Command Palette
Search for a command to run...
온라인 튜토리얼 | 1분 안에 10,000단어 분량의 서스펜스 소설을 제작하세요. LongWriter-glm4-9b는 긴 텍스트 출력의 병목 현상을 해소합니다.

최근 몇 년 동안 대규모 언어 모델(LLM)은 복잡한 텍스트를 이해하고 생성하는 데 뛰어난 역량을 보여주었습니다. 최대 10만 개의 토큰 입력을 처리할 수 있었지만, 2,000개 이상의 단어에 대한 일관된 출력을 생성하는 데 어려움을 겪는 경우가 많았습니다.
가장 큰 이유 중 하나는 SFT(지도 미세 조정) 데이터 세트에서 긴 출력 샘플이 부족하다는 것입니다.이 연구는 모델의 최대 출력 길이가 SFT 단계에서 노출되는 샘플의 길이와 유의미한 양의 상관관계를 가지고 있음을 보여줍니다. 다시 말해, 모델은 긴 텍스트를 이해하고 처리하는 방법은 배웠지만, 동일한 길이의 텍스트를 생성하는 방법은 아직 완전히 배우지 못했습니다.
이 문제를 해결하기 위해 청화대학교와 지푸 AI는 AgentWrite 기술을 기반으로 LongWriter-6k라는 데이터 세트를 구축했습니다. 이 데이터 세트에는 6,000개의 SFT 데이터 샘플이 포함되어 있으며 출력 길이는 2,000~32,000단어에 이릅니다.해당 데이터 세트는 현재 HyperAI 공식 웹사이트의 데이터 세트 섹션에서 이용 가능하며, 원클릭 입력을 지원합니다.
데이터 세트 주소:
이후 연구팀은 LongWriter-6k도 사용하고 GLM-4-9B 기반으로 학습하여 10,000단어 이상의 일관된 텍스트를 생성할 수 있는 LongWriter-glm4-9b 모델을 얻었으며, 이를 통해 대규모 언어 