Command Palette
Search for a command to run...
스탠포드, 애플 등 23개 기관이 DCLM 벤치마크를 발표했습니다. 고품질 데이터 세트가 스케일링 법칙을 뒤흔들 수 있을까? 기본 모델은 Llama3 8B와 동일한 성능을 보입니다.

사람들이 AI 모델에 계속해서 주목함에 따라, 확장 법칙에 대한 논쟁도 점점 더 격렬해지고 있습니다.
OpenAI는 2020년 논문 "신경망 언어 모델을 위한 스케일링 법칙"에서 스케일링 법칙을 처음 제안했습니다. 이는 대규모 언어 모델에 대한 무어의 법칙으로 간주됩니다. 그 의미는 다음과 같이 간략하게 요약될 수 있습니다.모델 크기, 데이터 세트 크기, 학습에 사용되는 부동 소수점 계산 수가 증가함에 따라 모델 성능이 향상됩니다.
스케일링 법칙의 영향으로, 많은 추종자들은 여전히 "큰" 것이 모델 성능을 개선하는 첫 번째 원칙이라고 믿고 있습니다. 특히 자금력이 풍부한 대기업은 방대하고 다양한 코퍼스 데이터 세트에 더 많이 의존합니다.
이와 관련하여, 박사 학위를 취득한 Qin Yujia는 칭화대학교 컴퓨터공학과의 한 연구원은 "LLaMA 3는 비관적인 현실을 보여줍니다. 모델 아키텍처를 변경할 필요가 없으며, 데이터 용량을 2T에서 15T로 늘리면 기적을 만들어낼 수 있습니다. 한편으로는 기존 모델이 장기적으로 대기업에게 기회가 될 수 있음을 시사합니다. 다른 한편으로는 스케일링 법칙의 한계 효과를 고려할 때, 차세대 모델이 GPT3에서 GPT4로 계속해서 개선되려면 최소 10배(예: 150T) 더 많은 데이터를 제거해야 할 수도 있습니다."라고 지적했습니다.

언어 모델 학습에 필요한 데이터 양의 지속적인 증가와 데이터 품질 등의 문제에 대응하여 워싱턴 대학교, 스탠포드 대학교, 애플 등 23개 기관이 공동으로 실험적 테스트 플랫폼인 DataComp for Language Models(DCLM)을 제안했습니다. 이 플랫폼의 핵심은 Common Crawl의 240T 신규 후보 어휘입니다. 훈련 코드를 수정함으로써 연구자들은 혁신을 위한 새로운 훈련 세트를 제안하도록 장려되며, 이는 언어 모델의 훈련 세트를 개선하는 데 매우 중요합니다.
관련 연구는 "DataComp-LM: 언어 모델을 위한 차세대 훈련 세트를 찾아서"라는 제목으로 학술 플랫폼에 게재되었습니다. http://arXiv.org 우수한.
연구 하이라이트
* DCLM 벤치마크 참가자는 412M에서 7B 매개변수에 이르는 모델에 대한 데이터 관리 전략을 실험할 수 있습니다.
* 모델 기반 필터링은 고품질의 학습 세트를 구축하는 데 중요합니다. 생성된 데이터 세트 DCLM-BASELINE은 2.6T 교육 토큰을 사용하여 MMLU에서 처음부터 7B 매개변수 언어 모델을 교육하여 64%의 5샷 정확도를 달성합니다.
* DCLM 기반 모델은 MMLU의 Mistral-7B-v0.3 및 Llama3 8B와 비슷한 성능을 보입니다.

서류 주소:
https://arxiv.org/pdf/2406.11794v3
오픈소스 프로젝트인 "awesome-ai4s"는 100개가 넘는 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
DCLM 벤치마크: 다양한 컴퓨팅 규모 요구 사항을 충족하기 위한 400M에서 7B까지의 다중 규모 설계
DCLM은 언어 모델을 개선하기 위한 데이터 세트 실험 플랫폼이며, 언어 모델 학습 데이터 관리를 위한 최초의 벤치마크입니다.
아래 그림과 같이,DCLM 워크플로는 주로 4단계로 구성됩니다. 규모 선택, 데이터 세트 구축, 모델 학습, 53개의 다운스트림 작업을 기반으로 모델 평가입니다.
