Command Palette
Search for a command to run...
컴퓨터 비전부터 의료 AI까지, 상하이 교통대학의 셰 웨이디는 다수의 연구 결과를 발표했으며, 이 연구 결과는 Nature 하위 저널/NeurIPS/CVPR 등에 게재되었습니다.

최근 몇 년 동안 과학을 위한 AI의 개발이 가속화되어 과학 연구 분야에 혁신적인 연구 아이디어가 생겨났을 뿐만 아니라 AI의 구현 채널이 확대되고 더욱 어려운 응용 시나리오가 제공되었습니다. 이러한 과정에서 점점 더 많은 AI 연구자들이 의학, 소재, 생물학과 같은 전통적인 과학 연구 분야에 집중하여 연구의 어려움과 산업적 과제를 탐구하기 시작했습니다.
상하이 교통대학교의 종신 교수인 셰 웨이디는 컴퓨터 비전 분야에 깊이 관여해 왔습니다. 그는 2022년 중국으로 돌아와 의료 인공지능 연구에 전념했습니다.HyperAI가 공동 주최한 COSCon'24 AI for Science 포럼에서 Xie Weidi 교수는 "헬스케어를 위한 일반주의 모델 개발을 향하여"라는 제목으로 오픈 소스 데이터 세트 구축 및 모델 개발을 포함한 다양한 관점에서 팀의 성과를 공유했습니다.

HyperAI는 원래 의도를 훼손하지 않으면서 심도 있는 공유를 구성하고 요약했습니다. 다음은 연설의 주요 내용을 요약한 것입니다.
의료 인공지능은 피할 수 없는 추세다
의학 연구는 모든 사람의 생명과 건강에 영향을 미치므로 매우 중요합니다. 동시에 의료자원의 불평등한 분배 문제는 오랫동안 근본적으로 해결되지 않았습니다.그래서 우리는 보편적 의료를 촉진하고 모든 사람이 고품질의 진단과 치료를 받을 수 있도록 돕고 싶습니다.
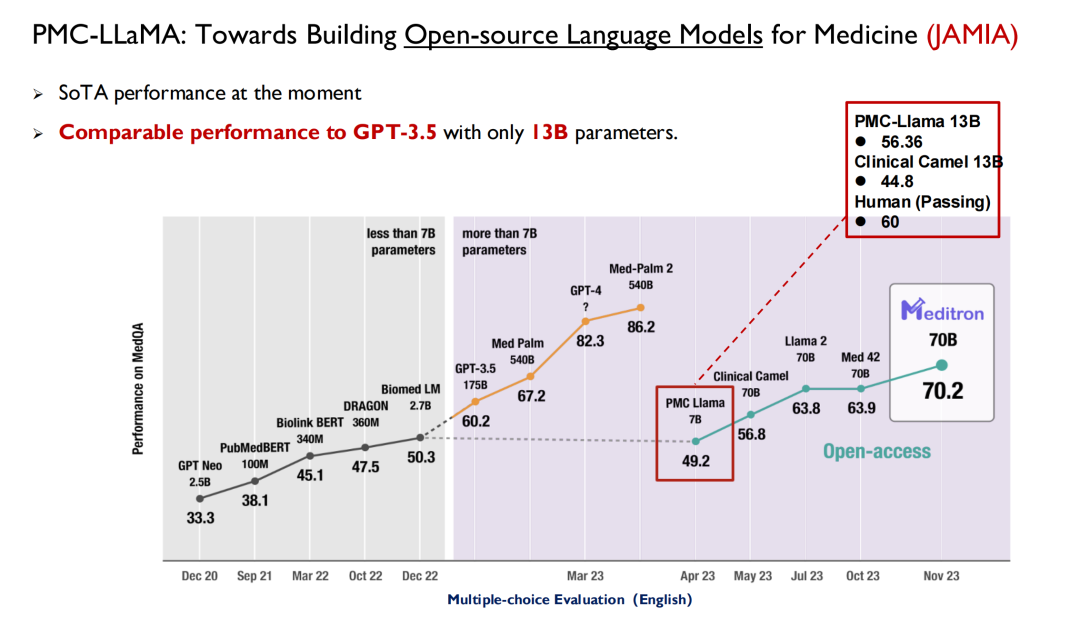
최근 몇 년 동안 출시된 ChatGPT와 다른 대형 모델은 모두 성능 테스트를 위한 주요 전장으로 의료를 사용했습니다. 아래 그림에서 보듯이, 미국 의사면허시험의 경우 2022년 이전까지 대형 모델은 50점 정도를 받을 수 있는 반면, 인간은 70점 정도만 받을 수 있어 AI는 의사들의 큰 관심을 끌지 못했습니다.
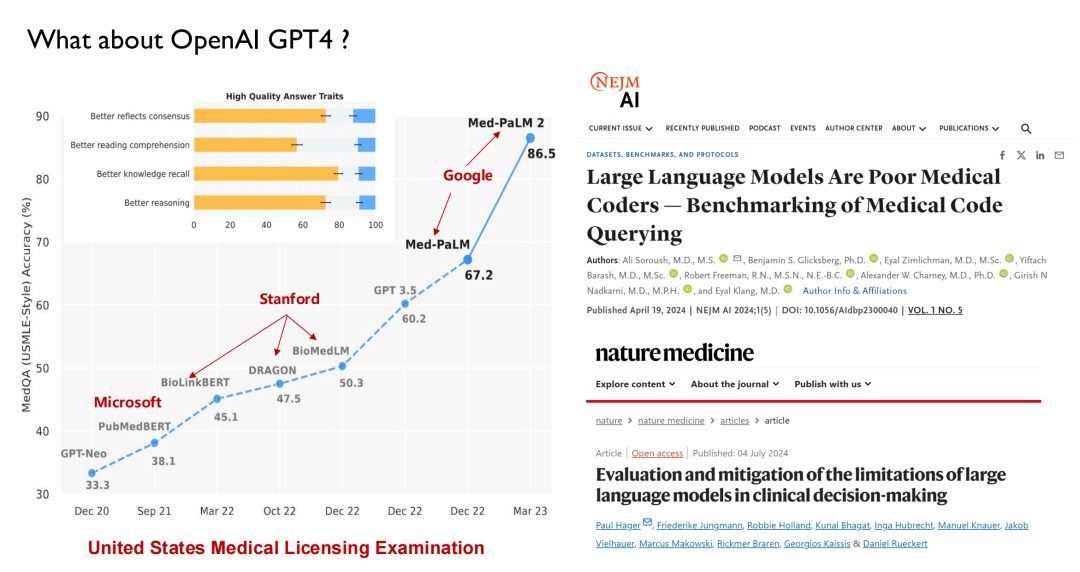
GPT 3.5가 출시되면서 점수가 60.2로 크게 개선되었습니다. 이후 구글은 Med-PaLM과 업데이트된 버전을 출시했는데, 최고 점수는 86.5에 달했습니다. 오늘날의 GPT-4는 90점까지 도달할 수 있습니다. 이처럼 높은 성능과 반복 속도 덕분에 의사들은 AI에 주목하기 시작했습니다.많은 의과대학에서는 이제 지능형 의학이라는 새로운 분야를 제공합니다.
마찬가지로, 의대생들만 인공지능에 대해 배워야 하는 것은 아닙니다.AI 전공 학생은 최종 학년에 의학 지식도 배울 수 있습니다.하버드 대학을 비롯한 여러 기관에서는 이미 AI 전공을 위한 관련 과정을 개설했습니다.
그러나 반면에 Nature Medicine과 같은 학술지에 실린 연구들은실제로 대규모 언어 모델은 의학을 이해하지 못합니다.예를 들어, 현재의 대형 모델은 ICD 코드(국제질병분류체계의 진단코드)를 이해하지 못하고, 의사처럼 환자의 검진 결과에 따른 적절한 의료지침을 제공하는 데 어려움을 겪습니다. 대형 모델은 의료 분야에서 여전히 많은 한계를 가지고 있음을 알 수 있습니다.저는 이것이 결코 의사를 대체할 수는 없다고 생각합니다. 저희 팀은 이 모델이 의사에게 더 나은 도움을 줄 수 있도록 만들고 싶습니다.
팀의 주요 목표: 일반 의료 인공지능 시스템 구축
저는 2022년에 중국으로 돌아와 의료 인공지능 연구를 시작했습니다. 그래서 오늘 제가 공유할 내용은 주로 지난 2년간 팀의 연구 성과입니다. 의료 산업은 광범위한 분야를 포괄하고 있기 때문에 우리가 개발한 모델이 보편적이라고는 할 수 없지만 가능한 한 많은 중요한 업무를 포괄할 수 있기를 바랍니다.
아래 그림과 같이,입력 측면에서는 다양한 모드를 지원하고자 합니다.예를 들어, 이미지, 오디오, 환자 건강 기록 등이 다중 모달 일반 의학 모델에 입력되면 의사는 이와 상호 작용할 수 있습니다.모델의 출력은 적어도 두 가지 형태를 갖습니다. 하나는 시각적이고,병변의 위치는 분할 및 감지를 통해 발견됩니다.두 번째는 텍스트(Text)입니다.진단 결과(Diagnosis) 또는 보고서(Report)를 출력합니다.
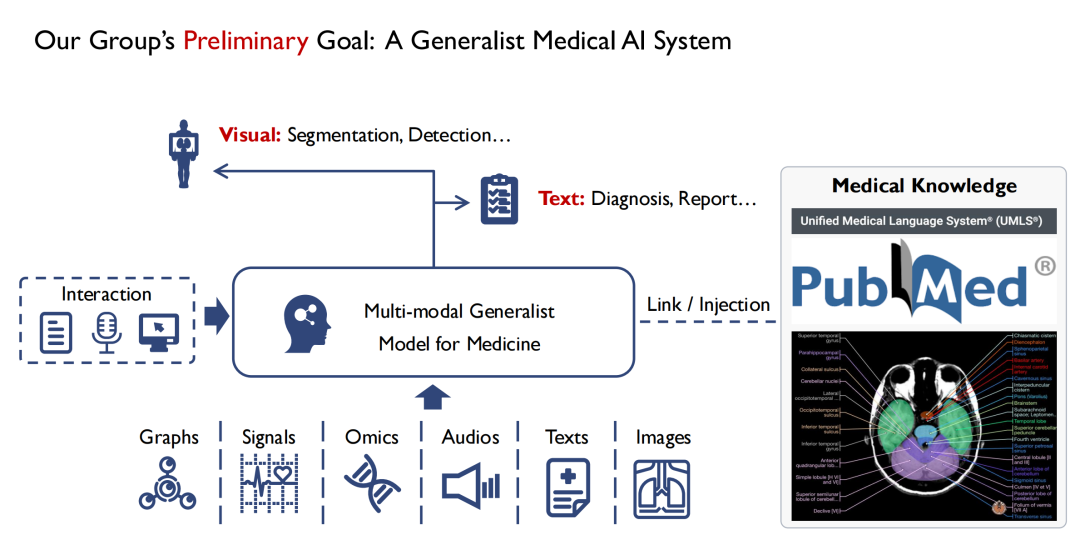
저는 컴퓨터 비전 전공이에요. 제가 관찰한 바에 따르면, 시각과 의학의 가장 큰 차이점은 의학, 특히 증거 기반 의학의 대부분 지식이 인간의 경험에서 요약된다는 점입니다. 초보자가 의학 서적을 모두 읽게 되면, 적어도 이론에 있어서는 의학 전문가가 될 수 있다. 그러므로,모델 훈련 과정에서 우리는 모든 의학적 지식을 모델에 주입하고자 합니다.모델에 기본적인 의학 지식이 부족하다면 의사와 환자의 신뢰를 얻기 어려울 것입니다.
그래서 요약하자면,저희 팀의 주요 목표는 다중 모달 보편적 의료 모델을 구축하고 가능한 한 많은 의학 지식을 여기에 주입하는 것입니다.
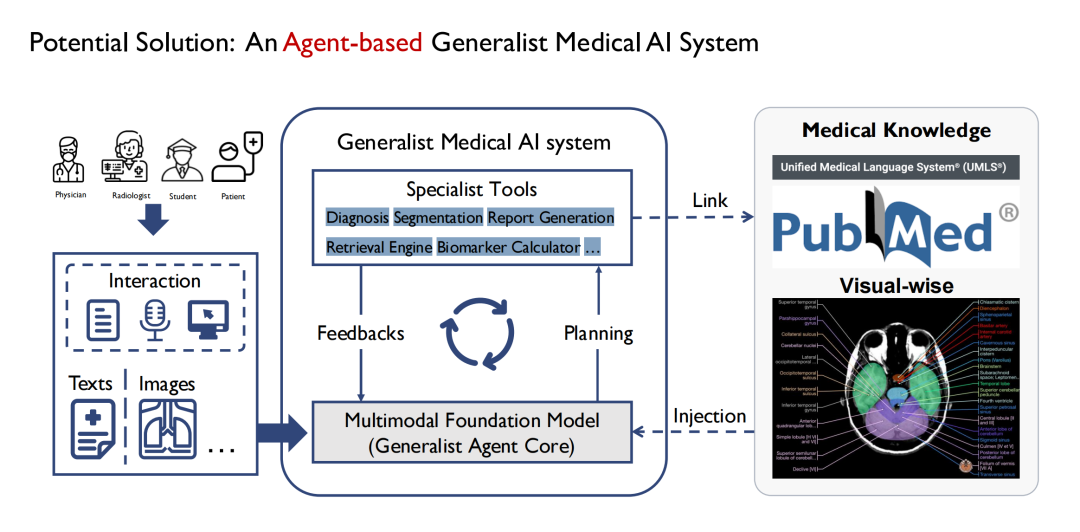
처음에는 일반적인 모델을 정의하는 것으로 시작했지만 점차 GPT-4만큼 전능한 의료 모델을 구축하는 것은 현실적으로 불가능하다는 것을 깨달았습니다. 병원에는 많은 부서가 있고 각 부서의 업무가 다르기 때문에 일반적인 모델로 모든 업무를 포괄하기 어렵습니다.그래서 우리는 Agent를 통해 이를 구현하기로 했습니다.아래 그림과 같이 가운데 있는 일반 모델은 여러 개의 하위 모델로 구성되며, 각 하위 모델은 본질적으로 Agent이며, 일반 모델은 최종적으로 Multi Agent 형태로 구성됩니다.
이 모델의 장점은 다양한 에이전트가 다양한 입력을 수용할 수 있기 때문에 모델의 입력 측면을 더 복잡하고 다양화할 수 있다는 것입니다. 여러 에이전트가 단계별로 다른 작업을 처리하는 과정에서 사고의 사슬을 형성할 수도 있습니다. 출력단도 더 풍부합니다. 예를 들어, 하나의 에이전트가 CT, MRI 등 다양한 유형의 의료 이미지 분할을 완료할 수 있습니다. 동시에 확장성도 더 뛰어납니다.
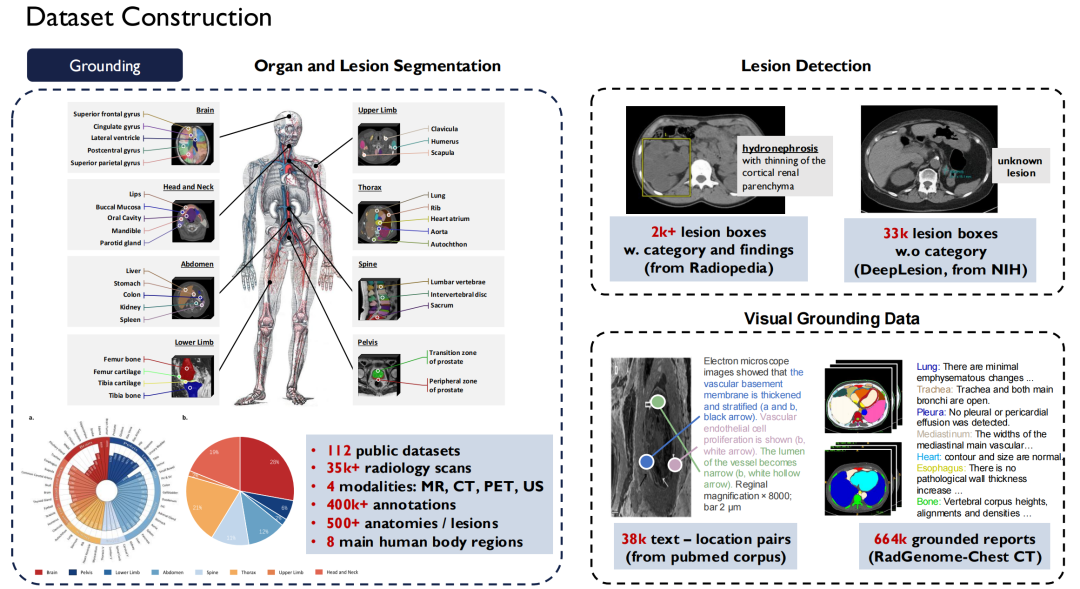
고품질 오픈 소스 데이터 세트 기여
다중모달 보편적 의료 모델을 구축한다는 큰 목표에 초점을 맞춰, 오픈 소스 데이터 세트, 대규모 언어 모델, 질병 진단 에이전트 등 다양한 측면에서 팀이 이룬 성과를 소개하겠습니다.
첫 번째는 오픈 소스 데이터 세트에 대한 우리의 기여입니다.
의료 분야에는 데이터 세트가 부족하지 않지만, 개인 정보 보호 문제로 인해 공개적으로 사용 가능한 고품질 데이터는 상대적으로 부족합니다. 학계 팀으로서 우리는 업계에 더 많은 고품질 오픈소스 데이터를 기여하고자 합니다.그래서 중국으로 돌아온 후, 저는 대규모 의료 데이터 세트를 구축하기 시작했습니다.
텍스트 측면에서 우리는 40억 개의 토큰을 포함하는 30,000권 이상의 의학 서적을 수집했습니다. 480만 건의 논문과 750억 개의 토큰을 포함하여 PubMed Central(PMC)에 있는 모든 의학 문헌을 크롤링했습니다. 그리고 인터넷에서 중국어, 영어, 러시아어, 일본어 등 8개 언어로 된 의학 서적을 수집하여 텍스트로 변환했습니다.
또한,우리는 또한 의료 분야에서 슈퍼 인스트럭션을 구축했습니다.업무의 다양성을 고려하면 1,350만 개의 샘플이 관련된 124개의 의료 업무가 나열되어 있습니다.

텍스트 데이터는 얻기 쉽지만, 시각-언어(이미지-텍스트 쌍)는 얻기가 더 어렵습니다. 우리는 Radiopaedia 웹사이트에서 약 20만 건의 사례를 크롤링하고, 논문에서 이미지와 캡션을 수집했으며, 기본 방사선 보고서에서 3만 권이 넘는 책을 수집했습니다.
현재 대부분의 데이터는 오픈 소스입니다.
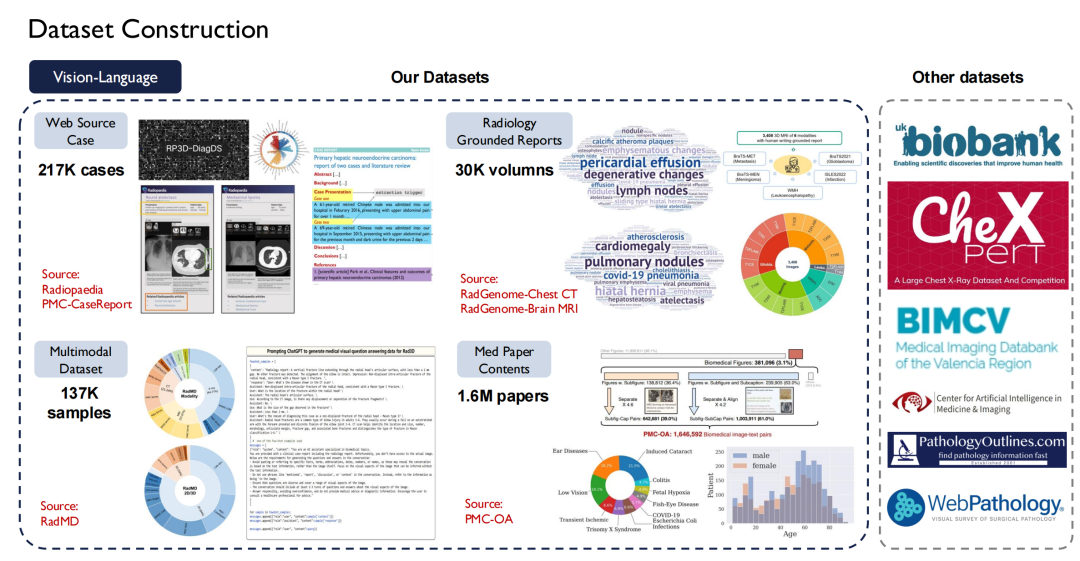
위 그림의 오른쪽은 영국 바이오뱅크와 같은 다른 공개 데이터 세트를 보여줍니다. 우리는 이를 위해 10년 동안 영국 내 약 10만 명의 환자에 대한 데이터를 구매하기 위해 비용을 지불했습니다. 또한, Pathology Outlines에서는 포괄적인 병리학 지식을 제공합니다.
접지 데이터 측면에서이게 제가 방금 언급한 세분화 및 감지 데이터입니다.우리는 시중에 나와 있는 약 120개의 방사선 영상 공개 데이터 세트를 하나의 표준으로 통합하여 35,000개 이상의 2D/3D 방사선 스캔 영상을 만들었습니다.이 데이터는 MR, CT, PET, US의 4가지 검사 방식을 다루며, 40만 개의 세부 주석이 포함되어 있고, 이 데이터는 신체의 500개 장기를 다룹니다.동시에 우리는 병변에 대한 설명을 확장하고 이 모든 데이터 세트를 오픈 소스로 공개했습니다.
전문적인 의료 모델을 만들기 위한 지속적인 반복
언어 모델
오직 고품질 오픈 소스 데이터 세트만이 학생과 연구자들이 더 나은 모델 학습을 수행하는 데 도움이 될 수 있습니다. 다음으로, 이 모델에 대한 팀의 성과를 소개하겠습니다.
첫 번째는 언어 모델로, 인간의 지식을 모델에 빠르게 주입하는 방법입니다. 지난 4월, 저희는 PMC-LLaMA라는 모델을 출시했고, 관련 연구는 "의학을 위한 오픈 소스 언어 모델 구축을 향하여"라는 제목으로 JAMIA에 게재되었습니다.
서류 주소:
https://academic.oup.com/jamia/article/31/9/1833/7645318
이것은 우리가 의료 분야에서 개발한 최초의 오픈 소스 대규모 언어 모델입니다. 우리는 위에서 언급한 모든 의료 데이터와 논문 데이터를 모델에 학습시키고, 자기회귀 학습을 수행한 다음, 데이터를 질문-답변 쌍으로 변환하기 위한 지침을 미세 조정했습니다.
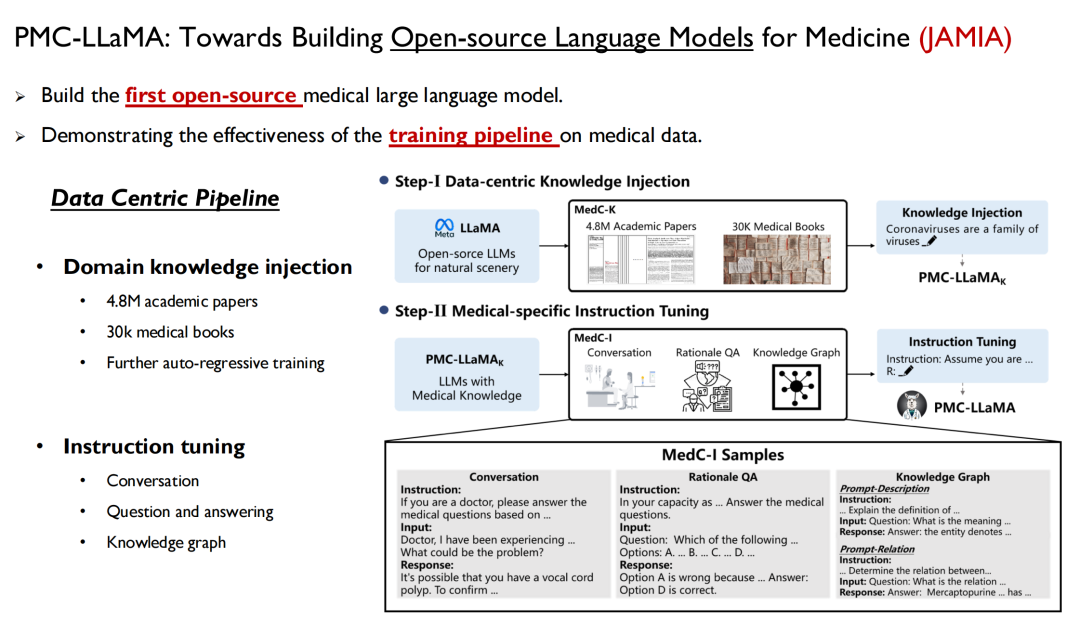
예일대학교 연구자들은 논문에서 다음과 같이 언급했습니다. PMC-LLaMA는 이 분야에서 가장 오래된 오픈소스 의료 모델입니다.많은 연구자들이 이후 이를 기준으로 활용했지만, 제 생각에는 PMC-LLaMA와 폐쇄형 소스 모델 사이에는 여전히 간극이 있으므로 앞으로도 이 모델을 계속 반복하고 업그레이드할 것입니다.
이후, 우리는 Nature Communications에 "의학을 위한 다국어 언어 모델 구축을 향하여"라는 제목의 또 다른 논문을 발표했습니다.영어, 중국어, 일본어, 프랑스어, 러시아어, 스페인어 등 6개 언어를 지원하는 다국어 의료 모델이 출시되었으며, 250억 개의 의료 관련 토큰으로 훈련되었습니다. 통일된 다국어 표준 테스트 세트가 없기 때문에 모든 사람이 테스트할 수 있는 관련 벤치마크도 구축했습니다.
실제로, 기본 모델이 업그레이드되고 의학 지식이 주입되면 결과적으로 대규모 의료 모델의 성능도 향상되는 것을 발견했습니다.
위에 언급된 대부분의 업무는 "객관식 문제"이지만, 의사가 실제 업무에서는 객관식 문제에만 답하는 것은 불가능하다는 것을 우리 모두 알고 있습니다. 따라서 대규모 언어 모델이 자유 텍스트 형태로 의사의 업무 흐름에 내장되기를 바랍니다. 이를 고려하여,새로운 연구에서는 임상 업무에 더 집중하고, 관련 데이터 세트를 수집하며, 모델의 임상적 확장성을 개선할 것입니다.
관련 논문은 아직 검토 중입니다.
시각 언어 모델
마찬가지로, 우리는 의학 분야에서 시각 언어 모델에 대한 연구를 수행한 최초의 팀 중 하나였습니다. 위에 언급된 데이터를 기반으로,우리는 3개의 오픈 소스 데이터 세트를 구축했습니다.
* PubMed Central에서 160만 개의 대규모 이미지-캡션 쌍을 수집하여 PMC-OA 데이터 세트를 구축했습니다.
* PMC-OA에서 227,000개의 의료 시각적 질문-답변 쌍을 생성하여 PMC-VQA를 형성했습니다.
* Radiopaedia 종에서 53,000개의 사례와 48,000개의 다중 이미지-캡션 쌍을 수집하여 Rad3D 데이터 세트를 구축했습니다.
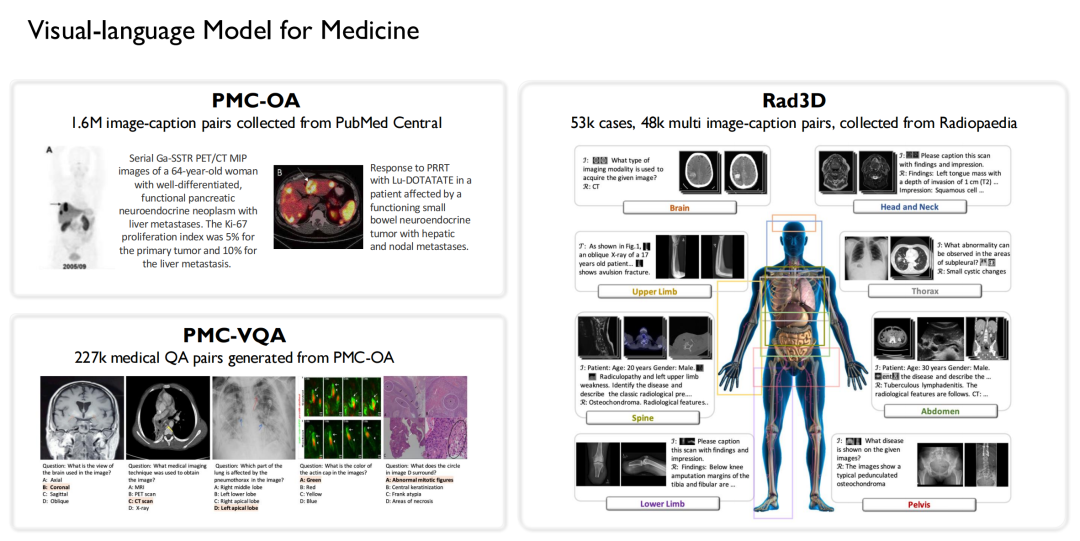
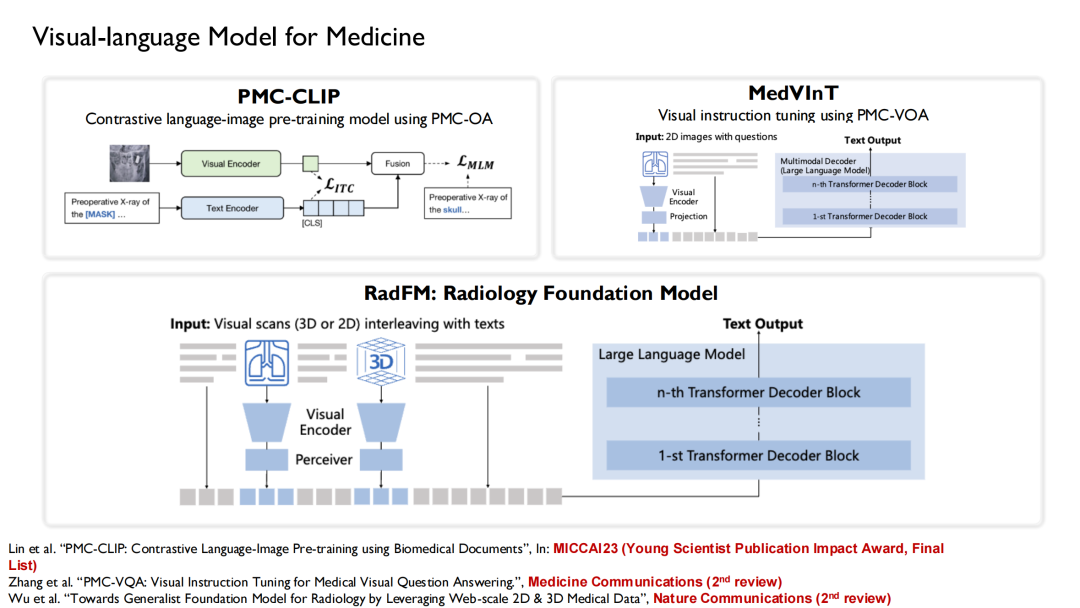
이러한 데이터 세트를 기반으로 훈련된 언어 모델을 결합했습니다.PMC-CLIP, MedVInT, RadFM의 세 가지 버전의 시각 언어 모델이 훈련되었습니다.
PMC-CLIP은 의료 인공지능 영상 분야 최고 학회인 MICCAI 2023에서 발표한 결과입니다.마침내 그는 "젊은 과학자 출판 영향력상 최종 후보"로 선정되었습니다.이 상은 지난 5년 동안 발표된 논문 중 3~7편의 수상 논문에 수여됩니다.
RadFM(Radiology Foundation Model)은 현재 매우 대중적이며, 많은 연구자들이 이를 기준으로 사용합니다. 훈련 과정 동안,우리는 텍스트와 이미지를 섞어서 모델에 입력했는데, 이 모델은 질문에 대한 답변을 바로 생성할 수 있습니다.
도메인별 지식을 강화하고 모델 성능을 개선합니다.
소위 지식 강화 표현 학습(Knowledge-enhanced Representation Learning)은 의학적 지식을 모델에 주입하는 방법에 대한 문제를 해결해야 합니다. 우리는 또한 이 과제에 관해 일련의 연구를 수행했습니다.
우선, 우리는 '지식'이 어디서 오는가 하는 문제를 해결해야 합니다.한편으로는 일반 의학 지식입니다.의학 분야 최대의 지식 그래프인 UMLS에서 판매하는 관련 논문과 서적, 그리고 인터넷에서 발췌한 자료입니다.반면에 특정 분야에 국한된 지식도 있습니다.예를 들어, 사례 보고서, 방사선 영상, 초음파 등. 해부학적 지식뿐만 아니라 이러한 모든 정보는 일부 웹사이트에서 얻을 수 있습니다. 물론, 여기서는 저작권 문제에 특별히 주의해야 합니다. 일부 웹사이트의 콘텐츠를 사용할 수 없기 때문입니다.

이러한 "지식"을 얻은 후, 지식 그래프를 그릴 수 있습니다.이는 질병과 질병, 약물과 약물, 단백질과 단백질 간의 관계를 확립하고 자세한 설명을 제공합니다.
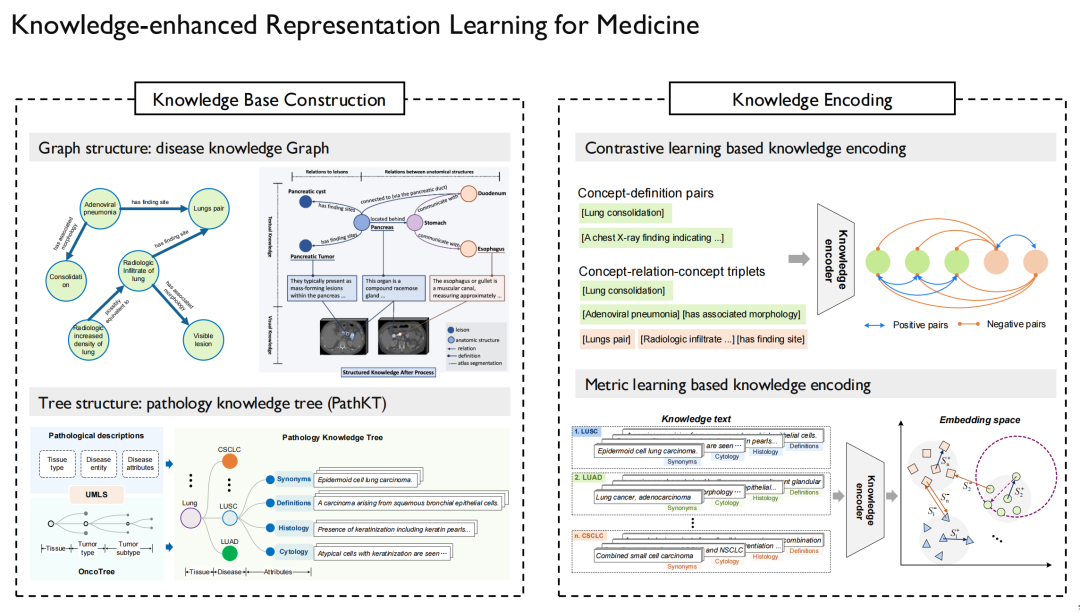
위 그림의 왼쪽은 우리가 만든 병리학 지식 그래프와 지식 트리입니다.주로 암 진단에 사용됩니다. 암은 인체의 다양한 기관에서 발생할 수 있으며 여러 하위 유형으로 나뉘는데, 이를 트리 구조 형태로 만드는 데 적합합니다. 마찬가지로 다중모달 병리학 외에도 다중모달 방사선학과 다중모달 엑스선학을 중심으로 한 관련 연구도 수행했습니다.
다음 단계는 이러한 지식을 언어 모델에 주입하여 모델이 그래프와 그래프의 점 사이의 관계를 기억할 수 있도록 하는 것입니다.언어 모델이 훈련되면 시각적 모델을 언어 모델에 맞춰 조정하기만 하면 됩니다.
우리는 우리의 결과를 Microsoft와 Stanford의 결과와 비교했고 그 결과는 다음과 같았습니다.도메인 지식이 추가된 모델은 도메인 지식이 없는 다른 모델보다 훨씬 더 높은 성능을 보입니다.
병리학 분야에서는 저희 논문 "계산 병리학을 위한 지식 강화 시각 언어 사전 학습"이 최고의 머신 러닝 컨퍼런스인 ECCV 2024(구두 발표)에 선정되었습니다. 이 작업에서는 지식 트리를 구축하고 이를 모델 학습에 주입한 다음 비전과 언어를 정렬합니다.
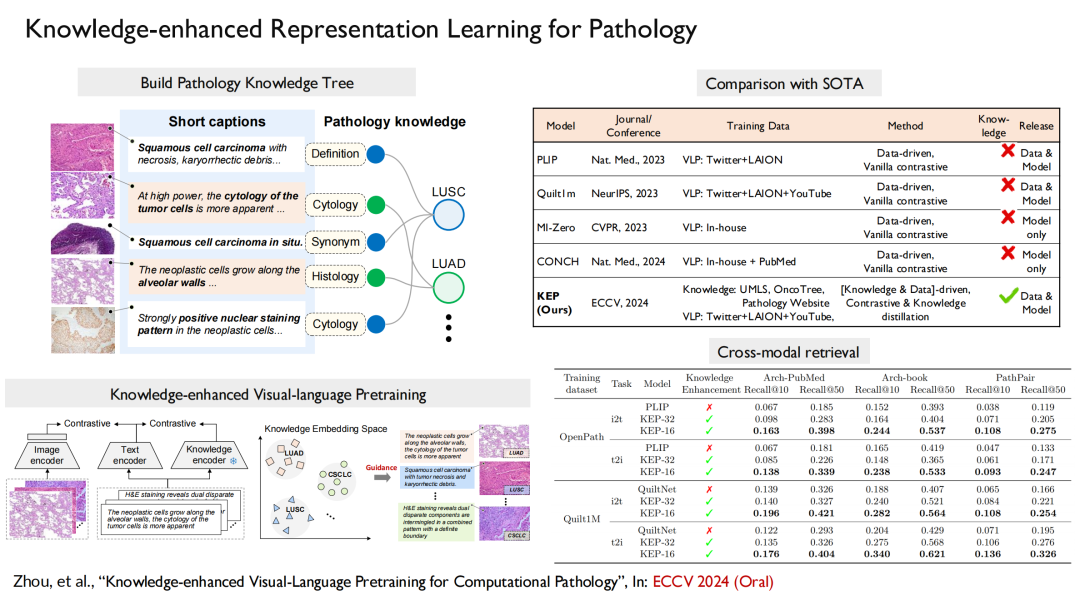
더 나아가, 우리는 동일한 방법을 사용하여 다중 모드 방사선 영상 모델을 구축하였고, 그 결과는 "방사선 영상에서 대규모 긴꼬리 질병 진단"이라는 제목으로 Nature Communications에 게재되었습니다.이 모델은 환자의 방사선 이미지를 기반으로 해당 증상을 직접 출력할 수 있습니다.
요약하자면,저희의 작업은 완전한 프로세스를 구현했습니다. 먼저, 20만 장의 이미지, 41,000장의 환자 이미지, 930가지 질병 등을 포함하는 가장 큰 방사선 이미지 오픈 소스 데이터 세트를 구축했습니다. 두 번째로, 우리는 특정 분야의 지식을 강화하기 위해 다중 모드, 다중 언어 모델을 구축했습니다. 마지막으로, 우리는 해당 벤치마크를 구축했습니다.
Xie Weidi 교수 소개
그는 상하이 교통대학의 종신 교수이며, 국가(해외) 고급 청년 인재 프로그램, 상하이 해외 고급 인재 프로그램, 상하이 모닝스타 프로그램의 수혜자입니다. 그는 또한 과학기술부 과학기술혁신 2030 - "신세대 인공지능" 중점 프로젝트의 청년 프로젝트 리더이며, 중국 국가자연과학기금의 프로젝트 리더이기도 합니다.
그는 박사학위를 받았습니다. 그는 옥스퍼드 대학교 시각 기하학 그룹(VGG)에서 Andrew Zisserman 교수와 Alison Noble 교수의 지도를 받았습니다. 그는 구글-딥마인드 전액 장학금, 중국-옥스퍼드 장학금, 옥스퍼드 대학교 공학부 우수상을 수상한 최초 수상자 중 한 명입니다.
그의 주요 연구 분야는 컴퓨터 비전과 의료 인공지능입니다. 그는 CVPR, ICCV, NeurIPS, ICML, IJCV, Nature Communications 등을 포함하여 60편 이상의 논문을 출판했으며, Google Scholar에서 12,500회 이상 인용되었습니다. 그는 여러 차례 세계 유수의 컨퍼런스와 세미나에서 최우수 논문상, 최우수 포스터상, 최우수 저널 논문상을 수상했으며, MICCAI 젊은 과학자 출판 영향력상 최종 후보에 올랐습니다. 그는 Nature Medicine과 Nature Communications의 특별 리뷰어이며, 컴퓨터 비전과 인공지능 분야의 대표적인 학회인 CVPR, NeurIPS, ECCV의 현장 의장을 맡고 있습니다.
* 개인 홈페이지 :

