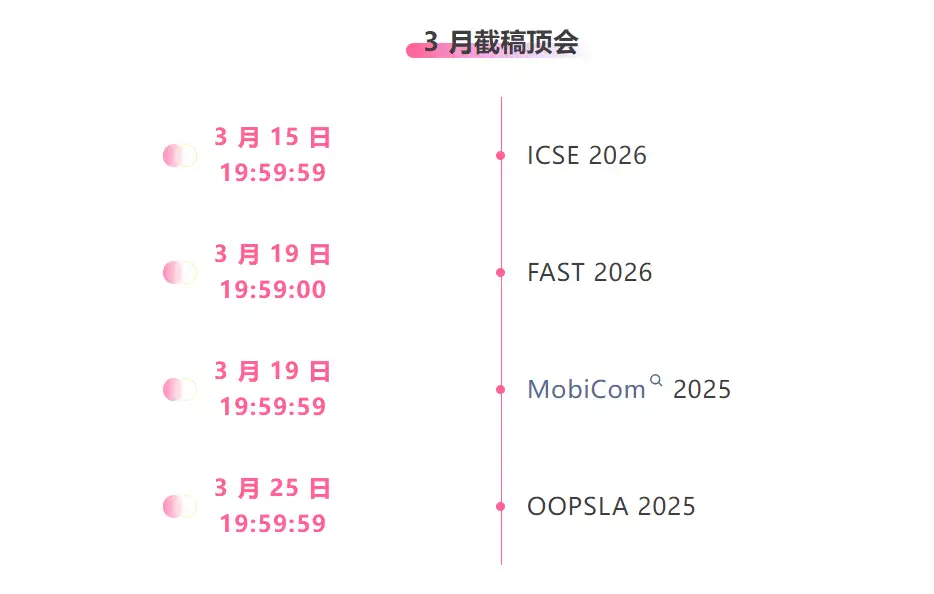
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!