Command Palette
Search for a command to run...
3초 만에 다중 음색 혼합 및 클로닝을 달성하세요! F5/E2 TTS 튜토리얼이 온라인에 공개되었습니다. PsyDTCorpus 5k 심리 대화 데이터 세트가 출시되어 심리 상담사의 언어 스타일을 정확하게 시뮬레이션합니다.

음성 복제 기술이 급속히 발전하면서 AI는 점점 더 사실적인 음성 효과를 시뮬레이션할 수 있게 되었지만, 제로 샘플 학습과 다중 감정 제어에는 여전히 많은 과제가 있습니다.
올해 초, E2 TTS는 패딩 마커로 텍스트 입력을 입력 음성과 같은 길이로 패딩한 다음, 잡음 제거를 수행하여 음성을 생성하는 간소화된 텍스트-음성 생성 방법을 구현했습니다. 최근 F5 TTS는 이 방법을 참조해 스트림 매칭의 비자기회귀 생성 방법을 기반으로 한 모델의 성능을 더욱 개량하여 다국어 합성을 지원할 뿐만 아니라 텍스트 내용에 따라 감정과 말하기 속도를 조절하여 긴 텍스트 음성 합성을 보다 섬세하고 부드럽게 만들어줍니다.
F5 TTS와 E2 TTS의 사운드 생성 효과를 모든 사람이 경험할 수 있도록 하기 위해,hyper.ai 공식 홈페이지에서 F5/E2 TTS 통합 튜토리얼을 공개했습니다. 클릭 한 번으로 복제가 가능합니다~
온라인으로 실행:https://go.hyper.ai/SZxqv
11월 4일부터 11월 8일까지 hyper.ai 공식 웹사이트가 업데이트됩니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 3개
* 커뮤니티 기사 선정: 4개 기사
* 인기 백과사전 항목: 5개
* 11월 마감일 상위 컨퍼런스: 6
공식 웹사이트를 방문하세요: hyper.ai
선택된 공개 데이터 세트
1. 헤어 유형 데이터세트 헤어 유형 데이터세트
헤어 타입 데이터셋은 다양한 헤어스타일을 분류하기 위한 이미지 데이터셋입니다. 여기에는 스트레이트, 웨이비, 컬리, 드레드락 등 4가지 유형의 헤어스타일에 대한 고품질 이미지가 포함되어 있으며, 총 1,992개의 이미지가 있습니다. 이 데이터 세트는 머신 러닝 모델을 훈련하여 모발 유형을 식별하고 분류하는 데 도움이 됩니다.
직접 사용:https://go.hyper.ai/aXYcj

2. AllClear 퍼블릭 클라우드 제거 데이터 세트
AllClear 데이터 세트는 현재 가장 큰 규모의 퍼블릭 클라우드 제거 데이터 세트로, 다양한 토지 이용 패턴을 포괄하는 전 세계적으로 분산된 23,742개의 관심 지역(ROI)과 총 400만 개의 이미지를 포함하고 있습니다. 이는 구름 제거 연구에서 벤치마크와 다양한 교육 데이터가 부족하다는 문제를 해결합니다.
직접 사용:https://go.hyper.ai/e2BYC

3. 무하라프(Muharaf) 필기 아랍어 데이터세트
무하라프 데이터 세트는 손으로 쓴 아랍어 문자 인식에 초점을 맞춘 머신 러닝 데이터 세트입니다. 이 데이터 세트에는 아랍어 전문가가 필사한 역사적 손으로 쓴 페이지의 1,600개 이상의 이미지가 포함되어 있습니다. 각 문서 이미지에는 텍스트 줄의 공간적 다각형 좌표와 기본 페이지 요소에 대한 정보가 함께 제공됩니다.
직접 사용:https://go.hyper.ai/NN2UR
4. 다중 모드 분광 화학 다중 모드 분광 데이터 세트
이 데이터 세트에는 특허 데이터의 화학 반응에서 추출한 790,000개 분자의 시뮬레이션된 1H-NMR, 13C-NMR, HSQC-NMR, 적외선 및 질량 분석(양이온 및 음이온 모드) 스펙트럼 데이터가 포함되어 있습니다. 이 기술은 다양한 스펙트럼 모드에서 얻은 정보를 통합하고 인간 전문가가 분자 구조를 분석하는 데 사용하는 방법을 시뮬레이션할 수 있으므로 구조 분석을 자동화하고 합성에서 구조 결정까지 분자 발견 프로세스를 단순화할 수 있는 잠재력을 가지고 있습니다.
