신경망이 밀도 함수 이론을 대체합니다! 칭화대 연구팀, 범용 소재 모델 DeepH 출시, 초정밀 예측 달성

재료 설계에서 재료의 전자 구조와 특성을 이해하는 것은 재료 성능을 예측하고, 새로운 재료를 발견하고, 재료 성능을 최적화하는 데 핵심입니다. 과거,밀도 함수 이론(DFT)은 업계에서 재료의 전자 구조와 특성을 연구하는 데 널리 사용됩니다. 그 핵심은 분자(원자)의 기본 상태에서 모든 정보의 운반체로 전자 밀도를 사용하는 것입니다.단일 전자의 파동 함수 대신, 다중 전자 시스템을 단일 전자 문제로 변환하여 해결하는데, 이는 계산 과정을 단순화할 뿐만 아니라 계산 정확도를 보장하고 조리개 분포를 보다 정확하게 반영할 수 있습니다.
그러나 DFT는 계산 비용이 많이 들고 일반적으로 소규모 재료 시스템을 연구하는 데만 사용할 수 있습니다. 재료 게놈 이니셔티브에서 영감을 받은 과학자들은 DFT를 사용하여 거대한 재료 데이터베이스를 구축하기 시작했습니다. 지금까지 수집된 데이터 세트는 제한적이지만, 이미 주목할 만한 시작입니다. 이를 기점으로, AI 기술이 새로운 변화를 가져오면서 연구자들은 "딥러닝과 DFT를 결합하고 신경망이 DFT의 본질을 심층적으로 학습하도록 하면 혁신적인 돌파구를 가져올 수 있을까?"라는 생각을 하게 되었습니다.
이는 딥러닝 밀도 함수 이론 해밀토니안(DeepH) 방법의 핵심입니다.DeepH는 DFT의 복잡성을 신경망에 집약함으로써 전례 없는 속도와 효율성으로 계산을 수행할 수 있을 뿐만 아니라, 더 많은 학습 데이터가 추가됨에 따라 지능도 지속적으로 향상됩니다.최근, 청화대학교 물리학과의 쉬융(Xu Yong)과 돤원후이(Duan Wenhui) 연구진은 자신들이 개발한 DeepH 방법을 성공적으로 사용하여 DeepH 범용 물질 모델을 개발하고 "대형 물질 모델"을 구축하기 위한 실행 가능한 솔루션을 보여주었습니다. 이 획기적인 발견은 혁신적인 소재 발견에 새로운 기회를 제공합니다.
"딥러닝 밀도 함수 이론 해밀토니안의 범용 재료 모델"이라는 제목의 관련 연구가 Science Bulletin에 게재되었습니다.

서류 주소:
https://doi.org/10.1016/j.scib.2024.06.011
오픈소스 프로젝트인 "awesome-ai4s"는 100개가 넘는 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
AiiDA를 통해 대규모 재료 데이터베이스를 구축하여 자기 재료 간섭을 제거합니다.
DeepH 일반 재료 모델의 보편성을 입증하기 위해 본 연구에서는 자동 대화형 인프라 및 데이터베이스(AiiDA)를 통해 104개의 고체 재료를 포함하는 대규모 재료 데이터베이스를 구축했습니다.
이 연구에서는 다양한 원소 구성을 보여주기 위해 주기율표의 처음 네 줄을 선택하여 자성 물질의 간섭을 피하기 위해 Sc에서 Ni까지의 전이 원소를 제외했고, 희귀 가스 원소도 제외했습니다. 후보 재료 구조는 Materials Project 데이터베이스에서 가져왔습니다. 원소 유형을 기반으로 한 필터링 외에도, 후보 재료는 재료 열에서 더욱 세분화되어 "비자성"으로 표시된 재료만 포함됩니다. 단순화를 위해, 단위 셀에 150개 이상의 원자가 포함된 구조는 제외되었습니다.
