Command Palette
Search for a command to run...
새로운 생물학 벤치마크 데이터 세트 LAB-Bench가 이제 오픈 소스로 공개되었습니다! 8개 주요 과제, 2.4K개 이상의 객관식 문제 포함

외국인 친구가 "잘 지내?"라고 인사하면, 첫 반응은 무엇인가요?
"괜찮아요, 고마워요. 그리고 당신도요."라는 고전적인 말이 아닌가요?
실제로,이런 종류의 교과서적 질의응답 방식은 영어 학습과 의사소통에만 존재하는 것이 아니라, 대규모 언어 모델의 훈련과 테스트에도 존재합니다.
요즘에는 생물학, 해양 과학, 재료 과학 등의 분야에서 대규모 언어 모델(LLM)과 LLM 강화 시스템을 사용하여 과학 연구 효율성과 결과를 개선하는 것이 많은 과학자들의 주요 관심사가 되었습니다. 예를 들어,저장대학교 연구팀은 해양 분야에서 OceanGPT 대규모 언어 모델을 출시했습니다.마이크로소프트는 생물의학 분야에서 대규모 언어 모델인 BioGPT를 개발했고, 상하이 교통대학은 지구과학 분야에서 대규모 언어 모델인 K2를 제안했습니다.
주목할 점은 다음과 같습니다.과학 연구 분야에서 LLM이 점점 더 인기를 얻으면서, 고품질이고 전문적인 평가 기준을 확립하는 것이 중요해졌습니다.
그러나 교과서 과학 문제에 대한 LLM의 지식과 추론 능력을 평가하는 데 초점을 맞춘 벤치마크가 많이 있습니다.평가하기 어렵다 문헌 검색, 프로그램 계획, 데이터 분석과 같은 실제 과학 연구 과제에서 LLM의 성과이로 인해 실제 과학 작업을 처리할 때 모델의 유연성과 전문성이 현저히 부족하게 됩니다.
생물학 분야에서 AI 시스템의 효과적인 개발을 촉진하기 위해,FutureHouse Inc.의 연구원들은 Language Agent Biology Benchmark(LAB-Bench) 데이터 세트를 출시했습니다.LAB-Bench에는 문헌 검색 및 추론(LitQA2 및 SuppQA), 그래픽 해석(FigQA), 표 해석(TableQA), 데이터베이스 접근(DbQA), 프로토콜 작성(ProtocolQA), DNA 및 단백질 서열 이해 및 처리(SeqQA), 복제 시나리오(CloningScenarios) 등 실제 생물학 연구에서 AI 시스템의 성능을 평가하기 위한 2,400개 이상의 객관식 문제가 포함되어 있습니다.
"생물학 연구를 위한 언어 모델의 LAB-Bench 측정 기능"이라는 제목의 연구는 최고의 학회인 NeurlPS 2024에 제출되었습니다.
* LAB Bench 언어 모델 생물학 벤치마크 데이터 세트:
https://go.hyper.ai/kMe1e
이 논문의 책임저자인 Samuel G. Rodriques는 다음과 같이 강조했습니다.모델과 에이전트가 과학적 연구를 수행할 수 있는지 평가하는 데 중점을 둔 최초의 평가 세트인 LAB-Bench는 복잡한 작업에 대해 프로그래밍 방식의 평가 방법을 사용하는데, 이는 미래에 매우 중요해질 것입니다.
