Oxford/Amazon/Westlake University/Tencent 등은 제로 샘플 임상 진단에 사용할 수 있는 다중 모드, 다중 도메인, 다중 언어 의료 모델 M³FM을 제안했습니다.

마블 영화를 좋아하는 많은 친구들이 이 장면에 놀랐을 거라고 생각해요. 영화 '아이언맨 2'에서 인공지능 집사 자비스는 스타크의 혈액 샘플을 수집하고 딥러닝 알고리즘을 사용하여 샘플 데이터를 빠르게 모듈화했습니다. 스타크의 몸에서 팔라듐 함량을 정확하고 빠르게 분석했으며, 보고서를 발행하면서 "기존 원소는 팔라듐 금속을 대체할 수 없으며, 새로운 원소를 합성해야 한다"는 등의 교차 영역 제안까지 제시했습니다.비록 수십 초 분량의 영상일 뿐이지만, 스마트 헬스케어의 자동화, 지능화, 프로세스 기반 기능을 완벽하게 보여줍니다.
하지만 실제로 동일한 결과를 얻으려면 의료진은 혈액 채취 및 검사, 영상 분석, 데이터 비교, 보고서 발행, 질병 분류 등 복잡한 과정을 거쳐야 합니다. 그리고 이는 거시적인 관점에서만 본 것입니다. 만약 우리가 그것을 무너뜨린다면, 상황은 더욱 악화될 것입니다. 임상 진단에서 가장 흔한 유형인 의료 영상을 예로 들면, 의료 영상은 임상적 소견을 설명하고 질병에 대한 추가 진단의 기초를 제공할 수 있습니다. 그러나 의료 이미지에 대한 보고서를 자연어로 정확하고 간결하며 완전하고 일관되게 설명하는 일은 많은 의료진에게 골치 아프고 지루한 일입니다.통계에 따르면, 경험이 풍부한 의사라 할지라도 보고서를 작성하는 데 보통 평균 5분 이상 걸리는 것으로 나타났습니다.
다행히 공상과학이 아직 현실을 완전히 밝히지는 못했지만, 어둠 속의 틈새로 이미 한 줄기 빛이 나타났습니다. 인공지능과 의료 건강의 교차점에서 점점 더 많은 과학 연구자들이 광범위한 연구를 수행하고 자동 보고서 생성 방법을 개발했습니다. 이러한 방법을 사용하면 의료진이 검토, 수정, 참조할 수 있는 초안 보고서가 자동으로 생성됩니다. 한편으로는 의료진의 시간 소모적이고 노동 집약적인 업무를 효과적으로 해결할 수 있으며, 다른 한편으로는 자동화를 통해 인적 오류의 가능성을 줄일 수 있습니다.
최근, 국제적으로 유명한 학술지 Nature Portfolio의 산하 저널인 npj Digital Medicine에서 "제로 샷 임상 진단을 위한 다중 모드 다중 도메인 다중 언어 의료 기반 모델"이라는 제목의 연구 결과가 게재되었습니다.여기에는 다중 모달(이미지와 텍스트), 다중 도메인(CT와 CXR), 다중 언어(중국어와 영어) 의료 기초 모델인 M³FM(Multimodal Multidomain Multilingual Foundation Model)이 언급되어 있으며, 이는 제로 샘플 임상 진단과 질병 보고 및 질병 분류 지원에 사용될 수 있습니다.연구진은 이 방법이 두 가지 감염성 질환과 14가지 비전염성 질환에 대한 9개의 벤치마크 데이터 세트에서 효과적임을 입증했으며, 이는 이전 방법보다 우수한 성과입니다.
이 연구에는 호화로운 저자들이 참여했습니다. 옥스퍼드 대학, 로체스터 대학, 아마존 등의 연구팀 외에도 웨스트레이크 대학 의료인공지능 연구실의 정예펑 박사와 텐센트 유투랩 톈얀 연구센터 소장인 우셴 박사도 참여했습니다.

서류 주소:
https://www.nature.com/articles/s41746-024-01339-7
오픈소스 프로젝트인 "awesome-ai4s"는 200개 이상의 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
데이터 손실은 여전히 기존 방법에 있어서 골치 아픈 문제입니다.
