Command Palette
Search for a command to run...
Llama 3.1 중국어 미세 조정 데이터 세트가 이제 온라인에 있으며, 대규모 모델을 한 번의 클릭으로 배포할 수 있습니다.

7월의 AI 서클은 작은 모델과 큰 모델이 가득했고, 흥미진진했습니다! 대부분의 학생들은 GPT-4o나 미스트랄-네모와 같은 작은 모형을 체험할 수 있지만, 라마-3.1-405B나 미스트랄-라지-2와 같은 초대형 모형은 많은 학생들에게 어려움을 줍니다.
괜찮아요!hyper.ai 공식 웹사이트의 튜토리얼 섹션에서는 "Open WebUI"와 "OpenAI 호환 API 서비스"를 사용하여 이 두 가지 초대형 모델을 시작하는 방법에 대한 튜토리얼을 제공합니다!또한, 중국 미세조정 데이터 세트인 DPO-zh-en-emoji도 온라인에 있습니다. 아래로 스크롤하여 링크를 받으세요~
8월 5일부터 8월 9일까지 hyper.ai 공식 웹사이트가 업데이트되었습니다.
* 고품질 튜토리얼 선택: 5개
* 고품질 공개 데이터 세트: 10
* 커뮤니티 게시물 선정 : 3개 게시물
* 인기 백과사전 항목: 5개
* 8월 마감일 상위 컨퍼런스: 2
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 튜토리얼
1. Open WebUI를 사용하여 Mistral Large 2 / Llama 3.1 405B를 한 번의 클릭으로 배포합니다.
이 튜토리얼에서는 OpenWebUI를 사용하여 Mistral Large 2 / Llama 3.1 405B를 한 번의 클릭으로 배포합니다. 관련 환경과 구성이 설정되었습니다. 추론을 경험하려면 컨테이너를 복제하고 시작하기만 하면 됩니다.
* Mistral Large 2 모델 배포를 온라인으로 실행하세요:
* Llama 3.1 405B 모델 배포를 온라인으로 실행하세요:
2. Mistral Large 2 / Llama 3.1 405B 모델 OpenAI 호환 API 서비스의 원클릭 배포
이 튜토리얼은 OpenAI 호환 API를 사용하여 Mistral-Large-Instruct-2407-AWQ를 배포하는 방법입니다. "OpenAI 호환 API"는 타사 개발자가 OpenAI와 동일한 요청 및 응답 형식을 사용하여 유사한 기능을 자체 애플리케이션에 통합할 수 있음을 의미합니다. 이 튜토리얼을 시작하면 모든 OpenAI 호환 SDK에서 이 모델에 연결할 수 있습니다. 이전 튜토리얼과 비교하면 더 복잡하고 프로그래밍에 대한 기본적인 이해가 있는 사람에게 적합합니다.
* Mistral Large 2 모델 배포를 온라인으로 실행하세요:
* Llama 3.1 405B 모델 배포를 온라인으로 실행하세요:
3. Gibbs-Diffusion을 사용하여 블라인드 이미지 노이즈 제거
GDiff는 Gibbs-Diffusion의 약자로, 신호 및 잡음 매개변수의 사후 샘플링 문제를 해결하는 베이지안 블라인드 잡음 제거 방법입니다. 이 튜토리얼은 "소음 듣기: Gibbs Diffusion을 이용한 맹목적인 잡음 제거" 논문을 기반으로 한 테스트 방법입니다. 튜토리얼 단계를 따라가면 연구 결과를 체험할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/y2wIU
선택된 공개 데이터 세트
1. DPO-zh-en-emoji 이모티콘 질의응답 데이터세트
이 데이터 세트는 대규모 언어 모델을 미세 조정하기 위해 설계되었습니다. 여기에는 많은 양의 질문-답변 쌍이 포함되어 있습니다. 각 질문에는 중국어와 영어 두 가지 버전의 답변이 있습니다. 답변에는 이모티콘을 포함한 재미있고 유머러스한 요소도 포함되어 있습니다. shareAI 팀은 이를 사용하여 Llama 3.1 8B 모델을 미세 조정했습니다.
직접 사용:https://go.hyper.ai/Y90pZ
2. UrbanSARFloods v1 홍수 매핑 벤치마크 데이터 세트
UrbanSARFloods는 도시와 개방 지역 홍수 매핑에 전념하는 데이터 세트로, 8,879개의 512×512 이미지 패치를 포함하고 있으며, 807,500제곱킬로미터를 포괄하고 18개의 홍수 사건을 다룹니다. 이를 통해 기존 대규모 SAR 기반 홍수 매핑 연구에서 도시 홍수에 대한 관심이 부족했던 문제가 해결되었습니다.
직접 사용:https://go.hyper.ai/yOXx7
3. VRSBench 대규모 고품질 원격 감지 시각 언어 벤치마크 데이터 세트
이 데이터 세트는 원격 감지 이미지 이해를 위해 설계된 다목적 시각 언어 벤치마크 데이터 세트입니다. 여기에는 수동으로 검증된 자세한 캡션이 달린 이미지 29,614개, 객체 참조 52,472개, 질문-답변 쌍 123,221개가 포함되어 있습니다. 이 연구의 목적은 일반적이고 대규모의 원격 감지 이미지 시각 언어 모델의 개발을 촉진하는 것입니다.
직접 사용:https://go.hyper.ai/O7DtC
4. ATLAS 고해상도 3D 캐릭터 텍스처 데이터 세트
이 데이터 세트의 전체 이름은 ArTicuLated humAn textureS(약칭 ATLAS)로, 텍스트 설명이 포함된 50,000개의 고화질 텍스처를 포함하는 가장 큰 고해상도(1,024 × 1,024) 3D 인간 텍스처 데이터 세트입니다. ECCV 2024에 관련 논문 결과가 선정되었습니다.
직접 사용:https://go.hyper.ai/Zx1nj
MIND에는 약 16만 개의 영어 뉴스 기사와 100만 명의 사용자가 생성한 1,500만 개 이상의 인상 로그가 포함되어 있으며, 이는 Microsoft News 웹사이트의 익명 행동 로그에서 수집되었습니다. 이 프로젝트의 목표는 뉴스 추천을 위한 벤치마크 데이터 세트로 활용하고 뉴스 추천 및 추천 시스템 분야의 연구를 촉진하는 것입니다.
직접 사용:https://go.hyper.ai/lVOyX
BoWFire 데이터 세트는 화염 감지에 전념하는 이미지 데이터 세트로, 화재 감지의 정확도를 높이고 오경보를 줄이는 것을 목표로 합니다. 이 데이터 세트에는 건물 화재, 산업 화재, 교통사고, 폭동 등 다양한 비상 상황에서의 화재 이미지가 포함되어 있습니다.
직접 사용:https://go.hyper.ai/73AYY
이 데이터 세트에는 CNN과 Daily Mail 기자들이 쓴 30만 개 이상의 뉴스 기사가 포함되어 있으며, 긴 문단을 1~2 문장으로 요약할 수 있는 모델을 개발하는 데 도움이 되도록 설계되었습니다.
직접 사용:https://go.hyper.ai/AbidL
8. Doodle Dataset Doodle Image Dataset
이 데이터 세트에는 340개의 그래피티 카테고리를 망라하는 100만 개 이상의 이미지가 포함되어 있으며, 머신 러닝 작업에 사용할 수 있습니다.
직접 사용:https://go.hyper.ai/Ns4M4
Yoga-16 데이터 세트는 요가 포즈 인식 모델의 분류 정확도를 개선하는 것을 목표로 합니다. 이는 훈련, 테스트, 검증의 세 가지 주요 디렉토리로 나뉘며, 각 디렉토리에는 16가지 요가 포즈에 해당하는 16개의 하위 디렉토리가 있습니다.
직접 사용:https://go.hyper.ai/iMe0Z
10. 인간 이미지 데이터 세트 남성 및 여성 인간 이미지 데이터 세트
데이터 세트에는 남성과 여성의 두 가지 사람 카테고리 이미지 폴더가 포함되어 있습니다. 이미지에는 얼굴, 상체, 전신이 포함됩니다. 이는 성별 인식, 인간 식별, 이미지 분류 등 다양한 프로젝트에 사용될 수 있습니다.
직접 사용:https://go.hyper.ai/6UJb7
더 많은 공개 데이터 세트를 보려면 다음을 방문하세요.
https://hyper.ai/datasets
커뮤니티 기사
1. 학술 공유 | 청화대학교 박사후연구원 Li Yuzhe가 게놈학에 AI를 적용하는 방법을 탐구하는 Cell/Nature 저널 논문을 자세히 설명합니다.
"AI4S를 만나다" 생방송 시리즈의 두 번째 에피소드에서는 청화대학교 장창펑 연구실의 박사후 연구원인 리위저를 초대했습니다. 8월 21일, 리위저 박사는 온라인 생방송을 통해 공간 전사체학과 단일 세포 오믹스 연구에서 AI가 어떻게 활용되는지에 대해 더욱 자세히 설명할 예정입니다.
이벤트 세부 정보 보기:https://go.hyper.ai/GIzpo
2. 세계 최초! 청화대/상하이교통대 등 공동 연구진, 당뇨병 진단 및 치료를 위한 시각적-대규모 언어 모델 구축, Nature 게재
Google Research와 MIT가 힘을 합쳐 IJCAI 2024 최우수 논문상을 수상했습니다! WeChat 공식 계정에서 IJCAI 2024에 답글을 달면 IJCAI 2024 최우수 논문상, 우수 논문상, AIJ 클래식 논문상 및 우수 논문상을 받을 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/ZGzI2
3. 처음이에요! GPT-2는 무선 통신의 물리적 계층을 강화하고 Peking University 팀은 사전 훈련된 LLM을 기반으로 하는 채널 예측 솔루션을 제안합니다.
청화대학교 의학부 부총장 겸 원장인 황톈인 교수가 이끄는 팀, 상하이 교통대학교 전기공학부 컴퓨터과학과/교육부 인공지능 핵심연구실의 성빈 교수가 이끄는 팀, 상하이 교통대학교 의학부 부속 제6인민병원의 지아 웨이핑 교수와 리화팅 교수가 이끄는 팀, 싱가포르 국립대학교와 싱가포르 국립안과병원의 친위종 교수가 이끄는 팀은 협력하여 세계 최초의 당뇨병 진단 및 치료를 위한 통합 시각-대규모 언어 모델 시스템인 DeepDR-LLM을 성공적으로 구축했습니다. 이 글은 연구에 대한 자세한 해석과 공유입니다.
전체 보고서 보기:https://go.hyper.ai/qnzSp
인기 백과사전 기사
1. 연합을 통한 교차(IoU)
2. 상호 정렬 융합 RRF
3. 대조 학습
4. 대규모 멀티태스크 언어 이해(MMLU)
5. 장기 기억과 단기 기억 장기 단기 기억
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
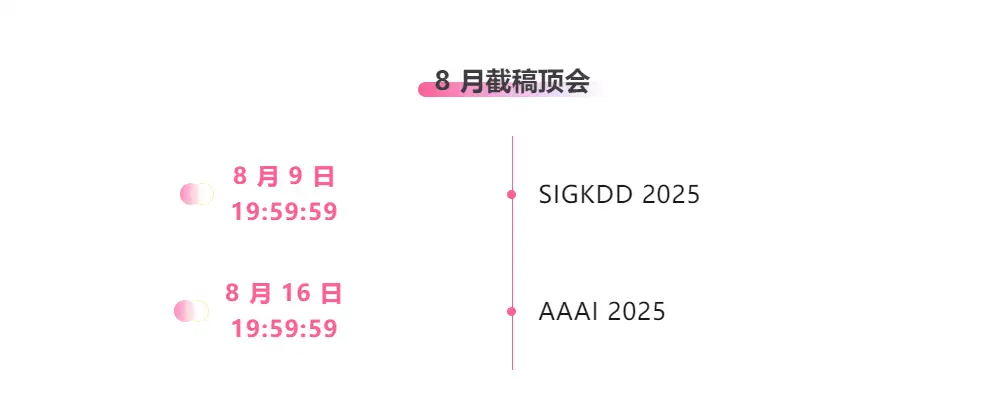
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1300개 이상의 공공 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 400개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 100개 이상의 AI4Science 논문 사례 해석
* 500개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.