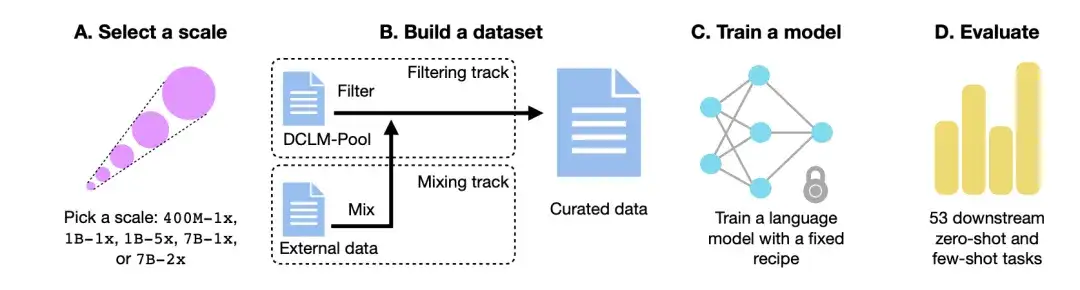
컴퓨팅 규모를 선택하세요
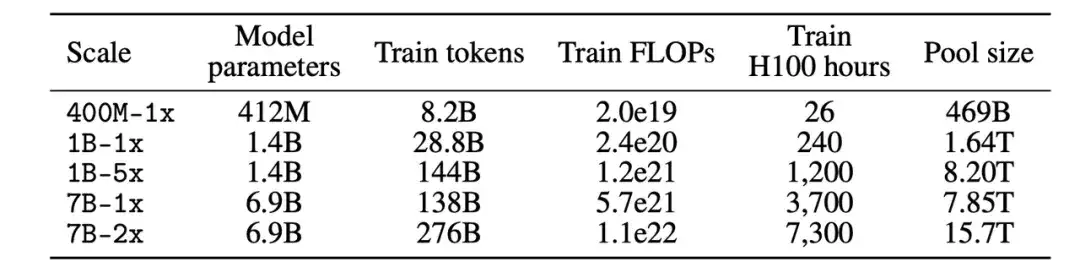
첫째, 컴퓨팅 규모 측면에서 연구진은 컴퓨팅 규모의 세 가지 규모에 걸쳐 다섯 가지의 서로 다른 경쟁 수준을 만들었습니다. 각 레벨(예: 400M-1x, 1B-1x, 1B-5x, 7B-1x, 7B-2x)은 모델 매개변수 양(예: 7B)과 친칠라 승수(예: 1x)를 지정합니다. 각 크기에 대한 훈련 토큰의 수는 매개변수 수에 친칠라 승수를 곱한 값의 20배입니다.
데이터 세트 구축
둘째, 매개변수 척도를 결정한 후, 데이터 집합을 구축하는 과정에서 참여자는 데이터를 필터링(Filter)하거나 혼합(Mix)하여 데이터 집합을 생성할 수 있습니다.
필터링 트랙에서연구진은 필터링되지 않은 크롤러 웹사이트인 Common Crawl에서 240T 토큰의 표준화된 코퍼스를 추출하고, DCLM-Pool을 구축한 후 컴퓨팅 규모에 따라 5개의 데이터 풀로 나누었습니다. 참가자는 알고리즘을 제안하고 데이터 풀에서 훈련 데이터를 선택합니다.
믹스 트랙에서,참가자는 다양한 출처의 데이터를 자유롭게 결합할 수 있습니다. 예를 들어, DCLM-Pool, 사용자 정의 크롤링 데이터, Stack Overflow, Wikipedia에서 데이터 문서를 합성합니다.
모델 학습
OpenLM은 분산 학습을 위한 FSDP 모듈에 초점을 맞춘 PyTorch 기반 코드 라이브러리입니다. 데이터 세트 간섭의 영향을 제거하기 위해 연구자들은 각 데이터 규모에서 모델 학습을 위한 고정된 방법을 사용했습니다.
연구진은 모델 아키텍처와 학습에 대한 이전의 절제 연구를 바탕으로 GPT-2 및 Llama와 같은 디코더 전용 Transformer 아키텍처를 채택하고 최종적으로 OpenLM에서 모델을 학습했습니다.
모델 평가
마침내,연구진은 기본 모델 평가에 적합한 53개의 다운스트림 작업을 사용하여 LLM-Foundry 워크플로를 사용하여 모델을 평가했습니다.이러한 하위 작업에는 질의 응답, 개방형 생성이 포함되며 인코딩, 교과서 지식, 상식적 추론과 같은 다양한 도메인을 포괄합니다.
데이터 정리 알고리즘을 평가하기 위해 연구진은 MMLU 5발 정확도, CORE 중심 정확도, EXTENDED 중심 정확도라는 세 가지 성능 지표에 초점을 맞췄습니다.
데이터 세트: DCLM을 사용하여 고품질 교육 데이터 세트를 구축하세요
DCLM은 어떻게 고품질 데이터 세트인 DCLM-BASELINE을 구성하고 데이터 관리 방법의 효과를 정량화합니까?
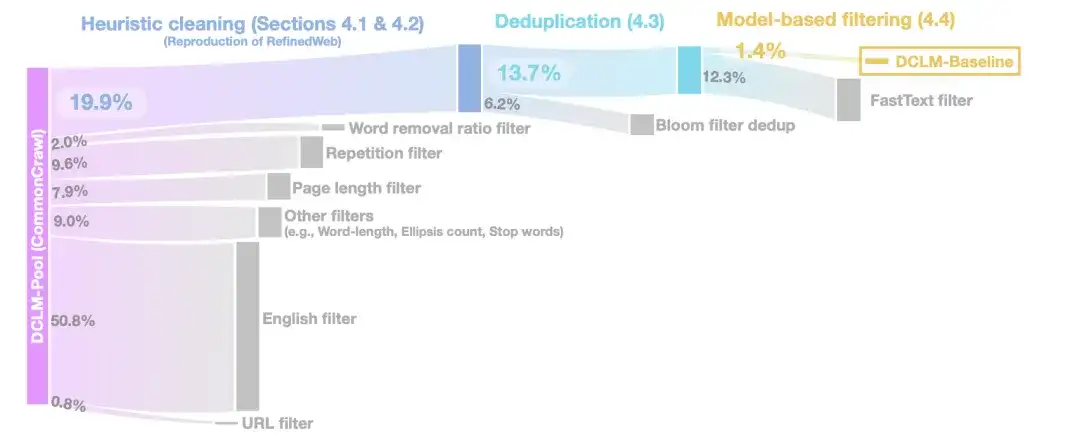
휴리스틱 청소 단계에서연구자들은 URL(URL 필터), 영어 필터(영어 필터), 페이지 길이 필터(페이지 길이 필터), 중복 콘텐츠 필터(반복 필터)를 제거하는 등 RefinedWeb의 방법을 사용하여 데이터를 정리했습니다.
중복 제거 단계에서연구진은 블룸 필터를 사용하여 추출된 텍스트 데이터의 중복을 제거한 후 수정된 블룸 필터가 10TB 데이터 세트로 더 쉽게 확장 가능하다는 것을 발견했습니다.
데이터 품질을 더욱 향상시키기 위해,모델 기반 필터링 단계에서 연구자들은 7가지 모델 기반 필터링 방법을 비교했습니다.PageRank 점수를 사용한 필터링, 의미적 중복 제거(SemDedup), fastText 이진 분류기 등을 포함한 결과, fastText 기반 필터링이 다른 모든 방법보다 우수한 것으로 나타났습니다.
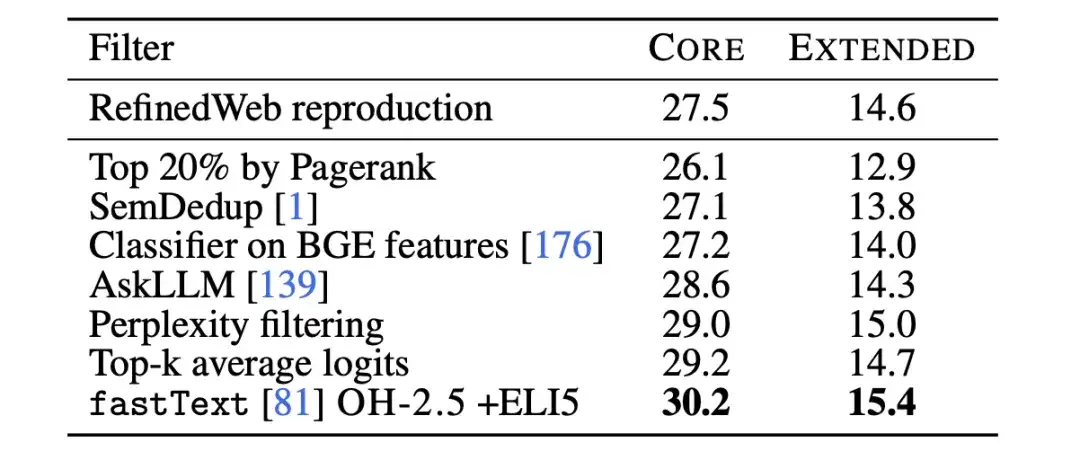
이후 연구진은 텍스트 분류기 절제를 사용하여 fastText 기반 데이터 필터링의 한계를 추가로 연구했습니다. 연구자들은 아래 그림에서 볼 수 있듯이 다양한 참조 데이터, 특징 공간, 필터링 임계값을 선택하여 여러 가지 변형을 훈련했습니다. 연구진은 참고 데이터로 GPT-3에서 사용하는 참고 데이터인 Wikipedia, OpenWebText2, RedPajama-books를 선택했습니다.
