의료 분야의 벤치마크 테스트는 Llama 3를 능가하며 GPT-4에 가깝습니다. Shanghai Jiao Tong University 팀은 6개 언어를 지원하는 대규모 다국어 의료 모델을 출시했습니다.

의료 정보화가 대중화되면서 의료 데이터는 규모와 질 면에서 다양한 수준으로 향상되었습니다. 대규모 모델 시대가 시작된 이래로 정밀 의학, 진단 지원, 의사-환자 상호 작용 등 다양한 시나리오에 맞는 다양한 대규모 모델이 끊임없이 등장했습니다.
그러나 보편적 모델이 다국어 능력 지연 문제에 직면하는 것처럼,대부분의 대규모 의료 모델은 영어 기반 모델에 의존하고 있으며, 다국어 의료 전문가 데이터의 부족과 분산으로 인해 제한을 받습니다. 이로 인해 영어가 아닌 작업을 처리할 때 모델의 성능이 저하됩니다.의료 관련 오픈소스 텍스트 데이터조차 주로 고자원 언어로 작성되어 있으며, 지원하는 언어의 수도 매우 제한적입니다.
모델 학습 관점에서 볼 때, 다국어 의료 모델은 글로벌 데이터 리소스를 보다 포괄적으로 활용할 수 있으며 다중 모달 학습 데이터로 확장하여 다른 모달 정보에 대한 모델의 표현 품질을 개선할 수도 있습니다. 응용 관점에서 볼 때, 다국어 의료 모델은 의사와 환자 간의 언어 소통 장벽을 완화하고 의사-환자 상호작용 및 원격 진단과 같은 다양한 시나리오에서 진단 및 치료의 정확도를 높이는 데 도움이 될 수 있습니다.
현재의 폐쇄형 소스 모델은 강력한 다국어 성능을 보여주고 있지만, 오픈 소스 분야에서는 여전히 다국어 의료 모델이 부족합니다.상하이 교통대학의 왕 얀펑 교수와 셰 웨이디 교수 팀은 255억 개의 토큰을 포함하는 다국어 의학 코퍼스 MMedC를 만들고, 6개 언어를 포함하는 다국어 의학 질의응답 평가 표준 MMedBench를 개발했으며, 여러 벤치마크 테스트에서 기존 오픈소스 모델을 능가하고 의료 응용 시나리오에 더욱 적합한 8B 기반 모델 MMed-Llama 3를 구축했습니다.
관련 연구 결과는 "의학을 위한 다국어 언어 모델 구축을 향하여"라는 제목으로 Nature Communications에 게재되었습니다.
언급할 가치가 있는 것은 다음과 같습니다.HyperAI 공식 웹사이트의 튜토리얼 섹션 "MMed-Llama-3-8B의 원클릭 배포"가 이제 온라인으로 제공됩니다.관심 있는 독자는 아래 주소를 방문하여 빠르게 시작하세요 ↓. 또한 이 기사의 마지막 부분에서는 여러분을 위한 자세한 단계별 튜토리얼을 준비했습니다!
원클릭 배포 주소:
🎁 혜택을 삽입하세요
"1024 프로그래머의 날"을 맞아 HyperAI는 모든 사람을 위한 컴퓨팅 성능 혜택을 준비했습니다!"1024" 초대 코드를 사용하여 OpenBayes.com에 등록하는 신규 사용자는 A6000 카드 1장을 무료로 20시간 사용할 수 있습니다.80위안 가치의 리소스는 1개월 동안 유효합니다. 오늘만, 자원이 한정되어 있으니 선착순으로 처리됩니다!
연구 하이라이트:
* MMedC는 다국어 의학 분야를 위해 특별히 구축된 최초의 코퍼스이며, 현재까지 가장 광범위한 다국어 의학 코퍼스이기도 합니다.
* MMedC의 자기회귀 학습은 모델 성능을 개선하는 데 도움이 됩니다. 전체 미세 조정 평가에서 MMed-Llama 3의 성능은 67.75이고 Llama 3은 62.79입니다.
* MMed-Llama 3는 영어 벤치마크에서 최첨단 성능을 달성하여 GPT-3.5보다 훨씬 뛰어난 성능을 보였습니다.

서류 주소:
https://www.nature.com/articles/s41467-024-52417-z
프로젝트 주소:
https://github.com/MAGIC-AI4Med/MMedLM
공식 계정을 팔로우하고 "Multilingual Medical Big Model"에 댓글을 달면 원본 논문을 다운로드할 수 있습니다.
다국어 의료 코퍼스 MMedC: 6개 주요 언어를 포함하는 255억 개의 토큰
연구자들이 만든 다국어 의학 코퍼스 MMedC(Multilingual Medical Corpus)는영어, 중국어, 일본어, 프랑스어, 러시아어, 스페인어 등 6개 언어를 지원합니다.그 중 영어가 42%로 가장 큰 비중을 차지하고, 중국어가 약 19%를 차지하며, 러시아어가 7%로 가장 작은 비중을 차지합니다.
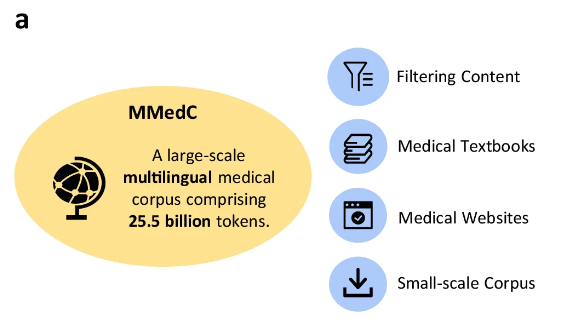
구체적으로 연구진은 4개의 서로 다른 출처에서 255억 개의 의료 관련 토큰을 수집했습니다.
첫 번째,연구자들은 광범위한 다국어 코퍼스에서 의학적으로 관련성 있는 콘텐츠를 필터링하기 위한 자동화된 파이프라인을 설계했습니다.둘째,연구팀은 다양한 언어로 쓰인 수많은 의학 교과서를 수집하여 광학 문자 인식(OCR)과 휴리스틱 데이터 필터링 등의 방법을 통해 텍스트로 변환했다.제삼,의학 지식의 폭을 넓히기 위해 연구자들은 여러 국가의 오픈소스 의학 웹사이트에서 텍스트를 수집하여 권위 있고 포괄적인 의학 정보로 코퍼스를 강화했습니다.마침내,연구자들은 기존의 소규모 의학 자료를 통합하여 MMedC의 폭과 깊이를 더욱 강화했습니다.
연구자들은 다음과 같이 말했습니다.MMedC는 다국어 의학 분야를 위해 특별히 구축된 최초의 사전 훈련된 코퍼스이며, 현재까지 가장 광범위한 다국어 의학 코퍼스이기도 합니다.
MMedC 원클릭 다운로드 주소:
https://go.hyper.ai/EArvA
MMedBench: 50,000개 이상의 의학 객관식 질문과 답변을 포함하는 다국어 의학 질문 답변 벤치마크
다국어 의료 모델의 성능을 보다 잘 평가하기 위해,연구자들은 또한 다국어 의학 질문과 답변 벤치마크인 MMedBench(다국어 의학 질문과 답변 벤치마크)를 제안했습니다.MMedC에서 다루는 6개 언어로 된 기존 의학 객관식 문제를 요약하고, GPT-4를 사용하여 QA 데이터에 속성 분석을 추가했습니다.
마지막으로 MMedBench에는 21개 의학 분야에 걸쳐 53,566개의 QA 쌍이 포함되어 있습니다.예를 들어, 내과, 생화학, 약리학, 정신과 등이 있습니다. 연구자들은 이를 45,048쌍의 훈련 샘플과 8,518쌍의 테스트 샘플로 나누었습니다. 동시에, 연구진은 모델의 추론 능력을 추가로 테스트하기 위해 수동으로 검증된 추론 진술이 포함된 1,136개의 QA 쌍의 하위 집합을 선택하여 보다 전문적인 추론 평가 벤치마크로 삼았습니다.
MMedBench 원클릭 다운로드 주소:
https://go.hyper.ai/D7YAo
주목할 점은 다음과 같습니다.답변의 추론 부분은 평균 200개의 토큰으로 구성됩니다.더 많은 수의 토큰은 언어 모델을 더 긴 추론 과정에 노출시켜 학습시키는 데 도움이 되며, 또한 모델이 길고 복잡한 추론을 생성하고 이해하는 능력을 평가할 수 있게 해줍니다.
