Command Palette
Search for a command to run...
온라인 튜토리얼 | YOLOv11을 실제로 사용해 보세요! 속도와 정확도를 모두 갖춘 강력한 객체 감지 도구

YOLO 모델은 항상 객체 감지를 위한 고전적인 선택이었습니다. YOLOv11은 차세대 타겟 감지 모델입니다.이 제품은 기존 시리즈의 높은 효율성과 실시간 성능을 계속 유지할 뿐만 아니라 감지 정확도와 복잡한 시나리오에 대한 적응 능력을 크게 향상시켜 더 강력한 정확도, 더 빠른 속도, 더 스마트한 추론 성능을 제공합니다.
YOLOv11은 기본 객체 감지 및 객체 분류부터 세부적인 인스턴스 분할까지, 심지어 자세 추정을 통해 사람이나 객체의 움직임을 분석하는 것까지 여러 가지 시각적 작업을 동시에 완료할 수 있습니다. 동시에 YOLOv11은 객체 감지 위치 지정에도 좋은 성능을 보입니다. 더욱 복잡한 시나리오의 요구 사항을 충족시키기 위해 이미지에서 타겟을 정확하게 찾아 식별할 수 있습니다. 예를 들어, 자율주행에서는 앞의 차량과 보행자를 정확하게 식별할 수 있을 뿐만 아니라, 차선과 교통 표지판의 위치도 정확하게 파악하여 주행 안전을 확보할 수 있습니다.
HyperAI HyperNeural 튜토리얼 섹션이 이제 "YOLOv11의 원클릭 배포"로 온라인에 공개되었습니다. 튜토리얼은 모든 사람을 위한 환경을 설정했습니다. 어떤 명령도 입력할 필요가 없습니다. YOLOv11의 강력한 기능을 빠르게 살펴보려면 복제를 클릭하세요!
튜토리얼 주소:
https://go.hyper.ai/ycTq1
데모 실행
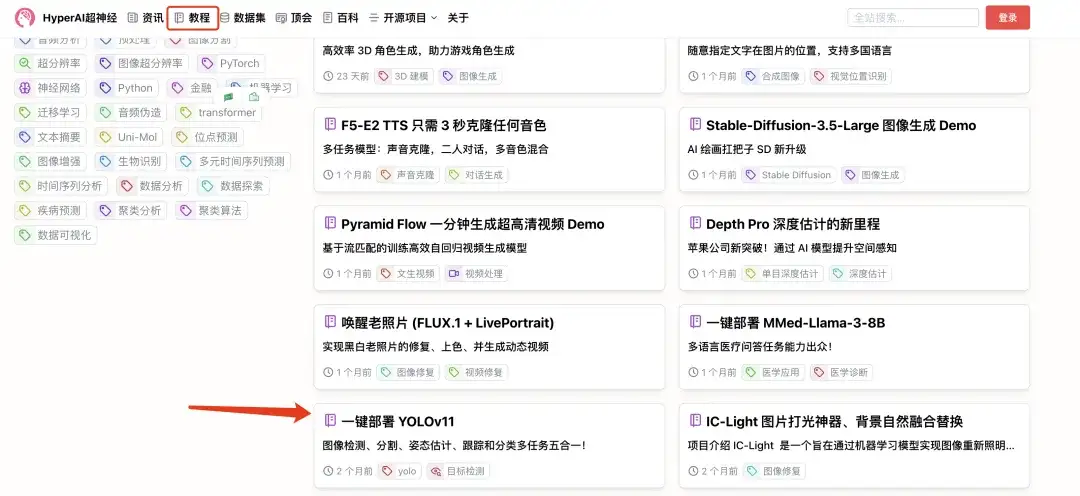
1. hyper.ai에 로그인하고, 튜토리얼 페이지에서 YOLOv11의 원클릭 배포를 선택하고, 이 튜토리얼을 온라인으로 실행을 클릭합니다.