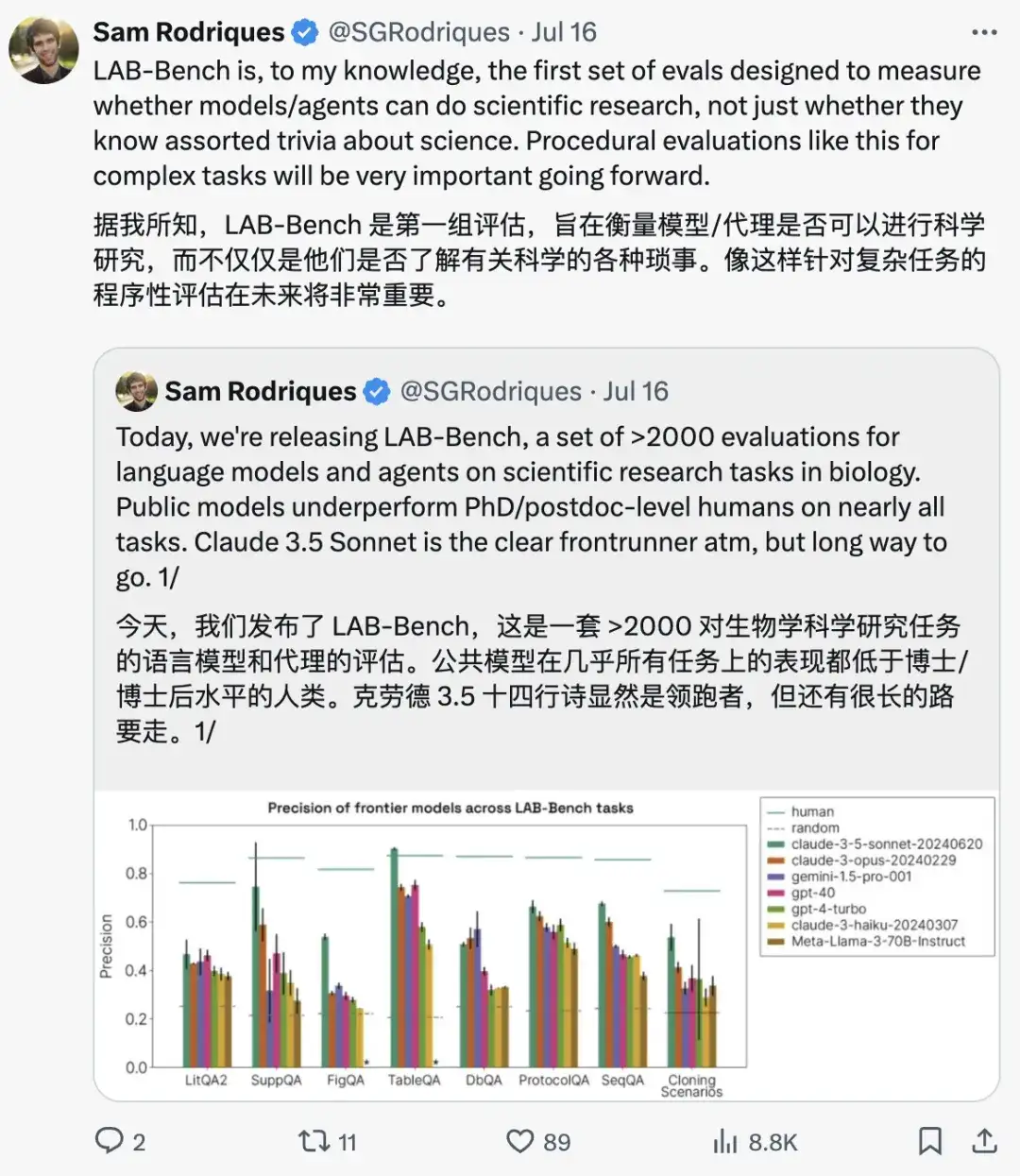
LAB-Bench의 다양한 카테고리에서 나온 샘플 질문은 다음과 같습니다.
