18개 임상 작업을 포함하는 284개 데이터 세트를 포함하는 상하이 AI 랩과 다른 연구진은 다중 모드 의료 벤치마크 GMAI-MMBench를 출시했습니다.

"이렇게 스마트한 의료 기기를 사용하면 환자는 기기에 누워 있기만 하면 스캔, 진단, 치료, 수리 등 전체 과정을 완료하고 건강한 재시작을 할 수 있습니다." 이는 2013년 공상과학 영화 "엘리시움"의 줄거리입니다.

요즘은 인공지능 기술이 급속도로 발전하면서 공상과학 영화에서 나오는 의료 장면이 현실이 될 수 있기를 기대합니다. 의료 분야에서 대규모 시각 언어 모델(LVLM)은 DeepSeek-VL, GPT-4V, Claude3-Opus, LLaVA-Med, MedDr, DeepDR-LLM 등과 같이 영상, 텍스트, 심지어 생리적 신호까지 다양한 데이터 유형을 처리할 수 있어 질병 진단 및 치료에 큰 발전 잠재력을 보여줍니다.
그러나 LVLM을 임상에 적용하기 전에 모델의 효과성을 평가하기 위한 벤치마크 테스트를 수립해야 합니다. 그러나 현재의 벤치마크는 일반적으로 특정 학술 문헌을 기반으로 하며 주로 단일 분야에 초점을 맞추고 있어 다양한 인식적 세부 사항이 부족하여 실제 임상 시나리오에서 LVLM의 효과와 성능을 종합적으로 평가하기 어렵습니다.
이에 대응하여 상하이 인공지능 연구소는 워싱턴 대학교, 모나쉬 대학교, 화동사범 대학교 등 여러 과학 연구 기관과 협력하여 GMAI-MMBench 벤치마크를 제안했습니다. GMAI-MMBench는 전 세계 284개의 다운스트림 작업 데이터 세트를 기반으로 구축되었으며, 38개의 의료 영상 모달리티, 18개의 임상 관련 작업, 18개 부서, 시각적 질의응답(VQA) 형식의 4개 지각적 세분성을 포함하고 있으며, 완전한 데이터 구조 분류와 다중 지각적 세분성을 갖추고 있습니다.
"GMAI-MMBench: 일반 의료 AI를 향한 포괄적인 다중 모드 평가 벤치마크"라는 제목의 관련 연구는 NeurIPS 2024 데이터세트 벤치마크에 선정되어 arXiv에 사전 인쇄본으로 게재되었습니다.

서류 주소:
https://arxiv.org/abs/2408.03361v7
"GMAI-MMBench 의료 다중모달 평가 벤치마크 데이터세트"는 이제 HyperAI 공식 웹사이트에서 이용 가능하며, 클릭 한 번으로 다운로드할 수 있습니다!
데이터세트 다운로드 주소:
https://go.hyper.ai/xxy3w
GMAI-MMBench: 현재까지 가장 포괄적이고 오픈 소스인 일반 의료 AI 벤치마크
GMAI-MMBench의 전반적인 구축 과정은 3가지 주요 단계로 나눌 수 있습니다.
먼저, 연구진은 전 세계 공공 데이터 세트와 병원 데이터에서 수백 개의 데이터 세트를 검색했습니다. 선별, 이미지 형식 통합, 레이블 표현 표준화를 거친 후, 고품질 레이블이 있는 284개 데이터 세트를 보관했습니다.
이 284개 데이터 세트는 2D 감지, 2D 분류, 2D/3D 분할 등 다양한 의료 영상 작업을 포괄하며 전문 의사가 주석을 달았기 때문에 의료 영상 작업의 다양성과 높은 임상적 관련성 및 정확성을 보장합니다.
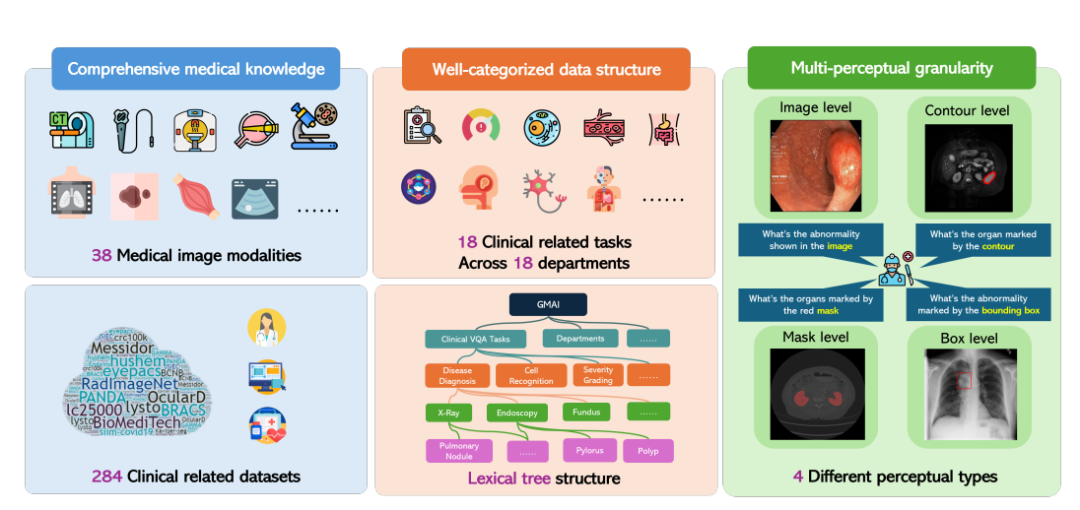
다음으로 연구진은 모든 라벨을 18개의 임상 VQA 작업과 18개의 임상 부서로 분류하여 다양한 측면에서 LVLM의 장단점을 종합적으로 평가할 수 있게 했으며, 이는 특정 요구 사항이 있는 모델 개발자와 사용자에게 편리합니다.
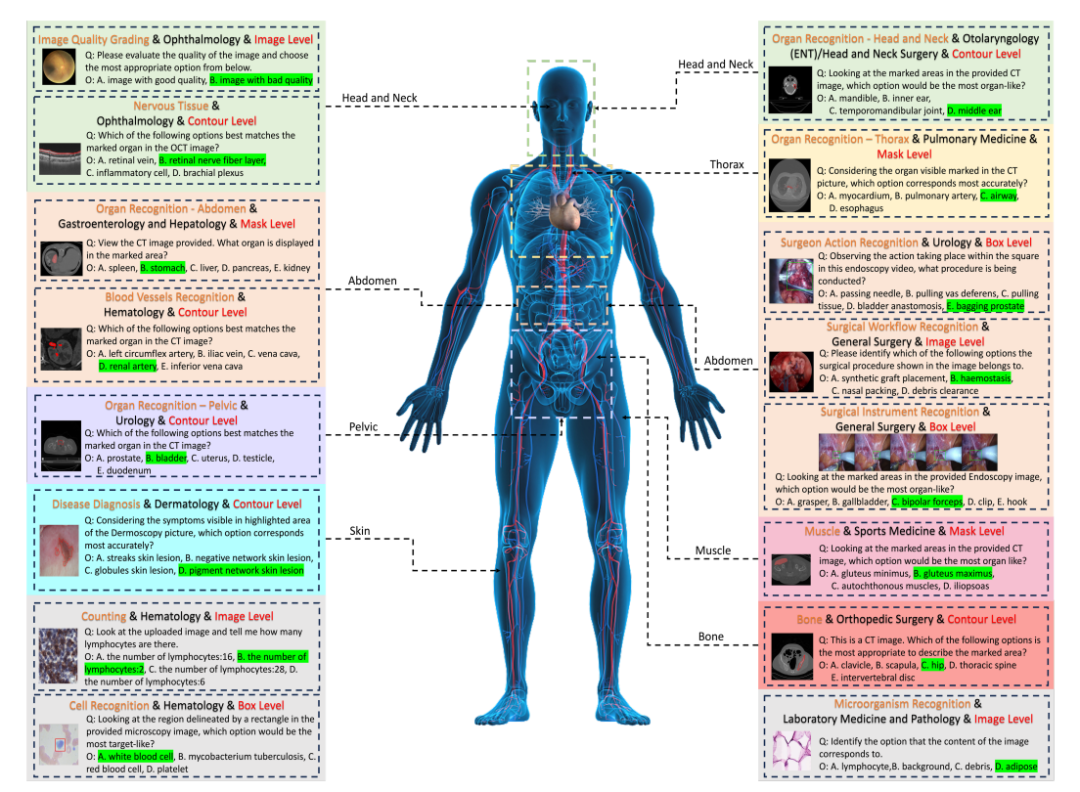
구체적으로 연구진은 모든 사례를 18개의 임상 VQA 작업, 18개의 부서, 38개의 모달리티 등으로 구분하는 어휘 트리 구조라는 분류 시스템을 설계했습니다. "임상 VQA 작업", "부서", "모달리티"는 필요한 평가 사례를 검색하는 데 사용할 수 있는 용어입니다. 예를 들어, 종양학과에서는 종양학 관련 사례를 선택하여 종양학 업무에서 LVLM의 성능을 평가할 수 있으며, 이를 통해 특정 요구 사항에 대한 유연성과 사용 편의성이 크게 향상됩니다.
마지막으로 연구자들은 각 라벨에 해당하는 질문과 옵션 풀을 기반으로 질문-답변 쌍을 생성했습니다.각 질문에는 이미지 모달리티, 작업 프롬프트, 해당 주석 세분성 정보가 포함되어야 합니다. 최종 벤치마크는 추가적인 검증과 수동 검토를 통해 얻어졌습니다.
50개 모델 평가, GMAI-MMBench 벤치마크에서 어떤 모델이 가장 우수한가
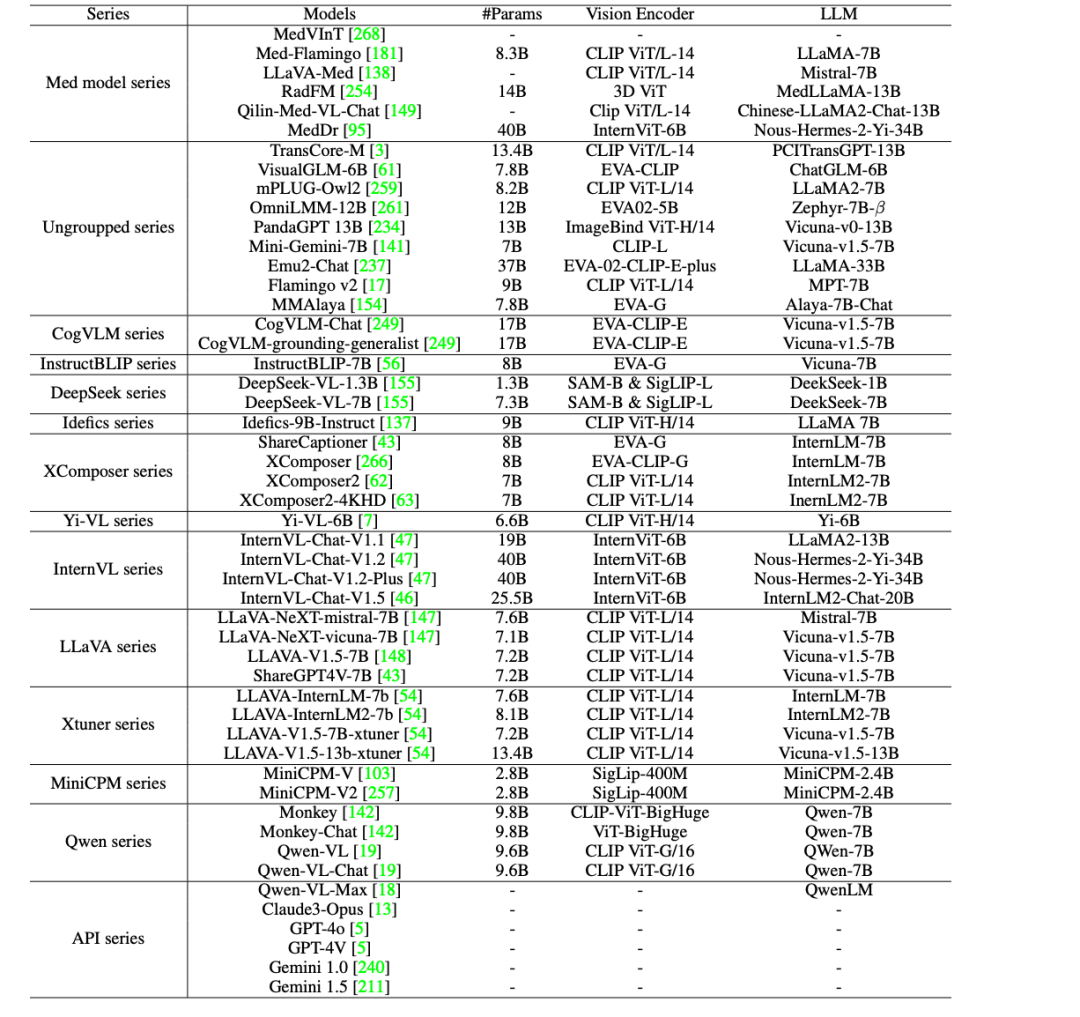
의료 분야에서 AI의 임상적용을 더욱 촉진하기 위해,연구진은 GMAI-MMBench에서 44개의 오픈 소스 LVLM(38개의 일반 모델과 6개의 의료용 특정 모델 포함)과 GPT-4o, GPT-4V, Claude3-Opus, Gemini 1.0, Gemini 1.5, Qwen-VL-Max와 같은 상업용 폐쇄 소스 LVLM을 평가했습니다.
결과는 현재 LVLM에 여전히 다음과 같은 5가지 주요 결함이 있음을 보여줍니다.
* 임상 적용 측면에서는 여전히 개선의 여지가 있습니다. 성능이 가장 좋은 모델인 GPT-4o조차도 실제 임상 적용에 필요한 요건을 충족했지만, 정확도는 53.96%에 불과합니다. 이는 현재의 LVLM이 의료 전문가의 문제를 처리하기에 부족하고 여전히 개선의 여지가 매우 크다는 것을 보여줍니다.
* 오픈소스 모델과 상용 모델 비교: MedDr 및 DeepSeek-VL-7B와 같은 오픈소스 LVLM의 정확도는 약 44%로, 일부 작업에서는 상용 모델인 Claude3-Opus 및 Qwen-VL-Max보다 성능이 뛰어나고 Gemini 1.5 및 GPT-4V와 비슷한 성능을 보입니다. 하지만 가장 성능이 좋은 GPT-4o와 비교하면 여전히 상당한 성능 격차가 존재합니다.
* 대부분의 의료용 모델은 일반 용도 LVLM의 일반적인 성능 수준(약 30% 정확도)에 도달하는 데 어려움을 겪습니다. 단, MedDr은 43.69% 정확도를 달성합니다.
* 대부분의 LVLM은 다양한 임상 VQA 작업, 부서 및 지각적 세부 사항에서 성과가 고르지 않습니다. 특히, 다양한 지각적 세분성을 이용한 실험에서 상자 수준 주석의 정확도는 항상 가장 낮았으며, 이미지 수준 주석의 정확도보다도 낮았습니다.
* 성능 병목 현상을 일으키는 주요 요인으로는 인식 오류(예: 이미지 콘텐츠를 잘못 식별), 의료 분야 지식 부족, 관련성 없는 답변 내용, 보안 프로토콜로 인한 질문에 대한 답변 거부 등이 있습니다.
요약하자면, 이러한 평가 결과는 의료 응용 분야에서 현재 LVLM의 성능은 여전히 개선의 여지가 많고 실제 임상적 필요를 충족시키기 위해 추가적으로 최적화되어야 함을 보여줍니다.
스마트 헬스케어 발전을 위한 오픈소스 의료 데이터 세트 수집
의학 분야에서는 고품질 오픈 소스 데이터 세트가 의학 연구와 임상 실무의 발전을 위한 중요한 원동력이 되었습니다. 이러한 목적을 위해 HyperAI는 여러분을 위해 몇 가지 의료 관련 데이터 세트를 선택했습니다. 각 데이터 세트는 다음과 같이 간략하게 소개됩니다.
PubMedVision 대규모 의료 VQA 데이터 세트
PubMedVision은 2024년에 선전 빅데이터 연구소, 홍콩 중국 대학, 국가 건강 데이터 연구소의 연구팀이 만든 대규모 고품질 의료 다중 모달 데이터 세트로, 130만 개의 의료 VQA 샘플을 포함하고 있습니다.
연구팀은 그래픽과 텍스트 데이터의 정렬을 개선하기 위해 대규모 시각 모델(GPT-4V)을 사용하여 이미지를 다시 설명하고 10가지 시나리오에서 대화를 구성했으며, 그래픽과 텍스트 데이터를 질의응답 형식으로 다시 작성하여 의학적 시각 지식의 학습을 강화했습니다.
직접 사용:https://go.hyper.ai/ewHNg
MMedC 대규모 다국어 의학 코퍼스
MMedC는 상하이 교통대학교 인공지능학원 스마트 헬스케어팀이 2024년에 구축한 다국어 의료 코퍼스입니다. 영어, 중국어, 일본어, 프랑스어, 러시아어, 스페인어 등 6개 주요 언어를 포함하는 약 255억 개의 토큰이 포함되어 있습니다.
연구팀은 또한 여러 벤치마크에서 매우 뛰어난 성능을 보인 다국어 의료 기반 모델인 MMed-Llama 3를 오픈 소스화했으며, 기존 오픈 소스 모델보다 성능이 훨씬 뛰어나고 특히 의료 분야에서 맞춤형 미세 조정에 적합합니다.
직접 사용:https://go.hyper.ai/xpgdM
MedCalc-Bench 의료 컴퓨팅 데이터 세트
MedCalc-Bench는 대규모 언어 모델(LLM)의 의료 컴퓨팅 역량을 평가하기 위해 특별히 설계된 데이터 세트입니다. 이 책은 미국 국립보건원 산하 국립의학도서관과 버지니아대학교 등 9개 기관이 공동으로 2024년에 출판했습니다. 이 데이터 세트에는 55개의 다양한 컴퓨팅 작업을 다루는 10,055개의 교육 인스턴스와 1,047개의 테스트 인스턴스가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/XHitC
OmniMedVQA 대규모 의료 VQA 평가 데이터 세트
OmniMedVQA는 의료 분야에 초점을 맞춘 대규모 시각적 질문 답변(VQA) 평가 데이터 세트입니다. 이 데이터 세트는 홍콩대학교와 상하이 인공지능 연구소가 2024년에 공동으로 출시했습니다. 여기에는 12가지 다양한 모달리티를 포함하는 118,010개의 다양한 이미지가 포함되어 있으며, 20개 이상의 다양한 인체 장기와 부위가 포함되어 있으며, 모든 이미지는 실제 의료 현장에서 가져온 것입니다. 이 연구의 목적은 대규모 의료 다중모달 모델 개발을 위한 평가 기준을 제공하는 것입니다.
직접 사용:https://go.hyper.ai/1tvEH
MedMNIST 의료 이미지 데이터 세트
MedMNIST는 2020년 10월 28일 상하이 교통대학에서 공개되었습니다. 이는 10개의 공공 의료 데이터 세트로 구성되어 있으며, 총 45만 개의 28*28 의료 다중 모드 이미지 데이터를 포함하고 있으며, 다양한 데이터 모드를 포괄하여 의료 이미지 분석과 관련된 문제를 해결하는 데 사용할 수 있습니다.
직접 사용:https://go.hyper.ai/aq7Lp
위의 내용은 이번 호에서 HyperAI가 추천하는 데이터 세트입니다. 고품질 데이터세트 리소스를 보셨다면 메시지를 남기시거나 기사를 제출해 알려주세요!
더 많은 고품질 데이터 세트를 다운로드하세요:https://go.hyper.ai/jJTaU
참고문헌:
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA