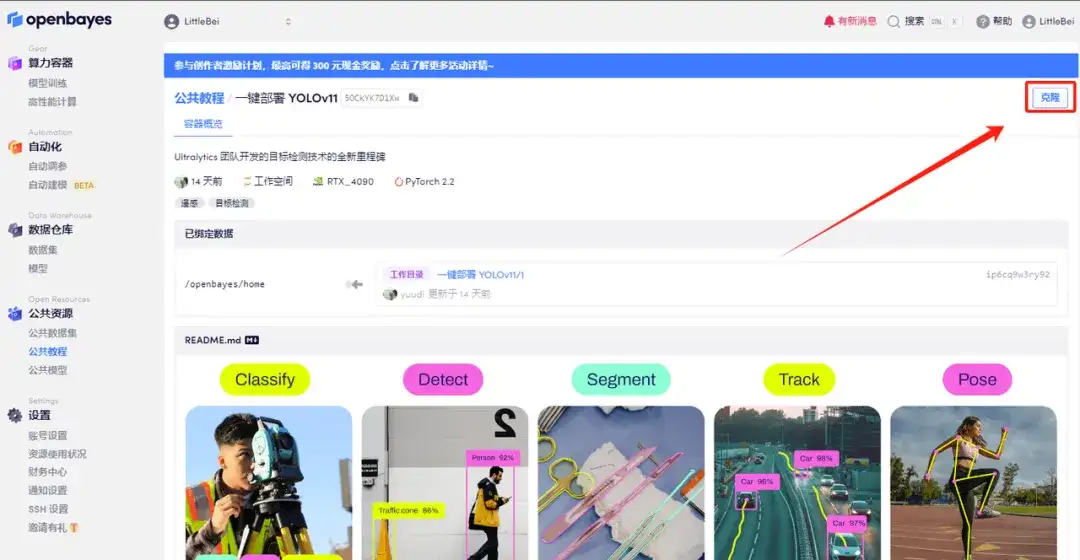
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
3. 오른쪽 하단에 있는 "다음: 해시레이트 선택"을 클릭합니다.
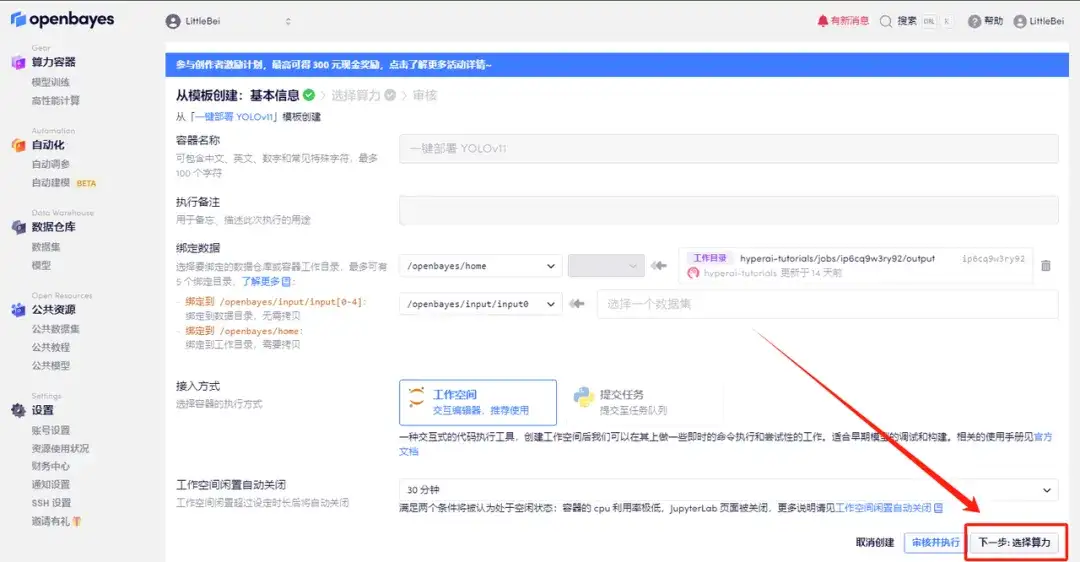
4. 페이지가 이동한 후 "NVIDIA RTX 4090"과 "PyTorch" 이미지를 선택하세요. 사용자는 자신의 필요에 따라 "사용한 만큼 지불" 또는 "사용한 만큼 지불"을 선택할 수 있습니다. 「일일/주간/월간」선택을 완료한 후 "다음: 검토"를 클릭하세요.