기존 약물의 새로운 활용법: 적응형 그래프 합성 신경망 기반 약물 재배치를 위한 Central South University 팀이 출시한 AdaDR

현대 사회에서 인간은 암, 당뇨병, 심혈관 질환 등 점점 더 흔해지는 복잡한 질병과 계속 싸워야 합니다. 기존 약물로는 더 이상 시장 수요를 충분히 충족시킬 수 없으며, 새로운 약물의 개발이 필수적입니다. 하지만 기존의 약물 발견 과정은 시간이 많이 걸리고 투자도 많이 필요합니다. 우리가 과거 약물과 포기된 화합물로부터 새로운 약물과 치료 표적을 사전에 선별할 수 있다면, 우리는 분명히 R&D 비용을 크게 절감하고 R&D 효율성을 개선할 수 있을 것입니다.
약물 재창출 또는 "기존 약물의 새로운 용도"는 기존 치료법을 새로운 질병 과정에 적용하는 FDA 승인 약물 개발 접근 방식입니다. 예를 들어, 실데나필은 원래 흉통을 치료하는 데 사용되었지만 나중에 PDE5(인산디에스테라아제 5형 억제제)로 밝혀지면서 시장에서 매우 인기를 얻었습니다.
기존 약물의 재창출은 약물 위험 감소, 임상 평가 주기 단축, 낮은 비용 및 높은 효율성 등의 장점으로 인해 현재 산업 연구에서 중요한 주제가 되었습니다.딥 러닝의 급속한 발전으로 그래프 합성 신경망(GCN)이 약물 재배치 작업에 널리 사용되었습니다. 그러나 기존의 GCN 기반 방법은 노드 기능과 토폴로지 구조를 심층적으로 통합하는 데 한계가 있습니다. 이에 대해 중남대학교의 연구진은 Bioinformatics에 "적응 그래프 합성 네트워크를 이용한 약물 재배치"라는 제목의 논문을 발표했습니다.
본 연구에서는 노드 특징과 토폴로지 구조를 심층적으로 통합하여 약물 재배치를 수행하는 AdaDR이라는 적응형 GCN 방법을 제안했습니다.AdaDR은 기존 그래프 합성 네트워크와 달리 적응형 그래프 합성 연산을 통해 네트워크 간의 상호작용 정보를 시뮬레이션하여 모델의 표현력을 향상시킵니다.
구체적으로, AdaDR은 노드 피처와 토폴로지 구조 모두에서 임베딩을 추출하고, 주의 메커니즘을 사용하여 임베딩의 적응적 중요도 가중치를 학습합니다.
실험 결과에 따르면 AdaDR은 약물 재배치에 있어서 여러 가지 기준 방법보다 성능이 뛰어난 것으로 나타났습니다. 또한, 사례 연구에서는 새로운 약물-질병 연관성을 발견하기 위한 탐색적 분석이 제공됩니다.
연구 하이라이트:
* 본 연구에서는 약물 재배치 작업을 위한 적응형 그래프 합성 네트워크 프레임워크를 제안하고, 위상 구조와 특징 공간에 대한 그래프 합성 연산을 수행합니다.
* 본 연구에서는 토폴로지 구조와 특징 간의 차이점을 고려하여 주의 메커니즘을 사용하여 이를 완전히 통합하여 모델 결과에 대한 기여도를 구분합니다.
* 본 연구에서 제안하는 모델은 약물 재위치 작업에서 실용적이며 약물 개발 실패 위험을 줄이는 데 도움이 됩니다.
서류 주소:
https://academic.oup.com/bioinformatics/article/40/1/btad748/7467059
데이터세트 다운로드 주소:
공식 계정을 팔로우하고 "이전"이라고 답글을 달면 전체 PDF를 받을 수 있습니다.
