Command Palette
Search for a command to run...
온라인 튜토리얼 | YOLO 시리즈는 10년 동안 11개 버전이 업데이트되었으며 최신 모델은 여러 대상 탐지 작업에서 SOTA에 도달했습니다.
YOLO(You Only Look Once)는 컴퓨터 비전 분야에서 가장 영향력 있는 실시간 객체 감지 알고리즘 중 하나입니다.높은 정밀도와 효율성으로 인해 업계에서 선호되고 있으며, 자율 주행, 보안 모니터링, 의료 영상 및 기타 분야에서 널리 사용됩니다.
이 모델은 워싱턴 대학의 대학원생인 조셉 레드먼이 2015년에 처음 발표했습니다. 이는 객체 감지를 단일 회귀 문제로 처리하는 개념을 개척하고, 종단 간 객체 감지를 달성했으며, 개발자들 사이에서 빠르게 폭넓은 인정을 받았습니다. 이후 알렉세이 보흐코프스키, 글렌 조처(울트라리틱스 팀), 메이투안 비주얼 인텔리전스 부서를 포함한 팀이 여러 가지 중요한 버전을 출시했습니다.
현재 GitHub에 있는 YOLO 시리즈 모델의 별 수는 수십만에 달하며 컴퓨터 비전 분야에서 그 영향력을 입증하고 있습니다.

YOLO 시리즈 모델은 단일 단계 감지 아키텍처를 특징으로 하며, 복잡한 영역 후보 상자 생성이 필요 없고 단일 전방 전파로 대상 감지를 완료할 수 있어 감지 속도가 크게 향상됩니다. 기존의 2단계 감지기(예: Faster R-CNN)와 비교했을 때,YOLO는 추론 속도가 빠르고, 고프레임 레이트 이미지의 실시간 처리를 실현할 수 있으며, 하드웨어 적응성을 최적화합니다.,임베디드 장치와 엣지 컴퓨팅 시나리오에서 널리 사용됩니다.
현재,HyperAI 공식 홈페이지의 '튜토리얼' 섹션에서는 YOLO 시리즈의 여러 버전을 출시했습니다. 클릭 한 번으로 바로 체험해 볼 수 있습니다~
이 글의 마지막에서는 YOLOv11의 최신 버전을 예로 들어 원클릭 배포 튜토리얼을 설명하겠습니다.
1. YOLOv2
출시 시간:2017
중요 업데이트:앵커 박스가 제안되었고, Darknet-19가 속도와 정확도를 개선하기 위해 백본 네트워크로 사용되었습니다.
TVM을 사용하여 DarkNet 모델에서 YOLO-V2를 컴파일합니다.
2. YOLOv3
출시 시간:2018
중요 업데이트:Darknet-53을 백본 네트워크로 사용하여 실시간 속도를 유지하면서 정확도를 크게 향상시켰으며, 다중 스케일 예측(FPN 구조)을 제안하여 다양한 크기의 객체를 감지하고 복잡한 이미지를 처리하는 데 있어 상당한 개선을 이루었습니다.
TVM을 사용하여 DarkNet 모델에서 YOLO-V3를 컴파일합니다.
3 , YOLOv5
출시 시간:2020
중요 업데이트:자동 앵커 프레임 조정 메커니즘을 도입하여 실시간 감지 기능을 유지하고 정확도를 향상시켰습니다. 더 가벼운 PyTorch 구현을 사용하여 학습과 배포를 더 쉽게 만들었습니다.
원클릭 배포:https://go.hyper.ai/jxqfm
4 , YOLOv7
출시 시간:2022
중요 업데이트:확장된 효율적 계층 집계 네트워크를 기반으로 매개변수 활용도와 컴퓨팅 효율성이 향상되어 더 적은 컴퓨팅 리소스로 더 나은 성능을 달성합니다. COCO 키포인트 데이터 세트에 포즈 추정 등의 추가 작업을 추가했습니다.
원클릭 배포:https://go.hyper.ai/d1Ooq
5 , YOLOv8
출시 시간:2023
중요 업데이트:
새로운 백본 네트워크를 채택하고 앵커 없는 새로운 감지 헤드와 손실 함수를 도입하여 평균 정확도, 크기, 지연 시간 측면에서 이전 버전보다 우수한 성능을 발휘합니다.
원클릭 배포:https://go.hyper.ai/Cxcnj
6 , YOLOv10
출시 시간:2024년 5월
중요 업데이트:비최대 억제(NMS) 요구 사항을 제거하여 추론 지연 시간을 줄입니다. 대규모 커널 합성곱과 부분적 자기 주의 모듈을 통합하면 많은 계산 비용을 추가하지 않고도 성능이 향상됩니다. 다양한 구성요소가 완전히 최적화되어 효율성과 정확성이 향상되었습니다.
YOLOv10 타겟 감지의 원클릭 배포:
YOLOv10 객체 감지의 원클릭 배포:
7 , YOLOv11
출시 시간:2024년 9월
중요 업데이트:탐지, 분할, 자세 추정, 추적, 분류를 포함한 여러 작업에서 최첨단(SOTA) 성능을 제공하며, 광범위한 AI 애플리케이션과 도메인의 기능을 활용합니다.
원클릭 배포:https://go.hyper.ai/Nztnq
YOLOv11 원클릭 배포 튜토리얼
HyperAI HyperNeural 튜토리얼 섹션에서는 이제 "YOLOv11의 원클릭 배포"가 시작되었습니다. 튜토리얼은 모든 사람을 위한 환경을 설정했습니다. 어떤 명령도 입력할 필요가 없습니다. YOLOv11의 강력한 기능을 빠르게 경험하려면 복제를 클릭하세요!