신규 사용자는 아래 초대 링크를 사용하여 등록하고 RTX 4090 4시간 + CPU 자유 시간 5시간을 받으세요!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_QZy7
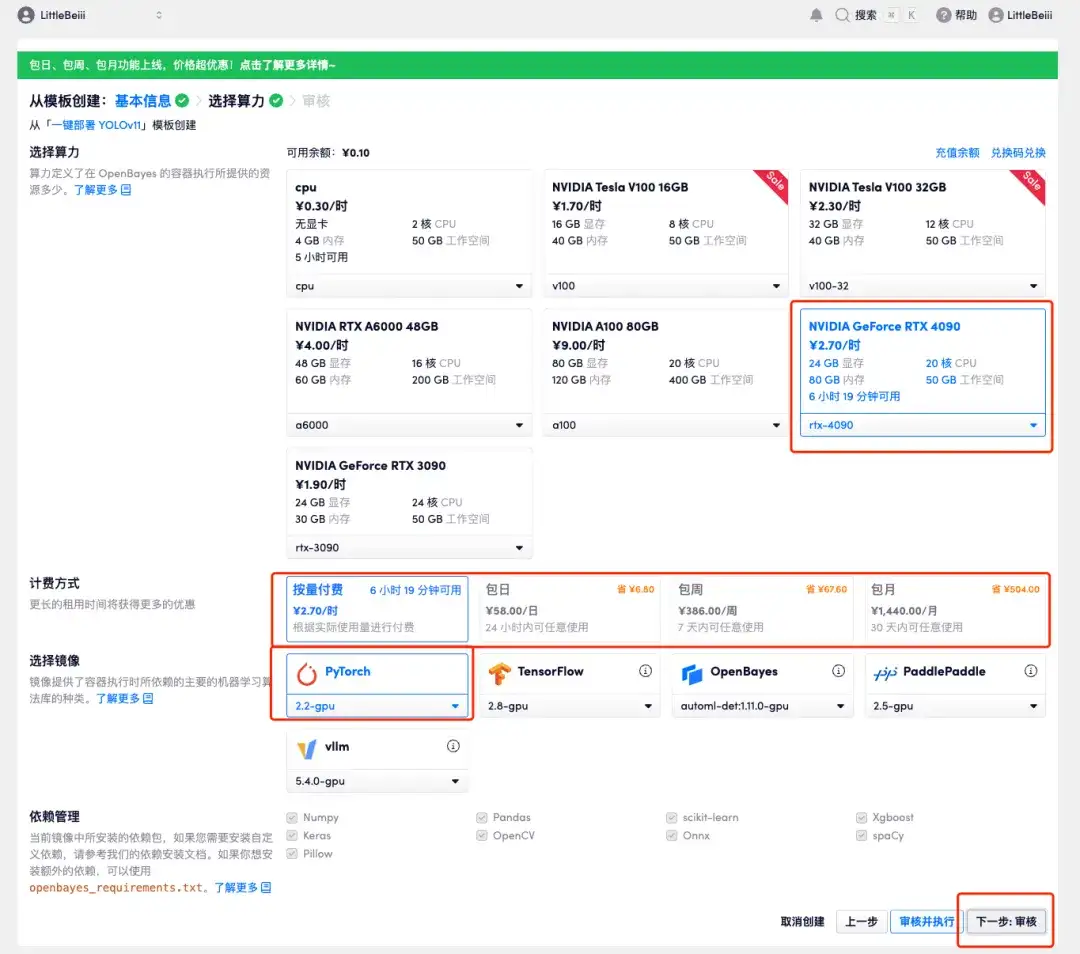
5. 확인 후 "계속"을 클릭하고 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 과정은 약 2분 정도 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다.API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.
