Command Palette
Search for a command to run...
퍼듀 대학교 팀은 인간의 반응적 파악을 시뮬레이션하여 로봇 학습을 위한 데이터 효율적인 촉각 표현을 달성했습니다.

촉각은 로봇이 자율 학습을 향해 나아가는 데 없어서는 안 될 부분으로, 기계가 물리적 세계의 세부 사항을 인식할 수 있는 능력을 부여합니다. 그러나 전통적인 촉각 지각 시스템을 훈련하는 데는 종종 막대한 양의 데이터 수집이 필요한데, 이는 비용이 많이 들고 비효율적입니다. 데이터 기반 접근 방식의 한계가 명확해짐에 따라효율적인 데이터 표현을 통해 촉각 학습의 성능을 개선하는 방법은 현재 로봇 연구의 초점 중 하나가 되었습니다.
최근 몇 년 동안 자기 지도 학습, 희소 표현, 교차 모달 지각을 기반으로 한 혁신적인 기술이 빠르게 등장하여 촉각 표현을 단순화하고 최적화하기 위한 새로운 아이디어를 제공했습니다.

이 분야의 획기적인 발전은 로봇이 제한된 데이터로 복잡한 작업에 신속하게 적응할 수 있게 할 뿐만 아니라, 인간과 환경과 상호 작용하는 능력을 크게 향상시킬 것입니다.이러한 혁명적 변화 속에서 데이터 효율적인 촉각 표현 기술은 로봇의 인지와 학습을 위한 새로운 문을 열고 있습니다.
12월 18일, Embodied Touch Community가 주최하고 HyperAI가 공동 주관한 "Newcomers on the Frontier"의 네 번째 온라인 공유 이벤트에서,퍼듀 대학교 박사과정 3학년인 쉬 정통(Xu Zhengtong)은 "로봇 학습을 위한 데이터 효율적 촉각 표현"이라는 주제로 LeTac-MPC와 UniT의 두 가지 주요 과학 연구 결과와 연구 기술 경로를 모든 사람과 공유했습니다.
하이퍼AI는 쉬정통 박사의 심도 있는 공유 내용을 원래 의도를 훼손하지 않고 편집하고 요약했습니다.
미분 가능한 최적화는 로봇 학습에 강력한 도구입니다.
최적화는 로봇공학 분야에서 매우 중요하고 효율적인 도구이며, 궤적 계획과 인간-컴퓨터 상호 작용에서 많은 뛰어난 결과를 보여주었습니다.최적화에 대해 논의하기 전에,먼저, 미분가능 최적화라는 개념을 소개하겠습니다.이 개념을 설명하기 위해, 최적화 문제의 일반적인 공식화부터 시작해 보겠습니다.
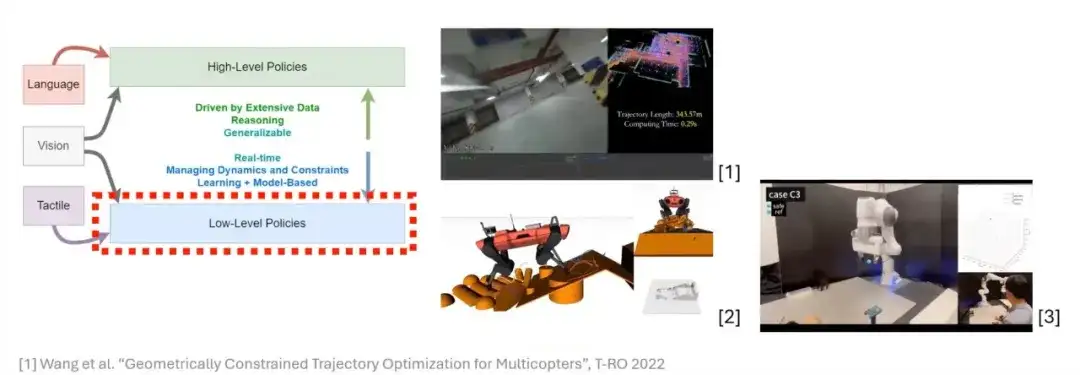
최적화의 핵심 아이디어는 특정 응용 시나리오에 대한 목적 함수(비용 함수)를 구성하는 것입니다.이러한 목적 함수는 일반적으로 많은 사전 지식을 포함하고 있으며 일련의 제약을 받을 수 있습니다. 따라서 최적화 문제를 공식화할 때 종종 이러한 제약 조건을 목적 함수에 추가하는 것이 필요합니다.
다음,우리는 최적화의 기본 형태인 2차 계획법(QP)에 초점을 맞출 것입니다.이는 최적화 분야에서 가장 간단한 형태 중 하나이지만 실제 적용에서는 여전히 광범위한 시나리오를 가지고 있습니다.

이러한 기초 위에서 우리는 "미분가능성"이라는 개념을 도입합니다. 미분가능성은 신경망에서 각 층의 출력이 내부 매개변수의 편미분을 계산할 수 있음을 의미합니다.미분가능 이차 프로그래밍(Differentiable QP)을 도입하는 것의 중요성은 다음과 같습니다.신경망에 최적화 계층을 추가하려면 해당 계층이 미분 가능한지 확인해야 합니다. 이런 방식으로만 최적화 계층의 매개변수가 자연스럽게 업데이트되고 네트워크 학습 및 추론 중에 그래디언트 정보를 통해 흐를 수 있습니다. 따라서 이차 계획법 문제를 미분 가능하게 만들 수 있다면, 이를 신경망에 통합하여 네트워크의 일부로 만들 수 있습니다.
더욱이 로봇 학습의 최적화 문제는 목적 함수와 제약 조건의 설계와 같이 특정 시나리오에 대한 사전 지식에 의존하는 경우가 많습니다. 미분 가능한 최적화 문제를 공식화함으로써, 우리는 이러한 사전 지식을 최대한 활용하고 이를 모델 설계에 효율적으로 통합할 수 있습니다. 그러나 어떤 경우에는 모델 기반 방식으로 문제를 설명할 수 없을 수도 있습니다(즉, 모델 기반 표현을 구성할 수 없습니다). 이와 관련하여,데이터 기반 방법을 사용하여 모델이 스스로 이러한 부분의 규칙을 학습하도록 할 수 있습니다. 이것이 미분 가능한 최적화 문제의 핵심 아이디어입니다.
요약하자면, 이차 계획법 문제는 미분가능하다는 특성을 가지고 있으므로 신경망의 일부로 도입할 수 있습니다.이러한 접근 방식은 네트워크 설계를 위한 새로운 도구를 제공할 뿐만 아니라, 로봇 학습에서 모델 설계에 더 많은 유연성과 가능성을 제공합니다.
LeTac-MPC: 촉각 신호 기반 반응성 파악 및 모델 제어 방법 연구
우리는 반응적 파악이라는 개념을 제안합니다.인간이 물건을 잡는 과정을 관찰한 결과, 인간은 주로 손가락을 통해 물건의 속성과 상태를 인지하고, 피드백을 바탕으로 손가락의 움직임을 조절한다는 사실을 발견했습니다. 예를 들어:
* 계란을 잡을 때 우리는 계란이 단단하지만 깨지기 쉽다고 느끼기 때문에 손상을 피하기 위해 적절한 힘을 가합니다. 손가락 피드백 압력이 증가할수록 그립력은 약해집니다.
* 빵을 잡을 때 빵이 부드러우므로 손가락의 움직임이 그에 맞게 조절되어 빵이 압착되어 변형되는 것을 방지합니다.
* 우유병을 잡을 때, 병을 흔들면 우유가 흔들리면서 물체의 관성이 변합니다. 손가락은 이러한 변화를 감지하고 병이 관성으로 인해 미끄러지는 것을 방지하기 위해 그립 동작을 동적으로 조절합니다.

반응형 파악 로봇 구현
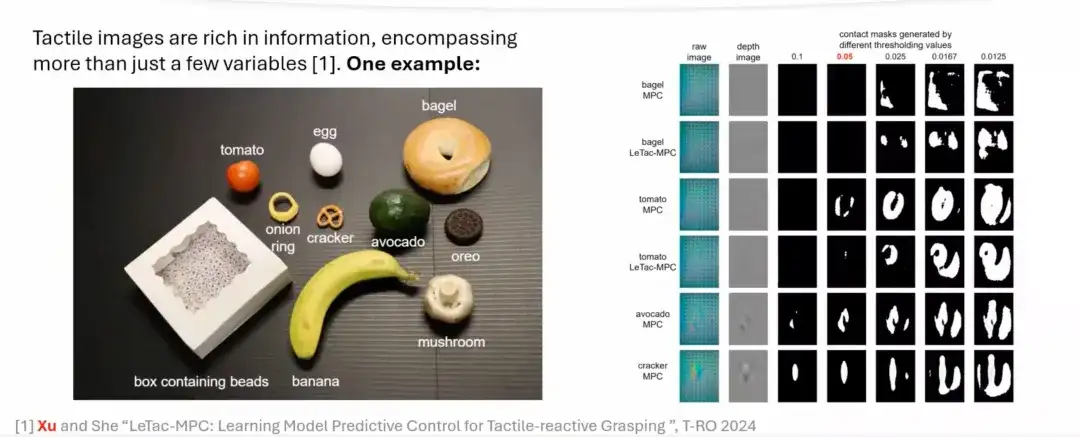
인간의 파악 과정을 바탕으로, 모델 기반 접근 방식을 통해 이 과정을 시뮬레이션하는 방법을 살펴보겠습니다.GelSight와 같은 시각 기반 촉각 센서를 사용하면원본 이미지에서 주요 특징을 추출하고, 간단한 처리를 통해 깊이 이미지나 차이 이미지를 생성하고, 임계값 연산을 통해 접촉 면적을 계산할 수 있습니다. 접촉 면적은 가해진 힘의 크기를 반영할 수 있습니다. 힘이 클수록 접촉면은 커진다. 힘이 작을수록 접촉면적은 작아집니다.
또한, 광학 흐름 기술을 사용하여 마커의 움직임을 추적하면 또 다른 중요한 양인 변위를 얻을 수 있습니다.이 양은 측면력과 관련이 있습니다. 이러한 신호를 결합하면 촉각 반응형 파악을 달성하기 위한 비례-미분(PD) 제어기를 기반으로 한 제어 방법을 구성할 수 있습니다.
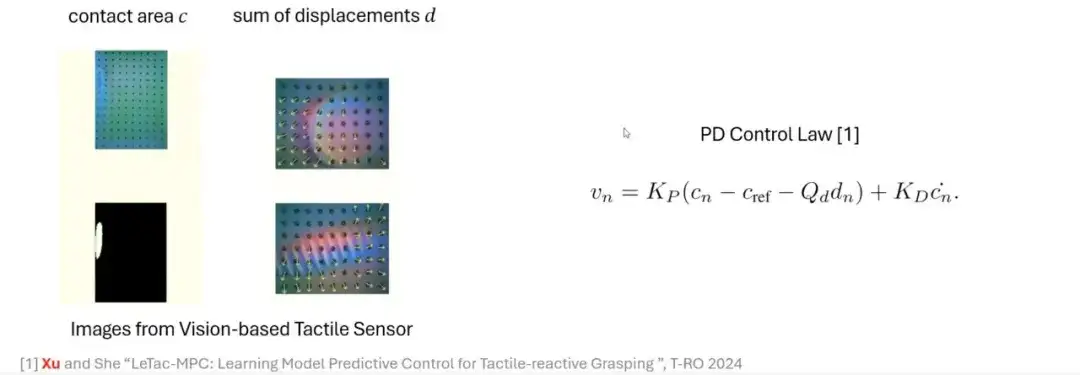
PD 컨트롤러에서 MPC 컨트롤러로
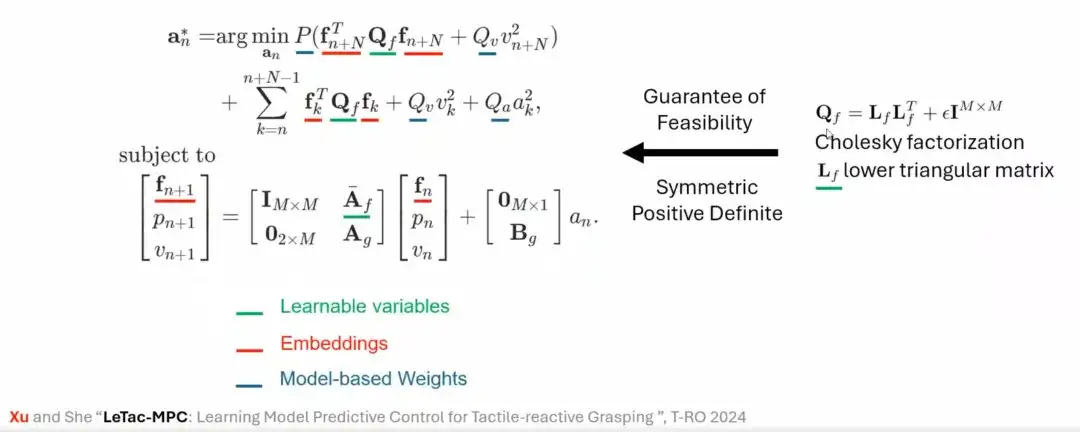
PD 컨트롤러 외에도 우리는 모델 예측 컨트롤러(MPC)를 기반으로 하는 파악 방법도 설계했습니다. MPC의 제어 목적은 PD 제어기와 유사하지만, 그 특징은 선형 가정과 그리퍼 모델에 기반합니다. 예를 들어, 선형 가정과 단일 자유도 그리퍼 동작 모델을 먼저 도입한 다음, 이 둘을 통합하여 모델링하고 마지막으로 MPC 기반 제어 법칙을 구성합니다.
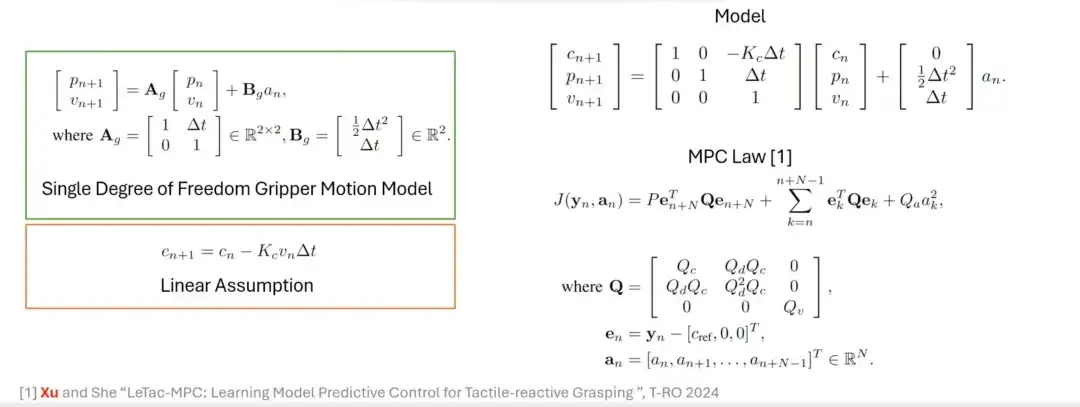
MPC 컨트롤러의 응용 및 제한 사항
MPC 컨트롤러 모델은 많은 시나리오에서 좋은 성능을 발휘합니다.여기서는 두 가지 응용 프로그램을 나열합니다.첫 번째 응용 프로그램은 다음과 같습니다.바나나를 끌 때 그립퍼는 바나나의 동적 피드백에 따라 힘을 조절하여 안정적인 그립을 보장합니다. 외부 힘이 제거되면(예: 사람이 바나나를 놓는 경우), 컨트롤러는 점차 안정된 상태로 수렴합니다.
서류 주소:
https://ieeexplore.ieee.org/document/10684081
두 번째 응용 프로그램은 IROS의 우리 그룹 내 다른 멤버가 제안한 결과입니다.즉, 복잡한 작업 작업을 실현하기 위해 다자유도 그리퍼를 사용하고, 우리가 제안한 MPC 컨트롤러를 채택했습니다.
서류 주소:
https://arxiv.org/abs/2408.00610

그러나 모델 기반 컨트롤러는 특정한 한계를 가지고 있으며 실제 생활에서 대부분의 일상 사물에 일반화하기 어렵습니다.이는 주로 모델링 과정에서 가정이 단순화되었기 때문이며, 이러한 가정은 일부 실제 객체에는 적용되지 않는 경우가 많습니다. 아래 그림에서 보듯이, 부드러운 물체나 복잡한 형상의 물체의 경우 단순히 임계값을 설정하는 것만으로는 접촉 면적을 정확하게 추출하기 어렵습니다. 그러나 아보카도나 비스킷과 같이 단단한 물체의 경우 촉각 신호(촉각 이미지)가 더 강하므로 접촉 면적을 정확하게 추출할 수 있습니다.
LeTac-MPC 컨트롤러의 세 가지 주요 장점
이 문제를 해결하기 위해 우리는 수학적 방법(예: 콜레스키 분해)을 사용하여 최적화 문제의 해결 가능성을 보장하고, 이를 통해 제어기의 학습 과정을 안정화했으며, 마지막으로 LeTac-MPC를 제안했습니다.
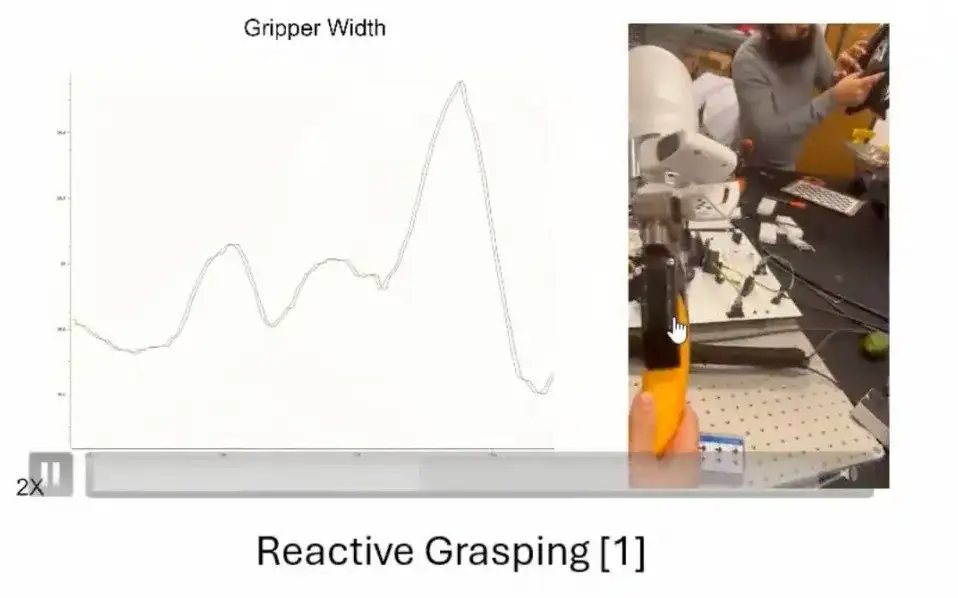
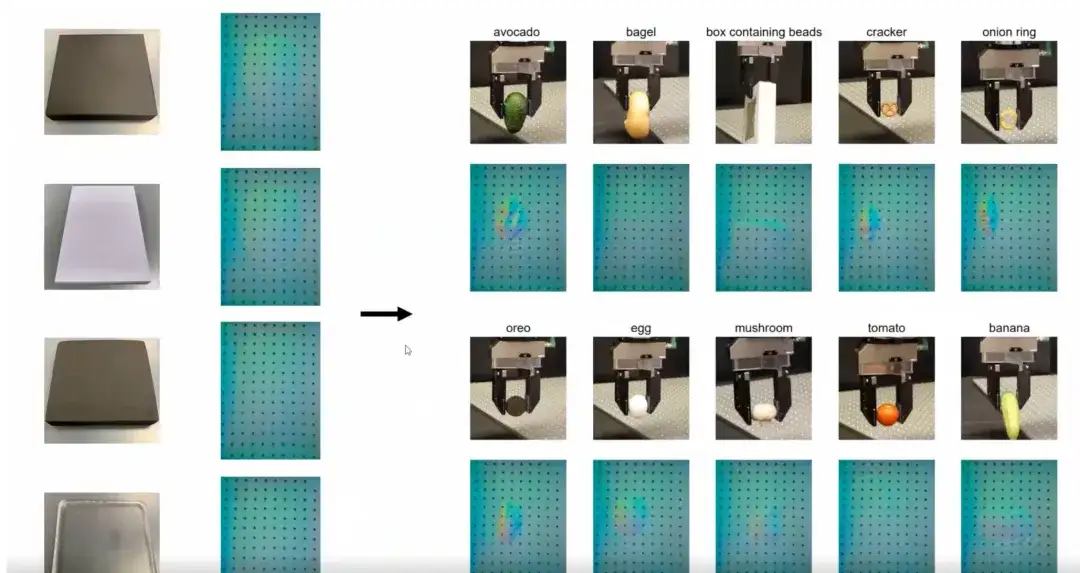
아래 그림은 가장 직관적인 훈련 결과를 보여줍니다. 우리는 경도가 다른 4개의 객체만 포함된 데이터 세트로 학습했습니다. 이러한 물체는 서로 다른 강성을 가지고 있습니다. 제한된 학습 데이터에도 불구하고, 우리는 다양한 크기, 모양, 재료, 질감의 일상 사물에 일반화되는 컨트롤러를 학습합니다.소규모 샘플 학습을 기반으로 한 이러한 일반화 능력은 컨트롤러의 주요 장점입니다.
두 번째로, 우리는 컨트롤러가 잡은 물체의 간섭에 강하도록 훈련합니다.실시간으로 잡는 방법과 강도를 조절하여, 외부 간섭으로 인해 잡은 물건이 떨어지지 않도록 할 수 있습니다.
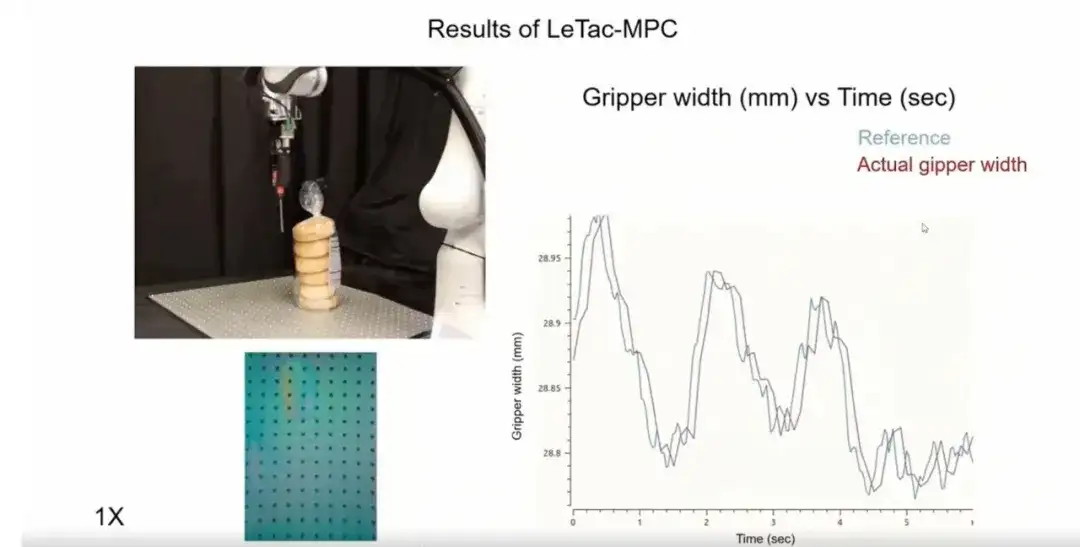
셋째, 우리가 훈련시키는 컨트롤러의 반응성이 매우 뛰어납니다.아래 그림에서 보듯이, 강렬한 움직임이나 관성 변화가 있는 시나리오(예: 파편으로 가득 찬 상자)에서 컨트롤러는 물체의 동적 변화에 신속하게 대응할 수 있습니다.
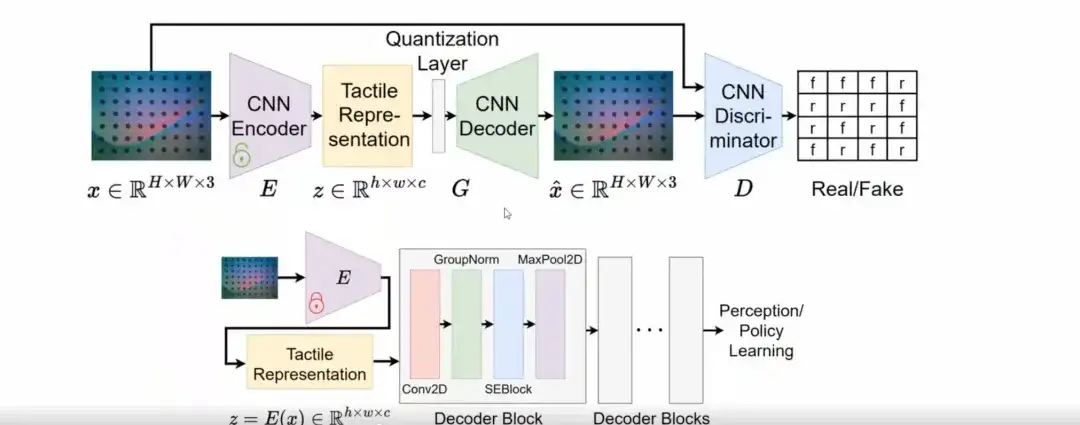
UniT: 로봇 학습을 위한 통합 촉각 표현
위의 연구를 통해 우리는 제어기의 일반화 능력을 달성했습니다. 단일한 간단한 물체를 사용하여 통합된 촉각 표현을 배울 수 있을까?
아래 그림에서 보듯이, 하나의 간단한 물체는 작은 공이나 렌치(앨런 키 등)와 같이 기하학적으로 간단한 물체일 수 있습니다. 이러한 물체의 촉각적 이미지는 비교적 단순하므로, 우리의 방법 역시 비교적 간단합니다.

구체적으로, 완전히 새로운 네트워크 구조를 설계하는 대신, VQGAN은 일반화 기능을 통해 촉각 표현을 효과적으로 학습할 수 있다는 것을 발견했습니다.
훈련 단계에서는 VQGAN 모델을 채택하여 촉각 표현을 학습합니다. 추론 단계에서는 VQGAN의 잠재 공간이 간단한 합성곱 계층을 통해 디코딩되어 인식이나 정책 학습과 같은 하위 작업에 연결됩니다.
서류 주소:
https://arxiv.org/abs/2408.06481
재건 실험
표현의 효과를 검증하기 위해 Allen Key와 Small Ball에 대한 재구성 실험을 수행했습니다.
첫 번째는 앨런 키 실험입니다.아래 그림에서 볼 수 있듯이, 훈련 데이터는 Allen Key에서만 나왔지만, 잠재 공간을 통해 보이지 않는 물체의 원본 이미지를 재구성할 수 있습니다. 즉, 잠재 공간에 원본 이미지의 유용한 정보가 대부분 담겨 있다는 것을 알 수 있습니다. MAE와 비교했을 때, MAE는 원본 이미지를 정확하게 재구성하는 데 어려움이 있는 것으로 나타났으며, 이는 MAE가 디코딩 과정에서 정보 손실이 발생할 수 있음을 시사합니다.

두 번째는 스몰볼 실험입니다.아래 그림에서 볼 수 있듯이, 훈련 데이터가 Small Ball에서만 나왔고 재구성 효과가 Allen Key만큼 좋지는 않지만, 이 모델은 어느 정도까지는 복잡한 객체의 원래 신호를 재구성할 수 있습니다.

또한 잠재 공간은 촉각적 기하학적 정보(모양 및 접촉 구성 등)를 포착할 뿐만 아니라, 마커의 움직임 정보도 암묵적으로 담고 있습니다. 예를 들어, 원본 이미지와 재구성된 이미지의 마커를 추적한 결과, 마커 추적 성능이 매우 유사하다는 것을 발견했습니다.

다운스트림 작업 및 벤치마크
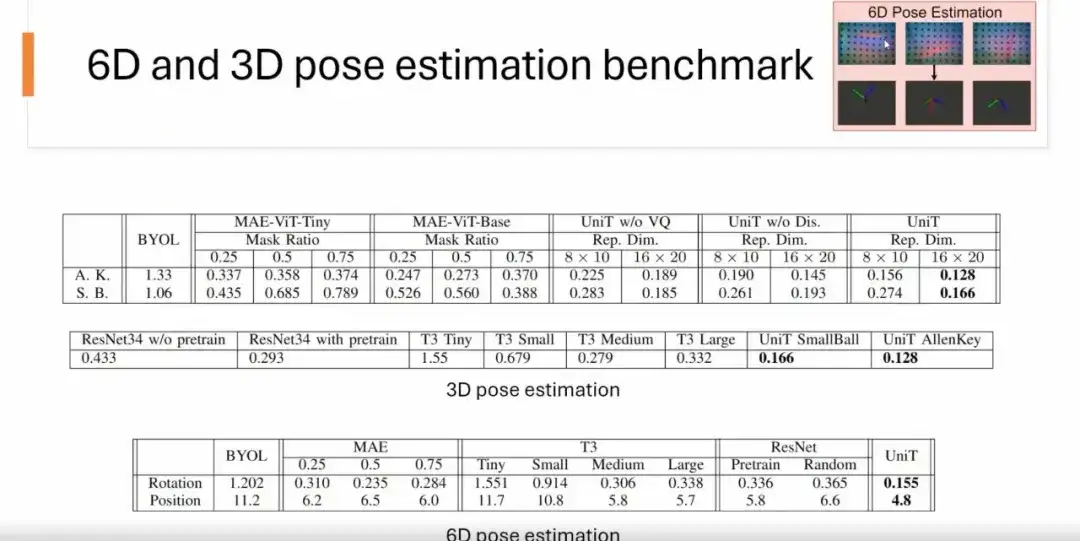
우리는 6D 포즈 추정, 3D 포즈 추정, 분류 벤치마크를 포함한 다양한 벤치마크에서 UniT 방법의 표현 능력을 테스트했습니다.
6D 포즈 추정의 경우,우리는 촉각적 원시 이미지(예: USB 플러그의 촉각적 이미지)를 입력하여 해당 위치와 회전을 예측합니다. 결과에 따르면, MAE, BYOL, ResNet 및 T3 방법과 비교했을 때 UniT 모델이 정확도 면에서 다른 방법보다 우수한 것으로 나타났습니다.
3D 포즈 추정을 위해,우리는 물체의 회전 자세만 예측합니다. 아래 그림에서 볼 수 있듯이 UniT은 다른 방법보다 성능이 더 좋습니다.
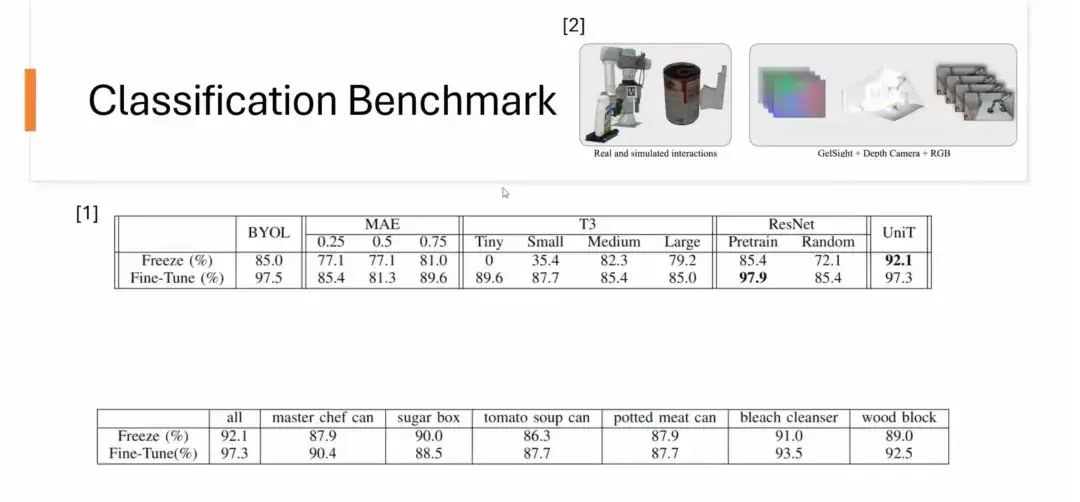
두 번째로, 우리는 분류 벤치마크도 수행했습니다.이 데이터 세트는 CMU의 YCBSight-Sim에서 나왔습니다. 데이터 세트의 크기는 작지만 UniT은 분류 작업에서 좋은 성능을 보여줍니다. 특히, 단일 물체에 대한 촉각 표현을 학습한 후에는 이를 자연스럽게 다른 보이지 않는 물체의 분류 작업으로 일반화할 수 있습니다. 예를 들어, 마스터 셰프에 대해서만 훈련된 표현은 6가지 서로 다른 물체의 분류에 성공적으로 적용될 수 있으며, 뛰어난 결과를 얻을 수 있습니다. 단일 객체에 대해 학습한 표현 중 일부는 많은 수의 객체에 대해 학습한 표현보다 성능이 더 뛰어납니다.