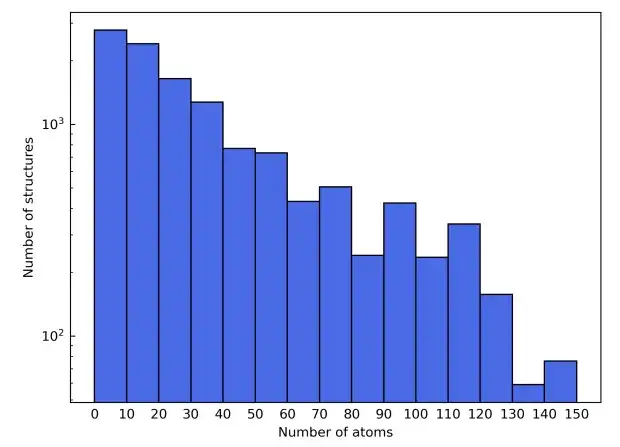
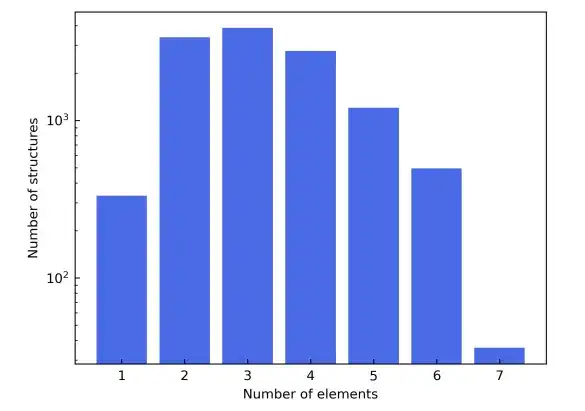
이러한 필터링 기준에 따라 최종 재료 데이터 세트는 총 12,062개의 구조로 구성되었습니다. 학습 과정에서 데이터 세트는 6:2:2의 비율로 학습 세트, 검증 세트, 테스트 세트로 나뉩니다. 다음,이 연구에서는 AiiDA(Automated Interactive Infrastructure and Database) 프레임워크를 사용하여 밀도 함수 이론 계산을 위한 고처리량 워크플로를 개발하고 이를 사용하여 재료 데이터베이스를 구축했습니다.
DFT 해밀토니안을 목표로 DeepH는 DeepH-2 방법을 사용하여 훈련됩니다.
연구에 따르면DFT 해밀토니안은 머신 러닝의 이상적인 대상입니다.
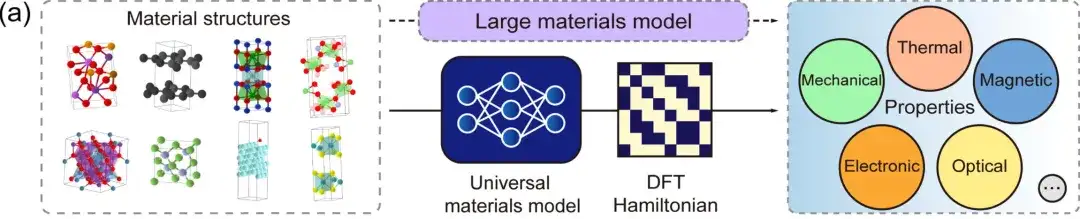
첫 번째,DFT 해밀토니안은 총 에너지, 전하 밀도, 밴드 구조, 물리적 반응과 같은 물리적 양으로부터 직접적으로 유도할 수 있는 기본적인 양입니다.DeepH 일반 재료 모델은 모든 재료 구조를 입력으로 받고 해당 DFT 해밀토니안을 생성하므로 위 그림에서 볼 수 있듯이 다양한 재료 속성을 직접 유도할 수 있습니다.
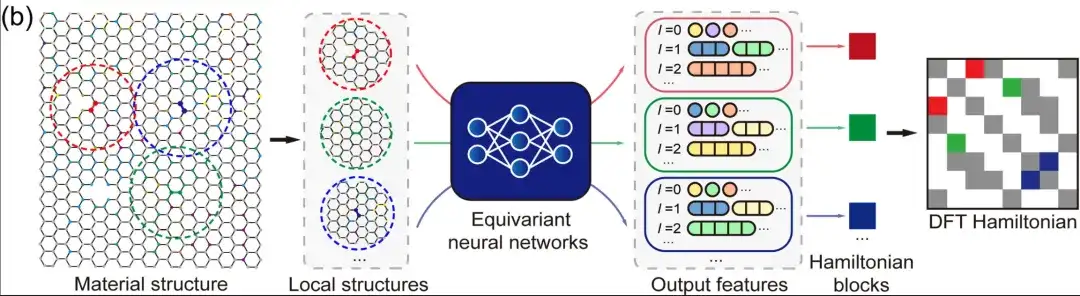
둘째,국소화된 원자 기저 집합의 경우, DFT 해밀토니안은 국소적 화학 환경에 의해 요소가 결정되는 희소 행렬로 표현될 수 있습니다.등변 신경망에서 DeepH는 위 그림에서 보듯이 서로 다른 각도 양자 수 l로 표시된 출력 특징을 사용하여 DFT 해밀토니안을 표현합니다. 따라서 전체 물질 구조의 DFT 해밀턴 행렬을 모델링하지 않고도 이웃하는 구조 정보를 기반으로 원자 쌍 사이의 해밀턴 행렬 요소를 모델링할 수 있습니다. 이를 통해 딥러닝 작업이 크게 간소화될 뿐만 아니라, 학습 데이터의 양도 크게 늘어납니다. 추론 측면에서, 딥 러닝 네트워크가 충분한 학습 데이터를 학습하면, 학습된 모델은 아직 보이지 않는 새로운 물질 구조에 대해서도 잘 일반화될 수 있습니다.
DeepH의 핵심 아이디어는 신경망을 사용하여 HDFT를 표현하는 것입니다.입력 자료 구조를 변경하여 DFT 코드로 생성된 HDFT 학습 데이터를 먼저 생성한 후, 이를 사용하여 신경망을 학습시킵니다. 이렇게 훈련된 네트워크 모델은 새로운 물질 구조를 추론하는 데 사용됩니다.
이 과정에는 두 가지 매우 중요한 사전 지식이 있습니다. 하나는 지역성의 원리입니다.이 연구에서는 DFT 해밀토니언을 국소화된 원자 샘플로 표현하고 해밀토니언을 원자 간 결합이나 원자 내 결합을 설명하는 블록으로 분해합니다. 따라서 단일 교육 자료 구조는 많은 수의 데이터에 대한 해밀토니안 블록에 해당할 수 있습니다. 더욱이 각 해밀턴 블록은 전체 구조가 아닌 국소 구조에 대한 정보를 기반으로 결정될 수 있습니다. 이러한 단순화를 통해 DeepH 모델의 높은 정확성과 전환성이 보장됩니다.
두 번째는 대칭의 원리입니다.물리 법칙은 다른 좌표계에서 볼 때에도 동일하게 유지됩니다. 따라서 해당 물리량과 방정식은 좌표 변환 하에서 동등성을 보입니다. 동등성을 유지하면 데이터 효율성이 향상될 뿐만 아니라 일반화 능력도 강화되어 DeepH의 성능을 크게 향상시킬 수 있습니다. 1세대 DeepH 아키텍처는 로컬 좌표계를 통해 동등성 문제를 단순화하고 로컬 좌표의 변환을 통해 동등한 특징을 복원합니다. 2세대 DeepH 아키텍처는 동등한 신경망을 기반으로 하며 DeepH-E3라고 합니다. 이 프레임워크에서 모든 입력, 은닉, 출력 계층의 특징 벡터는 동등한 벡터입니다. 최근, 이 연구의 저자 중 한 명이 딥 러닝을 위한 차세대 아키텍처인 DeepH-2를 제안했습니다. 효율성과 정확성 측면에서 DeepH-2가 가장 좋은 성능을 보입니다.
요약하면, 본 연구의 딥러닝 모델 DeepH는 DeepH-2 방법을 이용하여 학습되었으며, 총 1,728만 개의 매개변수를 포함하고 있다. 이는 3개의 동등한 변환 블록을 기반으로 메시지 전달에 사용될 수 있는 신경망을 형성했으며, 각 노드와 에지는 80개의 동등한 특징을 전달했습니다.재료 구조에는 원자 번호와 원자 간 거리가 내장되어 있으며, 기저 함수의 중심 범위가 0.0~9.0Å인 가우시안 평활화 전략이 채택되었습니다. 신경망의 출력 특징은 선형 층을 통과한 다음 위그너-에카르트 층을 통해 DFT 해밀토니안이 구성됩니다.
이 연구는 NVIDIA A100 GPU에서 343 에포크, 207시간 동안 학습되었습니다. 전체 학습 과정 동안 배치 크기는 1로 고정됩니다. 즉, 각 배치에는 하나의 재료 구조가 포함됩니다. 마지막으로, 초기 학습률은 4×10-4, 감소률은 0.5, 감소 인내심은 20, 선택된 최소 학습률은 1×10-5, 학습률이 이 값에 도달하면 학습이 중지됩니다.
DeepH는 뛰어난 추론 성능을 가지고 있으며 정확한 대역 구조 예측을 제공할 수 있습니다.
모델이 훈련, 검증 및 테스트 세트에서 예측한 밀도 함수 이론 해밀토니안 행렬 요소의 평균 절대 오차(MAE)는 각각 1.45, 2.35 및 2.20 meV였습니다.이는 보이지 않는 구조에 대해 추론할 수 있는 모델의 능력을 보여줍니다.
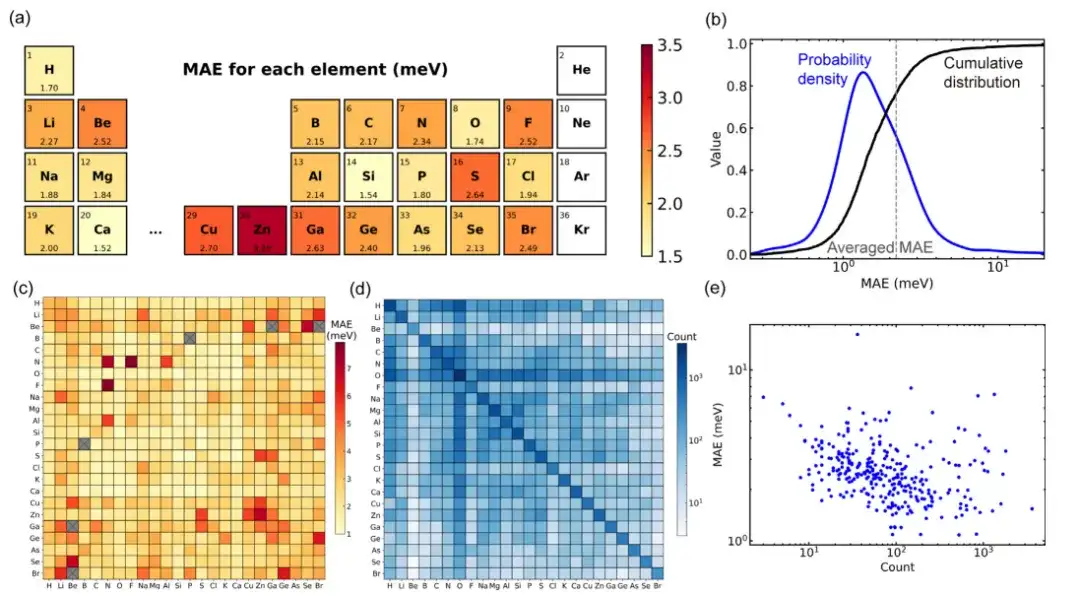
104가지 고체 재료의 대규모 재료 데이터베이스를 사용하여 Deep-2 방식으로 학습된 일반 재료 모델의 성능을 평가한 결과, 약 80%의 재료 구조가 데이터 세트의 모든 구조 중 평균(2.2 meV)보다 평균 절대 오차가 작았습니다. 단 34개의 구조(테스트 세트의 약 1.4%)만이 10 meV 이상의 평균 절대 오차를 보이는데, 이는 해당 모델이 주류 구조에 대해 좋은 예측 정확도를 가지고 있음을 나타냅니다.
데이터 세트를 추가로 분석하면, 재료 구조에 대한 모델 성능의 편차는 데이터 세트 분포의 편차로 인해 발생할 수 있습니다.연구 결과, 데이터 세트에 포함된 요소 쌍의 훈련 구조가 많을수록 해당 평균 절대 오차가 작아지는 것으로 나타났습니다. 이러한 현상은 딥러닝 일반 재료 모델에 "스케일링 법칙"이 존재한다는 것을 나타낼 수 있습니다. 즉, 더 큰 학습 데이터 세트가 모델 성능을 향상시킬 수 있습니다.
