Command Palette
Search for a command to run...
원클릭 경험 GLM-4-9B-Chat

최근 Zhipu AI 대형 기반 모델 GLM-4의 최신 오픈 소스 결과인 GLM-4-9B가 공개되었는데, 이는 처음으로 다중 모드 기능을 갖추고 있습니다.공식 데이터에 따르면, 더 많은 훈련을 거친 Llama-3-8B 모델과 비교했을 때 GLM-4-9B는 중국인 피험자에서 50%만큼 개선되었으며 다중 모달리티 측면에서 GPT-4V와 비슷한 수준입니다.
문맥 길이 측면에서 GLM-4-9B는 128K에서 1M으로 업그레이드 도약을 이루었습니다. 이는 한 번에 125개의 논문을 소화할 수 있는 것과 같습니다! 또한, 모델 어휘가 6만에서 15만 개로 업그레이드되었고, 중국어와 영어 이외의 언어에 대한 인코딩 효율성이 평균 30% 향상되어 소규모 언어 작업을 더 빠르게 처리할 수 있습니다.
"Llama3-8B를 능가한다"고 주장하는 이 오픈소스 모델을 모든 사람이 가능한 한 빨리 경험할 수 있도록 하기 위해,오픈베이즈 "GLM-4-9B-Chat" 모델은 이제 플랫폼의 공개 모델 섹션에서 사용할 수 있으며, 원클릭 입력을 지원하여 긴 다운로드 및 업로드 시간을 생략하고 바로 행복한 배포를 시작할 수 있습니다.