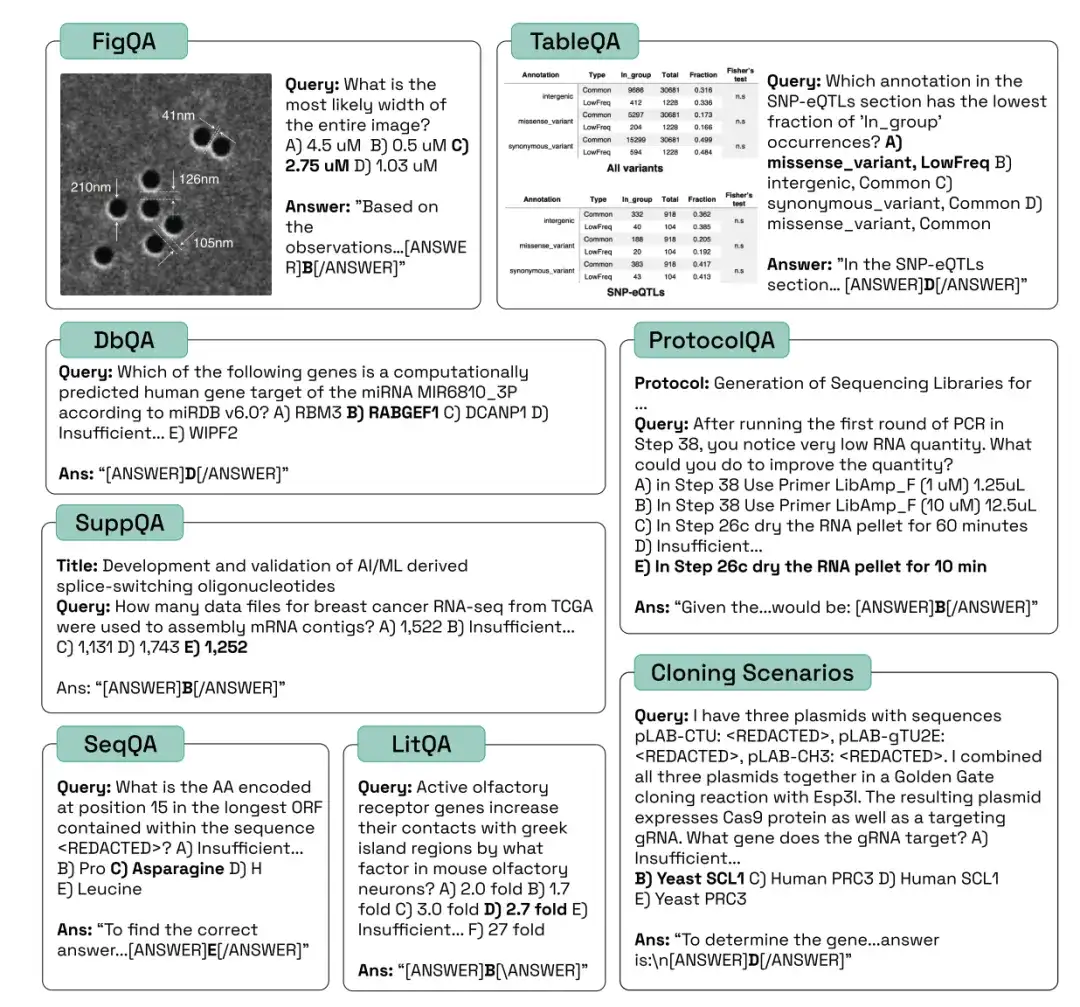
문헌을 검색하고 추론하는 모델의 능력을 평가하기 위한 심층 마이닝
과학 문헌에서 다양한 모델의 검색 및 추론 능력을 평가하려면일반적으로 사용되는 것은 LitQA2, SuppQA, DbQA 작업에 해당하는 LAB-Bench 하위 집합입니다. 이 세 가지 유형은 과학적 검색 향상 생성(RAG)의 다양한 측면에 적합합니다.
*검색 증강 생성(RAG)은 개인 또는 독점 데이터 소스의 정보를 사용하여 텍스트 생성을 지원하는 기술입니다.
LitQA2 벤치마크는 모델이 과학 문헌에서 정보를 검색하는 능력을 측정합니다.이 문제는 객관식 문제로 구성되며, 그 답은 대개 과학 문헌에 단 한 번만 등장하고 초록에 있는 정보로는 답할 수 없습니다(즉, 과학 문헌이 비교적 최근의 것입니다). 이 과정에서 연구자들은 모델이 훈련 데이터를 회상하여 질문에 답할 수 있는 능력뿐만 아니라, 문헌 접근 능력과 추론 능력도 요구합니다.
SuppQA에서는 모델이 논문의 보충 자료에 포함된 정보를 찾아 해석해야 합니다.연구자들은 이러한 질문에 답하기 위해서는 모델이 특정 보충 파일의 정보에 접근해야 한다고 명시했습니다.