데이터 세트: 4가지 주요 벤치마크 데이터 세트 사용
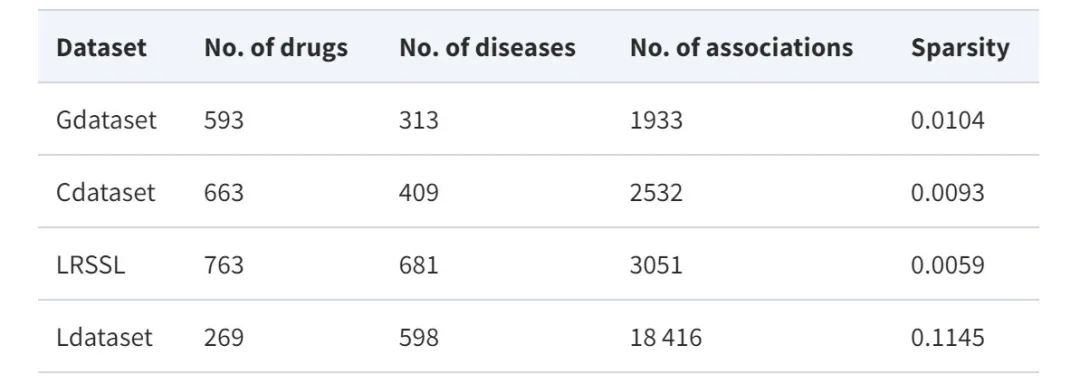
제안된 모델의 성능을 종합적으로 평가하기 위해,이 연구에서는 약물 재배치 작업에 널리 사용되는 네 가지 벤치마크 데이터 세트인 Gdataset, Cdataset, Ldataset, LRSSL을 활용했습니다.
* G데이터셋:황금 표준 데이터 세트로 간주되는 이 데이터 세트에는 DrugBank의 593개 약물과 OMIM 데이터베이스에 나열된 313개 질병 간의 1,933개 확인된 약물-질병 연관성이 포함되어 있습니다.
* C데이터셋:663개의 약물, 409개의 질병, 2,352개의 상호작용하는 약물-질병 연관성이 포함되어 있습니다.
* L데이터셋:CTD 데이터세트에서 수집한 이 데이터세트에는 269개 약물과 598개 질병 간의 18,416개 연관성이 포함되어 있습니다.
*LRSSL:763개 약물과 681개 질병을 포함하는 총 3,051개의 검증된 약물-질병 연관성이 포함되었습니다.
동시에, 약물/질병 특징 맵을 구축하기 위해 이 연구는 약물과 질병의 유사성 특성도 활용했습니다. 데이터 세트 통계는 다음 표에 나와 있습니다.
모델 아키텍처: 새로운 적응형 GCN 프레임워크 AdaDR
본 연구에서 제안하는 AdaDR 모델 프레임워크는 주로 세 가지 구성요소로 구성된다. 다음 그림과 같이:
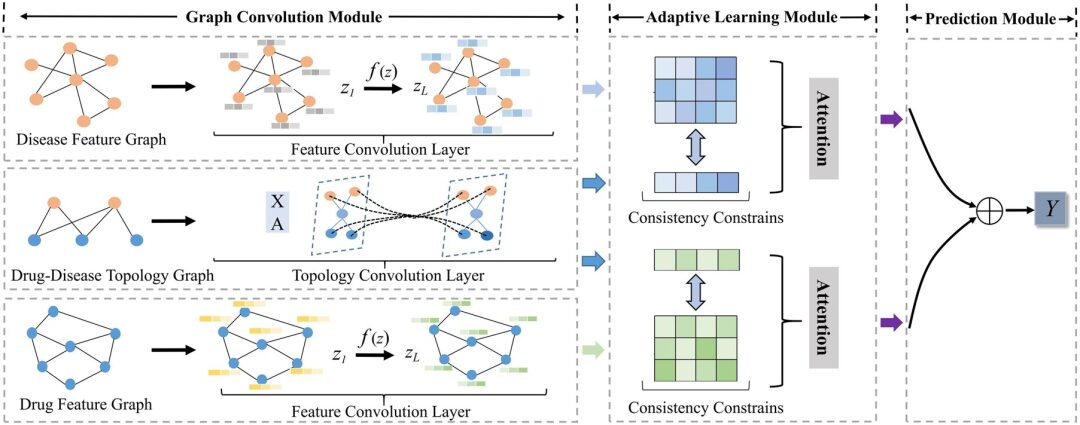
* 그래프 합성 모듈:약물/질병 임베딩을 피처 공간과 토폴로지 공간에서 표현하기 위해 피처 합성곱 계층과 토폴로지 합성곱 계층을 포함합니다.