의료 영상은 의료 영상 보고와 질병 분류의 기초가 되며, 이후의 임상 진단에 중요한 역할을 합니다. 따라서 관련 자동화 방법에 대한 연구는 자연스럽게 과학 연구 분야의 연구 초점 중 하나가 되었습니다. 그러나 유익한 연구 결과에도 불구하고 실용적인 관점에서 보면 여전히 많은 미흡함이 있습니다.그 중에서도 데이터의 부족이나 심지어는 전혀 없는 것이 주요 과제입니다.
한편으로는,질병 보고서 생성은 이미지 기반 언어 생성 작업과 비슷합니다. 즉, 목표는 입력 이미지를 설명하는 설명 텍스트를 생성하는 것입니다. 기존의 기본 방법은 임상의가 주석을 단 대량의 고품질 의료 교육 데이터에 크게 의존하는 경우가 많은데, 이를 수집하는 데는 비용과 시간이 많이 소요됩니다. 특히 희귀 질환과 영어가 아닌 언어의 경우 더욱 그렇습니다.
특히, 새로운 질병이나 희귀 질병의 경우, 이러한 질병은 일반적으로 초기 단계의 교육을 위한 충분한 효과적인 데이터가 부족합니다. 예를 들어, 2019년 후반에 전 세계적으로 맹위를 떨치기 시작한 신종 코로나바이러스 폐렴의 경우, 초기 단계에서 수집할 수 있는 데이터가 제한적이어서 시스템 학습 시간이 전염병의 첫 몇 차례 파동 기간보다 훨씬 길어졌습니다. "2024년 중국 희귀질환 산업 추세 관찰 보고서"에 따르면, 전 세계적으로 알려진 희귀질환은 7,000여 종에 달합니다. 보수적인 증거 기반 데이터에 따르면, 인구 중 희귀 질환의 유병률은 약 3.5%~5.9%이고, 전 세계적으로 희귀 질환에 걸린 사람의 수는 약 2억 6천만~4억 5천만 명입니다. 이처럼 규모가 크고 특이한 질병은 의심할 여지 없이 위의 문제들을 더욱 어렵게 만듭니다.
또한, 글로벌 의료 시스템은 다양한 지역, 다양한 인구, 다양한 언어로 구성됩니다. 영어가 아닌 다른 언어의 경우, 관련 레이블이 지정된 데이터가 매우 부족하거나 전혀 없는 경우가 많습니다. 따라서 제한된 라벨 데이터는 기존 방법을 사용하는 비영어 언어 교육 시스템에 의심할 여지 없이 큰 과제를 제기합니다. 동시에 이로 인해 기존 방법으로는 흔하지 않은 언어를 처리하는 것이 더 어려워지고, AI의 공정성이라는 목표에 더욱 부정적인 영향을 미치며, 소외 계층에게 충분한 혜택을 제공하지 못하게 됩니다.
반면에,질병을 효과적으로 분류하기 위해 현재의 고급 모델은 주로 BioViL, REFERS, MedKLIP, MRM과 같은 CLIP의 성공에서 영감을 얻었으며, 이는 모두 의료 다중 모드 데이터를 더 잘 이해하기 위해 개발되었습니다. 구현 과정에서 이러한 방법은 대조 학습을 활용하고 의료 데이터를 사용하여 CLIP 모델을 사전 학습시키지만, 대부분의 모델은 흉부 X선(CXR)에만 국한되므로 일반적으로 단일 프레임워크 내에서 다중 도메인, 다중 언어 의료 이미지와 텍스트를 처리하지 못합니다. 동시에, 이전 연구에서도 언어와 이미지의 다양한 영역에서 질병 발생을 전혀 보고하지 못했습니다.
* CLIP 모델은 OpenAI가 개발한 대조적 언어-이미지 사전 학습 모델로, 자연어 감독을 통해 학습하는 효과적인 방법입니다. CLIP은 주로 대조 학습을 통해 이미지와 텍스트 간의 연관성을 학습하고, 대규모 이미지-텍스트 쌍을 사전 학습하여 모델이 다양한 모달리티의 정보를 이해하고 연관시킬 수 있도록 합니다.
이러한 맥락에서, 샘플이 적거나 전혀 없이 다중 모드, 다중 도메인, 다중 언어를 이용한 임상 진단을 수행할 수 있는 모델을 개발하는 것이 시급합니다.본 연구에서 제안된 구체적인 혁신은 다음과 같습니다.