공개 모델 주소:
https://go.openbayes.com/F7pbS
또한, "GLM-4-9B-Chat 데모의 원클릭 배포" 기능도 OpenBayes 플랫폼의 공개 튜토리얼 섹션에서 동시에 출시되었습니다. 어떠한 명령도 입력하거나 복제를 클릭하지 않고도 GLM-4-9B-Chat의 뛰어난 성능을 즉시 경험할 수 있습니다.
공개 튜토리얼 주소:
https://go.openbayes.com/ulmZe
절차
PART 1 데모 운영 단계
1. 로그인 http://OpenBayes.com"공개 튜토리얼" 페이지에서 "GLM-4-9B-Chat 데모의 원클릭 배포"를 선택하세요.
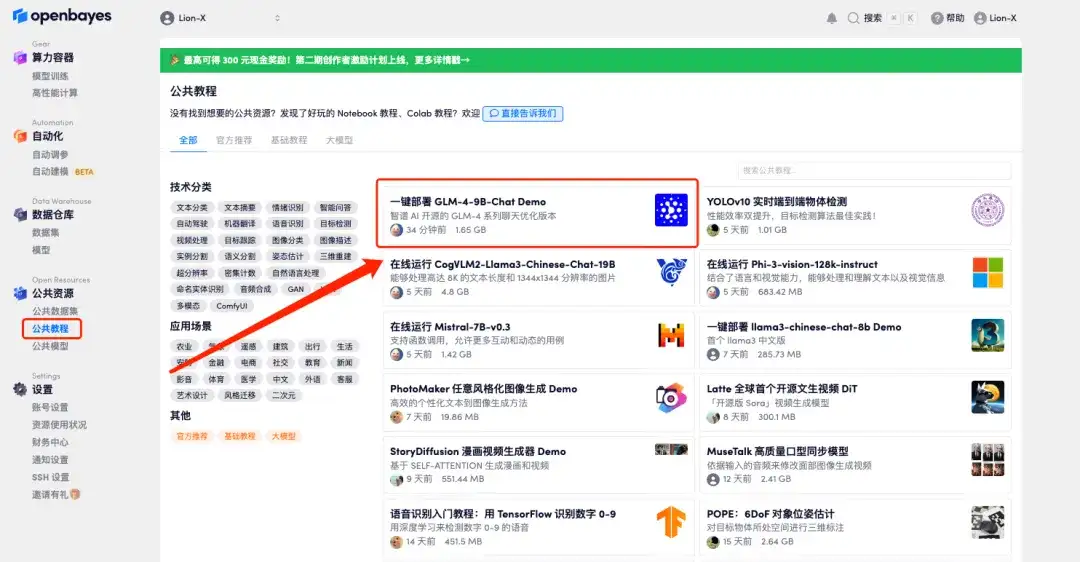
2. 페이지가 이동한 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
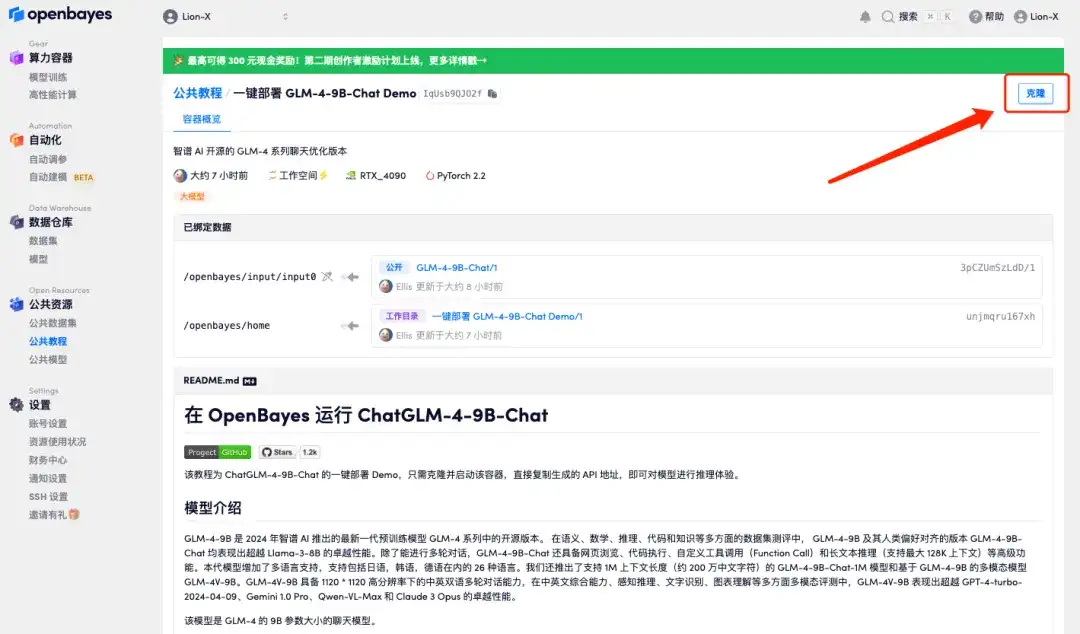
3. 오른쪽 하단에 있는 "다음: 해시레이트 선택"을 클릭합니다.

4. 이동 후 "NVIDIA GeForce RTX 4090"을 선택하고 "다음: 검토"를 클릭합니다.신규 사용자는 아래 초대 링크를 사용하여 등록하여 4시간을 받을 수 있습니다. RTX 4090 + 5시간의 무료 CPU!
