Command Palette
Search for a command to run...
ACL 2024에 선정되었습니다! 단백질 데이터와 텍스트 정보의 교차 모달 해석을 달성하기 위해 USTC의 Wang Xiang 팀은 단백질 텍스트 생성 프레임워크 ProtT3를 제안했습니다.

단백질의 역동적 구조에 대한 신비를 탐구하는 것은 새로운 약물 개발을 촉진하는 데 중요한 단계일 뿐만 아니라, 생명 과정을 이해하는 데 중요한 초석이기도 합니다. 그러나 단백질의 복잡성으로 인해 심층적인 구조 정보를 직접 포착하고 분석하는 것은 어렵습니다. 복잡한 생물학적 데이터를 직관적이고 이해하기 쉬운 표현으로 변환하는 방법은 과학 연구 분야에서 늘 주요 과제였습니다.
언어 모델(LM)의 급속한 발전과 함께 혁신적인 아이디어가 탄생했습니다.언어 모델은 방대한 양의 데이터로부터 텍스트 정보를 학습하고 추출할 수 있으므로, 단백질 데이터로부터 단백질 정보를 "읽어내는" 법을 학습하고 동적 단백질 구조 정보를 사람이 이해하기 쉬운 텍스트 설명으로 직접 변환할 수 있을까요?
이 유망한 아이디어는 실제 적용에서 많은 어려움에 부딪혔습니다. 예를 들어, 언어 모델은 단백질 시퀀스의 텍스트 코퍼스에 대해 사전 학습됩니다. 강력한 텍스트 처리 능력을 가지고 있지만, 단백질 구조의 비인간적인 "언어"를 이해할 수 없습니다. 이와 대조적으로, 단백질 언어 모델(PLM)은 단백질 서열 코퍼스에 대해 사전 학습되었으며 뛰어난 단백질 이해 및 생성 기능을 갖추고 있습니다.하지만 이 솔루션에도 마찬가지로 중요한 한계가 있습니다. 바로 텍스트 처리 기능이 부족하다는 것입니다.
PLM과 LM의 장점을 결합하여 단백질 구조를 깊이 이해할 수 있을 뿐만 아니라 텍스트 정보를 완벽하게 연결할 수 있는 새로운 모델 아키텍처를 구축할 수 있다면 약물 개발, 단백질 특성 예측, 분자 설계 및 기타 분야에 큰 영향을 미칠 것입니다. 하지만,단백질 구조와 인간 언어 텍스트는 서로 다른 데이터 양식에 속하며, 그 장벽을 깨고 통합하는 것은 쉽지 않습니다.
이와 관련하여,중국 과학기술대학의 왕샹은 싱가포르 국립대학의 류즈위안 팀과 홋카이도 대학의 연구팀과 함께 새로운 단백질-텍스트 모델링 프레임워크인 ProtT3를 제안했습니다.이 프레임워크는 모달리티 차이가 있는 PLM과 LM을 크로스 모달 프로젝터를 통해 결합합니다. 여기서 PLM은 단백질 이해에 사용되고 LM은 텍스트 처리에 사용됩니다. 효율적인 미세 조정을 달성하기 위해 연구진은 LoRA를 LM에 통합하여 단백질-텍스트 생성 프로세스를 효과적으로 조절했습니다.
또한 연구자들은 단백질 캡션, 단백질 질의응답(단백질 QA), 단백질 텍스트 검색을 포함한 단백질 텍스트 모델링 과제에 대한 양적 평가 과제도 수립했습니다. ProtT3는 세 가지 작업 모두에서 뛰어난 성과를 달성했습니다.
"ProtT3: 텍스트 기반 단백질 이해를 위한 단백질-텍스트 생성"이라는 제목의 연구가 ACL 2024 최고 학회에 선정되었습니다.
연구 하이라이트:
* ProtT3 프레임워크는 텍스트와 단백질 간의 모달리티 격차를 해소하고 단백질 서열 분석의 정확도를 향상시킬 수 있습니다.
* 단백질 캡션 작업에서 Swiss-Prot 및 ProteinKG25 데이터 세트에 대한 ProtT3의 BLEU-2 점수는 기준선보다 10포인트 이상 높습니다.
* 단백질 질의응답 과제에서 ProtT3의 PDB-QA 데이터세트에 대한 정확한 일치 성능은 2.5%만큼 향상되었습니다.
* 단백질 텍스트 검색 작업에서 ProtT3의 Swiss-Prot 및 ProteinKG25 데이터 세트에 대한 검색 정확도는 기준선보다 14% 이상 높습니다.
서류 주소:
https://arxiv.org/abs/2405.12564
데이터세트 다운로드 주소:
https://go.hyper.ai/j0wvp
오픈소스 프로젝트인 "awesome-ai4s"는 100개가 넘는 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
단백질 연구를 위한 3대 주요 데이터 세트 구축 및 최적화
연구진은 Swiss-Prot, ProteinKG25, PDB-QA의 세 가지 데이터 세트를 선택했습니다.
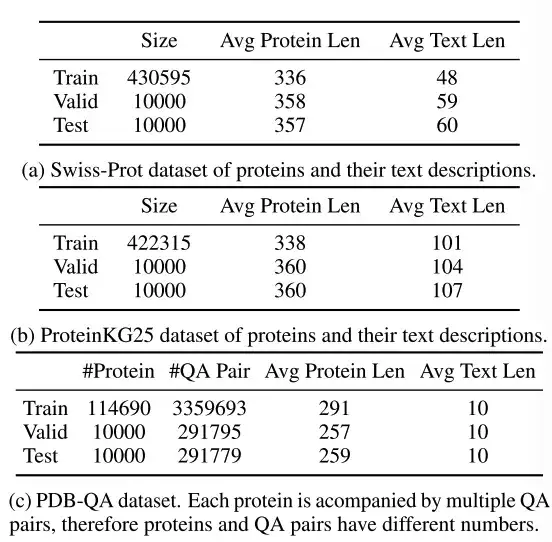
위의 표에서 보여지는 바와 같이,Swiss-Prot는 텍스트 주석이 있는 단백질 서열 데이터베이스입니다.연구자들은 데이터 세트를 처리하고 정보 유출을 막기 위해 텍스트 주석에서 단백질 이름을 제외했습니다. 생성된 텍스트 설명은 단백질 기능, 위치, 계열에 대한 주석을 연결합니다.
ProteinKG25는 Gene Ontology 데이터베이스에서 파생된 지식 그래프입니다.연구진은 먼저 같은 단백질의 세쌍을 모은 다음, 단백질 정보를 미리 정의된 텍스트 템플릿에 입력하여 세쌍을 자유 텍스트로 변환했습니다.
PDB-QA는 RCSB PDB2에서 파생된 단백질 단일 턴 질의응답 데이터 세트입니다.단백질 구조, 특성 및 추가 정보에 대한 30개의 질문 템플릿이 포함되어 있습니다. 아래 표에서 보듯이, 연구자들은 보다 세부적인 평가를 위해 답변의 형식(문자열 또는 숫자)과 내용의 초점(구조/속성 또는 보충 정보)을 기준으로 질문을 네 가지 범주로 나누었습니다.

ProtT3: 혁신적인 단백질-텍스트 생성 모델 아키텍처
아래 그림 a에서 보는 바와 같이,ProtT3는 단백질 언어 모델(PLM), 크로스 모달 프로젝터(Cross-ModalProjector), 언어 모델(LM) 및 LoRA 모듈로 구성됩니다.단백질-텍스트 생성 프로세스를 효과적으로 조절합니다.
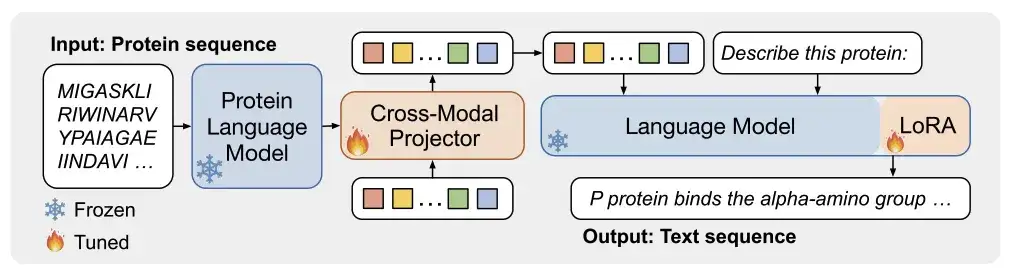
이 중 연구진이 선정한 단백질 언어 모델은 단백질 이해에 사용되는 ESM-2150M이다. 선택된 크로스 모달 프로젝터는 Q-Former로, PLM과 언어 모델 LM 간의 모달 차이를 연결하고 단백질 표현을 LM의 텍스트 공간에 매핑하는 데 사용됩니다. 선택된 언어 모델은 텍스트 처리에 사용되는 Galactica1.3B입니다. 연구진은 하위 적응의 효율성을 유지하기 위해 언어 모델에 LoRA를 통합하여 효율적인 미세 조정을 달성했습니다.
그림 b에 나타낸 바와 같이,ProtT3는 두 가지 학습 단계를 사용하여 단백질 텍스트의 효과적인 모델링을 강화합니다.이는 단백질-텍스트 검색 훈련과 단백질-텍스트 생성 훈련입니다.
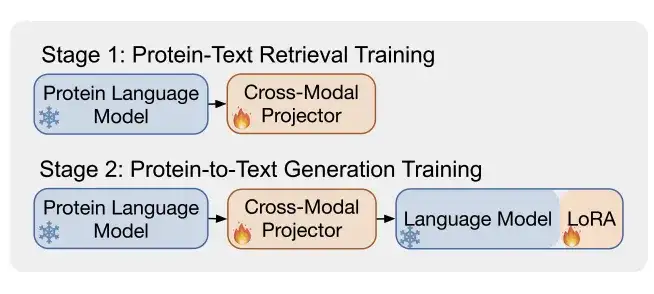
* 1단계: 단백질 텍스트 검색 훈련
아래 그림 a에 표시된 것처럼, 크로스 모달 프로젝터 Q-Former는 단백질 인코딩을 위한 단백질 변환기와 텍스트 처리를 위한 텍스트 변환기라는 두 개의 변환기로 구성됩니다. 두 변환기는 자기 주의를 공유하여 단백질과 텍스트 간의 상호작용을 가능하게 합니다.
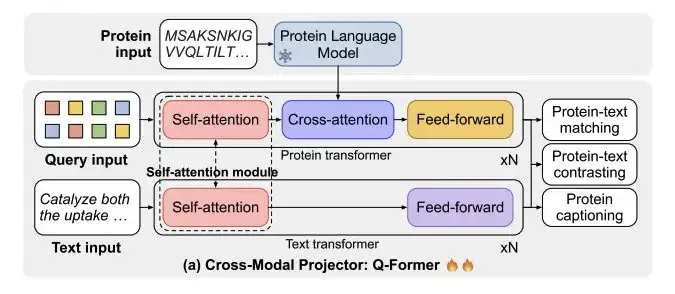
연구진은 Swiss-Prot와 ProteinKG25를 결합한 데이터 세트를 사용하여 ProtT3를 훈련시켜 단백질 텍스트 검색을 수행했습니다.여기에는 단백질-텍스트 대조, 단백질-텍스트 매칭(PTM), 단백질 캡션 작성(PCap)의 세 가지 작업이 포함됩니다.
* 2단계: 단백질-텍스트 생성 훈련
연구자들은 크로스 모달 프로젝터를 언어 모델(LM)에 연결하고 단백질 표현 Z를 LM에 입력하여 단백질 정보에 따라 텍스트 생성 프로세스를 조건화했습니다. 연구진은 선형 레이어를 사용하여 Z를 언어 모델 입력과 동일한 차원으로 투영하고, 생성된 각 데이터 세트에 대해 ProtT3를 별도로 훈련하고, 단백질 표현 뒤에 다른 텍스트 프롬프트를 추가하여 생성 프로세스를 추가로 제어했습니다.
또한 연구진은 LoRA를 도입하여 단백질-텍스트 생성 작업에 대한 3개 데이터세트에 대해 개별적으로 미세 조정을 실시했습니다.
단백질 분야의 올라운더로서 3가지 주요 과제에서 ProtT3의 성능을 평가합니다.
ProtT3의 성능을 평가하려면연구진은 단백질 캡션 작성, 단백질 QA, 단백질 텍스트 검색의 세 가지 작업에서 시스템을 테스트했습니다.
단백질에 대한 정확한 설명에 더 가까운 ProtT3는 더 높은 정확도를 가지고 있습니다.
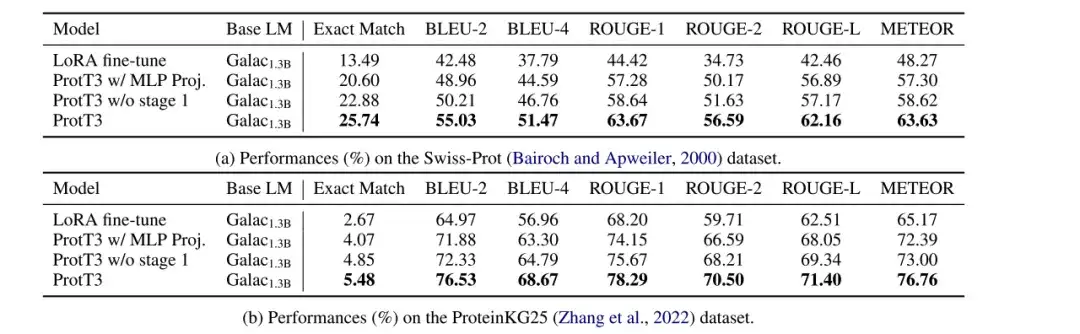
연구진은 Swiss-Prot 및 ProteinKG25 데이터 세트에서 단백질 캡션 작업에서 LoRA 미세 조정 Galactica1.3B, ProtT3 w/ MLP Proj., ProtT3 w/o stage 1 및 ProtT3 모델의 성능을 평가했으며, BLEU, ROUGE 및 METEOR를 평가 지표로 사용했습니다.
* MLP Proj.가 포함된 ProtT3: MLP를 사용하는 ProtT3의 크로스 모달 프로젝터를 대체하는 ProtT3의 변형입니다.
* 1단계 없는 ProtT3: ProtT3의 훈련 1단계를 건너뛰는 ProtT3의 변형
아래 그림과 같이 LoRA 미세조정된 Galactica1.3B와 비교해보면,ProtT3는 BLEU-2 점수를 10포인트 이상 향상시킵니다.단백질 언어 모델을 도입하는 것의 중요성과 단백질 입력을 이해하는 데 있어 ProtT3가 얼마나 효과적인지가 직관적으로 입증되었습니다. 게다가 ProtT3는 다른 측정 항목에서 두 가지 변형보다 우수한 성능을 보이는데, 이는 Q-Former 프로젝터와 1단계 학습을 사용하는 이점이 있음을 보여줍니다.
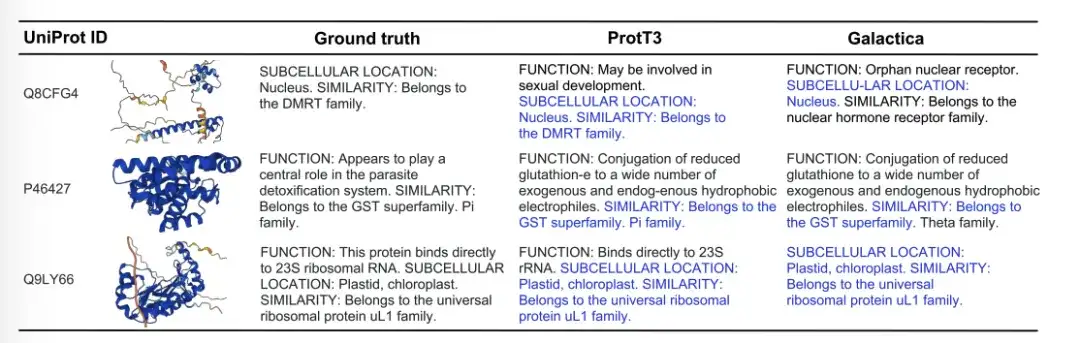
아래 그림은 Ground truth, ProtT3, Galactica의 세 가지 단백질 자막 생성 예를 보여줍니다. Q8CFG4 예에서 ProtT3의 주석 내용은 DMRT 패밀리를 더 정확하게 식별했지만 Galactica는 그렇지 않았습니다. P46427의 경우, 두 모델 모두 단백질의 기능을 파악하지 못했지만, ProtT3는 단백질 계열을 더 정확하게 예측했습니다. Q9LY66의 경우, 두 모델 모두 세포 내 위치와 단백질 계열을 성공적으로 예측했습니다. ProtT3는 단백질의 기능을 예측하는 데 한 걸음 더 나아가 실제 설명에 더 가깝습니다.
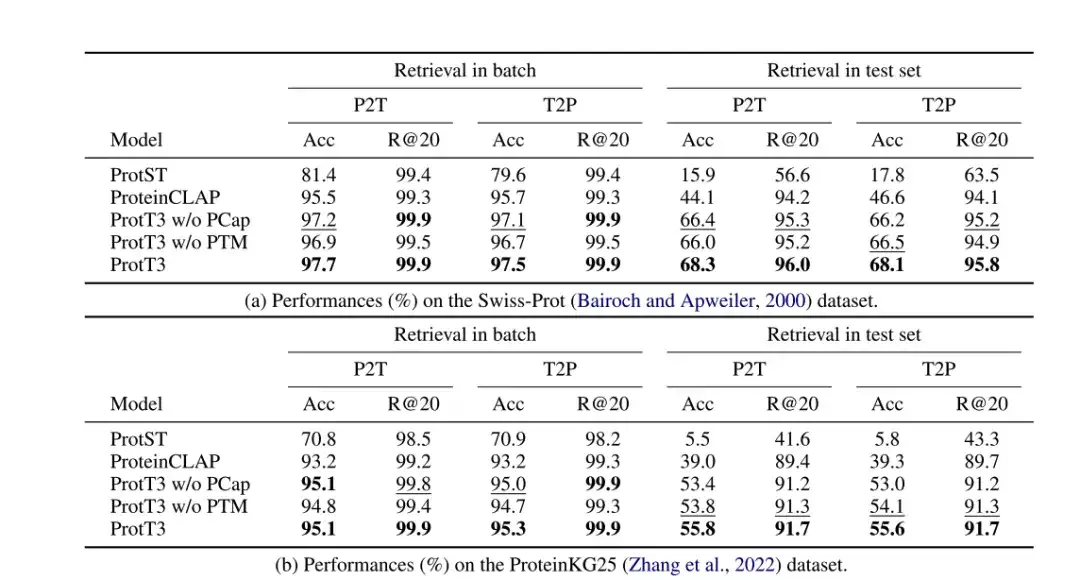
정확도는 기준 모델보다 141% 더 높습니다. TP3T, ProtT3는 단백질 텍스트 검색 능력이 더 뛰어납니다.
연구진은 정확도와 Recall@20을 평가 지표로 사용하여 Swiss-Prot와 ProteinKG25 데이터 세트에서 단백질 텍스트 검색에 있어 ProtT3의 성능을 평가했으며, ProtST와 ProteinCLAP을 기준 모델로 채택했습니다.
다음 표에서 보는 바와 같이,ProtT3의 정확도는 기준 모델보다 14% 이상 높습니다.이는 ProtT3가 단백질을 해당 텍스트 설명에 맞춰 정렬하는 데 더 뛰어나다는 것을 시사합니다. 또한,단백질-텍스트 매칭(PTM)은 ProtT3의 정확도를 1%-2%만큼 향상시켰습니다.PTM은 단백질과 텍스트 정보가 Q-Former의 초기 계층에서 상호 작용할 수 있도록 하여 더욱 세부적인 단백질-텍스트 유사성 측정을 달성하기 때문입니다.단백질 캡션링(PCap)은 ProtT3의 검색 정확도를 약 2%만큼 향상시킵니다.PCap은 텍스트 입력과 가장 관련성이 높은 단백질 정보를 추출하기 위해 쿼리 토큰을 장려하여 단백질-텍스트 정렬에 도움이 되기 때문입니다.
* PTM이 없는 ProtT3: ProtT3의 PTM 단계를 건너뜁니다.
* PCap이 없는 ProtT3: ProtT3의 PCap 단계를 건너뜁니다.
ProtT3는 단백질 구조와 특성을 예측할 수 있으며, 더 나은 질의응답 기능을 갖추고 있습니다.
연구진은 PDB-QA 데이터 세트에서 ProtT3의 단백질 질의응답 성능을 평가했으며, 정확한 일치를 평가 지표로 선택하고 LoRA에 의해 미세 조정된 Galactica1.3B를 기준 모델(LoRA ft)로 사용했습니다.
아래 그림과 같이,ProtT3의 정확한 일치 성능은 기준 TP3T보다 2.51 더 높습니다.ProtT3는 단백질 구조와 특성을 예측하는 데 있어 기준선을 지속적으로 능가하는 성능을 보였으며, 이는 ProtT3가 단백질과 텍스트 질문을 이해하는 데 있어 뛰어난 다중 모드 역량을 가지고 있음을 보여줍니다.
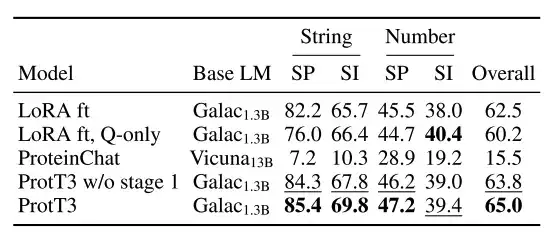
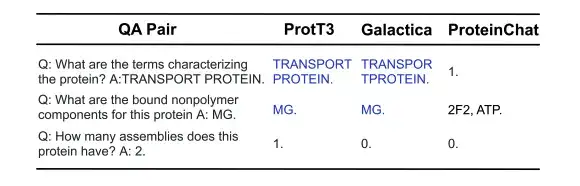
아래 그림에서 보듯이, 다음의 3가지 단백질 질의응답 예시에서 ProtT3와 Galactica는 둘 다 단백질 특성/구조에 관한 처음 두 질문에는 올바르게 답했지만, 숫자로 답해야 하는 세 번째 질문에는 실패했습니다. ProteinChat은 3개 질문 모두에 어려움을 겪었고, 그 중 어떤 질문에도 답변할 수 없었습니다.
단백질 언어의 잠금 해제, 생명 과학 분야에서 LLM의 최첨단 탐구
단백질을 텍스트로 변환하는 분야에 대한 연구자들의 탐구를 통해 인간은 복잡한 생물학적 현상을 인간이 이해할 수 있는 방식으로 밝혀낼 수 있게 되었습니다. 위 연구의 언어 모델은 단백질의 "잠재 공간"에 대한 심층적인 이해를 보여줄 뿐만 아니라, 생물학적 과제와 자연어 처리 사이의 다리 역할을 하여 약물 개발 및 단백질 기능 예측과 같은 연구에 새로운 길을 열어줍니다. 더 나아가,수십억 개 이상의 매개변수를 가진 대규모 언어 모델을 사용하여 더욱 복잡한 언어 구조를 처리한다면, 향후 생명 과학에 대한 탐구가 여러 수준에서 향상될 것으로 기대됩니다.
예를 들어,저장대학의 장창(Zhang Qiang)과 천화준(Chen Huajun)이 이끄는 팀은 InstructProtein이라는 혁신적인 대규모 언어 모델을 제안했습니다.이 모델은 인간 언어와 단백질 언어를 양방향으로 생성할 수 있는 기능을 가지고 있습니다: (i) 단백질 서열을 입력으로 받아 해당 단백질 서열의 텍스트 기능 설명을 예측합니다. (ii) 자연어를 사용하여 단백질 서열 생성을 촉진합니다.

구체적으로 연구진은 단백질과 자연어 코퍼스에 대한 LLM을 사전 훈련한 다음, 두 가지 다른 언어의 정렬을 용이하게 하기 위해 지도 학습 튜닝을 채택했습니다. InstructProtein은 다수의 양방향 단백질 텍스트 생성 작업에서 좋은 성능을 보입니다. 이 기술은 텍스트 기반 단백질 기능 예측 및 서열 설계 분야에서 선구적인 진전을 이루었으며, 단백질과 인간 언어 이해 간의 격차를 효과적으로 줄였습니다.
"InstructProtein: 지식 교육을 통해 인간과 단백질 언어 정렬"이라는 제목의 논문이 ACL 2024에 선정되었습니다.
* 원본 논문:https://arxiv.org/pdf/2310.03269
또한,시드니 공과대학교 팀은 또한 저장대학교 연구팀과 힘을 합쳐 대규모 언어 모델인 ProtChatGPT를 공동으로 출시했습니다.이 모델은 단백질 구조를 학습하고 이해하여 사용자가 단백질 관련 질문을 업로드하고 대화형 대화에 참여하여 궁극적으로 포괄적인 답변을 생성할 수 있도록 합니다.
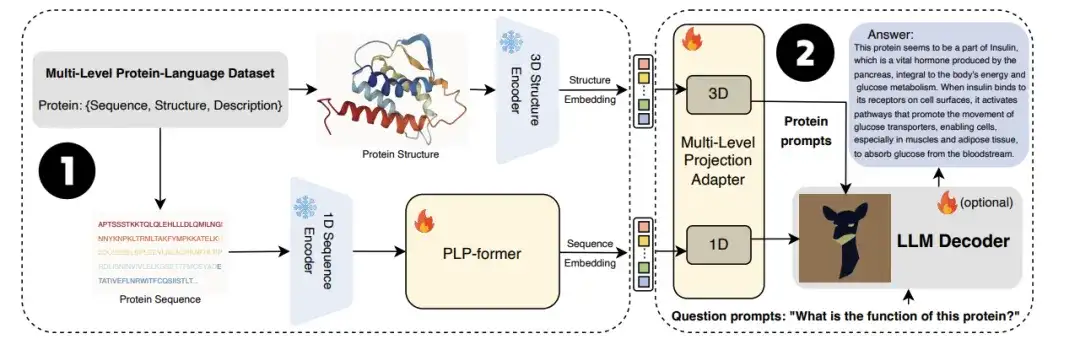
구체적으로, 단백질은 먼저 단백질 인코더와 단백질 언어 사전 학습 변환기(PLP-former)를 통과하여 단백질 임베딩을 생성한 다음, 이러한 임베딩은 Projection Adapter를 통해 LLM에 투영됩니다. 마지막으로 LLM은 사용자 질문과 프로젝션 임베딩을 결합하여 유익한 답변을 생성합니다. 실험 결과, ProtChatGPT는 단백질과 그에 따른 질문에 대한 전문적인 답변을 생성할 수 있으며, 단백질 연구의 심층적 탐구와 응용 확장에 새로운 활력을 불어넣을 수 있음이 밝혀졌습니다.
* 원본 논문:https://arxiv.org/abs/2402.09649
미래에는 대규모 언어 모델이 방대한 양의 풍부한 데이터를 사용하여 인간 인지의 한계를 훨씬 뛰어넘는 단백질의 기본 법칙이나 심층 구조를 추론할 수 있게 되면서 그 잠재력이 크게 발휘될 것입니다. 우리는 기술의 지속적인 발전으로 대규모 언어 모델이 단백질 연구를 더욱 밝은 미래로 이끌 것으로 기대합니다.