Command Palette
Search for a command to run...
상하이 교통대학교의 Yu Xiang 연구 그룹은 다양한 유형의 RNA 수정을 식별하고 계산 비용을 크게 줄이기 위한 이전 가능한 딥 러닝 모델을 발표했습니다.

2021년 중국과학원 원사인 가오푸의 큰 호소로 mRNA 백신은 하룻밤 사이에 유명해졌고, 신종 코로나바이러스 발병 당시 사람들의 희망이 되었습니다. 오늘날 그 특별한 과거는 역사가 되었지만 mRNA 백신의 기반이 되는 RNA 변형은 여전히 빠른 속도로 발전하고 있습니다.
소위 RNA 변형은 전사 후 조절의 중요한 유형으로, 다양한 RNA 전사 후 처리 및 대사 경로에 광범위하게 관여할 수 있습니다.
RNA 변형은 진핵생물의 성장과 발달에 중요한 생물학적 기능을 수행하기 때문에 주목할 만합니다.예를 들어, 최근 연구에 따르면 포유류 배아줄기세포에서 N⁶-메틸아데노신(m⁶A)의 불안정화 효과는 다양한 질병과 관련이 있고, 5-메틸시토신(m⁵C)은 벼의 고온 내성과 관련이 있는 것으로 나타났습니다.
그러나 RNA는 다양한 유형의 변형을 가지고 있으며, 현재까지 천연 RNA에서 160가지 이상의 유형의 변형이 발견되었습니다. 이전에는 옥스포드 나노포어 테크놀로지스(ONT)가 개발한 나노포어 직접 RNA 시퀀싱(DRS) 기술과 딥러닝 방법을 결합하여 단일 염기의 변형 식별을 실현할 수 있었습니다.그러나 이 방법은 단일 샘플에서 여러 변형 유형을 동시에 감지하는 데 어려움이 있습니다.
위 질문에 대한 답변으로, 상하이 교통대학교 생명과학 및 기술대학의 종신 부교수인 위 샹의 연구 그룹과 상하이 천산 식물원의 양 준/왕 홍샤 팀은 Nature Communications에 "나노포어 직접 RNA 시퀀싱을 사용하여 여러 유형의 RNA 수정을 식별할 수 있는 전이 학습"이라는 제목의 연구 논문을 발표했습니다.DRS에서 다양한 유형의 RNA 변형을 식별할 수 있도록 하는 전이 가능한 딥 러닝 모델인 TandemMod가 개발되었습니다.
연구 하이라이트:
* 동일한 성능을 보장하는 조건 하에서 학습 데이터 양, 모델 학습 시간 등 컴퓨팅 비용을 대폭 절감
* TandemMod는 동물, 식물 및 미생물에서 다양한 유형의 RNA 수정 부위 식별 및 전사체 연구를 위한 중요한 기술 지원을 제공합니다.
* TandemMod는 RNA 백신과 같은 인공적으로 변형된 RNA를 감지하는 데에도 사용할 수 있습니다.

서류 주소:
https://www.nature.com/articles/s41467-024-48437-4
오픈소스 프로젝트인 "awesome-ai4s"는 100개가 넘는 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
데이터 세트: 여러 데이터 세트를 사용한 타겟형 훈련
연구팀은 TandemMod 모델의 성능을 훈련하고 평가하기 위해 여러 데이터 세트를 실험에 사용했습니다.
첫 번째,연구팀은 누카에우 연구실에서 생성한 ELIGOS 시험관 내 전사 데이터 세트를 사용했습니다.6개의 수정된 염기(m¹A, m6A, m5C, hm5C, m⁷G 및 Ψ)에 대해 5개의 염기 수준 특징(평균, 중앙값, 표준 편차, 신호 길이 및 염기 품질)을 계산하고 수정되지 않은 염기와 비교했습니다.
두 번째로, 연구팀은 진핵 생물 mRNA의 가장 흔한 두 가지 변형인 m⁵C와 m⁶A를 기반으로 TandemMod의 성능을 연구하기로 결정했습니다.연구자들은 Curlcake 데이터세트를 사용하여 TandemMod m⁵C 모델을 훈련했습니다.데이터 세트는 가능한 모든 5-mer를 포함하는 시험관 내 전사 시퀀스에서 파생되었으며 4:1 비율로 훈련 세트와 테스트 세트로 나뉩니다.