튜토리얼 주소:https://go.hyper.ai/Nztnq
데모 실행
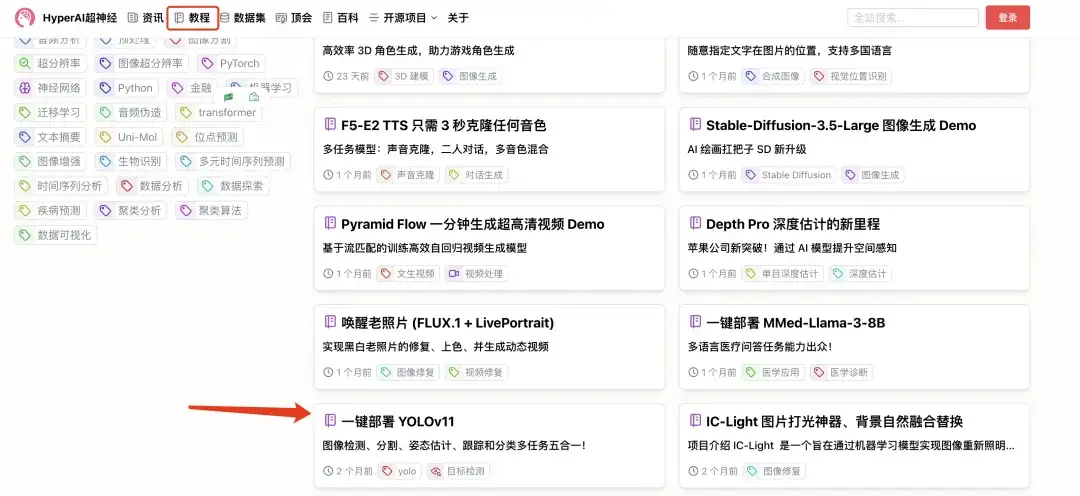
1. hyper.ai에 로그인하고, 튜토리얼 페이지에서 YOLOv11의 원클릭 배포를 선택하고, 이 튜토리얼을 온라인으로 실행을 클릭합니다.
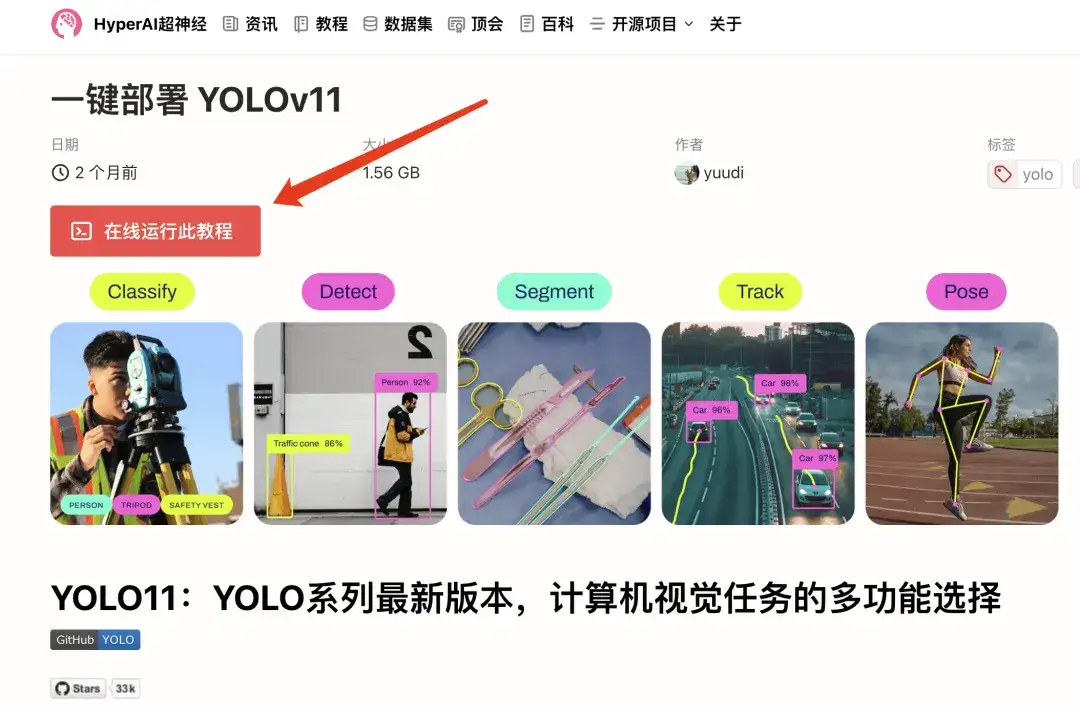
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
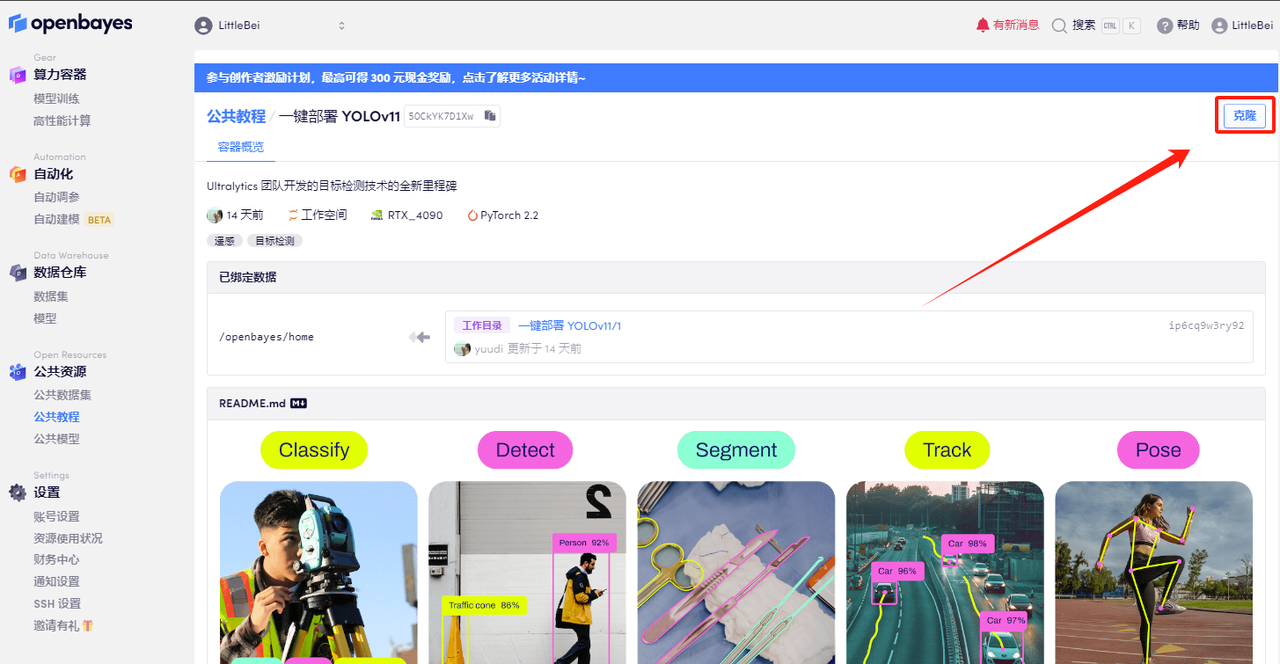
