Command Palette
Search for a command to run...
소량의 습식 실험 데이터로 단백질 언어 모델을 미세 조정하는 방법은 무엇입니까? 저장대학교팀의 연구 결과가 NeurIPS 2024에 선정되었으며, 논문의 첫 번째 저자는 설계 아이디어를 자세히 설명했습니다.

"AI4S를 만나다" 생방송 시리즈 5회가 12월 10일 오후 7시에 정시에 방송됩니다. HyperAI는 저장대학교 지식엔진 연구실 박사과정생인 왕쩌위안을 초대하게 되어 영광입니다. 이번에 그가 공유하는 주제는 "확산 잡음 제거 프로세스를 사용하여 대형 모델이 단백질을 최적화하는 데 도움이 되는 방법"입니다.
저장대학의 천화쥔 교수, 장창 연구원, 왕쩌위안 박사 등은 새로운 잡음 제거 단백질 언어 모델(DePLM)을 제안했습니다.단백질 언어 모델이 포착한 진화적 정보는 표적 속성과 관련성이 있는 정보와 관련성이 없는 정보가 혼합된 것으로 볼 수 있으며, 관련성이 없는 정보는 "노이즈"로 간주되어 제거되므로 단백질 적응 환경을 예측하고 단백질 최적화에 도움이 됩니다.
연구에 따르면 DePLM은 단백질 돌연변이의 영향을 예측하는 데 기존 방법보다 성능이 뛰어나고 새로운 단백질에 대한 강력한 일반화 기능을 갖추고 있는 것으로 나타났습니다. 이 업적은 NeurIPS 2024 최고 학회에 선정되었습니다. 이 생방송에서 왕쩌위안 박사는 이 논문의 혁신적인 아이디어를 자세히 설명할 것입니다.
HyperAI는 모든 사람을 위해 특별히 준비한 초고가 컴퓨팅 성능 혜택도 제공합니다.생방송 추첨에 참여하면 40위안 상당의 NVIDIA RTX A6000 10시간권을 얻을 기회가 주어지며, 해당 리소스는 1개월 동안 유효합니다.와서 생방송을 시청하기 위한 약속을 잡으세요!
라이브 방송을 예약하려면 클릭하세요:
QR 코드를 스캔하고 "AI4S"라고 댓글을 남겨 토론 그룹에 참여하세요⬇️

게스트 소개

주제를 공유하세요
확산 잡음 제거를 사용하여 대형 모델의 단백질 최적화 지원
소개
우리 연구 그룹은 대규모 모델과 확산 잡음 제거 모델을 결합하는 방법을 제안했습니다. 소량의 습식 실험 데이터로 미세 조정을 통해 단백질 적응형 지형 예측 작업에서 대규모 모델의 정확도가 향상되는 동시에 모델 자체의 우수한 일반화 능력도 유지됩니다.
청중에게 주는 혜택
1. 단백질 적합도 전망 예측을 위한 방법, 데이터 세트 및 지표 이해
2. 적응형 경관 예측에 확산 모델 강화 언어 모델(DePLM)을 사용하는 방법을 이해합니다.
3. AI 모델 학습을 위해 진화 정보, 습식 실험 및 기타 데이터를 결합하는 방법 탐색
논문 리뷰
HyperAI는 이전에 왕 쩌위안 박사를 첫 번째 저자로 하는 연구 논문 "DePLM: 속성 최적화를 위한 단백질 언어 모델 잡음 제거"를 해석한 바 있습니다.
연구 하이라이트
* DePLM은 PLM에 포함된 진화 정보를 최적화하여 타겟 속성과 관련 없는 정보를 효과적으로 필터링하고 단백질 최적화를 개선할 수 있습니다.
* DePLM은 돌연변이 효과를 예측하는 데 있어 최신 모델보다 성능이 뛰어날 뿐만 아니라 새로운 단백질에 대한 강력한 일반화 기능도 보여줍니다.
* 본 연구는 잡음 제거 확산 프레임워크에서 정렬 기반 순방향 프로세스를 설계하여 확산 프로세스를 돌연변이 가능성의 정렬 공간으로 확장하고, 학습 목표를 수치적 오류 최소화에서 정렬 관련성 최대화로 변경하여 데이터세트 독립 학습을 촉진하고 모델의 강력한 일반화 기능을 보장합니다.
데이터셋 수집
이 연구에서는 ProteinGym 단백질 돌연변이 데이터 세트를 선택하고, 지나치게 긴 야생형 단백질 데이터 세트를 제외한 후 최종적으로 201개의 심층 돌연변이 스크리닝(DMS) 데이터 세트를 유지했습니다.
데이터 세트는 직접 사용됩니다.
https://hyper.ai/datasets/32818
모델 아키텍처
아래 왼쪽 그림에서 볼 수 있듯이 DePLM은 PLM에서 파생된 진화 가능성을 입력으로 사용하고 특정 속성에 대한 잡음이 제거된 가능성을 생성하여 돌연변이의 영향을 예측합니다. 아래 그림의 중앙과 오른쪽 부분에서, 노이즈 제거 모듈은 피처 인코더를 사용하여 단백질의 표현을 생성하고, 1차 및 3차 구조를 고려한 다음, 이를 사용하여 노이즈 제거 모듈을 통해 우도의 노이즈를 필터링합니다.
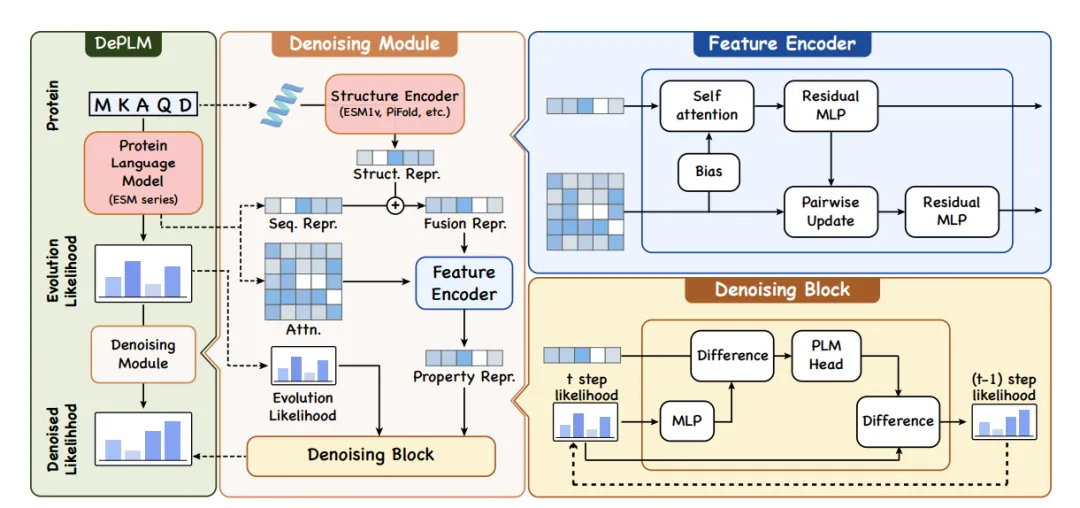
데이터 집합에 독립적인 학습을 달성하고 강력한 모델 일반화 능력을 보장하기 위해 연구진은 특성 값의 순위 공간에서 확산 과정을 수행하고 수치적 오류를 최소화하는 기존 목표를 순위 관련성을 최대화하는 목표로 대체했습니다.
저장대학교 지식엔진 연구실
지식엔진 연구실은 저장대학 컴퓨터과학기술학원, 소프트웨어학원 등을 기반으로 운영됩니다.우리는 지식 그래프, 대규모 언어 모델, 과학을 위한 AI 분야에서 학술 연구, 오픈 소스, 산업 혁신 및 응용 분야에 전념하고 있습니다. 공동 프로젝트에는 저장대학교-앤트그룹 지식 그래프 공동 연구 개발 센터, 저장대학교-알리바바 지식 엔진 공동 실험실 등이 포함됩니다.
이 팀은 뛰어난 박사후 연구원, 100세 노인, R&D 엔지니어 및 기타 정규직 연구원을 모집하고 있습니다. 모두 환영합니다~
연구실 Github 홈페이지:
AI4S 라이브 시리즈를 만나보세요
HyperAI(hyper.ai)는 데이터 과학 분야에서 중국 최대의 검색 엔진입니다. AI for Science의 최신 과학 연구 결과에 초점을 맞추고 Nature, Science 등 최고 저널에 실린 학술 논문을 실시간으로 추적합니다. 지금까지 약 200편의 AI for Science 논문에 대한 해석이 완료되었습니다.
또한, 우리는 중국 유일의 AI for Science 오픈소스 프로젝트인 awesome-ai4s도 운영하고 있습니다.
* 프로젝트 주소:
https://github.com/hyperai/awesome-ai4s
AI4S의 대중화를 더욱 촉진하고, 학술 기관의 과학 연구 결과의 보급 장벽을 더욱 낮추고, 이를 더 광범위한 산업 학자, 기술 애호가 및 산업 단위와 공유하기 위해 HyperAI는 "AI4S를 만나보세요" 영상 칼럼을 기획하여 AI for Science 분야에 깊이 관여하는 연구자 또는 관련 단위를 초대하여 영상 형식으로 연구 결과와 방법을 공유하고, 과학 연구 진행 및 홍보 및 구현 과정에서 AI for Science가 직면한 기회와 과제를 함께 논의하여 AI for Science의 대중화와 보급을 촉진합니다.
지금까지 우리는 지리정보과학, 생명과학, 단백질공학 분야를 아우르는 4회의 Meet AI4S 라이브 방송을 성공적으로 진행했습니다.
효율적인 연구 그룹과 연구 기관의 참여를 환영합니다!QR 코드를 스캔하여 "Neural Star" WeChat에 추가하면 자세한 내용을 확인할 수 있습니다↓
