Command Palette
Search for a command to run...
알파폴드의 한국 버전? 딥러닝 모델 AlphaPPIMd: 단백질-단백질 복합체 구조의 앙상블 탐색을 위한

단백질은 생명의 무대에서 없어서는 안 될 역할을 합니다. 이들은 세포 구성, 수리, 에너지 전환, 신호 전달 및 수많은 핵심 생물학적 기능에 관여하는 생물체에서 가장 활동적인 분자입니다. 동시에 단백질의 구조는 기능과 밀접한 관련이 있으며, 단백질의 기능은 단백질, 펩타이드, 뉴클레오타이드 및 다양한 소분자와의 복잡한 상호작용을 통해 달성됩니다. 이 단백질-단백질 상호작용(PPI)은 세포 신호 전달부터 면역 반응, 세포 주기 조절까지 세포 내에서 일어나는 많은 생물학적 과정의 핵심입니다.
그러나 단백질의 3차원 구조와 그 상호작용 특성에 대한 우리의 이해는 아직 불완전합니다. X선 결정학 및 극저온 전자 현미경과 같은 전통적인 실험 기술이 방법은 고해상도의 단백질 구조 정보를 제공할 수 있지만, 시간과 비용이 많이 듭니다.더욱이 그들은 동적 과정과 저농도 단백질을 분석하는 데 어려움을 겪습니다. 이로 인해 사람들이 단백질 기능과 상호작용 메커니즘을 심층적으로 이해하는 데 큰 제약이 따르며, 결국 약물 설계와 단백질 공학의 발전에 영향을 미칩니다.
이에 대응하여 연세대학교의 왕젠민 박사와 그의 협력자들은 딥러닝과 생성 AI를 결합했습니다.단백질-단백질 복합체의 형태적 앙상블을 탐색하기 위해 변압기 기반 생성 신경망 학습을 사용합니다.단백질-단백질 복합체의 구조와 역학에 영향을 미치는 주요 잔류물은 다양한 분자 동역학(MD) 궤적에서 알아냈으며, 단백질-단백질 결합에 대한 기계적 통찰력을 제공했습니다.

서류 주소:
https://doi.org/10.1101/2024.02.24.581708
AlphaPPIMd 모델: 분자 동역학 시뮬레이션 기반, 자기 주의 메커니즘을 핵심으로 함
연구팀은 바르나스-바스타 복합 궤적 세트를 데이터 세트로 사용했습니다.먼저, 바르나제-바스타 복합체의 결정 구조를 단백질 데이터 뱅크(PDB)에서 다운로드하고, 리간드와 결정학적 물을 제거하여 초기 복합체 구조인 A 및 D 사슬을 추출했습니다. 그런 다음 연구진은 AmberTools의 tleap 모듈을 사용하여 누락된 수소 원자를 추가하고 Na+와 Cl- 이온을 추가하여 중화시키고 TIP3P 물 분자의 12Å 주기적 경계 상자 내에서 용매화했습니다. 마지막으로, 시스템의 토폴로지와 좌표 파일은 AmberTools의 tleap 모듈과 AMBER ff14SB 힘장을 사용하여 컴파일되었습니다.
연구팀은 분자 동역학 시뮬레이션 시스템을 사용해 랑주뱅 적분기를 사용하여 에너지를 최소화하는 전형적인 NVT 시뮬레이션을 500단계로 수행했습니다. 그런 다음 300K에서 10,000단계의 NPT 시뮬레이션을 수행하여 평형 상태에 더욱 도달했으며, 입자 네트워크 Ewald 알고리즘을 사용하여 장거리 정전기적 상호 작용을 계산했습니다. 직접적인 공간적 상호작용의 차단값은 1nm로 설정되었고, 시뮬레이션 시간 단계는 2fs로 설정되었으며, SHAKE 알고리즘은 수소 원자를 포함하는 모든 결합의 길이를 제한하도록 설정되었습니다. 그런 다음 6개의 독립적인 100 ns 분자 동역학 시뮬레이션이 수행되었습니다. 모든 시뮬레이션은 OpenMM 7.7을 사용하여 수행되었습니다.
분자 동역학 시뮬레이션을 완료한 후,연구팀은 심층 생성 모델을 사용하여 기존 분자 동역학을 사용하여 분석하기 어려운 단백질 구조 상태를 포착하는 Transformer 기반의 AlphaPPIMd 모델을 구축했습니다. AlphaPPImd 프레임워크의 핵심은 자기 주의 메커니즘으로, MD 궤적에서 단백질-단백질 복합체의 형태에 영향을 미치는 주요 아미노산 잔류물 쌍을 포착할 수 있습니다.
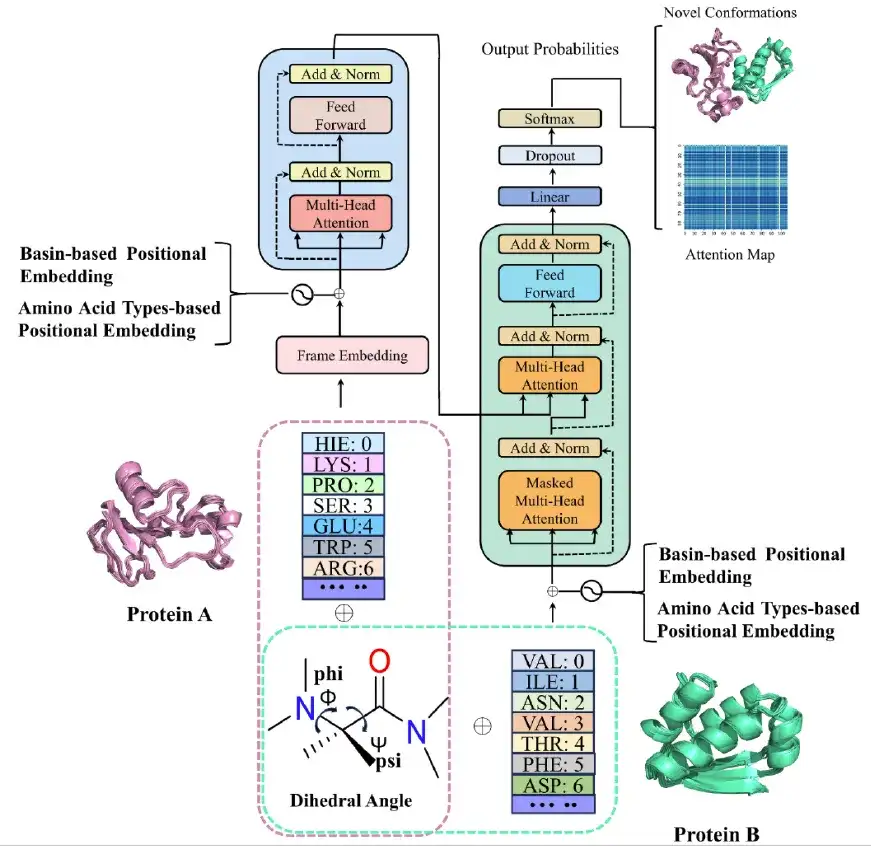
첫 번째,AlphaPPImd 프레임워크는 단백질-단백질 복합체의 MD 궤적을 전처리하여 두 사슬의 서열 길이, 서열 구성 및 아미노산 잔류물 유형을 얻고, 궤적에서 선택된 잔류물의 Φ,Ψ 각도를 계산하여 다양한 구조적 상태를 나타냅니다. (위 그림의 분홍색과 녹색 점선 상자와 같이)
둘째,연구진은 다중 헤드 자기 주의 메커니즘, 주의 점수, 기능 최적화 모듈을 포함하는 임베딩 모듈을 통해 AlphaPPImd의 인코더 모듈에 단백질-단백질 복합체 MD 궤적의 각 프레임을 입력했습니다. AlphaPPImd의 디코더는 단백질 복합체에서 다양한 유형과 위치의 잔류물이 구조에 미치는 영향을 학습하고 파악하는 데 사용됩니다.
마침내,예측 모듈은 다음 프레임에 대한 기본 상태를 반복적으로 생성하고, 모델러는 확장된 기본 상태 인코딩 궤적을 기반으로 단백질-단백질 복합체의 형태 모델을 재구성할 수 있습니다.
AlphaPPImd 디코더 모듈의 멀티헤드 셀프 어텐션 레이어는 특정 잔류물 쌍 간의 상호 작용을 학습합니다. 주의 기능은 쿼리(Q)와 키-값(KV) 출력 간의 매핑으로 볼 수 있습니다. AlphaPPImd는 단백질 복합체 잔류물 임베딩을 Q로, 글로벌 단백질 복합체 특징을 K와 V로 채택하고, Q와 K를 사용하여 어텐션 가중치를 계산합니다. 계산 공식은 다음과 같습니다.
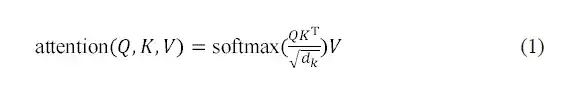
동시에 이 연구에서는 바르나스-바스타 복합체의 6개의 독립적인 100ns MD 궤적을 각각 1,000개의 프레임으로 구성된 300개의 원시 궤적으로 나누었습니다. MD 궤적은 단백질 원자만 유지되도록 사전 처리되었습니다. 각 MD 실행은 단백질-단백질 복합체의 제한된 물리적 스냅샷 세트를 제공합니다. 궤적의 각 프레임은 Φ,Ψ 인코딩의 기본 상태로 표현됩니다. 그러므로,단백질-단백질 복합체의 꼬임 상태는 텍스트 표현으로 축소됩니다.역학의 주요한 사소한 특징은 보존됩니다.
연구 결론: 평균 학습 정확도는 최대 0.995로 더 많은 단백질 복합체로 확장될 수 있습니다.
바르나스-바르스타 복합체는 총 197개의 잔기를 갖는 두 개의 서로 다른 사슬로 구성됩니다(바르나스 사슬: 잔기 108개, 바르스타 사슬: 잔기 89개). 이 연구에서는 KMeans 알고리즘을 사용하여 사이트를 0(아래 그림의 보라색), 1(아래 그림의 진한 파란색), 2(아래 그림의 녹색), 3(아래 그림의 노란색)으로 표시된 4개의 클러스터로 나눈 다음 각 클러스터의 질량 중심을 기록하고 저장하여 기저 상태에 인코딩된 비틀림 상태로부터 바르나스-바스타 복합체의 전체 원자 모델을 재구성했습니다.
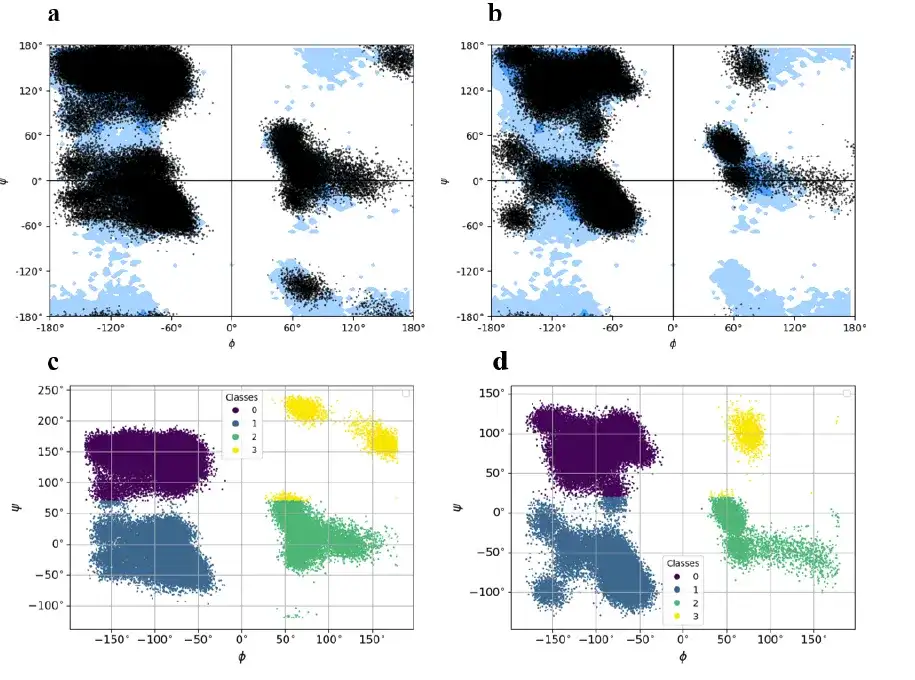
이 연구에서는 각 프레임의 궤적을 문자 벡터로 변환하는데, 각 문자 벡터는 4개의 클러스터에 해당하는 4개의 기호로 구성됩니다. 마지막으로, 유사한 표현 과정이 바르나스-바스타 복합체의 MD 궤적 데이터 세트에 있는 300개 모티프 모두에 대해 수행되었습니다.
요약하자면,바르나스-바르스타 복합체는 두 사슬에 인코딩된 잔류물의 기본 상태에 뚜렷한 차이가 있는 이종 이합체입니다.이는 바르나스-바스타 복합체가 새로운 기저 상태 인코딩 프레임워크를 생성하고 개별 단백질의 구조적 모델을 재구성하는 데 있어 상당히 다르다는 것을 의미합니다.
연구에 따르면AlphaPPImd 모델의 평균 학습 정확도는 0.995이고 평균 검증 정확도는 0.999입니다.AlphaPPImd는 빠르게 안정적인 성능을 달성했지만, Transformer 모델을 더욱 개선하고 모델이 학습한 MD 형태 분포를 풍부하게 하기 위해 이 연구에서는 여러 MD 궤적을 데이터 세트로 사용했습니다. 예를 들어, 이 연구에서는 테스트 세트의 궤적에서 무작위로 프레임을 입력으로 선택하고 훈련된 AlphaPPImd 프레임워크를 사용하여 100개의 기본 상태 인코딩 프레임을 생성했습니다.
결과는 다음과 같습니다이 모델은 성공적으로 형태를 샘플링하고 펼칠 수 있습니다.그리고 Φ와 Ψ의 이면체 제약조건은 올바르게 적용될 수 있습니다.
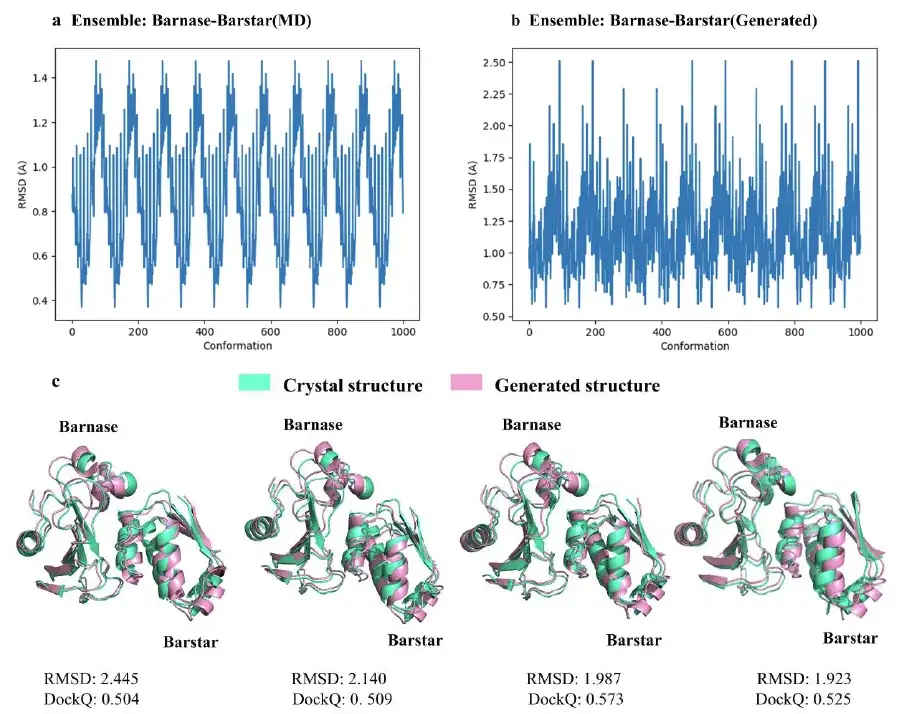
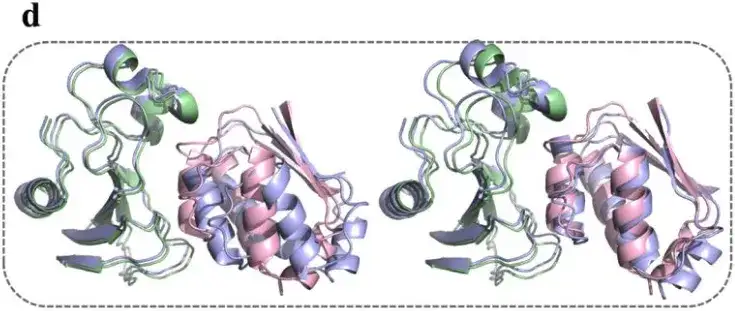
이 연구에서는 또한 AlphaPPImd 모델에 의해 생성된 1,000개의 바르나스-바르스타 복합 구조 중에서 RMSD가 2Å에 가까운 4개의 대표적인 구조를 선택했습니다. 연구 결과는 다음과 같습니다.AlphaPPImd가 생성한 단백질 복합체 구조 모델은 기준 결정 구조에 더 가깝습니다.정확도는 더 높았고(RMS 편차 < 2Å) 수용성도 더 높았습니다(DockQ ≥ 0.23).
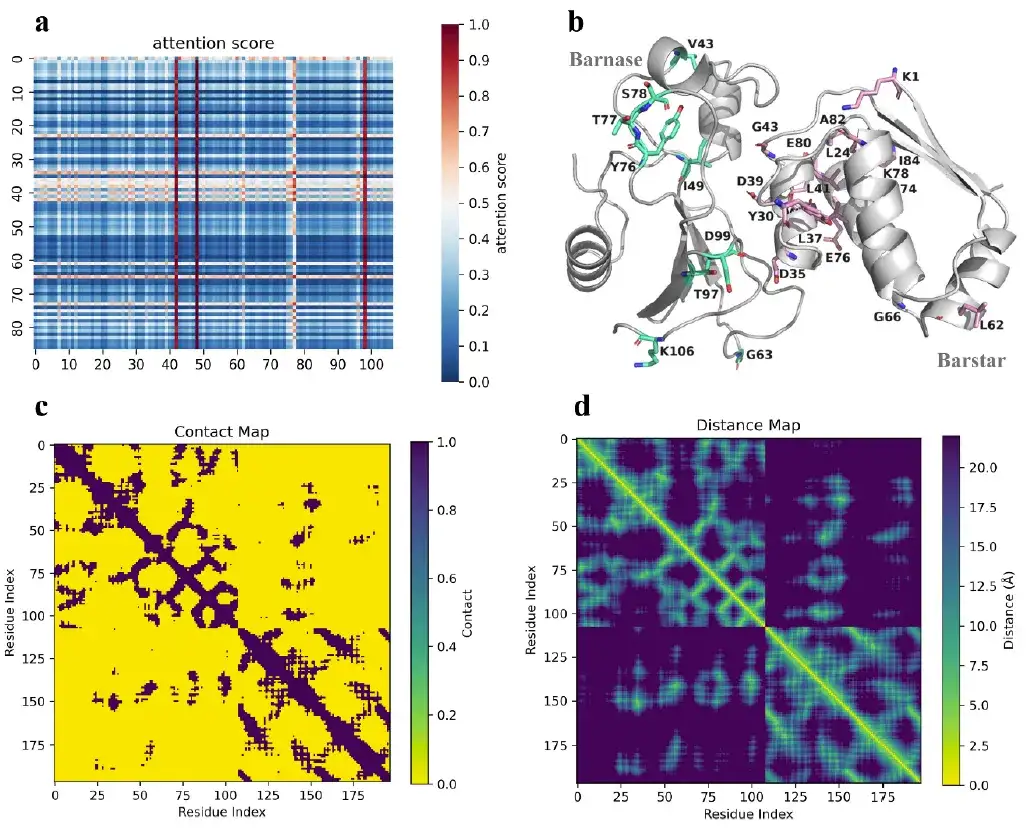
더욱이 AlphaPPImd의 주의 메커니즘은 주요 잔류물 간의 주의 가중치를 포착하고 단백질-단백질 결합에 대한 기전적 통찰력을 제공합니다.
연구에 따르면 AlphaPPImd 모델이 포착한 주요 잔류물은 주로 단백질 상호작용, 루프 및 나선의 인터페이스에 위치하는 것으로 나타났습니다.심층 생성 모델은 MD 궤적에서 바르나스-바르스타 복합체의 역학과 형태에 영향을 미치는 주요 잔류물을 포착했습니다.MD 결과를 보완하는 데 사용할 수 있습니다. 한편, AlphaPPImd 모델이 포착한 주요 잔류물은 주로 Mdm2-p53 상호작용 인터페이스에 위치해 있으며, 이는 이 모델이 다른 단백질-단백질 복합체로 확장될 수 있음을 증명합니다.
AI 단백질 예측: 알파폴드 백 가지 사상의 학교에
2016년 초, 알파고가 유명해진 이후, 딥마인드 팀은 단백질 접힘 문제에 대한 연구를 시작했습니다.
2018년 말 제13회 CASP(단백질 구조 예측에 대한 비판적 평가)에서 AlphaFold는 98개 참가자 중 1위를 차지했으며, 43개 단백질 중 25개의 구조를 정확하게 예측했습니다. 2020년에는 AlphaFold 2가 출시되어 단백질 단량체 구조를 매우 정확하게 예측하는 데 성공했습니다. 2021년 10월, DeepMind는 AlphaFold 2를 확장하고 여러 단백질의 복합체를 모델링할 수 있는 AlphaFold-Multimer라는 업데이트를 출시했습니다. 2024년 5월 8일, AlphaFold 3는 단백질에서 광범위한 생물학적 분자로 예측 범위를 확장하여 다시 한번 세상을 놀라게 했습니다.
알파폴드 2가 출시되던 당시 중국과학원 원사인 시이공은 언론에 이렇게 말했습니다. "제 생각에 이것은 인공지능이 과학 분야에 기여한 가장 큰 업적이며, 21세기 인류가 이룬 가장 중요한 과학적 혁신 중 하나입니다. 이는 인류의 자연 과학 탐구에 있어 매우 주목할 만한 역사적 업적입니다."
알파폴드의 사례를 통해 단백질 설계 분야에서 AI가 가져온 산업 혁명이 조용히 도래했습니다.
2023년에세계 최초의 AI 단백질 생성 모델인 NewOrigin(중국어 이름 "Darwin")이 세계 제조업 대회에서 공식적으로 공개되었습니다.NewOrigin의 대규모 모델은 조건부 생성 메커니즘을 기반으로 하며 AI, 분자 동역학, 양자 컴퓨팅, 습식 실험과 같은 다차원 피드백 메커니즘을 결합한 것으로 알려져 있습니다. 이 솔루션은 높은 정밀도로 단백질 서열, 단백질 기능, 단백질 지식 표현 및 기타 모달 단백질 함량을 생성하고 친화도, 안정성, 활성 및 발현과 같은 다차원 작업을 완료하여 실제 산업 응용 분야의 요구 사항을 충족합니다.
2022년 워싱턴 대학교 의과대학의 생물학자들은 Science에 두 편의 논문을 발표하면서 주요 발견을 소개했습니다. 연구자들은 다음과 같이 말했습니다.머신 러닝을 사용하면 몇 초 만에 단백질 분자를 만들 수 있습니다.예전에는 이 기간이 몇 달이 걸렸습니다. 자연에 존재하지 않는 단백질을 만드는 것은 백신 개발에 도움이 되고, 암 치료 연구를 가속화하고, 탄소 포집 도구를 개발하고, 지속 가능한 생체재료를 개발하는 데 도움이 될 것입니다.
AI 단백질 구조 예측이 단백질을 더 잘 이해하고 나아가 생명체를 이해하는 데 도움이 될 수 있다는 점에는 의심의 여지가 없습니다. 하지만 지식과 이해만으로는 충분하지 않습니다. 미래에는 과학자들이 AI를 이용해 단백질을 예측하고 의학 분야의 실질적인 문제를 해결해야 할 것입니다. 예를 들어, 필요에 따라 단백질을 변형하거나 자연에 존재하지 않는 단백질을 처음부터 설계해야 할 수도 있습니다. 앞으로의 길은 길고 힘들며, 우리는 AI가 생명과학 탐구에 더 많은 놀라움을 가져다주기를 기대합니다.