온라인 튜토리얼丨Niangniang Shiji는 즉시 "사천 및 충칭 소녀"로 변신합니까? Step-Audio-TTS는 음성 복제/음악 합성/음성 합성 3가지 기능을 하나로 구현합니다.

DeepSeek 오픈소스로 인한 전 세계적 열광은 여전히 존재합니다. 최근 Step Star와 Geely Auto Group은 다시 한번 움직임을 보여 Step-Audio-TTS-3B 모델을 오픈 소스로 공개했는데, 이는 업계에서 다시 한번 폭넓은 논의를 불러일으켰습니다.
옛날 옛적에,방언 데이터의 다양성과 복잡성, 그리고 모델 일반화에 대한 높은 수요로 인해 음성 복제 모델은 방언에 대한 성능이 좋지 않습니다.Step-Audio-TTS-3B는 현지 언어의 특성을 생생하게 표현해 낼 수 있습니다. LLM-Chat 패러다임 대규모 합성 데이터 세트를 기반으로 학습되었으며, 언어 구조에 대한 심층적인 통찰력을 갖추고 있습니다. 그것은 행간에서 언어의 미묘한 변화를 파악할 수 있습니다. 열정적인 쓰촨 방언이든, 구성, 육성 광둥어든, 그 리듬과 어조를 정확하게 포착하여 강한 지역 관습을 보여줍니다.