3. 오른쪽 하단에 있는 "다음: 해시레이트 선택"을 클릭합니다.
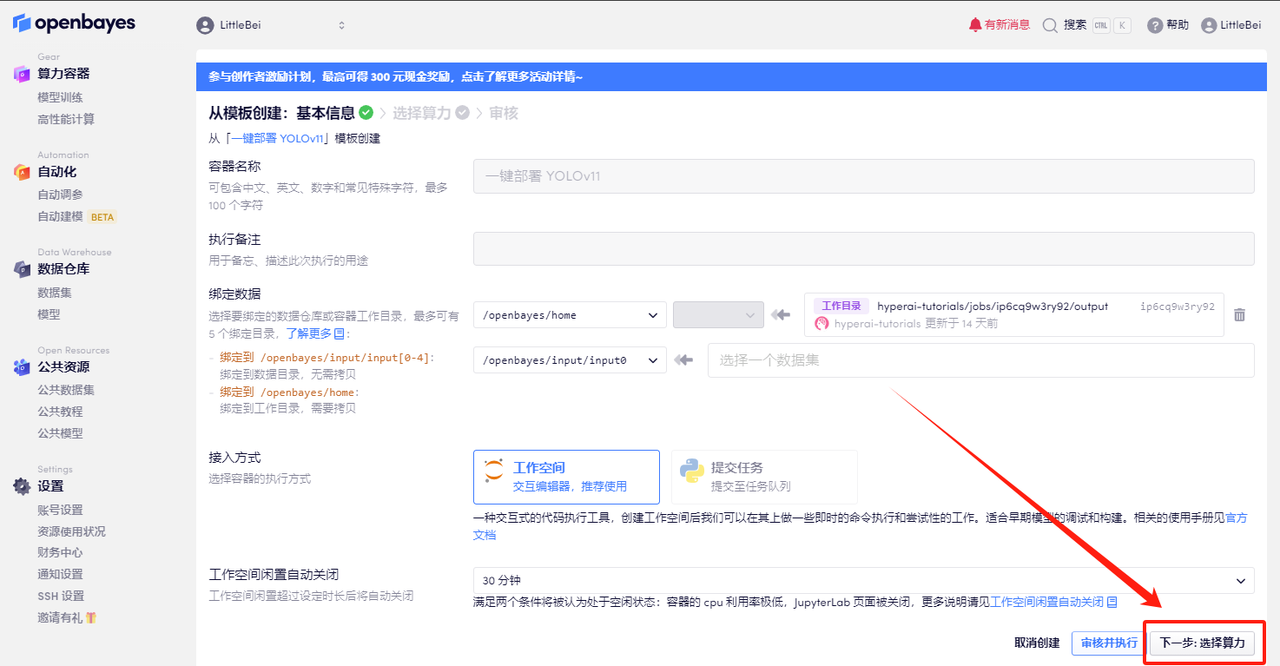
4. 페이지가 이동한 후 "NVIDIA RTX 4090"과 "PyTorch" 이미지를 선택하세요. 사용자는 자신의 필요에 따라 "사용 후 결제" 또는 "일일/주간/월간 패키지"를 선택할 수 있습니다. 선택을 완료한 후 "다음: 검토"를 클릭하세요.신규 사용자는 아래 초대 링크를 사용하여 등록하고 RTX 4090 4시간 + CPU 자유 시간 5시간을 받으세요!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_QZy7