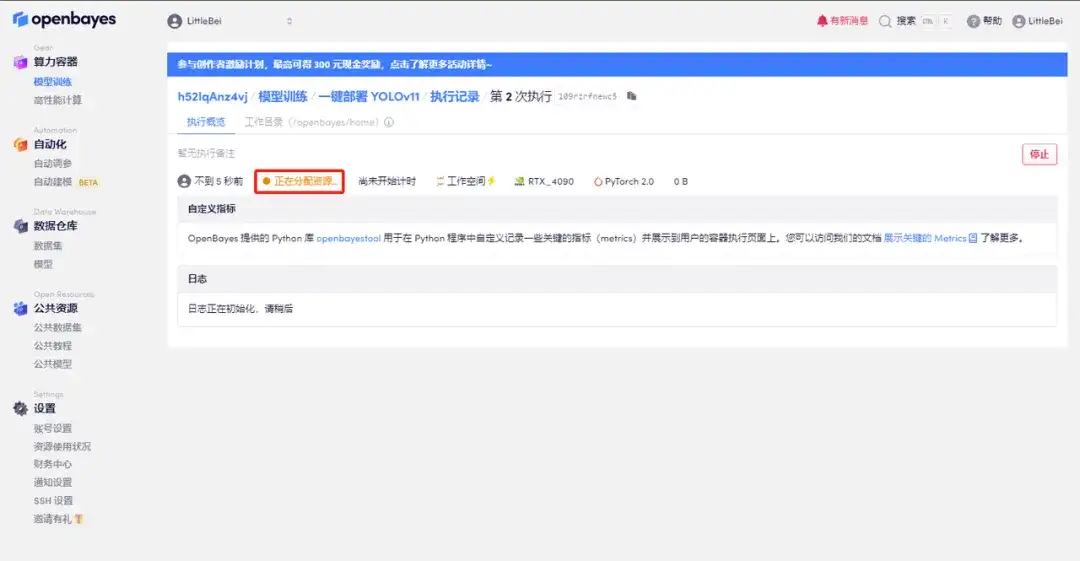
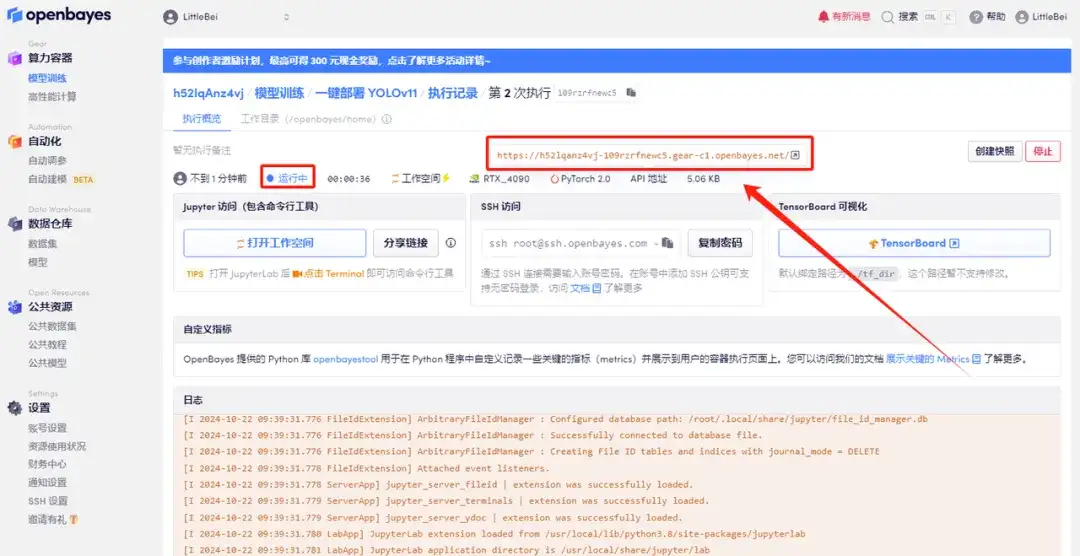
효과 시연
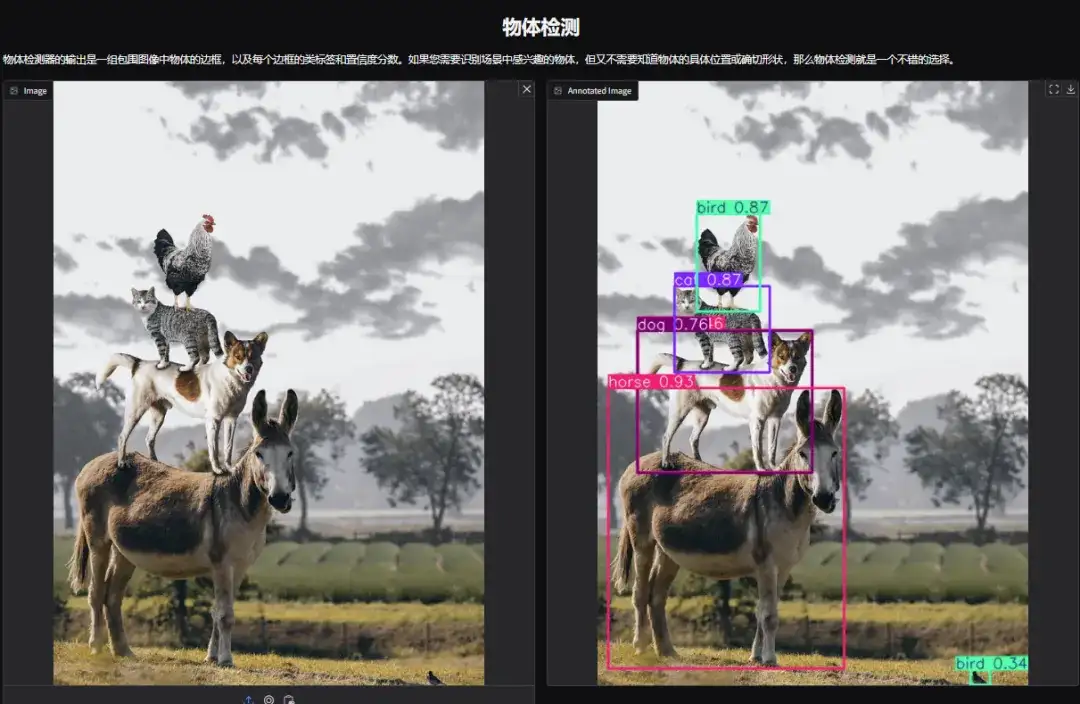
1. YOLOv11 객체 감지 데모 페이지를 엽니다. 쌓인 동물 사진을 업로드하고 매개변수를 조정한 후 "제출"을 클릭했습니다. YOLOv11이 사진 속 모든 동물을 정확하게 감지한 것을 볼 수 있습니다. 오른쪽 하단 모서리에 작은 새가 숨겨져 있는 것이 밝혀졌습니다! 알아차리셨나요?
다음 매개변수는 다음을 나타냅니다.
* 모델:사용을 위해 선택된 YOLO 모델 버전을 나타냅니다.
* 이미지 크기:입력 이미지의 크기. 모델은 감지하는 동안 이미지 크기를 이 크기로 조정합니다.