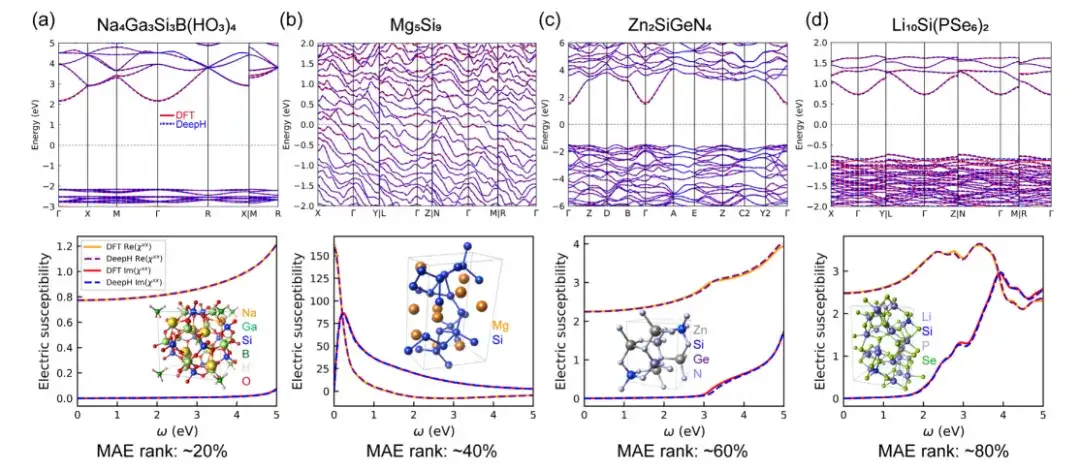
본 연구에서는 DeepH 일반 재료 모델의 재료 특성 예측 정확도를 평가하기 위해 밀도 함수 이론(DFT) 기반 및 DeepH 예측 DFT 해밀토니안을 사용하여 예제를 계산한 다음 두 가지 방법으로 얻은 계산 결과를 비교했습니다. 결과는 다음과 같습니다DeepH가 예측한 결과는 DFT가 계산한 결과와 매우 유사하여 DeepH가 재료 특성을 계산하는 데 있어 예측 정확도가 매우 높다는 것을 보여줍니다.
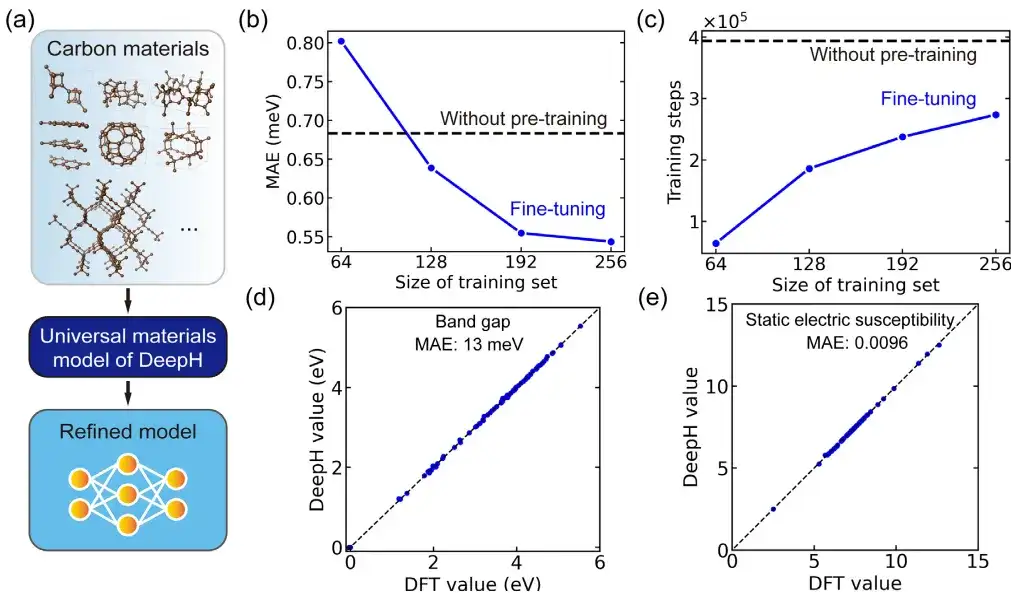
특정 응용 분야에서 이 연구는 미세 조정된 일반 재료 모델을 사용하여 탄소 동소체를 조사했습니다. 이 중 탄소 물질 데이터 세트는 사마라 탄소 동소체 데이터베이스(SACADA)에서 가져온 것으로, 서로 다른 원자 구조를 가진 총 427개의 탄소 동소체가 포함되어 있습니다.
이를 바탕으로 연구진은 일반 재료 모델을 미세 조정하고 탄소 재료에 특화된 개선된 DeepH 모델을 만들었습니다. 사전 학습이 없는 모델과 비교했을 때, 미세 조정을 통해 예측된 DFT 해밀토니언의 평균 절대 오차를 0.54 meV로 크게 줄일 수 있으며, 50% 미만의 구조를 학습하는 경우에도 비슷한 예측 정확도를 달성할 수 있습니다.