* 제안된 M³FM은 훈련을 위한 레이블이 지정된 데이터가 부족하거나 전혀 없는 경우를 대비해 제로샷 다중 모달 다중 도메인 다중 언어 임상 진단을 수행하려는 최초의 시도입니다.
* M³FM은 CXR과 CT라는 두 가지 의료 영상 데이터 영역을 포함한 9개 데이터 세트에 대한 효과를 검증합니다. 두 가지 다른 언어, 즉 중국어와 영어; 질병 보고와 질병 분류라는 두 가지 임상 진단 과제 그리고 2가지 감염성 질환과 14가지 비감염성 질환을 포함한 다양한 질병이 있습니다.
M³FM: 여러 데이터 세트로 검증된 두 가지 주요 모듈
이 연구에서 제안된 M³FM의 핵심 아이디어는 다양한 방식, 도메인, 언어에 걸쳐 공공 의료 데이터를 사용하여 모델을 사전 학습시켜 광범위한 지식을 학습한 다음, 레이블이 지정된 데이터가 필요 없이 이 지식을 활용하여 다운스트림 작업을 수행하는 것입니다. M³FM 프레임워크의 주요 구성 요소에는 2개의 주요 모듈이 포함됩니다.즉, MultiMedCLIP과 MultiMedLM입니다. 다음 그림과 같이:
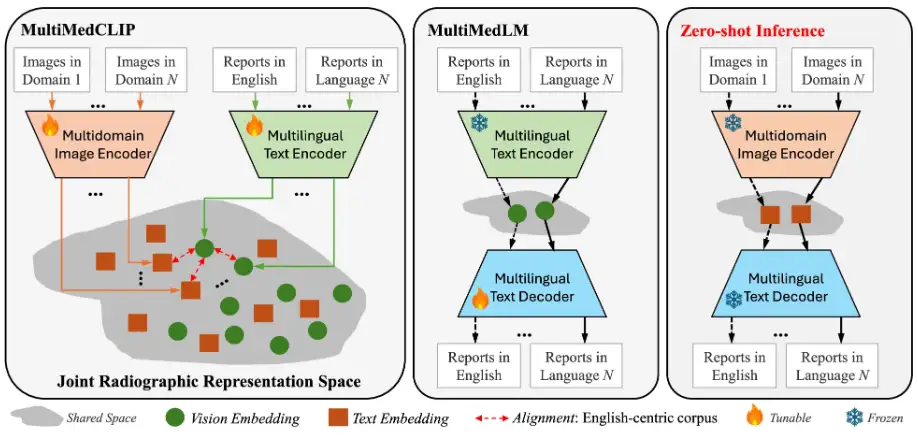
MultiMedCLIP은 공유되는 공통 잠재 공간에서 서로 다른 언어와 이미지를 정렬하고 연결하는 과정입니다.그런 다음 MultiMedLM은 공유 잠재 공간의 텍스트 표현을 기반으로 텍스트를 재구성하고, 마지막으로 M³FM은 통합 잠재 공간의 다양한 도메인에서 입력된 이미지의 시각적 표현을 기반으로 다국어 보고서를 직접 생성합니다.
구체적으로, MultiMedCLIP은 다중 도메인 시각적 인코더와 다국어 텍스트 인코더를 도입하여 공동 표현을 학습하기 위한 모듈로, 다양한 의료 영상 도메인과 다양한 언어의 시각적 및 텍스트 표현을 정렬하기 위한 공유 잠재 공간을 만드는 것을 목표로 합니다. 대조 학습 방법에서 영감을 얻은 연구진은 InfoNCE(Info Noise Contrastive Estimation) 손실과 MSE(Mean Square Error) 손실을 훈련 목표로 사용하여 양성 샘플 쌍 간의 유사성을 최대화하고 음성 샘플 쌍 간의 유사성을 최소화했습니다. 이를 통해 다양한 분야의 시각적 표현과 다양한 언어의 텍스트 표현 간의 일치를 달성하고, 다운스트림 제로샷 추론을 위한 견고한 기반을 마련했습니다.
MultiMedLM은 다국어 보고서를 생성하는 모듈입니다.MultiMedCLIP에서 추출한 표현을 기반으로 최종 의료 보고서를 생성하는 방법을 배우는 다국어 텍스트 디코더가 소개되었습니다. 이 부분은 중국어 텍스트나 영어 텍스트가 될 수 있는 입력 텍스트를 재구성하여 훈련하며, 자연어 생성 손실인 XE(교차 엔트로피) 손실을 훈련 목표로 사용합니다. 재구성 학습의 도입은 비지도 학습으로 볼 수 있으며, 학습을 위해 레이블이 지정되지 않은 일반 텍스트 데이터만 필요하다는 점을 언급할 가치가 있습니다. 따라서 다운스트림 작업에 대한 작업 주석 데이터를 학습할 필요가 없습니다. 또한 연구팀은 MultiMedLM 학습의 안정성을 확보하기 위해 랜덤 드롭아웃과 가우시안 노이즈를 추가로 도입했습니다.
실험에서는 AdamW 최적화 도구를 사용하였고, 학습률은 1e-4, 배치 크기는 32로 설정했습니다. 실험은 PyTorch와 V100 GPU에서 혼합 정밀도 학습을 사용하여 수행되었습니다.
데이터 세트 측면에서,사전 훈련은 MIMC-CXR 및 COVID-19-CT-CXR 데이터 세트에 대해 수행되었습니다. 여기서 MIMC-CXR은 377,110개의 CXR 이미지와 227,835개의 영어 방사선학 보고서로 구성되어 있으며, 현재까지 공개된 가장 큰 데이터 세트입니다. COVID-19-CT-CXR에는 1,000개의 CT/CXR 이미지와 해당 영문 보고서가 포함되어 있습니다. 또한 연구진은 두 데이터세트에서 영어 코퍼스의 절반을 추출하고 Google Translator를 사용하여 중국어-영어 교육팀을 구축했습니다. 연구 결과에 따르면 이 방법은 기계 번역 텍스트의 결과를 개선할 수 있는 것으로 나타났습니다.
평가 단계에서 사용된 데이터 세트에는 IU-Xray, COVID-19 CT, COV-CTR, 선전 결핵 데이터 세트, COVID-CXR, NIH ChestX-ray, CheXpert, RSNA 폐렴, SIIM-ACR 폐기종이 포함되어 모델 성능을 포괄적으로 평가할 수 있었습니다.
* IU-X선:여기에는 7,470개의 CXR 이미지와 3,955개의 영어 방사선학 보고서가 포함되었습니다. 데이터 세트는 학습, 검증, 테스트를 위해 무작위로 80% – 10% – 10%로 분할됩니다.
* 코로나19 CT:여기에는 1,104개의 CT 이미지와 368개의 중국 방사선학 보고서가 포함되어 있습니다. 마찬가지로 데이터 세트는 학습, 검증 및 테스트를 위해 무작위로 80% – 10% – 10%로 나뉩니다.
*COV-CTR:중국어와 영어 보고서와 연결된 726개의 COVID-19 CT 이미지가 포함되어 있습니다.
* 선전 결핵 데이터 세트:662개의 CXR 이미지가 포함되어 있으며, 훈련, 검증 및 테스트 세트는 7:1:2로 분할됩니다.
* COVID-CXR:900개가 넘는 CXR 이미지를 포함하는 이 데이터 세트는 훈련, 검증 및 테스트를 위해 무작위로 80% – 10% – 10%로 나뉩니다.
* NIH 흉부 엑스레이:112,120개의 CXR 이미지가 포함되어 있으며, 각 이미지에는 14가지 일반적인 방사선 질환의 발생이 표시되어 있으며, 훈련, 검증 및 테스트 세트의 비율은 7:1:2입니다.
* 체엑스퍼트:220,000개 이상의 CXR 진단 이미지가 포함되어 있습니다. 전처리 후, 훈련 세트에서 218,414개의 이미지, 검증 세트에서 5,000개의 이미지, 테스트 세트에서 234개의 이미지를 얻었습니다.
* RSNA 폐렴:약 30,000개의 방사선 이미지로 구성되어 있으며, 훈련, 검증 및 테스트 세트 비율은 85% – 5% – 10%입니다.
* SIIM-ACR 폐기종:여기에는 12,047개의 CXR 이미지가 포함되어 있으며, 훈련, 검증 및 테스트 세트의 비율은 70% – 15% – 15%입니다.