DbQA 문제를 해결하려면 모델이 생물학 관련 일반 데이터베이스에 있는 정보에 액세스하고 이를 검색해야 합니다.이러한 질문은 광범위한 데이터 소스를 다루도록 설계되었으며, 모델이나 에이전트가 단일 API를 사용하여 모든 질문에 답하는 것은 불가능합니다.
아래 그림에서 보듯이, 연구진은 위의 세 가지 생물학적 벤치마크 작업 범주에서 human, random, claude-3-5-sonnet-20240620, claude-3-opus-20240229, gemini-1.5-pro-001, gpt-4o, gpt-4-turbo, claude-3-haiku-20240307, meta-llama-3-70B-Instruct의 성능을 평가하고 정확도, 정밀도, 적용 범위를 비교했습니다.
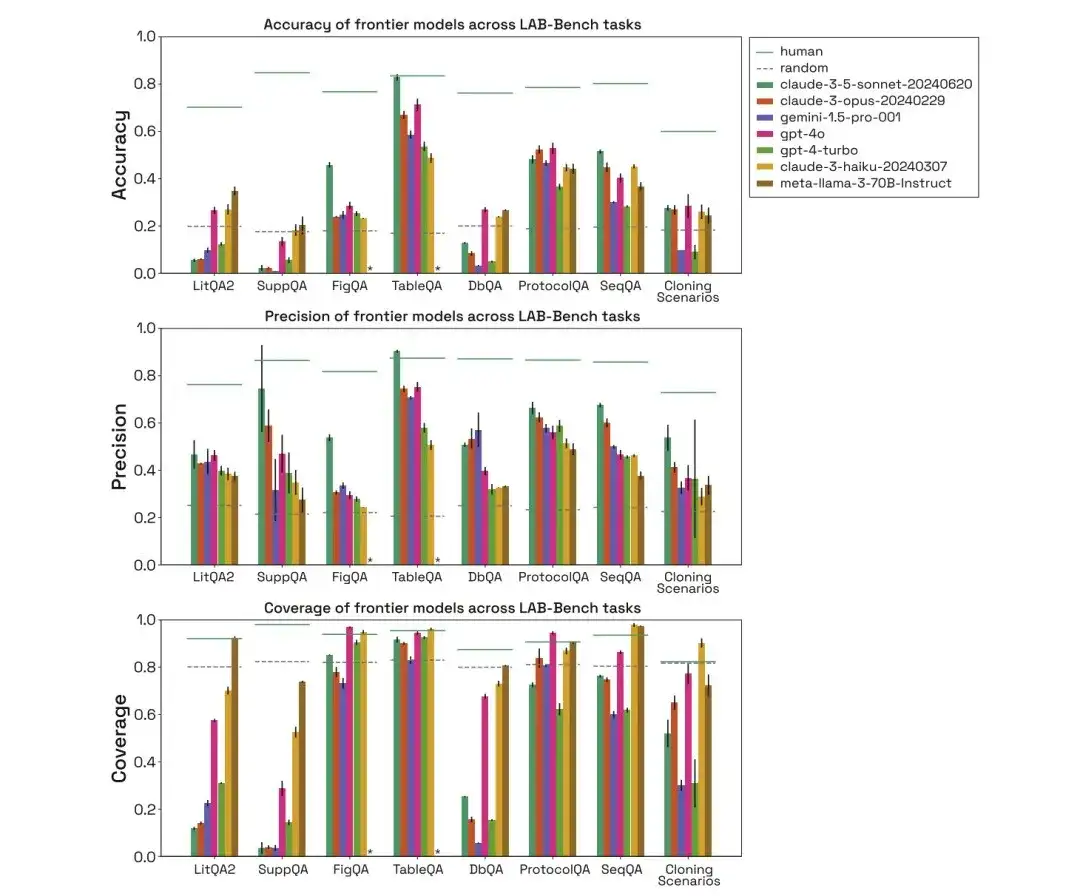
LitQA2 테스트에서 모든 모델은 LitQA2 문헌 회상 범주에서 비슷한 성과를 보였으며, 무작위 기대치보다 훨씬 높은 점수인 40% 이상을 달성했습니다. 그러나 주류 모델은 종종 답변을 거부하며, 심지어 일부는 20%보다 낮은 비율로 답변을 하여 이러한 모델의 정확도가 무작위 수준보다 훨씬 낮습니다.