직접 사용:https://go.hyper.ai/Z7zlr
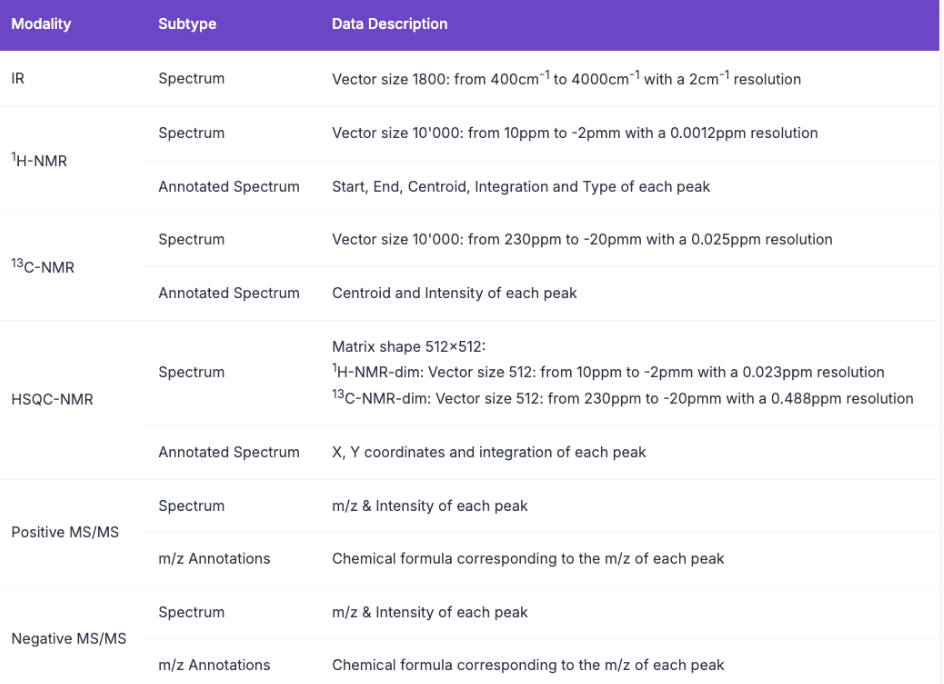
5. GMAI-MMBench 의료 다중 모드 평가 벤치마크 데이터세트
GMAI-MMBench는 일반 의료 인공지능 분야를 발전시키기 위해 고안된 다중 모드 평가 벤치마크입니다. 여기에는 38개의 의료 영상 모달리티와 18개의 임상적으로 관련된 과제를 포함하는 다양한 출처의 284개 데이터 세트가 포함되어 있으며, 18개의 다른 진료과를 포괄하고 있으며, 4가지 다른 지각적 세분성에서 평가되어 여러 차원에서 LVLM의 성능을 고려합니다.
직접 사용:https://go.hyper.ai/FL799
6. PsyDTCorpus 심리 상담사 디지털 트윈 데이터 세트
PsyDTCorpus 데이터 세트의 핵심 목표는 특정 심리 상담사의 언어 스타일과 상담 기술을 시뮬레이션하여 심리 상담사 디지털 트윈 모델인 SoulChat2.0의 개발과 교육을 지원하는 것입니다. 이 데이터 세트에는 상담사의 언어 스타일과 치료 기술 적용 방법이 포함된 5k개의 고품질 정신 건강 대화 데이터가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/hGi4O
7. GTSinger 노래 오디오 데이터 세트
이 데이터 세트는 전문 스튜디오에서 녹음된 80.59시간 분량의 노래를 담고 있는 대규모 오픈 소스 고품질 노래 데이터 세트입니다. 이 노래들은 중국어, 영어, 일본어, 한국어 등 9개 언어로 20명의 전문 가수가 부르며, 연구자들에게 매우 풍부한 음색과 스타일을 갖춘 자료 라이브러리를 제공합니다.
직접 사용:https://go.hyper.ai/wBcBz
8. OC22 촉매 시뮬레이션 데이터 세트
이 데이터 세트는 촉매 시뮬레이션 데이터 세트, 즉 Open Catalyst 2022(OC22) 데이터 세트입니다. 이 데이터 세트는 OC20 데이터 세트를 확장하고 보완하며, 더욱 복잡한 촉매 구조와 새로운 반응 유형을 포함하고 있으며, AI 모델의 훈련 및 테스트를 위한 더욱 풍부한 데이터를 제공합니다.
직접 사용:https://go.hyper.ai/M8Cpn
9. OQMD 오픈 소스 양자 재료 데이터 세트
OQMD 데이터 세트에는 밀도 함수 이론(DFT)을 사용하여 계산된 122만 개 이상의 재료의 열역학적 및 구조적 특성이 포함되어 있습니다. 데이터 세트의 데이터는 무기 결정 구조 데이터베이스(ICSD)에서 파생되었으며, 여기에는 약 30만 개의 화합물에 대한 DFT 총 에너지 계산과 일반적인 결정 구조의 변형이 포함됩니다.
직접 사용:https://go.hyper.ai/dGOKs
10. 재료 프로젝트 온라인 재료 데이터베이스
재료 프로젝트 데이터베이스의 데이터에는 결정 구조와 에너지 특성은 물론, 전자 구조와 열역학적 특성과 같은 자세한 정보가 포함되어 있습니다. 이 데이터 세트는 고처리량 기본 원리 계산을 사용하여 100만 개가 넘는 무기 재료에 대한 포괄적인 성능 데이터, 구조 정보 및 계산 시뮬레이션 결과를 제공하고, 이를 통해 새로운 재료의 발견 및 혁신 프로세스를 가속화하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/tGIVs
더 많은 공개 데이터 세트를 보려면 방문하세요.:
선택된 공개 튜토리얼
1. AnyText 다국어 시각적 텍스트 생성 및 편집
AnyText는 다국어 시각적 텍스트 생성 및 편집 모델입니다. 중국어, 영어, 일본어, 한국어 등 여러 언어로 텍스트 생성을 지원할 수 있으며, 입력 이미지의 텍스트 내용 편집도 지원합니다. 이 모델에 포함된 텍스트 생성 기술은 전자상거래 포스터, 로고 디자인, 창의적인 그래피티, 이모티콘과 같은 새로운 AIGC 응용 분야의 가능성을 제공합니다.
아래 링크를 클릭하고 튜토리얼 단계에 따라 컨테이너를 복제하고 시작한 다음, 창의력을 발휘하여 이미지를 디자인하세요.
온라인으로 실행:https://go.hyper.ai/uMcNa
2. F5/E2 TTS는 단 3초 만에 모든 사운드를 복제합니다.
이 튜토리얼에는 F5 TTS와 E2 TTS 모델의 데모 사용 방법이 포함되어 있습니다. F5 TTS는 추가적인 지도 없이 제로샷 학습을 통해 원본 텍스트에 자연스럽고 유창하며 충실한 음성을 빠르게 생성할 수 있습니다. E2 TTS는 전체 음성 시퀀스를 한 번에 생성할 수 있어 고품질 음성 출력을 유지하면서 생성 속도를 크게 향상시킵니다.
이 프로젝트는 Gradio 인터페이스를 통해 프런트엔드 대화형 인터페이스를 생성할 수 있습니다. 관련 모델과 종속성이 배포되었습니다. 한 번의 클릭으로 사운드 복제를 경험할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/SZxqv
Stable Diffusion 3.5 Large 모델은 이미지 품질, 타이포그래피, 복잡한 프롬프트 이해 및 리소스 효율성 측면에서 상당한 개선을 이룬 다중 모드 확산 생성기(MMDiT) 텍스트-이미지 모델입니다. 80억 개의 매개변수로 구성된 거대한 크기는 전문가 수준의 이미지 생성 기능을 제공하며, 특히 고해상도 이미지 생성 요구 사항에 적합합니다.
이 튜토리얼에서는 환경을 배포했으며, 튜토리얼 지침에 따라 고해상도 이미지를 직접 생성할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/w5k5V

💡또한, 안정적 확산 튜토리얼 교환 그룹도 만들었습니다. 친구들을 환영합니다. QR 코드를 스캔하고 [SD 튜토리얼]에 댓글을 남겨 그룹에 가입하여 다양한 기술 문제를 논의하고 신청 결과를 공유하세요~

커뮤니티 기사
1. 원소 주기율표를 거의 다룹니다! Meta는 1억 1천만 개의 DFT 계산 결과를 포함하는 오픈 소스 OMat24 데이터 세트를 출시했습니다.
최근 Meta는 Open Materials 2024 대규모 오픈소스 데이터 세트와 이를 지원하는 사전 학습된 모델 세트를 출시했습니다. 그 중 OMat24 데이터 세트에는 구조적, 구성적 다양성에 초점을 맞춘 1억 1천만 개 이상의 밀도 함수 이론 계산 결과가 포함되어 있습니다. 해당 데이터 세트는 현재 HyperAI 공식 웹사이트에서 이용 가능합니다. 본 논문은 연구논문을 자세히 해석하고 공유하는 것입니다.
전체 보고서 보기:https://go.hyper.ai/3wP7R
2. 활동리뷰丨상하이교통대학교/절강대학교/칭화대학교/오픈베이즈 의료/지리정보/도시복합시스템/과학연구의 새로운 패러다임을 다루는 다수의 전문가
COSCon'24 기간 동안, 공동 제작 커뮤니티인 HyperAI는 과학을 위한 AI를 주제로 오픈 소스 AI 포럼을 개최했습니다. 상하이 교통대학교, 저장대학교, 칭화대학교, OpenBayes 베이지안 컴퓨팅의 전문가와 학자들이 의료 인공지능, 지리 정보 인공지능, 과학 연구 지능형 컴퓨팅 클라우드 플랫폼, AI 기반 도시 복합 시스템 등 다양한 측면에 대한 통찰력을 공유했습니다. 이 기사는 포럼의 주요 내용을 리뷰한 것입니다. 자세한 내용을 보려면 여기를 클릭하세요.
이벤트 요약 보기:https://go.hyper.ai/s2RQU
3. NVIDIA로부터 2차 투자를 받았습니다! AI 제약회사 Terray, 세계 최대 화학 데이터 세트 구축을 위해 1억 2천만 달러 자금 조달 완료
AI 제약 회사인 테레이 테라퓨틱스(Terray Therapeutics)가 엔비디아의 벤처 캐피털 부문인 NVentures와 신규 투자자인 Bedford Ridge Capital이 주도한 1억 2,000만 달러 규모의 시리즈 B 펀딩 라운드를 완료했습니다. 이는 또한 엔비디아가 테레이에 투자한 두 번째 사례입니다. 또한 이 회사는 세계 최대 규모의 화학 데이터 세트를 구축하고 AI와 습식 실험을 결합하여 데이터 측면에서 폐쇄 루프를 형성했습니다. 자세한 설명을 보려면 여기를 클릭하세요.
전체 보고서 보기:https://go.hyper.ai/AWojF
"AI4S를 만나다" 라이브 시리즈의 네 번째 에피소드에서 박사 학위를 소지한 란 쿤야오가 상하이 교통대학교 크로스미디어 언어 지능 연구실의 연구원들이 "대형 모델 에이전트 기반 정신 건강 진단 및 상담 플랫폼"이라는 제목으로 발표를 했습니다. 그는 심리 클리닉의 사용 단계, 기술적 하이라이트, 미래 계획을 자세히 소개했습니다. 본 기사는 지능형 심리 클리닉 시연을 포함한 연설의 주요 내용을 요약한 것입니다. 클릭하면 빠르게 볼 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/CHhKC
인기 백과사전 기사
1. 변압기 모델
2. 변형 오토인코더 VAE
3. 인공신경망
4. 파레토 전선
5. 대규모 멀티태스크 언어 이해(MMLU)
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1300개 이상의 공공 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 400개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 100개 이상의 AI4Science 논문 사례 해석
* 500개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.
마지막으로 "크리에이터 인센티브 프로그램"을 추천드립니다. 관심 있는 친구들은 QR 코드를 스캔하여 참여할 수 있습니다!