실험 결과, M³FM은 기존의 고급 방식보다 뛰어난 성능을 보이는 것으로 나타났습니다.아래 그림과 같습니다. 질병 보고 결과에서 알 수 있듯이, 기존 방법은 제로샷 설정에서 질병 보고 작업을 처리할 수 없었지만, M³FM은 단일 프레임워크에서 여러 언어, 여러 도메인의 질병 보고를 동시에 수행할 수 있습니다. 소수의 샷 설정에서 10%의 다운스트림 레이블링 데이터로 학습했을 때 M³FM은 최첨단 결과를 달성했으며, CT-중국어 보고서 생성에서 완전 감독 방식인 R2Gen보다 1.5%의 CIDEr 및 1.2%의 ROUGE-L 점수로 더 나은 성능을 보였습니다.이는 M³FM이 라벨이 부착된 데이터가 부족할 때에도 정확하고 유효한 다국어 보고서를 생성할 수 있음을 보여주며, 따라서 희귀 질병이나 신종 질병에 특히 유용할 것입니다.
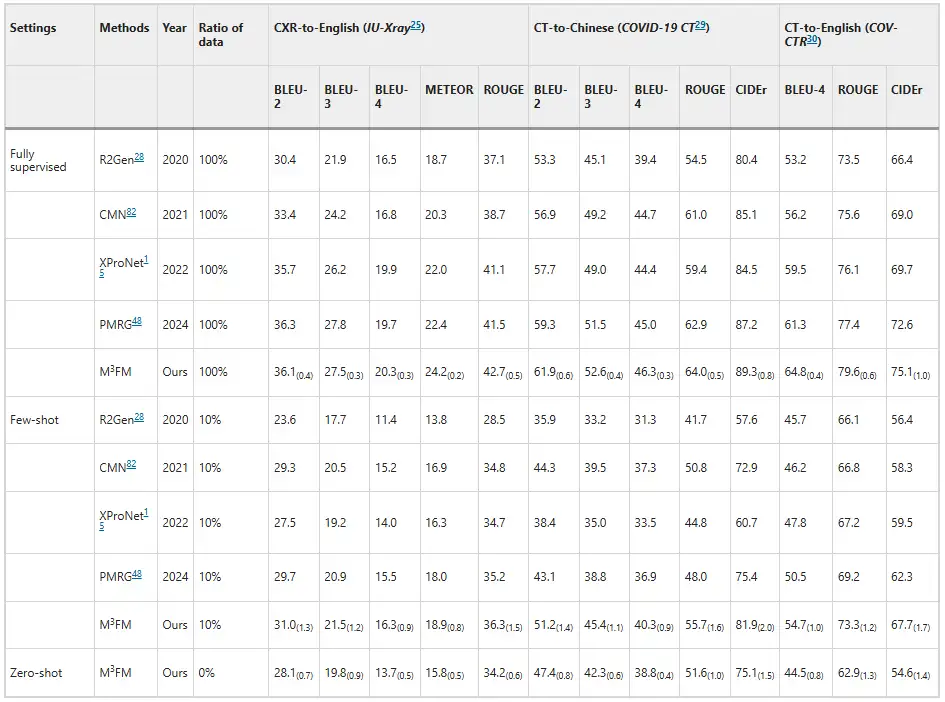
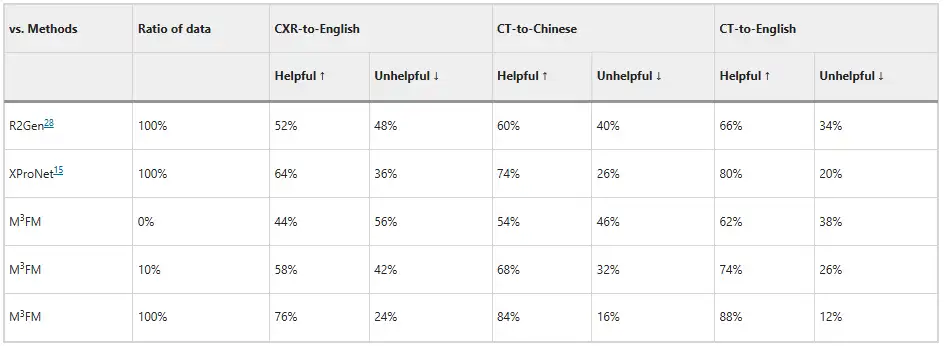
또한 연구진은 두 명의 임상의를 초대하여 모델을 평가하게 했고, 그 결과는 아래 그림에 나와 있습니다. 레이블이 지정된 데이터 학습 없이도 M³FM은 이상적인 다국어 및 다중 도메인 보고서를 생성할 수 있습니다. 레이블이 지정된 데이터 중 10%만 학습에 사용하는 경우, M³FM은 CXR-영어, CT-중국어 및 CT-영어 작업에서 각각 완전 지도 학습 방법인 R2Gen보다 6%, 8% 및 8% 더 높을 수 있습니다. 완전한 훈련 데이터를 사용할 때, M³FM은 세 가지 작업에서 R2Gen을 20% 이상 향상시킬 수 있으며, XProNet보다 각각 12%, 10%, 8% 더 높은 성능을 보일 수 있습니다.이는 M³FM이 임상의를 시간 소모적이고 노동 집약적인 보고서 작성 작업으로부터 해방시킬 수 있는 잠재력을 보여줍니다.