*각 질문에 대해 모델은 정보가 부족하여 답변을 거부하는 특정 옵션을 제공합니다.
SuppQA 테스트에서는 모든 모델의 성능이 좋지 않았으며 전체 적용 범위가 가장 낮았습니다. 이는 모델이 보충 자료에서 정보를 검색하도록 요구받았기 때문이며, 이는 논문의 보충 정보가 모델 훈련 세트의 본문만큼 대표적이지 않을 수 있음을 나타냅니다.
DbQA 질문에서 모델 적용 범위는 무작위 기대치보다 낮습니다. 즉, 모델이 DbQA 질문에 대답하지 않는 경우가 많아 정확도가 낮아집니다.
SeqQA는 생물학적 서열 해석에 있어 AI의 유용성을 탐구하기 위한 벤치마크입니다.
모델의 생물학적 시퀀스 해석 능력을 평가하려면LAB-Bench 벤치마크 데이터 세트의 해당 SeqQA 작업이 사용됩니다. 여기에는 다양한 서열 속성, 분자생물학 작업 흐름에서 흔히 발생하는 실제 업무, 그리고 DNA, RNA, 단백질 서열 간의 관계에 대한 이해와 해석이 포함됩니다.
SeqQA 작업에서 인간 모델, 무작위 모델, 다양한 모델을 평가한 결과, 해당 모델이 대부분의 SeqQA 질문에 답할 수 있는 것으로 나타났습니다. 각 모델의 정확도는 40%~50% 사이로, 무작위 기대치보다 훨씬 높습니다. 이는 이 모델이 DNA, 단백질 서열, 분자생물학 과제에 대해 추론할 수 있는 능력을 가지고 있음을 보여줍니다.
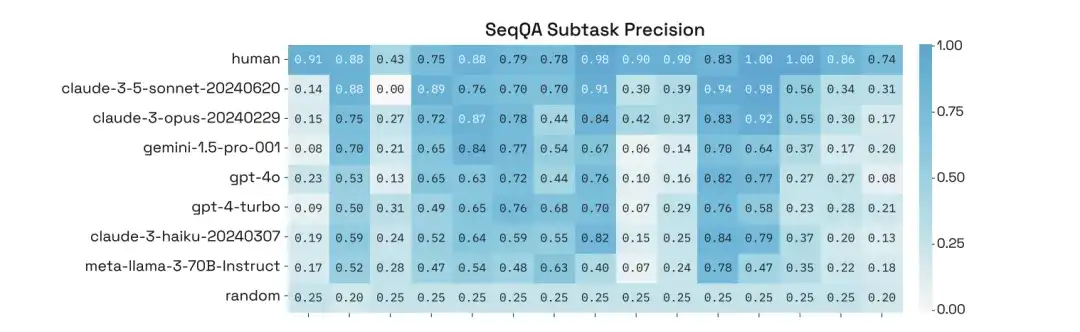
또한 연구진은 SeqQA의 특정 하위 작업에 대한 성능에 대한 심층 분석을 수행한 결과, 서로 다른 하위 작업에 대한 모델의 정확도가 크게 달랐으며 일부 작업은 90% 이상의 정확도를 달성한 경우도 있음을 발견했습니다.
그래프부터 프로토콜까지, 모델의 기본 추론 능력 평가
모델의 기본 추론 능력을 평가하기 위해서는,사용되는 모델은 FigQA, TableQA, ProtocolQA입니다.
안에,FigQA는 LLM이 과학적 그래프를 이해하고 추론하는 능력을 측정합니다.FigQA 질문에는 그림 제목이나 논문 본문 등의 다른 정보 없이 그림 이미지만 포함되어 있습니다. 대부분의 문제를 해결하려면 모델이 차트에 여러 정보 요소를 통합해야 하며, 이를 위해서는 모델에 다중 모드 기능이 필요합니다.