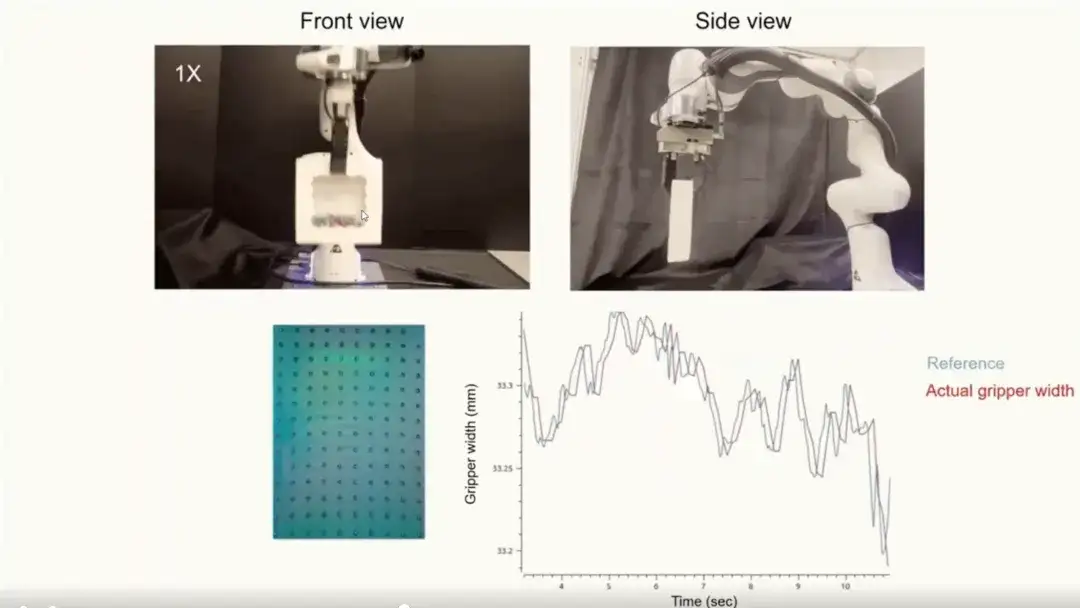
전략 학습 실험
우리는 정책 학습 실험에 촉각적 표현을 더 적용했습니다.복잡한 작업에서의 성능을 검증합니다. 실험에서는 Allen Key 데이터를 사용하여 훈련을 했고 다음 세 가지 작업을 평가했습니다.
* 앨런 렌치 삽입(왼쪽 참조): 정밀한 삽입 작업으로 매우 높은 정확도가 요구됩니다.
* 칩 잡기(그림 참조): 깨지기 쉬운 물건을 섬세하게 잡는 작업.
닭다리 매달기(오른쪽 참조): 장시간의 역동적인 움켜쥐기와 제어를 필요로 하는 양팔 작업입니다.

우리는 세 가지 다른 방법을 벤치마킹했습니다.세 가지 방법은 다음과 같습니다. 시각 전용(시각 신호에만 의존), 스크래치로부터 시각-촉각(시각과 촉각의 공동 훈련), UniT을 활용한 시각-촉각(전략 학습을 위해 UniT에서 추출한 촉각 표현을 사용)입니다. 아래 그림에서 보듯이 UniT 표현을 이용한 정책 학습 방법이 모든 작업에서 가장 좋은 성과를 보입니다.

앞으로도 HyperAI는 체현된 터치 커뮤니티가 온라인 공유 활동을 지속하고, 국내외 전문가와 학자를 초대하여 최첨단 결과와 통찰력을 공유할 수 있도록 지원할 것입니다. 기대해주세요!