모델의 출력 잠재력이 크게 확장되었고 문학 창작 및 뉴스 보도와 같은 실제 응용 분야에서 뛰어난 다재다능함을 보여주었습니다.
현재 HyperAI Super Neural Tutorial 섹션에서 "LongWriter-glm4-9b의 원클릭 배포"가 시작되었습니다.한 번의 클릭으로 복제가 시작됩니다.
튜토리얼 주소:
데모 실행
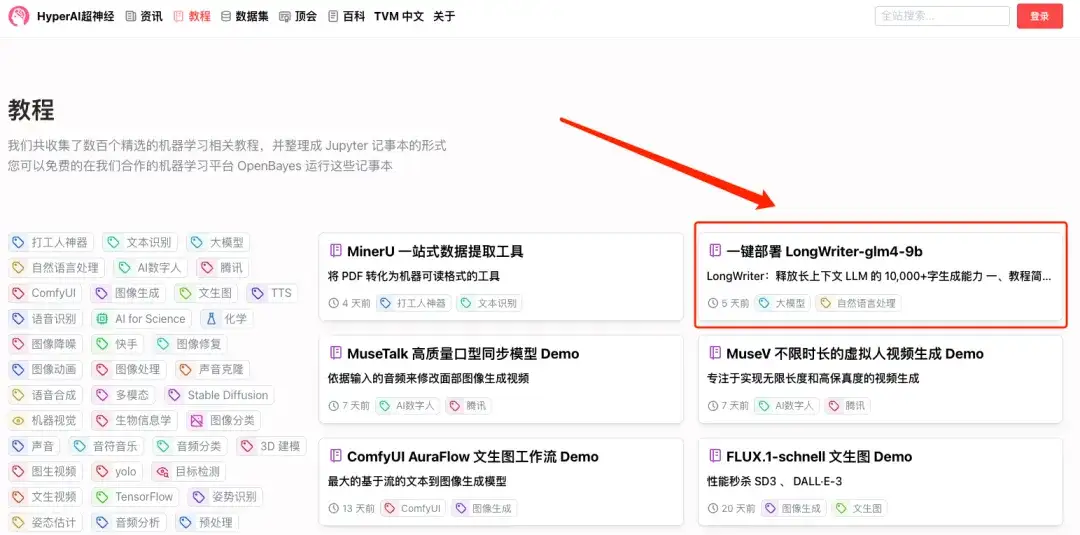
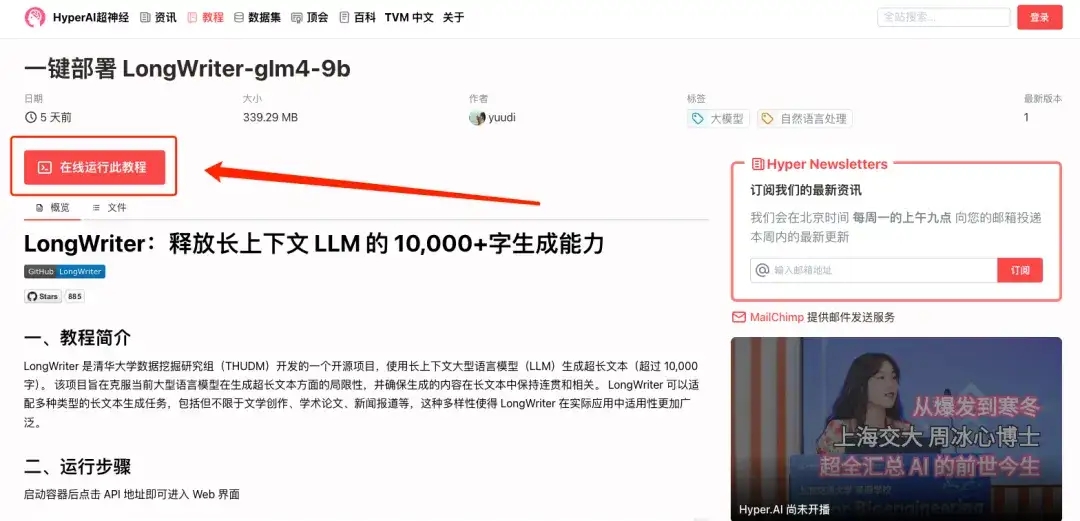
1. hyper.ai에 로그인하고 "튜토리얼" 페이지에서 "LongWriter-glm4-9b의 원클릭 배포"를 검색한 후 "이 튜토리얼을 온라인으로 실행"을 클릭합니다.
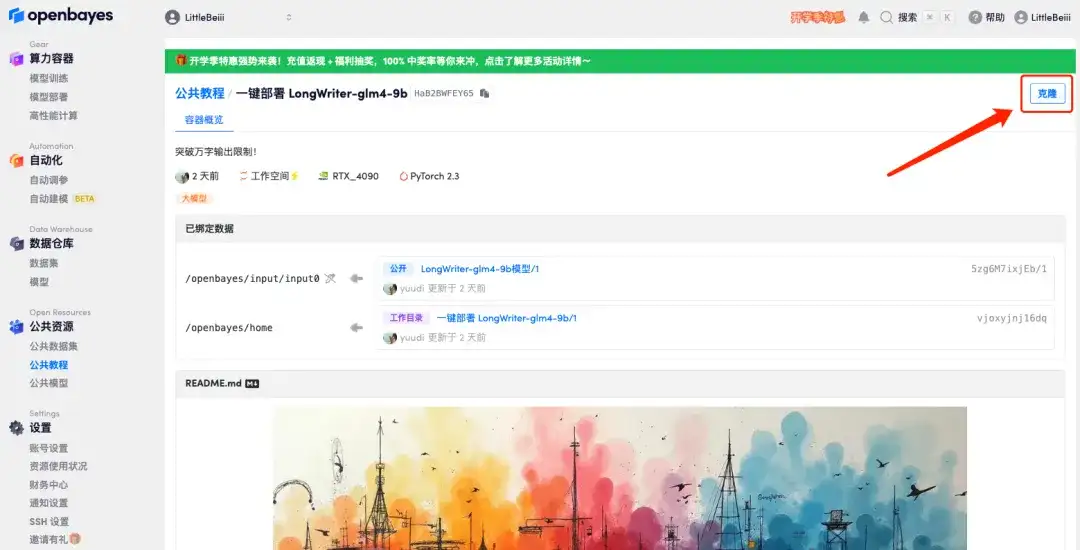