또한, 미세 조정을 통해 훈련 수렴성이 크게 향상되고 훈련 시간이 단축됩니다. 미세 조정은 예측 정확도를 높이고 학습 효율성을 강화하는 데 도움이 된다고 할 수 있습니다. 더 중요한 것은,미세하게 조정된 DeepH 모델은 재료 특성을 예측하는 데 상당한 이점을 보여주었습니다. 정밀하게 조정된 모델은 거의 모든 테스트 구조에 대해 정확한 밴드 구조 예측을 제공할 수 있습니다.
소재모델이 급증하고 있는데 AI4S는 아직 갈 길이 멀다
ChatGPT를 시작점으로 AI는 공식적으로 새로운 "빅 모델 시대"에 접어들었습니다. 이 시대는 복잡한 작업을 처리할 수 있는 딥 러닝 모델을 훈련하기 위해 방대한 데이터 세트와 고급 알고리즘을 사용하는 것이 특징입니다.재료 과학 분야에서는 이러한 대형 모델이 연구자들의 지혜와 결합되어 전례 없는 새로운 연구 시대를 열고 있습니다.이러한 대규모 모델은 엄청난 양의 과학 데이터를 처리하고 분석할 수 있을 뿐만 아니라 재료의 특성과 거동을 예측하여 새로운 재료의 발견과 개발을 가속화하고 이 분야를 보다 효율적이고 정확한 방향으로 이끌어갈 수 있습니다.
지난 기간 동안 과학을 위한 AI는 재료 과학과 끊임없이 충돌하여 새로운 불꽃을 만들어냈습니다.
중국에 본사를 둔중국과학원 물리학연구소 베이징 국가응집물질물리학연구센터의 SF10 그룹과 중국과학원 컴퓨터네트워크정보센터는 수만 개의 화학 합성 경로 데이터를 대형 모델 LLAMA2-7b에 공급하여 무기 재료의 합성 경로를 예측하는 데 사용할 수 있는 MatChat 모델을 얻었습니다. 중국 전자과학기술대학은 복단대학 및 중국과학원 닝보재료기술공정연구소와 협력하여 "피로 저항성 강유전체 재료"를 개발하는 데 성공하여, 70년 이상 이 분야에서 난제로 여겨졌던 강유전체 재료의 피로 문제를 해결하는 데 있어 세계를 선도하게 되었습니다. 상하이 교통대학교 AIMS 연구실은 차세대 지능형 소재 설계 모델인 알파 매트(Alpha Mat)를 개발했습니다. … 연구 성과가 끊임없이 나타나고 있으며, 소재의 혁신과 발견은 새로운 시대로 접어들었습니다.
전 세계를 둘러보며,구글 딥마인드는 재료과학을 위한 인공지능 강화학습 모델인 GNoME을 개발했는데, 이를 통해 열역학적으로 안정적인 결정질 물질 38만 개 이상을 찾아냈는데, 이는 "인류에게 800년간의 지적 축적을 더한 것과 같다"는 의미로, 새로운 물질을 발견하는 연구 속도를 크게 가속화했습니다. Microsoft의 MatterGen은 재료 과학 분야의 인공지능 생성 모델로, 필요한 재료 속성에 따라 새로운 재료의 구조를 수요에 따라 예측할 수 있습니다. Meta AI는 미국 대학과 협력하여 업계 최고의 촉매 소재 데이터 세트인 Open Catalyst Project와 유기 금속 프레임워크 흡착 데이터 세트인 OpenDAC을 개발했습니다. 기술 거대 기업들은 자체 기술로 재료 과학 분야를 뒤흔들었습니다.
전통적인 소재 연구 및 개발 방법과 비교했을 때, 인공지능은 더 광범위한 소재 가능성을 탐색할 수 있는 문을 열어주고 소재 발견과 관련된 시간과 비용을 크게 줄여줍니다. 그러나 과학 분야를 위한 AI는 여전히 재료 분야에서 신뢰성과 효과적인 구현 측면에서 과제에 직면해 있습니다. 여기에는 데이터 품질 보장, AI 시스템 훈련에 사용되는 데이터의 잠재적 편향 식별 및 완화가 포함됩니다. 이는 인공지능이 재료과학 분야에서 더 큰 역할을 하기까지는 아직 갈 길이 멀다는 것을 의미할 수도 있습니다.