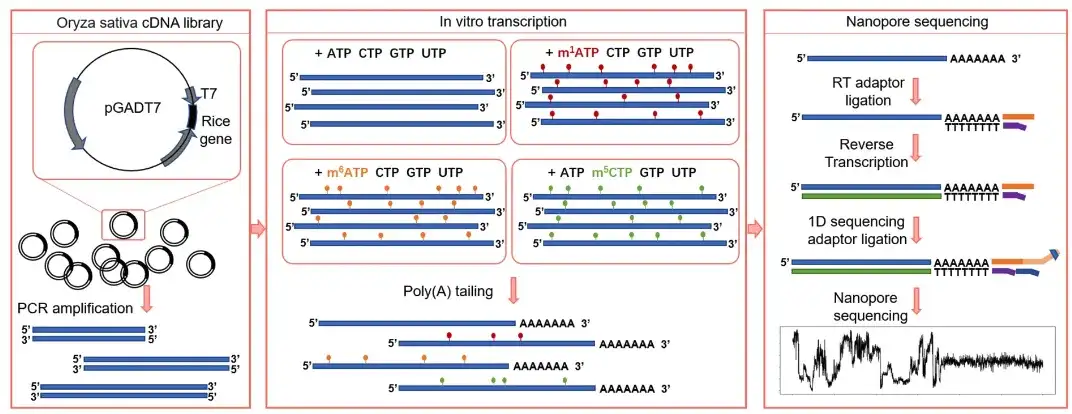
동시에, 시험관 내 합성 서열에서 전사된 RNA가 천연 서열의 전체 범위를 포괄할 수 없다는 문제를 해결하기 위해 연구팀은 T7 프로모터를 포함하는 벼 cDNA 라이브러리에 대한 시험관 내 전사를 수행하여 다양한 변형 태그가 있는 수천 개의 전사본을 얻었습니다. polyA 꼬리를 추가한 후 DRS를 통해 4개의 훈련 세트(m¹A, m6A, m5C 및 변형되지 않은 염기)가 구성되었습니다.이것을 IVET(In Vitro Apparent Transcriptome Dataset)라고 합니다.
모델 아키텍처: 딥러닝 프레임워크
연구팀은 이를 바탕으로 5개 염기에 할당된 전기 신호와 통계적 특성을 입력으로 사용하여 여러 유형의 RNA 변형을 동시에 감지할 수 있는 전이 학습 모델인 TandemMod를 학습시켰습니다.
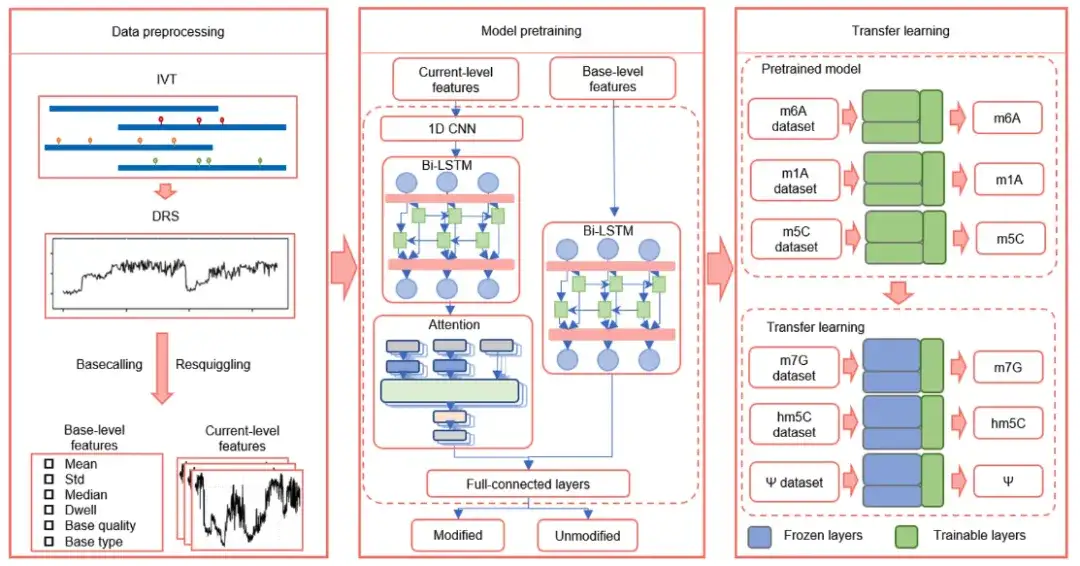
위 그림과 같이,TandemMod는 데이터 전처리, 모델 사전 학습, 전이 학습으로 구성됩니다.
그중 모델 사전 학습은 4가지 주요 구성 요소로 구성됩니다.
* 원래 전류 강도 신호의 지역적 특징을 추출하기 위한 1차원 합성 신경망(1D-CNN)
* 인접 신호 간의 장기적 상관관계를 포착하고 장기간 프로세스에서 맥락을 이해하는 능력을 향상시키는 데 사용되는 Bi-LSTM(Bi-LSTM)
* 주의 메커니즘은 각 기능의 중요성을 다른 시간에 가중시키고 모델의 중요한 신호를 포착하는 능력을 향상시키는 데 사용됩니다.
* 완전히 연결된 계층의 분류기는 모든 기능의 조합에 기반하여 예측을 내리는 역할을 합니다.
또한, 전이학습을 DRS 데이터에 적용하여 다양한 유형의 RNA 변형을 감지할 수 있는지 확인하기 위해,연구진은 IVET m5C 데이터 세트로 TandemMod를 훈련시켜 사전 훈련된 모델을 얻었습니다.TandemMod 모델에서 최상위 계층은 기능 추출기 역할을 하고 최하위 계층은 분류기 역할을 합니다. 연구진은 사전 훈련된 모델의 최상위 계층을 동결하고, 분류 오류를 최소화하기 위해 ELIGOS 훈련 세트(hm5C, m7G, Ψ 및 I)에서 최하위 계층을 다시 훈련했습니다.

2개의 에포크 이후, 모든 모델은 높은 정확도를 달성했습니다.hm⁵C, m⁷G, Ψ 및 I의 ROC-AUC는 각각 0.98, 0.95, 0.96 및 0.97에 도달했습니다. 위의 그림 a, b, c, d에 표시된 대로.
실험 결과: TandemMod는 학습 세트 데이터 양과 모델 학습 시간을 크게 줄였습니다.
실험 단계에서 연구팀은 TandemMod 모델을 XGBoost, 지원 벡터 머신(SVM), k-최근접 이웃(KNN)과 같은 기존 머신 러닝 알고리즘과 비교하여 성능을 평가했습니다. Curlcake 테스트 데이터셋 m⁶A 인식의 경우,TandemMod는 0.90의 정확도로 다른 알고리즘보다 우수한 성능을 보입니다.마찬가지로 m⁵C를 식별하기 위해 TandemMod는 0.95의 정확도를 달성했으며, 이 비교는 DRS 데이터를 사용하여 변형을 식별하는 데 있어 TandemMod가 얼마나 효과적인지를 보여줍니다.
또한 TandemMod는 생체 내에서 서로 다른 변형률 수준을 가진 샘플을 식별하는 데 있어서 tombo와 xPore보다 더 우수한 것으로 나타났습니다.이는 TandemMod가 음성 대조 샘플이 없어도 다양한 수정률을 가진 샘플을 정확하게 예측할 수 있음을 나타냅니다.
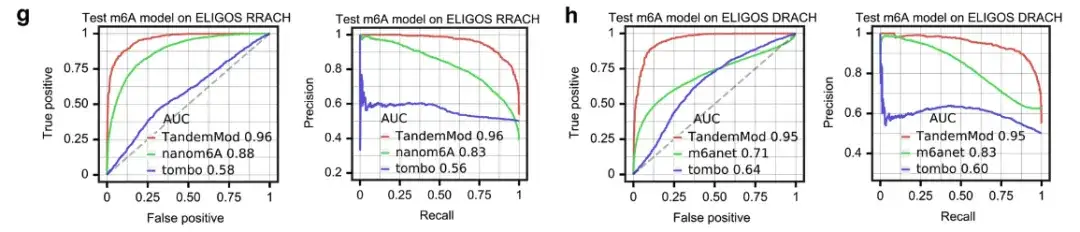
또한 연구팀은 위 그림에서 보듯이 TandemMod m⁶A 모델을 tombo, nanom6A, m6Anet과도 비교했다.
ELIGOS 발진(RA 또는 G, HA 또는 C 또는 U) 모티프에서 TandemMod, nanom6A 및 tombo의 ROC-AUC는 각각 0.96, 0.88 및 0.52였습니다. ELIGOS DRACH(DA, G 또는 U) 모티프에서 TandemMod, m6Anet 및 tombo의 ROC-AUC는 각각 0.95, 0.71 및 0.64였습니다.
이러한 결과는 다음을 나타냅니다.시험관 내 DRS 데이터 세트를 사용하여 훈련된 TandemMod는 기존 도구 중에서 가장 정확한 판독 수준 예측을 제공합니다.
연구팀은 TandemMod m⁵C 모델의 전이학습을 통한 m⁶A 검출의 분류 성능, 필요한 학습 데이터, 컴퓨팅 자원 활용도를 검증하고, 표준 인스턴스의 TandemMod m⁶A 모델과 비교하였다. 연구 결과에 따르면 전이 학습은 동일한 성능을 보장하는 동시에 학습 세트 데이터 양, 모델 학습 시간 등의 비용을 크게 줄일 수 있는 것으로 나타났습니다.