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
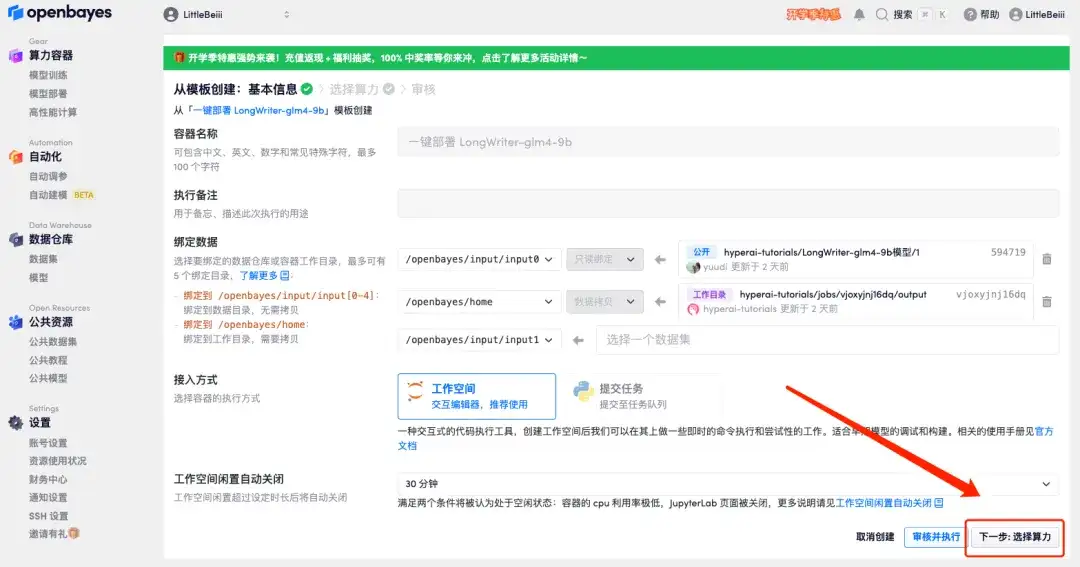
3. 오른쪽 하단에 있는 "다음: 해시레이트 선택"을 클릭합니다.
4. 페이지가 이동한 후 "NVIDIA RTX 4090"과 "PyTorch" 이미지를 선택하고 "다음: 검토"를 클릭합니다.신규 사용자는 아래 초대 링크를 사용하여 등록하고 RTX 4090 4시간 + CPU 자유 시간 5시간을 받으세요!
HyperAI 독점 초대 링크(복사하여 브라우저에서 열기):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
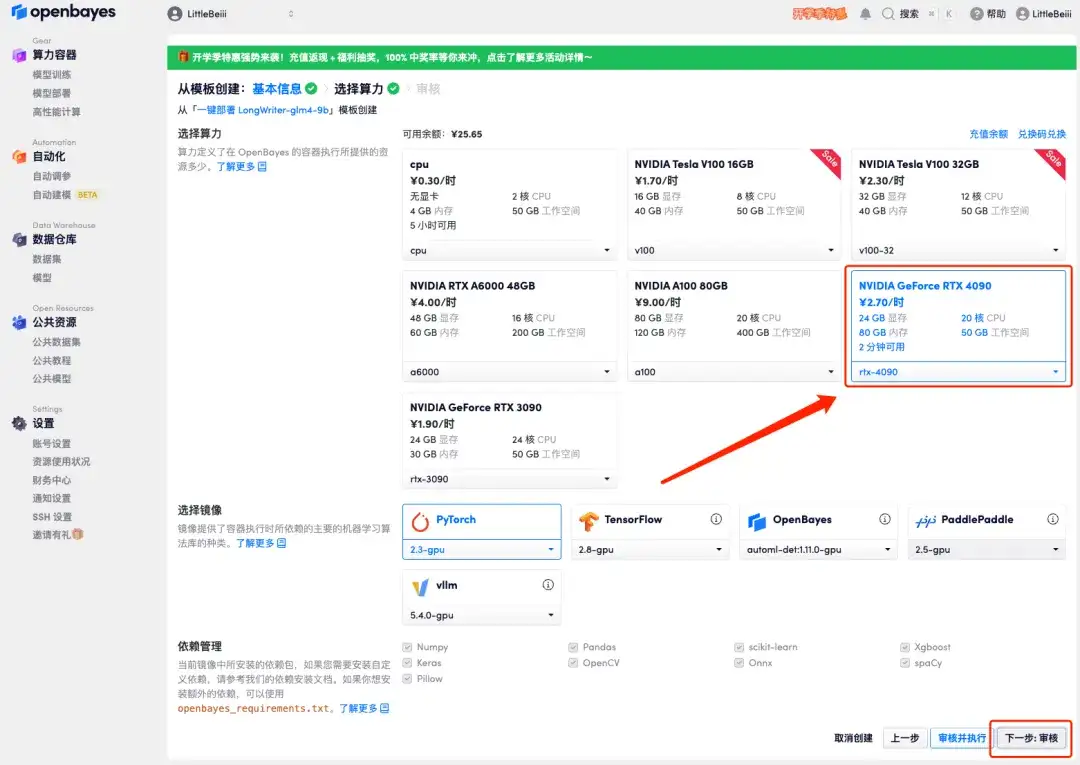
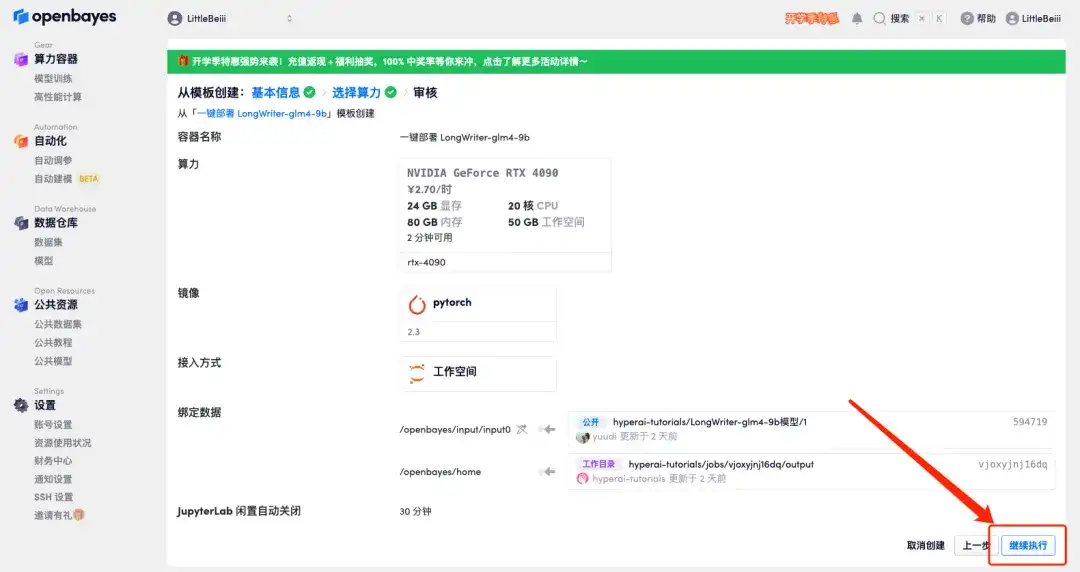