* 적응형 학습 모듈:주의 메커니즘은 획득된 임베딩의 중요성을 구별하는 데 사용됩니다. 이 모듈에서는 일관성 제약 조건을 사용하여 피처 공간과 위상 공간 간의 공통적인 의미 정보를 추출합니다.
* 예측 모듈:임베딩은 결과를 예측하기 위해 출력으로 연결됩니다.
연구 결과: AdaDR은 약물 재조정에서 다양한 기준 방법을 능가합니다.
전반적으로, 새로운 모델인 AdaDR은 약물 재배치 작업의 성능을 크게 향상시킬 수 있습니다.
첫째, 교차 검증에서의 성능은 다음과 같습니다.이 연구에서는 AdaDR 및 기타 모델에 대해 10겹 교차 검증을 수행하고 결과의 평균과 표준 편차를 계산했습니다.
결과에 따르면, AdaDR의 기능 통합 기능으로 인해 10배 교차 검증을 통해 얻은 4개 데이터 세트에 대한 최종 평균 결과가 비교 대상인 모든 방법보다 우수한 것으로 나타났습니다.
예를 들어, Gdataset, Cdataset, LRSSL 및 Ldataset의 4개 벤치마크 데이터 세트에서이 연구의 결과는 두 번째로 좋은 방법인 DRHGCN의 AUPRC(정밀도-재현율 면적)보다 각각 9.8%, 9.1%, 9.1%, 7.1% 더 높아서 새로운 방법의 효과성을 충분히 입증했습니다.
다음은 새로운 약물의 잠재적 징후를 예측하는 능력입니다.이 연구에서는 AdaDR이 새로운 약물의 잠재적 적응증을 예측하는 능력을 평가하기 위해 새로운 실험을 수행했습니다.
다른 7가지 방법과 비교했을 때 AdaDR이 가장 좋은 성능을 보입니다(아래 그림의 파란색 막대는 AdaDR을 나타냅니다). 아래 그림(a)에서 볼 수 있듯이 AUROC(수신기 작동 특성 곡선 아래의 면적) 측면에서 AdaDR은 0.948의 AUROC 값을 달성하여 다른 방법보다 우수합니다. 한편, 아래 그림(b)에서 볼 수 있듯이 AdaDR은 다른 모든 방법보다 높은 0.393의 AUPRC를 달성했습니다.
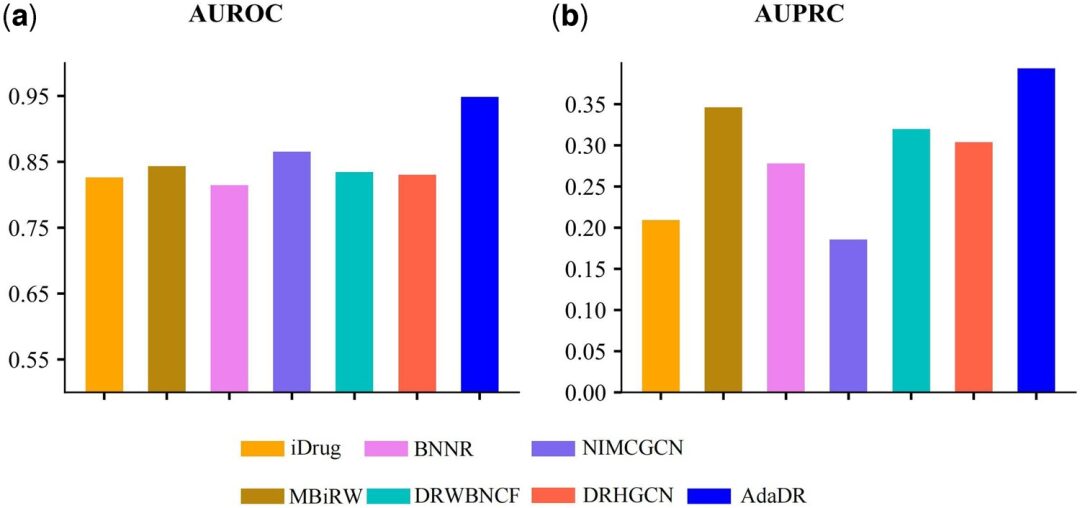
(a) AdaDR 및 기타 경쟁 방법을 사용하여 얻은 예측 결과의 AUROC.
(b) AdaDR 및 기타 경쟁 방법을 적용하여 얻은 예측 결과의 AUPRC.
AdaDR의 성능을 더욱 검증하기 위해 연구팀은 알츠하이머병(AD)과 유방암(BRCA)에 대한 후보 약물을 예측하는 데에도 AdaDR을 적용했다는 점도 언급할 가치가 있습니다.
그 중 알츠하이머병은 점진적으로 진행되는 신경퇴행성 질환으로 현재까지 효과적인 약물은 없습니다. 유방암은 유방 상피 세포가 다양한 발암 요인의 영향으로 통제 불가능하게 증식하는 현상입니다. 파클리탁셀, 카보플라틴 등 유방암 치료를 위한 다양한 약물이 이미 존재하지만, 더 많은 약물 옵션이 더 나은 치료 옵션을 제공할 수 있을 것입니다. 아래 표는 증거가 뒷받침된 약물 후보를 보고합니다.
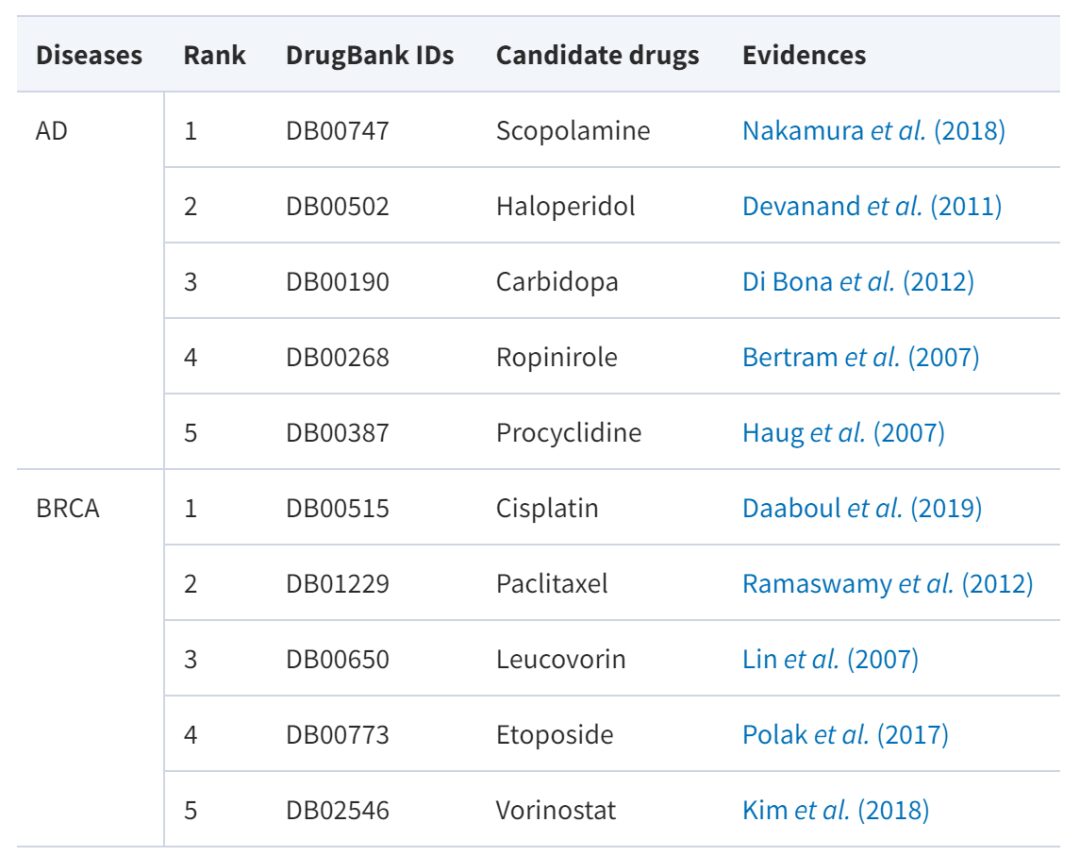
AdaDR 예측 점수에서 상위 5개 약물 중 많은 약물이 권위 있는 출처와 문헌을 통해 검증된 것을 볼 수 있습니다(성공률 100%). 더욱이 이 연구의 모델은 해석 가능한 결과를 산출할 수 있습니다. 예를 들어 파클리탁셀을 살펴보면, 이 모델은 그것이 유방암을 치료할 수 있다고 예측합니다. 이는 실제로 권위 있는 출처와 문헌에 의해 뒷받침됩니다.
흥미로운 점은 연구자들이 훈련 세트에 도세탁셀이 포함되어 있다는 것을 발견했다는 것입니다. 반면, 파클리탁셀과 도세탁셀은 같은 파클리탁셀 핵심을 가진 유사한 분자입니다.이는 새로운 모델이 약물 유사성 정보를 활용해 의미 있는 예측을 할 수 있음을 보여줍니다.
제약 R&D 투자 수익률은 계속해서 감소하고 있으며, 약물 재조정이 교착 상태를 깨는 열쇠가 될 수 있습니다.
오늘날 제약회사들은 전례 없는 변화를 겪고 있습니다. 코로나19 팬데믹과 그에 따른 경제 침체는 제약 회사에 일련의 어려움과 불확실성을 안겨주었고, 혁신을 통한 수익은 모든 제약 회사의 최우선 과제가 되었습니다.
바이오제약 기업들은 지난 10년 동안 혁신을 위한 R&D에 많은 투자를 했지만, 같은 기간 동안 수익은 크게 감소했습니다. 딜로이트 헬스 솔루션 센터가 발표한 "2019년 제약 혁신 수익률 평가"에 따르면, 2019년 제약 산업의 R&D 투자 수익률은 1.8%에 불과해 2010년 이후 최저 수준을 기록했습니다. 10개 보고서의 자료에 따르면, 제약 회사의 R&D 투자 수익률은 지난 10년 동안 하락 추세를 보였습니다.
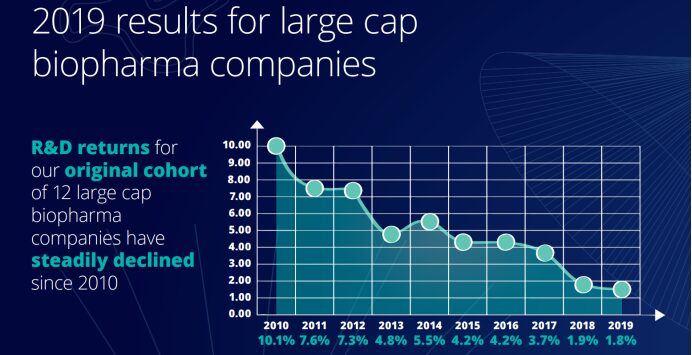
뿐만 아니라, 각 신약의 출시 후 최고 매출도 2018년 4억 700만 달러에서 2019년 3억 7,600만 달러로 감소하여 처음으로 4억 달러 아래로 떨어졌고, 2010년 8억 1,600만 달러의 절반에도 미치지 못했습니다. 신약 출시 비용은 2010년 11억 8,800만 달러에서 2019년 19억 8,100만 달러로 2010년 대비 6억 7,100만 달러 증가했습니다.최고 매출의 감소는 새로운 약물을 시장에 출시하는 데 드는 평균 비용의 증가와 극명한 대조를 이루는데, 이는 제약 회사들이 그 어느 때보다 연구 개발 과정에 많은 시간을 투자하고 있음을 시사합니다.