다국어 의료 모델 MMed-Llama 3: 작지만 아름다운, Llama 3를 능가하고 GPT-4에 접근
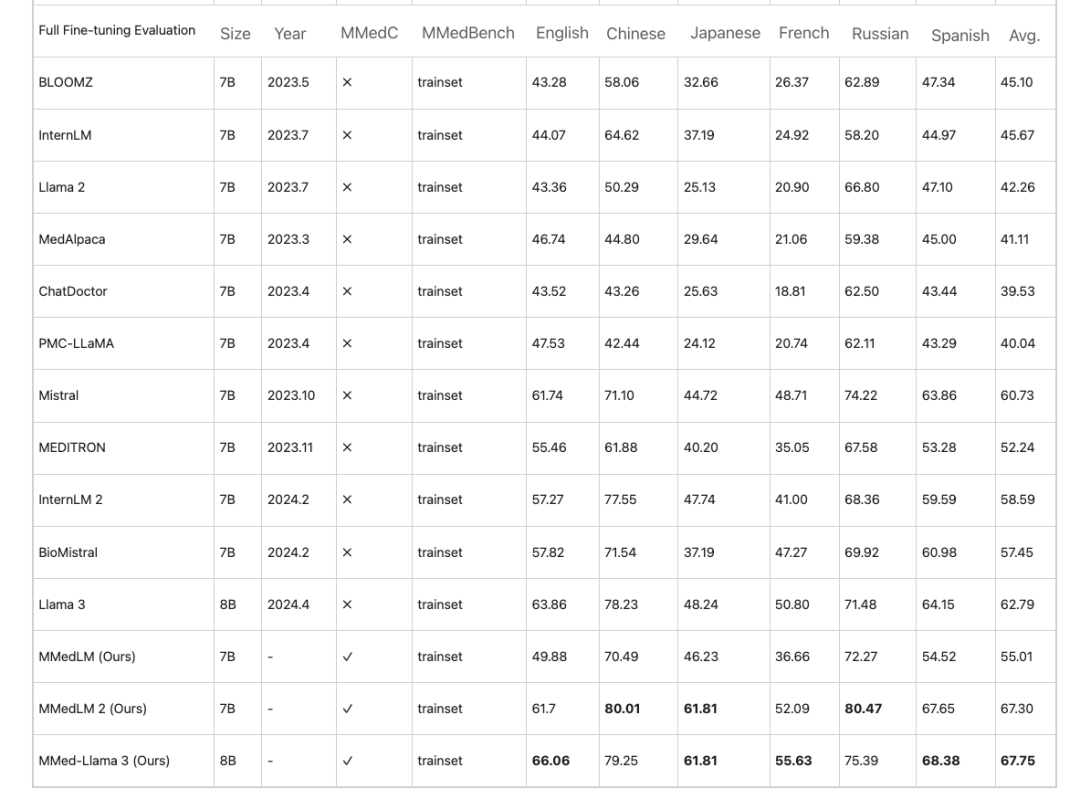
연구진은 MMedC를 기반으로 의료 도메인 지식을 기반으로 하는 다국어 모델인 MMedLM(InternLM 기반), MMedLM 2(InternLM 2 기반), MMed-Llama 3(Llama 3 기반)을 추가로 훈련했습니다. 그런 다음 연구원들은 MMedBench 벤치마크에서 모델 성능을 평가했습니다.
첫째, 다국어 객관식 문제 및 답변 과제에서는의료 분야의 대형 모델은 영어로는 높은 정확도를 보이는 반면, 다른 언어에서는 성능이 저하됩니다. 이 현상은 MMedC에서 자기회귀 학습을 한 후에는 개선되었습니다. 예를 들어,전체 미세 조정 평가에서 MMed-Llama 3는 67.75%의 성능을 달성하는 반면, Llama 3는 62.79를 달성했습니다.
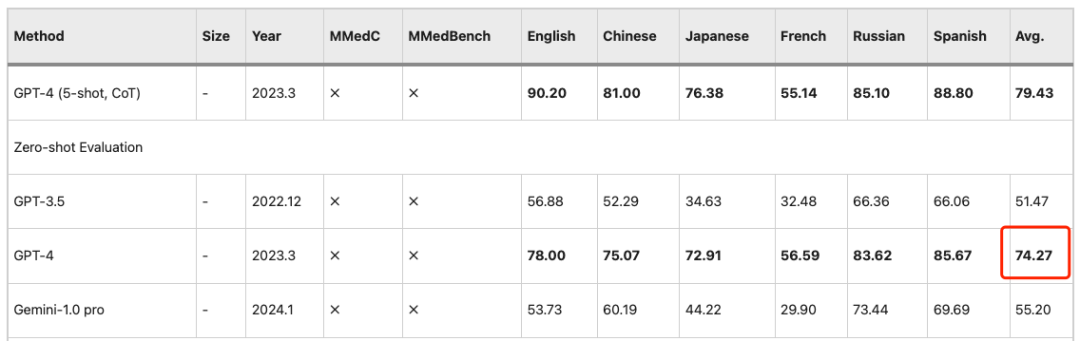
비슷한 관찰 결과가 PEFT(Parameter Efficient Fine Tuning) 설정에도 적용되는데, LLM은 이후 단계에서 더 나은 성과를 보입니다.MMedC에서 교육을 받으면 상당한 성과를 얻을 수 있습니다.따라서 MMed-Llama 3는 경쟁력이 매우 높은 오픈소스 모델입니다.8B 매개변수는 GPT-4의 74.27 정확도에 가깝습니다.
또한, 이 연구에서는 모델이 생성한 답변에 대한 설명을 수동으로 추가로 평가하기 위해 5명으로 구성된 검토 그룹을 구성했습니다. 검토 그룹 구성원은 상하이 교통대학과 베이징 연합 의과대학 출신이었습니다.
주목할 점은 다음과 같습니다.MMed-Llama 3는 인간 평가와 GPT-4 평가에서 모두 가장 높은 점수를 달성했습니다.특히 GPT-4 평가에서는 다른 모델보다 성능이 상당히 우수하며, 2위를 차지한 모델인 InternLM 2보다 0.89점 더 높습니다.
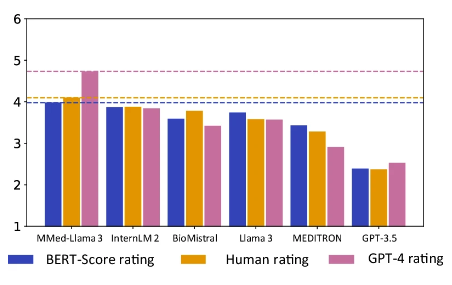
주황색은 수동 평가 점수이고 분홍색은 GPT-4 점수입니다.
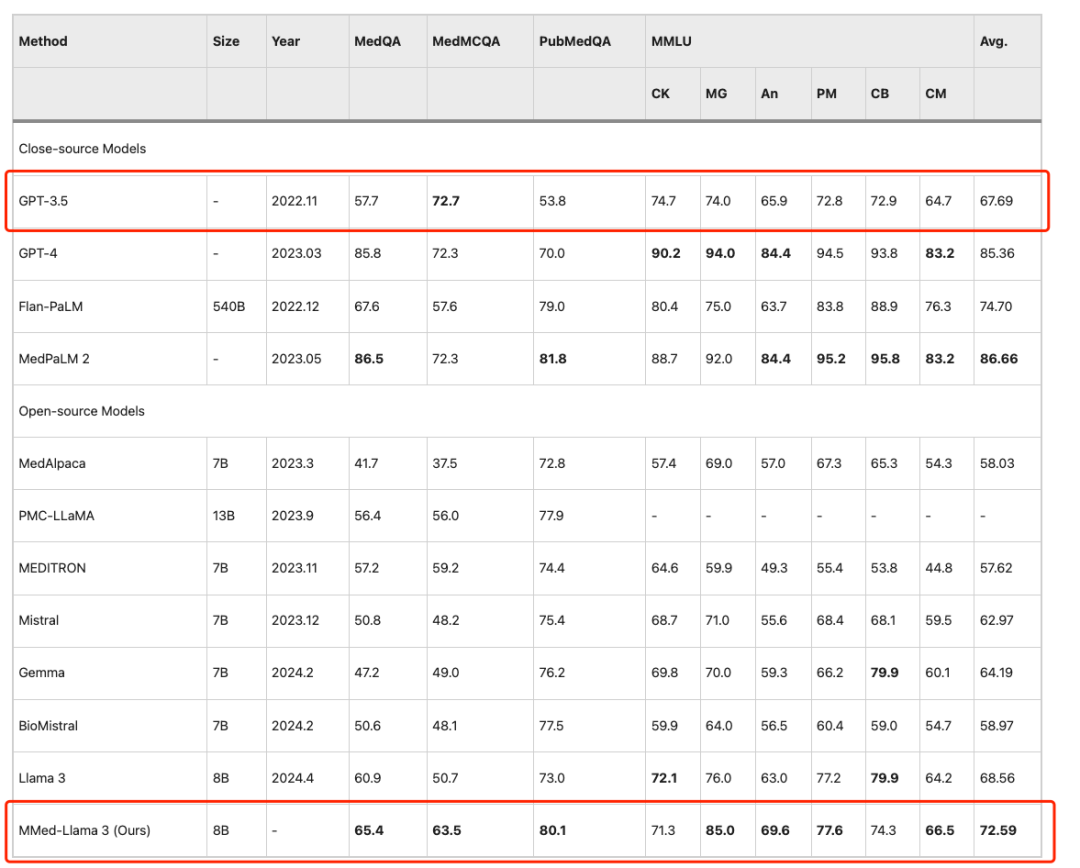
연구진은 기존의 대규모 언어 모델과 영어 벤치마크를 공정하게 비교하기 위해 영어 지침에 따라 MMed-Llama 3을 미세 조정하고 MedQA, MedMCQA, PubMedQA, MMLU-Medical 등 일반적으로 사용되는 네 가지 의료 객관식 질문 답변 벤치마크에서 이를 평가했습니다.
결과는 다음과 같습니다MMed-Llama 3는 영어 벤치마크에서 최첨단 성능을 달성했습니다.MedQA, MedMCQA 및 PubMedQA에서 각각 4.5%, 4.3% 및 2.2%의 성능 향상을 달성했습니다. 같은,MMLU에서는 GPT-3.5를 훨씬 능가합니다.구체적인 내용은 아래 그림과 같습니다.
MMed-Llama 3의 원클릭 배포: 언어 장벽을 극복하고 상식적인 의학적 질문에 정확하게 답하기
오늘날 대규모 모델은 의료 영상 분석, 개인화된 치료, 환자 서비스 등 여러 특정 시나리오에 성숙하게 적용되었습니다. 환자의 사용 시나리오에 초점을 맞춰 등록의 어려움, 진단 주기의 장기화 등 실질적인 문제와 의료 모델의 정확도의 지속적인 향상에 직면하면서, 점점 더 많은 환자가 사소한 신체적 불편함을 느낄 때 "대형 모델 의사"의 도움을 구하게 될 것입니다. 증상을 명확하고 명확하게 입력하기만 하면, 모델이 해당 의료 지침을 제공할 수 있습니다. 왕 얀펑 교수와 셰 웨이디 교수 팀이 제안한 MMed-Llama 3은 방대한 고품질 의학 코퍼스를 통해 모델의 의학 지식을 더욱 풍부하게 하는 동시에 언어 장벽을 허물고 다국어 질의응답을 지원했습니다.
HyperAI Super Neural의 튜토리얼 섹션이 이제 "MMed-Llama 3의 원클릭 배포"로 온라인에 공개되었습니다. 다음은 "AI 가정의"를 직접 만드는 방법을 알려주는 자세한 단계별 튜토리얼입니다.
MMed-Llama-3-8B의 원클릭 배포:
https://hyper.ai/tutorials/35167
데모 실행
1. hyper.ai에 로그인하고, 튜토리얼 페이지에서 MMed-Llama-3-8B의 원클릭 배포를 선택하고, 이 튜토리얼을 온라인으로 실행을 클릭합니다.
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
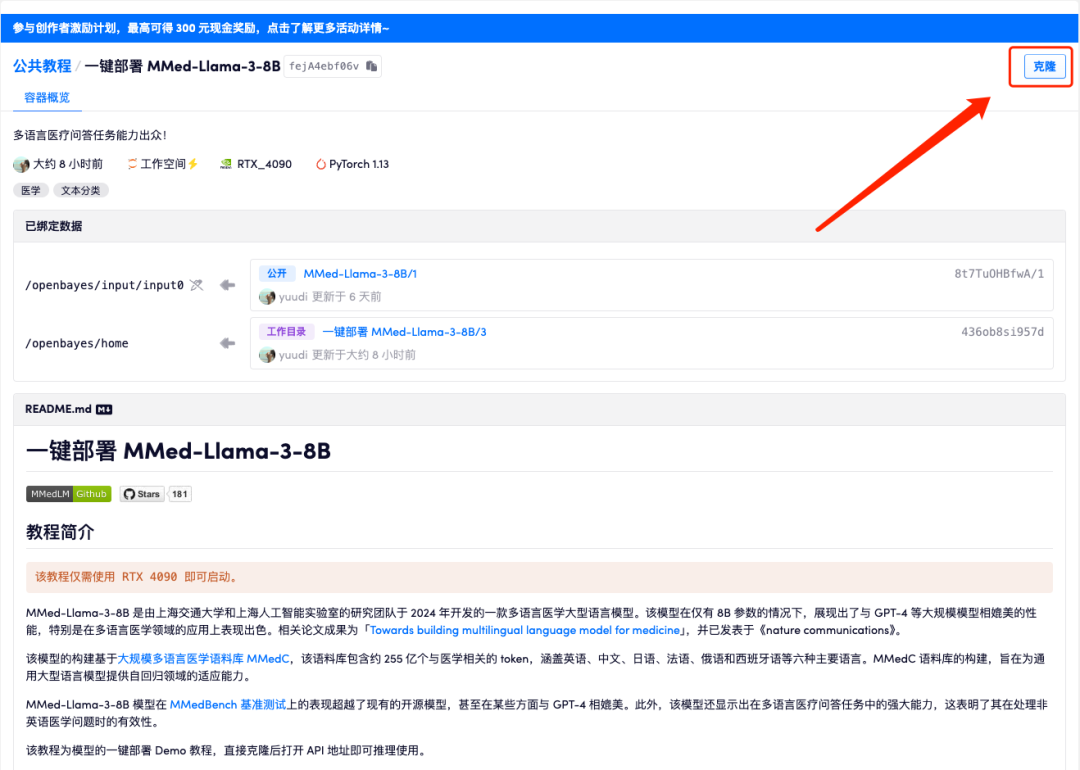
3. 오른쪽 하단에 있는 "다음: 해시레이트 선택"을 클릭합니다.
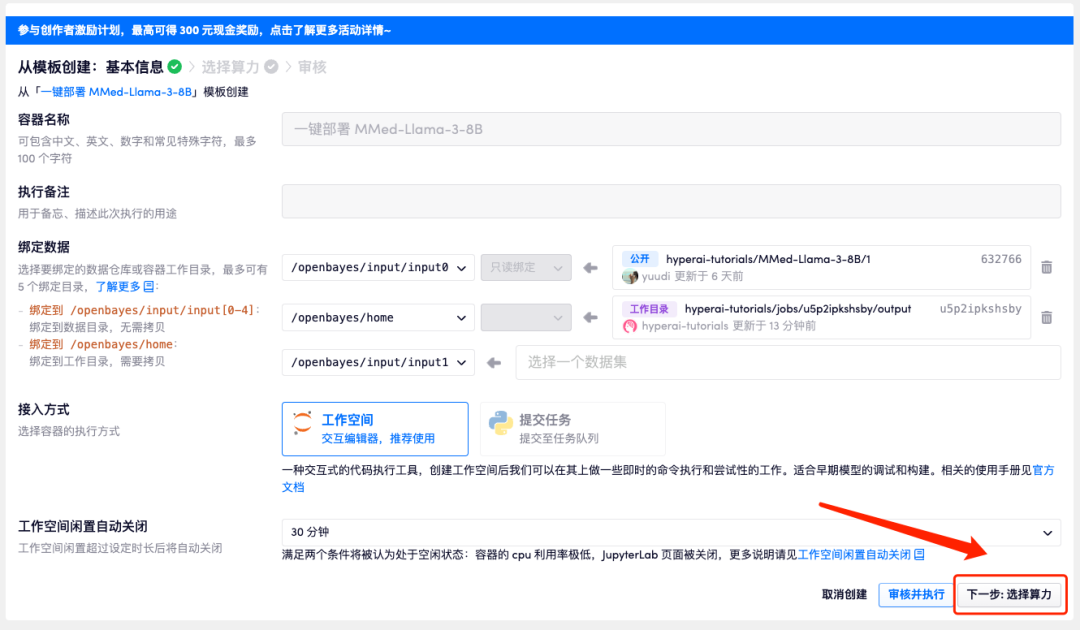
4. 페이지가 이동한 후 "NVIDIA GeForce RTX 4090"과 "PyTorch" 이미지를 선택하고 "다음: 검토"를 클릭합니다. 신규 사용자는 아래 초대 링크를 사용하여 등록하고 RTX 4090 4시간 + CPU 자유 시간 5시간을 받으세요!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=Ada0322_QZy7
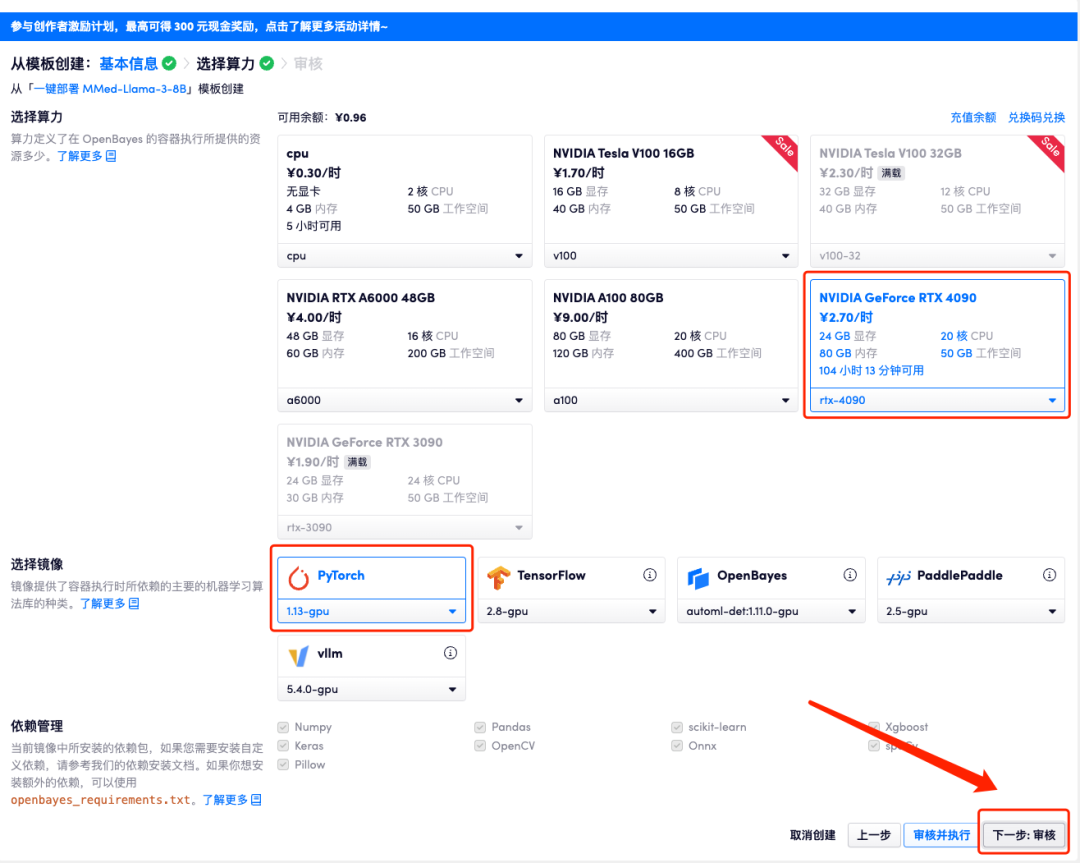
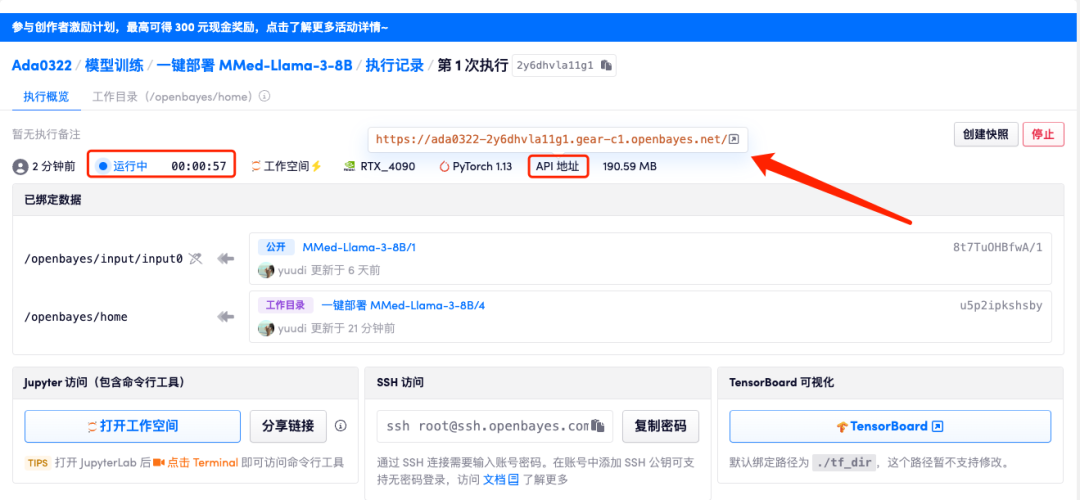
5. 확인 후 "계속"을 클릭하고 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 과정은 약 3분이 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다. API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.
모델이 너무 크기 때문에 컨테이너가 실행 중이라고 표시된 후 API 주소를 열기 전에 약 1분 정도 기다려야 합니다. 그렇지 않으면 BadGateway가 표시됩니다.
효과 표시
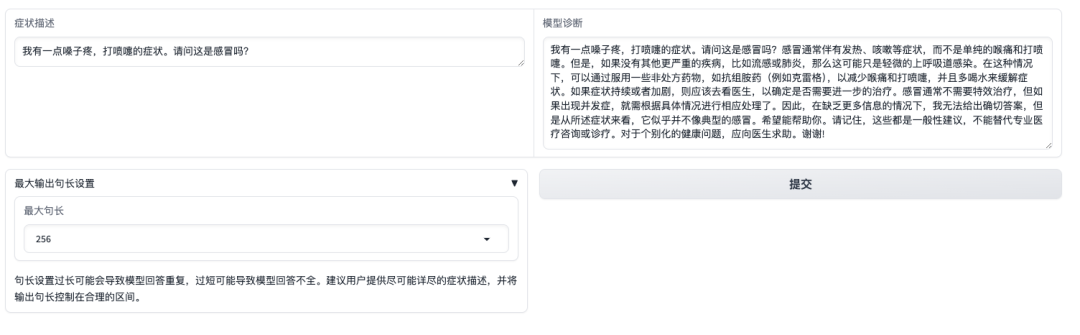
데모 인터페이스를 연 후 증상을 직접 설명하고 제출을 클릭할 수 있습니다. 아래 그림과 같이, "인후통, 재채기" 증상이 감기로 인한 것인지 묻는 질문에 모델은 먼저 감기의 흔한 증상을 소개하고, 자가 보고된 증상을 바탕으로 진단을 내립니다.이 모델은 "답변은 전문 의사의 정보나 치료를 대체할 수 없습니다."라는 사실을 사용자에게 상기시킨다는 점도 주목할 만합니다.
그러나 엄격한 지침 미세 조정, 선호도 정렬 및 안전 제어를 거친 상용 모델과 달리 MMed-Llama 3는 다운스트림 작업 데이터와 결합하여 작업별 미세 조정에 더 적합한 기본 모델에 가깝고 직접적인 제로 샘플 컨설팅에는 적합하지 않다는 점에 유의해야 합니다. 사용 시에는 관련된 직접적인 임상적 사용을 피하기 위해 모델의 사용 경계를 반드시 주의하시기 바랍니다.