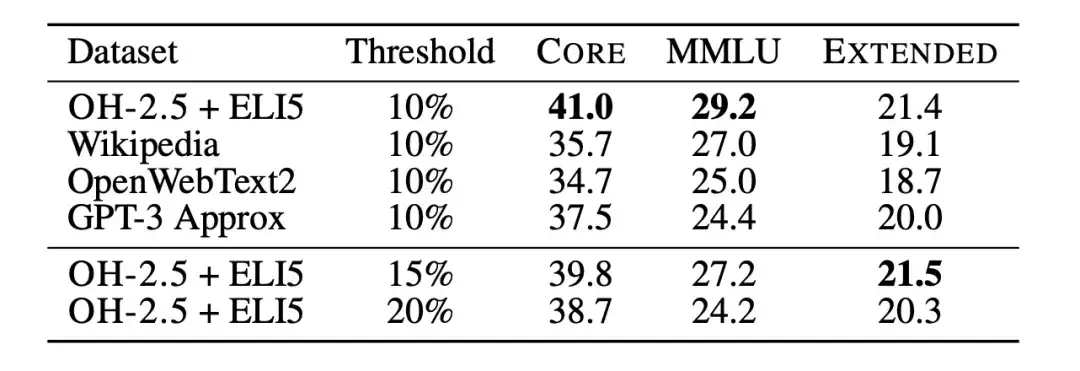
동시에,연구자들은 또한 교육 형식의 데이터를 혁신적으로 활용하여 OpenHermes 2.5(OH-2.5)와 r/ExplainLikeImFive(ELI5) 서브레딧에서 높은 점수를 받은 게시물에서 예를 추출했습니다.결과는 OH-2.5 + ELI5 방법이 일반적으로 사용되는 기준 데이터와 비교하여 CORE에서 3.5%를 개선한다는 것을 보여줍니다.
연구진은 또한 엄격한 임계값(즉, 10%의 임계값)을 적용하면 더 나은 성능을 얻을 수 있다는 것을 발견했습니다. 그래서,연구자들은 fastText OH-2.5 + ELI5 분류 점수를 사용하여 데이터를 필터링하고, 처음 10% 문서를 유지하여 DCLM-BASELINE을 얻었습니다.
연구 결과: 모델 기반 필터링은 고품질 데이터 세트를 생성하는 데 중요합니다.
먼저, 연구진은 평가되지 않은 사전 훈련 데이터의 오염이 결과에 영향을 미칠 수 있는지 분석했습니다.
대규모 언어 모델의 성능을 측정하기 위한 벤치마크로서, MMLU는 모델이 다양한 언어를 이해하는 능력을 보다 포괄적으로 조사하는 것을 목표로 합니다. 따라서 연구진은 MMLU를 평가 집합으로 사용하여 MMLU에서 DCLM-BASELINE에 존재하는 문제점을 발견하고 제거했습니다. 그런 다음 연구자들은 탐지된 MMLU 중복을 사용하지 않고 DCLM-BASELINE을 기반으로 7B-2x 모델을 훈련했습니다.
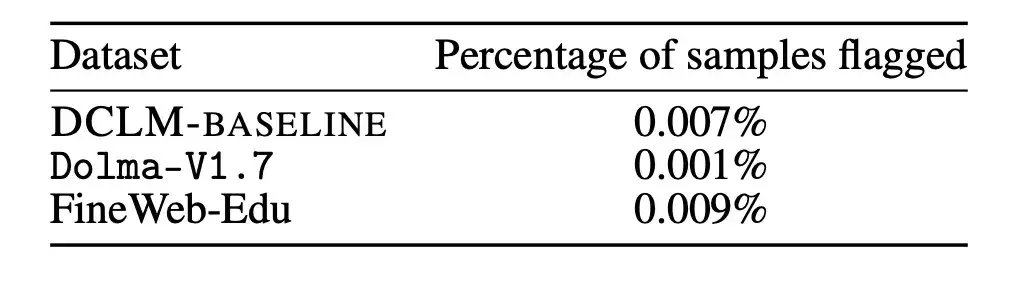
결과는 아래 그림과 같습니다. 오염된 샘플을 제거해도 모델 성능이 저하되지 않습니다. 이것으로부터 알 수 있는 것은MMLU 벤치마크에서 DCLM-BASELINE의 성능 향상은 데이터 세트에 MMLU의 데이터가 포함되었기 때문이 아닙니다.

또한 연구진은 위의 제거 전략을 Dolma-V1.7과 FineWeb-Edu에 적용하여 DCLM-BASELINE과 이러한 데이터 세트 간의 오염 차이를 측정했습니다. DLCM-BASELINE의 오염 통계는 다른 고성능 데이터 세트의 오염 통계와 거의 유사한 것으로 나타났습니다.
두 번째로, 연구진은 훈련된 새로운 모델을 매개변수 척도가 7B-8B인 다른 모델과 비교했습니다. 결과에 따르면 DCLM-BASELINE 데이터 세트를 기반으로 생성된 모델은 오픈 소스 데이터 세트로 학습된 모델보다 성능이 뛰어나고, 폐쇄 소스 데이터 세트로 학습된 모델과 경쟁력이 있는 것으로 나타났습니다.
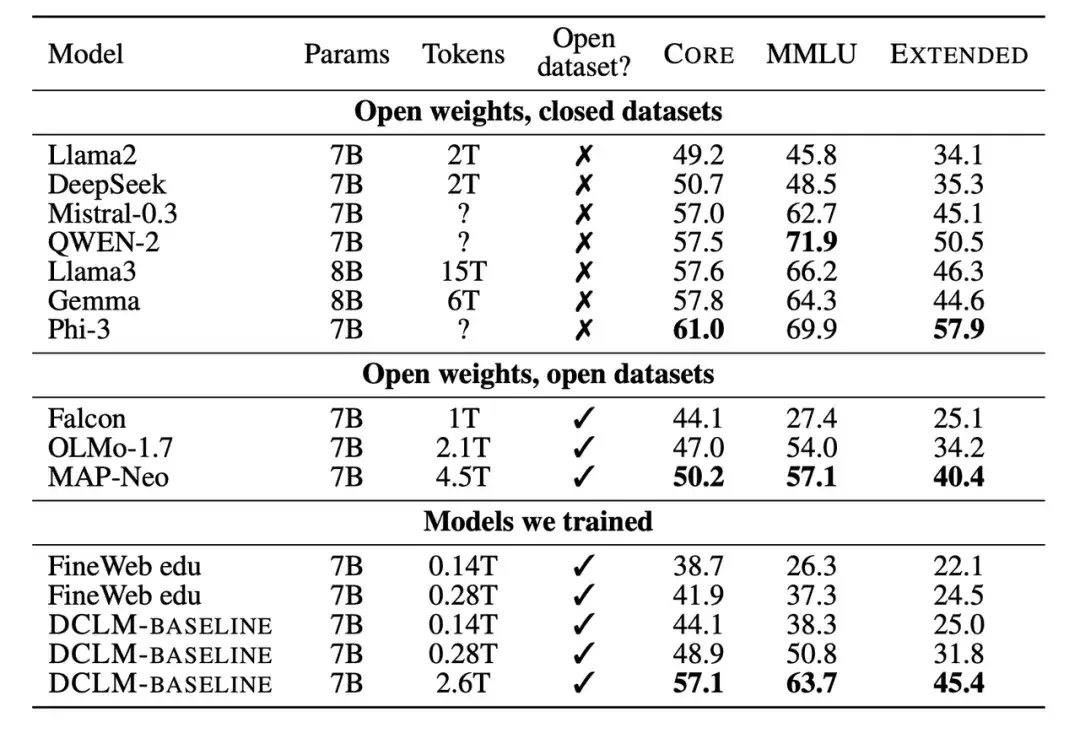
많은 수의 실험 결과는 다음을 보여줍니다.모델 기반 필터링은 고품질 데이터 세트를 형성하는 데 핵심이며, 데이터 세트 설계는 언어 모델을 훈련하는 데 매우 중요합니다.생성된 데이터 세트 DCLM-BASELINE은 2.6T 교육 토큰을 사용하여 MMLU에서 7B 매개변수 언어 모델을 처음부터 교육하여 64%의 5샷 정확도를 달성합니다.
기존의 가장 진보된 오픈 데이터 언어 모델인 MAP-Neo와 비교했을 때,생성된 데이터 세트 DCLM-BASELINE은 MMLU를 6.6 %만큼 향상시키고, 학습에 필요한 계산량을 40%만큼 줄였습니다.
DCLM의 기본 모델은 MMLU(63% 및 66%) 기반의 Mistral-7B-v0.3 및 Llama3 8B와 비슷하며, 53개의 자연어 이해 과제에서 비슷한 성능을 보였지만, Llama3 8B보다 학습에 필요한 계산량이 6.6배 적었습니다.
스케일링 법칙: 미래 방향은 불확실하며 언어 모델을 위한 차세대 훈련 세트를 찾고 있습니다.
요약하자면, DCLM의 핵심은 모델 기반 필터링을 통해 연구자들이 고품질의 학습 세트를 구축하도록 장려하여 모델 성능을 개선하는 것입니다. 이는 또한 "큰 것이 아름답다"는 모델 학습 추세에 따른 문제를 해결하는 새로운 접근 방식을 제공합니다.
박사 학위를 취득한 Qin Yujia 청화대학교에서 컴퓨터공학을 전공한 그는 "이제 데이터 규모를 줄일 때가 됐다"고 말했습니다. 그는 여러 논문을 분석하고 요약한 결과, "정리 후 깨끗한 데이터 + 작은 모델이 더러운 데이터 + 큰 모델의 효과에 더 가까울 수 있다"는 사실을 발견했습니다.
7월 초, 빌 게이츠는 Next Big Idea 팟캐스트의 최신 에피소드에서 AI 기술의 패러다임 전환이라는 주제를 언급했으며, 확장 법칙이 종말을 고할 것이라고 생각했습니다. 컴퓨터 상호작용에 있어서 AI 혁명은 아직 도래하지 않았지만, 진정한 진전은 단순히 모델의 크기를 늘리는 것이 아니라 인간에 더 가까운 메타인지 능력을 달성하는 데 있습니다.

이에 앞서 2024년 베이징 지위안 회의에서는 국내 업계 리더들이 스케일링 법률의 미래 방향에 대해 심도 있는 논의를 한 바 있다.
제로원 에브리씽의 CEO인 카이푸 리(Kai-Fu Lee)는 스케일링 법칙이 효과적이라는 것이 입증되었으며 아직 정점에 도달하지는 않았지만, 스케일링 법칙을 무작정 GPU를 늘리는 데 사용할 수는 없다고 말했습니다. 단순히 더 많은 컴퓨팅 파워를 축적하여 모델 효과를 개선하는 데에만 의존한다면, 충분한 GPU를 보유한 회사나 국가만이 승리할 뿐입니다.
청화대학교 지능산업연구소장인 장야친은 스케일링 법칙이 실현된 것은 주로 방대한 데이터의 활용과 컴퓨팅 능력의 상당한 향상에 기인한다고 말했습니다. 이는 향후 5년간 산업 발전의 주요 방향으로 남을 것입니다.

다크사이드오브더문 CEO 양지린은 스케일링 법칙에는 본질적인 문제가 없다고 생각합니다. 컴퓨팅 파워와 데이터가 더 많아지고, 모델 매개변수가 더 커지면 모델은 계속해서 더 많은 지능을 생성할 수 있습니다. 그는 스케일링 법칙이 계속해서 발전할 것이라고 믿지만, 이 과정에서 스케일링 법칙의 방법도 상당히 바뀔 수 있다고 생각합니다.
바이촨 인텔리전스의 CEO인 왕샤오촨은 확장 법칙 외에도 컴퓨팅 성능, 알고리즘, 데이터 및 기타 패러다임에서 새로운 변화를 모색해야 하며, 이를 단순히 지식 압축으로만 전환해서는 안 된다고 생각합니다. 오직 이 시스템에서 벗어나야만 AGI로 나아갈 수 있는 기회를 얻을 수 있습니다.
대규모 모델의 성공은 주로 모델 개발, 리소스 할당, 적절한 교육 데이터 선택에 대한 귀중한 지침을 제공하는 스케일링 법칙의 존재 덕분입니다. Scaling Laws의 종말이 어디인지는 아직 알 수 없지만, DCLM 벤치마크는 모델 성능을 개선하기 위한 새로운 사고 패러다임과 가능성을 제공합니다.
참고문헌:
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361