뿐만 아니라, RAP과 허밍 생성을 실현한 최초의 TTS 모델로, 음악 음성 합성의 빈틈을 메웠습니다. 과거에는 리드미컬한 랩 콘텐츠를 만들려면 전문적인 가수가 필요했습니다. 이제 Step-Audio-TTS-3B의 도움으로 사용자는 정확한 리듬과 매끄러운 흐름으로 RAP 보컬을 빠르게 생성하여 무한한 가능성을 열어갈 수 있습니다.
현재 HyperAI 공식 홈페이지의 '튜토리얼' 섹션에서 'Step-Audio-TTS-3B 생산 수준 방언 음성 생성 모델'이 출시되었습니다.이 튜토리얼에는 음성 합성, 음악 합성, 음성 복제의 세 가지 기능이 포함되어 있습니다. 직접 와서 체험해보세요~
튜토리얼 주소:
데모 실행
1. hyper.ai에 로그인하고 튜토리얼 페이지에서 Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model을 선택하고 이 튜토리얼을 온라인으로 실행을 클릭합니다.
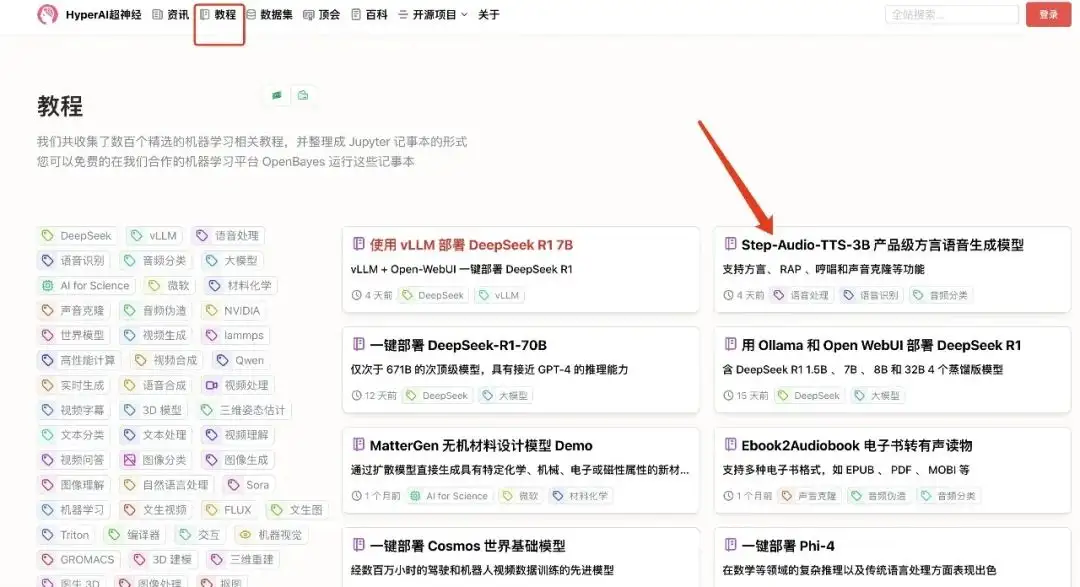
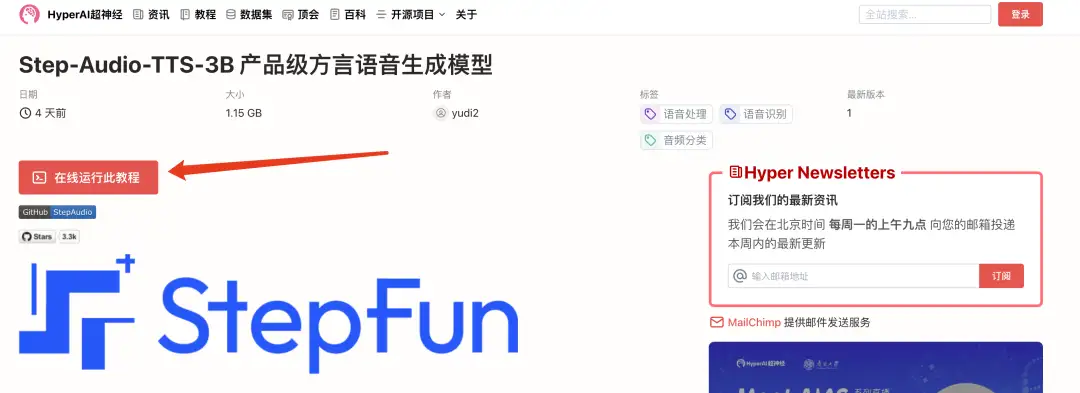
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
