Command Palette
Search for a command to run...
가장 큰 비디오 분할 데이터 세트인 Meta를 한 번의 클릭으로 다운로드하세요! 47개국을 아우르는 50.9K개의 실제 영상이 포함되어 있습니다.

2023년 4월, Meta는 "모든 것을 세분화"할 수 있다고 주장하며 SAM(Segment Anything Model)을 출시했습니다. 기존의 컴퓨터 비전(CV) 작업을 뒤집는 이 혁신적인 성과는 업계에서 폭넓은 논의를 불러일으켰으며 의료 영상 분할과 같은 수직 분야 연구에 빠르게 적용되었습니다. 최근 SAM이 다시 업그레이드되었습니다.메타 오픈 소스 Segment Anything Model 2(SAM 2)는 컴퓨터 비전 분야에서 또 다른 획기적인 이정표를 세웠습니다.
이미지 분할부터 비디오 분할까지,SAM 2는 실시간 큐 분할에서 뛰어난 성능을 보여줍니다.이 모델은 이미지와 비디오의 세분화 및 추적 기능을 통합된 모델로 도입합니다. 비디오 프레임에 프롬프트(클릭, 상자 또는 마스크)를 입력하기만 하면 이미지나 비디오 속의 모든 객체를 정확하게 식별하고 세분화할 수 있습니다. 이 독특한 제로 샘플 학습 기능은 SAM 2에 매우 높은 다용성을 제공합니다.이 기술은 의학, 원격 감지, 자율 주행, 로봇 공학, 위장 물체 감지 등의 분야에서 뛰어난 응용 잠재력을 보여줍니다. Meta는 "우리의 데이터, 모델, 통찰력이 비디오 세분화 및 관련 인식 작업에서 중요한 이정표가 될 것이라고 믿습니다!"라고 확신합니다.
그것은 사실입니다. SAM 2가 출시되자마자 모두가 사용하기를 고대했고, 그 효과는 믿을 수 없었습니다!

SAM 2가 오픈 소스로 공개된 지 2주도 채 되지 않아 토론토 대학의 연구진이 이를 의료 이미지와 비디오에 사용하여 논문을 발표했습니다!

원본 논문:
https://arxiv.org/abs/2408.03322
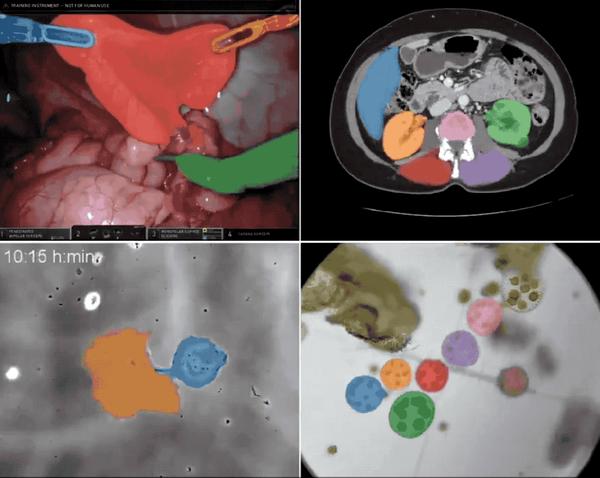
모델을 학습시키려면 데이터가 필요하며 SAM 2도 예외는 아닙니다. 동시에 Meta는 SAM 2를 훈련하는 데 사용된 대규모 데이터 세트 SA-V를 오픈 소스로 공개했습니다.이 데이터 세트는 일반 객체 분할 모델을 훈련, 테스트, 평가하는 데 사용될 수 있다고 합니다.HyperAI는 공식 웹사이트에 "SA-V: Meta Building the Largest Video Segmentation Dataset"을 출시했습니다. 클릭 한 번으로 다운로드할 수 있습니다!
SA-V 비디오 분할 데이터 세트 직접 다운로드:
https://go.hyper.ai/e1Tth
더 많은 고품질 데이터 세트를 다운로드하세요:
https://go.hyper.ai/P5Mtc
기존의 비디오 분할 데이터 세트를 넘어선다! SA-V는 다양한 주제와 시나리오를 다룹니다.
메타 연구원들은 다음 표에 표시된 것처럼 Data Engine을 사용하여 대규모의 다양한 비디오 분할 데이터 세트 SA-V를 수집했습니다.데이터 세트에는 50.9K개의 비디오, 642.6K개의 마스크릿(191K는 SAM 2의 도움으로 수동으로 주석 처리, 452K는 SAM 2에서 자동으로 생성)이 포함되어 있습니다.다른 일반적인 비디오 객체 분할(VOS) 데이터 세트와 비교했을 때 SA-V는 비디오, 마스크릿, 마스크의 수를 크게 개선했습니다.주석이 달린 마스크의 수는 기존 VOS 데이터 세트의 53배입니다.이는 미래의 컴퓨터 비전 작업을 위한 풍부한 데이터 리소스를 제공합니다.
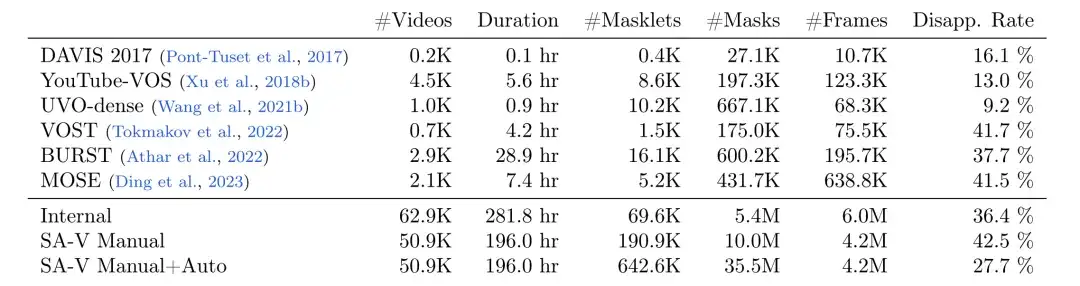
마스크 조각 수, 마스크 수, 프레임 수, 소멸률 비교
* SA-V 매뉴얼에는 수동으로 주석이 달린 라벨만 포함되어 있습니다.
* SA-V Manual+Auto는 수동으로 주석이 달린 레이블과 자동으로 생성된 마스크 세그먼트를 결합합니다.
SA-V에 포함된 비디오의 수는 기존 VOS 데이터 세트보다 많은 것으로 알려졌으며, 평균 비디오 해상도는 1401×1037픽셀입니다.수집된 영상에는 다양한 일상 풍경이 담겨 있습니다.평균 길이가 14초인 실내 장면 영상 54%와 실외 장면 영상 46%가 포함되어 있습니다. 또한,이 영상의 주제도 다양합니다.마스크는 위치, 사물, 장면 등을 포함하며, 큰 사물(예: 건물)부터 세부적인 세부 사항(예: 실내 장식)까지 다양합니다.
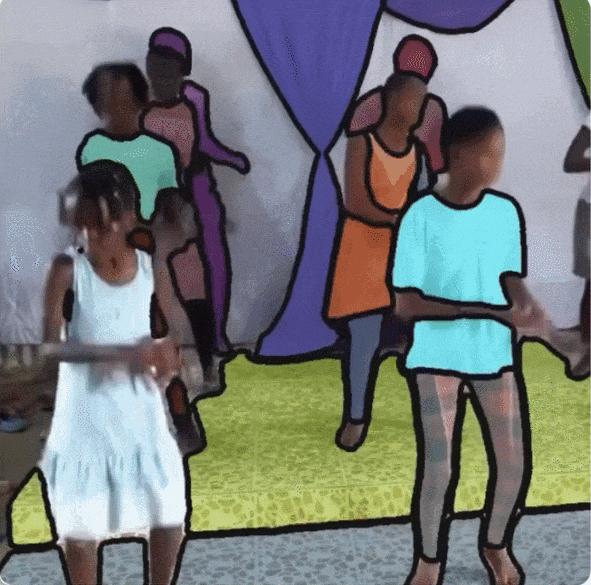
아래 그림과 같이,SA-V 영상은 47개국을 다룹니다.그리고 다양한 참여자들의 결과를 보면, 그림 a에서 볼 수 있듯이, DAVIS, MOSE, YouTubeVOS의 마스크 크기 분포와 비교했을 때, SA-V가 0.1 미만인 정규화된 마스크 영역(normalized mask area)은 88%를 초과합니다.
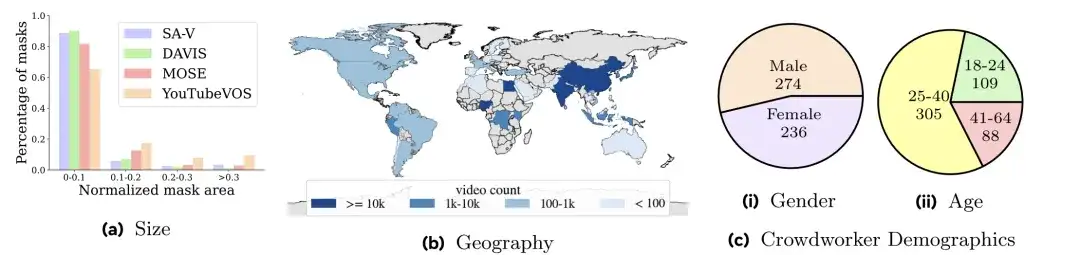
연구자들은 비디오 작성자와 그들의 지리적 위치를 기준으로 SA-V 데이터 세트를 나누었습니다.데이터 내의 유사한 객체가 최소한으로 중복되도록 합니다.SA-V 검증 및 SA-V 테스트 세트를 만들기 위해 연구진은 비디오를 선택할 때 까다로운 장면에 초점을 맞춰 주석 작성자가 빠르게 움직이는 객체, 다른 객체에 의해 가려진 객체 또는 사라지거나 다시 나타나는 패턴을 보이는 객체를 식별하도록 요구했습니다. 마지막으로, SA-V 검증 세트에는 293개의 마스크릿과 155개의 비디오가 있고, SA-V 테스트 세트에는 278개의 마스크릿과 150개의 비디오가 있습니다. 또한 연구진은 내부적으로 사용 가능한 라이선스 비디오 데이터를 사용하여 훈련 세트를 더욱 강화했습니다.
SA-V 비디오 분할 데이터 세트 직접 다운로드:
https://go.hyper.ai/e1Tth
위의 내용은 이번 호에서 HyperAI가 추천하는 데이터 세트입니다. 고품질 데이터세트 리소스를 보셨다면 메시지를 남기시거나 기사를 제출해 알려주세요!
더 많은 고품질 데이터 세트를 다운로드하세요:
https://go.hyper.ai/P5Mtc