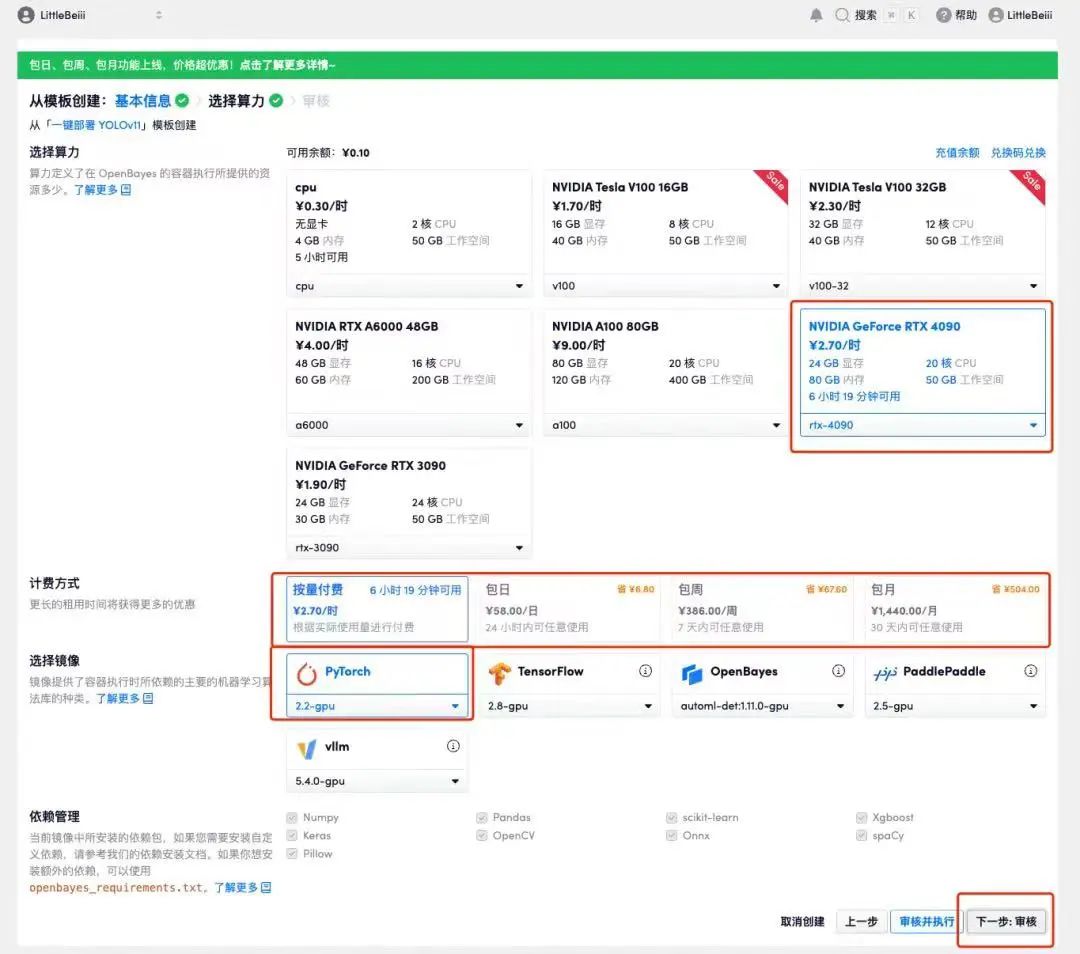
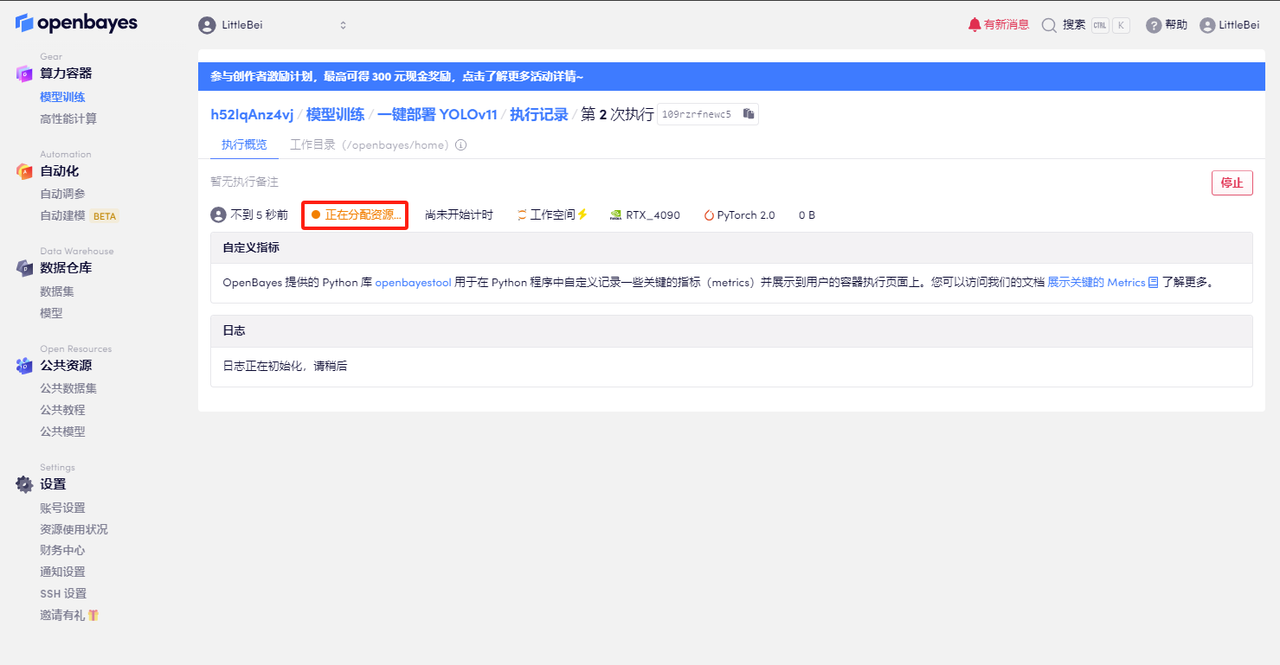
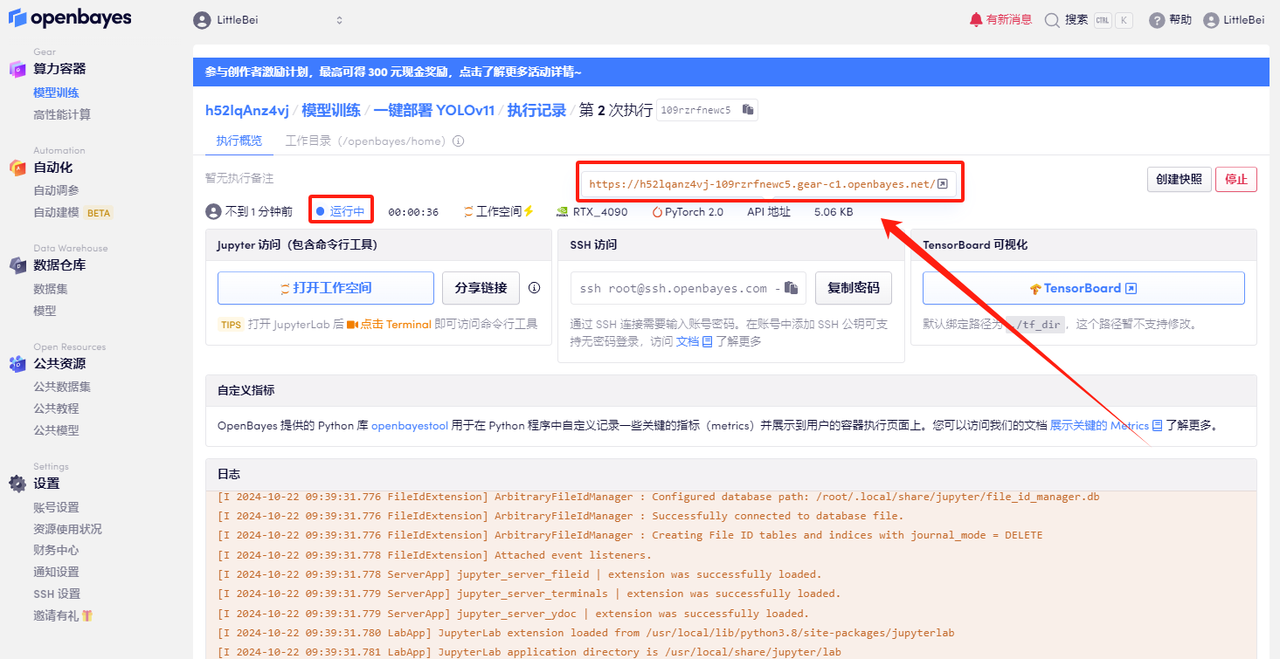
5. 확인 후 "계속"을 클릭하고 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 과정은 약 2분 정도 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다. API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.
효과 시연
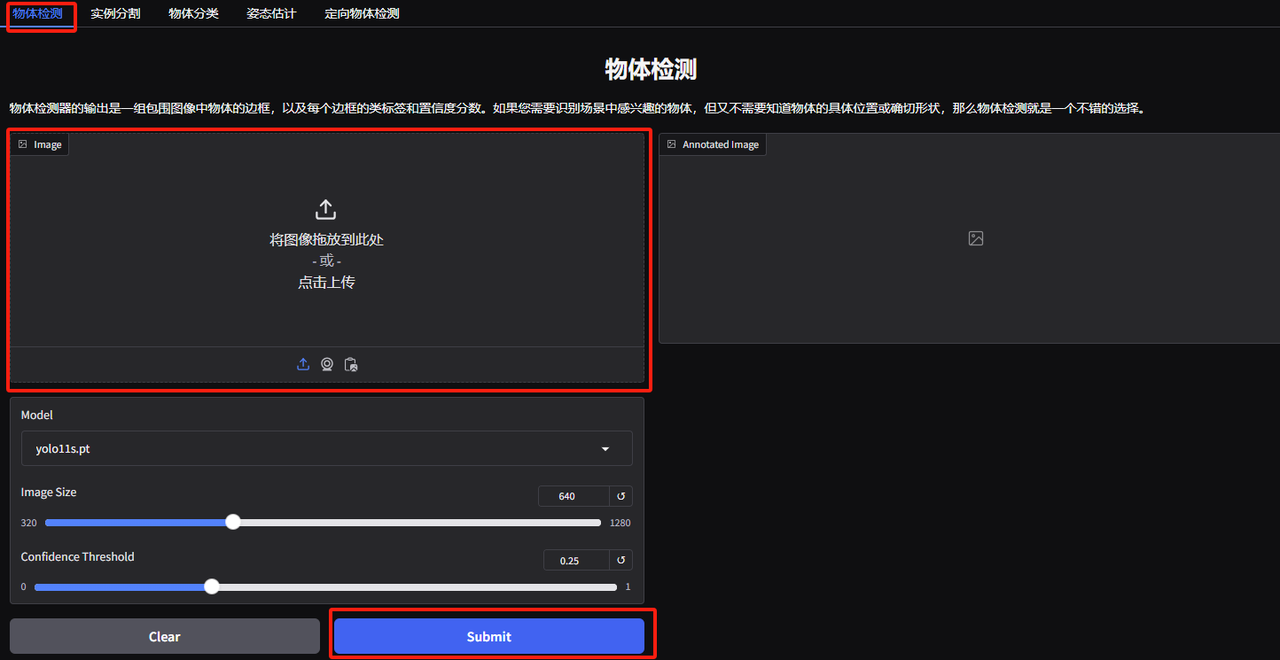
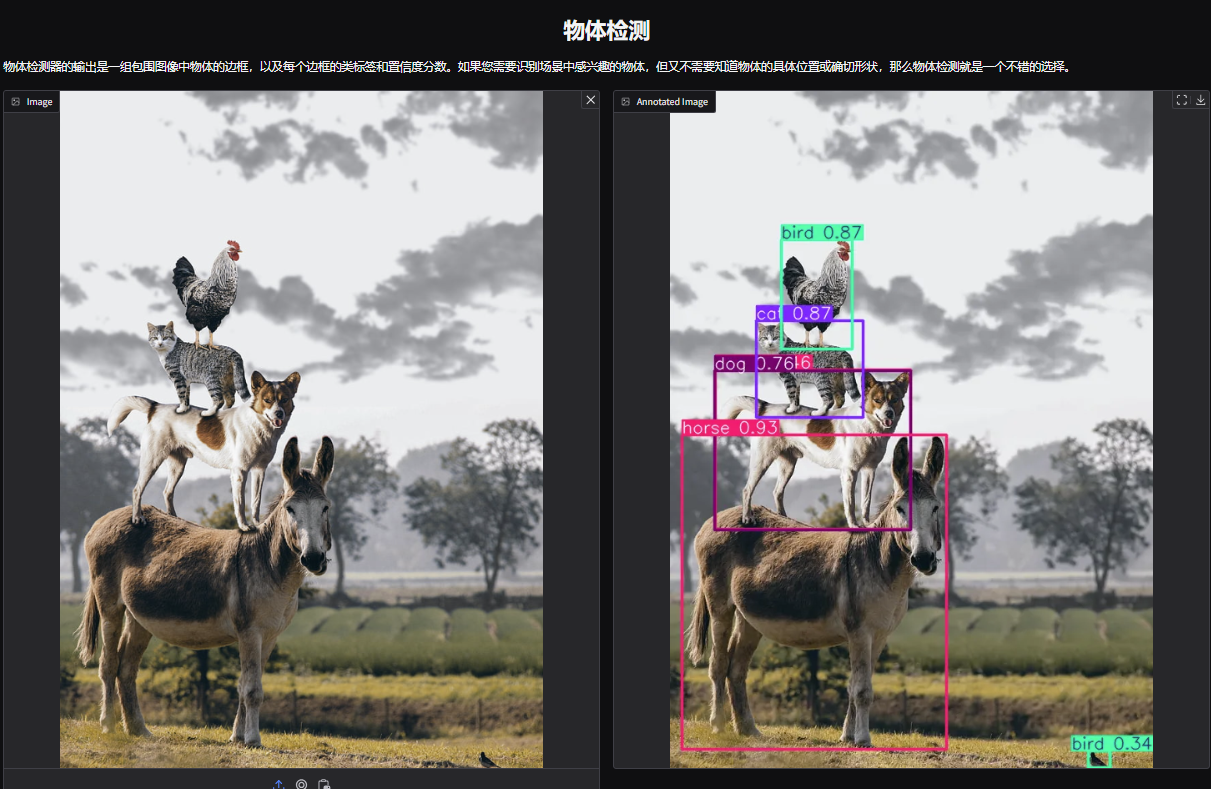
1. YOLOv11 객체 감지 데모 페이지를 엽니다. 쌓인 동물 사진을 업로드하고 매개변수를 조정한 후 "제출"을 클릭했습니다. YOLOv11이 사진 속 모든 동물을 정확하게 감지한 것을 볼 수 있습니다. 오른쪽 하단 모서리에 작은 새가 숨겨져 있는 것이 밝혀졌습니다! 알아차리셨나요?
다음 매개변수는 다음을 나타냅니다.
* 모델:사용을 위해 선택된 YOLO 모델 버전을 나타냅니다.
* 이미지 크기:입력 이미지의 크기. 모델은 감지하는 동안 이미지 크기를 이 크기로 조정합니다.
* 신뢰 임계값:신뢰 임계값은 모델이 타겟 탐지를 수행할 때 이 설정 값을 초과하는 신뢰도를 갖는 탐지 결과만 유효한 타겟으로 간주됨을 의미합니다.
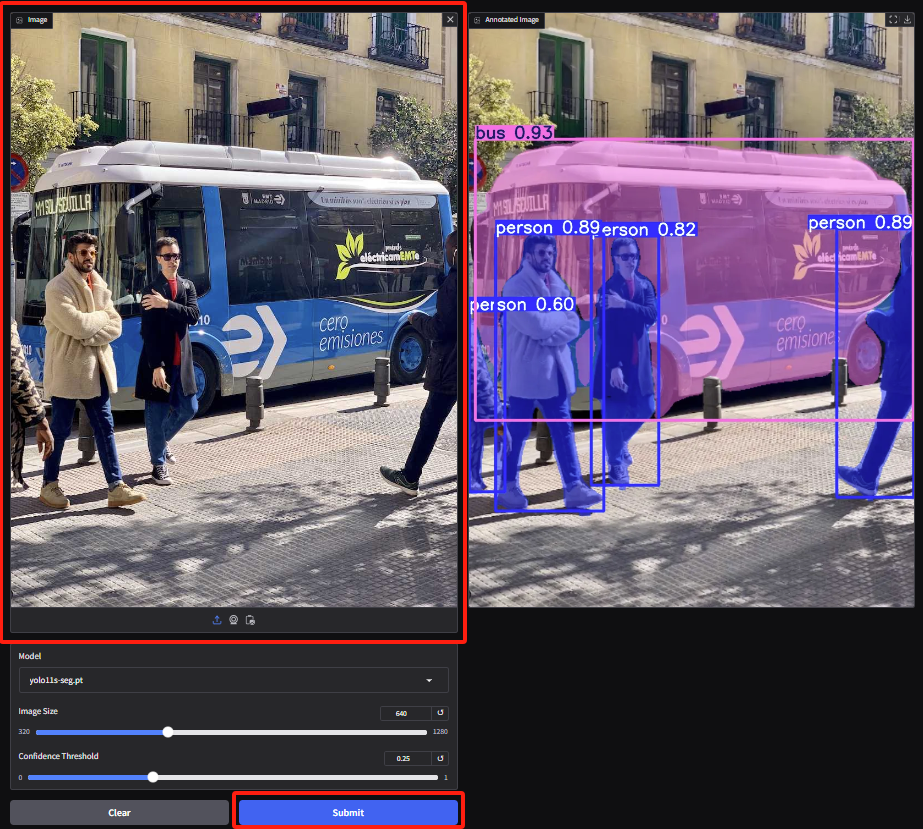
2. 인스턴스 분할 데모 페이지에 접속하여 이미지를 업로드하고 매개변수를 조정한 후, "제출"을 클릭하여 분할 작업을 완료합니다. 폐색이 있더라도 YOLOv11은 사람들을 정확하게 분할하고 버스의 윤곽을 그리는 훌륭한 성과를 보입니다.