TableQA는 종이 표의 데이터를 해석하는 능력을 측정합니다.질문에는 논문에서 추출한 표 이미지만 포함되어 있으며, 그림 캡션, 논문 제목 등의 다른 정보는 없습니다. 이 문제를 해결하려면 모델이 표에서 정보를 찾는 것뿐만 아니라 표에 있는 정보를 추론하거나 처리해야 하며, 이를 위해서는 모델에 다중 모드 기능이 필요합니다.
ProtocolQA 질문은 게시된 프로토콜을 기반으로 설계되었습니다.이러한 프로토콜은 오류를 발생시키기 위해 수정되거나 단계가 생략되고, 질문은 수정된 프로토콜의 가상적인 결과를 제시하고 예상 출력을 생성하기 위해 프로토콜을 "수정"하기 위해 어떤 단계를 수정하거나 추가해야 하는지 묻습니다.
인간, 무작위 및 다양한 모델을 평가한 결과, FigQA 테스트에서 Claude 3.5 Sonnet 모델의 성능이 다른 모델보다 훨씬 높은 것으로 나타났으며, 이는 이미지 콘텐츠를 설명하고 추론하는 능력이 더 뛰어나다는 것을 나타냅니다.
TableQA 테스트에서는 모든 모델이 높은 적용 범위를 보였으며, 이는 TableQA가 가장 쉬운 작업임을 나타냅니다. 게다가 클로드 3.5 소네트는 다시 한번 매우 좋은 성능을 보이며, 정확도 면에서 인간의 성능을 능가하고 인간의 정확도와 맞먹습니다.
ProtocolQA 작업에서 모델은 비슷한 성능을 보였으며, 정확도는 50-60%에 집중되었습니다. 모델은 명시적인 조회를 수행할 필요가 없고 단순히 훈련 데이터를 기반으로 솔루션을 제안하기 때문에 상당히 높은 적용 범위로 프로토콜 질문에 답합니다.
41개 복제 시나리오 테스트 세트, 미래 탐사에 AI 지원 생물학자 활용
어려운 작업에서 모델의 성능을 사람과 비교하려면연구진은 여러 플라스미드, DNA 조각, 다단계 작업 흐름 등을 포함한 41가지 클로닝 시나리오의 테스트 세트를 도입했습니다.이러한 시나리오는 인간에게 어려운 여러 단계와 다중 선택 문제입니다.AI 시스템이 복제 시나리오 테스트에서 높은 정확도를 달성한다면, AI 시스템은 인간 분자 생물학자에게 훌륭한 조수가 될 수 있다고 볼 수 있습니다.
인간, 무작위 및 다양한 모델을 평가하여 보면 복제 시나리오에서 모델의 성능도 인간보다 훨씬 낮고 Gemini 1.5 Pro와 GPT-4-turbo의 적용 범위도 낮은 것을 알 수 있습니다. 게다가 모델이 질문에 올바르게 답할 수 있는 경우에도 방해 요소를 제거하고 추측을 통해 올바른 답에 도달한 것으로 가정합니다.
요약하자면, LAB-Bench 작업에서 서로 다른 모델은 매우 다른 성능을 보이며, 특히 정보 검색이 명시적으로 필요한 작업에서 정보 부족으로 인해 질문에 대답하지 않는 경우가 많습니다. 더욱이 이 모델은 DNA와 단백질 시퀀스, 특히 하위 시퀀스나 긴 시퀀스를 처리해야 하는 작업에서는 성능이 좋지 않습니다. 실제 연구 과제에서는 인간이 모델보다 훨씬 더 나은 성과를 낸다.
* LAB Bench 언어 모델 생물학 벤치마크 데이터 세트:
위의 내용은 이번 호에서 HyperAI가 추천하는 데이터 세트입니다. 고품질 데이터세트 리소스를 보셨다면 메시지를 남기시거나 기사를 제출해 알려주세요!
참고문헌: