ICLR 2025에 선정되었습니다! 저장대학의 션춘화(Shen Chunhua) 등은 볼츠만 정렬 기술을 제안했고, 단백질 결합 자유에너지 예측이 SOTA에 도달했습니다.

단백질-단백질 상호작용(PPI)은 모든 유기체가 다양한 생물학적 기능을 수행하는 데 필요한 기반이며, 이러한 기능은 주로 서로 다른 단백질 분자 간의 상호작용과 영향을 통해 달성됩니다. 단백질-단백질 상호작용을 정확하게 식별하고 이해하는 것은 단백질 기능을 해독하고, 생명 활동을 밝히고, 질병 메커니즘을 탐구하고, 표적 약물을 개발하고, 생물학적 응용 프로그램을 혁신하는 데 매우 중요합니다.
최근 몇 년 동안 컴퓨터와 인공지능의 발달로 과학 연구 커뮤니티에서 PPI에 대한 연구는 딥러닝의 지원을 받아 큰 진전을 이루었습니다. 특히 DeepMind가 2024년에 출시한 AlphaFold 3는일반 단백질 복합체의 구조를 예측하는 성공률은 거의 80%로 높아졌습니다.이는 또한 수십 년 동안 과학 연구 커뮤니티를 괴롭혀 온 단백질 상호작용의 고충실도 계산 모델링 문제를 효과적으로 해결합니다.
그러나 단백질 간의 상호작용은 결합과 해리를 포함하는 역동적인 과정입니다. 정적 구조만을 연구해서 생물학적 분자 간의 상호작용을 완전히 파악하는 것은 어렵습니다.결합 자유 에너지(∆G, 결합 상태와 비결합 상태 사이의 깁스 자유 에너지 차이)와 같은 매개변수는 단백질-단백질 상호작용의 역학을 정량적으로 특성화할 수 있습니다.그러나 결합 자유 에너지(∆∆G, 돌연변이 효과라고도 함)의 변화를 정확하게 예측하는 방법은 과학계에서 단백질-단백질 상호작용을 이해하거나 조절하는 데 필요한 전제 조건 중 하나가 되었습니다.
이를 바탕으로 저장대학교 컴퓨터과학기술학원의 션춘화 교수팀은 호주 애들레이드대학교와 미국 노스이스턴대학교의 팀들과 함께우리는 사전 훈련된 역 폴딩 모델에서 ∆∆G의 예측으로 지식을 전송하기 위해 볼츠만 정렬이라는 기술을 공동으로 제안합니다.이 연구에서는 먼저 ∆∆G의 열역학적 정의를 분석하고 볼츠만 분포를 도입하여 에너지와 단백질 구조 분포를 연결하여 사전 학습된 확률적 모델의 잠재력을 강조했습니다. 그런 다음 연구팀은 베이즈 정리를 사용하여 직접 추정을 피하고 단백질 역접힘 모델이 제공하는 로그 가능도를 사용하여 ∆∆G를 추정했습니다. 이 유도는 다른 이전 실험에서 관찰된 역 폴딩 모델의 결합 에너지와 로그 가능도 사이의 높은 상관관계에 대한 합리적인 설명을 제공합니다.
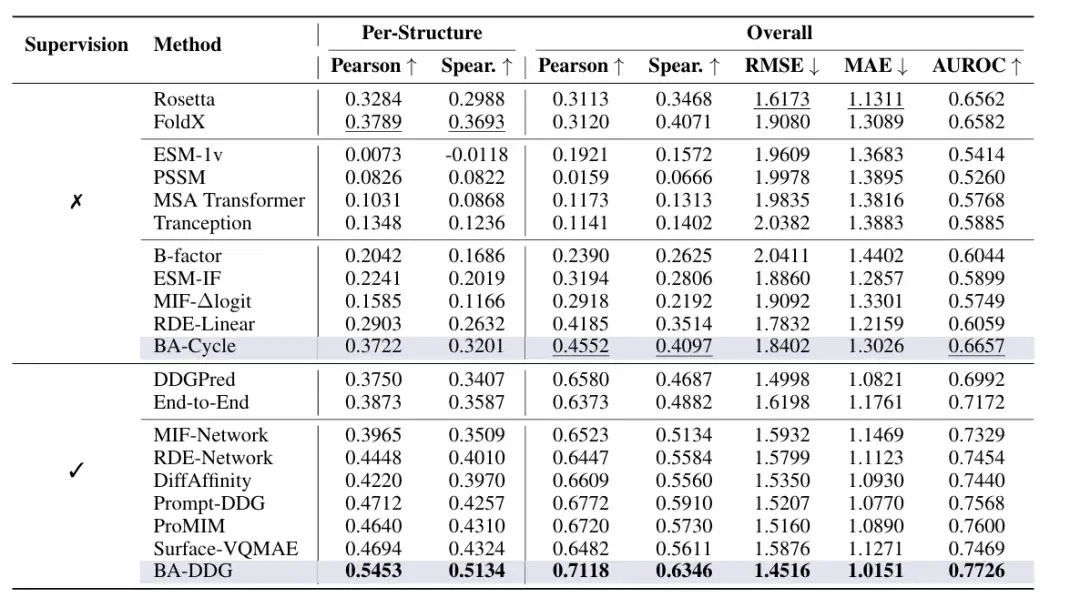
이전의 역폴딩 기반 방법과 비교했을 때, 이 방법은 SKEMPI v2 데이터 세트에 대해 실험 결과가 더 우수한 수준을 보여줍니다.지도 학습 상태와 비지도 학습 상태에서 스피어만 계수는 각각 0.5134와 0.3201에 도달했습니다.이전 SOTA 방식인 0.4324 및 0.2632보다 상당히 높습니다.
"단백질-단백질 상호작용에 대한 돌연변이 효과의 예측 인자로서의 볼츠만 정렬 역 폴딩 모델"이라는 제목의 이 업적은 인공지능 분야 최고 국제 학술대회인 ICLR 2025에 포함되었습니다. 올해 ICLR에는 총 11,565건의 논문이 접수되었고, 그중 32,08% 원고만이 채택되었다는 점도 언급할 가치가 있습니다.

서류 주소:
https://arxiv.org/abs/2410.09543
학술적 정보 공유 이벤트를 추천해 주세요. 최신 Meet AI4S 라이브 방송 초대는 3월 7일 오후 12시입니다.화중과학기술대학교 황홍 준교수, 상하이인공지능연구소 AI과학센터 청년연구원 주동잔, 상하이교통대학교 자연과학연구소 조교수 주빙신개인적 성과를 소개하고 과학 연구 경험을 공유하세요.
딥러닝은 돌연변이 효과 계산에서 패러다임 전환을 가속화합니다.
과학계에서는 오랫동안 ∆∆G의 예측에 대해 연구해 왔습니다.전통적인 방법은 생물물리학적 방법과 통계적 방법의 두 가지 범주로 나눌 수 있습니다.그 중 생물물리학적 방법은 주로 에너지 계산을 통해 단백질이 원자 수준에서 어떻게 상호 작용하는지 시뮬레이션합니다. 통계적 방법은 특징 공학에 의존하며, 주로 설명자를 사용하여 단백질의 기하학적, 물리적, 진화적 특성을 파악합니다.
어떤 전통적인 방법을 사용하든 인간의 전문 지식에 크게 의존해야 한다는 것은 의심의 여지가 없습니다. 이는 시간과 노동력이 많이 소요될 뿐만 아니라 단백질 간의 복잡한 상호 작용을 정확하게 포착할 수도 없습니다. 게다가 두 방법 모두 각자의 단점이 있습니다. 예를 들어, 생물물리학적 방법은 속도와 정확성의 균형을 맞추는 데 종종 어려움을 겪습니다. 딥러닝 기반 방법은 단백질 모델링에 뛰어난 "재능"을 보여줄 뿐만 아니라 ∆∆G 예측 패러다임의 변환도 가속화합니다.
이를 증명하는 사례가 점점 더 많아지고 있습니다. 예를 들어, 중국 과학 아카데미의 한 팀은 SidechainDiff라는 표현 학습 기반 방법을 제안했습니다.이 방법은 리만 확산 모델을 사용하여 측쇄 구조의 생성 과정을 학습하고 단백질-단백질 계면에서 발생하는 돌연변이의 구조적 배경 표현도 제공할 수 있습니다.학습된 표현을 사용하여 이 방법은 단백질-단백질 결합에 대한 돌연변이의 영향을 예측하는 데 있어 최첨단 성능을 달성합니다.
이 연구의 제목은 "측쇄 확산 확률 모델을 통한 단백질-단백질 결합에 대한 돌연변이 효과 예측"이며 NeurIPS 2023에 포함되었습니다.
* 서류 주소:
딥러닝 기반 방법은 상당한 성과를 달성했지만 아직 완벽하지는 않습니다. 우연히도 위의 예와 같이,이 논문에서는 또한 "결합 에너지를 설명할 수 있는 실험 데이터가 부족하다"고 언급합니다.이는 일반적으로 딥 러닝 방법을 기반으로 하는 주요 과제로 간주되며, 돌연변이 예측 능력을 향상시키기 전에 많은 수의 레이블이 지정되지 않은 데이터 세트로 사전 훈련을 하는 경향이 있는 팀으로 직접 이어졌습니다. 여기에는 단백질 역접힘, 마스크 모델링, 위의 예에서의 측쇄 모델링과 같은 다양한 사전 학습 에이전트 작업이 포함됩니다.
다행히도 이러한 "대안적" 방법은 목표를 달성했지만 불행히도 예외 없이 약점도 드러났습니다. 대부분의 사전 학습 기반 방법은 지도 미세 조정(SFT)만 사용합니다.그러나 데이터 정렬의 중요성이 무시되어, 지도 학습을 통해 모델이 비지도 학습 사전 학습 중에 이전에 습득한 일반 지식을 잊어버릴 수 있으며, 그 결과 과대 맞춤의 위험이 발생합니다.돌이켜보면, 이러한 "대안적" 방법은 정확한 돌연변이 예측을 위해 습득한 지식을 전수하는 것이 시급하다는 점을 의심할 여지 없이 강조합니다.
SOTA 모델을 능가하는 볼츠만 정렬의 혁신적인 개발
구체적으로 연구팀은 먼저 볼츠만 분포와 열역학 사이클 원리를 기반으로단백질이 돌연변이될 때 결합 자유 에너지의 변화는 단백질 아미노산 서열이 발생할 확률과 관련이 있습니다.볼츠만 정렬이 제안되었습니다(아래 그림의 오른쪽에 표시된 대로). 이후 연구팀은 BA-Cycle이라는 방법을 제안했는데, 이는 역 폴딩 모델을 볼츠만 정렬에 통합하고 역 폴딩 모델을 사용하여 단백질 서열의 가능성을 예측함으로써 돌연변이를 평가하는 방식입니다(아래 그림의 왼쪽 참조).
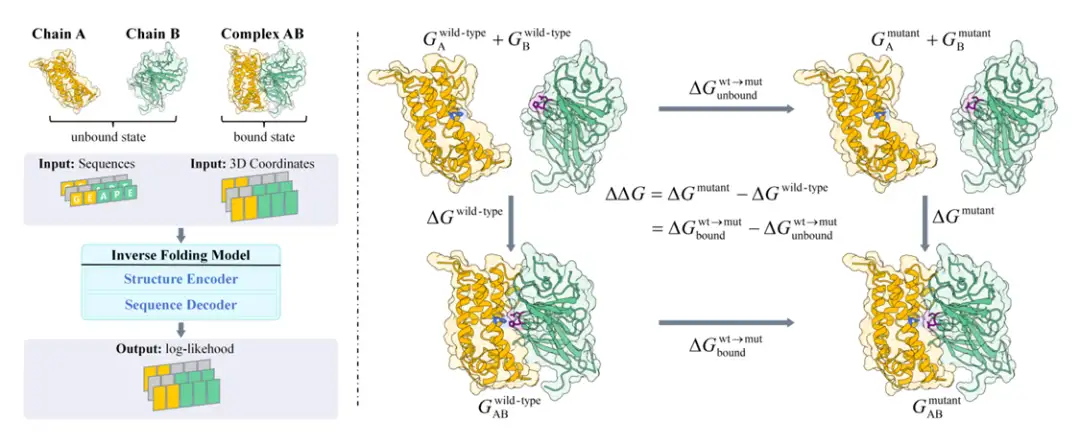
단백질 결합 자유 에너지와 단백질 서열 조건부 확률 사이의 연관성을 확립하고 주어진 서열에서 단백질 구조의 확률 p(X|S)를 직접 추정하는 데 직면한 두 가지 주요 어려움을 해결하기 위해서는 다음 사항을 언급할 가치가 있습니다.기존 단백질 구조 예측 모델의 한계와 확률론적 모델의 단점,연구팀은 베이즈 정리를 결합 자유도 계산식에 대입하여, p(X|S) = p(S|X) ・ p(X)/p(S)로 표현하고, 결합 자유 에너지를 단백질 서열의 조건부 확률 p(X|S)와 연결하는 데 성공하여, p(X|S)를 직접 추정하는 어려움을 피했다. 이는 결합 자유 에너지의 변화와 단백질 서열의 조건부 확률 사이의 관계에 대한 추가 분석을 위한 기초를 마련했습니다.
또한, 돌연변이 전후 단백질 구조는 변하지 않는다고 가정하므로,연구팀은 역 폴딩 모델을 사용하여 결합된 상태와 결합되지 않은 상태의 순서 확률을 평가했습니다.결합 상태의 백본 구조는 일반적으로 알려져 있으며, 모델은 그 확률을 직접 계산할 수 있습니다. 비결합 상태의 백본 구조는 명확하게 주어지지 않으며, 복합체의 두 사슬을 개별적으로 평가하여 확률을 추정할 수 있습니다.
이를 바탕으로,연구팀은 ∆∆G의 비지도 추정을 위해 BA-Cycle이라는 방법을 제안했습니다.∆∆G의 비지도 평가는 사전 훈련된 역 폴딩 모델 ProteinMPNN을 사용하여 달성되었습니다. 이는 열역학 순환에서 비결합 상태의 확률을 명시적으로 고려하지 않은 이전의 관련 연구와는 극명한 대조를 이룹니다.
마침내,연구팀은 또한 BA-DDG라는 방법을 제안했습니다.BA-사이클은 결합 자유 에너지 변화 라벨 데이터를 사용하여 볼츠만 정렬을 통해 미세 조정되었습니다. BA-DDG는 BA-Cycle과 동일한 순방향 프로세스를 사용합니다. BA-DDG의 목표는 원래 사전 학습된 모델의 분포를 유지하면서 실제 결합 자유 에너지 변화와 예측된 결합 자유 에너지 변화 사이의 격차를 최소화하는 것입니다.
연구팀은 SKEMPI v2 데이터 세트에 대한 일련의 실험적 검증을 수행했습니다.이 중 SKEMPI v2 데이터 세트는 7,085개의 아미노산 돌연변이와 열역학적 매개변수 및 운동 속도 상수의 변화를 포함하여 348개의 단백질 복합체를 포함하는 주석이 달린 돌연변이 데이터 세트입니다.
총 7개의 평가 지표가 있으며, 이 중 5개의 종합 지표는 피어슨 상관계수, 스피어만 순위 상관계수, 최소제곱평균제곱오차(RMSE), 최소평균절대오차(MAE), AUROC입니다. 연구팀은 또한 돌연변이를 구조적 특성에 따라 그룹화하고, 각 그룹에 대한 피어슨 상관 계수와 스피어만 상관 계수를 두 가지 추가 지표로 계산했습니다.
연구팀은 먼저 BA-Cyale과 BA-DDG를 SOTA 비지도 및 지도 방법과 비교했습니다.Rosetta Cartesian ∆∆G 및 FoldX와 같은 전통적인 경험적 에너지 함수를 포함하여 비지도 방법에는 세 가지 유형이 있습니다. ESM-1v, PSSM(Position-Specific Scoring Matrix), MSA Transformer 및 Tranception과 같은 시퀀스/진화 기반 방법 그리고 ∆∆G 레이블에 대해 훈련되지 않은 구조적 정보를 기반으로 한 사전 훈련된 방법(예: ESM-1F, MIF-∆logits, RDE-Linear 및 B-factor)이 있습니다.
지도 학습 방법은 DDGPred와 End-to-End와 같은 종단 간 학습 모델을 포함하여 두 가지 범주로 나뉩니다. 그리고 ∆∆G에 따라 미세 조정된 구조적 정보를 기반으로 한 사전 학습 방법에는 MIF-Network, RDE-Network, DiffAffinity, Prompt-DDG, ProMIM 및 Surface-VQMAE가 있습니다.
결과는 다음과 같습니다BA-DDG는 모든 평가 지표에서 모든 기준보다 우수한 성과를 보였습니다.이 중 지도학습법 하의 피어슨 상관계수와 스피어만 상관계수는 각각 0.5453과 0.5134로 나타났다. 각 구조의 상관관계가 크게 개선되어 실제 적용 시 신뢰성이 더욱 높아졌습니다.BA-Cycle은 경험적 에너지 함수와 비슷한 성능을 달성하고 모든 비지도 학습 기준보다 우수한 성능을 보입니다.다음 그림과 같이:
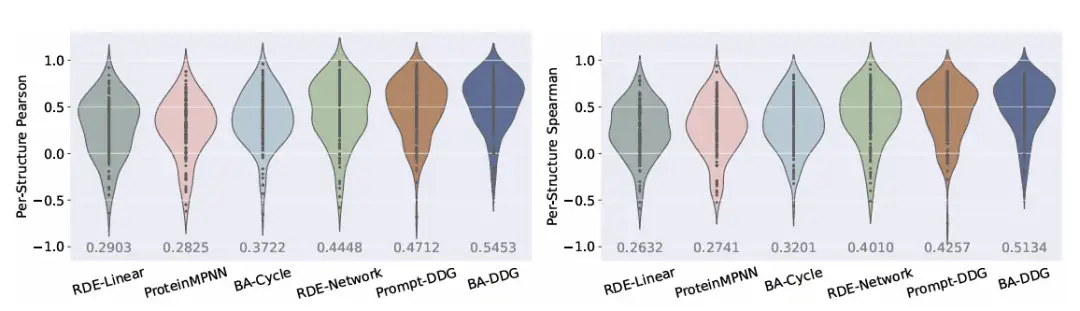
또한 관련 시각적 분석에서도 다음 사항이 명확히 확인됩니다.BA-DDG는 질적 시각화와 양적 측정 항목 모두에서 다른 방법보다 우수한 성과를 보입니다.다음 그림과 같이:
또한 연구진은 결합 에너지 예측, 단백질-단백질 도킹, 항체 최적화에 대한 실험을 수행했으며, 그 결과 폭넓은 적용 가능성이 있음을 보여주었습니다. 이러한 긍정적 영향은 약물 설계 및 가상 스크리닝에 매우 중요한 역할을 할 것이며, 미래에 실제 적용을 위한 이론적 토대를 마련할 것입니다.
AI 보편화를 실현하기 위해 머신러닝과 머신비전을 심도 있게 함
본 연구에서 연구진은 학제간 이론을 활용하여 단백질 서열 분석에 대한 새로운 관점을 제공하는 동시에 혁신적인 모델 통합 및 모델 최적화를 통해 체계적인 연구 프레임워크를 형성했습니다. 이러한 단계별 심층 연구 방법은 단백질 서열과 자유 에너지 변화 사이의 관계를 완전하고 심층적으로 이해하는 데 도움이 될 뿐만 아니라 후속 연구에 대한 새로운 아이디어도 제공합니다.
언급할 가치가 있는 것은 다음과 같습니다.본 연구의 주요 참여자 중 한 명인 션춘화 교수는 오랫동안 머신 러닝과 컴퓨터 비전 연구에 헌신해 왔습니다.그는 지금까지 150편이 넘는 논문을 출판했으며, 그중 일부는 TPAMI와 IJCV 등 국제적으로 유명한 학술 플랫폼에 게재되었습니다. 2025년이 시작된 지 불과 두 달 만에 션춘화 교수가 이끄는 팀은 중요한 성과를 거두었고, 사전 인쇄 플랫폼인 arXiv에 논문 3편을 게재했습니다.