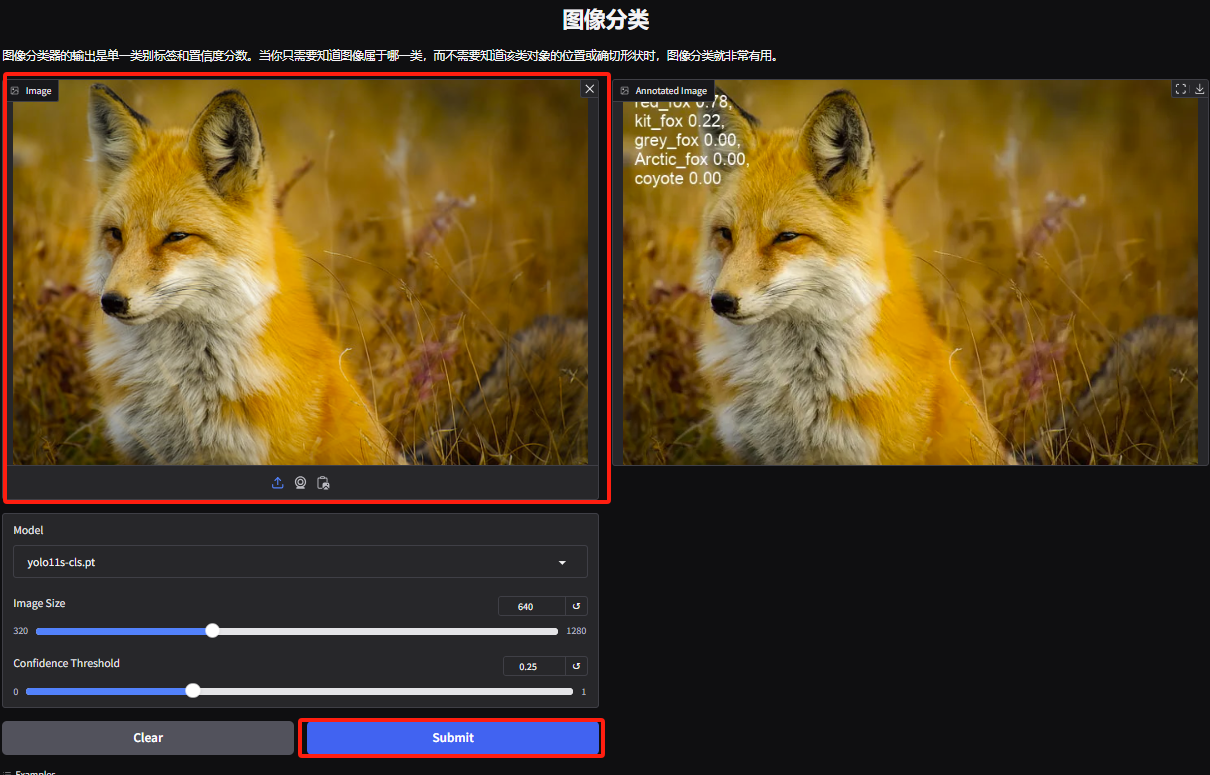
3. 객체 분류 데모 페이지로 들어갑니다. 편집자가 여우 사진을 업로드했습니다. YOLOv11은 사진 속 여우의 특정 종을 붉은 여우로 정확하게 감지할 수 있습니다.