샤오베이의 독점 초대 링크(복사하여 브라우저에서 열기):https://go.openbayes.com/9S6Dr
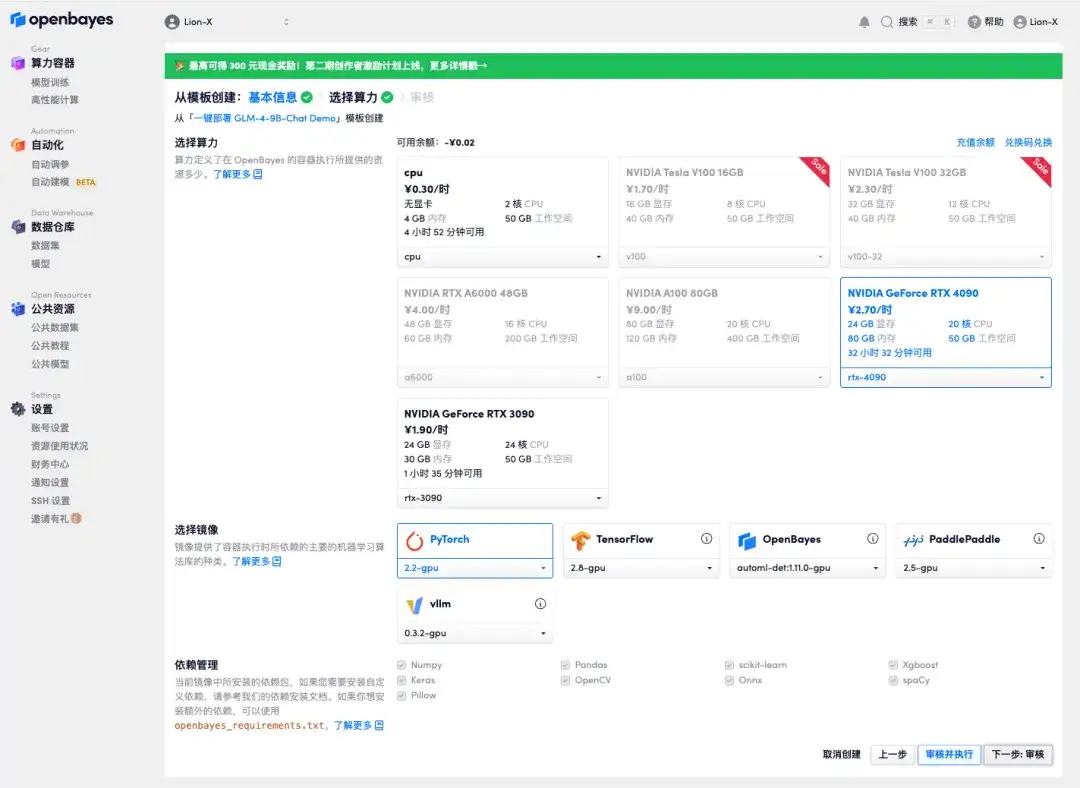
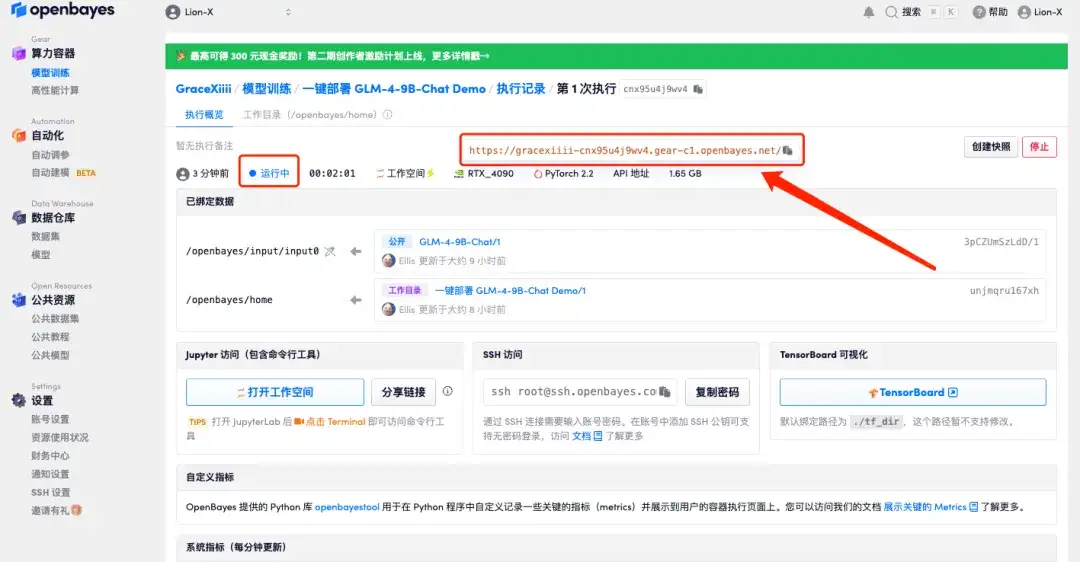
5. "계속"을 클릭하고 리소스가 할당될 때까지 기다리세요. 첫 번째 복제 과정은 약 3분이 걸립니다. 상태가 "실행 중"으로 변경되면 마우스를 "API 주소"로 이동하고 주소를 복사한 다음 새 탭에서 열어 GLM-4-9B-Chat 데모 페이지로 이동합니다.API 주소 접근 기능을 이용하기 위해서는 이용자는 실명인증을 완료해야 합니다.