첫 번째 기사에서 션춘화 교수의 연구 그룹은 CNN 네트워크를 기반으로 한 DNA 기반 모델인 ConvNova를 개발했습니다. 이 모델은 디자인은 단순하지만 놀라운 성능을 가지고 있습니다.관련 히스톤 작업에서 평균 점수는 2위 방법인 5.8%를 넘어섰으며, 더 적은 매개변수로 더 빠른 계산을 달성했습니다.동시에, 이 방법은 CNN 네트워크 아키텍처에 기반한 방법이 Transformer 네트워크와 SSM 네트워크에 기반한 방법에 비해 강력한 경쟁력을 가지고 있음을 검증합니다. 관련 연구는 "DNA 기초 모델 영역에서의 합성 구조 재검토"라는 제목으로 출판되었습니다.
* 서류 주소:
https://arxiv.org/abs/2502.18538
두 번째 논문에서는 션춘화 교수 연구팀과 상하이 AI 연구실이 공동으로 일반 시각 모델인 DICEPTION을 개발했습니다.사전 훈련된 확산 모델은 다중 작업 시각 인식 문제를 해결하는 데 사용되는데, 이는 훈련 데이터가 적게 필요하고 작업에 대한 적응성이 뛰어납니다.0.06%의 SAM 데이터만 사용하여 이 모델은 세분화 등의 작업에서 SOTA 모델과 비슷한 수준을 달성하고, 색상 코딩을 통해 작업 출력을 통합하여 학습 비용을 크게 절감합니다. 관련 연구는 "DICEPTION: 시각적 지각 작업을 위한 일반 확산 모델"이라는 제목으로 출판되었습니다.
* 서류 주소:
https://arxiv.org/pdf/2502.17157
세 번째 기사에서 션춘화 교수 팀은 알리바바와 협력하여 PhyCoBench라는 벤치마크를 제안했습니다. 이는 물리 법칙에 맞는 비디오를 생성하는 비디오 생성 모델의 능력을 평가하는 데 사용됩니다. 이 연구에서는 또한 광 흐름과 비디오 프레임을 계단식으로 생성하는 확산 모델인 자동 평가 모델 PhyCoPredictor를 소개합니다. 자동 및 수동 정렬의 일관성 평가를 비교하여,실험 결과에 따르면 PhyCoPredictor는 인간의 평가 능력에 가장 가까운 것으로 나타났습니다.관련 연구는 "광학 흐름 유도 프레임 예측을 통한 비디오 생성 모델 평가를 위한 물리적 코히어런스 벤치마크"라는 제목으로 출판되었습니다.
* 서류 주소:
https://arxiv.org/pdf/2502.05503
션춘화 교수의 팀은 유익한 성과를 거두었을 뿐만 아니라, 그의 개인적 영향력도 탁월했습니다. 션춘화 교수가 발표한 관련 논문은 언제나 과학 연구 커뮤니티에서 인용되는 중요한 자료가 되어 왔습니다. 그는 또한 글로벌 정보 분석 기업인 엘스비어가 발표한 '2023년 가장 많이 인용된 중국 연구자' 목록에도 선정됐습니다.
현재 션춘화 교수는 저장대학 컴퓨터 지원 설계 및 영상 시스템 국가중점연구실의 추시 석좌교수 겸 부소장으로 3년간 재직하고 있습니다. 그는 풍부한 연구 성과를 거두었을 뿐만 아니라, 상당한 교육 성과도 거두었으며, 많은 석사, 박사과정 학생을 양성했습니다. 또한, 이곳에 위치한 컴퓨터 지원 설계 및 그래픽 시스템 국가중점연구소는 '산학연'을 연결하는 인터페이스 역할을 하며, 최근 몇 년간 다각적인 발전을 이루고 있습니다. Ant를 비롯한 많은 기업과 협력하여 과학연구의 혁신거점, 인재육성거점, 혁신육성거점이 되었습니다.