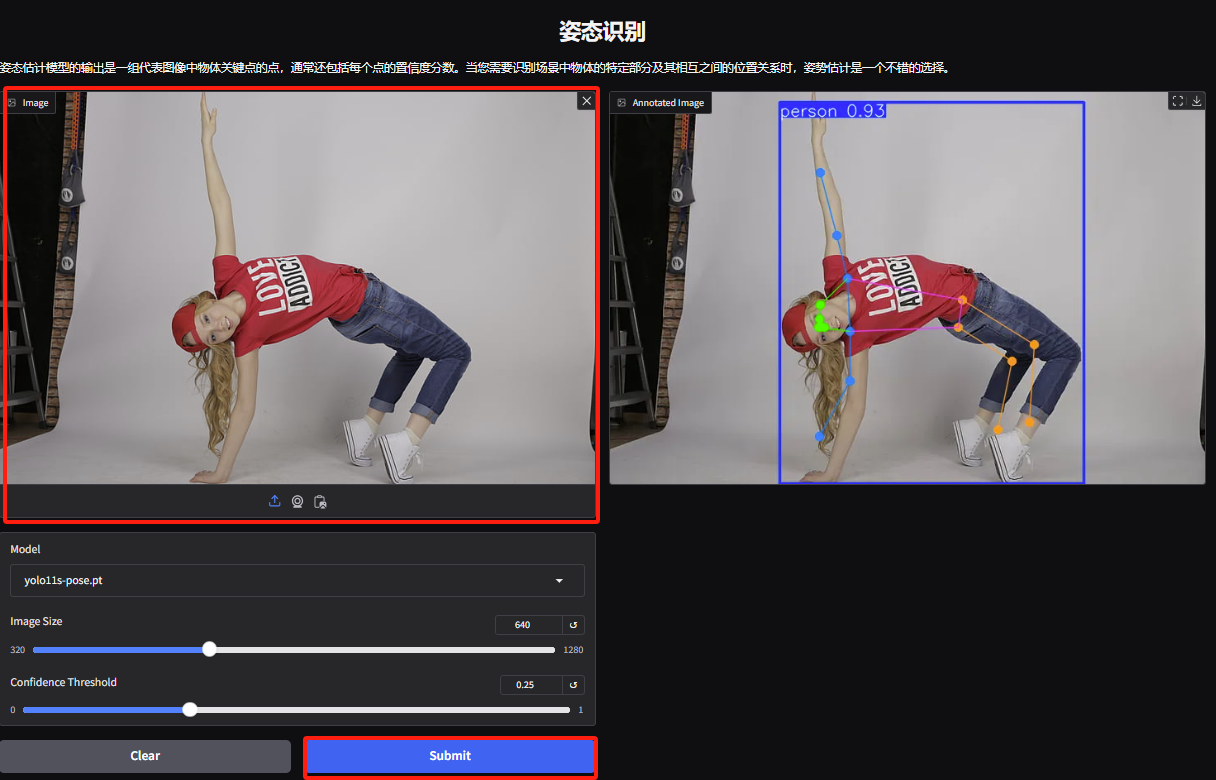
4. 제스처 인식 데모 페이지에 접속하여 사진을 업로드하고, 사진에 따라 매개변수를 조정한 후 "제출"을 클릭하면 제스처 동작 분석이 완료됩니다. 캐릭터의 과장된 신체 움직임을 정확하게 분석한 것을 볼 수 있습니다.
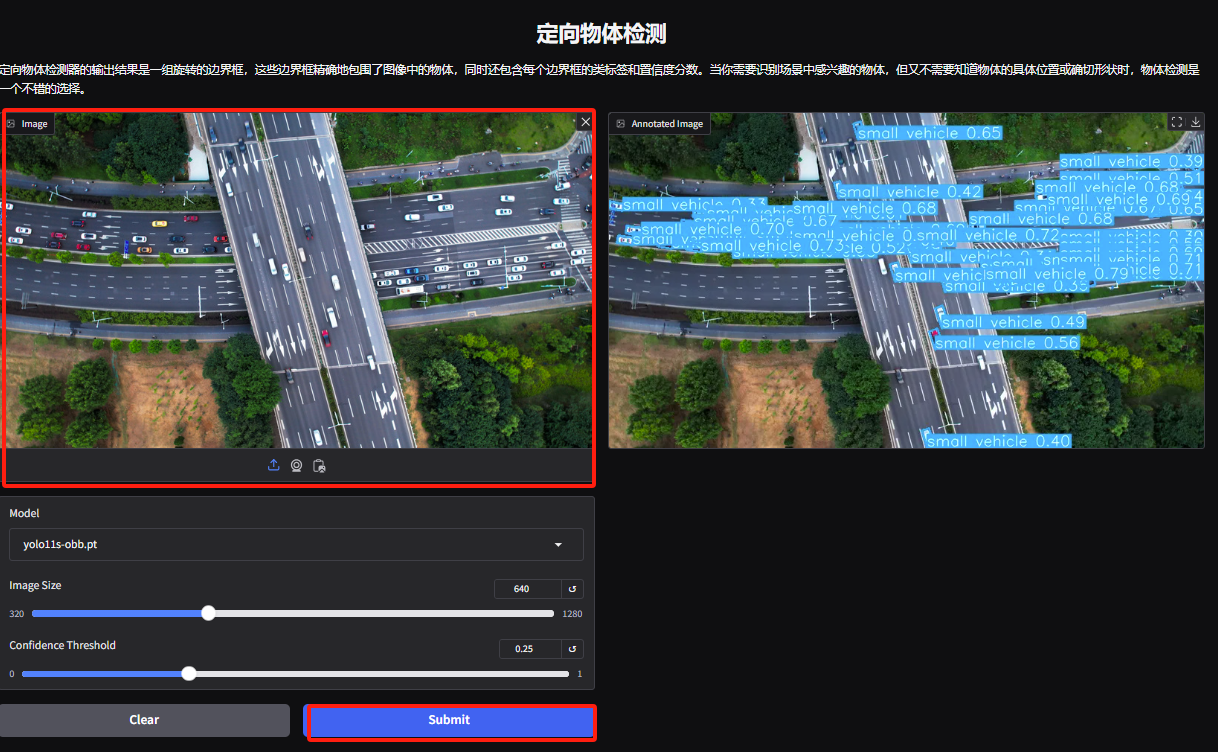
5. Directed Object Detection Demo 페이지에서 이미지를 업로드하고 매개변수를 조정한 다음 "제출"을 클릭하여 객체의 구체적인 위치와 분류를 식별합니다.