재분류된 약물은 약물을 시장에 출시하는 데 필요한 초기 비용과 시간을 절약할 수 있으므로 기초 연구 작업에서 임상 치료로의 전환을 가속화할 수 있습니다. 업계 관계자에 따르면, 새로운 약물은 연구 개발 초기부터 시판 허가 승인까지 시험관 내 연구, 전임상 동물 실험, 임상 1상, 2상, 3상 등 일련의 연구를 거쳐야 합니다. 일반적으로 10년에서 15년이 걸리고 비용은 최소 10억 달러가 듭니다. 비교해보면, 일부 조사에 따르면 약물을 재판매하는 데 드는 비용은 평균 3억 달러이고 시장에 출시되기까지 약 6.5년이 걸립니다.
약물 재위치화에는 주로 머신 러닝 기반 방법, 빅데이터 마이닝 및 위치 지정 기반 방법, 생체 내 위치 지정 기반 방법이 포함됩니다.생체 내 방법과 비교했을 때, 머신 러닝과 빅데이터 마이닝을 기반으로 한 약물 재위치 기술은 빠른 속도와 낮은 비용이라는 장점이 있으며, 잠재적으로 강력한 기술이 되었습니다.
"머신 러닝과 빅 데이터 마이닝을 기반으로 한 약물 재분배 알고리즘에 대한 고찰"이라는 논문에서는 최근 몇 년간의 계산적 약물 재분배 연구 진행 상황을 소개합니다.
안에,기존의 머신러닝 알고리즘 방식을 기반으로,먼저, 약물 및 부작용 정보, 약물의 화학 구조 정보, 질병 및 유전자 관련 정보를 통합한 후, 특징 추출 및 특징 선택을 통해 학습 데이터를 얻고, 이후 관련 머신 러닝 알고리즘을 선택하여 학습하고, 마지막으로 학습된 알고리즘 모델을 사용하여 약물 재배치 결과를 얻습니다.
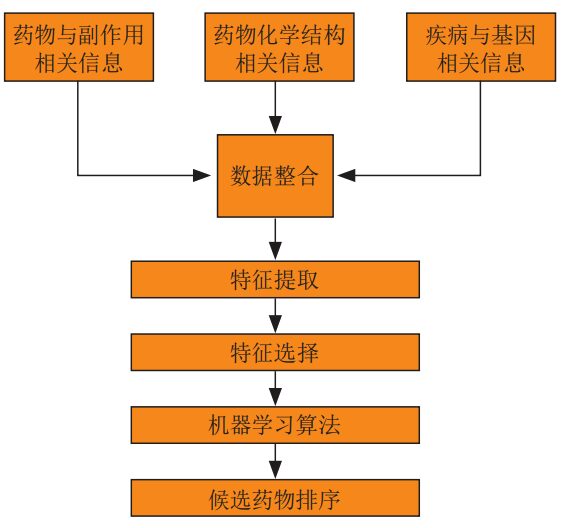
딥러닝 기반 방법에서는일부 연구자들은 약물 개발의 여러 측면에서 딥 러닝 신경망과 다양한 머신 러닝 방법을 체계적으로 비교했습니다. 연구 결과에 따르면 딥러닝은 기존 머신러닝 알고리즘보다 더 나은 성능을 보였습니다.
네트워크 유사성 추론 방법에서는동중국과학기술대학 연구팀은 약물-표적 이분 네트워크의 위상적 유사성만을 사용하여 기존 약물의 새로운 표적을 추론하는 네트워크 기반 추론(NBI) 방법을 제안했습니다.
빅데이터 마이닝 기술의 발전으로, 머신러닝과 빅데이터 마이닝 알고리즘을 기반으로 한 약물 재분배는 질병 치료에 점점 더 효과적인 방법을 제공할 것이며 생물의학 연구의 초점이 되었습니다. 미래의 약물 재조명 과정에서 합리적 추론과 계산 모델링이 중요한 역할을 할 것이라고 믿을 만한 이유가 있습니다.
참고문헌:
1.https://www.cn-healthcare.com/article/20191224/content-527902.html
2.https://pps.cpu.edu.cn/cn/article/pdf/preview/b286f85e-a37a-4007-ab94-918629aef556.pdf
3.https://mp.weixin.qq.com/s/lD-HyfwUHiX4f-llS6lykQ