* 신뢰 임계값:신뢰 임계값은 모델이 타겟 탐지를 수행할 때 이 설정 값을 초과하는 신뢰도를 갖는 탐지 결과만 유효한 타겟으로 간주됨을 의미합니다.
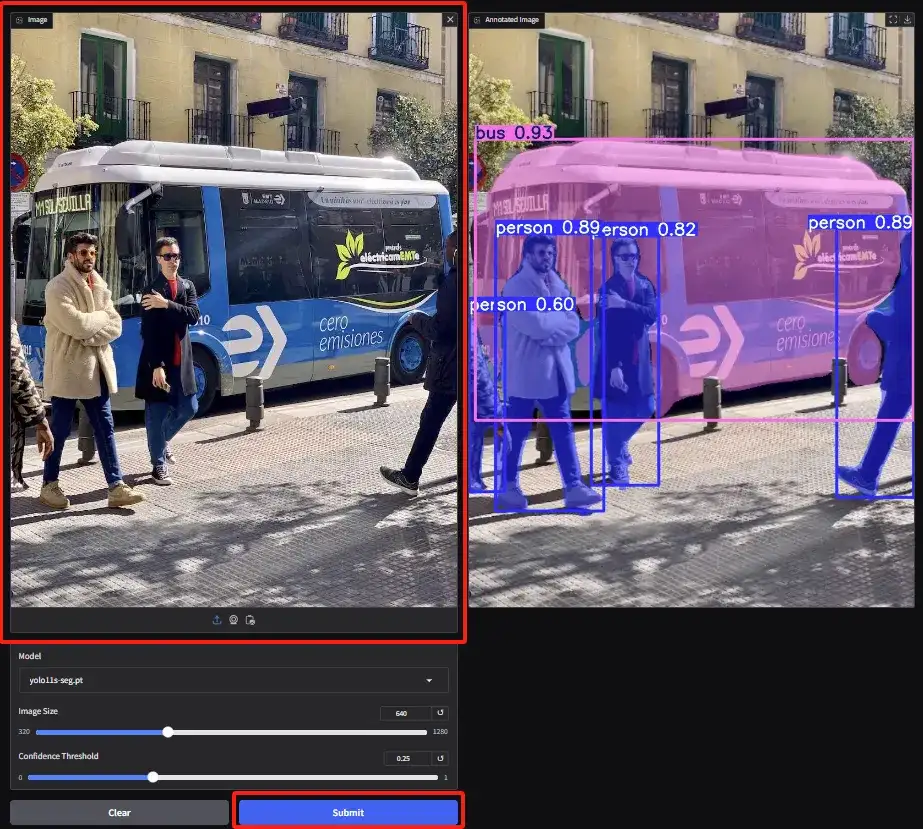
2. 인스턴스 분할 데모 페이지에 접속하여 이미지를 업로드하고 매개변수를 조정한 후, "제출"을 클릭하여 분할 작업을 완료합니다. 폐색이 있더라도 YOLOv11은 사람들을 정확하게 분할하고 버스의 윤곽을 그리는 훌륭한 성과를 보입니다.