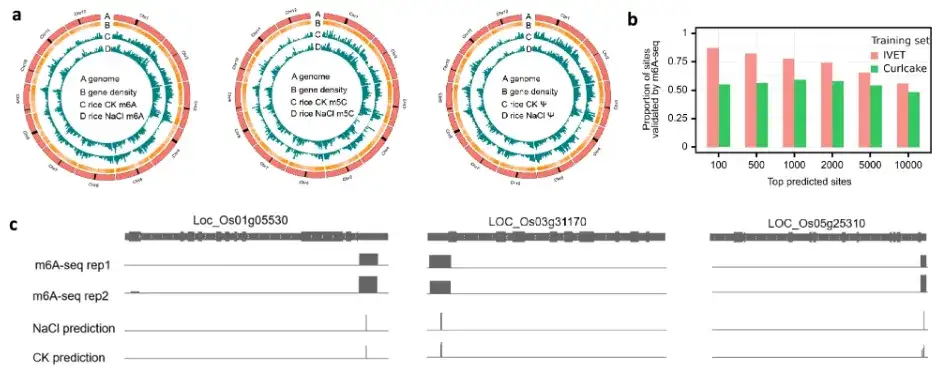
마지막으로 연구팀은 DRS 데이터 시퀀싱을 위해 TandemMod 모델이 새로운 종으로 확장될 수 있는지 테스트했으며, 인간 세포주(2개의 변형 효소 녹아웃 샘플과 5개의 야생형 샘플)를 사용하여 TandemMod의 신뢰성을 더욱 검증했습니다. 동시에 연구팀은 TandemMod를 사용하여 고염 스트레스 하에서 벼 묘목의 m⁶A, m⁵C 및 Ψ의 후성유전학적 변형 지도를 작성하고 고염 환경에서 mRNA의 m⁶A 및 m⁵C의 공동 변형과 변형 속도의 변화를 밝혔습니다. 위의 그림과 같이.
RNA 변형으로 생명 탐구의 새로운 문이 열렸다
오랜 세월 동안 사람들은 삶에 대한 탐구를 멈춘 적이 없습니다. RNA 세계 가설이 제안된 이후, RNA가 생명의 기원이라는 주장은 의심할 여지 없이 현재 가장 설득력 있는 답변 중 하나가 되었습니다. 1960년에 최초로 RNA 변형이 발견된 이래로 이는 오랫동안 과학 연구의 최우선 순위였으며 최근 연구에서도 여전히 높은 수준의 관심을 받고 있습니다.
이 논문에서 언급한 Yu Xiang의 연구 그룹과 Yang Jun/Wang Hongxia 팀, 그리고 기사에서 언급한 ONT 회사 외에도 RNA 수정 연구를 수행하는 팀과 회사가 많이 있습니다.

예를 들어, 2021년에 시안 교통-리버풀 대학의 멍 지아 교수 팀은 Nature Communications 저널에 "널리 발생하는 12가지 RNA 변형에 대한 통합 예측 및 해석을 위한 주의 기반 다중 라벨 신경망"이라는 제목의 논문을 발표했습니다.
서류 주소:https://www.nature.com/articles/s41467-021-24313-3
이 논문에서는 어텐션 메커니즘을 갖춘 다중 레이블 딥 러닝 프레임워크를 기반으로 한 MultiRM 모델을 언급합니다.널리 존재하는 12개의 전사체 부위를 동시에 예측할 수 있을 뿐만 아니라, 예측 과정에서 핵심 시퀀스도 추출하여 분석하여 다양한 유형의 RNA 변형 간에 강력한 상관관계를 밝혀냈습니다. 이를 통해 시퀀스 기반 RNA 변형 메커니즘을 보다 종합적으로 분석하고 이해하는 데 도움이 됩니다.

우연히도 Nature Biotechnology에 게재된 "xPore를 이용한 나노포어 직접 RNA 시퀀싱에서 차등 RNA 수정 식별"이라는 제목의 2021년 논문에서연구팀은 xPore를 사용하여 Direct RNA-seq 데이터에서 높은 정밀도로 RNA 변형을 식별하고 단일 고처리량 실험에서 차등적 변형 및 발현을 분석했습니다.
서류 주소:https://www.nature.com/articles/s41587-021-00949-w
이러한 연구는 우리가 RNA 세계에 대한 문을 더욱 열어 "생명의 진정한 의미"를 더욱 탐구할 수 있도록 도와줍니다. 다양한 연구의 진행에는 아직 극복해야 할 병목 현상이 많지만, "선구자"들의 끊임없는 도전으로 RNA 연구의 문이 이미 열렸습니다.
참고문헌:
1. https://news.sjtu.edu.cn/jdzh/2