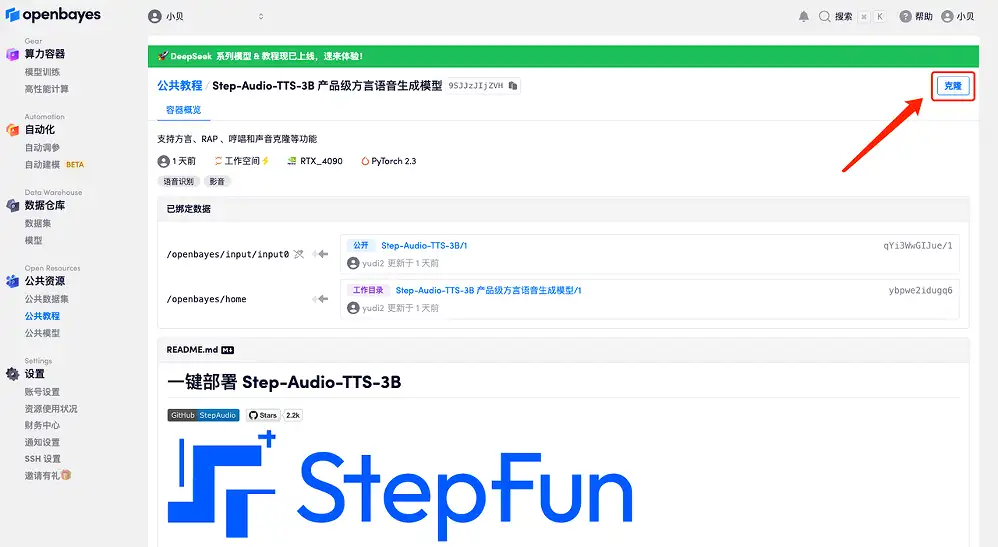
3. "NVIDIA RTX A6000"과 "PyTorch" 이미지를 선택하세요. OpenBayes 플랫폼에서 새로운 청구 방법이 출시되었습니다. 귀하의 요구 사항에 따라 "사용 후 결제" 또는 "일일/주간/월간 패키지"를 선택할 수 있습니다. "계속"을 클릭하세요. 신규 사용자는 아래 초대 링크를 사용하여 등록하고 RTX 4090 4시간 + CPU 자유 시간 5시간을 받으세요!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_QZy7
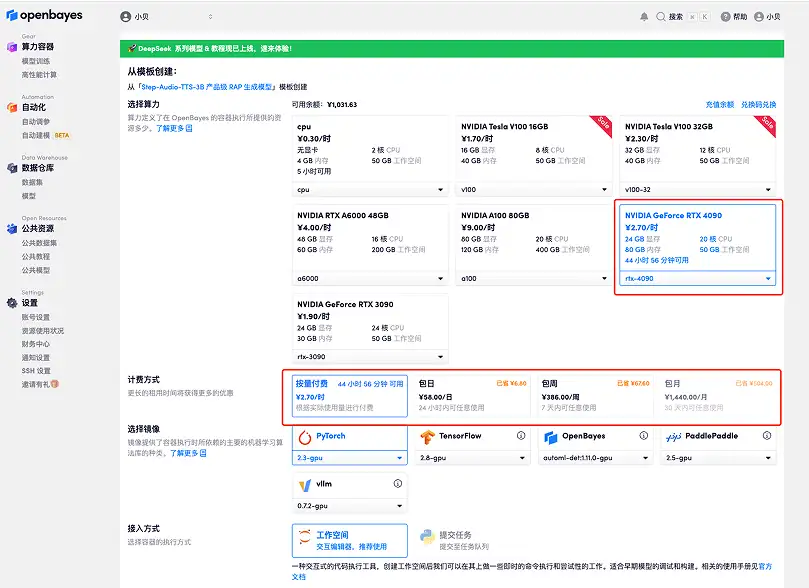
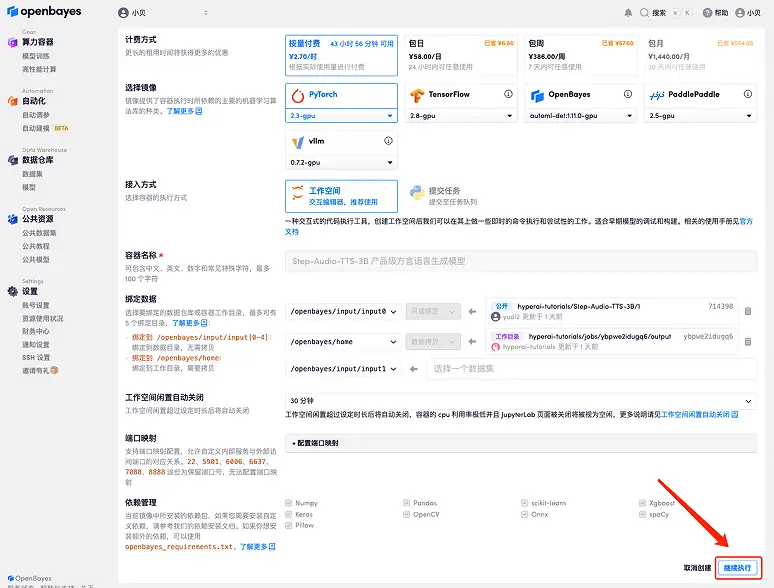
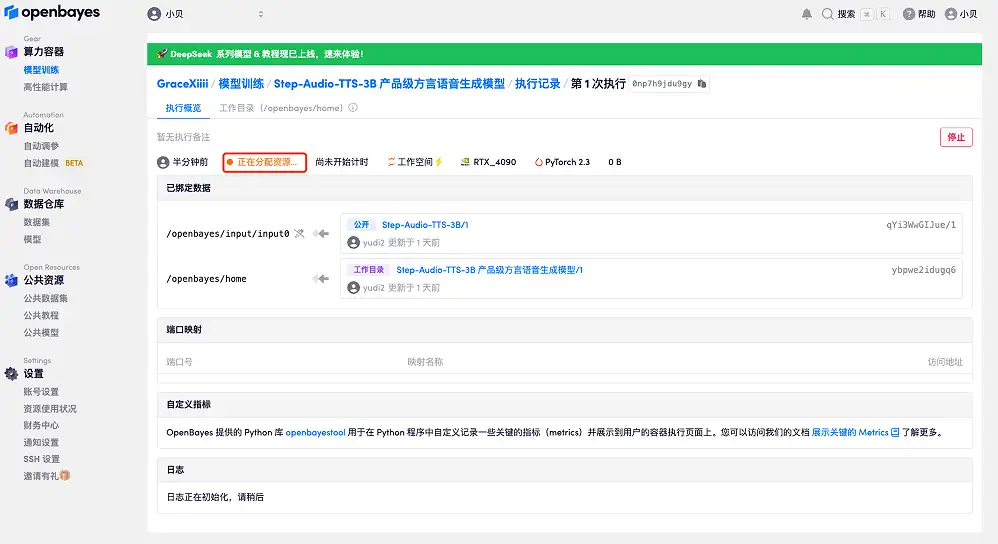
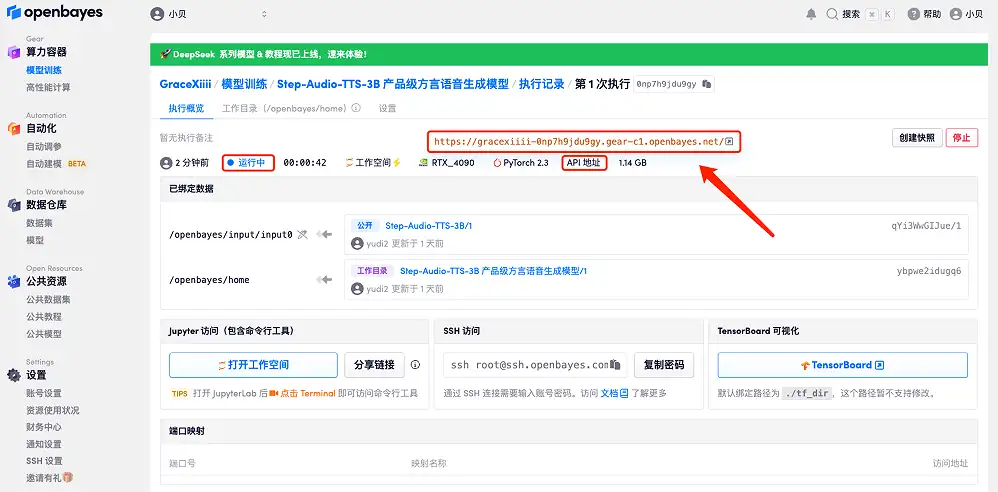
4. 리소스가 할당될 때까지 기다리세요. 첫 번째 클로닝 과정은 약 2분이 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다. API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.

효과 표시
이 튜토리얼에는 일반 음성 합성, 음악 합성, 음성 복제의 세 가지 기능이 포함되어 있습니다.
1. 일반 음성 합성
이 기능은 공식 기본 음성 캐릭터인 팅팅과 새로 추가된 나타 음성을 미리 설정하고, 다국어 생성, 감정, 방언 및 기타 설정을 지원합니다.
음성 합성 톤 설명
* Tingting 사운드는 공식 4s 오디오 프롬프트 파일에서 생성됩니다.
* 나타의 소리는 14초 오디오 프롬프트 "나는 제3왕자 나타입니다. 나는 자유분방하고 시를 쓰는 것을 좋아합니다. 나는 주머니에 손을 넣고 걷고, 구부러진 길을 곧게 만들 수 있습니다" 파일에서 생성됩니다.
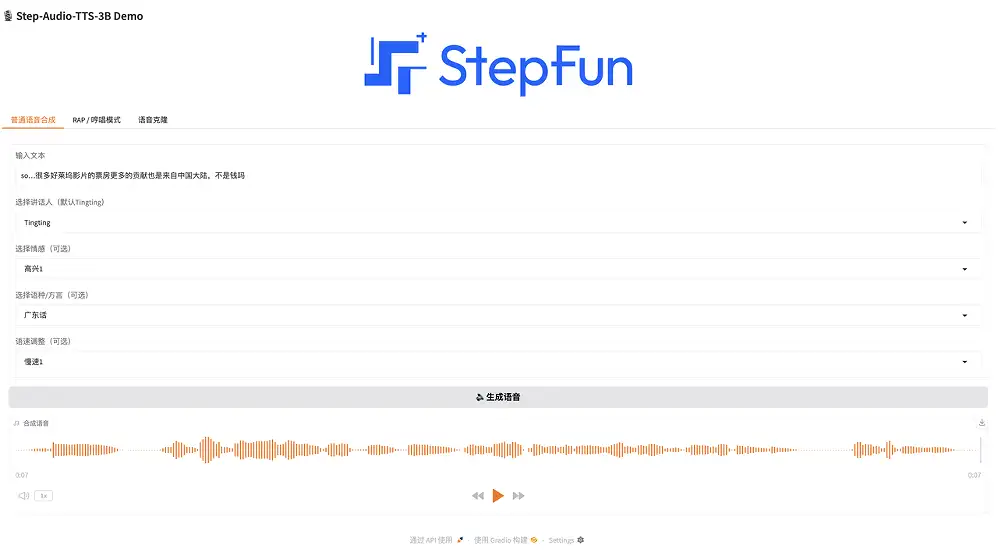
데모 페이지에서 "일반 음성 합성"을 선택하고, 텍스트를 입력하고, 말하는 사람을 선택하고(기본값은 팅팅), 감정(행복, 화남, 슬픔, 요염함)을 선택하고, 언어/방언(중국어, 영어, 일본어, 만다린어, 쓰촨어, 광둥어, 광동어)을 선택하고, 말하는 속도(빠르게 또는 느리게)를 선택합니다. '음성 생성'을 클릭하기만 하면 됩니다.