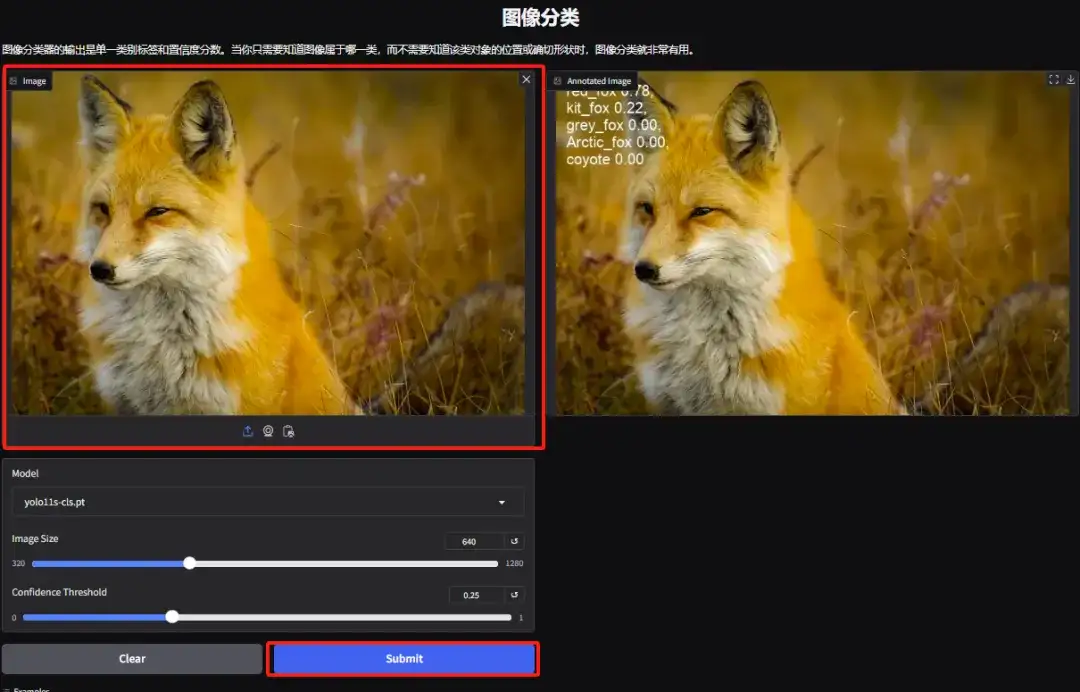
3. 객체 분류 데모 페이지로 들어갑니다. 편집자가 여우 사진을 업로드했습니다. YOLOv11은 사진 속 여우의 특정 종을 붉은 여우로 정확하게 감지할 수 있습니다.
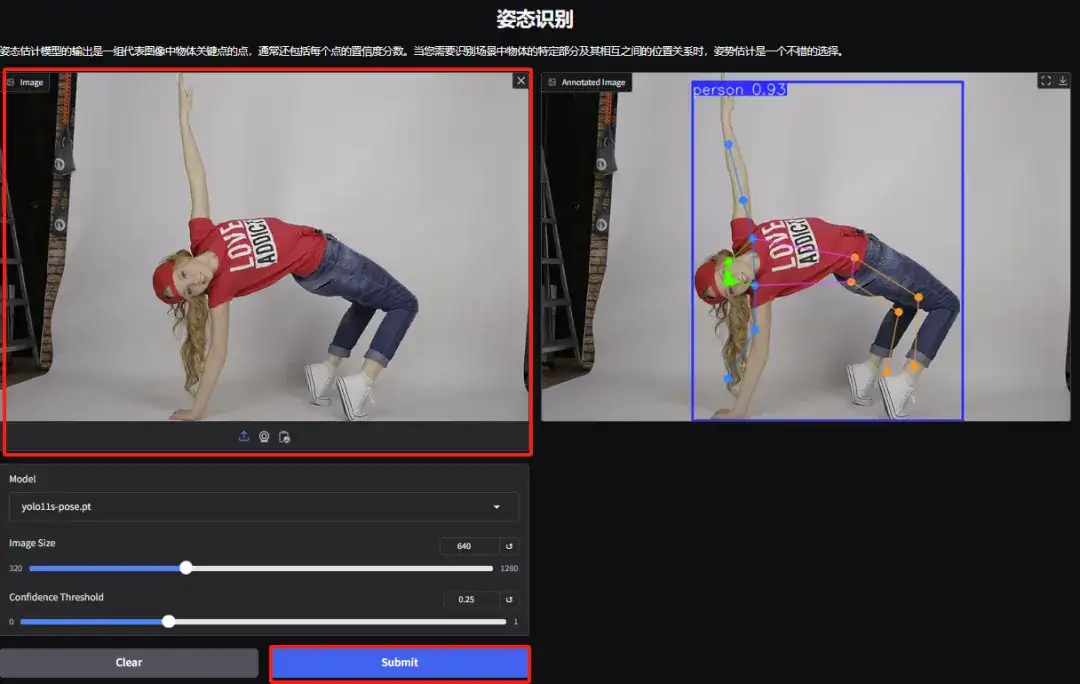
4. 제스처 인식 데모 페이지에 접속하여 사진을 업로드하고, 사진에 따라 매개변수를 조정한 후 "제출"을 클릭하면 제스처 동작 분석이 완료됩니다. 캐릭터의 과장된 신체 움직임을 정확하게 분석한 것을 볼 수 있습니다.