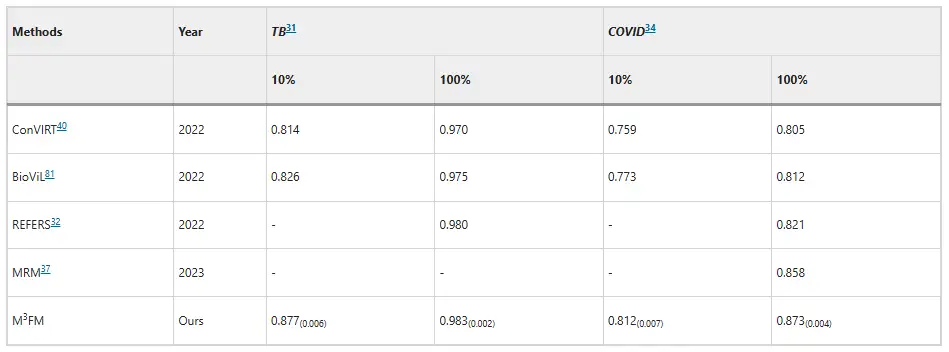
질병 분류 측면에서 M³FM은 감염성 질환 진단에 우수한 것으로 나타났습니다.선전 결핵 데이터 세트와 COVID-CXR 데이터 세트에서 10%의 훈련 데이터를 사용했을 때, M³FM의 AUC 점수는 각각 기존 최상의 결과보다 5.1%와 3.9% 더 높았습니다. 훈련 데이터를 전체적으로 사용했을 때, M³FM은 두 가지 감염병에서 가장 좋은 결과를 얻었습니다. 비전염성 질환의 경우, 데이터 세트는 NIH ChestX-ray에서 나왔고, M³FM은 1%의 훈련 레이블만으로 완전 감독 방식인 Model Genesis와 비슷한 결과를 얻었습니다. 10%에서 M³FM은 여러 질병의 진단에 있어서 기준 방법인 MRM과 REFERS보다 우수한 성과를 보였습니다. 또한 이를 통해 질병 진단에 있어서 M³FM의 효과성과 일반화 능력이 확인되었습니다.
AI가 스마트 헬스케어를 선도하고, 정예펑 팀이 선두를 차지합니다.
이전에는 많은 연구소가 이 문제에 집중해 왔으며, 그들이 제안한 모델은 각기 다른 초점과 장점을 가지고 있습니다.
예를 들어, 보고서의 자동 생성과 관련하여, 대련 해사대학 정보과학기술학원은 의료 및 생물학적 영상 분석 분야의 전문 포럼인 의료 영상 분석에 "DACG: 방사선 보고서 생성을 위한 이중 주의 및 맥락 안내 모델"이라는 제목의 연구 논문을 발표했습니다. 이 논문에서는 영상의학 보고서 자동 생성을 위한 이중 주의 및 맥락 안내(DACG) 모델을 제안했는데, 이는 시각적 데이터와 텍스트 데이터의 편향을 완화하고 긴 텍스트 생성을 촉진할 수 있습니다.
서류 주소:
https://www.sciencedirect.com/science/article/abs/pii/S1361841524003025
여러 언어에 맞게 설계된 모델도 있습니다. 예를 들어, 상하이 교통대학교의 왕 얀펑 교수와 셰 웨이디 교수 팀은 255억 토큰을 포함하는 다국어 의학 코퍼스 MMedC를 만들고, 6개 언어를 포함하는 다국어 의학 질의응답 평가 표준 MMedBench를 개발했으며, 여러 벤치마크 테스트에서 기존 오픈소스 모델을 능가하고 의료 응용 시나리오에 더욱 적합한 8B 기반 모델 MMed-Llama 3를 구축했습니다. 관련 연구 결과는 "의학을 위한 다국어 언어 모델 구축을 향하여"라는 제목으로 Nature Communications에 게재되었습니다.
딸깍 하는 소리확인하다상세 보고서: 의료 분야의 벤치마크 테스트는 Llama 3를 능가하고 GPT-4에 가깝습니다. 상하이 교통대학교 연구팀은 6개 언어를 포괄하는 다국어 의료 모델을 출시했습니다.
비교해 보면, M³FM이 다중 모달리티, 다중 도메인, 다중 언어 등의 측면에서 보여준 탁월한 성과는 의심할 여지 없이 인공지능과 의료의 교차점에 새로운 활력을 불어넣을 것입니다.물론, 이 연구에 관해 이야기할 때 우리는 이 논문의 저자 중 한 명인 정예펑 박사를 언급하지 않을 수 없습니다.
사실, 이 논문은 새롭게 만들어진 결과물이라고 할 수 있으며, 정예펑 박사의 새로운 시작을 알리는 신호로도 볼 수 있습니다. 2024년 7월 29일, IEEE 펠로우, AIMBE 펠로우이자 의료 인공지능 과학자인 정예펑이 웨스트레이크대학교에 정식으로 합류하여 공학대학 교수로 임용되었고, 의료 인공지능 연구실을 설립했습니다. 본 연구실의 연구 방향에는 의료 영상 분석, 의료 자연어 이해, 생물정보학 등이 포함됩니다. 본 논문은 본 연구실 창립 1년차의 중요한 성과 중 하나입니다.
이러한 성과 외에도 연구실에서는 의료 분야에서 여러 논문을 발표했습니다. 그중 하나가 "약하게 레이블이 지정된 데이터의 잠재력 해제: 비정상 탐지 및 보고서 생성을 위한 공진화 학습 프레임워크"라는 제목의 연구입니다. 이 연구에서는 완전 레이블이 지정된 데이터와 약하게 레이블이 지정된 데이터를 사용하여 CXR 이상 탐지와 보고서 생성이라는 두 가지 작업의 상호 개발을 촉진하는 협력적 이상 탐지 및 보고서 생성(CoE-DG) 프레임워크를 소개합니다. 이 연구는 IEEE 의료영상학회지에 게재되었습니다.
물론, 본 연구실에서는 현재 널리 사용되는 대규모 언어 모델에 대한 연구 결과도 보유하고 있습니다. EMNLP 2024에 게재된 "대규모 언어 모델의 환각 완화를 위한 대조 디코딩(Mitigating Hallucinations of Large Language Models in Medical Information Extraction via Contrastive Decoding)"이라는 논문이 그 예입니다. 본 논문은 LLM이 의료 상황에서 "환각"을 경험하기 쉽다는 현상에 대한 해결책을 제시하고, "대체 대조 디코딩(ALCD)"을 제안합니다. 이 방법은 모델의 인식 기능과 분류 기능을 분리하고 예측 과정에서 두 기능의 가중치를 동적으로 조정함으로써 오류 발생을 크게 줄일 수 있습니다. 이 기술은 다양한 의료 업무에서 좋은 성과를 보이고 있습니다.
현재 이러한 성과는 아직 실험실 단계에 있거나 구현을 위한 추진력이 있지만 결국 AI는 의료 분야를 지능화, 지능화, 자동화로 이끌 것입니다. 정예펑 박사는 "의료 인공지능은 빠르게 발전하는 분야입니다. 10~15년 안에 인공지능이 의사의 진단과 치료 정확도를 확보하고 널리 활용될 것으로 예상합니다."라고 말했습니다.
참고문헌:
1.https://www.nature.com/articles/s41746-024-01339-7
2.https://mp.weixin.qq.com/s/pMNXAvzgGRpPwqVtCWjXbA
3.https://mp.weixin.qq.com/s/6hw6EJY6slAIRbGGN9XY9g