2. 음악 합성
이 기능은 공식 홈페이지의 기본 음성 캐릭터인 팅팅과 새로 추가된 나타 음색을 사전 설정하고, RAP과 허밍을 지원합니다.
랩 사운드 설명
* Tingting 사운드는 공식 11s 오디오 프롬프트 파일에서 생성됩니다.
* 네자의 소리는 14초 오디오 프롬프트 "천둥이 울리고 너무 무서워서 온몸을 때려요. 운명을 바꾸기 위해 나팔을 불어요. 재앙을 헤쳐나가기 위해 웃어요. 똑딱똑딱똑딱똑딱" 파일에서 생성됩니다.
윙윙거리는 소리 설명
* Tingting 사운드는 12초 오디오 프롬프트 파일에 의해 생성됩니다.
* 네자의 소리는 14초 오디오 프롬프트 "나는 두려움 없이 태어났다. 아버지가 누구든, 누구든, 주인이 통치자를 제거하더라도 그는 결코 나에게 명령할 수 없을 것이다" 파일에서 생성됩니다.
데모 페이지에서 "음악 합성"을 선택하고, 텍스트를 입력하고, 스피커(기본값은 Tingting)를 선택하고, 모드(RAP 또는 Humming)를 선택합니다. "RAP/허밍 생성"을 클릭하세요.

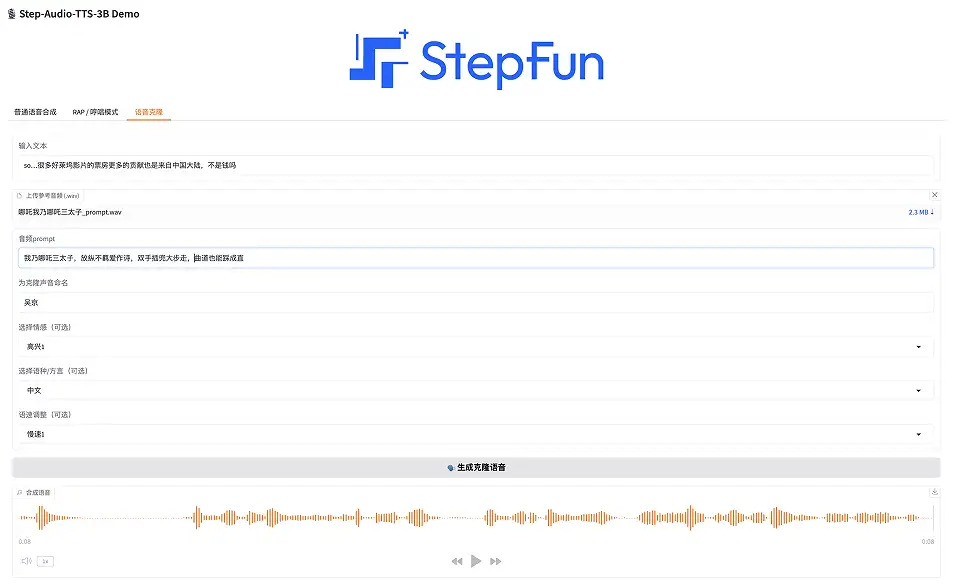
3. 음성 복제
이 기능은 사용자가 사용자 정의 음색 오디오를 업로드하고 개인화된 음성을 생성할 수 있도록 지원합니다.
데모 페이지에서 "음성 복제"를 선택하고, 텍스트를 입력하고, 참조 오디오(.wav 형식)를 업로드하고, 복제된 음성의 이름을 지정하고, 감정(행복, 화남, 슬픔, 요염함)을 선택하고, 언어/방언(중국어, 영어, 일본어, 만다린어, 쓰촨어, 광둥어, 광동어)을 선택하고, 말하는 속도(빠르게 또는 느리게)를 선택합니다. "음성 복제 생성"을 클릭하세요.