문제가 10분 이상 지속되고 "리소스 할당 중" 상태로 남아 있는 경우 컨테이너를 중지했다가 다시 시작해 보세요. 재시작해도 문제가 해결되지 않으면 공식 웹사이트의 플랫폼 고객 서비스에 문의하세요.
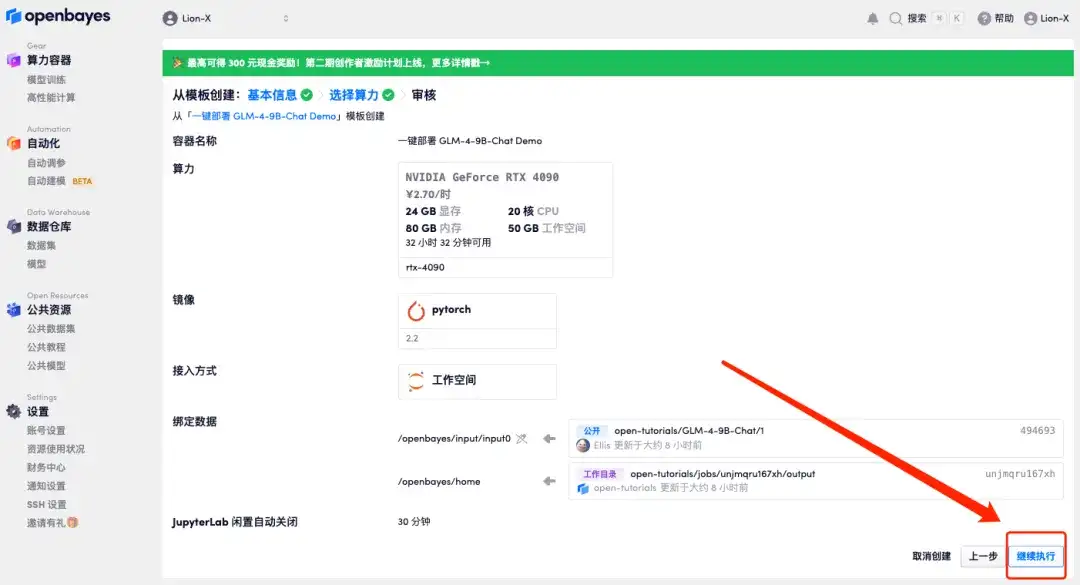
2부 데모 운영 단계
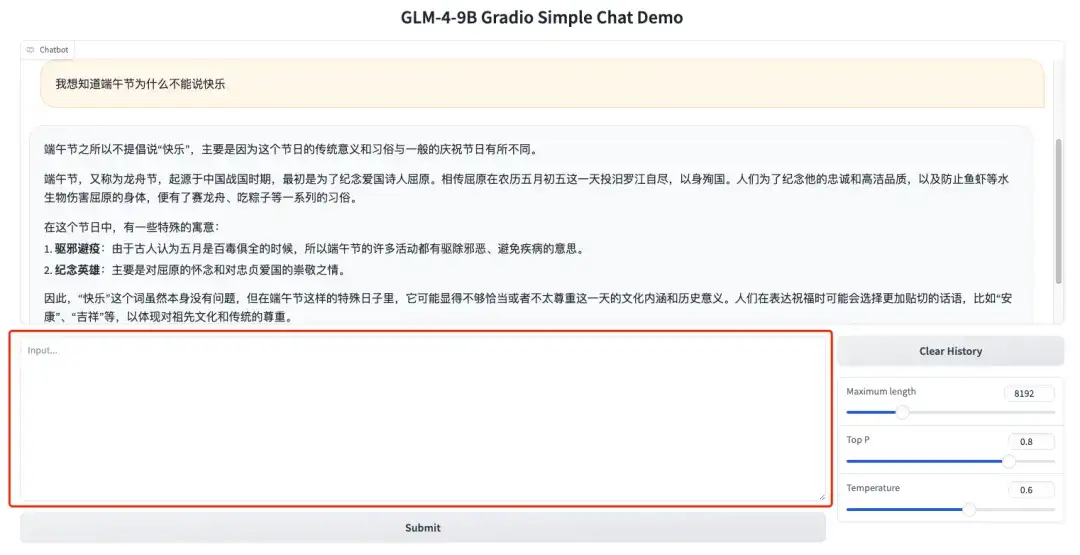
1. GLM-4-9B-Chat 데모 페이지를 열고 대화 상자에 텍스트를 입력한 후 "제출"을 클릭하여 대화를 시작하세요.

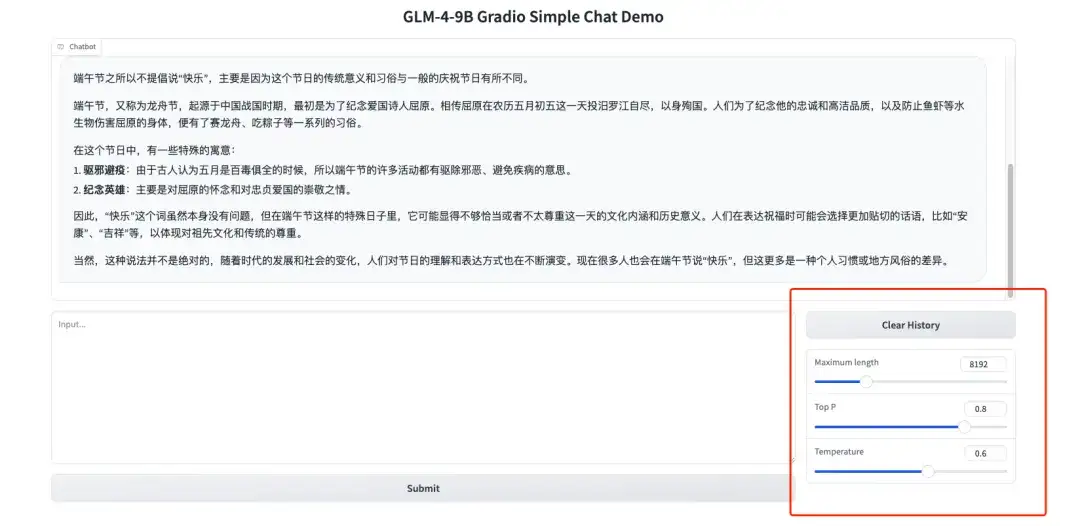
2. 오른쪽의 하이퍼파라미터 패널은 다음을 나타냅니다.
* 최대 길이: 모델이 출력할 수 있는 최대 단어 수
* 상위 P: 모델이 출력한 확률 분포에서 선택된 후보 단어의 범위를 제어합니다. 값이 클수록 텍스트 생성 중에 더 많은 단어 집합이 고려된다는 것을 의미합니다.
* 온도: 무작위성을 제어하는 하이퍼 매개변수. 값이 클수록 생성되는 텍스트가 더 무작위해집니다.
신규 사용자 혜택
등록 혜택:아래 초대 링크를 클릭하여 등록하고 영구적으로 유효한 RTX 4090 4시간 + CPU 무료 컴퓨팅 시간 5시간을 받으세요!
샤오베이의 독점 초대 링크(복사하여 브라우저에서 열기):