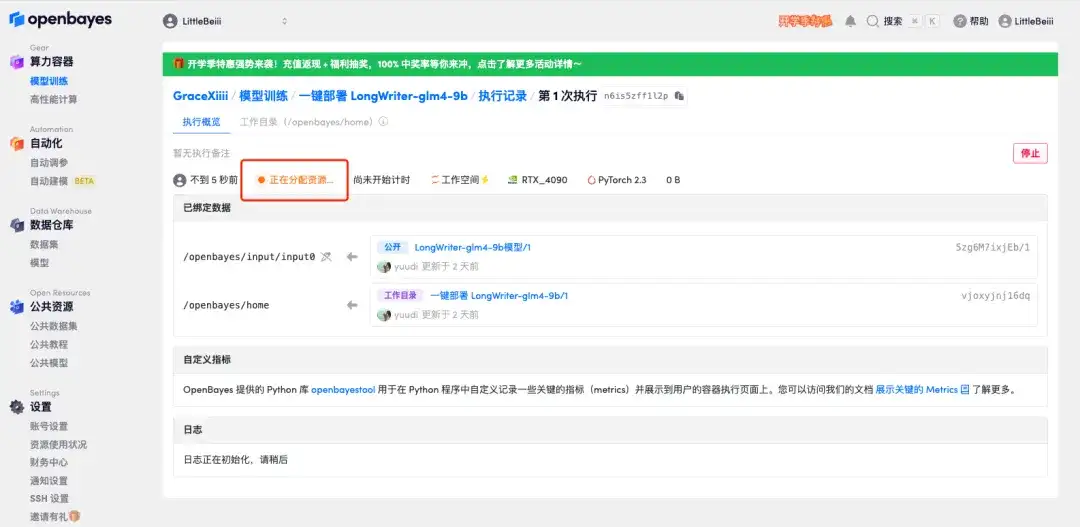
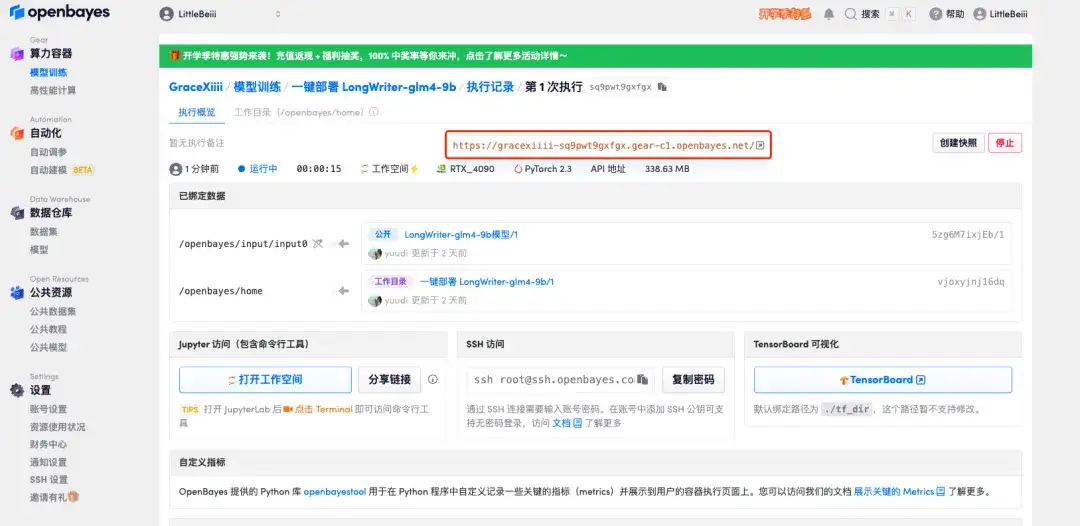
5. 확인 후 "계속"을 클릭하고 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 과정은 약 2분 정도 걸립니다. 상태가 "실행 중"으로 변경되면 "API 주소" 옆에 있는 점프 화살표를 클릭하여 데모 페이지로 이동합니다.API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.
효과 미리보기
1. 데모 인터페이스를 열고 10,000단어 분량의 서스펜스 소설을 생성해 보세요.
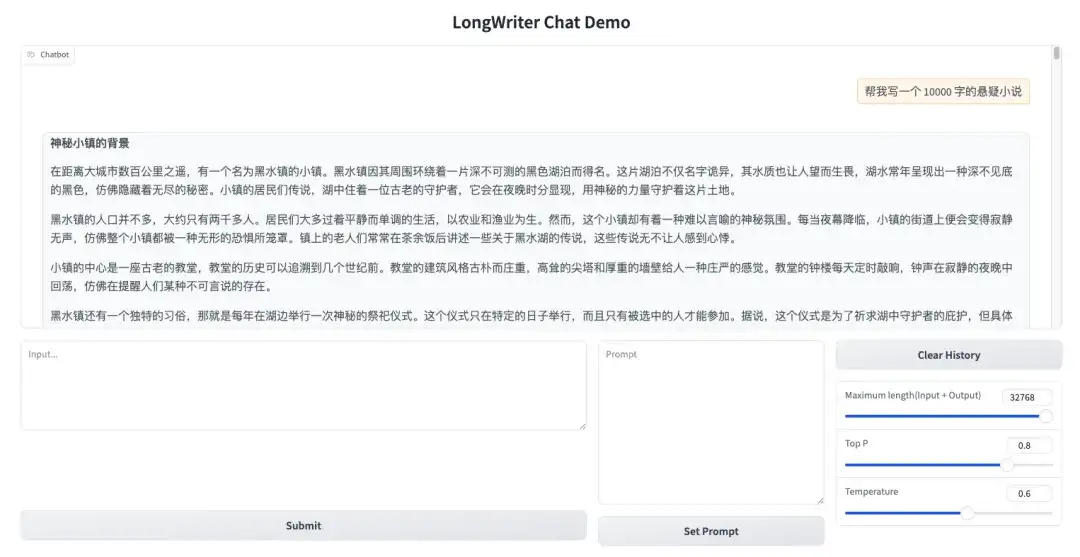
2. 긴 서스펜스 소설이 빠르게 출력되는 것을 볼 수 있습니다.