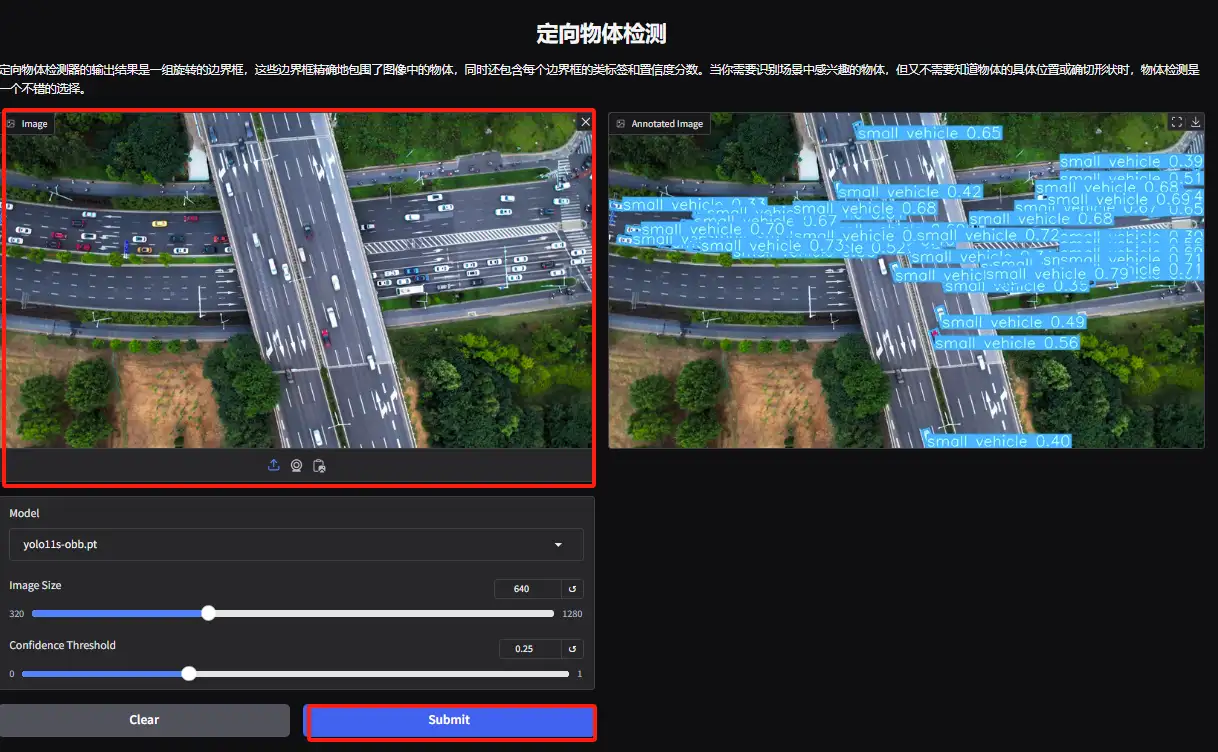
5. Directed Object Detection Demo 페이지에서 이미지를 업로드하고 매개변수를 조정한 다음 "제출"을 클릭하여 객체의 구체적인 위치와 분류를 식별합니다.